PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
0. 前言
生成式人工智能已成为当前研究的热门领域,生成对抗网络 (Generative Adversarial Network, GAN) 模型于 2014 年提出,自基础 GAN 架构诞生以来,针对不同应用场景的各类 GAN 变体不断涌现并持续演进。
与变分自编码器 (Variational Autoencoder, VAE)不同,VAE 可以学习数据的潜分布,并通过从该分布中采样生成新的样本;自回归模型则逐步生成数据,每次生成一个元素,并以之前生成的元素为条件生成数据。而 GAN 无需显式建模数据分布,即可生成与训练数据高度相似且多样性丰富的样本,这种能力使其在生成逼真内容方面表现尤为突出。
本质上,GAN 由两个神经网络组成------生成器 (Generator) 和判别器 (Discriminator)。以图像生成为例,生成器的任务是生成逼真的虚假图像,而判别器的职责则是区分真实图像与生成器产生的虚假图像。
通过联合优化过程,生成器最终能学会生成足以骗过判别器的超逼真图像。模型训练完成后,其生成器部分即可作为可靠的数据生成装置。除作为无监督学习的生成模型外,GAN 在半监督学习领域同样表现出色------例如在图像任务中,判别器学习到的特征可提升分类模型的性能。
本节将重点介绍深度卷积生成对抗网络 (Deep Convolutional GAN, DCGAN)。与浅层 GAN (层数较少的简单架构)不同,DCGAN 通过多层复杂卷积架构能生成细节更丰富的高质量图像。其本质是无监督的卷积神经网络 (Convolutional Neural Network, CNN)模型,生成器和判别器均采用纯卷积结构(不含全连接层)。
在本节中,将首先解析 GAN 的核心组件(生成器、判别器及联合优化机制),随后基于 PyTorch 实战构建 DCGAN 模型,并通过图像数据集训练验证性能。
1. 生成器和判别器
生成对抗网络 (Generative Adversarial Network, GAN) 由两大核心组件构成------生成器 (Generator) 与判别器 (Discriminator),二者本质上都是神经网络。采用不同神经网络架构的生成器和判别器会衍生出不同类型的 GAN。
GAN 中的生成器通常以随机噪声作为输入,并输出与真实数据维度相同的生成结果(我们称之为虚假数据)。而判别器则扮演着二元分类器的角色:它依次接收生成的虚假数据与真实数据作为输入,并预测输入数据的真伪。下图展示了 GAN 模型的整体架构示意图:
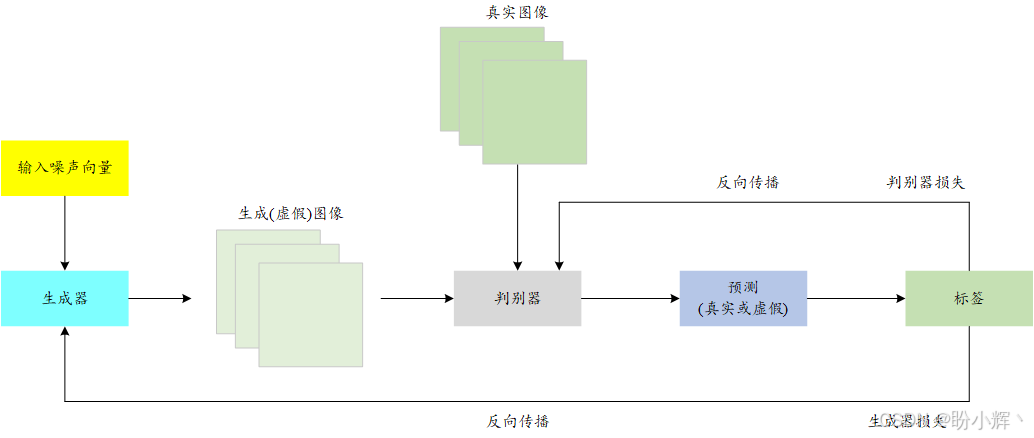
判别器网络的优化方式与常规二元分类器相同,均采用二元交叉熵损失函数。其优化目标是准确将真实图像判定为"真" (real),生成图像判定为"假" (fake)。而生成器网络的优化目标则截然相反------其损失函数数学表达式为 − l o g ( D ( G ( z ) ) ) -log(D(G(z))) −log(D(G(z))),其中 z z z 代表输入生成器 G G G 的随机噪声, G ( z ) G(z) G(z) 表示生成器产生的虚假图像, D ( G ( x ) ) D(G(x)) D(G(x)) 是判别器模型 D D D 的输出概率------即图像为真的概率。当判别器将生成图像误判为真实图像时(即 D ( G ( z ) ) → 1 D(G(z))→1 D(G(z))→1),生成器损失达到最小化。这本质上构成了生成器试图欺骗判别器的对抗博弈过程。
在具体实现时,这两个损失函数采用交替反向传播策略,也就是说,在每次训练迭代中,首先冻结判别器参数,通过生成器损失的反向传播来优化生成器网络。接着,冻结生成器参数,通过判别器损失的反向传播来优化判别器网络。这种交替优化机制称为"联合优化",可以将其类比为极小极大博弈 (Minimax Game),这种训练范式确保了生成器与判别器在对抗中协同进化,最终达到纳什均衡状态。
2. DCGAN 的生成器和判别器
就深度卷积生成对抗网络 (Deep Convolutional GAN, DCGAN)而言,其生成器与判别器采用全卷积架构。下图展示了 DCGAN 生成器的具体结构。

