文章目录
- 前置须知:矩阵微积分基础
- 先放结论
- 背景问题
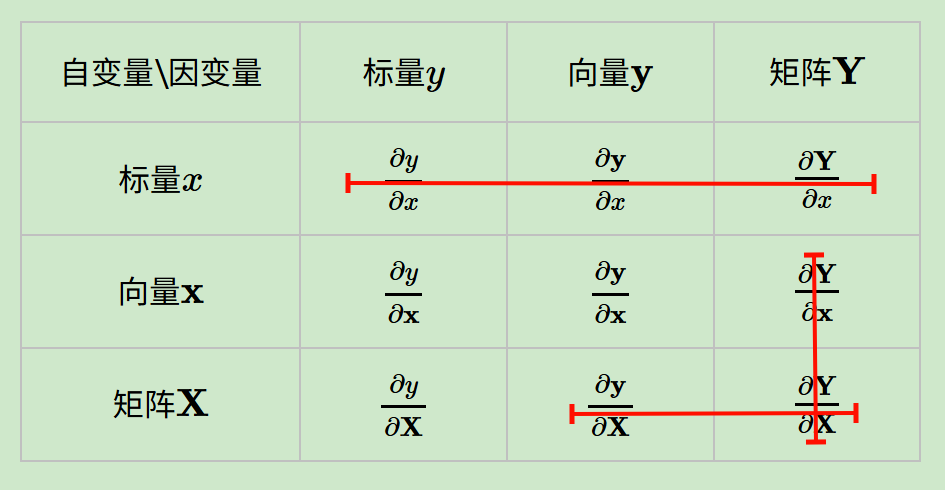
- 机器学习中的矩阵向量求导
-
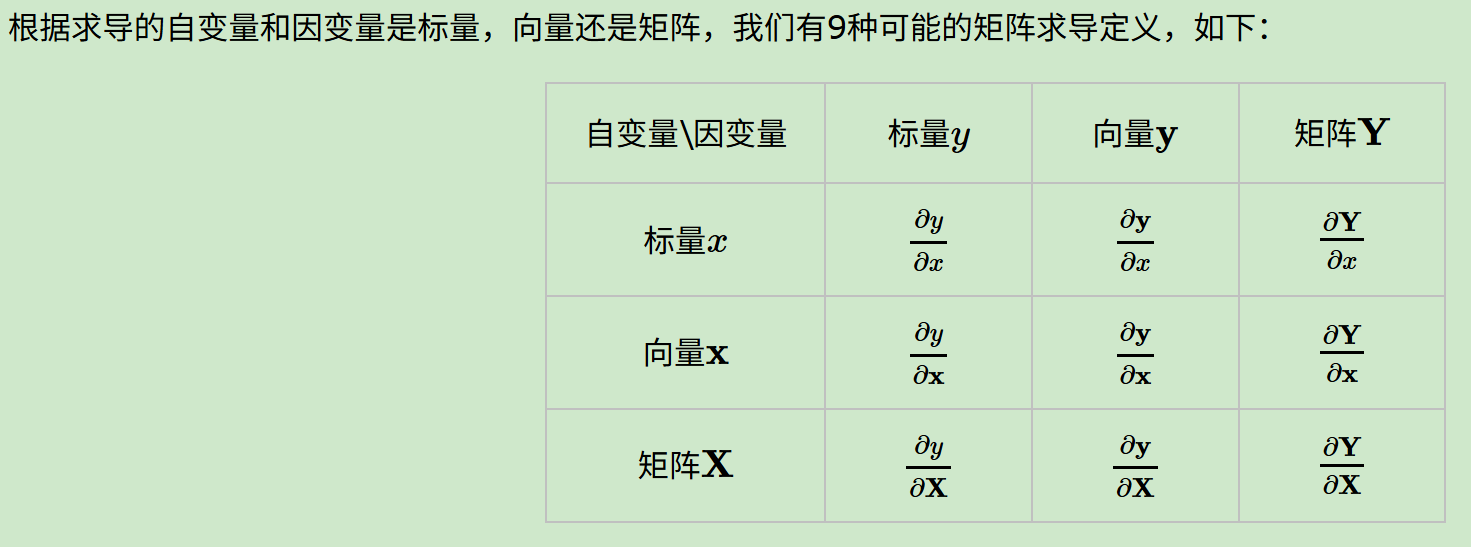
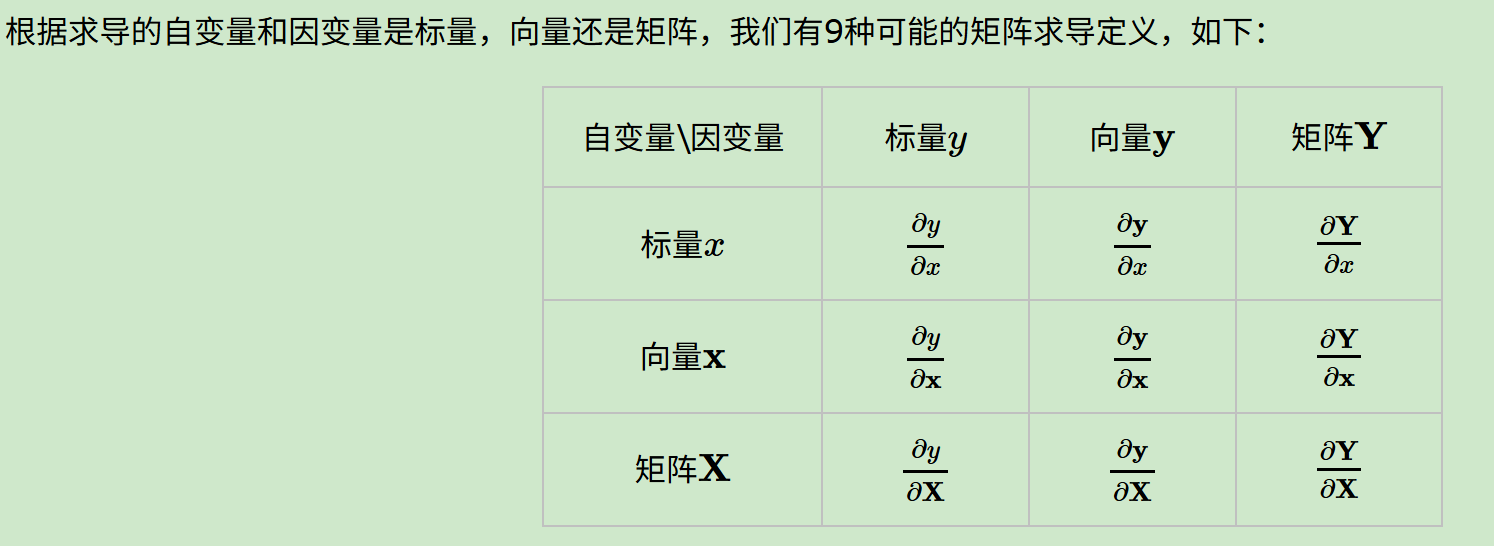
- 9种排列组合
- 求导布局
- 用定义法求解矩阵向量求导
- 用微分法求解矩阵向量求导:引入微分概念
- 矩阵向量求导的链式法则
- 矩阵对矩阵求导
-
- 矩阵对矩阵求导的定义
- 矩阵对矩阵求导的微分法
-
- [1. 先回顾标量对矩阵求导的微分形式](#1. 先回顾标量对矩阵求导的微分形式)
- [2. 推广到矩阵对矩阵求导](#2. 推广到矩阵对矩阵求导)
- [3. 类比标量微分,引入向量化](#3. 类比标量微分,引入向量化)
- 完整的推导过程
-
- [1. 先明确标量对矩阵求导的微分公式(基础)](#1. 先明确标量对矩阵求导的微分公式(基础))
- [2. 把矩阵函数拆成标量函数的集合](#2. 把矩阵函数拆成标量函数的集合)
- [3. 用向量化算子 vec ( ⋅ ) \text{vec}(\cdot) vec(⋅) 打包所有标量微分](#3. 用向量化算子 vec ( ⋅ ) \text{vec}(\cdot) vec(⋅) 打包所有标量微分)
- [4. 构造梯度矩阵,得到最终类比结果](#4. 构造梯度矩阵,得到最终类比结果)
- 类比关系的核心对应表
- 回到我们的问题
- 参考
前置须知:矩阵微积分基础
https://en.wikipedia.org/wiki/Matrix_calculus
https://zh.wikipedia.org/wiki/矩阵微积分
先放结论
从标量,到向量,再到矩阵,从微分再到求导。
依据排列组合,在深度学习的矩阵计算背景在,我们遇到的情况会比简单微积分中的标量对标量的运算复杂很多。
以求导为例,依据排列组合A(2,3)=6,我们有向量对标量的求导,标量对向量的求导,向量对向量的求导,向量对矩阵的求导,矩阵对向量的求导,以及矩阵对矩阵的求导等。
有工科本科基础数理知识的人可以简单归纳总结一下,所谓的向量矩阵求导本质上就是多元函数求导,仅仅是把函数的自变量,因变量以及标量求导的结果排列成了向量矩阵的形式,方便表达与计算,更加简洁而已。

