
目录
[1.1 机器学习的概念](#1.1 机器学习的概念)
[1.2 三大学习范式](#1.2 三大学习范式)
[1.3 经典算法](#1.3 经典算法)
[1.4 机器学习工作流程](#1.4 机器学习工作流程)
[2.1 深度学习的崛起](#2.1 深度学习的崛起)
[2.2 神经网络基础](#2.2 神经网络基础)
[3.1 计算机视觉](#3.1 计算机视觉)
[3.2 机器视觉](#3.2 机器视觉)
[3.3 核心辨析](#3.3 核心辨析)
[3.4 核心任务](#3.4 核心任务)
[3.5 技术栈演进](#3.5 技术栈演进)
一、什么是机器学习?
1.1 机器学习的概念
机器学习是人工智能的一个分支,它使计算机能够从数据中学习并做出预测或决策,而无需明确编程。核心思想是:通过算法从历史数据中学习规律,并应用于新数据。
机器学习是一种通过算法和模型使计算机从数据中自动学习并进行预测或决策的技术,属于人工智能的一个分支。其核心目标是让计算机在没有明确编程指令的情况下,通过对大量数据的分析,识别模式和规律,从而构建适应新数据的模型。机器学习包括监督学习、无监督学习和强化学习等不同类型,广泛应用于图像识别、自然语言处理、推荐系统和自动驾驶等领域,具备自适应、自动化和泛化能力,是数据驱动的技术创新。
领域内的一些学者也对机器学习给出了定义------汤姆·米切尔(Tom Mitchell)是卡内基梅隆大学的计算机科学教授,被认为是机器学习领域的奠基人之一。他的经典定义在机器学习教科书中被广泛引用:如果计算机程序在完成某类任务T时,通过经验E在某一表现度量P下的表现有所提高,则称该程序从经验E中学习。机器学习的目标是使用计算机预测未知的事件或场景。1959年,亚瑟·塞缪尔(Arthur Samuel)将机器学习描述为"赋予计算机在没有明确编程指令下学习能力的研究领域"。他断言,编程计算机通过经验进行学习,最终应能消除大部分详细编程工作的需求。
核心思想:
-
训练:给算法提供大量带有标签(监督学习)或无标签(无监督学习)的数据。
-
学习:算法自动找出数据中的模式、规律或特征。
-
预测/推断:将学习到的模型应用于新的、未见过的数据,做出判断或预测。
1.2 三大学习范式
-
监督学习:数据有标签。如:根据历史房价数据(特征:面积、地段等;标签:价格)预测新房价。常用算法:线性回归、决策树、支持向量机。
-
