编码器结构
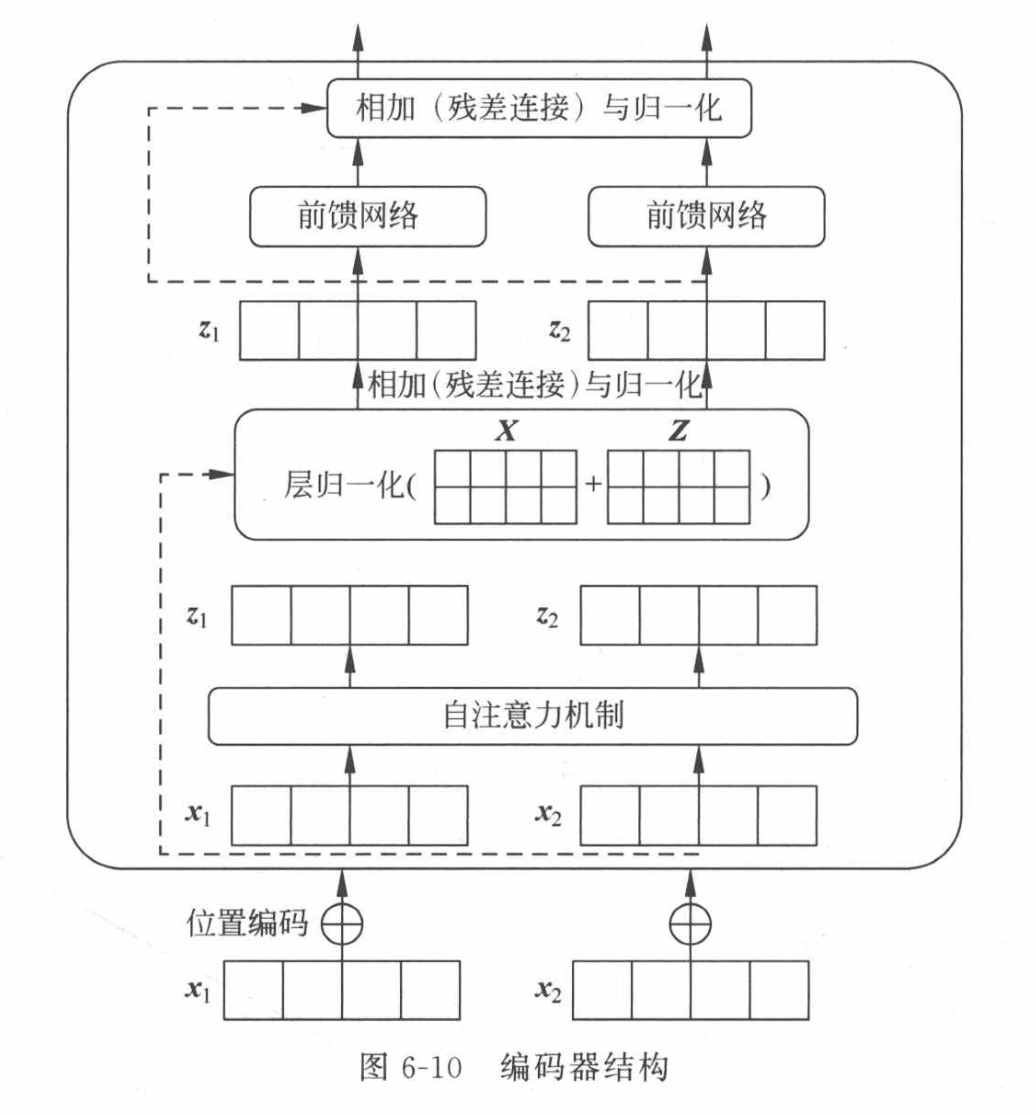
每个编码器中的自注意力层周围都有一个残差连接,然后是层归一化步骤。归一化的输出再通过前馈网络(FeedForward Network,FFN)进行映射,以进行进一步处理。前馈网络本质上就是几层神经网络层,其中间采用ReLU激活函数,两层之间采用残差连接。
- 残差连接可以帮助梯度进行反向传播,让模型更快更好地收敛。
- 层归一化用于稳定网络,减轻深度学 习模型数值传递不稳定的问题。
至于Transformer中的FNN是一个MLP,它在自注意力机制之后对序列中的每个向量单独应用。FNN起到以下两个主要作用。
(1)引人非线性:虽然自注意力机制能捕捉序列中不同位置的向量之间的依赖关系,但它本质上是线性的。通过引人FNN层,Transformer可以学习到输人序列的非线性表示,这有助于模型捕捉更复杂的模式和结构。
(2)局部特征整合:FNN层是一个MLP,对序列中每个位置的向量独立作用。这意味着它可以学习到局部特征并整合这些特征,以形成更丰富的特征表示。这种局部特征整合与自注意力机制中的全局依赖关系形成互补,有助于提高模型性能。换句话说,自注意力机制学习的是向量之间的关系,而FNN学习的是每个向量本身更好的特征表示。

GPT
