近期行业爆出 NVIDIA 与 AI 芯片初创企业 Groq 达成了一项重磅 技术许可与人才招募协议。虽然市场上有传闻称 NVIDIA 以约 200 亿美元收购 Groq,但官方声明显示,这并不是一次传统意义上的公司并购;Groq 将继续作为独立实体运营,而 NVIDIA 则通过非排他性许可协议获得 Groq 的关键技术产权,并将包括创始人 Jonathan Ross 在内的多位核心工程师纳入麾下。

这样的结构在技术圈常被称为 "逆向 acqui-hire"(reverse acqui-hire):一方面获得核心 IP 与人才,另一方面又尽可能规避传统收购所面临的反垄断审查风险。
在 AI 硬件领域,NVIDIA 长期以 GPU 为主力,在大规模训练计算上几乎形成了行业基准。随着推理(Inference)计算需求的爆发增长,市场也出现了越来越多依赖更低延迟、更高能效的专用架构追赶者,而 Groq 正是其中的代表之一,其 LPU(Language Processing Unit) 便是为推理任务优化的定制 ASIC 设计。
什么是 LPU?它为何引发关注?
目前,英伟达靠Rubin CPX主攻大上下文推理(预填充与通用推理),谷歌则以TPU主打能效优势,但在"解码"环节,市场选择仍十分有限。解码是Transformer模型推理中的token生成阶段,现已成为AI工作负载分类的关键维度,其核心诉求是确定性与低延迟------而HBM在推理场景中存在延迟高、功耗大的短板,Groq的独特解法是采用SRAM(静态随机存取存储器),这也正是LPU(低功耗推理单元)的核心价值所在。
LPU的核心竞争力源于两大设计:一是确定性执行,二是将片上SRAM作为主要权重存储介质,通过可预测性实现高速推理。
Groq此前推出的GroqChip与GroqCard两款核心产品,搭载230MB片上SRAM,内存带宽高达80TB/s。相比HBM,SRAM无需承受DRAM访问延迟与内存控制器排队耗时,延迟优势极为显著,同时单位比特访问能耗更低,还能省去PHY开销,在内存密集型的解码场景中能效比突出。另一大优势是确定性周期调度:通过编译时调度消除内核间的时间波动,让解码流水线利用率接近饱和,吞吐量远超主流加速器。
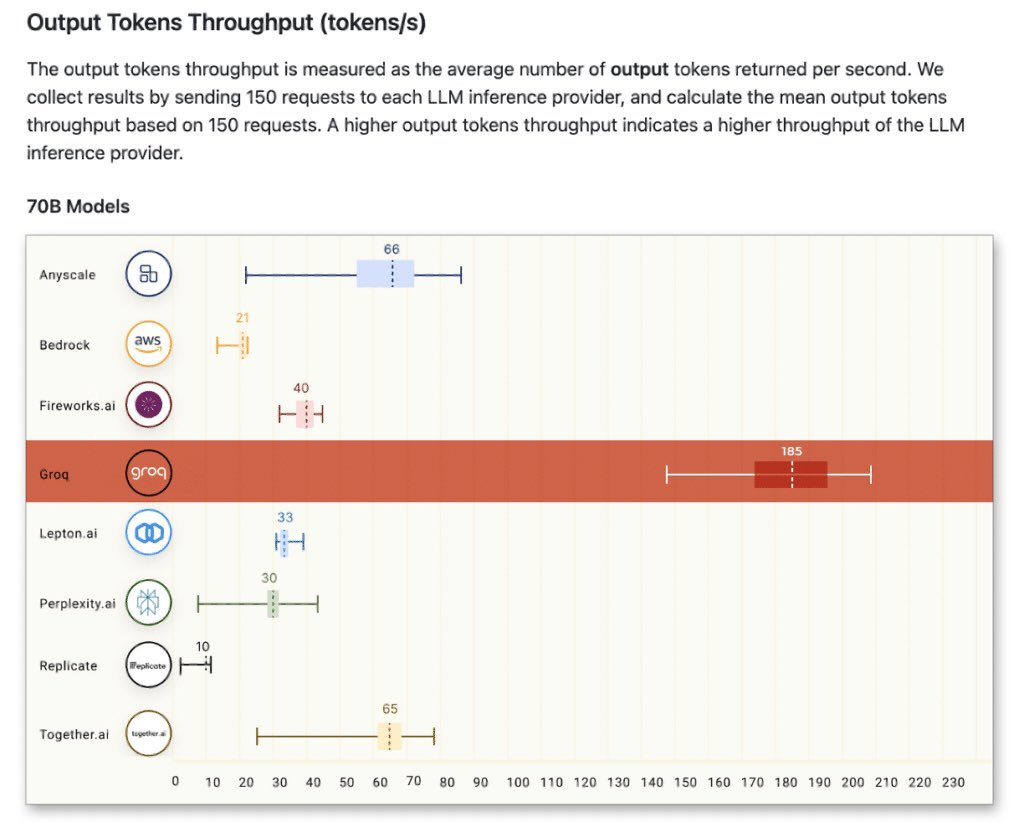
综上,LPU完全贴合超大规模厂商的推理需求,但存在一个行业忽视的局限:虽性能扎实,却因高度专用化尚未成为主流选择------而这正是英伟达的切入点。
Feynman GPU 与 LPU 的可能整合:类似 AMD X3D 的堆叠思路
最新传闻进一步指出,NVIDIA 正在为 下一代 GPU 架构(代号 Feynman) 做更大胆的规划:Groq 的 LPU 单元预计将在 2028 年前集成到 Feynman GPU 中。

专家 AGF 认为,英伟达的实现方案或将借鉴 AMD X3D CPU 的设计思路 ------ 采用台积电 SoIC 混合键合技术,将带 3D 垂直缓存的芯片块集成至主计算芯片。他指出,Feynman GPU 不宜采用单片式集成 SRAM:一方面 SRAM 的制程缩放存在瓶颈,另一方面在先进节点上集成 SRAM 会浪费高端硅片资源,大幅提升单位晶圆面积的使用成本,因此更优选择是将 LPU 单元堆叠在 Feynman 主计算芯片上。

这一方案具备合理性:Feynman 主芯片将采用 1.6nm A16 工艺,集成张量单元、控制逻辑等计算模块;独立的 LPU 芯片则搭载大容量 SRAM 阵列。台积电的混合键合技术是关键互联保障,相比封装外内存,它能实现更宽接口、更低单位比特能耗;加之 A16 工艺支持背面供电,芯片正面可预留充足空间用于 SRAM 垂直互联,确保低延迟解码响应。
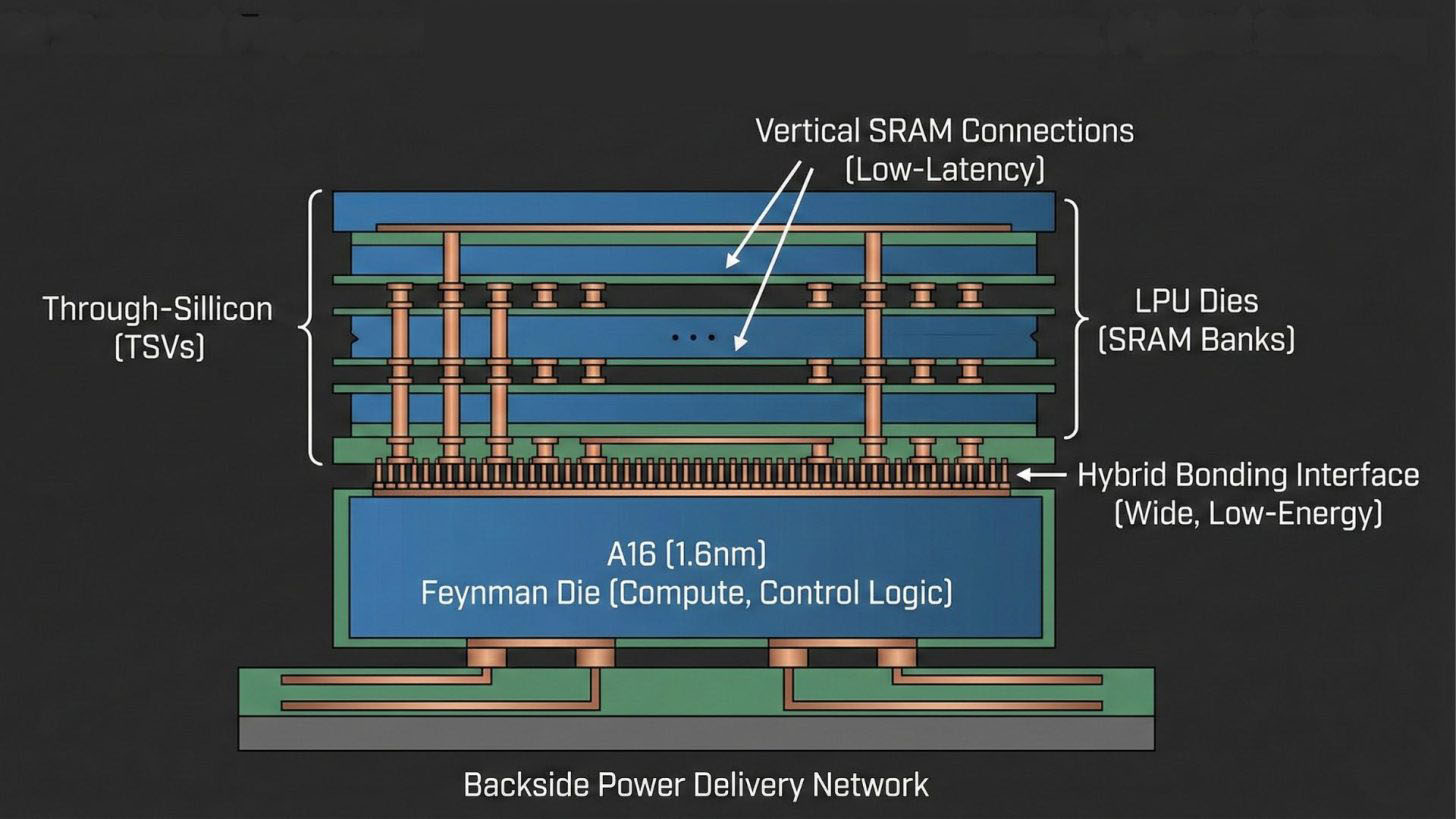
但该方案仍面临多重挑战:首先是散热难题,高算力密度的主芯片叠加需持续高吞吐的 LPU,堆叠设计会加剧散热压力,可能引发性能瓶颈;其次是执行层面的冲突,LPU 采用固定执行顺序,与 GPU 追求的灵活性存在本质矛盾;即便解决了硬件层面的问题,核心痛点仍在软件适配 ------LPU 需要显式内存分配,而 CUDA 内核的设计逻辑是硬件抽象化,二者兼容需极高的工程优化水平。

