RAG中的上下文压缩(Contextual Compression)
RAG的烦恼:信息太多,噪声太大
RAG系统的本质,就是"先检索,再生成"。你问个问题,系统先去知识库里搜一圈,把相关的内容捞出来,然后丢给大模型生成答案。
听起来很美好,但实际用起来,常常是这样的:
检索出来的内容,Relevant(相关)和Irrelevant(无关)混杂在一起。
有用的信号被一堆废话包围,模型的上下文窗口被"水文"占满。
结果:答案啰嗦、跑题、甚至答非所问。
举个栗子:
你问"AI决策的伦理问题有哪些?",检索出来的段落里,既有"AI的历史",又有"AI的优点",还有"AI的缺点",真正和伦理相关的内容,可能只占三分之一。
怎么办?
别慌,今天我们就来聊聊------上下文压缩(Contextual Compression)!
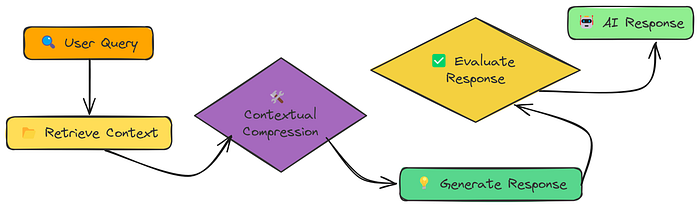
什么是上下文压缩?
上下文压缩,就是在RAG检索后,把无关内容"剪掉",只留下和问题最相关的部分。
这里的"压缩"既指压缩单个文档的内容,也指批量过滤文档。我们可以使用给定查询的上下文来压缩它们,以便只返回相关信息,而不是立即按原样返回检索到的文档。
这样做的好处:
- 减少噪声:让大模型只看到有用的信息。
- 提升准确率:答案更聚焦、更靠谱。
