我们准备在本地的idea的maven项目中测试连接上虚拟机上的大数据集群(hadoop、hive、spark)
一、本地host文件增加master主机的映射
hosts文件路径 在Windows系统中
hosts文件的默认路径为: C:\Windows\System32\drivers\etc\hosts
修改hosts文件的步骤
打开路径C:\Windows\System32\drivers\etc ,找到hosts文件。
右键文件,选择"属性",在"安全"选项卡中修改权限为可编辑。
将hosts文件复制到桌面,用记事本或其他文本编辑器打开并修改内容。
保存修改后的文件,并将其替换回原路径。
二、本地浏览器查看web页面
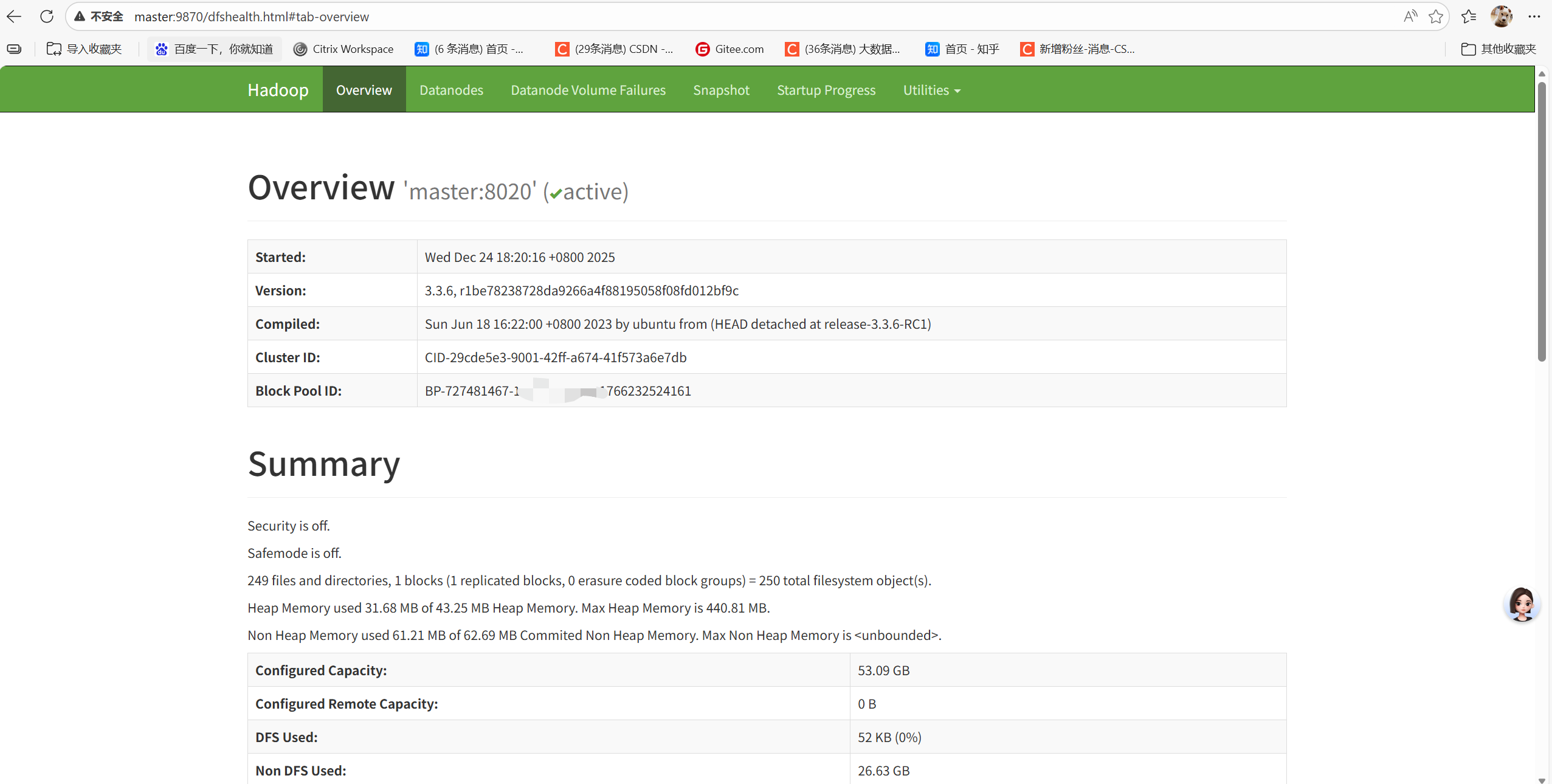
hadoop:
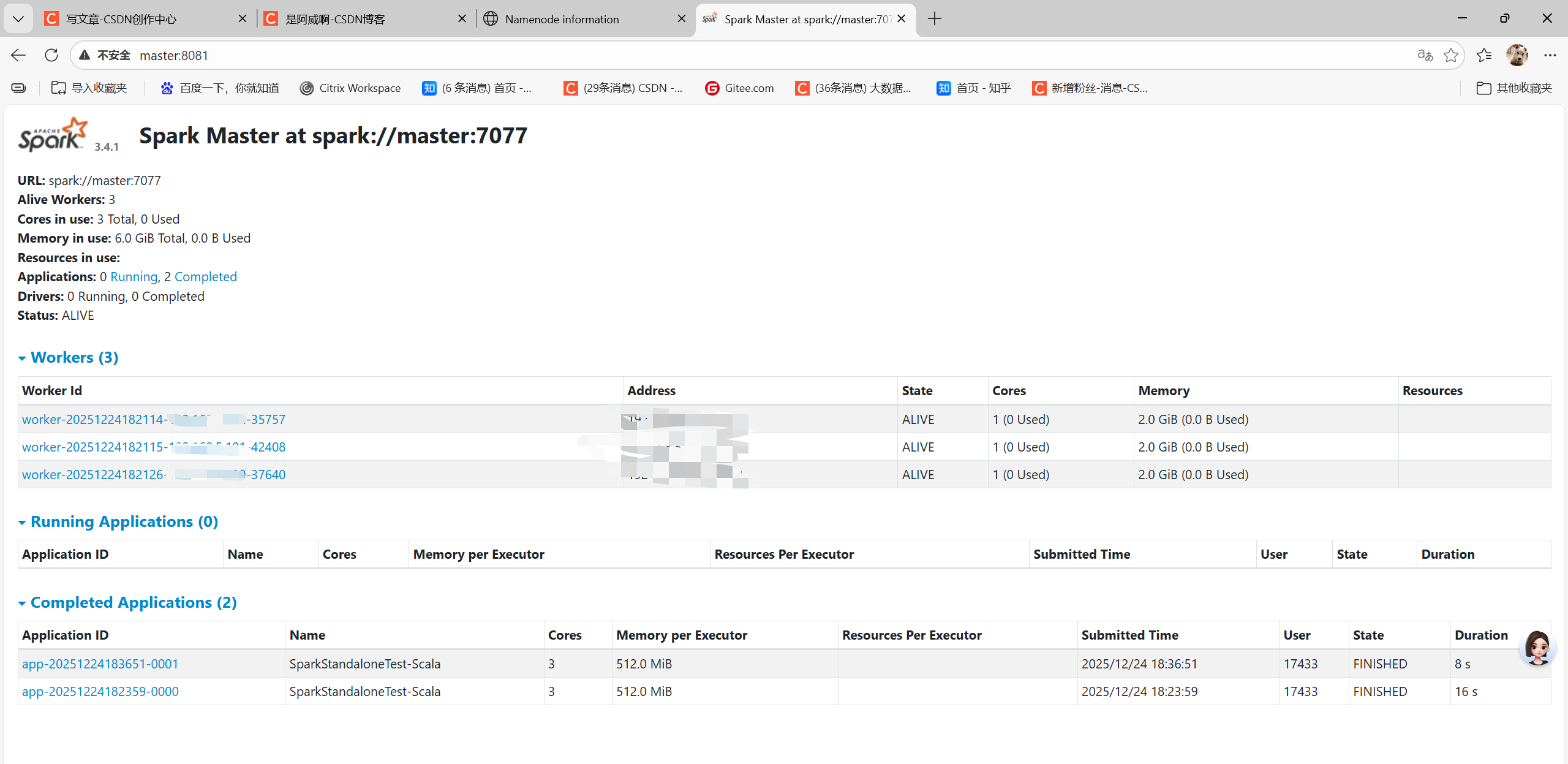
spark:
如果确认服务已启动但是看不到页面,可以尝试开放端口
永久开放(需重载生效) sudo firewall-cmd --permanent --add-port=7077/tcp --zone=public
重载配置(使永久规则生效) sudo firewall-cmd --reload
二、设置maven项目的pom文件
注意maven项目要根据自己的hadoop、yarn、spark、hive版本引入相关依赖
XML
<!-- 统一版本管理 -->
<properties>