首先,将大小为 64 的随机噪声输入向量进行重塑,并通过线性层投影为 128 个 16 x 16 大小的特征图。随后,通过一系列上采样和卷积层进行处理。
在卷积神经网络中,上采样是指通过插入零值行列或使用插值方法(如双线性插值或最近邻插值)来增加特征图空间分辨率的过程。这一技术常见于图像分割等任务,其最终输出需要与输入图像保持相同的空间维度。
本节所用模型的第一个上采样层采用最近邻策略,直接将 16 x 16 的特征图转换为 32 x 32 尺寸。紧接着是一个 3 x 3 卷积核、输出 128 个特征图的二维卷积层。该卷积层输出的 128 个 32 x 32 特征图会继续上采样至 64 x 64 尺寸,再经过两个二维卷积层处理,最终生成 64 x 64 大小的(虚假) RGB 图像。
我们已经了解了生成器模型的结构,接下来,查看判别器模型架构:

可以看到,该架构中每个卷积层采用步长 (stride) 为 2 的设计,能有效缩减空间维度,同时不断增加通道深度(即特征图数量)。这是一个经典的基于CNN的二分类架构,用于区分真实图像与生成的虚假图像。
了解了生成器和判别器网络的架构后,可以构建完整的 DCGAN 模型,并在图像数据集上进行训练。
接下来,我们将使用 PyTorch 来构建并训练 DCGAN。我们将详细讨论如何实例化 DCGAN 模型、加载图像数据集、训练 DCGAN 的生成器和判别器,以及从训练好的 DCGAN 生成器中生成虚假图像。
3. 使用 PyTorch 实现 DCGAN
在本节中,使用 PyTorc h构建、训练并测试 DCGAN 模型。
3.1 定义生成器
(1) 首先,导入所需的库:
python
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torchvision import datasets(2) 定义模型的超参数,训练模型 10 个 epoch,批大小为 32,学习率为 0.001,图像大小为 64 x 64 x 3。latent_dimension 是随机噪声向量的长度,表示我们将从一个 64 维的潜空间中采样随机噪声作为生成器模型的输入:
python
num_eps=10
bsize=32
lrate=0.001
lat_dimension=64
image_sz=64
chnls=1
logging_intv=200(3) 定义生成器模型:
python
class GANGenerator(nn.Module):
def __init__(self):
super(GANGenerator, self).__init__()
self.inp_sz = image_sz // 4
self.lin = nn.Linear(lat_dimension, 128 * self.inp_sz ** 2)
self.bn1 = nn.BatchNorm2d(128)
self.up1 = nn.Upsample(scale_factor=2)
self.cn1 = nn.Conv2d(128, 128, 3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(128, 0.8)
self.rl1 = nn.LeakyReLU(0.2, inplace=True)
self.up2 = nn.Upsample(scale_factor=2)
self.cn2 = nn.Conv2d(128, 64, 3, stride=1, padding=1)
self.bn3 = nn.BatchNorm2d(64, 0.8)
self.rl2 = nn.LeakyReLU(0.2, inplace=True)
self.cn3 = nn.Conv2d(64, chnls, 3, stride=1, padding=1)
self.act = nn.Tanh()(4) 定义了 __init__ 方法后,定义 forward 方法,按顺序调用各个网络层:
python
def forward(self, x):
x = self.lin(x)
x = x.view(x.shape[0], 128, self.inp_sz, self.inp_sz)