背景问题
1个简单的手搓全连接层网络,其中反向传播计算当前层梯度的backward函数
python
def backward(self, dvalues):
"""
Description
-----------
反向传播, 计算当前层的梯度, 更新梯度值用于优化更新参数
Args
-----
dvalues: np.ndarray
下一层(靠近loss层)传递过来的梯度, 损失对当前层输出的偏导, 作为当前层需要计算梯度的起点;
"""
# 计算权重的梯度
self.dweights = np.dot(self.inputs.T, dvalues)
# 计算偏置的梯度
self.dbiases = np.sum(dvalues, axis=0, keepdims=True)
# 计算输入的梯度, 也就是再传到上一层(靠近input)时梯度计算的起点
self.dinputs = np.dot(dvalues, self.weights.T)如何理解这里的权重梯度公式的形式?(注意是理解矩阵的形式)
我们已知的有
python
dvalues(当前层梯度起点) = ∂L(整体loss)/∂out(当前层输出, 也就是下一层输入)
依据链式法则, ∂L/∂W = ∂L/∂out * ∂out/∂W所以很简单有
python
∂L/∂W = dvalues * ∂out/∂W而前向传播数据的时候有
python
out = inputs @ weights + biases所以如何理解形式上的
python
∂L/∂W = dvalues * ∂(inputs @ weights + biases)/∂W ≈ inputs.T * dvalues也就是说如何理解∂out/∂W = inputs.T?
机器学习中的矩阵向量求导
9种排列组合
其中标量对标量的求导,在简单微积分中就有,不用讨论。
而从简单的计算结果理解上,对于涉及到标量的运算,似乎我们很容易理解。
比如说向量对标量的求导,我们可以简单拆分为向量的每一个分量对标量求导的再排列

还是那句话,对于涉及到标量的运算,我们在常识上"似乎"会更容易理解与接受这种结果一点,
为什么是似乎呢?
求导布局
还是前面那个问题,

我们从结果上容易理解与接受这种计算"定义",那么形式呢?
就是这个m维的求导结果排列成的m维向量到底应该是列向量还是行向量?
这个问题的答案是:行向量或者列向量皆可!毕竟我们求导的本质只是把标量求导的结果排列起来,至于是按行排列还是按列排列都是可以的。但是这样也有问题,在我们机器学习算法法优化过程中,如果行向量或者列向量随便写,那么结果就不唯一,乱套了。
为了解决这种形式的问题,我们需要引入求导布局的概念,也就是矩阵微积分中一些符号约定。

参考:https://en.wikipedia.org/wiki/Matrix_calculus#Layout_conventions
最基本的求导布局有两个:分子布局(numerator layout)和分母布局(denominator layout )。

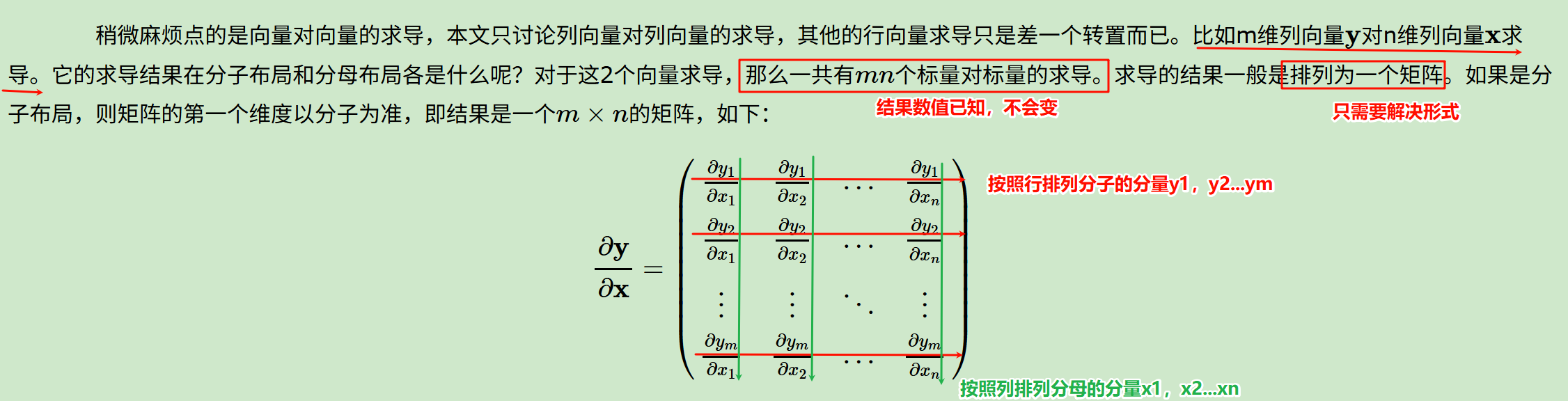
(y的m个元素按行排列,x的n个元素按列排列,也就是mxn矩阵,第i行第j列元素是m维向量y的第i个标量元素对n维向量x的第j个标量元素的导数)。

分子布局,即结果为(分子向量的维度为行数x分母向量的维度为列数)

分母布局,即结果为(分母向量的维度为行数x分子向量的维度为列数)。
结果的数值上其实都是y分量标量对x分量标量的导数,
我们很容易就能够从定义上看出分子布局和分布布局互为转置,
同时也了解分布布局和梯度概念更近。

好,到这里,我们对于涉及到标量的求导运算,从结果上能够接受(结果就是1个1个标量对标量求导,数值是不会变的,变化的是这些数值的排列形式),从形式上我们也清楚大概有两种标记方式(且互为转置)。
并且可以将这些标记方式简单记忆为:
- 分子布局,即结果为(分子向量的维度为行数x分母向量的维度为列数)
- 分母布局,即结果为(分母向量的维度为行数x分子向量的维度为列数)
- 总结就是分子/母布局,则矩阵的第1个维度就以分子/母为准
- 矩阵整体的数值结果是不会变的,就是分子的每个标量对分母的每个标量的求导,只不过结果上我们只知道有分子维度x分母维度个数(mxn=mn),就是只知道有mn个组合之后的数,但是这个mn个数的排列形式,就是用分子还是分母布局
当前前面只是向量总结归纳出来的结论,
我们再稍微规范一下,纳入矩阵,那么完整流程一般是:
- 先分析一下有多少个标量对标量的求导,就是一个组合问题,得到mn个组合数(这mn个组合数的结果是不变的,因为结果的数值是不会变的,都是分子的数值对分母的数值求导)
- 再考虑是分子布局还是分母布局的问题,首先前提是mn要不就是mxn排列,要不就是nxm排列。
- 分子布局:行数看齐分子的维度(或者列数看齐分母的维度)
- 分母布局:行数看齐分母的维度(或者列数看齐分子的维度)
- 哪个好理解从哪个推导入手,反之另外一个布局就是单纯的转置
稍微再回顾一下:
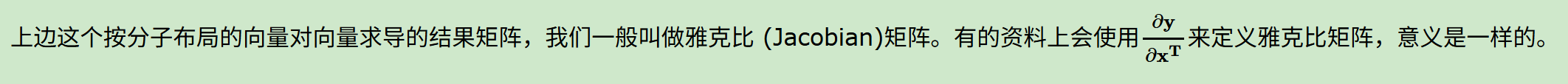
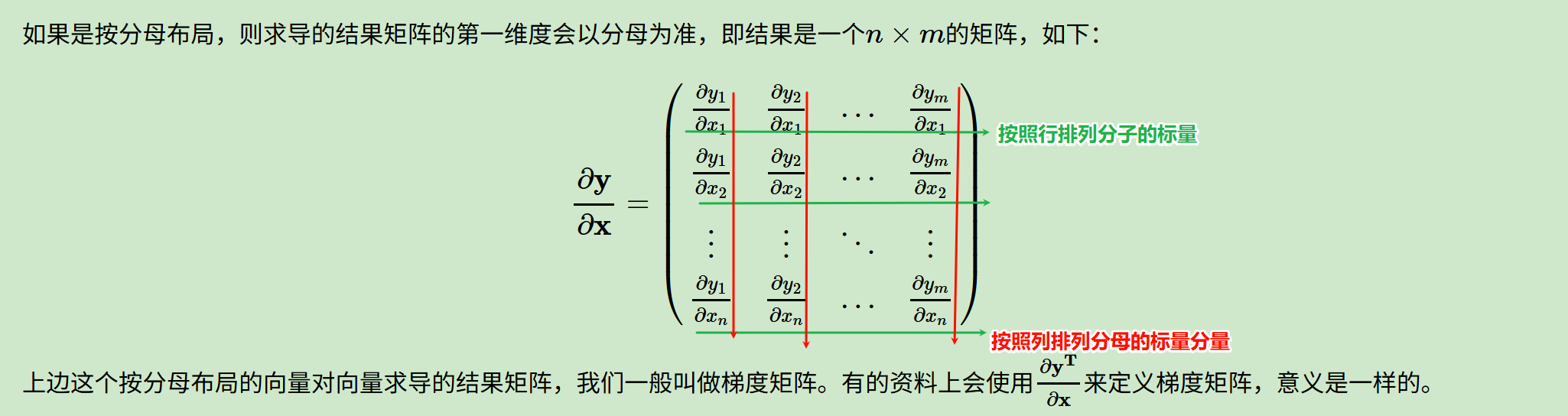
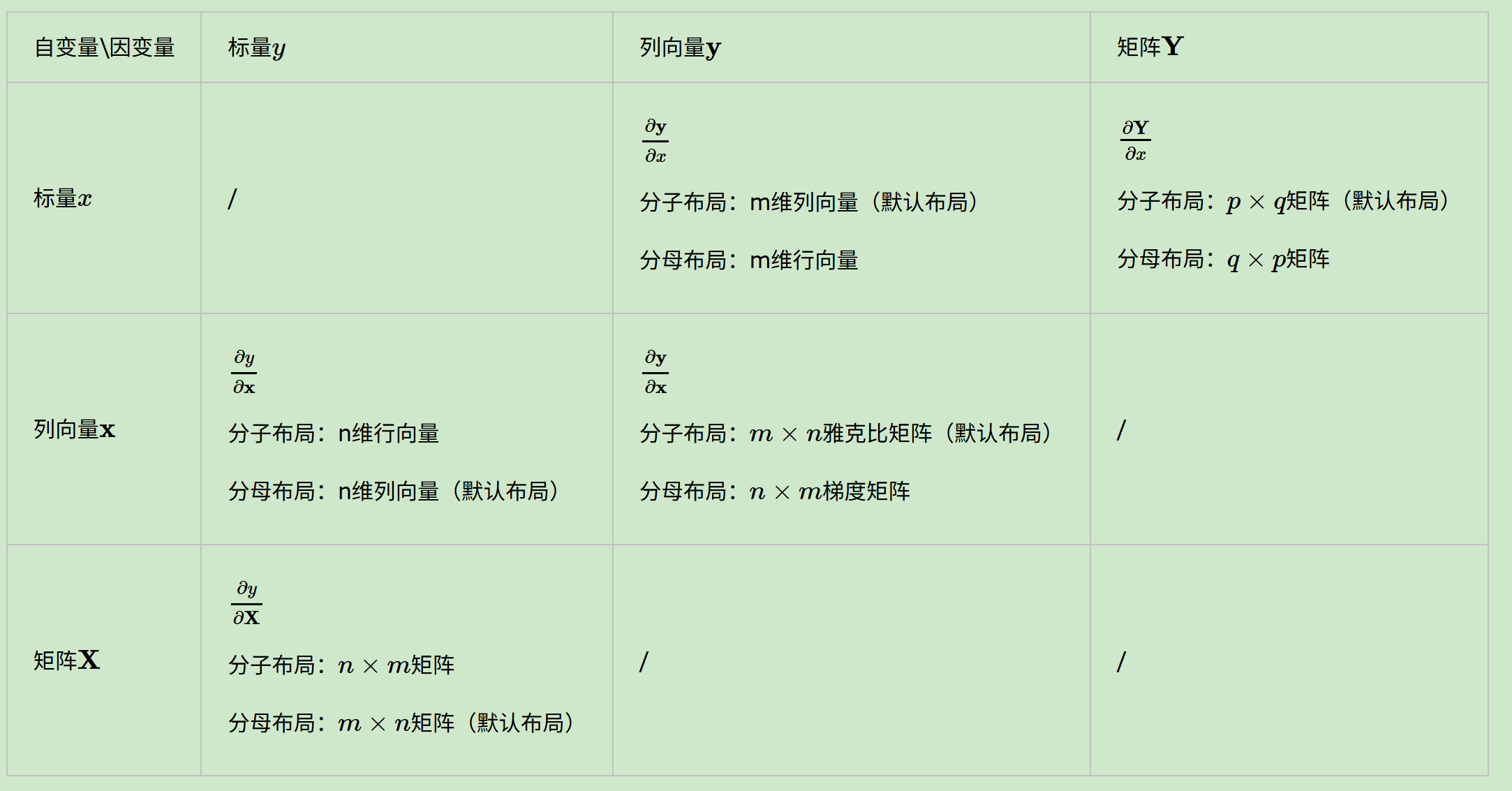
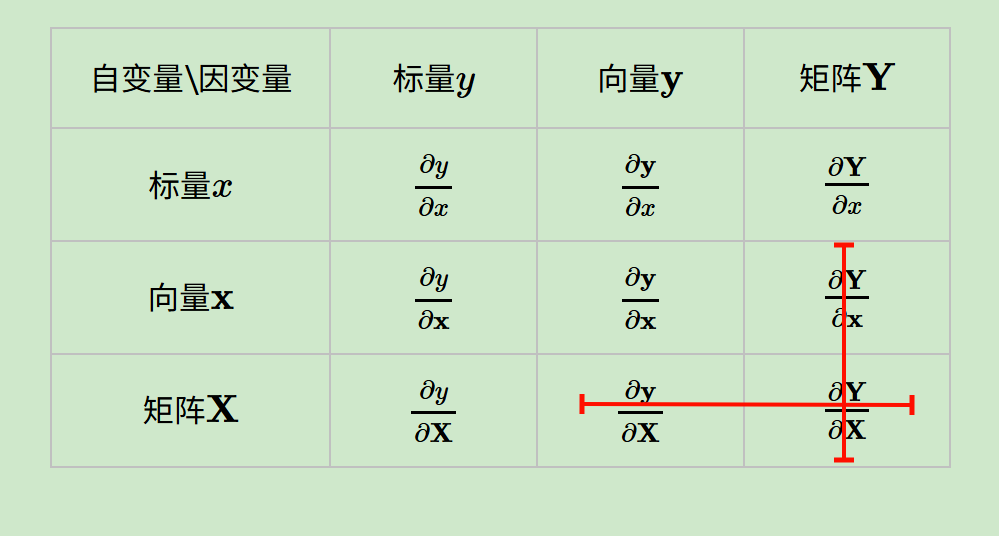
有了布局的概念,我们对于上面6种求导类型(涉及到标量的6种),可以各选择一种布局来求导(当然其实是5种,因为标量对标量不需要考虑布局)。但是对于某一种求导类型,不能同时使用分子布局和分母布局求导。
从转置和梯度概念字眼上,我们貌似离背景问题很近了,这不过就是一个约定俗成的符号习惯?
但是在机器学习算法原理的资料推导里,我们并没有看到说正在使用什么布局,也就是说布局被隐含了,这就需要自己去推演,比较麻烦。但是一般来说我们会使用一种叫混合布局的思路,即如果是向量或者矩阵对标量求导,则使用分子布局为准,如果是标量对向量或者矩阵求导,则以分母布局为准。
这个很容易理解,只要是1个标量 x 1个非标量的运算,我们就倾向于以非标量所在的位置(分子还是分母)去选布局,将其维度作为结果的第1个维度(比如说行数)。
问题在于向量对向量求导,有些分歧(进一步就是矩阵对矩阵、矩阵和向量),因为分子分母写法直觉上都写法都差不多同样可以接受。
参考:https://www.cnblogs.com/pinard/p/10750718.html
用定义法求解矩阵向量求导
前面讲了向量矩阵求导的9种定义与求导布局的概念,下面开始就是计算的细节,也就是代码对应实现应该如何考虑的问题?
我们先来讲一下下面这6种,因为矩阵vs向量+矩阵vs矩阵的比较复杂。