<!-- 基础环境 -->
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!-- 核心依赖版本 -->
<scala.version>2.12.17</scala.version>
<scala.compat.version>2.12</scala.compat.version>
<spark.version>3.4.1</spark.version>
<hadoop.version>3.3.6</hadoop.version>
<hive.version>3.1.2</hive.version>
<!-- 其他依赖版本 -->
<kafka.version>3.4.0</kafka.version> <!-- 与Spark 3.4.1兼容 -->
<mysql-connector.version>8.0.33</mysql-connector.version>
<log4j2.version>2.20.0</log4j2.version>
<slf4j.version>1.7.36</slf4j.version>
<commons-lang3.version>3.12.0</commons-lang3.version>
<!-- 插件版本 -->
<maven-compiler-plugin.version>3.10.1</maven-compiler-plugin.version>
<scala-maven-plugin.version>4.8.1</scala-maven-plugin.version>
<maven-shade-plugin.version>3.4.1</maven-shade-plugin.version>
</properties>
<!-- 依赖管理(子模块可直接引用,无需指定版本) -->
<dependencyManagement>
<dependencies>
<!-- Scala核心 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark核心 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
<!-- 集群环境需排除内置Hadoop,本地测试可保留 -->
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Spark SQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Kafka整合 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Hive整合 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop核心 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Hive JDBC -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector.version}</version>
