强化学习入门指南:从零开始的智能决策之旅
强化学习作为人工智能领域最激动人心的分支之一,正以其独特的决策能力改变着我们对智能系统的认知。如果你对如何让机器学会自主决策充满好奇,那么踏上强化学习的学习之旅将是一段充满挑战与收获的经历。
理解强化学习的基本框架
强化学习的核心思想简洁而深刻:智能体通过与环境互动学习最优行为策略。想象一下教小狗做游戏的过程------当它做出正确动作时给予奖励,错误时则没有奖励甚至会有轻微惩罚。经过反复尝试,小狗逐渐明白哪些行为能带来更多奖励。强化学习算法正是模拟这一过程,但以数学和计算的形式实现。
这个框架包含几个基本要素:智能体(做出决策的主体)、环境(智能体交互的外部世界)、状态(环境的当前情况)、动作(智能体可执行的操作)、奖励(环境对动作的反馈)以及策略(智能体选择动作的规则)。理解这些要素及其相互关系是入门的第一步。
循序渐进的学习路径
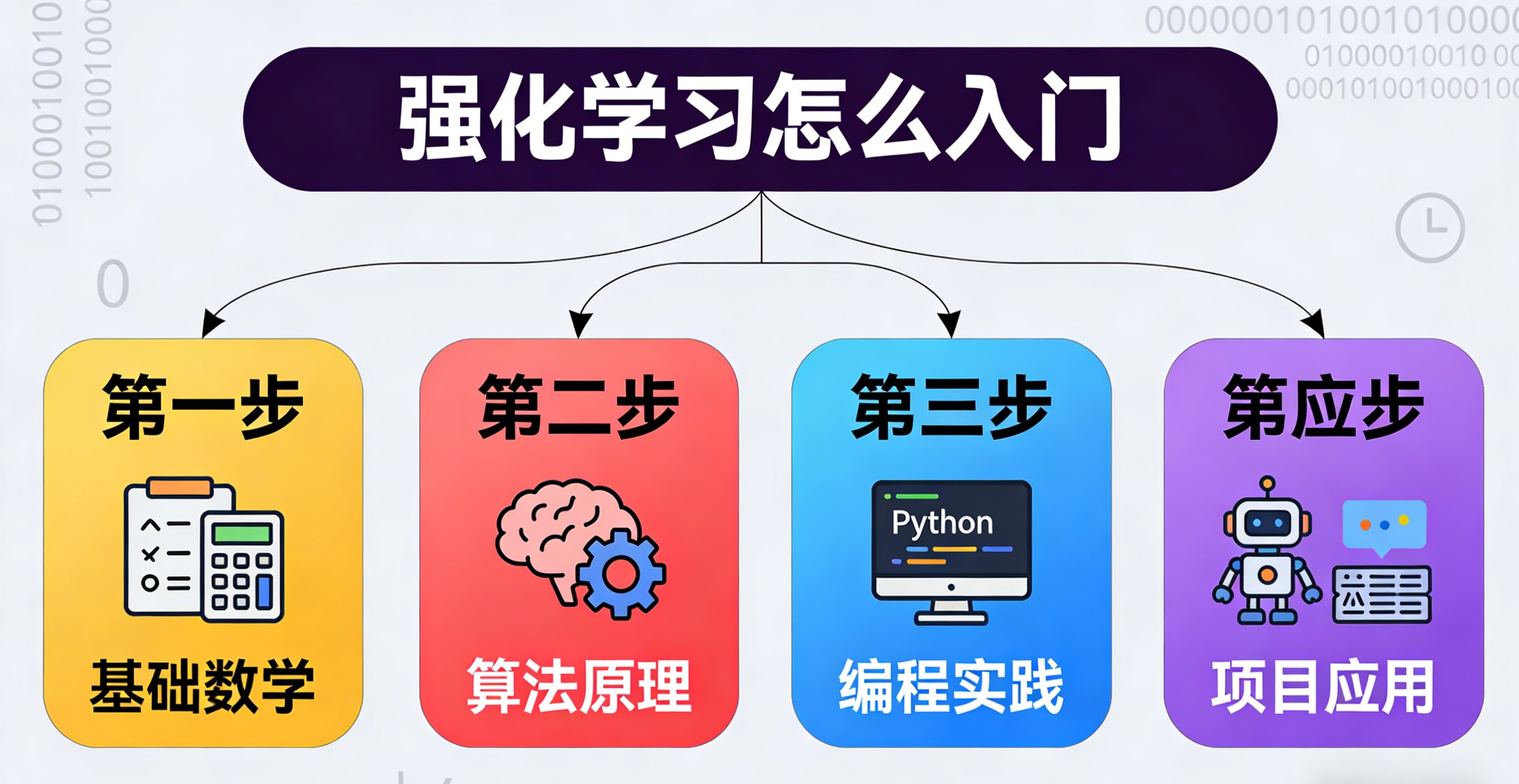
第一阶段:奠定数学与编程基础
强化学习建立在概率论、线性代数和微积分之上,特别是期望值、矩阵运算和梯度下降等概念。同时,Python编程能力必不可少,建议熟练掌握NumPy、Pandas等科学计算库。这一阶段不需要深入钻研每个数学细节,但需要理解基本概念及其在强化学习中的应用方式。
第二阶段:掌握经典算法
从简单的多臂老虎机问题开始,你可以直观理解探索与利用的平衡这一核心问题。接着学习马尔可夫决策过程,这是大多数强化学习问题的理论框架。然后循序渐进地研究时序差分学习、Q学习、深度Q网络等经典算法。每个算法最好通过小型项目实践,例如使用OpenAI Gym提供的简单环境进行测试。
第三阶段:深入现代方法
掌握基础后,可以进一步学习策略梯度方法、演员-评论家架构以及近年的先进算法如近端策略优化。同时理解强化学习中的关键挑战:信用分配问题、稀疏奖励问题以及安全探索等实际考虑因素。
