1. 论文摘要总结表
| 项目 | 内容 |
|---|---|
| 论文标题 | End-to-End Object Detection with Transformers (DETR) |
| 作者/机构 | Nicolas Carion 等 / Facebook AI |
| 核心创新点 | 1. 直接集合预测 :将检测视为集合预测,移除NMS和Anchor。 2. Transformer架构 :引入Transformer进行全局上下文建模。 3. 二分图匹配损失 :使用匈牙利算法进行预测框与真实框的一对一匹配。 4. 对象查询 (Object Queries):引入可学习的查询嵌入来探测图像中的对象。 |
| 主要架构 | CNN骨干网 + Transformer编码器 + Transformer解码器 + 前馈网络 (FFN) |
| 性能表现 | 在COCO数据集上与Faster R-CNN精度相当;大目标检测更优,小目标稍弱;推理代码极其简洁(<50行PyTorch代码)。 |
| 优势 | 架构简单,无需自定义层;端到端训练;全局视野;易于扩展(如全景分割)。 |
| 局限性 | 训练时间极长(需要更长的周期收敛);小目标检测性能不如改进后的Faster R-CNN;计算复杂度较高。 |
2. 论文具体实现流程
输入:
- 一张图像 ximgx_{\text{img}}ximg,尺寸为 3×H0×W03 \times H_0 \times W_03×H0×W0(训练时会进行批处理和Padding)。
处理流程:
-
特征提取 (CNN Backbone):
- 图像通过ResNet-50等骨干网。
- 输出 :低分辨率特征图 f∈RC×H×Wf \in \mathbb{R}^{C \times H \times W}f∈RC×H×W(通常 C=2048,H=H0/32,W=W0/32C=2048, H=H_0/32, W=W_0/32C=2048,H=H0/32,W=W0/32)。
-
降维与展平:
- 使用 1×11 \times 11×1 卷积将通道数 CCC 降至 ddd(如256)。
- 将空间维度折叠,得到序列 d×HWd \times HWd×HW。
-
位置编码:
- 生成固定的空间位置编码(Positional Encodings),并添加到特征序列中(在每一层注意力输入处)。
-
Transformer编码器 (Encoder):
- 输入特征序列进行多层自注意力(Self-Attention)和前馈网络(FFN)处理。
- 作用:利用全局注意力分离对象实例,增强特征上下文。
-
Transformer解码器 (Decoder):
- 输入 :NNN 个可学习的对象查询 (Object Queries)(初始化为随机向量)。
- 交互:查询与编码器输出的特征进行交叉注意力(Cross-Attention),并进行查询间的自注意力。
- 输出 :NNN 个解码后的输出嵌入。
-
预测头 (FFN):
- 每个输出嵌入通过共享的FFN。
- 分类分支 :预测 NNN 个类别(包括"无对象" ∅\varnothing∅)。
- 回归分支 :预测 NNN 个边界框坐标(中心点、宽高)。
损失计算与训练逻辑:
- 二分图匹配 :使用匈牙利算法,基于分类分数和框的相似度(L1 + GIoU),将 NNN 个预测与 MMM 个真实标注(GT)进行一对一最优匹配(GT不足的补 ∅\varnothing∅)。
- 损失函数:计算匹配对的分类损失(负对数似然)和框回归损失(L1 + GIoU)。
输出:
- 最终的检测结果集合:包含类别和坐标,过滤掉"无对象"类即为最终检测结果。
3. 有趣的白话版详细解说
想象你在玩"找茬"游戏
老派的做法(Faster R-CNN等):
以前的AI就像一个拿放大镜的强迫症患者。它先把图片画上成千上万个密密麻麻的格子(Anchor),然后在每个格子里猜:"这里有苹果吗?那里有苹果吗?"。因为它猜了太多次,经常会对着同一个苹果喊十次"我找到了!"。这时候就需要一个叫"非极大值抑制(NMS)"的裁判员冲上来,把重复的喊声都删掉,只保留最好的那个。这套流程很复杂,而且那些格子的大小还得人工精心设计,稍微设不好就找不到东西。
DETR的做法(本文主角):
DETR就像是一个拥有上帝视角的指挥官,带着一个由100个特工(Object Queries)组成的团队。
- 看全景(Transformer):DETR不像老派AI那样死盯着局部,它是用Transformer的大脑直接看整张图。它能理解"桌子上放着苹果"这种关系,因为它能同时看到桌子和苹果。
- 特工出动(Queries):DETR直接派出这100个特工。每个特工都会问图片特征:"嘿,有没有归我管的东西?"。
- 各司其职(集合预测):如果图里有3个苹果,那么其中3个特工会分别举手说:"我负责这个苹果"、"我负责那个苹果",剩下的97个特工会说:"我这里没东西(No Object)"。
- 连连看(二分图匹配):训练的时候,为了教这100个特工谁该负责什么,DETR用了一种叫"匈牙利算法"的数学游戏,强行把特工和图里的真实物体一对一连线。谁连得最准就奖励谁,没连对就惩罚。
个人观点与理解:
DETR这篇论文绝对是目标检测领域的一个里程碑。它最酷的地方在于**"把复杂留给机器,把简单留给人"**。它干掉了该死的锚框(Anchor)和NMS,让代码变得极其清爽(推理代码不到50行!)。虽然它训练起来特别慢(像个慢热的天才,需要看很久才能学会),而且对极小的物体(比如远处的一只鸟)眼神儿不太好,但它证明了Transformer这种在像ChatGPT这种语言模型里大杀四方的架构,在看图找东西上也一样无敌。它开启了计算机视觉的一个新时代,也就是现在的"ViT(Vision Transformer)"时代。对于小白来说,你只需要知道:以前的AI是拿放大镜扫,现在的DETR是一眼定乾坤。