标量对标量不谈,事实上 (对标量求导)这种场景在机器学习中很少见,无论是标量、向量、矩阵对标量求导,所以略。
我们先看一下下面这3种:
用定义法求解标量对向量求导

比如说x是(n,1),n行1列的矩阵,也就是维度为n的列向量。
然后系数矩阵,也就是(n,1)的列向量a,a.T @ x 得到我们的标量结果。

然后从结果角度上看,其实a.T @ x 和 x.T @ a都是两个向量的点积,也就是数值结果是一样的,都是一样的标量,所以同样的一个式子:

下面这个其实就是自己分量和自己分量的点积,也就是范数平方,求导就是2xi


标量对向量求导的一些基本法则
标量对向量求导的一些基本法则,这些法则和标量对标量求导的过程类似;
此处参考导数公式列表:https://zh.wikipedia.org/wiki/导数列表

比如说第一条这里我们可以将分子的标量当成函数值y,分母的向量当做是自变量x,
那么这其实就是一个多元的常值函数,常值函数的导数=0(在标量vs标量求导中很容易理解)
用定义法求解标量对矩阵求导

同理,是求导结果是mxn个标量,排列的话,因为是分母布局,所以还是一个mxn的矩阵。
标量对矩阵求导也有和前面标量对向量求导类似的基本法则。
用定义法求解向量对向量求导

先分析一下结果是nm或mn个标量,我们先看y的第i分量(行)对x的第j分量的求导结果,
而y的第i分量(行)=系数矩阵A的第i行对自变量向量x的内积,yi=Ai @ x
因为这里用的是分子布局,所以结果是A,如果是分母布局,那么用的就是A.T。
定义法矩阵向量求导的局限
使用定义法虽然已经求出一些简单的向量矩阵求导的结果,但是对于复杂的求导式子,则中间运算会很复杂,同时求导出的结果排列也是很头痛的。
用微分法求解矩阵向量求导:引入微分概念
前面讲符合直觉的定义法求解矩阵向量求导的方法,但是这个方法对于比较复杂的求导式子,中间运算会很复杂,同时排列求导出的结果也很麻烦。
下面布局中标量对向量的求导,以及标量对矩阵的求导使用分母布局。
矩阵微分
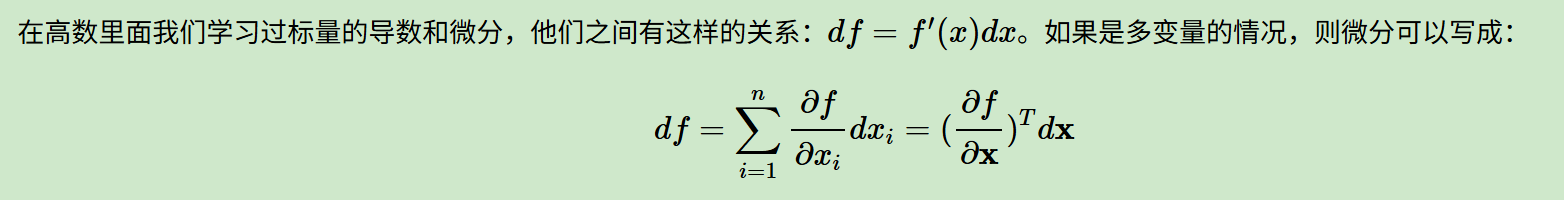
这个式子比较巧妙,首先多元函数f(x1,x2...,xn),我们简单看作是一个标量,
那么df按照我们在高数里面的偏微分拆解来看,其实就是中间那个求和的式子,
既然有分量求和,既然自变量x显然是一个向量,那么我们其实就可以按照前面讲过的将这整个式子写成1个矩阵微积分的形式。
比如说x为1个n维的向量,标量f对向量x的导数按照分母布局法也是一个和x一样的shape的n维向量,
那么这个求和其实就是一个内积,那么写出来就是上面图中第1个式子=第3个式子的形式。

我们可以看到标量微分和向量微分之间是一个标量对向量导数转置的关系。
如果推广到矩阵的话,就是对于矩阵中每一个分量(比如说第i行第j列元素)进行求导,所以一共有mn个标量。

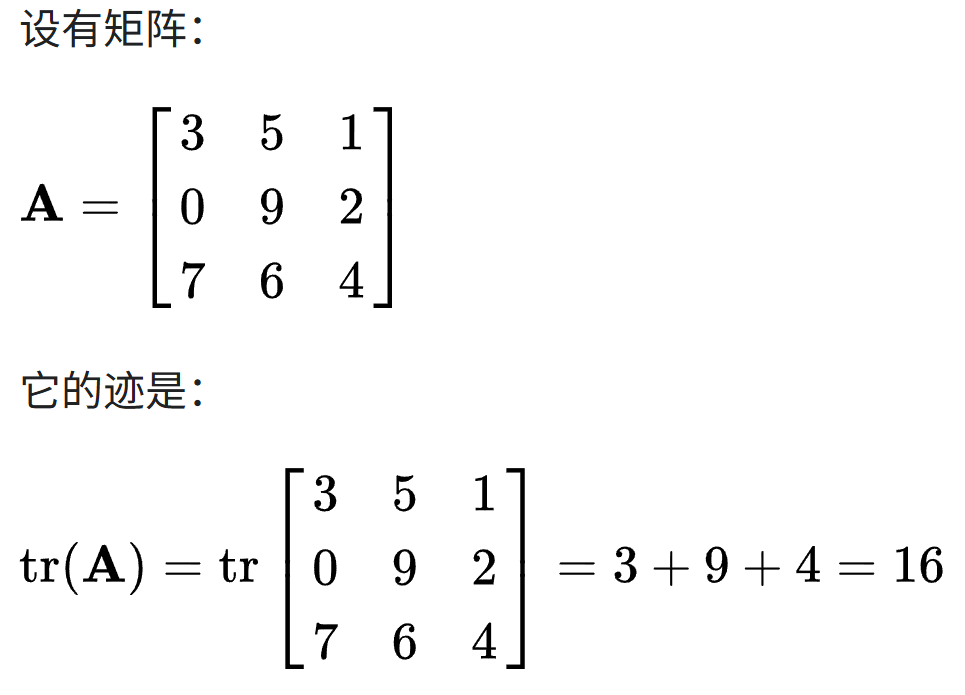
插播:矩阵的迹trace
下面公式推导中需要用到矩阵的迹trace概念,回顾请参考:https://zh.wikipedia.org/wiki/跡

迹的一些性质:

迹的一个循环的性质,
对于方阵,主要是方阵乘法满足结合律,对于普通矩阵,只要看AB=BA的迹结果,
在外推的同时,注意abc=(ab)c天然的顺序,
也就是只要某一个循环改变后的乘积依然存在(矩阵乘法存在),那么得到的迹数依然与原来的迹数相同。
简单记忆就是每次只把最后一个(最右边)矩阵移到最左边(如果矩阵乘法依然存在的话),可以快速得到一个可行的循环排列,然后其trace等同

我们下面需要用到一个涉及到转置的trace性质,
比如说C是一个nxm矩阵(就是下面的A.T),B是1个mxn的矩阵,这是普遍的1个情况(因为迹要求是方阵,而矩阵乘法又要求中间维度相等,所以在涉及到迹计算的两个矩阵,基本上都是维度转置的这种情况)

