PyTorch实战------pix2pix详解与实现
-
- [0. 前言](#0. 前言)
- [1. pix2pix 架构](#1. pix2pix 架构)
- [2. pix2pix 生成器](#2. pix2pix 生成器)
- [3. pix2pix 判别器](#3. pix2pix 判别器)
- 相关链接
0. 前言
我们已经深入探讨了生成对抗网络 (Generative Adversarial Network, GAN)模型,现有数百种不同类型的 GAN 变体,且仍在持续涌现。这些 GAN 变体的差异主要体现在以下三方面:目标应用长场景、基础模型架构和优化策略调整(如损失函数修改)。例如,超分辨率 GAN (SRGAN) 用于提升低分辨率图像的分辨率;CycleGAN 采用双生成器架构;最小二乘 GAN (LSGAN) 使用均方误差替代传统交叉熵作为判别器损失。
在本节中,我们将探讨与神经风格迁移模型相关的一种 GAN 模型。这种特殊类型的 GAN 将图像之间的风格迁移任务进行了扩展,并且进一步提供了一个通用的图像到图像的转换框架,称为 pix2pix,接下来我们将简要解析 pix2pix 架构并使用 PyTorch 实现生成器和判别器。
1. pix2pix 架构
我们在《神经风格迁移》一节训练完成的神经风格迁移模型仅适用于特定的图像对。而 pix2pix 作为更通用的模型,一旦训练成功,就能实现任意图像对之间的风格转换。实际上,该模型的应用远不止于风格迁移,还可用于以下图像到图像转换任务,背景遮罩生成(自动分离图像/视频中的前景目标)、色彩补全(基于输入图像的色彩信息自动生成完整配色方案)。
需要注意的是,pix2pix 是一种条件 GAN,它与常规的 GAN 不同,因为 pix2pix 模型通过成对图像训练,能够学习输入与输出图像之间的直接映射关系。这种训练方式使其可以生成细节精细的高质量图像,而其他 GAN 模型由于缺乏成对训练数据往往难以达到同等效果。此外,pix2pix 还能生成满足特定约束条件的图像,这使其在图像转换和编辑任务中表现优异。
从本质上说,pix2pix 的工作机制与其他 GAN 模型类似,都包含生成器和判别器两大组件。但与标准 GAN不同,pix2pix 的生成器并非接收随机噪声作为输入,而是以真实图像为输入,并尝试生成其转换版本。例如在风格迁移任务中,生成器就会输出经过风格转换的图像。
相应地,判别器的输入也发生了变化,它需要同时处理图像对(而非单张图像)。输入为原始真实图像及其对应的转换图像。当输入是真实的转换图像对时,判别器应输出 1;当输入包含生成器产生的转换图像时,判别器应输出 0。pix2pix 模型架构如下所示:
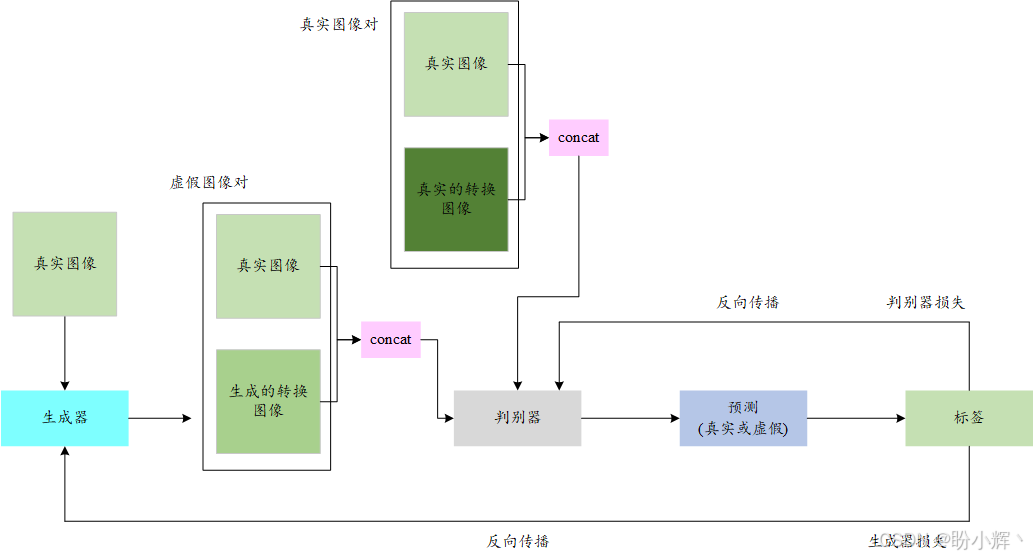
pix2pix 基本思路与常规的 GAN 相同。唯一的不同之处在于,判别器所面临的"真或假"问题是基于一对图像,而不是单张图像。
2. pix2pix 生成器
