Transformer实战(33)------高效自注意力机制
-
- [0. 前言](#0. 前言)
- [1. 高效 Transfomer 模型](#1. 高效 Transfomer 模型)
- [2. 高效自注意力机制](#2. 高效自注意力机制)
- [3. 基于固定模式的稀疏注意力](#3. 基于固定模式的稀疏注意力)
-
- [3.1 Longformer](#3.1 Longformer)
- [3.2 BigBird](#3.2 BigBird)
- [4. 可学习模式](#4. 可学习模式)
-
- [4.1 Reformer](#4.1 Reformer)
- [4.2 实现 Reformer](#4.2 实现 Reformer)
- [5. 低秩分解、核方法及其他方法](#5. 低秩分解、核方法及其他方法)
- 小结
- 系列链接
0. 前言
我们已经学习了如何设计自然语言处理 (Natural Language Processing, NLP) 架构,以利用 Transformer 成功解决实际任务。在本节中,我们将学习高效稀疏 Transformer,如 Linformer、BigBird 和 Performer。查看这些模型在各种基准测试中的表现,包括内存与序列长度的关系以及速度与序列长度的关系。
随着大规模神经网络模型的扩展,在有限计算能力下运行大模型变得越来越困难,如何构建高效的模型变得尤为重要。基于 Transformer 的架构由于自注意力机制中的点积计算具有平方级复杂度,尤其在处理长文本自然语言处理 (Natural Language Processing, NLP) 任务中,面临复杂性瓶颈。字符级语言模型、语音处理和长文档处理都属于典型的长文本问题。近年来,研究人员已经提出了许多提高自注意力机制效率的技术,例如 Reformer、Performer 和 BigBird。
1. 高效 Transfomer 模型
基于 Transformer 的模型在许多自然语言处理 (Natural Language Processing, NLP) 问题中取得了优异表现,但其代价是平方级的内存和计算复杂度。为了降低计算复杂性和内存占用,研究人员已经提出了多种方法。除了修改模型架构,还有一些方法在不改变原始架构的情况下,对训练好的模型或训练阶段进行改进。这些方法分为两类:模型压缩和高效自注意力机制。我们已经学习了模型压缩方法,在本节中,我们专注于介绍高效注意力机制。
自注意力头并未针对长序列进行优化,在处理长序列时效率不高。为了解决这个问题,研究人员提出了多种不同的方法。其中,最有效的方法是自注意力稀疏化,另一个广泛使用的方法是内存高效的反向传播,该方法在缓存中间结果和重新计算之间取得平衡。在前向传播中计算的中间激活值,在反向传播时需要用来计算梯度。梯度检查点可以显著减少内存占用和计算量。另一种方法是管道并行算法,将小批次数据划分为微批次,并利用了前向和后向传播之间的等待时间,将数据传输到深度学习加速器(如图形处理单元 (Graphics Processing Unit, GPU) 或张量处理单元 (Tensor Processing Unit, TPU) )中。
