导读:
随着信用卡交易的普及,欺诈检测已成为银行风险控制的核心挑战。该问题的关键在于欺诈交易仅占极低比例,导致数据高度不平衡,使得传统分类模型严重失效。为此,本文提出一种基于数据重构与阈值自适应的不平衡分类模型。本研究以Kaggle信用卡欺诈数据集为对象,首先通过特征选择与样本平衡技术进行数据重构,从源头优化数据质量与分布。进而,在逻辑回归模型基础上,突破默认0.5阈值的限制,引入阈值自适应调整机制,系统优化分类决策边界。结果表明,本方法有效解决了类别不平衡带来的预测偏差。其中,"数据重构"显著提升了模型对欺诈交易的识别能力,而"阈值自适应"则在召回率与误报率之间实现了基于业务需求的最优平衡。二者协同,共同构成了一个高效、实用的欺诈检测解决方案,为金融风控领域的类似问题提供了重要的方法论参考与实践价值。
作者信息:
孙 娜, 刘政永:河北金融学院河北省金融科技应用重点实验室,河北 保定
论文详情
研究思路
实现研究目标,本文设计并实施了一个以数据重构和阈值自适应为核心的研究路线------第一步数据探索与基准建立;第二步数据重构与特征工程;第三步模型优化与阈值自适应。
本文研究数据来源于Kaggle的Credit Card Fraud Detection竞赛项目,案例数据可在官网(https://www.kaggle.com/)上下载数据。
建模过程
1. 第一阶段数据探索与基准模型构建
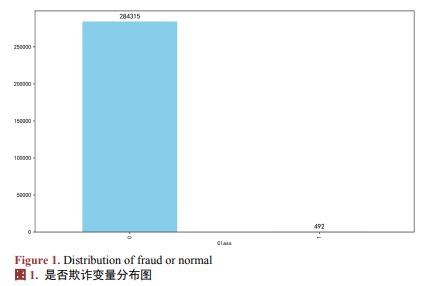
本研究采用Kaggle平台提供的"Credit Card Fraud Detection"数据集,共计284,807条交易记录,其中欺诈交易仅492笔,占比0.172%,呈现出典型的高度不平衡分布。数据集中除"Time"与"Amount"为原始特征外,其余V1~V28变量均为经主成分分析(PCA)处理后的降维结果,以保护用户隐私。
首先通过做类别变量作分布图(见图1),对是否欺诈分布的统计分析发现,欺诈与非欺诈样本数量差异显著,呈现极端不平衡现象。
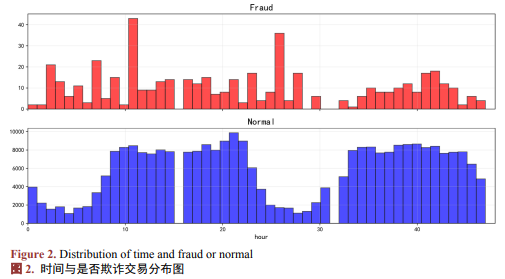
将Time变量单位改成小时,作欺诈交易和正常交易的时间分布图(见图2),由图2知,正常交易呈现明显的周期性波动,而欺诈交易未表现出显著的时间规律。
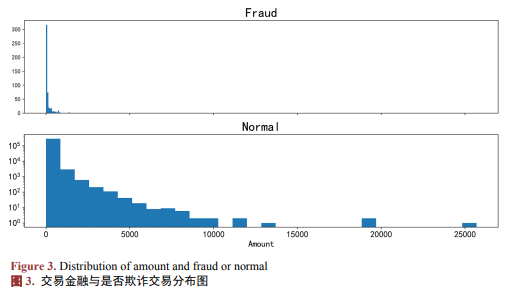
最后,对变量Amount与是否为欺诈交易关系进行可视化分析。作欺诈交易和正常交易的金额分布图(见图3),由图3可知,欺诈交易多集中于小额交易,交易金额(Amount)在区分欺诈行为上的判别能力有限。
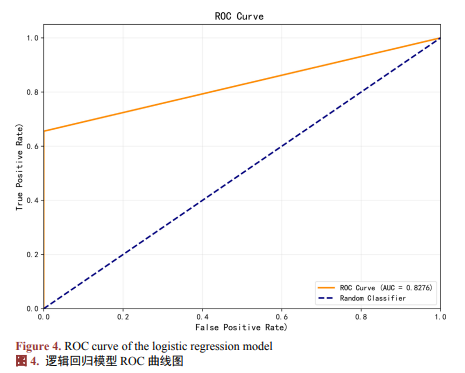
采用逻辑回归模型作为基准模型,将全部特征纳入建模过程,作逻辑回归模型ROC曲线(见图4)。
