Lin, H., Zheng, X., Li, L., Chao, F., Wang, S., Wang, Y., Tian, Y., & Ji, R. (2023). Meta Architecture for Point Cloud Analysis. CVPR.
博主导读 :
在点云深度学习的江湖里,各路门派为了争夺 SOTA 盟主之位,练就了各种花哨的武功。从 PointNet++ 的"球查询",到 DGCNN 的"动态图",再到 Point Transformer 的"自注意力",网络结构越来越复杂,公式越来越长。
但这就带来了一个大麻烦:大家的招式都太独特了,根本没法公平比武。 当一个新的 SOTA 出现时,我们不知道它变强是因为它的"内功心法"(算子设计)真的好,还是因为它偷偷吃了"大力丸"(训练技巧、数据增强)。
PointMeta 站出来做了一件大事:它编写了一部"点云兵器谱"(元架构)。它把市面上主流的算法都拆解成了 4 个标准零件,放进同一个炉子里炼。
炼丹的结果令人大跌眼镜:原来那些花里胡哨的 Attention、动态图,在设计合理的"朴素"算子面前,并没有绝对优势。 作者更是顺手拼凑出了一套"最强简易连招"------PointMetaBase ,用极低的计算量吊打了当时的霸主 PointNeXt。
论文:Meta Architecture for Point Cloud Analysis
1. 痛点:乱花渐欲迷人眼
在 PointMeta 出现之前,点云领域存在两个严重的"认知迷雾":
- 架构壁垒:PointNet++ 是基于 MLP 的,DGCNN 是基于 Graph 的,Point Transformer 是基于 Attention 的。大家的代码库、数据流完全不同,很难把 PointNet++ 的 Pooling 换成 Transformer 的 Attention 来单独测试效果。
- 算力黑洞:为了追求精度,模型越来越重。比如 Point Transformer 虽然准,但计算量大得吓人;PointNeXt 虽然优化了,但依然沿用了 PointNet++ 的一些低效设计。
PointMeta 的灵魂拷问 :
如果我们把所有网络都拆解成相同的原子操作 ,能不能找到一套既快又准的"黄金组合"?
2. 核心大招:元架构 (Meta Architecture) 🧩
作者提出,无论你的网络多复杂,本质上都在做 4 件事。PointMeta 定义了一个标准模块包含这 4 个元函数 (Meta Functions):
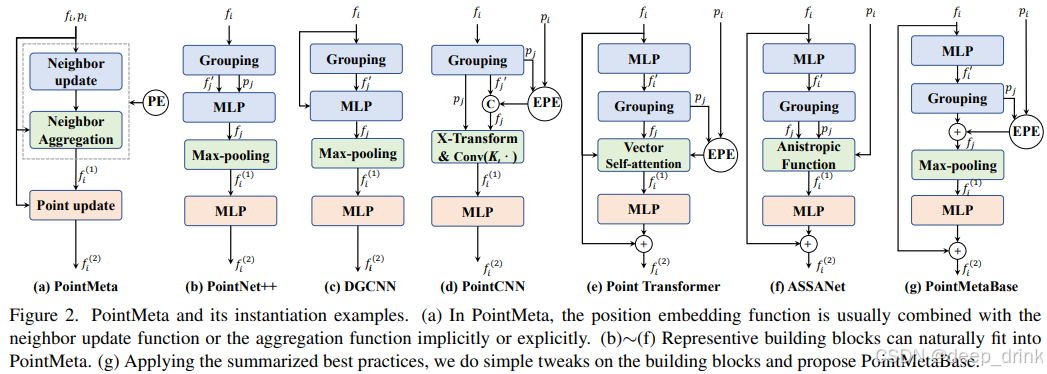
- 邻居更新 (Neighbor Update, Φ n \Phi^n Φn) :
- 干啥:找邻居,并对邻居特征做初步处理。
- 例子:PointNet++ 的 MLP,或者 Point Transformer 的 Linear。
- 位置编码 (Position Embedding, Φ e \Phi^e Φe) :
- 干啥:告诉网络"邻居在哪里"。
- 例子 :PointNet++ 的
Concat(x, y, z),或者 Transformer 的位置编码相加。
- 邻居聚合 (Neighbor Aggregation, Φ a \Phi^a Φa) :
- 干啥:把一堆邻居的信息压缩成一个点。
- 例子:Max Pooling, Sum Pooling, Attention 加权求和。
- 点更新 (Point Update, Φ p \Phi^p Φp) :
- 干啥:聚合完之后,再对中心点特征做一次提炼。
- 例子:ResNet 的 MLP Block。
一统江湖 :
通过这 4 个步骤,PointNet++, DGCNN, Point Transformer, ASSANet 全都能被装进这个框架里(如论文 Figure 2 所示)。这就为公平竞技铺平了道路。
3. 炼丹实录:打破直觉的"最佳实践" 🔥
这一部分是论文最精彩的**"打假"环节**。作者控制变量测试了各种组合,得出了很多反直觉的结论。
3.1 邻居更新:先 MLP 还是先 Grouping?