参数共享在高效深度学习中由来已久。最典型的例子是循环神经网络 (Recurrent Neural Network, RNN),其中展开表示的单元使用共享参数。因此,训练参数的数量不会受到输入大小的影响。一些共享参数(也称为权重绑定或权重复制)通过扩展网络来减少可训练参数的数量。例如,Linformer 在头和层之间共享投影矩阵。Reformer 则共享查询和键,但这会导致一定的性能损失。
2. 高效自注意力机制
由于 Transformer 的计算和内存复杂度主要来自自注意力机制,因此通常通过改进注意力机制来实现更高效的 Transformer 模型。自注意力机制的计算复杂度与输入序列长度呈平方级关系。对于较短的输入,平方级复杂度可能不是问题,但处理长文档时,我们需要改进注意力机制,使其复杂度与序列长度呈线性关系。
高效注意力机制 (Efficient Self-Attention) 大致可以分为三种类型:
- 基于固定模式的稀疏注意力
- 可学习的稀疏模式
- 低秩分解/核函数
接下来,我们首先介绍基于固定模式的稀疏注意力。
3. 基于固定模式的稀疏注意力
注意力机制由查询 (query)、键 (key) 和值 (value) 组成,公式如下:
A t t e n t i o n ( Q , K , V ) = S c o r e ( Q , A ) ⋅ V Attention(Q,K,V)=Score(Q,A)\cdot V Attention(Q,K,V)=Score(Q,A)⋅V
其中,得分函数(通常是 softmax ) 需要进行矩阵乘法,其内存和计算复杂度为 O ( n 2 ) O(n^2) O(n2),因为在自注意力模式下,每个词元位置需要关注所有其他词元位置以构建其嵌入表示。对所有词元位置重复相同的过程,从而导致复杂度为平方级。这种计算方式资源消耗较高,特别是在处理长上下文的 NLP 问题时。为了解决这一问题,研究人员提出了多种技术来减轻复杂度,降低自注意力机制的二次复杂度,在性能、计算和内存之间进行权衡。
降低复杂度的最简单方法是稀疏化全自注意力矩阵,或找到另一种方法来近似全注意力。稀疏注意力模式通过定义如何连接/断开某些位置,同时不干扰信息在各层之间的流动,帮助模型跟踪长期依赖关系并构建句子级编码。
下图展示了全自注意力 (Full self-attention, 即完整的经典自注意力机制) 和稀疏注意力 (sparse attention),图中,行对应输出位置,列对应输入位置。全自注意力模型会直接在任意两个位置之间传递信息。而在图中右侧所示的局部滑动窗口注意力(即稀疏注意力)中,空白单元格表示相应的输入-输出位置之间没有交互。图中的稀疏模型基于固定模式,这些模式是手动设计的规则。具体地说,局部滑动窗口注意力是最早提出的稀疏化方法之一,也称为基于局部的固定模式方法,它假设每个位置有用的信息通常位于其邻近位置。每个查询词元会关注当前位置左边和右边各2个键词元,即窗口大小为 4。这一规则以相同的方式应用于 Transformer 的每一层,我们也可以令窗口大小随着层数的增加而增大。下图简要展示了全自注意力(左)和稀疏注意力(右)之间的区别:
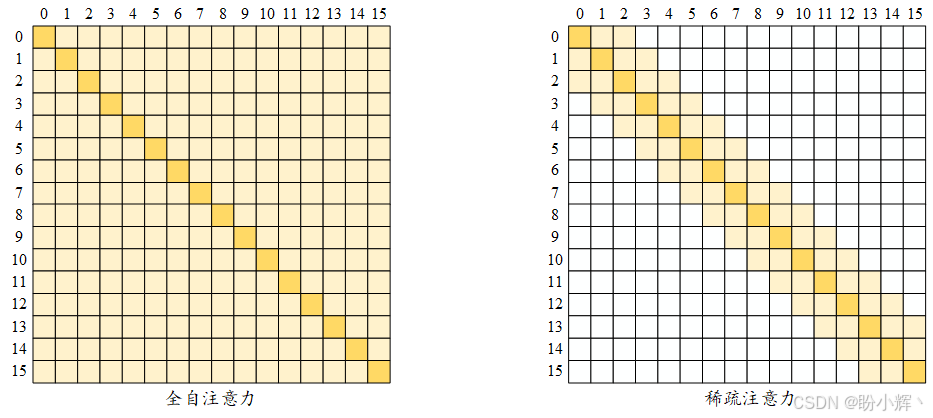
在稀疏模式下,信息通过模型中的连接节点(非空单元格)进行传输。例如,稀疏注意力矩阵的输出位置 7 无法直接关注输入位置3(如上图右侧的稀疏矩阵),因为单元格 (7,3) 是空的。但位置 7 可以通过位置 5 间接关注位置 3,即 (7->5,5->3 => 7->3)。上图中还显示了,全自注意力需要有 n 2 n^2 n2个活跃单元格(顶点),而稀疏模型大约只需要 5 × n 5×n 5×n 个单元格。
