论文题目:Active Event-based Stereo Vision(基于活动事件的立体视觉)
会议:CVPR2025
摘要:传统的基于帧的主动立体成像系统在快速运动场景中遇到了重大挑战。然而,如何设计一种高速深度传感的新模式仍然是一个悬而未决的问题。在本文中,我们提出了一种新颖的问题设置,即基于事件的主动立体视觉,它首次提供了将双目事件相机和红外投影仪集成用于高速深度传感的见解。从技术上讲,我们首先构建了一个立体相机原型系统,并呈现了一个具有超过21.5k时空同步标签的真实世界数据集,同时还创建了一个具有立体事件流和23.8k同步标签的真实合成数据集,频率为15 Hz。然后,我们提出了ActiveEventNet,这是一个轻量级但有效的基于活动事件的立体匹配神经网络,它学习从低延迟的立体事件流中生成高质量的密集视差图。实验表明,我们的ActiveEventNet优于最先进的方法,同时显着降低了计算复杂度。与传统立体相机相比,我们的解决方案在高速场景中提供了卓越的深度感测,同时我们的原型也实现了高达150 FPS的推理速度。我们相信这种新模式将为未来的深度传感系统提供新的见解。
我们的项目可以在https://github.com/ jianningli /active_event_based_stereo获得。
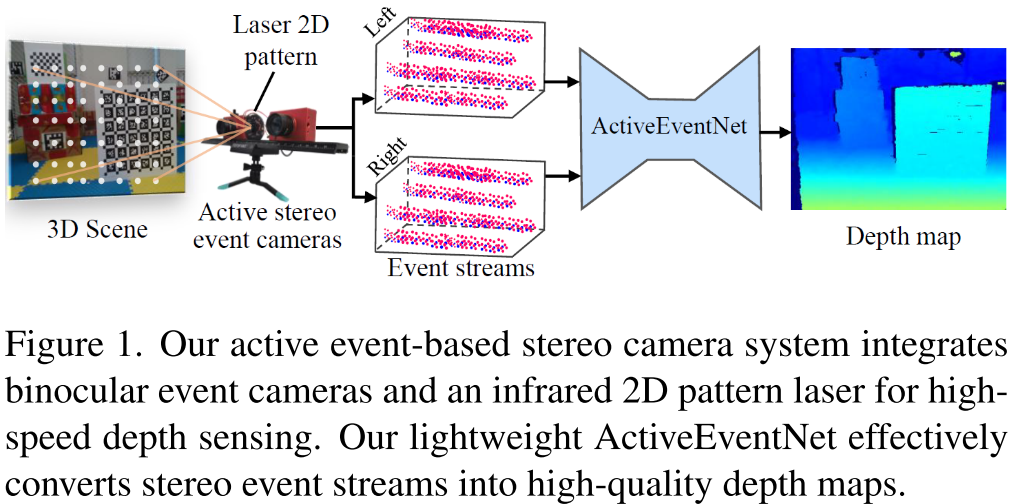
主动事件立体视觉------开启高速深度感知新时代
引言:突破传统视觉的速度瓶颈
想象一下,一架竞速无人机以每秒数十米的速度在复杂环境中飞行。传统相机即使以90 FPS的速度工作,在两帧之间仍然可能发生致命碰撞。这不是科幻场景,而是当前高速机器人面临的真实挑战。清华大学季向阳教授团队在CVPR 2025上发表的这篇论文,为这个问题提供了一个革命性的解决方案:主动事件立体视觉。
什么是事件相机?为什么它适合高速场景?