- 节省上下文窗口:能处理更长的文档,成本更低。
压缩不是一刀切,常见有三种玩法:
-
Selective(选择性保留)
- 只保留和问题直接相关的句子/段落,原文照抄,不做改写。
-
Summary(摘要压缩)
- 把相关内容浓缩成简明扼要的摘要,信息密度高。
-
Extraction(句子抽取)
- 只抽取原文中包含关键信息的句子,逐句列出。
不同场景,可以选不同流派:
你要"原汁原味",选Selective或Extraction;
你要"言简意赅",选Summary。
RAG上下文压缩的完整流程
1. 文档预处理
PDF提取文本:用PyMuPDF等工具,把PDF里的内容全都抽出来。
分块(Chunking):把长文本切成小块(比如每1000字一块,重叠200字),方便后续检索。
2. 向量化与检索
文本嵌入(Embedding):用OpenAI、bge等模型,把每个chunk变成向量。
向量检索:用户提问后,把问题也变成向量,找出最相似的Top-K个chunk。
3. 上下文压缩(核心!)
对每个检索到的chunk,调用大模型,按指定压缩方式(Selective/Summary/Extraction)处理,只保留和问题相关的内容。
批量处理:一次性压缩多个chunk,效率更高。
4. 生成最终答案
把压缩后的内容拼成上下文,丢给大模型生成最终答案。