pix2pix 模型采用的生成器子模型是图像分割领域著名的 UNet 卷积神经网络。如下图所示,UNet 的架构具有以下特征:
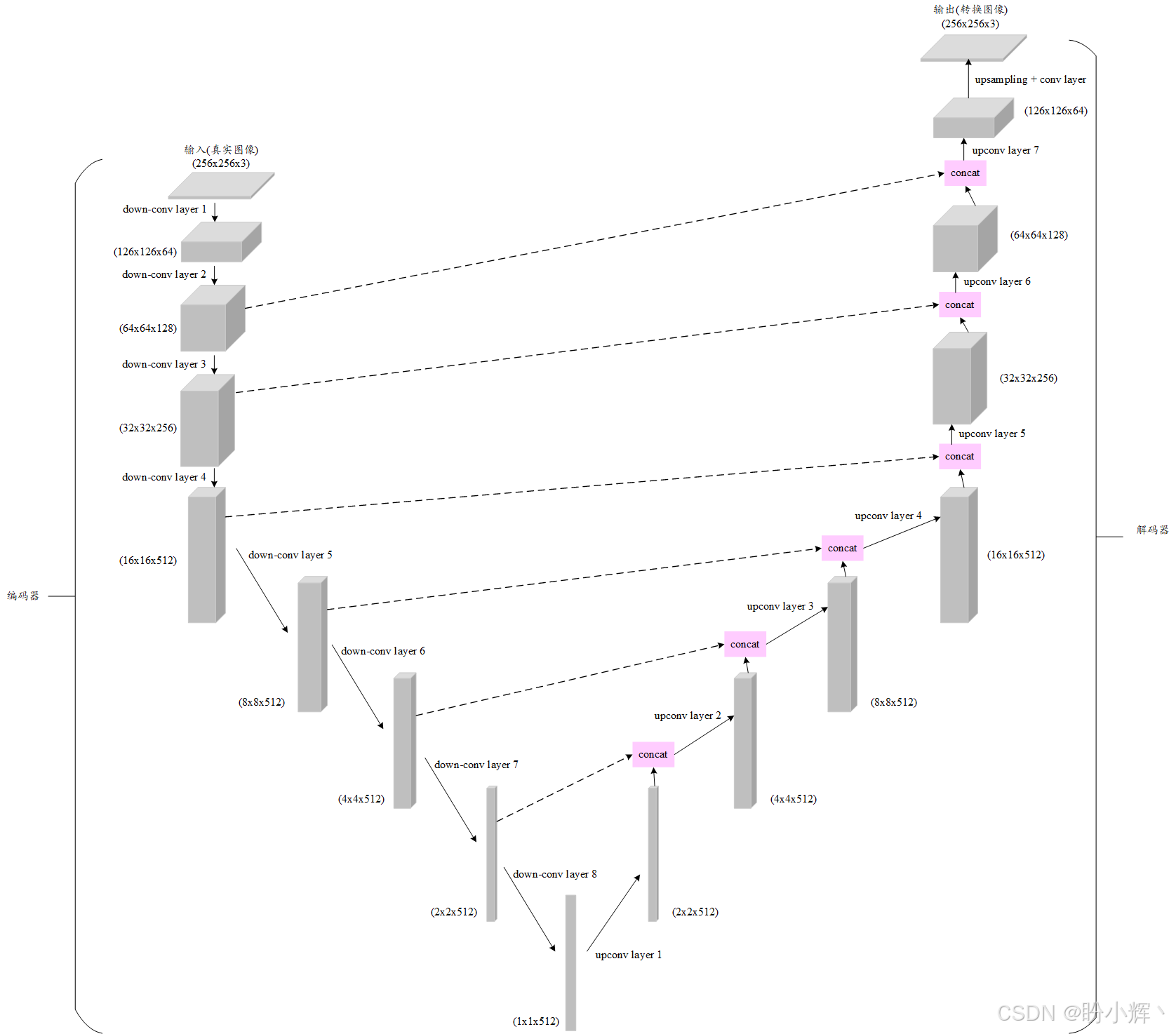
首先,UNet 名称源于其独特的 U 型结构,主要包含两个核心组件:
- 编码器部分,将
256 x 256的RGB输入图像编码成一个512大小的特征向量,通过卷积层逐步下采样,提取多层次特征 - 解码器部分,将
512维嵌入向量重构为输出图像,采用转置卷积层进行上采样,恢复空间维度
通过 UpConvBlock 和 DownConvBlock 两个类构建 UNet 的各层级结构。首先定义 UpConvBlock 类:
python
class UpConvBlock(nn.Module):
def __init__(self, ip_sz, op_sz, dropout=0.0):
super(UpConvBlock, self).__init__()
self.layers = [
nn.ConvTranspose2d(ip_sz, op_sz, 4, 2, 1),
nn.InstanceNorm2d(op_sz),
nn.ReLU(),
]
if dropout:
self.layers += [nn.Dropout(dropout)]
def forward(self, x, enc_ip):
x = nn.Sequential(*(self.layers))(x)
op = torch.cat((x, enc_ip), 1)
return op上采样卷积块中的转置卷积层采用 4 x 4 核,步长为 2,这使得输出空间维度相较于输入实现翻倍。在此转置卷积层中,4 x 4 核会以隔点采样方式(因步长设定为 2 )遍历输入图像。每个像素点都会与 4 x 4 核中的 16 个数值进行乘法运算。
运算结果在图像范围内的重叠数值会被累加求和,最终生成长度和宽度均为输入图像两倍的输出特征图。此外,在前向传播方法中,拼接操作是在完成上采样卷积块的前向传递后执行的。
定义 DownConvBlock 类:
python
class DownConvBlock(nn.Module):
def __init__(self, ip_sz, op_sz, norm=True, dropout=0.0):
super(DownConvBlock, self).__init__()
self.layers = [nn.Conv2d(ip_sz, op_sz, 4, 2, 1)]
if norm:
self.layers.append(nn.InstanceNorm2d(op_sz))
self.layers += [nn.LeakyReLU(0.2)]
if dropout:
self.layers += [nn.Dropout(dropout)]
def forward(self, x):
op = nn.Sequential(*(self.layers))(x)
return op下采样卷积块中的卷积层采用 4 x 4 核,步长为 2,并启用了填充 (padding)。由于步长值为 2,该层的输出空间维度会缩减为输入的一半。
类似于DCGAN中使用的 LeakyReLU 激活函数,也是为了处理负输入,并有助于缓解梯度消失问题。
UNet 的一个关键特性是跳跃连接 (skip connections),该机制将编码器各层的特征图(沿通道维度)与解码器对应层进行拼接融合。使用编码器部分的特征可以帮助解码器在每次上采样时更好地定位高分辨率信息。
实际上,编码器部分是由一系列下卷积块组成,每个下卷积块本身是由一个 2D 卷积层、一个实例归一化层和一个 LeakyReLU 激活层组成。相应的,解码器部分由一系列上卷积块组成,每个上卷积块由一个 2D 反卷积层、一个实例归一化层和一个 ReLU 激活层组成。
UNet 生成器架构的最后部分是一个基于最近邻的上采样层,接着是一个 2D 卷积层,最后是一个 tanh 激活函数。接下来,定义 UNet 生成器:
python
class UNetGenerator(nn.Module):
def __init__(self, chnls_in=3, chnls_op=3):
super(UNetGenerator, self).__init__()
self.down_conv_layer_1 = DownConvBlock(chnls_in, 64, norm=False)
self.down_conv_layer_2 = DownConvBlock(64, 128)
self.down_conv_layer_3 = DownConvBlock(128, 256)
self.down_conv_layer_4 = DownConvBlock(256, 512, dropout=0.5)
self.down_conv_layer_5 = DownConvBlock(512, 512, dropout=0.5)
self.down_conv_layer_6 = DownConvBlock(512, 512, dropout=0.5)
self.down_conv_layer_7 = DownConvBlock(512, 512, dropout=0.5)
self.down_conv_layer_8 = DownConvBlock(512, 512, norm=False, dropout=0.5)
self.up_conv_layer_1 = UpConvBlock(512, 512, dropout=0.5)
self.up_conv_layer_2 = UpConvBlock(1024, 512, dropout=0.5)
self.up_conv_layer_3 = UpConvBlock(1024, 512, dropout=0.5)
self.up_conv_layer_4 = UpConvBlock(1024, 512, dropout=0.5)
self.up_conv_layer_5 = UpConvBlock(1024, 256)
self.up_conv_layer_6 = UpConvBlock(512, 128)
self.up_conv_layer_7 = UpConvBlock(256, 64)
self.upsample_layer = nn.Upsample(scale_factor=2)
self.zero_pad = nn.ZeroPad2d((1, 0, 1, 0))
self.conv_layer_1 = nn.Conv2d(128, chnls_op, 4, padding=1)
self.activation = nn.Tanh()UNet 架构中共包含 8 个下采样卷积层和 7 个上采样卷积层。上采样卷积层的特殊之处在于其双输入设计,一个来自前一个上卷积层的输出,另一个来自对应的下卷积层的输出。
定义 forward 方法:
python
def forward(self, x):
enc1 = self.down_conv_layer_1(x)
enc2 = self.down_conv_layer_2(enc1)
enc3 = self.down_conv_layer_3(enc2)
enc4 = self.down_conv_layer_4(enc3)
enc5 = self.down_conv_layer_5(enc4)
enc6 = self.down_conv_layer_6(enc5)
enc7 = self.down_conv_layer_7(enc6)
enc8 = self.down_conv_layer_8(enc7)
dec1 = self.up_conv_layer_1(enc8, enc7)
dec2 = self.up_conv_layer_2(dec1, enc6)
dec3 = self.up_conv_layer_3(dec2, enc5)
dec4 = self.up_conv_layer_4(dec3, enc4)
dec5 = self.up_conv_layer_5(dec4, enc3)
dec6 = self.up_conv_layer_6(dec5, enc2)
dec7 = self.up_conv_layer_7(dec6, enc1)
final = self.upsample_layer(dec7)
final = self.zero_pad(final)
final = self.conv_layer_1(final)
return self.activation(final)完成 pix2pix 模型的生成器部分后,继续分析判别器模型。
3. pix2pix 判别器
判别器模型同样是一个二分类器,其特殊之处在于需要同时接收两张图像作为输入。这两组输入会沿通道维度进行拼接。判别器模型架构如下所示:
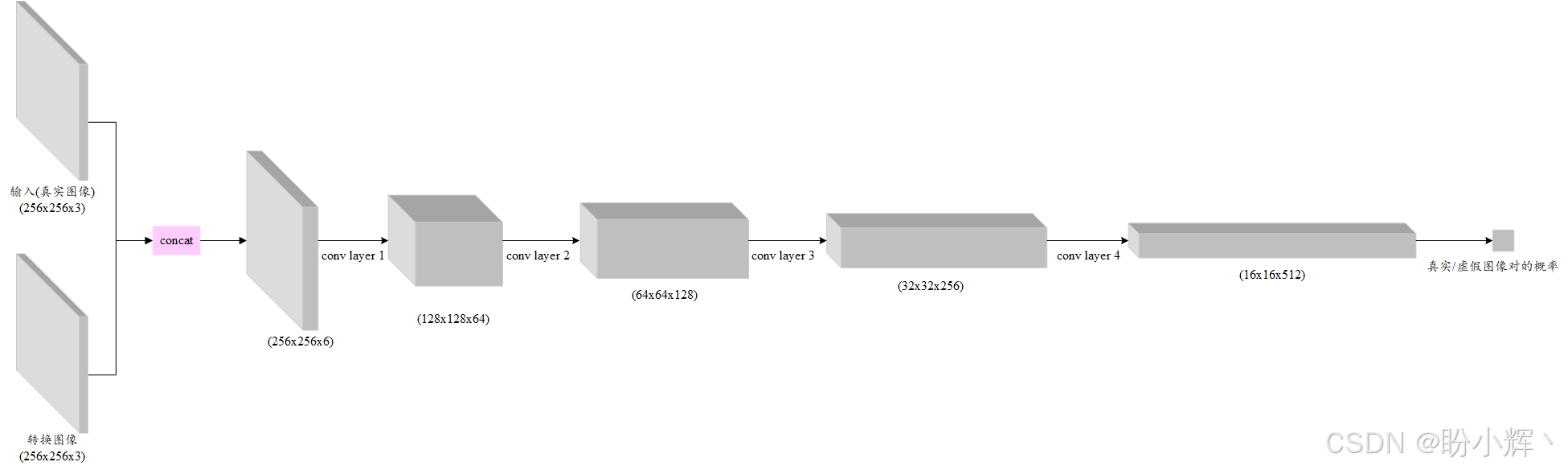
判别器是一个卷积神经网络 (Convolutional Neural Network, CNN),其最后三个卷积层均接有归一化层和 LeakyReLU 激活层:
python
class Pix2PixDiscriminator(nn.Module):
def __init__(self, chnls_in=3):
super(Pix2PixDiscriminator, self).__init__()
def disc_conv_block(chnls_in, chnls_op, norm=1):
layers = [nn.Conv2d(chnls_in, chnls_op, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(chnls_op))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.lyr1 = disc_conv_block(chnls_in * 2, 64, norm=0)
self.lyr2 = disc_conv_block(64, 128)
self.lyr3 = disc_conv_block(128, 256)
self.lyr4 = disc_conv_block(256, 512)可以看到,经过 4 个卷积层的逐级处理,空间特征的通道深度 (channel depth) 在每步都实现翻倍。其中第 2、3、4 层在卷积操作后均加入了归一化层,且每个卷积块末端都应用了斜率为 -0.2 的 LeakyReLU 激活函数。最后,实现前向传播方法:
python
def forward(self, real_image, translated_image):
ip = torch.cat((real_image, translated_image), 1)
op = self.lyr1(ip)
op = self.lyr2(op)
op = self.lyr3(op)
op = self.lyr4(op)
op = nn.ZeroPad2d((1, 0, 1, 0))(op)
op = nn.Conv2d(512, 1, 4, padding=1)(op)
return op首先,输入图像会经过通道拼接后传入四个卷积块,最终输出一个二元概率值,用于判断该图像对是真实样本还是生成器产生的伪造样本。通过这种架构,pix2pix 模型在训练过程中逐步学习,使得生成器最终能够接收任意输入图像,并执行其在训练阶段习得的图像转换功能。
转换功能的一个示例是以边缘轮廓图作为输入,生成完整图像输出。如图所示,pix2pix 模型成功将背包草图转换为逼真的背包图像。

当生成器输出的转换图像与真实转换版本难以区分时,即可判定 pix2pix 模型训练成功。从原理上看,pix2pix 的整体架构与DCGAN高度相似:两者的判别器均采用基于 CNN 的二分类器,而 pix2pix 的生成器则借鉴了 UNet 图像分割模型,结构稍显复杂。
相关链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)