传统相机 vs 事件相机
传统相机像电影胶片一样,按固定帧率(如30 FPS)捕获完整图像。而事件相机的工作原理完全不同------它模仿人类视网膜,只在像素亮度发生变化时记录事件,具有:
- 微秒级时间分辨率:比传统相机快1000倍以上
- 高动态范围:120dB以上(传统相机约60dB)
- 低延迟:实时响应场景变化
- 低功耗:只记录变化,能耗显著降低
现有方案的困境
尽管事件相机潜力巨大,但现有的事件立体深度系统都是被动式的,面临两大问题:
- 无纹理区域失效:在白墙、天花板等区域无法匹配特征点
- 暗光场景失败:低光照下事件稀疏,深度估计不准确
而单目事件相机+结构光方案虽然能工作,但在远距离和环境光干扰下精度不如双目系统。
核心创新:主动事件立体视觉
1. 系统设计:硬件的完美融合
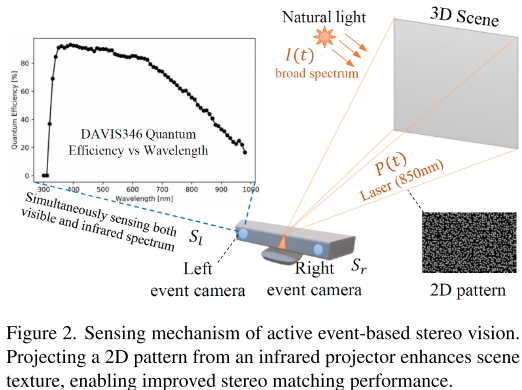
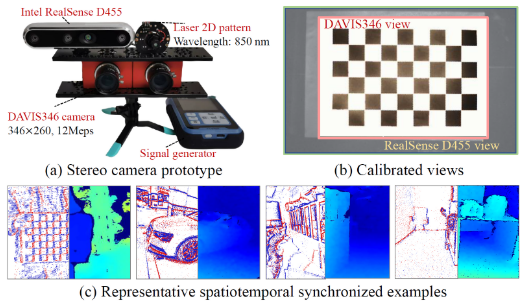
研究团队构建了一个创新的硬件原型:
┌─────────────────────────────────────┐
│ 红外2D模式投影仪 (850nm) │
└─────────────────┬───────────────────┘
│ 投影增强纹理
┌─────────┴─────────┐
│ │
┌────▼────┐ ┌───▼─────┐
│ DAVIS346│ │ DAVIS346│
│ (左相机) │ │ (右相机) │
└─────────┘ └─────────┘
双目事件相机工作原理:
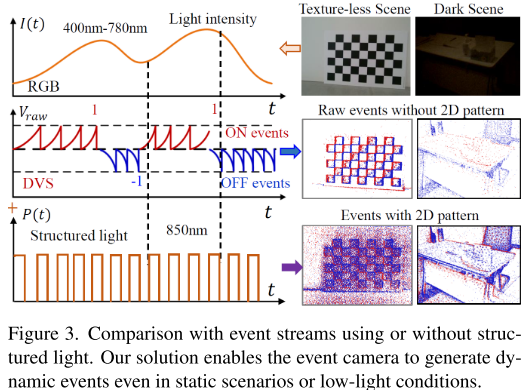
- 850nm红外激光投影2D模式到场景
- 事件相机芯片对300-1000nm光谱敏感,能同时捕获自然光和激光
- 即使在完全静态或极暗场景,通过调整激光频率也能产生事件流
2. 数据集:填补领域空白
团队构建了两个高质量数据集:
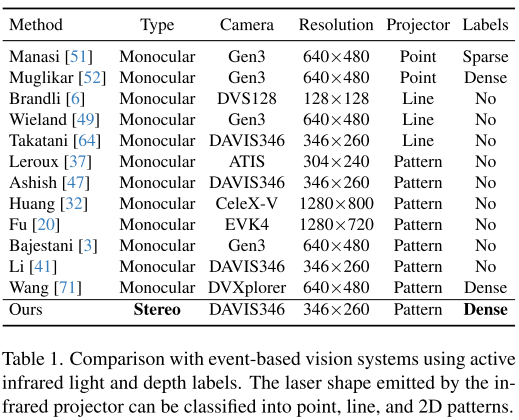
Active-Event-Stereo(真实数据):
- 85个序列,涵盖室内外、日夜、快慢速度等场景
- 21.5k个15Hz同步深度真值
- 专业时空校准,确保标签精度
RealSense-Event-Sim(合成数据):
- 119个红外视频序列,用V2E模拟器转换
- 23.8k个20Hz标签
- 高度逼真,节省大量标注成本
3. 算法:轻量级却不失精度
ActiveEventNet架构
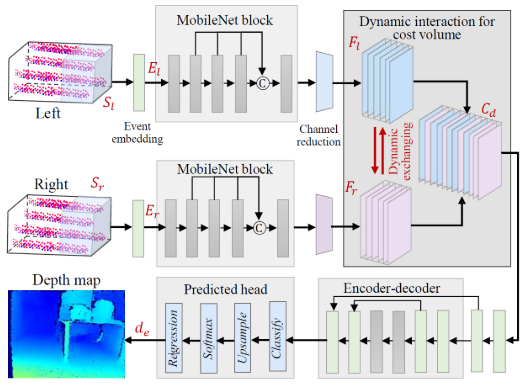
事件流 → 时间分箱 → 事件张量表示
↓
MobileNet特征提取
↓
动态交互代价体
↓
轻量级编码器-解码器
↓
密集视差图两大技术突破
突破一:引入MobileNet深度可分离卷积
传统卷积计算量大,MobileNet通过分解为:
- 深度卷积(Depthwise):每个通道独立卷积
- 逐点卷积(Pointwise):1×1卷积融合通道
这样计算量降低至原来的1/8~1/9,速度提升近6倍!
突破二:动态交互代价体
传统方法简单拼接左右特征图,本文提出智能交互:
# 伪代码示意
for each channel c:
if BN层缩放因子 < 阈值:
# 该通道不重要,用对方视图替换
左特征[c] = 左特征[c] + 权重 * 右特征[c]
右特征[c] = 右特征[c] + 权重 * 左特征[c]
# 拼接交互后的特征
代价体 = concat(左特征, 右特征)这种动态策略让模型自动学习哪些通道需要跨视图信息,显著提升精度。
实验结果:数据说话
1. 精度与速度的完美平衡
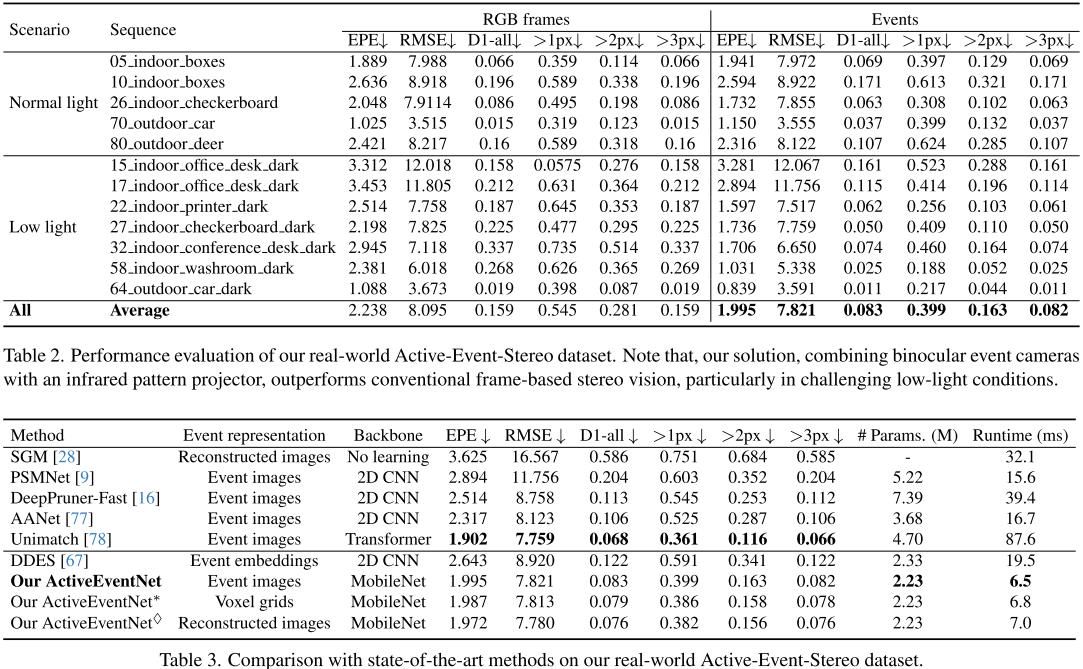
在真实数据集上与SOTA方法对比:
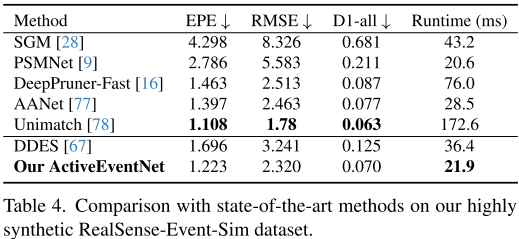
| 方法 | EPE↓ | 参数量(M) | 速度(ms) | 速度提升 |
|---|---|---|---|---|
| Unimatch (Transformer) | 1.902 | 4.70 | 87.6 | - |
| DDES (CNN) | 2.643 | 2.33 | 19.5 | - |
| ActiveEventNet | 1.995 | 2.23 | 6.5 | 12× |

结论:
- 精度与最优方法相当
- 速度快12倍,参数少一半
- GPU上可达150 FPS!
2. 结构光的惊人效果
对比有无结构光的性能:
| 场景类型 | 无结构光EPE | 有结构光EPE | 改善 |
|---|---|---|---|
| 低光办公室 | 3.281 | 2.894 | 13.3% |
| 暗光会议室 | 2.945 | 1.706 | 42.1% |
| 暗光洗手间 | 2.381 | 1.031 | 56.7% |
| 平均 | 2.614 | 1.993 | 23.7% |
在低光场景下,结构光带来的提升尤为显著!
3. 高速场景实测
与RealSense D455(90 FPS)的对比测试:
场景: 快速挥动的手臂
| 相机 | 深度图质量 | 备注 |
|---|---|---|
| RealSense D455 | ❌ 严重模糊 | 运动模糊导致失效 |
| 本文原型 | ✅ 清晰准确 | 高时间分辨率无模糊 |
4. 静态场景也能工作
这是一个令人惊喜的发现:
传统被动事件相机: 静态场景 → 无事件 → 无法工作 本文主动方案: 调制激光频率 → 持续产生事件 → 正常工作
消融实验:每个设计都有价值
MobileNet块的贡献
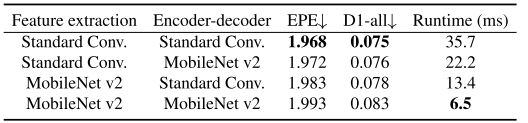
| 模块 | 使用MobileNet? | EPE↓ | 速度(ms) |
|---|---|---|---|
| 特征提取 | ❌ | 1.968 | 35.7 |
| 编解码器 | ❌ | 1.968 | 35.7 |
| 特征提取 | ✅ | 1.983 | 13.4 |
| 编解码器 | ✅ | 1.972 | 22.2 |
| 两者都用 | ✅ | 1.993 | 6.5 |
结论: 精度略微下降(<0.03),速度提升5.5倍,完全值得!
动态交互 vs 传统方法

| 代价体构建方式 | EPE↓ | RMSE↓ |
|---|---|---|
| 简单拼接 | 2.527 | 8.823 |
| 相关性计算 | 2.316 | 8.124 |
| 动态交互 | 1.993 | 7.821 |
结论: 动态交互策略显著优于传统方法,且计算开销相当。
可视化:一图胜千言
论文提供了丰富的可视化结果,展示了不同场景下的性能:
室内低光场景:
- RGB图像:几乎全黑
- 传统SGM:稀疏噪声点
- DDES:深度图有断裂
- 本文方法: 完整密集深度图
室外快速运动:

- RGB图像:明显模糊
- RealSense D455:深度图错误
- 本文方法: 清晰准确的物体轮廓
技术细节:给开发者的参考
训练配置
# 主要超参数
max_disparity = 192
threshold_gamma = 1e-2 # BN缩放因子阈值
epochs = 50
optimizer = Adam(lr=1e-3)
loss = L1Loss() # 绝对差损失事件表示
采用事件图像(Event Image)表示:
- 将连续事件流分成时间箱(temporal bins)
- 每个箱内统计正负极性事件
- 转换为2D图像状张量
这种表示在精度和速度间取得良好平衡。
推理优化
- 输入分辨率:346×260
- 批大小:1(实时处理)
- GPU:NVIDIA 3090
- 推理时间:6.5ms/帧
- 等效帧率:153 FPS
应用前景:改变哪些领域?
1. 高速机器人
- 无人机竞速: 150 FPS深度感知,避免高速碰撞
- 工业机械臂: 实时抓取快速移动物体
- 自动驾驶: 应对突发路况的快速响应
2. AR/VR
- 低延迟头部追踪: 减少晕动症
- 手势识别: 捕捉快速手部动作
- 空间建模: 实时高质量3D重建
3. 安防监控
- 暗光监控: 低光环境下仍能获取深度
- 高速抓拍: 捕捉快速移动目标
- 隐私保护: 事件流不含完整图像信息
4. 科学研究
- 高速现象记录: 液滴碰撞、爆炸过程等
- 生物运动分析: 昆虫翅膀拍打、细胞运动
- 体育科学: 运动员动作的超高速分析
局限性与未来方向
当前局限
- 分辨率限制: DAVIS346分辨率较低(346×260)
- 成本问题: 事件相机目前价格较高
- 标定复杂: 多相机系统标定需要专业设备
- 数据集规模: 虽然质量高,但样本量仍需扩充
未来研究方向
- 更高分辨率: 新一代事件相机(如1280×720)
- 端到端学习: 从事件到深度的完全学习系统
- 多模态融合: 结合RGB、事件、IMU等多传感器
- 实时SLAM: 基于主动事件立体的实时建图定位
- 硬件加速: 专用ASIC或FPGA实现,降低功耗和成本
总结:范式转变的开始
这篇论文不仅仅是一个技术改进,而是提出了一个全新的视觉感知范式:
- 首次将主动光投影与双目事件相机结合
- 首个主动事件立体视觉数据集
- 首个针对轻量级设计的事件立体网络
- 实现150 FPS的实时高速深度感知
正如作者在结论中所说:
"We believe that our prototype will provide novel insight into developing the next-generation neuromorphic stereo cameras."
这项工作为下一代神经形态视觉系统指明了方向,有望在高速机器人、自动驾驶、AR/VR等领域掀起新的技术革命。