实践:学习过程中不可或缺的一环
强化学习是高度实践导向的领域。建议从以下步骤开始:
-
搭建开发环境,安装Python及相关库(如TensorFlow或PyTorch、Gym)
-
尝试现成的代码示例,先运行再理解
-
从修改简单参数开始,逐步尝试自己实现经典算法
-
参与在线竞赛或解决实际问题,如控制仿真机器人、游戏AI等
初学者常犯的错误是过早陷入理论细节而忽视实践。最佳的学习方式是理论学习和代码实现交替进行,每一部分新学到的理论知识都应尝试用代码表达出来。
优质学习资源推荐
对于初学者,Richard Sutton的《强化学习导论》是不可多得的经典教材,其在线版本免费开放。David Silver的强化学习课程视频结合了清晰的讲解与直观的示例。此外,OpenAI提供的Spinning Up项目专门为学习者设计了系统的实践路径。中文社区中也有不少优质博客和教程,适合初次接触时快速建立直观理解。
学习过程中,积极参与开源项目和社区讨论至关重要。GitHub上有大量强化学习项目可供参考,从他人的代码中学习是最快的进步方式之一。遇到问题时,不要犹豫在相关论坛或社群中提问,强化学习社区通常乐于助人。
保持耐心与好奇心
强化学习入门之路可能充满挫折------算法调试困难、训练过程不稳定、结果复现挑战等。这些困难正是学习过程的一部分。重要的是保持耐心,从每个小进展中获得成就感,并对智能体如何逐步学会复杂行为保持孩童般的好奇。
强化学习不仅是一门技术,更是一种理解学习和决策本质的窗口。随着学习的深入,你可能会发现这些概念不仅适用于机器,也启发我们反思人类自身的学习过程。现在,打开你的编辑器,从第一个"Hello, RL"程序开始这段精彩的旅程吧。智能决策的世界正等待你的探索,每一步代码、每一次调试、每一个成功的训练循环,都将使你更接近掌握这门让机器学会"思考"的艺术。
相关学习推荐:强化学习核心技术理论与应用课程