</dependency>
<!-- 日志框架 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j2.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j2.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.compat.version}</artifactId>
<version>3.2.15</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-testing-base_${scala.compat.version}</artifactId>
<version>3.4.1_1.4.0</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>三、编写测试代码
1、hadoop
Scala
package com.dw
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import java.net.URI
object HdfsTest {
def main(args: Array[String]): Unit = {
// 配置HDFS地址和虚拟机用户名
val hdfsUri = "hdfs://master:8020" // 替换为虚拟机IP
val userName = "hadoop" // 替换为虚拟机的Hadoop用户名(如hadoop)
// 创建配置对象
val conf = new Configuration()
val fs = FileSystem.get(new URI(hdfsUri), conf, userName)
// 测试创建目录
val testDir = new Path("/test_scala")
if (fs.exists(testDir)) {
fs.delete(testDir, true) // 递归删除
}
val isCreated = fs.mkdirs(testDir)
println(s"HDFS目录创建是否成功:$isCreated")
// 关闭FileSystem
fs.close()
}
}测试结果:

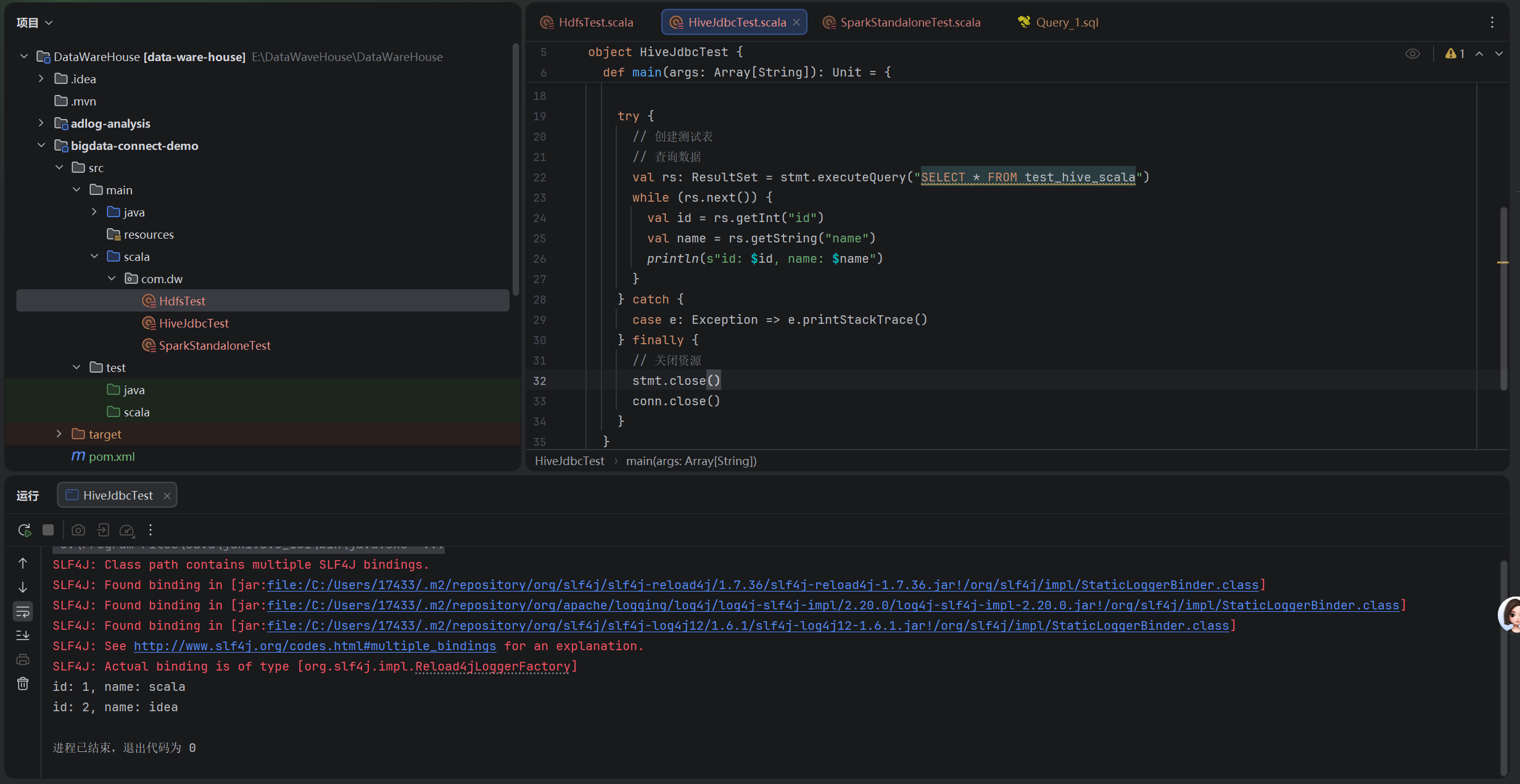
2、hive
Scala
package com.dw
import java.sql.{Connection, DriverManager, ResultSet, Statement}
object HiveJdbcTest {
def main(args: Array[String]): Unit = {
// 加载Hive JDBC驱动