由图4知,模型在测试集上准确率很高(0.9992),但由于数据不平衡,模型对欺诈样本的识别能力(即召回率)较差(0.8276)。这一结果明确了不进行数据重构与阈值调整的模型在业务中的局限性,为后续核心工作的展开提供了明确方向。
2. 第二阶段:特征工程与不平衡数据处理
前面我们在简单数据分析的基础上,建立模型进行预测,但也存在一些问题,需要我们精益数据。主要问题是(1) 我们只对金额、时间等变量进行探索分析,没有分析V1~V28变量与是否欺诈之间的关系,都纳入模型,容易过拟合。(2) 本项目中欺诈与正常数据严重不平衡,上面建立的模型预测精度高并不能说明模型好。举个例子,我们拿到有1000条病人的数据集,其中990人为健康,10个有癌症,我们要通过建模找出这10个癌症病人,如果一个模型预测到了全部健康的990人,而10个病人一个都没找到,此时其正确率仍然有99%,但这个模型是无用的,并没有达到我们寻找病人的目的。因此,本阶段从特征和样本两个层面重塑训练数据,为模型提供高质量的学习基础。
为提升模型泛化能力并缓解过拟合,采用分布重叠分析(图5)、Lasso回归(图6)、随机森林模型(图7)三种方法进行特征筛选。
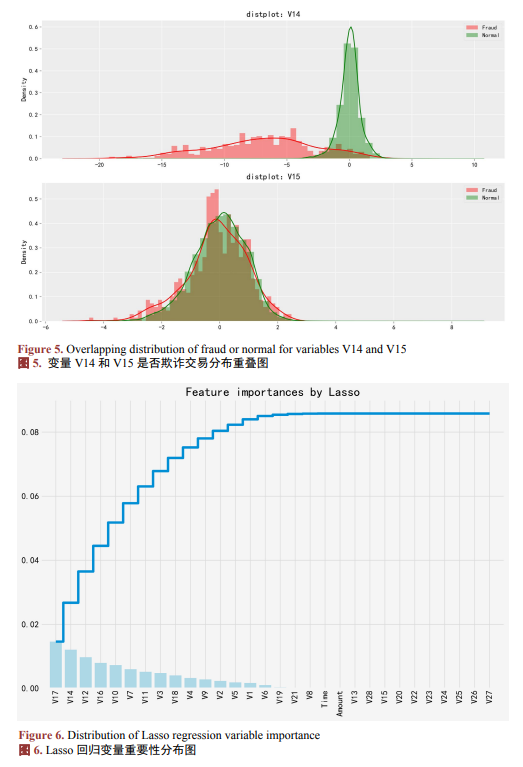
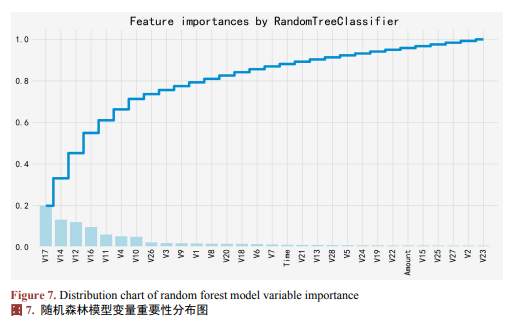
为从根本上改善模型对少数类的识别能力,本研究实施了样本分布的重构。为缓解类别不平衡对模型性能的影响,一般采用以下两种采样策略:(1) 下采样(Undersampling),从多数类中随机抽取与少数类等量的样本,构建平衡训练集;(2) 过采样(Oversampling),采用SMOTE算法对少数类样本进行合成扩充,使其与多数类样本数量一致。
3. 第三阶段:模型优化与阈值调优
本阶段在数据重构的基础上,聚焦于模型决策过程的优化,其核心是引入"阈值自适应"机制,以将模型输出的概率转化为更契合业务需求的分类结果。具体详见原文链接。
结论
本研究围绕数据重构与阈值自适应两大核心策略,对高度不平衡的信用卡欺诈数据进行了系统建模,得出以下结论:(1) 数据重构是提升模型判别能力的基石。通过特征选择与SMOTE过采样相结合的数据重构策略,有效解决了特征冗余与样本不平衡的双重问题,为模型学习提供了高质量的数据基础,显著提升了对欺诈交易的召回率。(2) 阈值自适应是优化模型业务价值的关键。突破固定阈值的限制,采用自适应阈值调整机制,使模型能够在高召回率与低误报率之间取得基于业务需求的最优平衡,证明了其在决策层面的强大灵活性。(3) 协同作用驱动模型性能飞跃。本研究验证了"数据重构"与"阈值自适应"的协同效应。数据重构从底层提升了模型的判别能力,而阈值自适应则从决策层面将这种能力转化为实际的业务价值,二者共同构成了一个完整且高效的不平衡分类解决方案。
基金项目:
2025年度河北省金融科技应用重点实验室课题(2025006)
原文链接: