1. 数据预处理与特征工程
在进入模型之前,必须将原始数据转化为适合混合架构的格式。
- 归一化 (Normalization):对时间序列数据进行 Min-Max 缩放或 Z-Score 标准化,以加快收敛。
- 滑动窗口拆分 (Sliding Window):将长序列切割成固定长度的输入块 (过去的时间步)和标签 (预测的时间步)。
- 维度转换 :调整张量形状以符合 Transformer 的输入要求,通常为
[batch_size, seq_len, input_dim]。
2. 构建 Transformer-LSTM 混合骨架
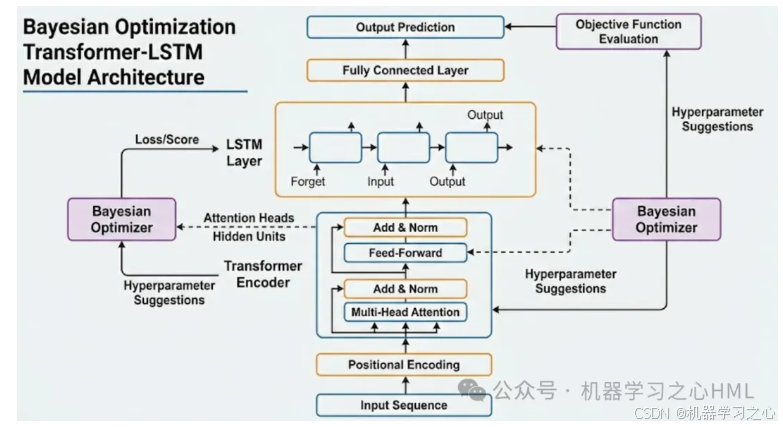
搭建我们在前一张图中看到的模型结构。
- Transformer 层:通过多头注意力提取全局特征。
- LSTM 层:接收 Transformer 的输出,捕捉短期时序依赖。
- 全连接输出层:映射到最终的预测维度。
3. 定义超参数搜索空间 (Search Space)
这是贝叶斯优化的关键。你需要确定哪些参数对性能影响最大,例如:
- Transformer 参数:Head 数量、Layer 数量、Dropout 率。
- LSTM 参数:Hidden Units(隐藏单元数)。
- 优化参数:学习率 (Learning Rate)、Batch Size。
4. 贝叶斯优化核心循环
贝叶斯优化不同于随机搜索,它通过"学习"之前的经验来寻找最优解。
其具体执行步骤如下:
- 定义目标函数 (Objective Function):输入一套超参数,运行模型训练,并返回验证集上的损失(如 RMSE 或 MAE)。
- 构建代理模型 (Surrogate Model) :通常使用高斯过程 (Gaussian Process) 或 TPE (Tree-structured Parzen Estimator)。它会建立超参数与模型表现之间的概率模型。
- 采集函数 (Acquisition Function):利用策略(如期望改善 EI)决定下一步测试哪组参数,平衡"探索"(尝试新领域)与"利用"(深挖已知优秀领域)。
- 迭代更新:
- BO 建议一组参数 训练模型 获取 Loss 更新代理模型。
5. 最佳模型训练与验证
当达到设定的迭代次数或收敛后:
- 提取最优参数:获取 BO 找到的最佳参数组合。
- 重新训练:使用全量训练集和这组最优参数训练最终模型。
- 测试评估:在完全未见的测试集上评估模型的泛化能力。
实现步骤总结表
| 阶段 | 核心任务 | 常用工具 |
|---|---|---|
| 数据层 | 清洗、滑动窗口、归一化 | Pandas, Scikit-learn |
| 模型层 | Transformer + LSTM 堆叠 | PyTorch, TensorFlow |
| 优化层 | 建立代理模型,定义概率分布 | Optuna, Hyperopt, Scikit-Optimize |
| 输出层 | 性能评估、可视化预测结果 | Matplotlib, Seaborn |