4. 论文完整翻译
摘要 :
我们提出了一种新方法,将目标检测视为一个直接的集合预测问题。我们的方法简化了检测流程,有效地消除了许多手工设计的组件,如非极大值抑制(NMS)过程或锚框(Anchor)生成,这些组件显式地编码了我们对任务的先验知识。新框架称为DEtection TRansformer或DETR,其主要成分是一个基于集合的全局损失函数(通过二分图匹配强制进行唯一预测)和一个Transformer编码器-解码器架构。给定一组固定的、较小的学习到的对象查询(object queries),DETR推理对象之间的关系以及全局图像上下文,从而并行地直接输出最终的预测集合。与许多其他现代检测器不同,新模型概念简单,不需要专门的库。在具有挑战性的COCO目标检测数据集上,DETR展示了与完善且高度优化的Faster R-CNN基线相当的准确性和运行时性能。此外,DETR可以很容易地推广,以统一的方式生成全景分割。我们展示了它明显优于竞争基线。训练代码和预训练模型可在 https://github.com/facebookresearch/detr 获取。
1. 引言 (Introduction)
目标检测的目标是为每个感兴趣的对象预测一组边界框和类别标签。现代检测器通过一种间接的方式来解决这个集合预测任务,即在大量的候选框(proposals)37,5、锚框(anchors)23或窗口中心(window centers)53,46上定义代理回归和分类问题。它们的性能受到后处理步骤的显著影响(旨在合并近似重复的预测),也受到锚框集设计以及将目标框分配给锚框的启发式方法的影响52。为了简化这些流程,我们提出了一种直接集合预测方法来绕过代理任务。这种端到端的哲学已经在机器翻译或语音识别等复杂的结构化预测任务中带来了重大进展,但在目标检测中尚未实现:先前的尝试43,16,4,39要么添加了其他形式的先验知识,要么在具有挑战性的基准测试中未被证明与强基线具有竞争力。本文旨在弥合这一差距。

图1:DETR通过结合通过CNN和Transformer架构,直接(并行地)预测最终的检测集。在训练期间,二分图匹配将预测与真实框(ground truth boxes)唯一分配。没有匹配的预测应产生"无对象"(no object, ∅)的类别预测。
我们通过将目标检测视为直接集合预测问题来简化训练流程。我们采用基于Transformer 47的编码器-解码器架构,这是一种流行的序列预测架构。Transformer的自注意力机制显式地模拟序列中元素之间的所有成对交互,使这些架构特别适合集合预测的特定约束,例如移除重复预测。
我们的DEtection TRansformer(DETR,见图1)一次性预测所有对象,并使用执行预测对象与真实对象之间二分图匹配的集合损失函数进行端到端训练。DETR通过丢弃编码先验知识的多个手工设计组件(如空间锚框或非极大值抑制)简化了检测流程。与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在任何包含标准CNN和Transformer类的框架中轻松复现。1
与大多数先前关于直接集合预测的工作相比,DETR的主要特征是二分图匹配损失和具有(非自回归)并行解码的Transformer的结合29,12,10,8。相比之下,先前的工作侧重于使用RNN的自回归解码43,41,30,36,42。我们的匹配损失函数唯一地将预测分配给真实对象,并且对预测对象的排列是不变的,因此我们可以并行地输出它们。
我们在最流行的目标检测数据集之一COCO 24上评估DETR,并与非常有竞争力的Faster R-CNN基线37进行比较。Faster R-CNN经历了许多设计迭代,自最初发表以来其性能有了很大提高。我们的实验表明,我们的新模型达到了可比的性能。更具体地说,DETR在大型对象上展示了显著更好的性能,这一结果可能得益于Transformer的非局部计算。然而,它在小对象上的性能较低。我们期望未来的工作能够像FPN 22对Faster R-CNN的发展那样改善这一方面。
DETR的训练设置在多个方面与标准目标检测器不同。新模型需要超长的训练计划,并且受益于Transformer中的辅助解码损失。我们深入探讨了哪些组件对所展示的性能至关重要。
DETR的设计理念很容易扩展到更复杂的任务。在我们的实验中,我们展示了在预训练的DETR之上训练一个简单的分割头(segmentation head),在全景分割(Panoptic Segmentation)19这一最近获得关注的具有挑战性的像素级识别任务上,表现优于竞争基线。
1 在我们的工作中,我们使用标准深度学习库中的Transformer 47和ResNet 15骨干网的标准实现。
2. 相关工作 (Related work)
我们的工作建立在几个领域的先前工作之上:集合预测的二分图匹配损失、基于Transformer的编码器-解码器架构、并行解码和目标检测方法。
2.1 集合预测 (Set Prediction)
没有一种规范的深度学习模型可以直接预测集合。基本的集合预测任务是多标签分类(例如,参见计算机视觉背景下的40,33),其中基线方法(一对多)不适用于检测等问题,因为检测中元素之间存在底层结构(即几乎相同的框)。这些任务的第一个困难是避免近似重复。大多数当前的检测器使用非极大值抑制(NMS)等后处理来解决这个问题,但直接集合预测是免后处理的。它们需要模拟所有预测元素之间交互的全局推理方案以避免冗余。对于固定大小的集合预测,密集的全连接网络9是足够的,但成本高昂。一种通用的方法是使用自回归序列模型,如循环神经网络48。在所有情况下,损失函数都应该对预测的排列保持不变。通常的解决方案是基于匈牙利算法(Hungarian algorithm)20设计一种损失,以找到真实值和预测之间的二分图匹配。这强制了排列不变性,并保证每个目标元素都有一个唯一的匹配。我们遵循二分图匹配损失的方法。然而,与大多数先前的工作相反,我们远离了自回归模型,并使用具有并行解码的Transformer,如下所述。
2.2 Transformer和并行解码 (Transformers and Parallel Decoding)
Transformer由Vaswani等人47引入,作为机器翻译的新的基于注意力的构建块。注意力机制2是从整个输入序列聚合信息的神经网络层。Transformer引入了自注意力层,类似于非局部神经网络(Non-Local Neural Networks)49,它扫描序列的每个元素并通过聚合来自整个序列的信息来更新它。基于注意力的模型的主要优势之一是它们的全局计算和完美记忆,这使得它们比RNN更适合长序列。Transformer现在正在自然语言处理、语音处理和计算机视觉8,27,45,34,31的许多问题中取代RNN。
Transformer最初用于自回归模型,遵循早期的序列到序列模型44,逐个生成输出标记。然而,高昂的推理成本(与输出长度成正比,且难以批处理)导致了并行序列生成的开发,这在音频29、机器翻译12,10、词表示学习8以及最近的语音识别6领域中都有出现。我们也结合了Transformer和并行解码,以在计算成本和执行集合预测所需的全局计算能力之间取得适当的平衡。
2.3 目标检测 (Object detection)
大多数现代目标检测方法都相对于一些初始猜测进行预测。两阶段检测器37,5相对于候选框(proposals)预测框,而单阶段方法相对于锚框(anchors)23或可能的对象中心网格53,46进行预测。最近的工作52表明,这些系统的最终性能在很大程度上取决于这些初始猜测的设置方式。在我们的模型中,我们能够移除这个手工过程,并通过直接预测相对于输入图像的绝对框预测集(而不是相对于锚框)来简化检测过程。
基于集合的损失 (Set-based loss) 。一些目标检测器9,25,35使用了二分图匹配损失。然而,在这些早期的深度学习模型中,不同预测之间的关系仅通过卷积或全连接层建模,手工设计的NMS后处理可以提高其性能。最近的检测器37,23,53使用真实值和预测之间的非唯一分配规则以及NMS。
可学习的NMS方法16,4和关系网络(relation networks)17通过注意力显式地模拟不同预测之间的关系。使用直接集合损失,它们不需要任何后处理步骤。然而,这些方法采用额外的手工上下文特征,如候选框坐标,以有效地模拟检测之间的关系,而我们要寻找减少模型中编码的先验知识的解决方案。
循环检测器 (Recurrent detectors)。与我们的方法最接近的是用于目标检测43和实例分割41,30,36,42的端到端集合预测。与我们类似,它们使用基于CNN激活的编码器-解码器架构和二分图匹配损失来直接生成一组边界框。然而,这些方法仅在小型数据集上进行了评估,并未与现代基线进行对抗。特别是,它们基于自回归模型(更确切地说是RNN),因此没有利用具有并行解码的最新Transformer。
3. DETR模型 (The DETR model)
对于检测中的直接集合预测,两个要素至关重要:(1) 一个强制预测框和真实框之间唯一匹配的集合预测损失;(2) 一个能够(单次传递)预测一组对象并模拟它们关系的架构。我们在图2中详细描述了我们的架构。
3.1 目标检测集合预测损失 (Object detection set prediction loss)
DETR在单次通过解码器时推断出固定大小的 NNN 个预测集合,其中 NNN 被设置为显著大于图像中典型的对象数量。训练的主要困难之一是根据真实值对预测对象(类别、位置、大小)进行评分。我们的损失在预测对象和真实对象之间产生最佳二分图匹配,然后优化特定于对象(边界框)的损失。
让我们用 yyy 表示真实对象集,y^={y^i}i=1N\hat{y} = \{\hat{y}i\}{i=1}^Ny^={y^i}i=1N 表示 NNN 个预测的集合。假设 NNN 大于图像中的对象数量,我们也认为 yyy 是一个大小为 NNN 的集合,用 ∅\varnothing∅(无对象)填充。为了在这两个集合之间找到二分图匹配,我们在 NNN 个元素的排列 σ∈SN\sigma \in \mathfrak{S}_Nσ∈SN 中搜索具有最低成本的排列:
σ^=argminσ∈SN∑iNLmatch(yi,y^σ(i)),(1) \hat{\sigma} = \underset{\sigma \in \mathfrak{S}N}{\arg \min} \sum{i}^N \mathcal{L}{\text{match}}(y_i, \hat{y}{\sigma(i)}), \quad (1) σ^=σ∈SNargmini∑NLmatch(yi,y^σ(i)),(1)
其中 Lmatch(yi,y^σ(i))\mathcal{L}{\text{match}}(y_i, \hat{y}{\sigma(i)})Lmatch(yi,y^σ(i)) 是真实值 yiy_iyi 和索引为 σ(i)\sigma(i)σ(i) 的预测之间的成对匹配成本。这个最佳分配是通过匈牙利算法高效计算的,遵循先前的工作(例如 43)。
匹配成本同时考虑了类别预测和预测框与真实框的相似性。真实集的每个元素 iii 可以看作 yi=(ci,bi)y_i = (c_i, b_i)yi=(ci,bi),其中 cic_ici 是目标类别标签(可能是 ∅\varnothing∅),bi∈0,14b_i \in 0, 1^4bi∈0,14 是定义真实框中心坐标及其相对于图像大小的高度和宽度的向量。对于索引为 σ(i)\sigma(i)σ(i) 的预测,我们将类别 cic_ici 的概率定义为 p^σ(i)(ci)\hat{p}{\sigma(i)}(c_i)p^σ(i)(ci),预测框定义为 b^σ(i)\hat{b}{\sigma(i)}b^σ(i)。使用这些符号,我们将 Lmatch(yi,y^σ(i))\mathcal{L}{\text{match}}(y_i, \hat{y}{\sigma(i)})Lmatch(yi,y^σ(i)) 定义为 −1{ci≠∅}p^σ(i)(ci)+1{ci≠∅}Lbox(bi,b^σ(i))-\mathbb{1}{\{c_i \neq \varnothing\}} \hat{p}{\sigma(i)}(c_i) + \mathbb{1}{\{c_i \neq \varnothing\}} \mathcal{L}{\text{box}}(b_i, \hat{b}_{\sigma(i)})−1{ci=∅}p^σ(i)(ci)+1{ci=∅}Lbox(bi,b^σ(i))。
这种寻找匹配的过程起到了与现代检测器中用于将候选框37或锚框22匹配到真实对象的启发式分配规则相同的作用。主要区别在于,我们需要为没有重复的直接集合预测找到一对一匹配。
第二步是计算损失函数,即上一步中匹配的所有配对的匈牙利损失(Hungarian loss)。我们定义的损失类似于常见目标检测器的损失,即类别预测的负对数似然和稍后定义的框损失的线性组合:
LHungarian(y,y^)=∑i=1N−logp\^σ\^(i)(ci)+1{ci≠∅}Lbox(bi,b\^σ\^(i)),(2) \mathcal{L}{\text{Hungarian}}(y, \hat{y}) = \sum{i=1}^{N} \left -\\log \\hat{p}_{\\hat{\\sigma}(i)}(c_i) + \\mathbb{1}_{\\{c_i \\neq \\varnothing\\}} \\mathcal{L}_{\\text{box}}(b_i, \\hat{b}_{\\hat{\\sigma}(i)}) \\right, \quad (2) LHungarian(y,y^)=i=1∑N−logp\^σ\^(i)(ci)+1{ci=∅}Lbox(bi,b\^σ\^(i)),(2)
其中 σ^\hat{\sigma}σ^ 是在第一步(1)中计算的最佳分配。在实践中,当 ci=∅c_i = \varnothingci=∅ 时,我们将对数概率项的权重降低10倍,以解决类别不平衡问题。这类似于Faster R-CNN训练过程通过子采样37平衡正/负候选框。注意,对象和 ∅\varnothing∅ 之间的匹配成本不依赖于预测,这意味着在这种情况下成本是常数。在匹配成本中,我们使用概率 p^σ^(i)(ci)\hat{p}{\hat{\sigma}(i)}(c_i)p^σ^(i)(ci) 而不是对数概率。这使得类别预测项与 Lbox(⋅,⋅)\mathcal{L}{\text{box}}(\cdot, \cdot)Lbox(⋅,⋅)(下文描述)可公度,我们观察到了更好的实证性能。
边界框损失 (Bounding box loss) 。匹配成本和匈牙利损失的第二部分是 Lbox(⋅)\mathcal{L}{\text{box}}(\cdot)Lbox(⋅),它对边界框进行评分。与许多将框预测作为相对于某些初始猜测的 Δ\DeltaΔ 的检测器不同,我们直接进行框预测。虽然这种方法简化了实现,但它带来了损失相对缩放的问题。最常用的 ℓ1\ell_1ℓ1 损失即使由于相对误差相似,对于小框和大框也会有不同的尺度。为了缓解这个问题,我们使用 ℓ1\ell_1ℓ1 损失和广义IoU损失(Generalized IoU loss)38 Liou(⋅,⋅)\mathcal{L}{\text{iou}}(\cdot, \cdot)Liou(⋅,⋅) 的线性组合,后者是尺度不变的。总的来说,我们的框损失 Lbox(bi,b^σ(i))\mathcal{L}{\text{box}}(b_i, \hat{b}{\sigma(i)})Lbox(bi,b^σ(i)) 定义为 λiouLiou(bi,b^σ(i))+λL1∥bi−b^σ(i)∥1\lambda_{\text{iou}} \mathcal{L}{\text{iou}}(b_i, \hat{b}{\sigma(i)}) + \lambda_{L1} \|b_i - \hat{b}{\sigma(i)}\|1λiouLiou(bi,b^σ(i))+λL1∥bi−b^σ(i)∥1,其中 λiou,λL1∈R\lambda{\text{iou}}, \lambda{L1} \in \mathbb{R}λiou,λL1∈R 是超参数。这两个损失按批次内的对象数量进行归一化。
3.2 DETR架构 (DETR architecture)
整个DETR架构非常简单,如图2所示。它包含三个主要组件,我们将在下面描述:用于提取紧凑特征表示的CNN骨干网、编码器-解码器Transformer和用于进行最终检测预测的简单前馈网络(FFN)。
与许多现代检测器不同,DETR可以在任何提供通用CNN骨干网和Transformer架构实现的深度学习框架中实现,只需几百行代码。DETR的推理代码可以在PyTorch 32中用不到50行代码实现。我们希望我们方法的简单性能吸引新的研究人员加入检测社区。