我们可以不看转置,A.T当做是C,那么CB其实就和我们前面看到的AB从推导上没有区别
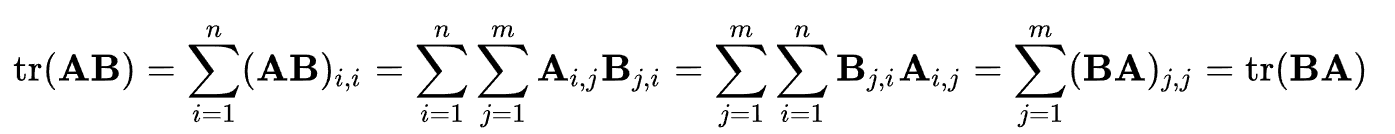
那么
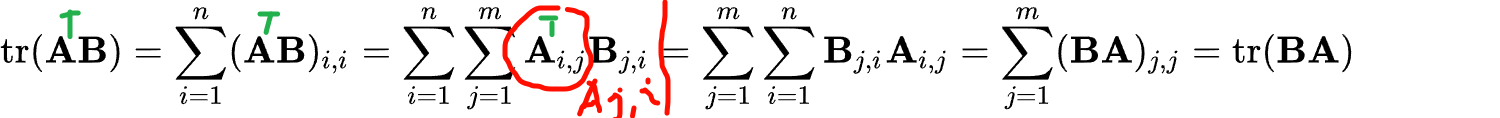
所以实际上就是两个shape一样的矩阵(A、B)逐位置(第i行第j列)元素点积的全累积。
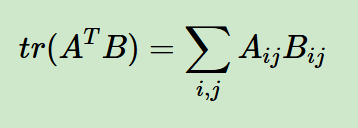
现在回到我们前面标量对于矩阵的微分的公式

以及前面中间科普的trace迹的公式
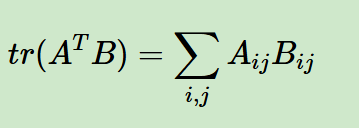
我们就能够得到下面这个公式
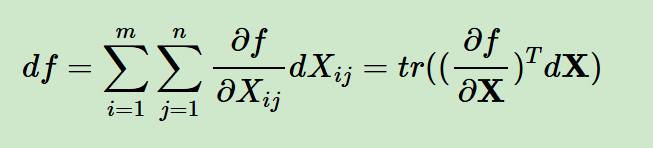
仔细看,能够发现对矩阵的微分和对矩阵的导数也有1个转置的关系
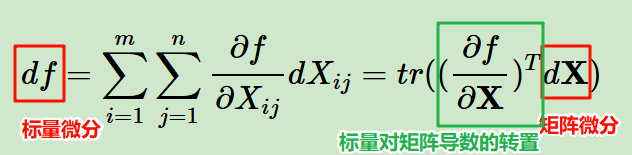
结合前面的向量和这里的矩阵,我们对比起来看:

由于标量的迹函数就是它本身(上面的等式从结果上看其实都是1个标量),那么矩阵微分和向量微分可以统一表示:在外面套了一个迹函数而已,对标量不影响
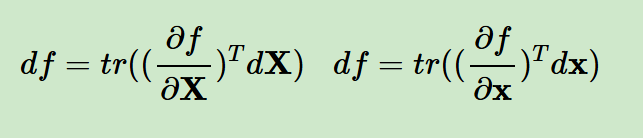
矩阵微分的性质
其中涉及到迹trace的部分,参考:https://en.wikipedia.org/wiki/Trace_(linear_algebra)#Properties
矩阵微分性质的补充,参考:https://en.wikipedia.org/wiki/Matrix_calculus#Derivatives_with_matrices
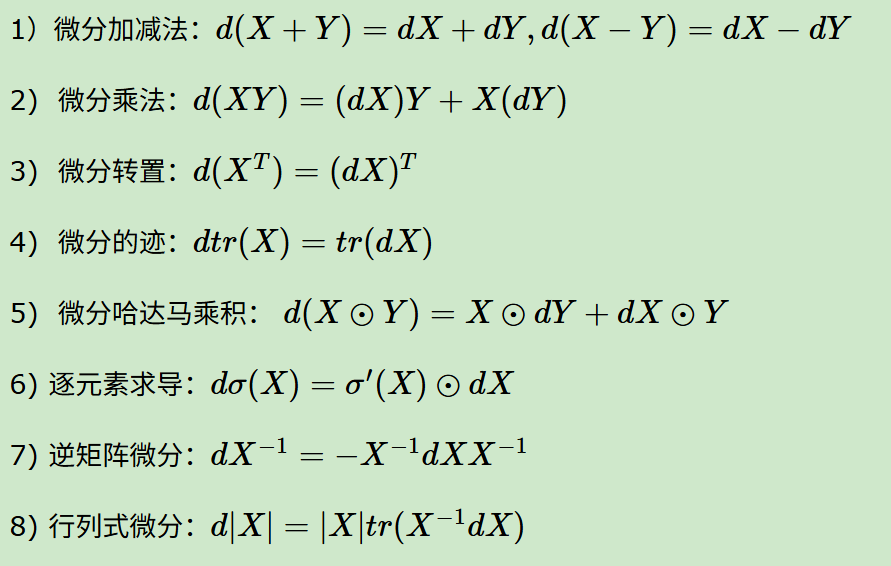
首先就是涉及到矩阵乘法(一般)的不可交换性,顺序写法上要注意点,
也就是第2条性质中,微分乘法的d(X)Y,矩阵微分的乘法顺序核心还是为了保证矩阵维度匹配,写法习惯上都是矩阵乘法,所以不要写成Yd(X)。
其余的,其中哈达马乘积可能会有点陌生,
参考维基百科:https://zh.wikipedia.org/wiki/%E9%98%BF%E9%81%94%E7%91%AA%E4%B9%98%E7%A9%8D_(%E7%9F%A9%E9%99%A3)

实际上就是逐元素(逐位置)乘积,
其一些性质可以手动推一下:

使用微分法求解矩阵向量求导
因为前面我们已经得到了矩阵微分和导数的关系,现在我们可以通过微分间接地去求矩阵的导数。
若标量函数f是矩阵X经加减乘法、逆、行列式、逐元素函数等运算构成,则使用相应的运算法则对f求微分,再使用迹函数技巧给df套上迹并将其它项交换至dX左侧,那么对于迹函数里面在dX左边的部分,我们只需要加一个转置就可以得到导数了。
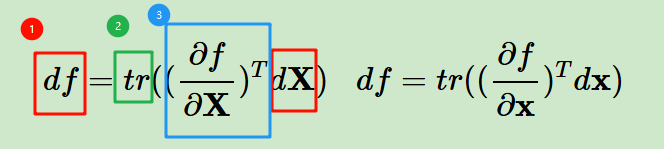
简单来说:
- 先拿到标量f和矩阵X的微分,也就是df、dX------》先拿到微分等式,dX部分其实很简单,只看和X相关的初等矩阵式,其余都可以简单类比为标量中的系数,也就是微分项=0无贡献
- 再给微分等式做迹trace变换(标量df的迹还是标量本身)
- 矩阵微分也就是等式右边,我们要对迹trace函数里面的等式进行整理,整理成某一个项*dX形式,也就上图中蓝色框出来的部分,然后这一项(也就是这个蓝框)再做一个转置,我们就拿到了标量对矩阵/向量的导数了
参考:https://www.cnblogs.com/pinard/p/10791506.html
计算中可能会用到的迹函数的一些技巧如下:

其中比较难理解的还是哈达玛乘积的(包含转置的矩阵乘法和迹的交换)这个性质,略证如下:


对于我们要证明的等式,假设A/B/C都是mxn也就是和m行n列的矩阵
左边:
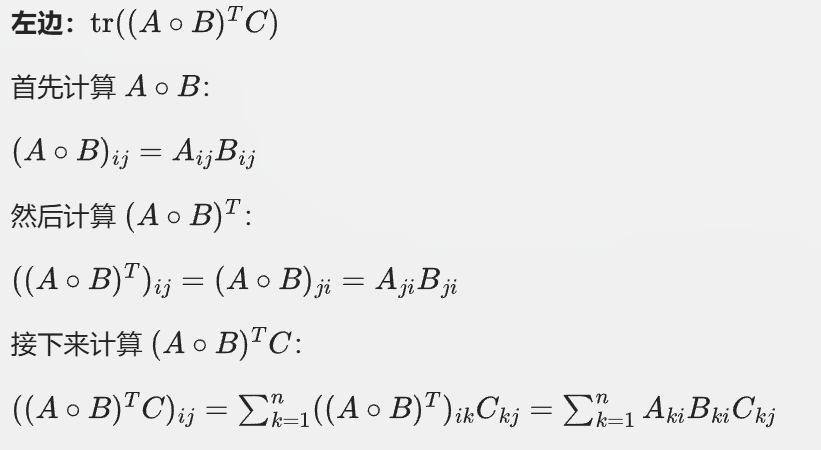
因为迹是取对角线,所以我们看i,i元素(也就是第i行第i列)
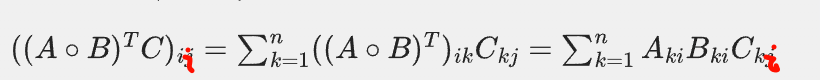
也就是将上面的(矩阵)ii再套1个n层的累积
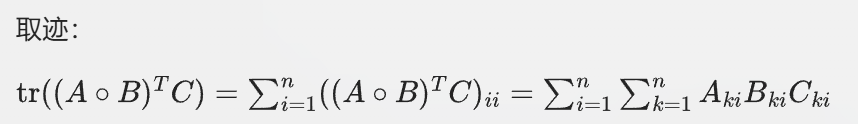
右边:
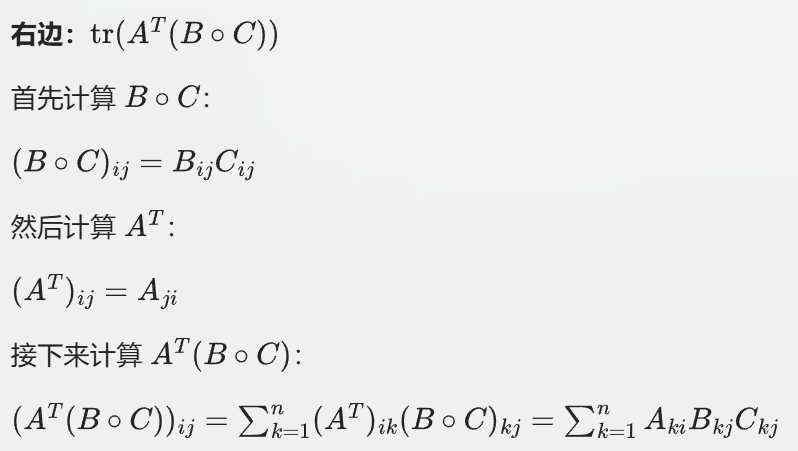
同样看这个结果的第i行第i列
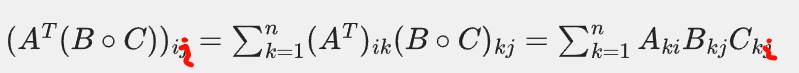
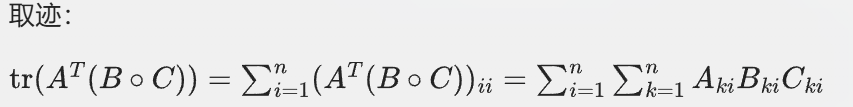
然后我们比较两边,两边的表达式在形式上是相同的,且累和的次数n是一致的,都是矩阵的维度
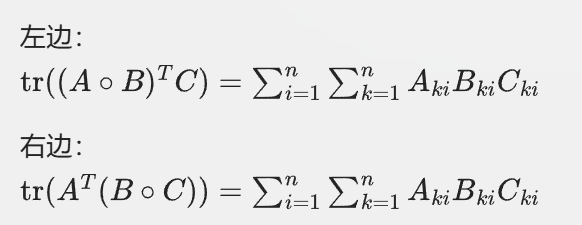
现在还是用前面定义法中用到的求导问题,
注意写法上微分的顺序

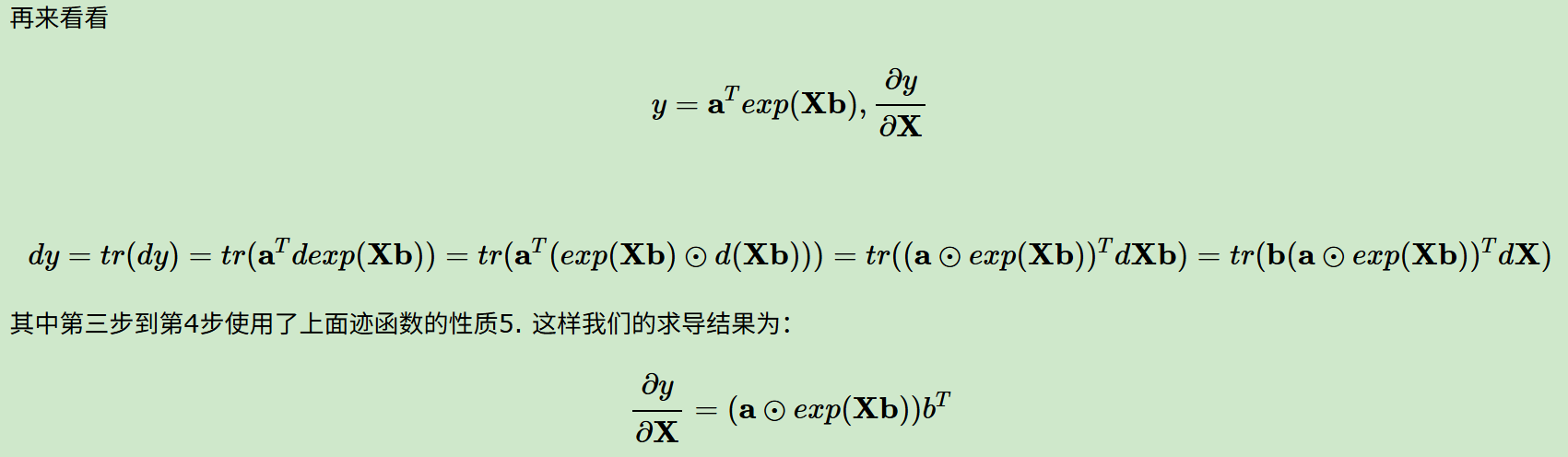
基本上微分法的套路就这些,可以看到,我们可以完全从数学公式的推导中进行一步一步的变换,然后拿到我们的结果,而不需要再1个1个手工复杂计算再反推间接的矩阵表达式了。
迹函数对向量矩阵求导------微分法的另外用途
前面讲到矩阵向量求导的微分法需要用到迹函数的技巧,
那么反过来,在一个有导数、迹函数的微分法等式中,
我们也可以用微分法来求迹函数对于矩阵向量的导数。
首先是下面这两项
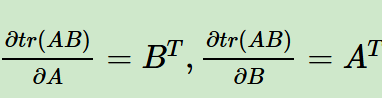
我们可以通过微分法,或者是从定义上(就是拆分分子分母的每一个元素)去证明。
如果是微分法的话,比如说第1个式子,我们就只把A矩阵看作是变量,那么B矩阵其实就是一个常数矩阵,那么我们只关注单变量的话,其实就是dtr(AB)/dA。



当然如果使用定义,也就是直接对矩阵的单个元素求导,再拼接成导数矩阵的话。

同理:
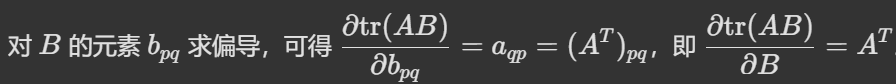

矩阵向量求导的链式法则
前面讲使用微分法来求解矩阵向量求导的方法,但是很多时候,我们求导的自变量和因变量之间直接地有很多复杂的多层链式求导的关系,也就是套了很多层壳。
这个场景其实在深度学习中尤其常见,比如说反向传播梯度的时候,我们要怎么将loss的变化更新到每一层、每一层的上一层直到输入层的参数上,其实这中间就是通过层与层之间的梯度传播,也就是链式法则层层套起来。
那么这个时候如果我们直接用微分法,比如说要直接求loss对第一个中间层的权重或者是偏置等参数的导数,
我们按照前面步骤,会先求微分,但是loss的微分可能会比较难表示;
在微分之后,我们还要取loss微分矩阵的迹,更是难上加难(当然如果第一步loss微分的矩阵形式能够解析表示出来,其实求迹不会太难),总之一般使用起来是会比较麻烦的。
所以我们考虑将标量求导中的链式法则也引入进来做进一步拓展。
向量对向量求导的链式法则
同样的,下面的推导式子中,标量对向量的求导、标量对矩阵的求导使用分母布局, 向量对向量的求导使用分子布局。
参考:https://www.cnblogs.com/pinard/p/10825264.html

向量的链式法则,很容易从矩阵维度上去接受这种结果形式。
标量对多个向量的链式求导法则

出现了,转置的形式!

这里的X是样本矩阵,每一行都是一个样本点,每一列是每一个样本的一个维度,nxn
θ是系数矩阵,列向量,nx1
y是每一个样本点的label,也是列向量nx1
l是所有样本点loss的总和,是1个1x1的标量,其实这里应该取1个均值,更符合我们最小二乘法中MSE的形式,但是问题不大。

这里接一点经典机器学习中线性回归的部分,

最优参数有两种情况:
 ,这个公式应该在很多的机器学习书中都非常常见了,我们正常的逻辑思维就是一些都代数解析化,然后用公式一路推推推,会更符合数学直觉点
,这个公式应该在很多的机器学习书中都非常常见了,我们正常的逻辑思维就是一些都代数解析化,然后用公式一路推推推,会更符合数学直觉点

标量对多个矩阵的链式求导法则


这个背景其实眼尖的人能够一下子就看出,如果X是输入,那么Y就是对输入做一个简单的权重以及偏置运算,然后z就是在激活函数之后的输出,所以z对X的求导其实可以看作是一个简单的全链接、前馈神经网络的输出对于输入的导数。


其中转置部分就是一个简单的变换
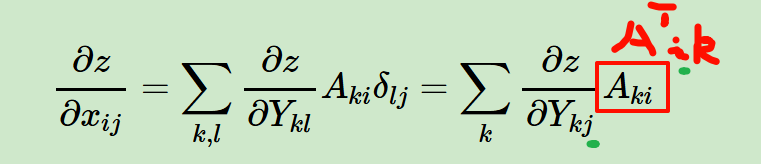

其实到这一步,就已经能够解决我们前面背景中提出的问题了,
我们背景中的问题是:

其实就是一个标量对矩阵求导的问题,
然后这个标量对于矩阵的导数,其实就是
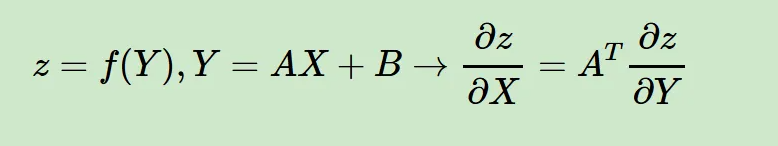
loss=z,out=Y,weights=X,inputs=A
总的来说,矩阵向量求导在前面我们讨论三种方法,定义法,微分法和链式求导法。在同等情况下,优先考虑链式求导法,尤其是第三节的四个结论。其次选择微分法、在没有好的求导方法的时候使用定义法是最后的保底方案。
矩阵对矩阵求导
矩阵对矩阵求导的定义