无监督学习:数据无标签。如:将客户按消费习惯自动分成不同群组。常用算法:聚类、降维。
-
强化学习:智能体通过与环境互动,根据奖励或惩罚来学习最优策略。如:AlphaGo。

1.3 经典算法
1990至2010年代,随着计算能力提升,机器学习进入快速发展期,涌现出多种经典算法。1995年,Freund与Schapire提出AdaBoost,通过加权集成多个弱分类器提升性能。同年,Vapnik与Cortes提出支持向量机(SVM),以最大化分类间隔提高精度。Breiman于1996年提出Bagging方法,随后发展为随机森林(Random Forest),有效增强模型鲁棒性并缓解过拟合。
Jerome Friedman于1999年提出梯度提升机(GBM),通过迭代优化残差构建强分类器,广泛应用于金融和预测分析。同年,Google提出PageRank算法,基于随机游走理论评估网页权重,引领了信息检索与大数据分析的突破。
强化学习方面,SARSA算法于2001年提出,强调策略依赖的在线学习;策略梯度方法则通过直接优化期望奖励,适用于连续控制任务。Actor-Critic算法结合了价值估计与策略优化,提升了训练效率与稳定性。Q-learning和策略梯度方法共同推动了强化学习应用于机器人与自动化系统。
在序列建模领域,隐马尔可夫模型(HMM)被广泛用于语音识别与生物信息学 ,而条件随机场(CRF)则通过放宽独立假设提升了自然语言处理中的序列标注能力。2006年提出的极限学习机(ELM)利用固定隐藏层权重,显著提高训练效率,适用于大规模分类与回归。
神经网络领域继续取得进展。1989年,Yann LeCun将反向传播应用于卷积神经网络,成功用于手写识别,开创了深度学习的先河。1998年,索尼推出基于强化学习的娱乐机器人Aibo,展示了人机交互的潜力。1997年,IBM的"深蓝"击败国际象棋冠军卡斯帕罗夫,虽未采用机器学习,但激发了对AI战略博弈的兴趣。
强化学习在博弈中的应用代表为IBM的TD-Gammon,该模型采用时间差分学习(TD)不断优化策略。2006年,Netflix举办Netflix Prize竞赛,推动了协同过滤和推荐算法的发展。2009年,蒙特卡罗树搜索(MCTS) 因其在策略博弈中的出色表现获得关注,并成为后续AlphaGo的重要技术基础。

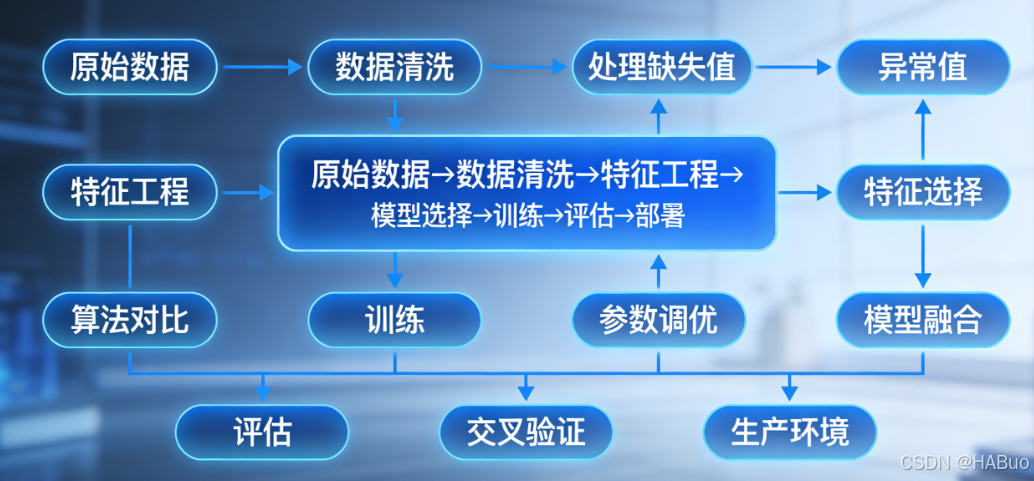
1.4 机器学习工作流程