骨干网 (Backbone) 。从初始图像 ximg∈R3×H0×W0x_{\text{img}} \in \mathbb{R}^{3 \times H_0 \times W_0}ximg∈R3×H0×W0(具有3个颜色通道2)开始,传统的CNN骨干网生成较低分辨率的激活图 f∈RC×H×Wf \in \mathbb{R}^{C \times H \times W}f∈RC×H×W。我们使用的典型值为 C=2048C=2048C=2048,以及 H,W=H032,W032H, W = \frac{H_0}{32}, \frac{W_0}{32}H,W=32H0,32W0。
Transformer编码器 (Transformer encoder) 。首先,一个1x1卷积将高层激活图 fff 的通道维度从 CCC 减少到较小的维度 ddd,创建一个新的特征图 z0∈Rd×H×Wz_0 \in \mathbb{R}^{d \times H \times W}z0∈Rd×H×W。编码器期望一个序列作为输入,因此我们将 z0z_0z0 的空间维度折叠成一维,导致 d×HWd \times HWd×HW 的特征图。每个编码器层都具有标准架构,由多头自注意力模块和前馈网络(FFN)组成。由于Transformer架构是排列不变的,我们用固定的位置编码31,3补充它,这些编码被添加到每个注意力层的输入中。我们将架构的详细定义推迟到补充材料中,该定义遵循47中描述的内容。
2 输入图像被批处理在一起,充分应用0填充以确保它们都具有与批次中最大图像相同的尺寸 (H0,W0)(H_0, W_0)(H0,W0)。
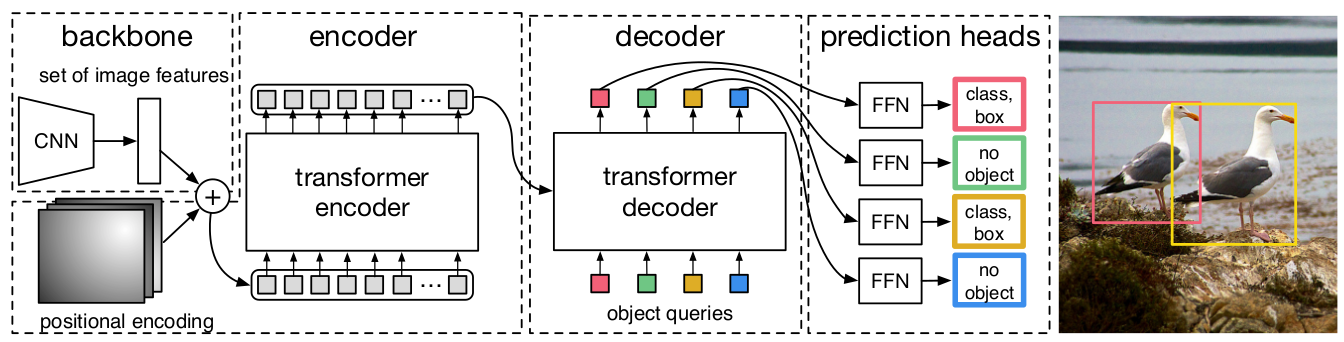
图2:DETR使用传统的CNN骨干网来学习输入图像的2D表示。模型将其展平并在将其传入Transformer编码器之前用位置编码进行补充。然后,Transformer解码器将少量固定数量的学习到的位置嵌入(我们称为对象查询,object queries)作为输入,并另外关注编码器输出。我们将解码器的每个输出嵌入传递给共享的前馈网络(FFN),该网络预测检测结果(类别和边界框)或"无对象"类。
Transformer解码器 (Transformer decoder) 。解码器遵循Transformer的标准架构,使用多头自注意力和编码器-解码器注意力机制转换大小为 ddd 的 NNN 个嵌入。与原始Transformer的区别在于,我们的模型在每个解码器层并行解码 NNN 个对象,而Vaswani等人47使用自回归模型,一次预测输出序列的一个元素。我们建议不熟悉这些概念的读者参考补充材料。由于解码器也是排列不变的,因此 NNN 个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是我们称为*对象查询(object queries)*的学习到的位置编码,与编码器类似,我们将它们添加到每个注意力层的输入中。NNN 个对象查询由解码器转换为输出嵌入。然后,它们通过前馈网络(在下一小节中描述)独立解码为框坐标和类别标签,从而产生 NNN 个最终预测。使用对这些嵌入的自注意力和编码器-解码器注意力,模型利用它们之间的成对关系全局地推理所有对象,同时能够使用整个图像作为上下文。
预测前馈网络 (Prediction feed-forward networks, FFNs) 。最终预测由具有ReLU激活函数和隐藏维度 ddd 的3层感知机以及线性投影层计算。FFN预测相对于输入图像的标准化中心坐标、框的高度和宽度,线性层使用softmax函数预测类别标签。由于我们预测固定大小的 NNN 个边界框集合,其中 NNN 通常远大于图像中实际感兴趣对象的数量,因此使用额外的特殊类标签 ∅\varnothing∅ 来表示槽内未检测到对象。这个类别在标准目标检测方法中扮演类似于"背景"类别的角色。
辅助解码损失 (Auxiliary decoding losses)。我们发现在训练期间在解码器中使用辅助损失1很有帮助,特别是有助于模型输出每个类别的正确对象数量。我们在每个解码器层之后添加预测FFN和匈牙利损失。所有预测FFN共享其参数。我们使用额外的共享层归一化(layer-norm)来归一化来自不同解码器层的预测FFN的输入。
4. 实验 (Experiments)
我们表明,在COCO的定量评估中,DETR取得了与Faster R-CNN相当的结果。然后,我们提供了架构和损失的详细消融研究,并附有见解和定性结果。最后,为了证明DETR是一个通用且可扩展的模型,我们展示了全景分割的结果,仅在固定的DETR模型上训练了一个小的扩展。我们提供代码和预训练模型以复现我们的实验,网址为 https://github.com/facebookresearch/detr。
数据集 (Dataset)。我们在COCO 2017检测和全景分割数据集24,18上进行实验,包含118k张训练图像和5k张验证图像。每张图像都标注了边界框和全景分割。训练集中每张图像平均有7个实例,单张图像最多63个实例,涵盖从小到大的各种尺寸。如果未指定,我们报告bbox AP作为AP,即多个阈值上的积分度量。为了与Faster R-CNN进行比较,我们报告最后一个训练周期的验证AP,对于消融研究,我们报告最后10个周期的中位数验证结果。