x = self.bn1(x)
x = self.up1(x)
x = self.cn1(x)
x = self.bn2(x)
x = self.rl1(x)
x = self.up2(x)
x = self.cn2(x)
x = self.bn3(x)
x = self.rl2(x)
x = self.cn3(x)
out = self.act(x)
return out在本节中,使用了显式的逐层定义方式,而不是 nn.Sequential 方法,这样做是因为逐层定义的方式更容易调试。同时在模型中使用了批归一化和 LeakyReLU 层。
批归一化 (Batch Normalization) 通常在线性层或卷积层后使用,它有两个主要目的:一是加速训练过程,二是减少对初始网络权重的敏感性。ReLU (Rectified Linear Unit) 激活函数可能会导致负值输入的所有信息丢失。LeakyReLU 在负值区间保留一定的梯度,从而防止在训练 GAN 模型时出现梯度消失问题。
3.2 定义判别器
(1) 与生成器类似,定义判别器模型:
python
class GANDiscriminator(nn.Module):
def __init__(self):
super(GANDiscriminator, self).__init__()
def disc_module(ip_chnls, op_chnls, bnorm=True):
mod = [nn.Conv2d(ip_chnls, op_chnls, 3, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25)]
if bnorm:
mod += [nn.BatchNorm2d(op_chnls, 0.8)]
return mod
self.disc_model = nn.Sequential(
*disc_module(chnls, 16, bnorm=False),
*disc_module(16, 32),
*disc_module(32, 64),
*disc_module(64, 128),
)
# width and height of the down-sized image
ds_size = image_sz // 2 ** 4
self.adverse_lyr = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())首先,定义一个通用的判别器模块,它由一个卷积层、一个可选的批归一化层、一个 LeakyReLU 层和一个 dropout 层组成。在构建判别器模型时,我们重复堆叠该模块四次------每次为卷积层配置不同的参数组合。
该模型的设计目标是:当 64 x 64 x 3 的 RGB 图像输入时,随着数据在卷积层中逐级传递,其通道数(即深度)会不断增加,而图像的高度和宽度则持续缩减。最终判别器模块的输出会被展平,并送入全连接层至模型最终输出(即二分类结果)。该输出会经过 Sigmoid 激活函数处理,从而给出图像为真实样本(或非虚假样本)的概率值。
(2) 判别器的 forward 方法接受一个 64 x 64 的 RGB 图像作为输入,并输出图像为真实图像的概率:
python
def forward(self, x):
x = self.disc_model(x)
x = x.view(x.shape[0], -1)
out = self.adverse_lyr(x)
return out(3) 定义了生成器和判别器模型之后,可以实例化这两个模型。同时,定义对抗损失函数 (adversarial loss function),二元交叉熵损失函数 (binary cross-entropy loss):
python
# instantiate the discriminator and generator models
gen = GANGenerator()
disc = GANDiscriminator()