另一种重要模式是全局注意力 (global attention)。在这种模式下,一些选定的词元或额外注入的词元用作全局注意力节点,它们可以关注所有其他位置,并被其他位置关注。因此,任意两个词元位置之间的最大路径距离等于 2。假设我们有一个句子 [GLB, the, cat, is, very, sad],其中 GLB 是一个注入的全局词元,窗口大小为 2,这意味着一个词元只能关注其左右相邻的 token 以及 GLB。cat 和 sad 之间没有直接的交互,但可以通过 cat-> GLB、GLB-> sad 的交互,利用 GLB 词元建立超链接。全局词元可以从现有词元中选择,也可以是额外添加的词元(如 [CLS])。如下图所示,前两个词元位置被选为全局词元:
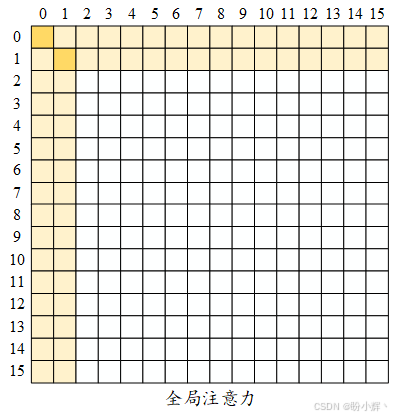
全局词元不一定位于句子的开头。例如,Longformer 模型除了选择前两个词元外,还会随机选择其他全局词元。
除了滑动窗口和全局注意力外,还有四种常见的稀疏模式,如下图所示。随机注意力( random attention, 下图中的第一个矩阵)通过随机选择现有词元来简化信息流动。但大多数情况下,随机注意力作为组合模式 (combined pattern) 的一部分使用(下图中左下角矩阵),组合模式由其他模式组合构成。空洞注意力 (dilated attention) 类似于滑动窗口,但在窗口中加入了一些间隔(如下图右上角所示)。块状模式( blockwise pattern, 下图右下角)为其他模式提供了基础,它将词元分成固定数量的块,特别适用于长上下文问题。例如,将 4096 x 4096 的注意力矩阵使用大小为 512 的块进行分块时,会得到 8 个 (512 x 512) 的查询块和键块。许多高效模型,如 BigBird 和 Reformer,都采用这种分块方法来降低复杂度。
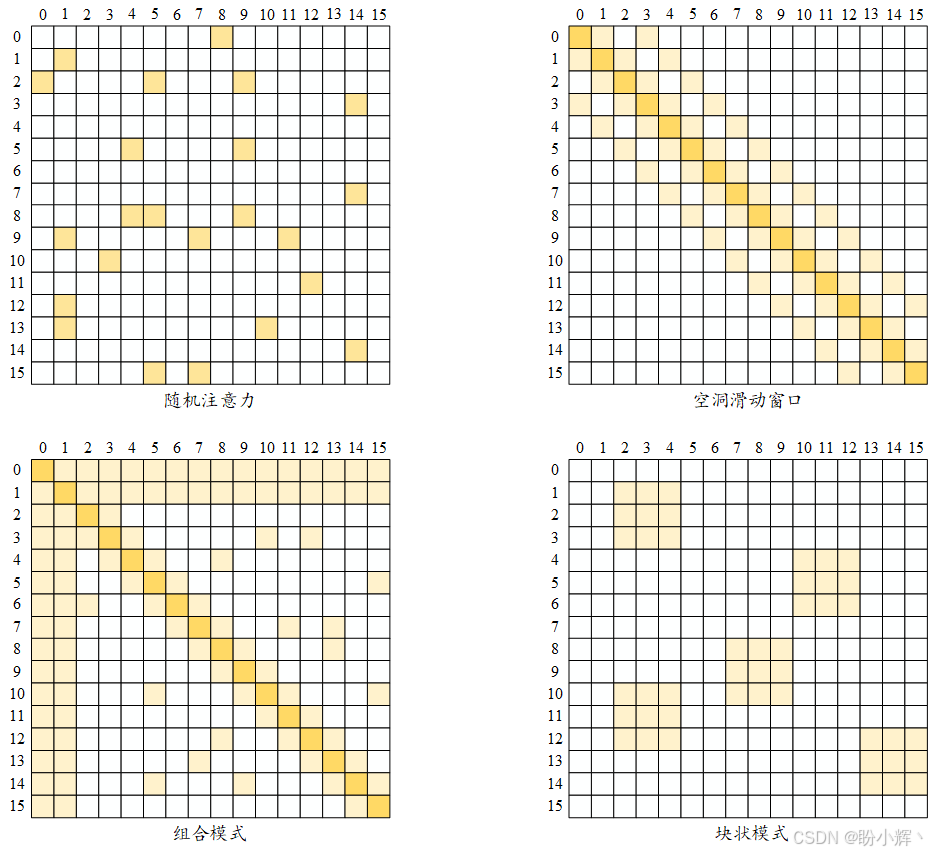
需要注意的是,这些模式需要得到加速器和库的支持。例如,空洞注意力需要特殊的矩阵乘法操作。
3.1 Longformer
接下来,我们将实现高效 Transformer 模型,使用由 transformers 库支持的模型及其预训练权重。Longformer 是使用稀疏注意力的模型之一,它结合了滑动窗口和全局注意力,并支持空洞滑动窗口注意力。
(1) 首先,需要安装 py3nvml 库以进行基准测试:
shell
$ pip install py3nvml(2) Longformer 提供了多个预训练权重,加载 allenai/longformer-base-4096 权重并处理一段长文本:
python
from transformers import LongformerTokenizer, LongformerModel
import torch
tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
model = LongformerModel.from_pretrained('allenai/longformer-base-4096')
sequence= "hello "*4093