技术细节 (Technical details) 。我们使用AdamW 26训练DETR,将Transformer的初始学习率设置为 10−410^{-4}10−4,骨干网的设置为 10−510^{-5}10−5,权重衰减为 10−410^{-4}10−4。所有Transformer权重使用Xavier init 11初始化,骨干网使用来自TORCHVISION的ImageNet预训练ResNet模型15,并冻结BatchNorm层。我们报告了两种不同骨干网的结果:ResNet-50和ResNet-101。相应的模型分别称为DETR和DETR-R101。遵循21,我们还通过向骨干网的最后阶段添加扩张(dilation)并移除该阶段第一次卷积的步幅来增加特征分辨率。相应的模型分别称为DETR-DC5和DETR-DC5-R101(扩张C5阶段)。这种修改将分辨率提高了两倍,从而提高了小目标的性能,代价是编码器自注意力的成本高出16倍,导致整体计算成本增加2倍。表1给出了这些模型与Faster R-CNN的FLOPs的完整比较。
我们使用尺度增强,调整输入图像的大小,使得最短边至少为480,最多为800像素,而最长边最多为1333 50。为了帮助通过编码器的自注意力学习全局关系,我们还在训练期间应用随机裁剪增强,将性能提高了约1 AP。具体来说,训练图像以0.5的概率被裁剪为随机矩形块,然后再调整大小为800-1333。Transformer使用默认的0.1 dropout进行训练。在推理时,一些槽预测为空类别。为了优化AP,我们用第二高得分的类别覆盖这些槽的预测,使用相应的置信度。与过滤掉空槽相比,这提高了2个AP点。其他训练超参数可以在A.4节中找到。对于我们的消融实验,我们使用300个周期的训练计划,在200个周期后学习率下降10倍,其中一个周期是一次遍历所有训练图像。在16个V100 GPU上训练基线模型300个周期需要3天,每个GPU 4张图像(因此总批量大小为64)。对于用于与Faster R-CNN比较的更长计划,我们训练500个周期,在400个周期后学习率下降。与较短的计划相比,该计划增加了1.5 AP。
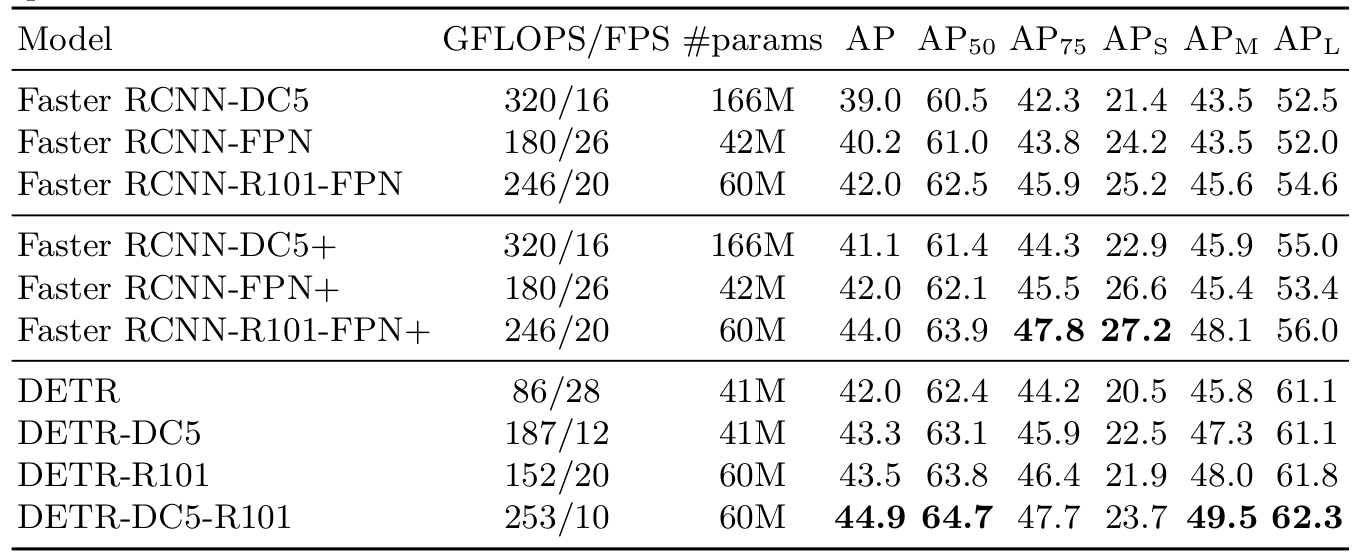
表1 :在COCO验证集上与使用ResNet-50和ResNet-101骨干网的Faster R-CNN的比较。顶部部分显示了Detectron2 50中Faster R-CNN模型的结果,中间部分显示了使用GIoU 38、随机裁剪训练时间增强和长9x训练计划的Faster R-CNN模型的结果。DETR模型取得了与经过大量调优的Faster R-CNN基线相当的结果,具有较低的 APSAP_SAPS 但大大提高了 APLAP_LAPL。我们使用torchscript Faster R-CNN和DETR模型来测量FLOPS和FPS。名称中不含R101的结果对应于ResNet-50。
4.1 与Faster R-CNN的比较 (Comparison with Faster R-CNN)
Transformer通常使用Adam或Adagrad优化器进行训练,具有非常长的训练计划和dropout,这对DETR也是如此。然而,Faster R-CNN是用SGD训练的,数据增强最少,我们不知道Adam或dropout的成功应用。尽管存在这些差异,我们试图使Faster R-CNN基线更强。为了使其与DETR对齐,我们将广义IoU 38添加到框损失中,同样的随机裁剪增强和已知能提高结果的长时间训练13。结果如表1所示。在顶部部分,我们显示了来自Detectron2 Model Zoo 50的使用3x计划训练的Faster R-CNN结果。在中间部分,我们显示了结果(带有"+"),对于相同的模型但使用9x计划(109个周期)和描述的增强进行训练,总共增加了1-2 AP。在表1的最后部分,我们展示了多个DETR模型的结果。为了在参数数量上具有可比性,我们选择了一个具有6个Transformer和6个解码器层、宽度为256且有8个注意力头的模型。像带有FPN的Faster R-CNN一样,该模型有41.3M参数,其中23.5M在ResNet-50中,17.8M在Transformer中。尽管Faster R-CNN和DETR都有可能通过更长的训练进一步改进,但我们可以得出结论,DETR可以与具有相同参数数量的Faster R-CNN竞争,在COCO val子集上达到42 AP。DETR实现这一点的方式是提高 APLAP_LAPL (+7.8),但请注意模型在 APSAP_SAPS 上仍然落后 (-5.5)。具有相同参数数量和相似FLOP计数的DETR-DC5具有更高的AP,但在 APSAP_SAPS 上仍然显著落后。Faster R-CNN和带有ResNet-101骨干网的DETR也显示了可比的结果。
4.2 消融研究 (Ablations)
Transformer解码器中的注意力机制是模拟不同检测特征表示之间关系的关键组件。在我们的消融分析中,我们探讨了架构和损失的其他组件如何影响最终性能。对于这项研究,我们选择基于ResNet-50的DETR模型,具有6个编码器、6个解码器层和宽度256。该模型有41.3M参数,在短和长计划上分别达到40.6和42.0 AP,运行速度为28 FPS,与具有相同骨干网的Faster R-CNN-FPN类似。

表2:编码器大小的影响。每一行对应一个具有不同数量编码器层和固定数量解码器层的模型。随着编码器层数的增加,性能逐渐提高。
编码器层数 (Number of encoder layers)。我们通过改变编码器层的数量来评估全局图像级自注意力的重要性(表2)。如果没有编码器层,总体AP下降3.9个点,大目标上的下降更为显著,为6.0 AP。我们假设,通过使用全局场景推理,编码器对于解耦对象很重要。在图3中,我们可视化了训练模型的最后一个编码器层的注意力图,聚焦于图像中的几个点。编码器似乎已经分离了实例,这可能简化了解码器的对象提取和定位。