Class.forName("org.apache.hive.jdbc.HiveDriver")
// HiveServer2连接信息
val url = "jdbc:hive2://master:10000/default" // 替换为虚拟机IP
val user = "hadoop" // 虚拟机用户名
val password = "123456" // Hive默认无密码
// 建立连接
val conn: Connection = DriverManager.getConnection(url, user, password)
val stmt: Statement = conn.createStatement()
try {
// 创建测试表
// 查询数据
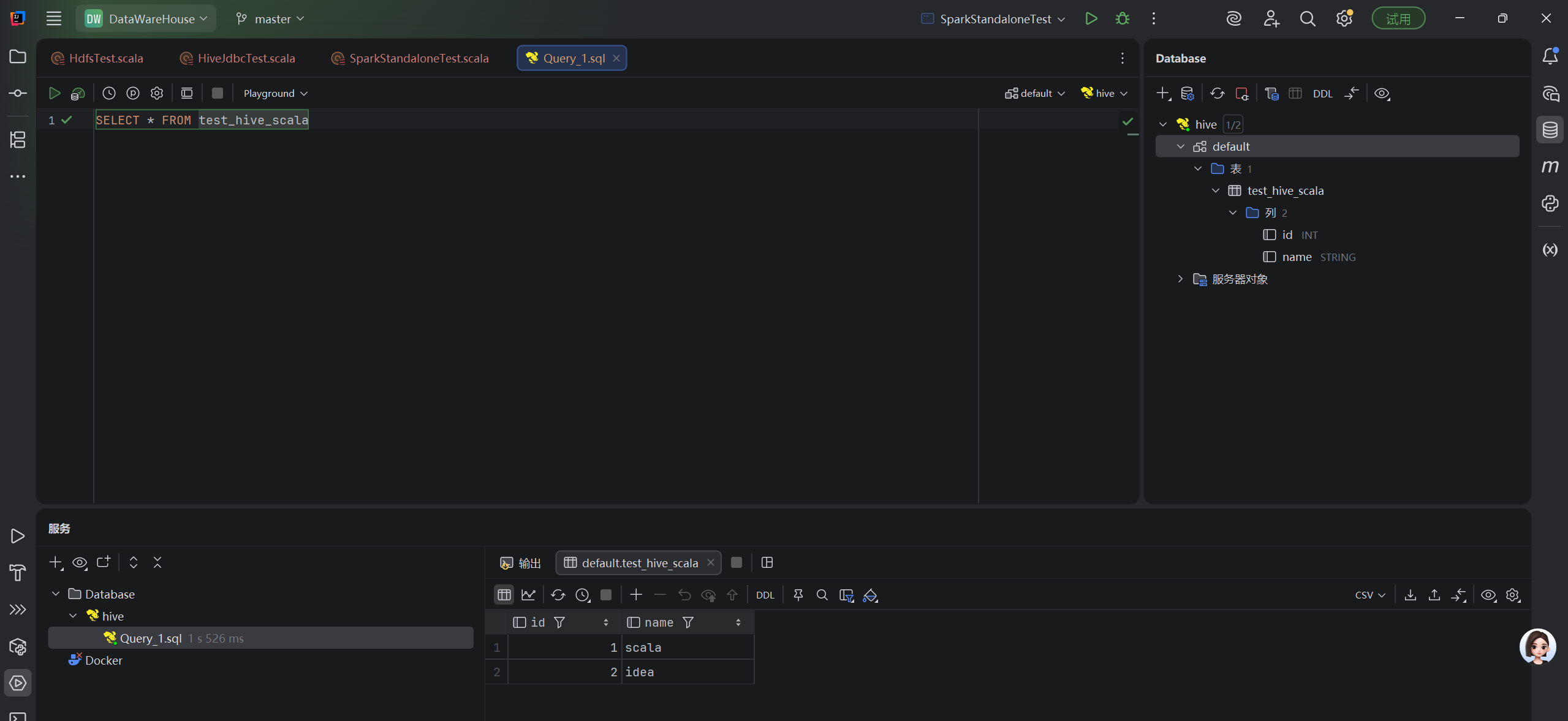
val rs: ResultSet = stmt.executeQuery("SELECT * FROM test_hive_scala")
while (rs.next()) {
val id = rs.getInt("id")
val name = rs.getString("name")
println(s"id: $id, name: $name")
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
// 关闭资源
stmt.close()
conn.close()
}
}
}测试结果:
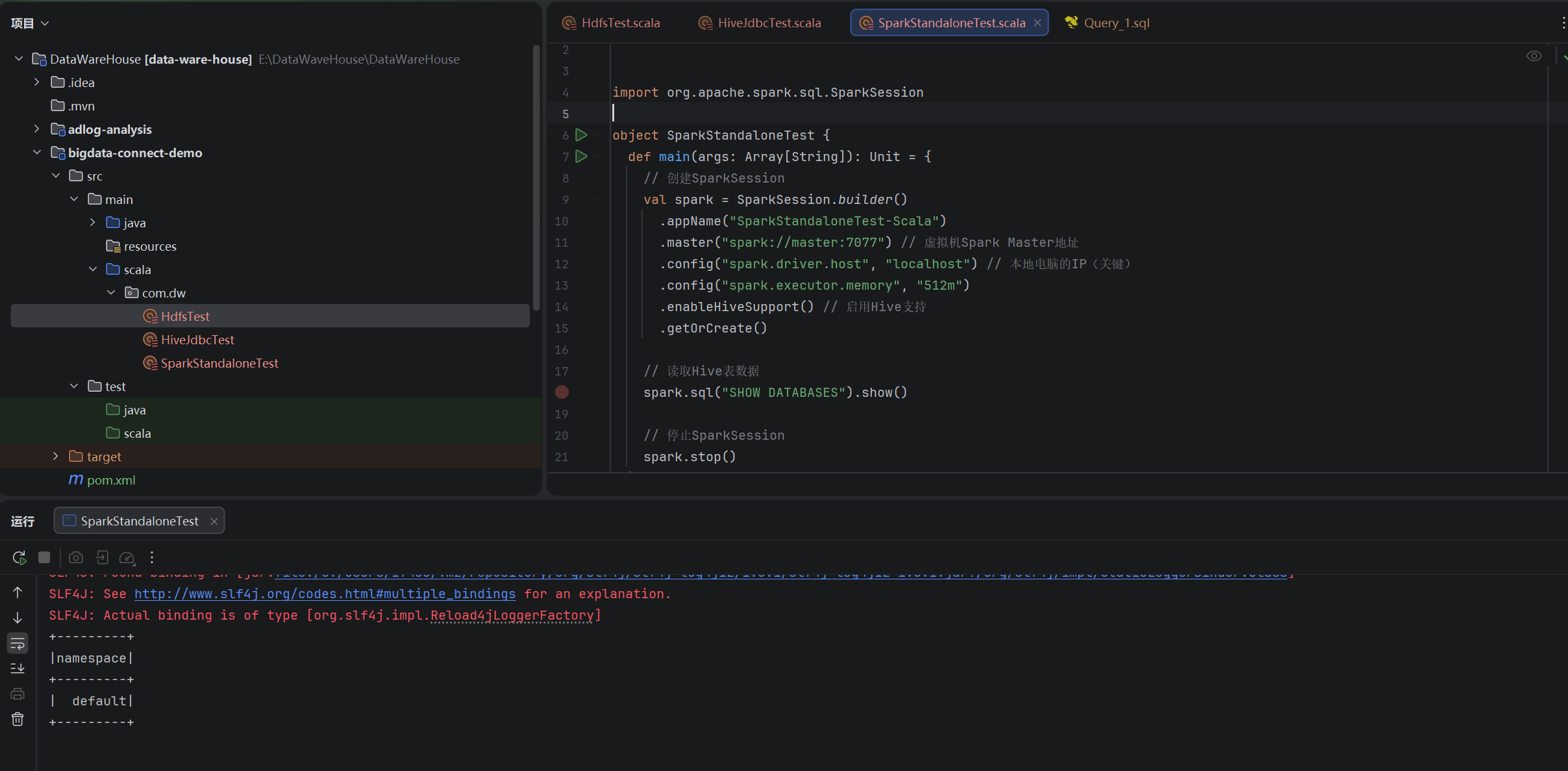
3、spark
Scala
package com.dw
import org.apache.spark.sql.SparkSession
object SparkStandaloneTest {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark = SparkSession.builder()
.appName("SparkStandaloneTest-Scala")
.master("spark://master:7077") // 虚拟机Spark Master地址
.config("spark.driver.host", "localhost") // 本地电脑的IP(关键)
.config("spark.executor.memory", "512m")
.enableHiveSupport() // 启用Hive支持
.getOrCreate()
// 读取Hive表数据
spark.sql("SHOW DATABASES").show()
// 停止SparkSession
spark.stop()
}
}测试结果:
四、idea中的hive连接引擎
idea自带的hive查询引擎:
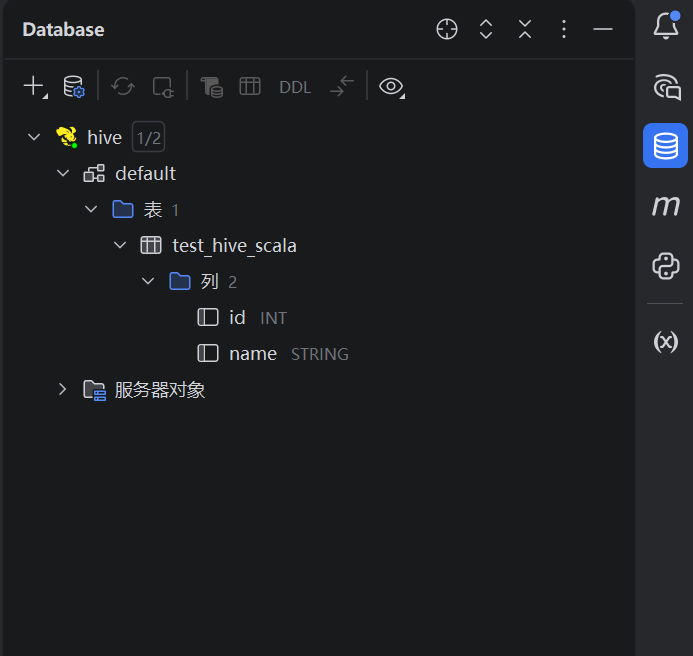
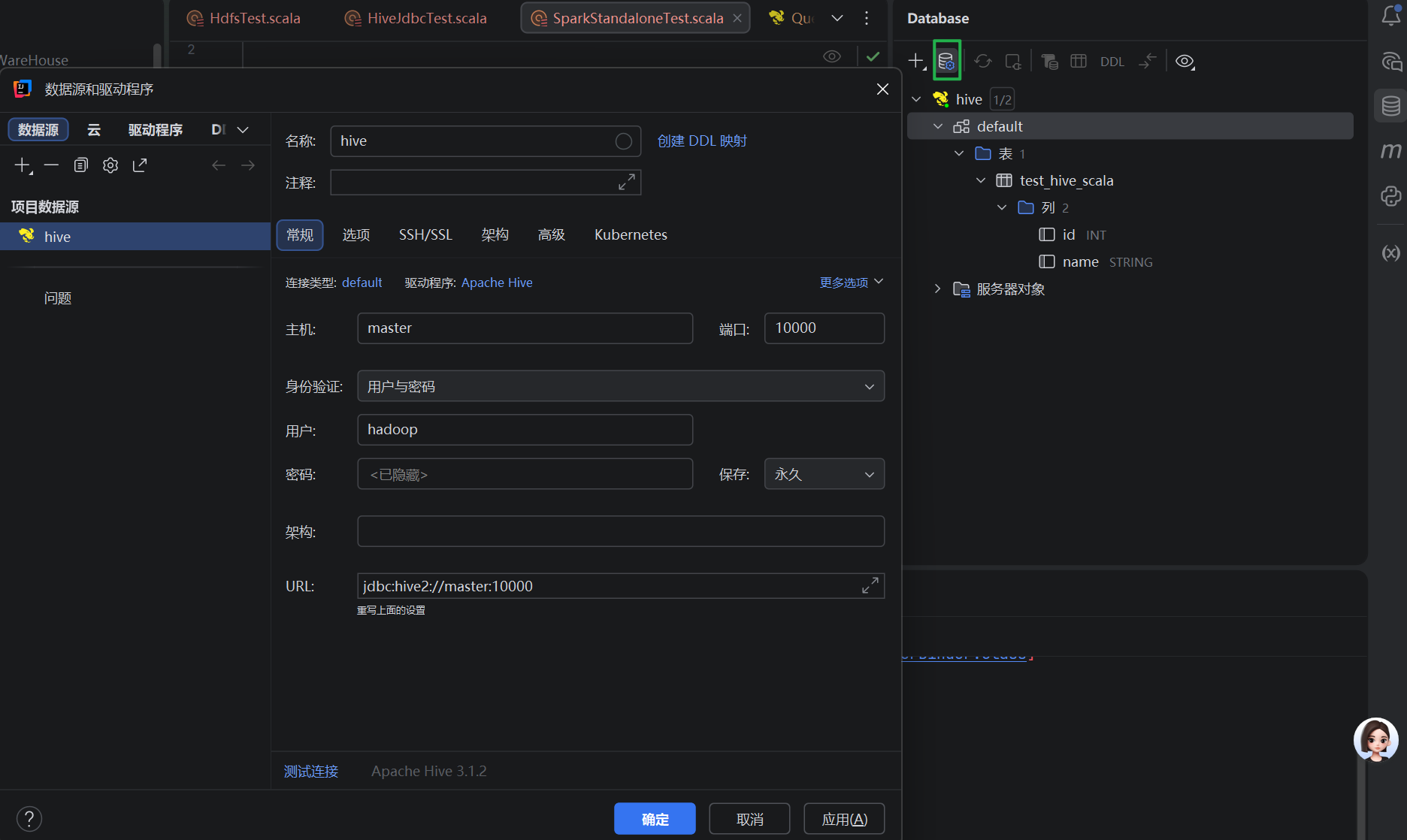
就可以在客户端直接查询hivesql