二、深度学习革命
2.1 深度学习的崛起
核心定义 :机器学习的一个子领域,其灵感来源于人脑的神经网络结构。它使用包含多个层次(因此称为"深度")的神经网络来自动学习数据的多层次抽象特征。
关键特征:
-
层次化特征学习:网络底层学习简单特征(如边缘、角落),高层组合这些简单特征形成复杂概念(如眼睛、轮子)。
-
端到端学习:传统方法需要人工设计和提取特征,而深度学习直接从原始数据(如图像像素、文本)输入,自动输出最终结果。
-
数据驱动,算力要求高:通常需要海量数据和强大的计算资源(如GPU)进行训练。
2.2 神经网络基础
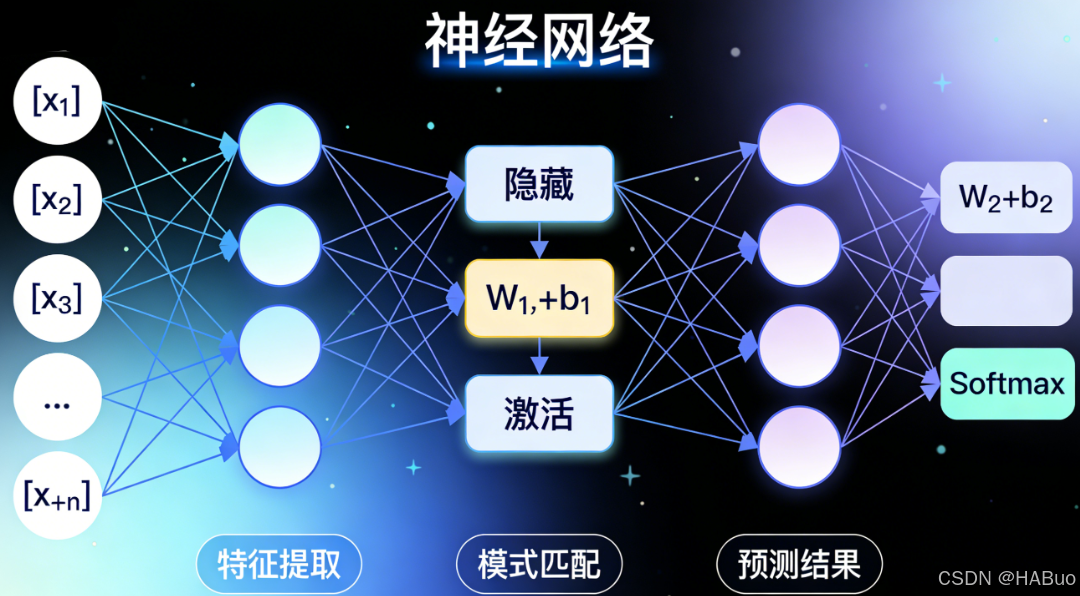
核心组件
-
- 激活函数:ReLU、Sigmoid、Tanh、GELU
-
- 损失函数:MSE、Cross-Entropy、Hinge Loss
-
- 优化器:SGD、Adam、AdamW、RMSprop
-
- 正则化:Dropout、BatchNorm、L1/L2正则化
代表性网络结构:
-
卷积神经网络:专为处理网格状数据(如图像)设计,是计算机视觉的基石。
-
循环神经网络:擅长处理序列数据(如文本、语音、时间序列)。
-
Transformer:当前最主流的架构,通过"自注意力机制"极大地提升了处理长序列数据的效率,是当今大语言模型和许多先进视觉模型的基础。
三、计算机视觉&机器视觉
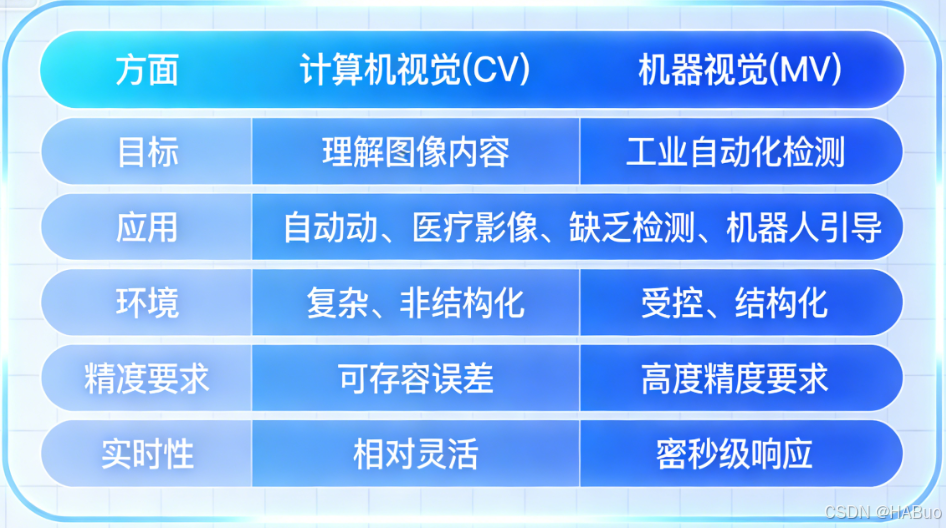
3.1 计算机视觉
计算机视觉核心定义 :一门研究如何让计算机从数字图像或视频中获取高级理解的科学。其终极目标是使计算机能像人类一样"看"懂世界。
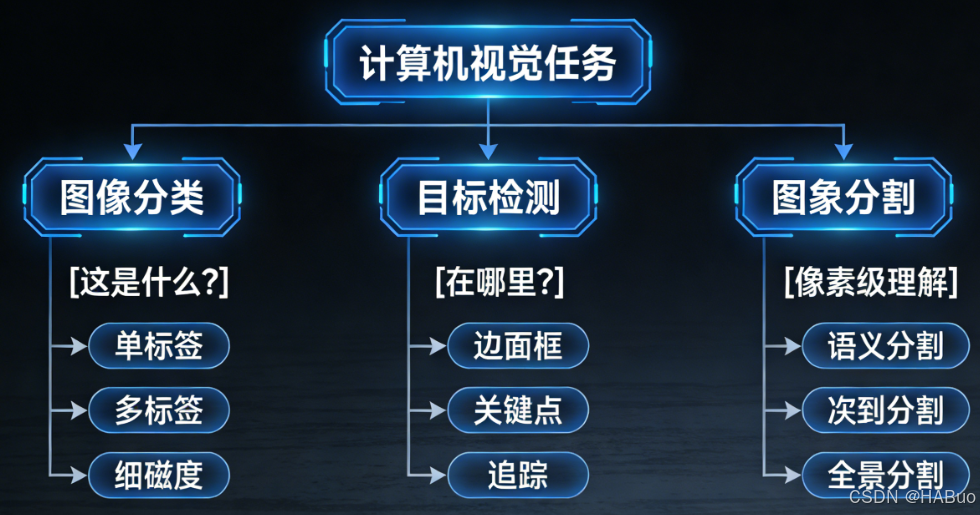
计算机视觉核心任务:
-
图像分类:判断图像中主要是什么物体("这是一只猫")。
-
目标检测:识别图像中有什么物体,并确定它们的位置("这里有一只猫,那里有一只狗")。
-
图像分割:将图像中的每个像素进行分类,勾勒出物体的精确轮廓。
-
图像生成:根据文本描述或草图生成逼真的图像。
-
三维重建:从多张二维图像恢复场景的三维结构。
计算机视觉技术组成:
-
传统图像处理:使用数学和信号处理方法,如滤波、边缘检测、形态学操作(仍广泛用于预处理)。
-
机器学习/深度学习 :目前绝对的主流方法,尤其是CNN和Vision Transformer,用于完成上述所有高级理解任务。