这两种定义虽然没有什么问题,但是很难用于实际的求导,比如说前面提到的微分法。

其实这里的向量化我们可以理解为展开,也就是numpy中的flatten操作。
矩阵对矩阵求导的微分法

矩阵对矩阵求导的定义,是对标量对矩阵求导的直接推广,核心是把"单个标量梯度"扩展为"多个标量梯度的集合":
1. 先回顾标量对矩阵求导的微分形式
标量 f f f 对矩阵 X X X 的微分公式:
d f = tr ( ( ∂ f ∂ X ) T d X ) df = \text{tr}\left( \left( \frac{\partial f}{\partial X} \right)^T dX \right) df=tr((∂X∂f)TdX)
这个公式的本质是:标量微分 = 梯度矩阵与微分矩阵的内积(迹的形式)。
- 若 X X X 是 m × n m\times n m×n 矩阵, ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f 也是 m × n m\times n m×n 矩阵,每个元素 ∂ f ∂ X i j \frac{\partial f}{\partial X_{ij}} ∂Xij∂f 就是 f f f 对 X X X 单个元素的偏导。
- 迹 tr ( A T B ) \text{tr}(A^T B) tr(ATB) 刚好等价于矩阵 A A A 和 B B B 的弗罗贝尼乌斯内积,用来把"矩阵元素的偏导×微分元素"的求和,包装成简洁的迹运算。
2. 推广到矩阵对矩阵求导
设 F F F 是 p × q p\times q p×q 矩阵, X X X 是 m × n m\times n m×n 矩阵,矩阵函数 F = F ( X ) F=F(X) F=F(X) 本质是 p q pq pq** 个标量函数的集合**: F k l = F k l ( X ) , k = 1.. p , l = 1.. q F_{kl}=F_{kl}(X),\ k=1..p,\ l=1..q Fkl=Fkl(X), k=1..p, l=1..q。
矩阵对矩阵的导数 ∂ F ∂ X \frac{\partial F}{\partial X} ∂X∂F,定义为以每个标量函数的梯度为块的分块矩阵:
∂ F ∂ X = ( ∂ F 11 ∂ X ∂ F 12 ∂ X ... ∂ F 1 q ∂ X ∂ F 21 ∂ X ∂ F 22 ∂ X ... ∂ F 2 q ∂ X ⋮ ⋮ ⋱ ⋮ ∂ F p 1 ∂ X ∂ F p 2 ∂ X ... ∂ F p q ∂ X ) \frac{\partial F}{\partial X} = \begin{pmatrix} \frac{\partial F_{11}}{\partial X} & \frac{\partial F_{12}}{\partial X} & \dots & \frac{\partial F_{1q}}{\partial X} \\ \frac{\partial F_{21}}{\partial X} & \frac{\partial F_{22}}{\partial X} & \dots & \frac{\partial F_{2q}}{\partial X} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial F_{p1}}{\partial X} & \frac{\partial F_{p2}}{\partial X} & \dots & \frac{\partial F_{pq}}{\partial X} \end{pmatrix} ∂X∂F= ∂X∂F11∂X∂F21⋮∂X∂Fp1∂X∂F12∂X∂F22⋮∂X∂Fp2......⋱...∂X∂F1q∂X∂F2q⋮∂X∂Fpq
每个子块 ∂ F k l ∂ X \frac{\partial F_{kl}}{\partial X} ∂X∂Fkl 都是 m × n m\times n m×n 矩阵(对应标量 F k l F_{kl} Fkl 对 X X X 的梯度)。
3. 类比标量微分,引入向量化
如果直接对每个 F k l F_{kl} Fkl 写标量微分:
d F k l = tr ( ( ∂ F k l ∂ X ) T d X ) dF_{kl} = \text{tr}\left( \left( \frac{\partial F_{kl}}{\partial X} \right)^T dX \right) dFkl=tr((∂X∂Fkl)TdX)
把这 p q pq pq 个式子堆叠起来会非常繁琐。
而向量化算子 vec ( ⋅ ) \text{vec}(\cdot) vec(⋅) 刚好能把矩阵 F F F 和 d F dF dF 都变成 p q × 1 pq\times 1 pq×1 的列向量,把"分块矩阵的梯度"转化为"普通的矩阵-向量乘法",也就是前面给出的形式:
vec ( d F ) = ∂ vec ( F ) ∂ vec ( X ) T ⋅ vec ( d X ) \text{vec}(dF) = \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)^T} \cdot \text{vec}(dX) vec(dF)=∂vec(X)T∂vec(F)⋅vec(dX)
这个类比的核心对应关系可以总结为:
| 标量对矩阵求导 | 矩阵对矩阵求导 |
|---|---|
| 标量 f f f | 矩阵 F F F → 向量化为 vec ( F ) \text{vec}(F) vec(F)(列向量) |
| 微分 d f df df | 微分 d F dF dF → 向量化为 vec ( d F ) \text{vec}(dF) vec(dF)(列向量) |
| 梯度 ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f(矩阵) | 梯度矩阵 ∂ vec ( F ) ∂ vec ( X ) T \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)^T} ∂vec(X)T∂vec(F)( p q × m n pq\times mn pq×mn 矩阵) |
| 内积形式 tr ( A T B ) \text{tr}(A^T B) tr(ATB) | 矩阵-向量乘法 A ⋅ b A \cdot b A⋅b |
完整的推导过程
1. 先明确标量对矩阵求导的微分公式(基础)
设 f f f 是标量函数 , X X X 是 m × n m\times n m×n 矩阵, X i j X_{ij} Xij 是 X X X 的第 i i i 行第 j j j 列元素。
标量微分的定义式为:
d f = ∑ i = 1 m ∑ j = 1 n ∂ f ∂ X i j d X i j df = \sum_{i=1}^m\sum_{j=1}^n \frac{\partial f}{\partial X_{ij}} dX_{ij} df=i=1∑mj=1∑n∂Xij∂fdXij
而迹的性质 告诉我们: ∑ i = 1 m ∑ j = 1 n A i j B i j = tr ( A T B ) \sum_{i=1}^m\sum_{j=1}^n A_{ij} B_{ij} = \text{tr}(A^T B) i=1∑mj=1∑nAijBij=tr(ATB)。
令 A = ∂ f ∂ X A=\frac{\partial f}{\partial X} A=∂X∂f(梯度矩阵,元素是 ∂ f ∂ X i j \frac{\partial f}{\partial X_{ij}} ∂Xij∂f), B = d X B=dX B=dX,代入上式就得到标量对矩阵求导的迹形式微分公式:
d f = tr ( ( ∂ f ∂ X ) T d X ) (1) df = \text{tr}\left( \left( \frac{\partial f}{\partial X} \right)^T dX \right) \tag{1} df=tr((∂X∂f)TdX)(1)
这是我们类比的出发点。
2. 把矩阵函数拆成标量函数的集合
设 F F F 是 p × q p\times q p×q 的矩阵函数 , F = F ( X ) F=F(X) F=F(X),它的每个元素 F k l F_{kl} Fkl( k = 1.. p , l = 1.. q k=1..p,\ l=1..q k=1..p, l=1..q)都是关于 X X X 的标量函数。
对每一个标量元素 F k l F_{kl} Fkl,套用公式 (1) 可以写出:
d F k l = tr ( ( ∂ F k l ∂ X ) T d X ) (2) dF_{kl} = \text{tr}\left( \left( \frac{\partial F_{kl}}{\partial X} \right)^T dX \right) \tag{2} dFkl=tr((∂X∂Fkl)TdX)(2)
这里 ∂ F k l ∂ X \frac{\partial F_{kl}}{\partial X} ∂X∂Fkl 是 m × n m\times n m×n 矩阵,就是标量 F k l F_{kl} Fkl 对 X X X 的梯度。
3. 用向量化算子 vec ( ⋅ ) \text{vec}(\cdot) vec(⋅) 打包所有标量微分
vec ( ⋅ ) \text{vec}(\cdot) vec(⋅) 的作用是按列堆叠矩阵元素 ,比如 F F F 向量化后:
vec ( F ) = ( F 11 F 21 ⋮ F p 1 F 12 ⋮ F p q ) p q × 1 \text{vec}(F) = \begin{pmatrix} F_{11} \\ F_{21} \\ \vdots \\ F_{p1} \\ F_{12} \\ \vdots \\ F_{pq} \end{pmatrix}_{pq \times 1} vec(F)= F11F21⋮Fp1F12⋮Fpq pq×1
对应的微分 vec ( d F ) \text{vec}(dF) vec(dF)就是把所有 d F k l dF_{kl} dFkl 按同样顺序堆叠成 p q × 1 pq\times1 pq×1 列向量。
现在我们要把公式 (2) 的 p q pq pq 个等式,转化为 vec ( d F ) \text{vec}(dF) vec(dF) 与 vec ( d X ) \text{vec}(dX) vec(dX) 的关系,需要用到迹与向量化的桥梁公式:
tr ( A T B ) = vec ( A ) T vec ( B ) (3) \text{tr}(A^T B) = \text{vec}(A)^T \text{vec}(B) \tag{3} tr(ATB)=vec(A)Tvec(B)(3)
把公式 (3) 代入公式 (2),得到:
d F k l = vec ( ∂ F k l ∂ X ) T vec ( d X ) (4) dF_{kl} = \text{vec}\left( \frac{\partial F_{kl}}{\partial X} \right)^T \text{vec}(dX) \tag{4} dFkl=vec(∂X∂Fkl)Tvec(dX)(4)
4. 构造梯度矩阵,得到最终类比结果
把公式 (4) 对应的 p q pq pq 个等式堆叠起来,写成向量乘法形式:
( d F 11 d F 21 ⋮ d F p q ) = ( vec ( ∂ F 11 ∂ X ) T vec ( ∂ F 21 ∂ X ) T ⋮ vec ( ∂ F p q ∂ X ) T ) ⋅ vec ( d X ) \begin{pmatrix} dF_{11} \\ dF_{21} \\ \vdots \\ dF_{pq} \end{pmatrix} =\begin{pmatrix} \text{vec}\left( \frac{\partial F_{11}}{\partial X} \right)^T \\ \text{vec}\left( \frac{\partial F_{21}}{\partial X} \right)^T \\ \vdots \\ \text{vec}\left( \frac{\partial F_{pq}}{\partial X} \right)^T \end{pmatrix} \cdot \text{vec}(dX) dF11dF21⋮dFpq = vec(∂X∂F11)Tvec(∂X∂F21)T⋮vec(∂X∂Fpq)T ⋅vec(dX)
左边就是 vec ( d F ) \text{vec}(dF) vec(dF),右边的大矩阵我们定义为 ∂ vec ( F ) ∂ vec ( X ) T \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)^T} ∂vec(X)T∂vec(F)(维度 p q × m n pq\times mn pq×mn),于是就有:
vec ( d F ) = ∂ vec ( F ) ∂ vec ( X ) T ⋅ vec ( d X ) (5) \text{vec}(dF) = \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)^T} \cdot \text{vec}(dX) \tag{5} vec(dF)=∂vec(X)T∂vec(F)⋅vec(dX)(5)
再结合矩阵对矩阵导数的分块定义 ∂ F ∂ X = ( ∂ vec ( F ) ∂ vec ( X ) ) \frac{\partial F}{\partial X} = \left( \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)} \right) ∂X∂F=(∂vec(X)∂vec(F)),就完成了从标量对矩阵求导到矩阵对矩阵求导的类比推导。
类比关系的核心对应表
| 标量对矩阵求导(公式1) | 矩阵对矩阵求导(公式5) | 类比逻辑 |
|---|---|---|
| d f df df(标量微分) | vec ( d F ) \text{vec}(dF) vec(dF)(向量微分) | 单个标量微分 → 标量微分的向量堆叠 |
| tr ( ⋅ ) \text{tr}(\cdot) tr(⋅)(内积包装) | 矩阵-向量乘法(线性映射) | 迹把元素求和包装 → 梯度矩阵把向量映射包装 |
| ∂ f ∂ X \frac{\partial f}{\partial X} ∂X∂f( m × n m\times n m×n 梯度矩阵) | ∂ vec ( F ) ∂ vec ( X ) T \frac{\partial \text{vec}(F)}{\partial \text{vec}(X)^T} ∂vec(X)T∂vec(F)( p q × m n pq\times mn pq×mn 梯度矩阵) | 单个标量的梯度 → 所有标量梯度的向量化堆叠 |

参考:https://www.cnblogs.com/pinard/p/10930902.html

回到我们的问题
现在再回到我们的问题,
我们的问题现在看起来其实就是一个矩阵对矩阵的求导
我们以输入层来进行演示说明(也可以是其他中间层的输入),
输入数据 X:100 个样本,每个样本 784 个特征 → 形状 (100, 784);
权重 weights:784 个特征 × 10 个神经元 → 形状 (784, 10);------》X @ weights → 形状 (100, 784) @ (784, 10) = (100, 10);
偏置 biases:1 行 × 10 个神经元 → 形状 (1, 10)(全 0 初始化,即 \[0,0,0,...,0])。------》NumPy 的广播机制会自动把 (1,10) 的偏置 "复制扩展" 成 (100,10)
总而言之,out输出是(100, 10),然后权重是(784, 10),也就是一个(100, 10)的矩阵对一个(784, 10)的矩阵求导。
这是只关注局部,也就是out对w求导,
但是整体是loss这个标量对weights求导,是标量对矩阵求导,采用分母布局法。
然后答案我们前面就已经给出了:
我们背景中的问题是:
其实就是一个标量对矩阵求导的问题,
然后这个标量对于矩阵的导数,其实就是
loss=z,out=Y,weights=X,inputs=A
参考
https://zh.wikipedia.org/zh-hans/矩阵微积分
https://en.wikipedia.org/wiki/Matrix_calculus(这个是核心总览)
刘建平Pinard老师的几篇公式推导博客:
https://www.cnblogs.com/pinard/p/10750718.html
https://www.cnblogs.com/pinard/p/10773942.html
https://www.cnblogs.com/pinard/p/10791506.html