如果压缩后内容太少,可以回退用原始chunk。
5. 评估与可视化
对比不同压缩方式的效果:准确率、信息量、上下文长度、压缩比。
可视化原文和压缩后的内容,直观感受"瘦身"效果。
再上升到理论层面一些。现有的上下文压缩方法主要分为基于词汇的压缩(硬提示,如LLMLingua和RECOMP)和基于嵌入的压缩(软提示,如Gist、AutoCompressor和ICAE)。前者通过选择或总结上下文中的重要词或短语来减少上下文大小,后者则通过嵌入模型将上下文转换为较少的嵌入token。
但这个对于不同的场景,会有不同的方案,我们来具体看下RAG这个场景的代表方案。
一、基于硬提示的RAG上下文压缩方案
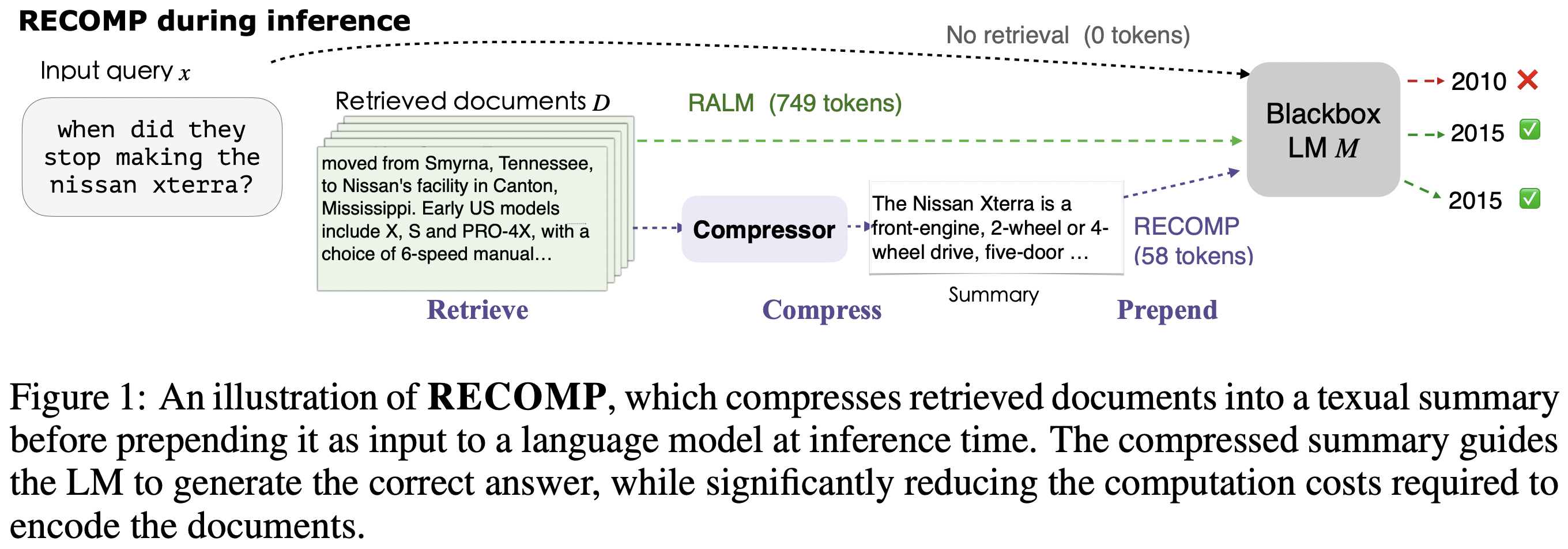
1、RECOMP
论文名称:《RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation》
原文地址:https://arxiv.org/pdf/2310.04408
其核心思想为,通过在上下文增强之前将检索到的文档压缩成文本摘要来提高语言模型的性能,同时减少计算成本。
实现上,包括两个压缩器:
- 一个是提取式压缩器,从检索到的文档集中选择相关句子。该方法训练一个双编码器模型,将句子和输入序列嵌入到固定维度的嵌入空间中,并通过计算它们的内积来评估句子的有用性。最终摘要是从与输入最相关的句子中选择的前N个句子。
- 一个是生成式压缩器,通过综合多个检索到的文档中的信息来生成摘要。该方法从一个极端规模的LM(如GPT-3)中蒸馏出一个轻量级的生成式压缩器,使用教师模型生成摘要,并通过一个裁判模型评估生成的摘要对目标任务的表现,选择表现最好的摘要进行训练。
2、CompAct
论文名称:《Compressing Long Context for Enhancing RAG with AMR-based Concept Distillation》
原文地址:https://arxiv.org/pdf/2405.03085
其思想在于,使用基于AMR(Abstract Meaning Representation)的概念蒸馏算法来压缩长文本,通过从AMR图中提取关键概念节点,将冗余的支持文档转换为简洁的概念集。

在具体实现上,首先是设计基于概念的RAG框架,该框架通过从原始支持文档中提取的关键概念来增强LLMs的推理能力。框架包括三个主要组件:信息检索、概念蒸馏和基于概念的推理。
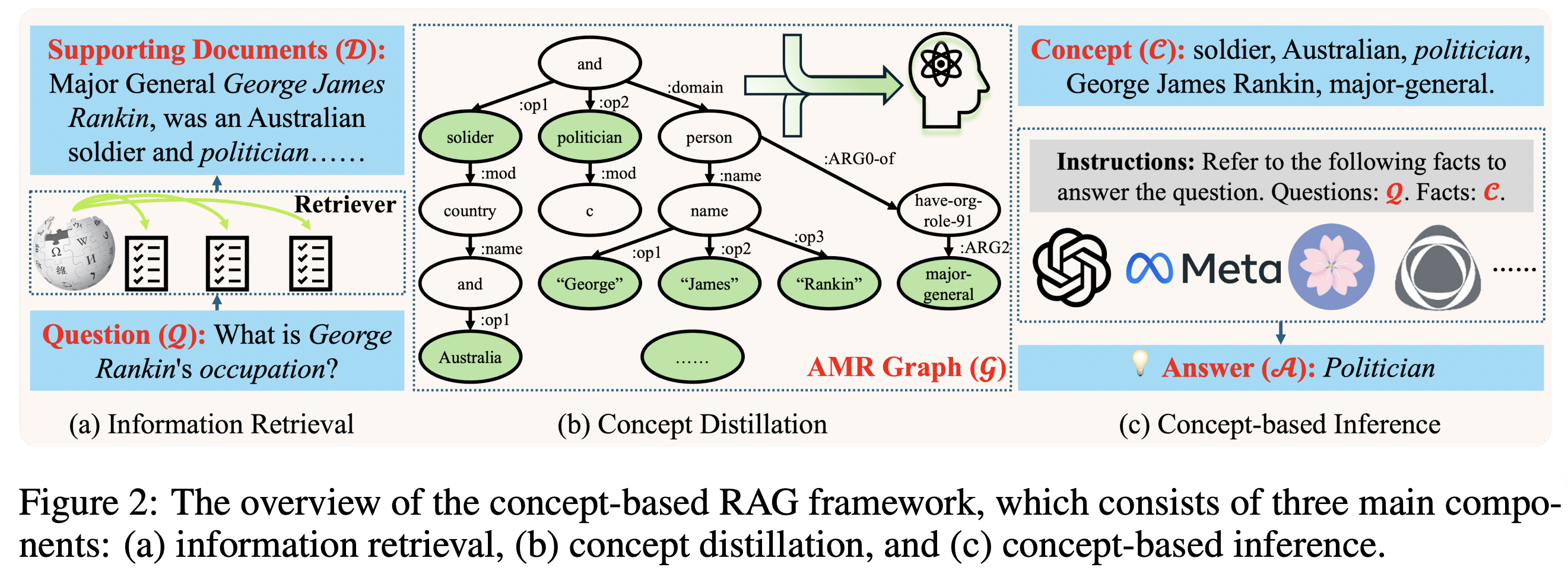