# define the loss metric
adv_loss_func = torch.nn.BCELoss()对抗损失函数将在训练循环中用来定义生成器和判别器的损失函数。从概念上讲,我们使用二元交叉熵作为损失函数是因为目标本质上是二元的------即要么是真实图像,要么是生成图像,而二元交叉熵损失函数正是处理这类二元分类任务的理想选择。
3.3 加载图像数据集
为了训练 DCGAN 生成逼真的虚假图像,我们将使用 MNIST 数据集,该数据集包含 0 到 9 的手写数字图像。通过使用 torchvision.datasets 可以直接下载 MNIST 数据集,并使用它创建数据集 (dataset) 和数据加载器 (dataloader) 实例:
python
# define the dataset and corresponding dataloader
dloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./data/mnist/",
download=True,
transform=transforms.Compose(
[transforms.Resize((image_sz, image_sz)),
transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=bsize,
shuffle=True,
)我们已完成模型架构和数据管道的定义,接下来编写 DCGAN 模型的训练流程。
3.4 DCGAN 训练循环
接下来,将训练 DCGAN 模型。
(1) 为生成器和判别器定义 Adam 优化器,Adam 优化器的 beta1 和 beta2 参数分别设为 0.5 和 0.999:
python
# define the optimization schedule for both G and D
opt_gen = torch.optim.Adam(gen.parameters(), lr=lrate)
opt_disc = torch.optim.Adam(disc.parameters(), lr=lrate)(2) 训练生成器,运行训练循环来训练 DCGAN。由于需要同时训练生成器和判别器,训练流程将交替执行以下两个步骤:训练生成器模型和训练判别器模型。首先训练生成器:
python
os.makedirs("./images_mnist", exist_ok=True)
for ep in range(num_eps):
for idx, (images, _) in enumerate(dloader):
# generate grounnd truths for real and fake images
good_img = Variable(torch.FloatTensor(images.shape[0], 1).fill_(1.0), requires_grad=False)
bad_img = Variable(torch.FloatTensor(images.shape[0], 1).fill_(0.0), requires_grad=False)
# get a real image
actual_images = Variable(images.type(torch.FloatTensor))
# train the generator model
opt_gen.zero_grad()
# generate a batch of images based on random noise as input
noise = Variable(torch.FloatTensor(np.random.normal(0, 1, (images.shape[0], lat_dimension))))
gen_images = gen(noise)
# generator model optimization - how well can it fool the discriminator
generator_loss = adv_loss_func(disc(gen_images), good_img)
generator_loss.backward()