图3:一组参考点的编码器自注意力。编码器能够分离单个实例。预测是使用基线DETR模型在验证集图像上进行的。
解码器层数 (Number of decoder layers)。我们在每个解码层之后应用辅助损失(见3.2节),因此,预测FFN被设计为从每个解码器层的输出中预测对象。我们通过评估每个解码阶段将预测的对象来分析每个解码器层的重要性(图4)。AP和AP50在每一层之后都有所提高,导致第一层和最后一层之间有非常显著的+8.2/9.5 AP改进。由于其基于集合的损失,DETR不需要NMS。为了验证这一点,我们对每个解码器后的输出运行具有默认参数50的标准NMS程序。NMS提高了第一个解码器预测的性能。这可以通过以下事实来解释:Transformer的单个解码层无法计算输出元素之间的任何互相关,因此它倾向于为同一对象进行多个预测。在第二层及随后的层中,激活上的自注意力机制允许模型抑制重复预测。我们观察到,随着深度的增加,NMS带来的改善逐渐减弱。在最后一层,我们观察到AP略有损失,因为NMS错误地移除了真阳性预测。
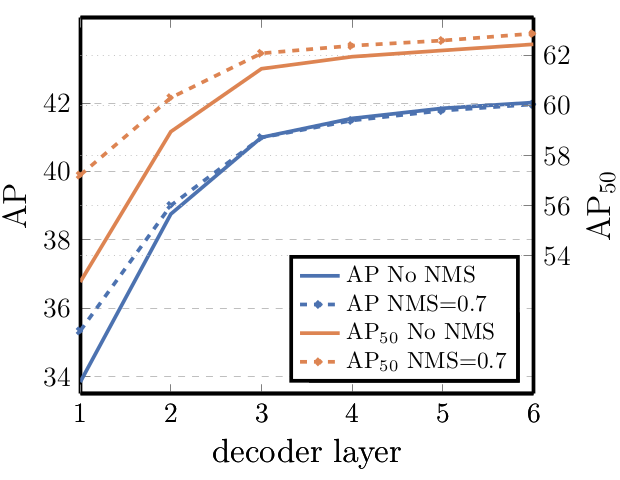
图4:每个解码器层之后的AP和AP50性能。评估了单个长计划基线模型。DETR通过设计不需要NMS,这一点由此图验证。NMS降低了最后几层的AP,移除了TP预测,但提高了前几个解码器层的AP,移除了重复预测,因为第一层没有通信,并且稍微提高了AP50。
与可视化编码器注意力类似,我们在图6中可视化了解码器注意力,为每个预测对象用不同颜色着色注意力图。我们观察到解码器注意力相当局部,这意味着它主要关注对象的末端,如头部或腿部。我们假设在编码器通过全局注意力分离实例之后,解码器只需要关注末端以提取类别和对象边界。
FFN的重要性 (Importance of FFN)。Transformer内部的FFN可以被视为1x1卷积层,使得编码器类似于注意力增强卷积网络3。我们尝试完全移除它,只在Transformer层中保留注意力。通过将网络参数数量从41.3M减少到28.7M,仅在Transformer中保留10.8M,性能下降了2.3 AP,我们因此得出结论,FFN对于取得良好结果很重要。
位置编码的重要性 (Importance of positional encodings)。我们的模型中有两种位置编码:空间位置编码和输出位置编码(对象查询)。我们尝试了固定和学习编码的各种组合,结果见表3。输出位置编码是必需的,不能移除,所以我们尝试要么在解码器输入处传递一次,要么在每个解码器注意力层添加到查询中。在第一个实验中,我们完全移除空间位置编码并在输入处传递输出位置编码,有趣的是,模型仍然达到了超过32 AP,与基线相比损失了7.8 AP。然后,我们像原始Transformer 47那样,一次性传递固定的正弦空间位置编码和输出编码在输入处,发现这导致比直接在注意力中传递位置编码下降1.4 AP。传递给注意力的学习空间编码给出了类似的结果。令人惊讶的是,我们发现不在编码器中传递任何空间编码只会导致1.3 AP的微小下降。当我们将编码传递给注意力时,它们在所有层之间共享,并且输出编码(对象查询)总是被学习的。
鉴于这些消融,我们得出结论,Transformer组件:编码器中的全局自注意力、FFN、多个解码器层和位置编码,都对最终的目标检测性能有显著贡献。

图5:稀有类别的分布外泛化。即使训练集中没有图像包含超过13只长颈鹿,DETR在泛化到24只及更多同类实例时也没有困难。

表3:不同位置编码与基线(最后一行)的结果比较,基线在编码器和解码器的每个注意力层传递固定的正弦位置编码。学习的嵌入在所有层之间共享。不使用空间位置编码会导致AP显著下降。有趣的是,仅在解码器中传递它们只会导致轻微的AP下降。所有这些模型都使用学习到的输出位置编码。
损失消融 (Loss ablations) 。为了评估匹配成本和损失的不同组件的重要性,我们训练了几个打开和关闭它们的模型。损失有三个组件:分类损失、ℓ1\ell_1ℓ1 边界框距离损失和GIoU 38损失。分类损失对于训练是必不可少的,不能关闭,所以我们训练了一个没有边界框距离损失的模型,和一个没有GIoU损失的模型,并与使用所有三种损失训练的基线进行比较。结果如表4所示。单独的GIoU损失占了大部分模型性能,与组合损失的基线相比仅损失0.7 AP。不带GIoU使用 ℓ1\ell_1ℓ1 显示结果较差。我们只研究了不同损失的简单消融(每次使用相同的权重),但其他组合方式可能会取得不同的结果。

图6:可视化每个预测对象的解码器注意力(来自COCO val集的图像)。预测是使用DETR-DC5模型进行的。注意力分数针对不同对象用不同颜色编码。解码器通常关注对象的末端,如腿和头。彩色观看效果最佳。

表4 :损失组件对AP的影响。我们训练了两个模型,分别关闭 ℓ1\ell_1ℓ1 损失和GIoU损失,观察到 ℓ1\ell_1ℓ1 单独使用效果不佳,但与GIoU结合时提高了 APMAP_MAPM 和 APLAP_LAPL。我们的基线(最后一行)结合了两种损失。
4.3 分析 (Analysis)
解码器输出槽分析 (Decoder output slot analysis)。在图7中,我们可视化了DETR解码器中不同槽为COCO 2017 val集中所有图像预测的框。DETR为每个查询槽学习了不同的专业化。我们观察到每个槽都有几种操作模式,专注于不同的区域和框大小。特别是,所有槽都有预测图像宽框的模式(在图中可见为中间对齐的红点)。我们假设这与COCO中对象的分布有关。