3.2 机器视觉
核心定义 :计算机视觉技术在工业环境中的工程化应用 。它是一个集成了硬件和软件的系统 ,旨在执行具体的、可重复的视觉检测和控制任务,通常与自动化生产线紧密相连。
核心特点:
-
目标导向 :不是为了"理解",而是为了完成一个具体的、可测量的工业任务。
-
强调可靠性和速度:必须在高速生产线上稳定、快速、准确地工作。
-
系统集成 :不仅包括软件算法,还包括光学相机、工业镜头、专用光源、传感器、机械臂等硬件。
-
受控环境:光照、物体位置、背景等通常经过精心设计,以简化视觉任务。
典型任务:
-
外观检测:检测产品表面的划痕、污渍、裂纹。
-
尺寸测量:零件的长、宽、孔径是否符合公差。
-
OCR读取:读取产品上的生产日期、批号、条形码/二维码。
-
引导与定位:引导机械臂准确抓取和放置零件。
3.3 核心辨析
3.4 核心任务
3.5 技术栈演进
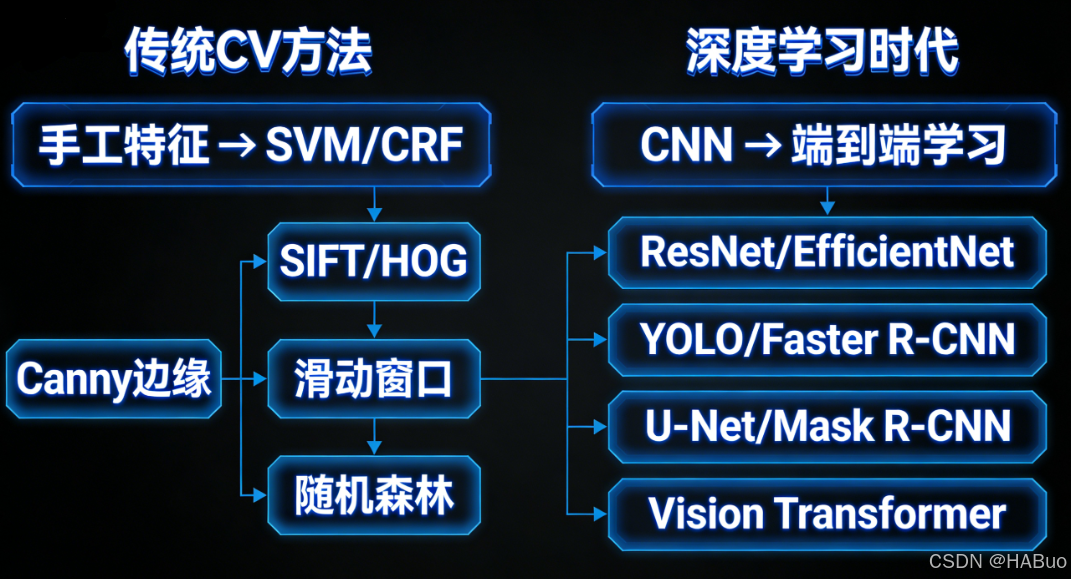
四、总结
| 特征维度 | 机器学习 | 深度学习 | 计算机视觉 | 机器视觉 |
|---|---|---|---|---|
| 本质 | 方法论/工具集 | 一种先进的ML技术 | 学科/应用领域 | 工业工程系统 |
| 核心目标 | 从数据中学习通用规律并预测 | 自动学习数据的深层特征表示 | 让计算机"看懂"图像内容 | 用视觉完成具体的工业任务 |
| 关键输入 | 各类结构化/非结构化数据 | 海量原始数据(图、文、音) | 数字图像/视频 | 工业相机采集的图像+触发信号 |
| 主要方法 | 决策树、SVM、贝叶斯等 | CNN、RNN、Transformer等 | 深度学习为主,传统图像处理为辅 | 集成CV解决方案,强调稳定与速度 |
| 输出结果 | 预测值、分类标签、聚类分组 | 复杂的特征、生成的内容 | 对图像内容的理解(标签、框、掩码) | 通过/失败信号、测量值、坐标指令 |
| 场景比喻 | "学会解题方法" | "拥有深度思考能力" | "研究如何看懂图画" | "流水线上的质检员" |
简单关系链 :
深度学习 (强大的方法) → 极大地推动了 计算机视觉 (研究领域) 的发展 → 其技术被应用于构建 机器视觉 系统 (解决工业问题),而它们都属于 机器学习 这一实现人工智能的广阔方法论范畴。