- 传统做法 (G-before-M) :先 Grouping 拿到 N × K N \times K N×K 个邻居,再跑 MLP。 (PointNet++, PointNeXt)
- PointMeta 结论 :先 MLP 再 Grouping (M-before-G)!
- 原因 :在 Grouping 之前( N N N 个点)跑 MLP,计算量是 N N N;在 Grouping 之后( N × K N \times K N×K 个点)跑,计算量是 N × K N \times K N×K。
- 把 MLP 移到前面,计算量直接除以 K K K (通常 K = 32 K=32 K=32),且精度几乎不掉。这就是 ASSANet 的核心智慧。
3.2 位置编码:显式还是隐式?
- 传统做法 :PointNet++ 喜欢隐式 (IPE) ,把坐标 p j − p i p_j-p_i pj−pi 拼接到特征 f f f 后面,让 MLP 自己去学。
- PointMeta 结论 :显式位置编码 (EPE) 最好!
- 做法 :单独用一个小网络把坐标映射成位置向量 e e e,然后直接 f + e f + e f+e。
- 优势:IPE 会导致 MLP 输入维度变大,浪费算力;EPE 轻量且直接,效果最好。
3.3 邻居聚合:Attention 真的不可战胜吗?
- 传统迷信:Self-Attention 是最强的,Max Pooling 太土了。
- PointMeta 结论 :Max Pooling 性价比无敌!
- 实验表明,把 Point Transformer 里的 Attention 换成 Max Pooling,mIoU 仅仅掉了 0.2%,但参数量和 FLOPs 大幅下降。
- 深度洞察 :Max Pooling 其实可以看作是一种稀疏的、二值化的 Attention(只关注最强的那个特征,其他权重为0)。在点云这种稀疏数据上,它足够好用了。
3.4 点更新 (Point Update)
-
问题:这个环节要给多少计算量?
-
PointMeta 结论:N1P2 配置最好。即邻居更新用 1 层 MLP,点更新用 2 层 MLP。不要用倒瓶颈结构(Inverted Bottleneck),那是浪费算力。
4. 终极缝合:PointMetaBase 🤖
基于上面的实验,作者拼凑出了一套**"平民版最强连招"** ------ PointMetaBase。
它的配置简直**"朴素"到令人发指**:
- 邻居更新 :M-before-G(为了省 K K K 倍算力)。
- 位置编码:EPE(显式加法)。
- 邻居聚合 :Max Pooling(是的,你没看错,就用最简单的)。
- 点更新:2 层 MLP。
这就是 PointMetaBase。没有 Attention,没有动态图,只有 MLP 和 MaxPool。
5. 实验结果:降维打击 📊
作者拿这个"朴素"的 PointMetaBase 去挑战当时的 SOTA 霸主 PointNeXt。结果非常打脸:
- S3DIS 场景分割 :
- PointMetaBase-L vs. PointNeXt-L :
- mIoU:+1.7% (更高)
- FLOPs:13% (只有对方的 1/8)
- PointMetaBase-XL vs. PointNeXt-XL :
- mIoU:+1.4% (更高)
- FLOPs:11% (只有对方的 1/9)
- PointMetaBase-L vs. PointNeXt-L :
为什么?
因为 PointNeXt 虽然优化了训练策略,但它沿用了 PointNet++ 的 G-before-M (先聚合后计算)和 IPE (隐式位置编码),导致大量算力被浪费在重复的邻居特征计算上。
而 PointMetaBase 把好钢都用在了刀刃上(增加了网络深度和宽度),用更简单的算子换来了更强的特征表达。
6. 总结 (Conclusion)
PointMeta 给我们上了一堂生动的**"第一性原理"**课:
- 不要盲目迷信复杂算子:很多时候,Attention 带来的提升不如把它换成更多的 MLP 层来得实在。
- 架构设计要有"大局观" :算子的微调(Micro)不如数据流的优化(Macro)重要。避开 O ( N × K ) O(N \times K) O(N×K) 的重计算是提速的关键。
- PointMetaBase 是真·基石:如果你现在要设计新的点云网络,建议别去魔改 Point Transformer 了,直接在这个架构上改,起点就是 SOTA。
📚 参考文献
1 Lin, H., Zheng, X., et al. (2023). Meta Architecture for Point Cloud Analysis. CVPR.
💬 互动话题:
- 关于 Max Pooling:你觉得为什么在点云领域,简单的 Max Pooling 能抗衡复杂的 Attention?是因为点云的稀疏性吗?
- 关于未来:PointMeta 似乎把 MLP 结构的潜力挖掘殆尽了。你觉得下一代的点云网络突破口会在哪里?(提示:也许是大模型/预训练?)
📚 附录:点云网络系列导航
🔥 欢迎订阅专栏 :【点云特征分析_顶会论文代码硬核拆解】持续更新中...
本文为 CSDN 专栏【点云特征分析_顶会论文代码硬核拆解】原创内容,转载请注明出处。