为什么这件事值得关注?
相比大规模训练阶段的高吞吐计算需求,推理阶段更强调低延迟与能效比。对于像 ChatGPT 这样的实时服务,推理成本与体验直接关联最终的商业回报。LPUs 在这类场景下的优化优势,正是 NVIDIA 所看重的竞争点。

通过与 Groq 的合作与技术吸纳,NVIDIA 有望将自身从传统 GPU 供应商向 混合推理/训练硬件平台提供者 转型,在 AI 基础设施竞争中建立更高壁垒。
如果 LPU 能被集成进入主流 GPU 平台,可能对其他竞争者(如 Google TPU、AMD MI 系列)构成新的压力,同时也可能催生更多异构协同计算的创新。
总结
这次 NVIDIA 与 Groq 的联动,表面看是许可与人才引入,实际上有可能在未来几年内对 AI 推理架构产生深远影响。从 Groq 的 LPU 技术,到传闻中的 2028 年版 Feynman GPU 堆叠式集成计划,这一战略布局显示出 NVIDIA 在 AI 硬件赛道上的新思路:不是简单的收购之战,而是架构和战略上的深度融合。
未来几年,随着推理负载不断增长与 AI 应用场景延伸,这种"GPU + LPU"的混合架构是否会成为行业新标准,也值得我们持续关注。