opt_gen.step()首先为真实和虚假的图像生成标签。真实图像的标签为 1,虚假图像的标签为 0。这些标签将作为判别器模型的目标输出,判别器模型是一个二分类器。接下来,从 MNIST 数据集加载一批真实图像,并使用生成器生成一批虚假图像,输入为随机噪声。最后,将生成器损失定义为以下两者之间的对抗损失:
- 判别器模型预测的虚假图像(由生成器模型生成)的"真实"概率
- 目标值
1
本质上,当判别器被"欺骗",将生成的虚假图像误判为真实图像时,即表明生成器成功完成了它的任务,此时生成器损失值会较低。在计算出生成器损失后,我们即可通过反向传播梯度来调整生成器的参数。
需要特别说明的是:在上述生成器优化步骤中,我们保持判别器参数不变,仅使用判别器模型进行前向传播计算。
(3) 训练判别器:接下来,进行相反的操作------即冻结生成器模型的参数,并训练判别器模型。为了训练判别器模型,需要真实图像和虚假图像。将判别器的损失定义为对抗损失或二元交叉熵损失:
python
# train the discriminator model
opt_disc.zero_grad()
# calculate discriminator loss as average of mistakes(losses) in confusing real images as fake and vice versa
actual_image_loss = adv_loss_func(disc(actual_images), good_img)
fake_image_loss = adv_loss_func(disc(gen_images.detach()), bad_img)
discriminator_loss = (actual_image_loss + fake_image_loss) / 2
# discriminator model optimization
discriminator_loss.backward()
opt_disc.step()
batches_completed = ep * len(dloader) + idx
if batches_completed % logging_intv == 0:
print(f"epoch number {ep} | batch number {idx} | generator loss = {generator_loss.item()} | discriminator loss = {discriminator_loss.item()}")
save_image(gen_images.data[:25], f"images_mnist/{batches_completed}.png", nrow=5, normalize=True)分别计算真实图像批次和生成图像批次的判别器损失:真实图像批次的目标值为 1,生成图像批次的目标值为 0。然后将这两个损失的平均值作为最终的判别器损失,并通过反向传播梯度来优化判别器模型参数。
每经过若干 epoch 和 batch 后,记录模型的性能指标------即生成器损失和判别器损失,输出如下所示:
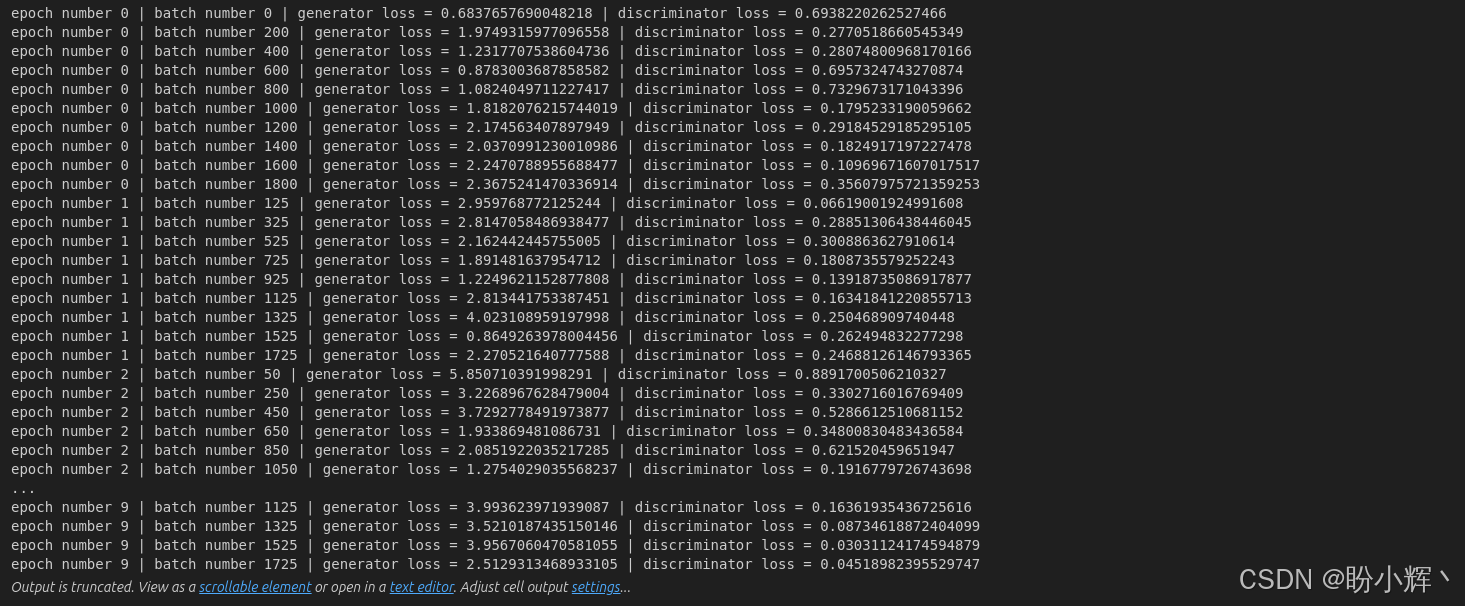
可以看到损失值存在一定波动,这是 GAN 模型在联合训练机制下的典型现象。除了输出日志外,我们还会定期保存网络生成的图像样本。可以看到,生成的图像质量逐步提升:

通过将训练后期 epoch 的生成结果与原始 MNIST 图像对比可以看出,DCGAN 已经能够生成相当逼真的手写数字图像。我们已经学习了如何使用 PyTorch 从零构建一个 DCGAN 模型,我们可以使用任何图像数据集来训练 DCGAN 模型,一个常用的图像数据集是名人面孔数据集。
小结
自生成对抗网络 (Generative Adversarial Network, GAN) 提出以来,一直是一个活跃的研究和开发领域。本节探索了 GAN 的基本概念,重点解析了其两大核心组件------生成器与判别器的架构设计,深入阐述了 GAN 模型的整体工作机制,并使用 PyTorch 从零开始实现了深度卷积生成对抗网络 (Deep Convolutional GAN, DCGAN)。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)