其次,在这个基础上,采用一种AMR概念蒸馏算法,将支持文档从连续序列转换为离散概念,核心思路为:使用mBart-based解析器将支持文档解析为AMR图;设计SplitSnt函数将AMR图分割成基于句子的子图;通过深度优先搜索(DFS)遍历AMR图中的节点,提取关键概念并格式化为概念集合;处理特殊角色(如:name, :wiki, :date-entity)以确保概念的完整性和一致性;使用ConceptFormat和ConceptBacktrace函数过滤和回溯概念,确保概念与原始支持文档的语义一致。
3、FAVICOMP
论文名称:《Familiarity-aware Evidence Compression for Retrieval Augmented Generation》
原文地址:https://arxiv.org/pdf/2409.12468
一般RAG面临的主要挑战是LLM难以过滤掉多个证据片段中的不一致和不相关信息。FAVICOMP通过引入一种新的集成解码技术,主动降低压缩证据的困惑度,使其对目标模型更熟悉。
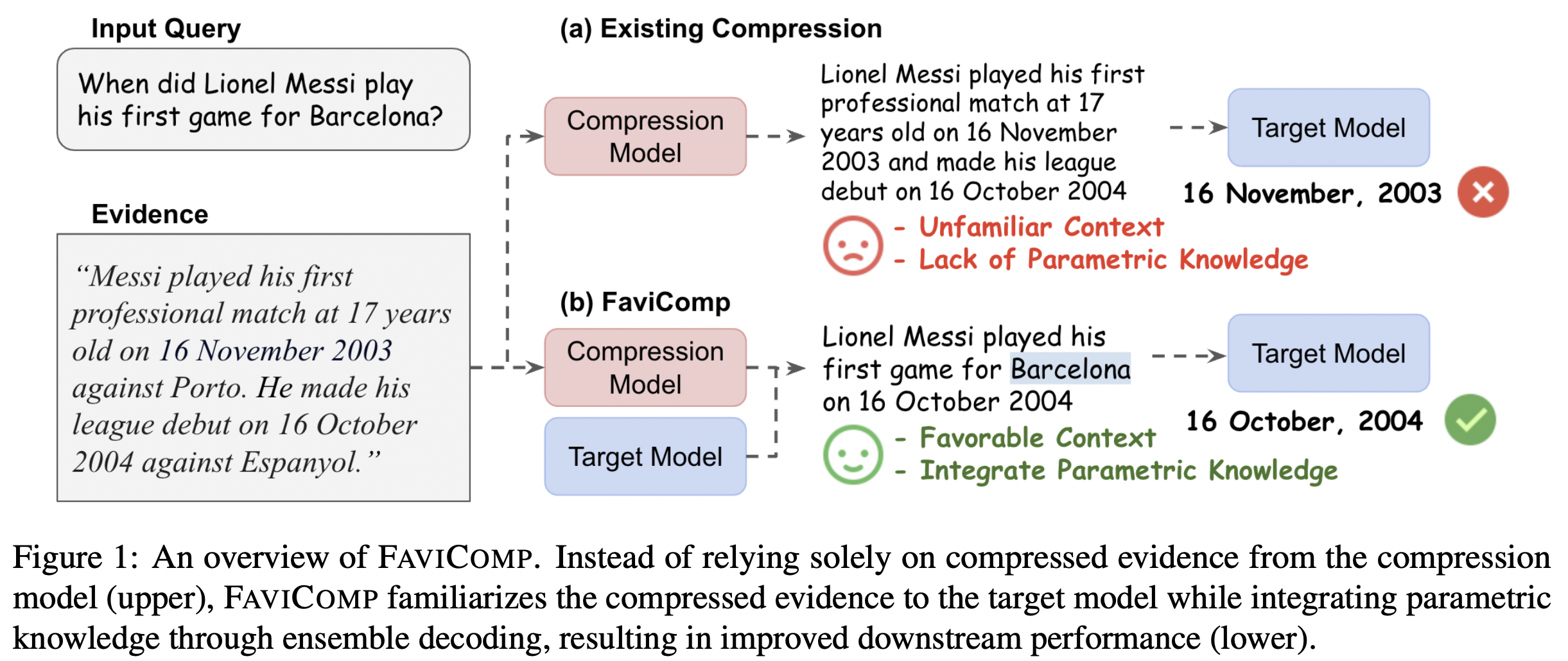
具体包括两个步骤:
一个是证据压缩(Evidence Compression),首先,使用一个压缩模型将检索到的证据文档压缩成一个与输入相关的简洁上下文。压缩模型的目标是将证据文档生成一个查询相关的摘要。
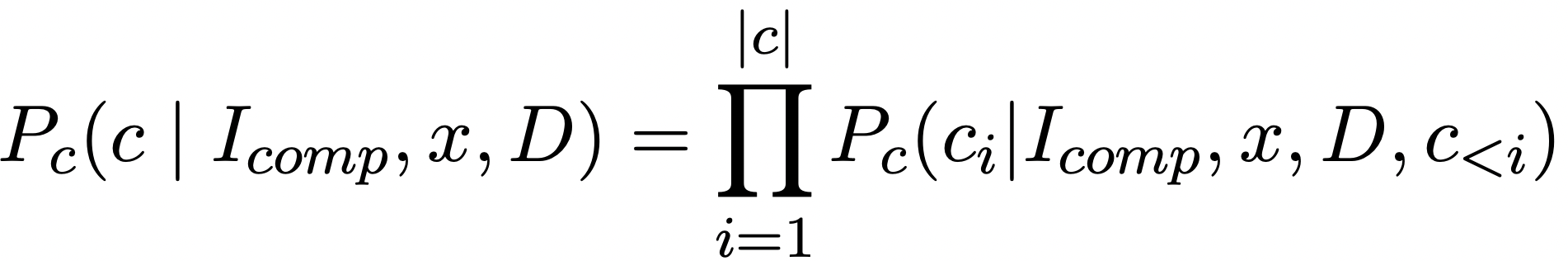
另一个是集成解码(Ensemble Decoding),为了使压缩后的证据对目标模型更加熟悉,FAVICOMP引入了集成解码技术。
具体来说,在解码过程中,结合压缩模型和目标模型的token概率,选择概率最高的token。
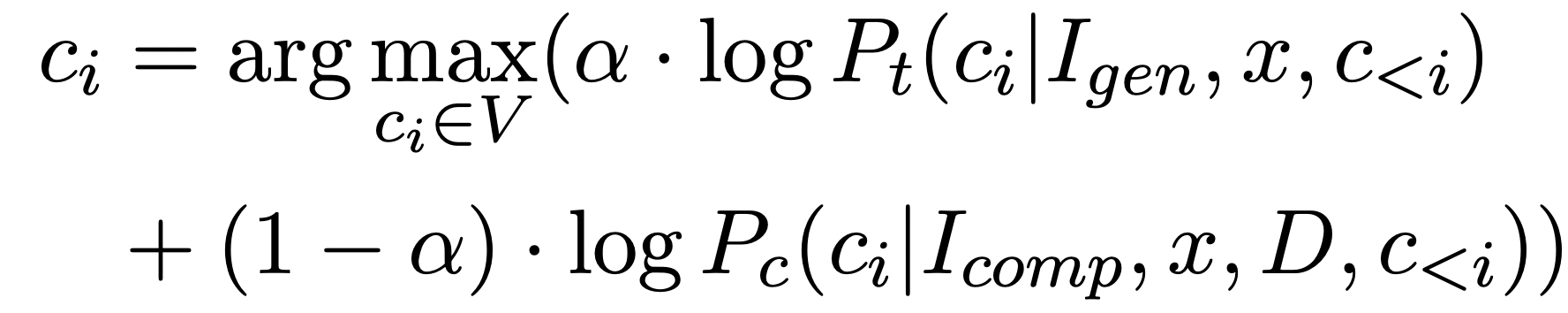
二、基于软提示的RAG上下文压缩方案
1、xRAG
论文名称:《xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token》
原文地址:https://arxiv.org/pdf/2405.13792
GitHub地址:https://github.com/Hannibal046/xRAG
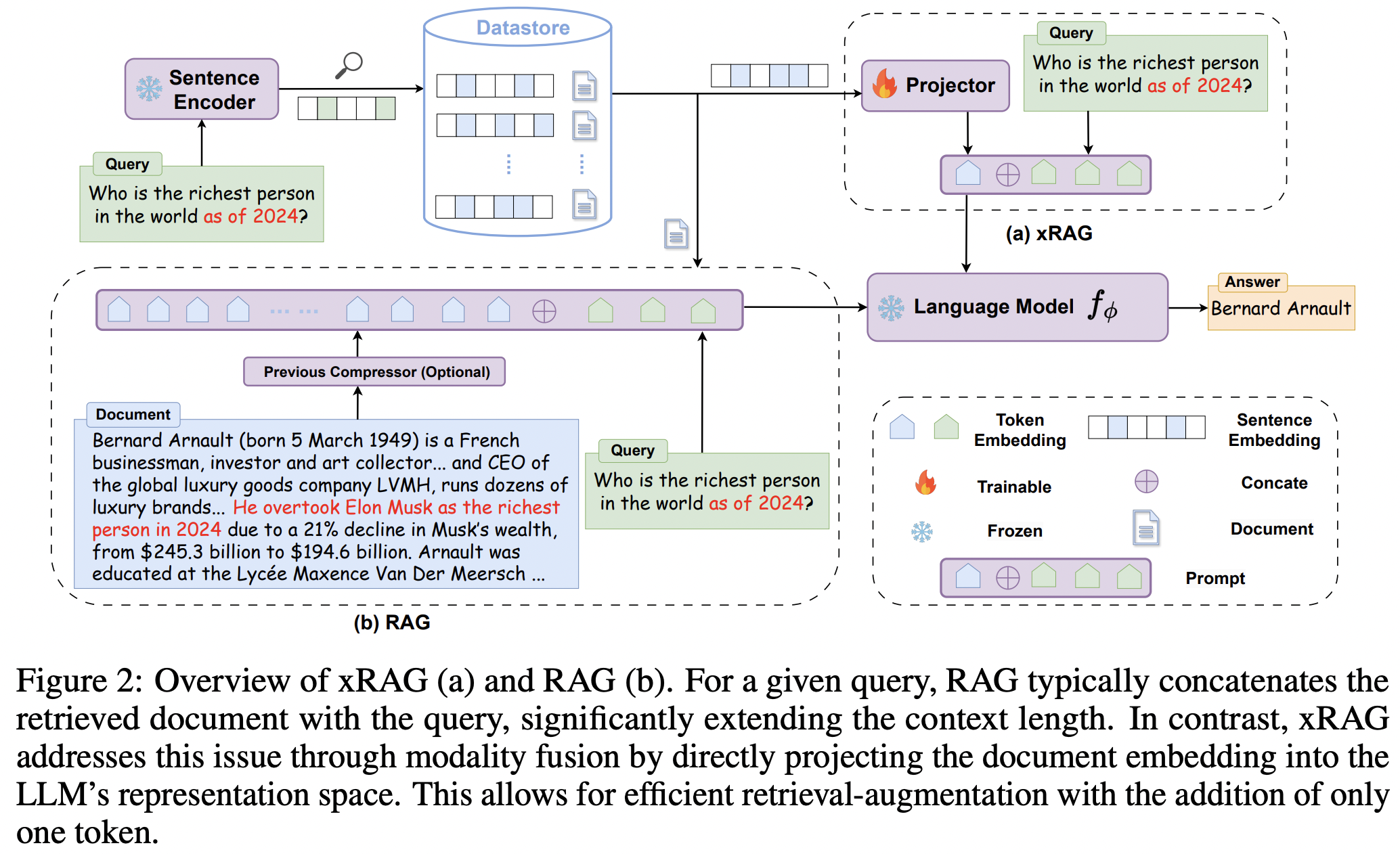
这个工作通过模态融合的方式将文档嵌入直接投影到LLM的表示空间中,从而实现极端的压缩率。

实现上,xRAG通过重新解释密集检索中的文档嵌入,将其视为检索模态的特征,从而实现上下文压缩。具体地,xRAG引入了一个模式投影器W,该投影器被训练以直接将检索特征E投影到语言模型(LLM)的表示空间中。这样,输入到LLM的表示就从传统的嵌入层Emb(D⊕q)变为W(E)⊕Emb(q),大大减少了输入的长度。
