锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer PyTorch2内置实现
PyTorch的Transformer实现主要封装在torch.nn中,核心是四个相互关联的类,它们共同构成了一个完整的编码器-解码器架构。为了便于你理解各部分的关系,我将它们梳理成了以下结构图:
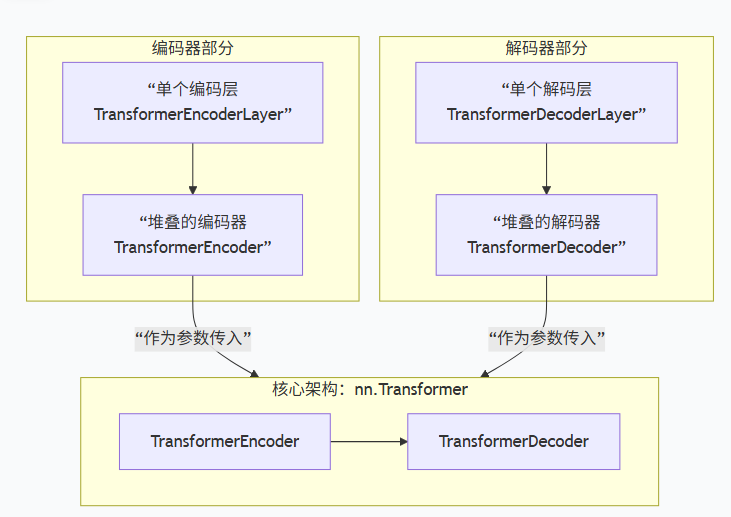
下面是每个组件的关键说明:
-
nn.TransformerEncoderLayer :这是最基础的编码单元。它包含一个多头自注意力机制 和一个前馈神经网络,每个子层后都接有残差连接和层归一化。
-
nn.TransformerEncoder :它的作用是将多个
TransformerEncoderLayer堆叠起来,上一层的输出作为下一层的输入。 -
nn.TransformerDecoderLayer :比编码层复杂,它包含三个核心子模块:掩码多头自注意力 (防止看到未来信息)、多头交叉注意力 (关注编码器输出)、前馈神经网络。
-
nn.TransformerDecoder :与编码器类似,负责堆叠多个
TransformerDecoderLayer。 -
顶层nn.Transformer类 :这是你通常直接调用的类。在初始化时,你需要传入定义好的编码器和解码器(或指定层数由内部自动创建),并通过
forward方法接收源序列和目标序列进行计算。
我们看一个应用示例:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
# 随机种子以确保可重复性
torch.manual_seed(0)
np.random.seed(0)
random.seed(0)
# 简单的数据集,输入序列和目标序列
input_sequences = [
[1, 2, 3, 4],
[1, 3, 2, 4],
[2, 1, 4, 3],
[4, 3, 2, 1],
]
target_sequences = [
[4, 3, 2, 1],
[4, 2, 3, 1],
[1, 4, 3, 2],
[2, 1, 3, 4],
]
# 超参数
num_epochs = 1000
learning_rate = 0.01
num_heads = 2 # 多头注意力的头数
num_layers = 2 # 编码解码器的层数
input_dim = 5 # 最大词汇表大小 + 1
output_dim = 5 # 最大词汇表大小 + 1
seq_length = 4
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, seq_length, num_heads, num_layers):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(input_dim, 16)
self.transformer = nn.Transformer(d_model=16, nhead=num_heads, num_encoder_layers=num_layers,
num_decoder_layers=num_layers)
self.fc_out = nn.Linear(16, output_dim)
def forward(self, src, tgt):
src = self.embedding(src) # [batch_size, seq_length, embedding_dim]
tgt = self.embedding(tgt) # [batch_size, seq_length, embedding_dim]
# 转置为[seq_length, batch_size, embedding_dim]
src = src.permute(1, 0, 2)
tgt = tgt.permute(1, 0, 2)
output = self.transformer(src, tgt) # [seq_length, batch_size, embedding_dim]
output = output.permute(1, 0, 2) # [batch_size, seq_length, embedding_dim]
return self.fc_out(output)
# 数据准备
input_tensor = torch.tensor(input_sequences, dtype=torch.long)
target_tensor = torch.tensor(target_sequences, dtype=torch.long)
# 模型实例化
model = TransformerModel(input_dim, output_dim, seq_length, num_heads, num_layers)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 创建了一个交叉熵损失函数实例
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 创建一个Adam优化器实例
# 训练循环
for epoch in range(num_epochs):
model.train() # 进入训练模式
optimizer.zero_grad() # 清空梯度
output = model(input_tensor, target_tensor[:, :-1]) # 输入目标序列的前n-1个
output = output.reshape(-1, output_dim) # [batch_size * (seq_length - 1), output_dim]
target = target_tensor[:, 1:].reshape(-1) # 目标序列去掉第一个元素并reshape
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 模型评估
def evaluate(model, input_seq):
model.eval()
input_tensor = torch.tensor(input_seq, dtype=torch.long).unsqueeze(0) # 添加batch维
tgt = torch.zeros((1, seq_length), dtype=torch.long) # 初始化目标序列
output = []
for _ in range(seq_length):
with torch.no_grad():
pred = model(input_tensor, tgt)
pred_token = pred[:, -1, :].argmax(dim=-1) # 预测最后一个token
output.append(pred_token.item())
tgt[0, -1] = pred_token.item() # 更新目标序列
return output
# 测试模型
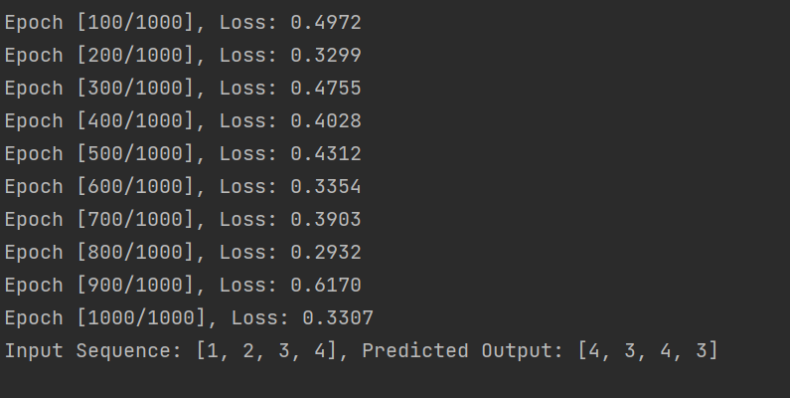
test_input = [1, 2, 3, 4]
predicted_output = evaluate(model, test_input)
print(f'Input Sequence: {test_input}, Predicted Output: {predicted_output}')运行结果: