前言
本章博客将针对递归归并排序、非递归归并排序、计数排序进行讲解,最后还会整理一下包括前两篇博客写的排序的稳定性
归并排序
如果你的快速排序基础扎实的话,那么归并排序应该对你来说不是啥太大的问题,因为他们都是分治的思想,先看一张图片
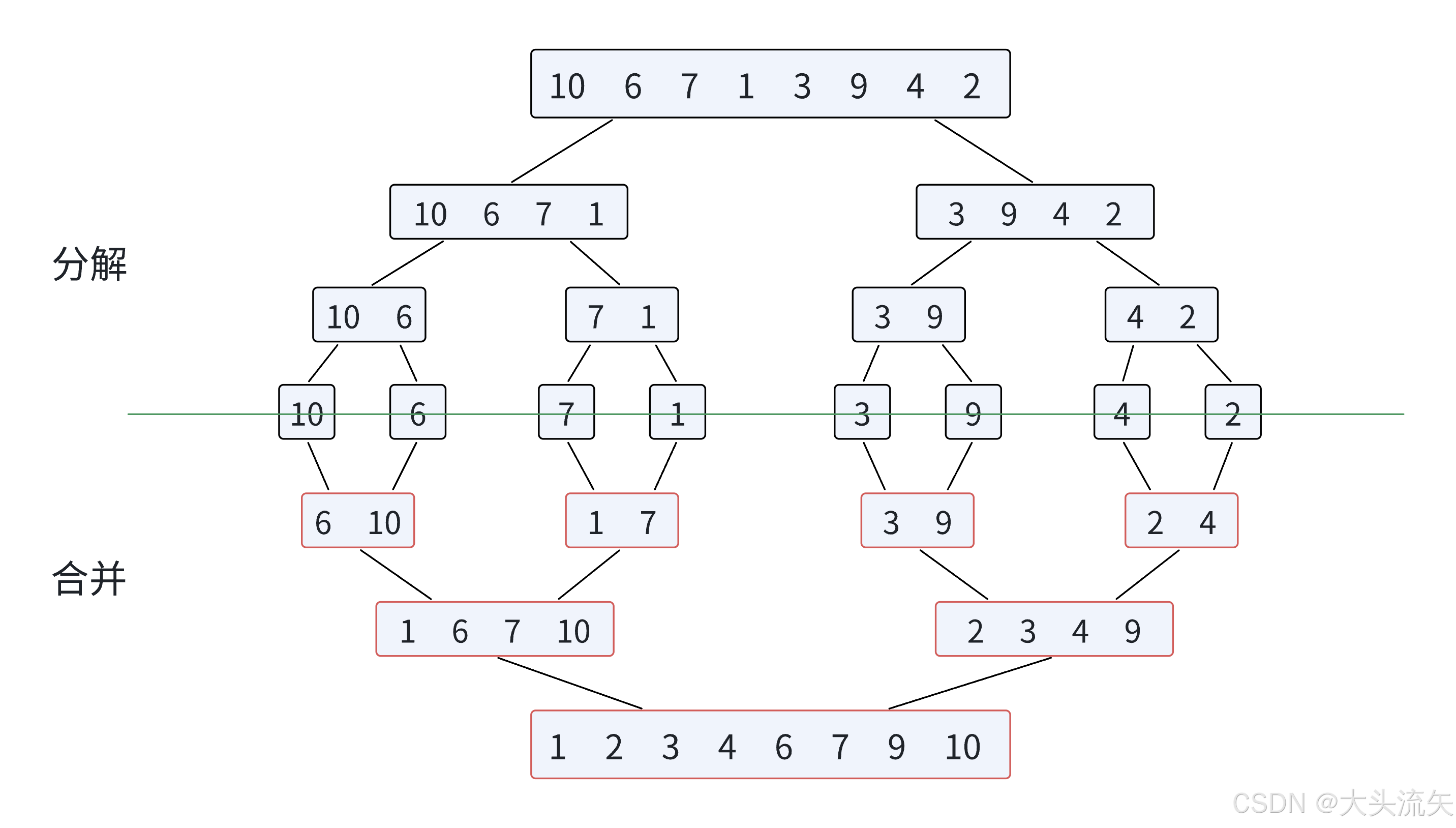
注意点:
这个在分解的过程中还是再原数组里,不要看这张图片好像是把数组里的元素分开了,其实只是和快速排序一样划分了一下有效区间,但是在划分的方式上还是有区别的
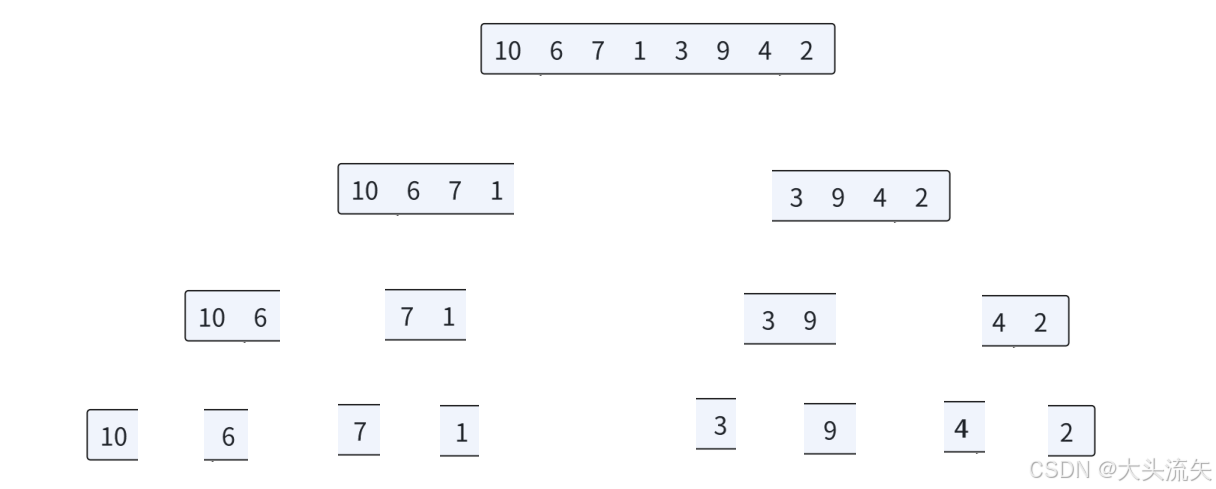
归并排序的划分是平均分,他无关中间的值是多少,他只关心划分出来的左右区间内的元素个数是否是1,如果是1说明该区间就有序了,就可以归并了
**归并逻辑:**划分出来的两个有序区间,从头开始比较,小的插入一个新的数组,最后两个区间如果都归并完了,那么再把新数组的数据拷贝回原数组
代码实现:
创建一个用来归并的数组
递归函数要判断当前的区间左右值是否有效(左区间不能大于右区间)
每次调用递归函数的时候,传入的值应该是左区间和中间值,中间值+1和左区间
如果已经符合归并条件了(最后一层递归是1 1归并,倒数第二层是 2 2归并,倒数第三层 4 4归并...以此类推)(1 1归并就是俩个有序的一个元素区间归并,2 2归并就是俩个有序的2个元素区间归并)那么就开始合并,创建一个循环,循环处理的就是俩个有序区间的排序,俩俩比较小的入新数组,最后入完再把新数组里的元素拷贝会原数组的原位置
cpp
//归并排序
//递归部分
void _MergeSort(int* a, int * tmp , int begin, int end)
{
//保证区间有效性
if (begin >= end)
{
return;
}
//中间值
int mid = begin + (end - begin) / 2;
//每次折半递归
_MergeSort(a, tmp, begin, mid);
_MergeSort(a, tmp, mid + 1, end);
//当函数执行到这里的时候说明,数组已经划分完区间了
//分别拿到两个区间的首地址和结束地址
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
//新数组的下标开始处
//这里的下标和原数组保持一致,方便后面往回拷贝数据
int index = begin;
//如果俩个区间有一个录完了,那就结束循环
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//将未入完的数据接着入到新数组中
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//将新数组的数据拷贝回原数组的相应位置
//为了保证拷贝回去的位置是原来的位置
//end -begin + 1是两区间归并完后数组的元素个数
memcpy(a + begin, tmp + begin, (end - begin + 1) * (sizeof(int)));
}
void MergeSort(int* a, int n)
{
//创建一个新数组用来归并排序
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("tmp fail");
exit(-1);
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}这里我在解释一下a+begin,tmp+begin,还记的tmp归并时的下标是index = begin嘛,应为我们的tmp数组是按照原数组的大小来创建的,然后我们为了保证最后在拷贝回原数组的时候可以方便一点,所以我们选择了俩个区间的元素在原数组是什么下标,在tmp里就保持一致
非递归版本的归并排序
非递归版本的归并排序思路:
可以从递归的思路下手,递归的目的就是为了筛选出最后的只有一个元素区间(因为这样这个区间就是有序的),而且递归版本是1 1归,2 2归,4 4归...所以,我们是不是也可以从1 1归开始,只要控制每次归并的区间只有一个元素就可以了,这就是1 1归,那么2 2 归就是在数组1 1 归以后,在执行,因为1 1归以后数组就是俩俩有序的
第一步还是要有一个tmp数组
第二步要有一个gap来确保1 1、2 2、3 3..归
第三步就是归并的代码
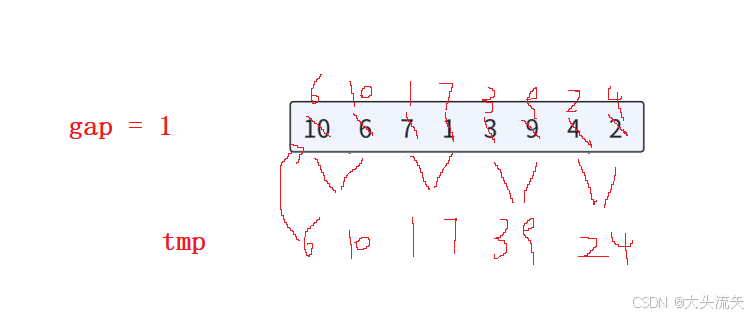
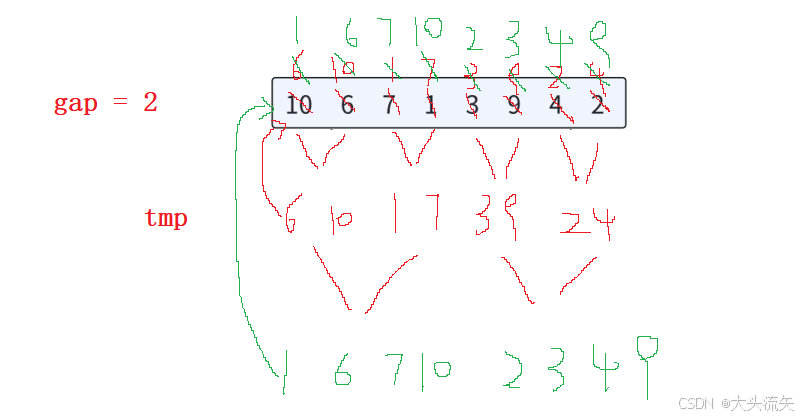
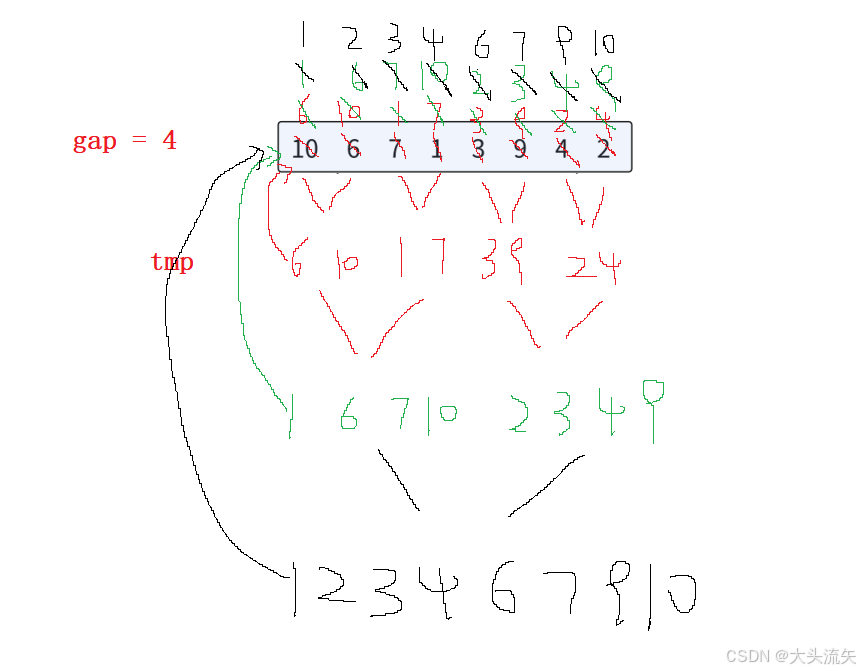
非递归就是这样的流程(其实递归也是这个流程)
代码实现:
cpp
void MergeSortNonR(int* a, int n)//这里的n是元素个数
{
int* tmp = (int*)malloc(sizeof(int) * (n + 1));
if (tmp == NULL)
{
perror("tmp fail");
exit(-1);
}
//控制数组归并步长
int gap = 1;
//当gap的长度大于等于数组的长度时就结束
while (gap < n)
{
//归并区间
//为什么i+=gap*2?
//你可以套一下值看看
for (int i = 0; i < n; i += 2 * gap)
{
//这个是固定公式
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//防止越界
if (begin2 > n)
{
break;
}
if (end2 > n)
{
end2 = n;
}
//tmp的下标
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//此时的i就是俩区间的起始下标
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
//1 1归,结束 2 2归...
gap *= 2;
}
}if (begin2 > n)
{
break;
}
if (end2 > n)
{
end2 = n;
}
这里再解释一下为什么要加这个条件,来防止越界,正常上面的我们8个元素是不会越界的但是9、10、11呢
1里面有begin1、end2
2里面有begin2、end2
我们可以观察到其实会越界的位置都是end1、begin2、end2这些位置
所以我在归并的循环里面加了限制条件,如果end1和begin2都大于n了那么就不需要归并了,此时就只有一个有序区间
如果是end2大于n了,那么此时还是有俩个有序区间的还是需要归并的,我们只需要把end2修正一下就可以了,end2 = n即可,这样end2就不会越界了
归并排序的时间复杂度
归并排序的代码逻辑
第一步将数据分成若干个区间,每个区间只有一个元素,保证了每个区间是有序的
第二步,在第一部的基础上,现在数组两两有序,那就两两归并
直到全部归并完毕
所以这个过程中的最大层数是logn层
然后交换的次数也是n次(这里的n是根据大O的渐进表示法得来的),所以归并排序的时间复杂度就是O(nlogn)
计数排序
计数排序⼜称为鸽巢原理,是对哈希直接定址法的变形应用。
操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中

先创建一个新数组tmp,对于原数组的每一个元素都能在tmp数组中的下标找到
原数组第一个是6,那么在tmp的数组中下标为6的位置就++
原数组第一个是1,那么在tmp的数组中下标为1的位置就++
原数组第一个是2,那么在tmp的数组中下标为2的位置就++
原数组第一个是9,那么在tmp的数组中下标为9的位置就++
原数组第一个是4,那么在tmp的数组中下标为4的位置就++
...
直到遍历完原数组中的所有值,接着就是根据tmp数组的的每个下标的值来对原数组排序即可
tmp数组0下标是0,那么说明原数组中没有0这个元素
tmp数组1下标是2,那么说明原数组中有2个1,此时我们就对原数组的0、1下标覆盖为1
tmp数组2下标是2,那么说明原数组中有2个2,此时我对就对原数组的2、3下标覆盖为2
...以此类推,直到tmp数组访问完最后一个下标
以上这种是计数排序的绝对下标
这种写法对于数据量很大的时候就会很乏力,应为要开辟的空间很多,而且很程度上都是浪费的,就比如:101 102 103 104 105这五个数据,按照绝对下标来说的话,我们要开辟105个空间,但是前101都是没用的浪费的,为了杜绝浪费,我们一般使用相对下标来写代码
相对下标:
先遍历找出原数组中的最大值和最小值,然后用最大值减最小值+1算出原数组的数据值范围
比如,刚刚那个数据最大的是105,最小的是101,那么105 -101 + 1就是 5,那么我们只需要创建5个数据的数组就可以,101就可以存在0下标,102就存在1下标,103就存在2下标,104就存在3下标,105就存在4下标,然后往外拿的时候在加上最小值在放回原数组就可以了
代码实现:
cpp
// 计数排序
void CountSort(int* a, int n)
{
//先选出最大最小值
int max = a[0];
int min = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
//先创建一个新数组
int* tmp = (int*)calloc(max-min+1, sizeof(int) * (max - min + 1));
if (tmp == NULL)
{
perror("tmp fail");
exit(-1);
}
//先根据a数组里的数据,往新数组中记录
int i = 0;
while (i < n)
{
tmp[a[i++] - min]++;
}
//在根据tmp数组中的数据,往原数组覆盖数据
int j = 0;
for (i = 0; i < max - min + 1; i++)
{
while (tmp[i])
{
a[j++] = i + min;
tmp[i]--;
}
}
free(tmp);
tmp = NULL;
}计数排序适合那种数据中出现大规模重复数据,且数据的大小值区间比较集中的,对于这一类数据,计数排序会有奇效