2、COCOM
论文名称:《Context Embeddings for Efficient Answer Generation in RAG》
原文地址:https://arxiv.org/pdf/2407.09252
项目地址:https://huggingface.co/naver/cocom-v1-128-mistral-7b
这个工作通过一个压缩器模型将长上下文压缩成少量上下文嵌入。压缩器模型与生成器模型相同,使用相同的预训练语言模型,并通过自编码任务,训练压缩器模型和生成器模型联合学习如何有效地压缩和解压缩上下文。
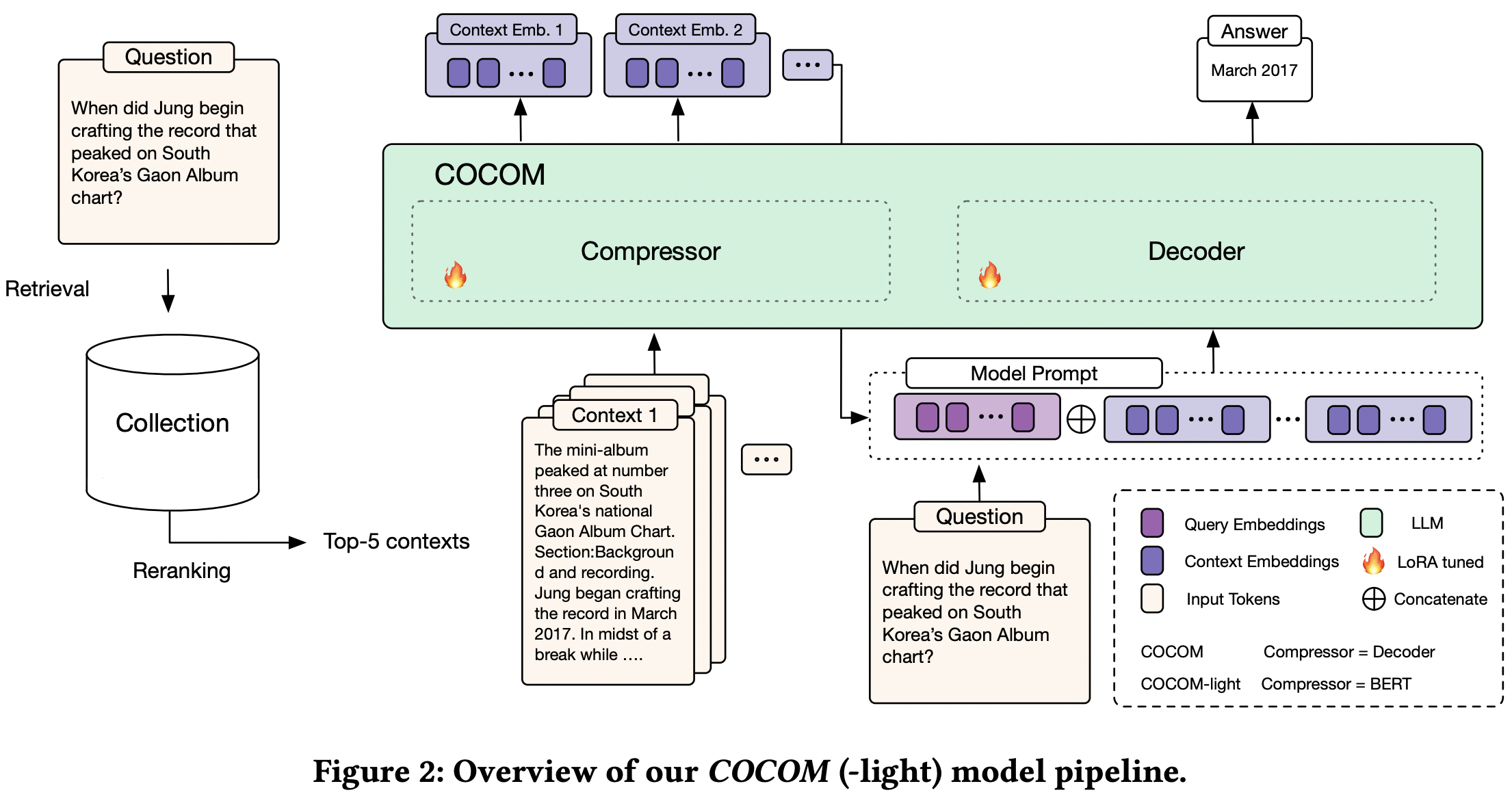
自适应压缩率:压缩嵌入的数量可以根据压缩率ξ和输入长度n进行调整:
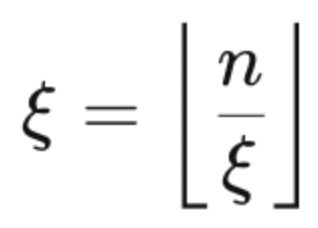
例如,当压缩长度为128的上下文时,压缩率为64,得到2个上下文嵌入,输入减少了64倍。
此外,还可以处理多个检索到的段落上下文,即上下文独立压缩后,使用SEP特殊标记在嵌入之间进行区分,然后将其输入到LLM中。
参考资料
https://blog.csdn.net/bagell/article/details/143507074