图7 :DETR解码器中总共 N=100N=100N=100 个预测槽中的20个在COCO 2017 val集所有图像上的所有框预测的可视化。每个框预测表示为一个点,其中心坐标在通过每张图像大小归一化的1x1正方形中。这些点是颜色编码的,使得绿色对应于小框,红色对应于大的水平框,蓝色对应于大的垂直框。我们观察到每个槽学习专注于某些区域和框大小,具有几种操作模式。我们注意到几乎所有槽都有预测大型图像宽框的模式,这在COCO数据集中很常见。
对未见过实例数量的泛化 (Generalization to unseen numbers of instances)。COCO中的某些类别在同一图像中没有很多同类实例。例如,训练集中没有长颈鹿超过13只的图像。我们创建了一个合成图像3来验证DETR的泛化能力(见图5)。我们的模型能够找到图像上的所有24只长颈鹿,这显然是分布外的。这个实验证实了在每个对象查询中没有很强的类别专业化。
3 基础图片来源: https://www.piqsels.com/en/public-domain-photo-jzlwu
4.4 用于全景分割的DETR (DETR for panoptic segmentation)
全景分割19最近引起了计算机视觉社区的大量关注。类似于Faster R-CNN 37扩展到Mask R-CNN 14,DETR可以通过在解码器输出之上添加掩码头(mask head)来自然扩展。在本节中,我们展示了这样的头可以通过以统一的方式处理stuff和thing类别来用于产生全景分割19。我们在COCO数据集的全景标注上进行实验,该数据集除了80个thing类别外,还有53个stuff类别。
我们训练DETR预测COCO上stuff和things类别的框,使用相同的配方。预测框是训练所必需的,因为匈牙利匹配是使用框之间的距离计算的。我们还添加了一个掩码头,为每个预测框预测一个二进制掩码,见图8。它将每个对象的Transformer解码器输出作为输入,并在编码器的输出上计算多头(M个头)注意力分数,为每个对象生成M个小分辨率的注意力热图。为了进行最终预测并提高分辨率,使用了类FPN架构。我们在补充材料中更详细地描述了架构。掩码的最终分辨率是步幅4,每个掩码使用DICE/F-1损失28和Focal loss 23独立监督。
掩码头可以联合训练,或者分两步过程,即我们只训练DETR的框,然后冻结所有权重并仅训练掩码头25个周期。实验上,这两种方法给出了类似的结果,我们报告使用后一种方法的结果,因为它导致总挂钟时间训练更短。
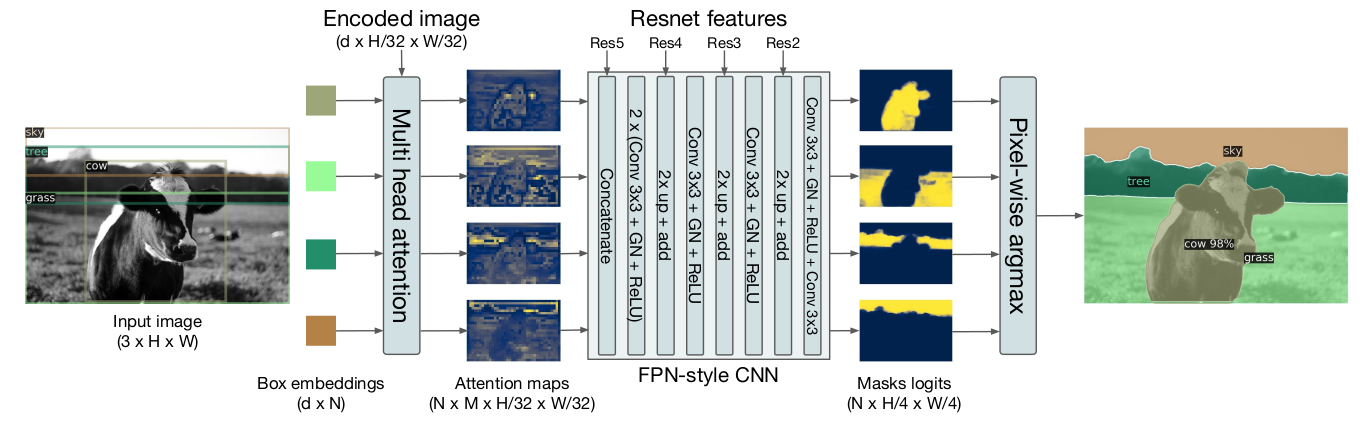
图8:全景头的插图。为每个检测到的对象并行生成二进制掩码,然后使用像素级argmax合并掩码。
为了预测最终的全景分割,我们只需对每个像素的掩码分数使用argmax,并将相应的类别分配给生成的掩码。此过程保证最终掩码没有重叠,因此,DETR不需要通常用于对齐不同掩码的启发式方法19。
图9:由DETR-R101生成的全景分割的定性结果。DETR以统一的方式为things和stuff生成对齐的掩码预测。
训练细节 (Training details)。我们按照边界框检测的配方训练DETR、DETR-DC5和DETR-R101模型,以预测COCO数据集中stuff和things类别的框。新的掩码头训练25个周期(详见补充材料)。在推理期间,我们首先过滤掉置信度低于85%的检测,然后计算每像素argmax以确定每个像素属于哪个掩码。然后我们将同一stuff类别的不同掩码预测合并为一个,并过滤空的(小于4个像素)。
主要结果 (Main results) 。定性结果如图9所示。在表5中,我们将我们的统一全景分割方法与几种对待things和stuff不同的成熟方法进行了比较。我们报告全景质量(PQ)以及things(PQthPQ^{th}PQth)和stuff(PQstPQ^{st}PQst)的细分。我们还报告了掩码AP(在things类别上计算),在任何全景后处理之前(在我们的例子中,在进行像素级argmax之前)。我们表明,DETR优于COCO-val 2017上的已发布结果,以及我们强大的PanopticFPN基线(使用与DETR相同的数据增强进行训练,以便公平比较)。结果细分显示,DETR在stuff类别上特别占优势,我们假设编码器注意力允许的全局推理是这一结果的关键因素。对于things类别,尽管在掩码AP计算上与基线相比有高达8 mAP的严重赤字,但DETR获得了有竞争力的 PQthPQ^{th}PQth。我们还在COCO数据集的测试集上评估了我们的方法,并获得了46 PQ。我们希望我们的方法能激发未来对全景分割完全统一模型的探索。

表5:与最先进方法UPSNet 51和Panoptic FPN 18在COCO val数据集上的比较。我们使用与DETR相同的数据增强重训练了PanopticFPN,并在18x计划上进行以公平比较。UPSNet使用1x计划,UPSNet-M是具有多尺度测试时间增强的版本。
5. 结论 (Conclusion)
我们介绍了DETR,一种基于Transformer和二分图匹配损失的直接集合预测的目标检测系统新设计。该方法在具有挑战性的COCO数据集上取得了与优化的Faster R-CNN基线相当的结果。DETR易于实现,具有灵活的架构,易于扩展到全景分割,并具有竞争力的结果。此外,它在大目标上取得了比Faster R-CNN显著更好的性能,这可能归功于自注意力执行的全局信息处理。
这种新的检测器设计也带来了新的挑战,特别是在关于小目标的训练、优化和性能方面。目前的检测器需要数年的改进来应对类似的问题,我们期待未来的工作能成功解决DETR的这些问题。