inputs = tokenizer(sequence, return_tensors="pt")
print("input shape: ",inputs.input_ids.shape)
outputs = model(**inputs)输出如下所示:
shell
input shape: torch.Size([1, 4096])可以看到,Longformer 可以处理长度最多为 4096 的序列。当我们传入长度超过 4096 的序列时,会抛出错误 IndexError: index out of range in self,因为 4096 是该模型的最大限制。
(3) Longformer 的默认 attention_window 为 512,即每个词元周围的注意力窗口大小。实例化两个 Longformer 配置对象,第一个是默认配置,第二个是更轻量的配置,将窗口大小设置为较小的值(例如,设置为 4 )使模型更轻量:
python
from transformers import LongformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
config_longformer=LongformerConfig.from_pretrained("allenai/longformer-base-4096")
config_longformer_window4=LongformerConfig.from_pretrained("allenai/longformer-base-4096", attention_window=4)需要注意的是,调用 XformerConfig.from_pretrained() 不会下载模型的实际权重,而是只会从 Hugging Face Hub 下载配置。在本节中,由于我们不会进行微调,因此只需要配置对象:
(4) 使用这些配置实例,可以使用自定义数据集训练 Longformer 语言模型,并将配置对象传递给 Longformer 模型:
python
from transformers import LongformerModel
model = LongformerModel(config_longformer)除了训练 Longformer 模型,还可以对预训练权重进行下游任务的微调。
(5) 接下来,使用 PyTorchBenchmark 比较这两种配置在不同输入长度 [128, 256, 512, 1024, 2048, 4096] 下的时间和内存性能:
python
sequence_lengths=[128,256,512,1024,2048,4096]
models=["config_longformer","config_longformer_window4"]
configs=[eval(m) for m in models]
benchmark_args = PyTorchBenchmarkArguments(
sequence_lengths= sequence_lengths,
batch_sizes=[1],
models= models)
benchmark = PyTorchBenchmark(
configs=configs,
args=benchmark_args)
results = benchmark.run()输出如下所示:
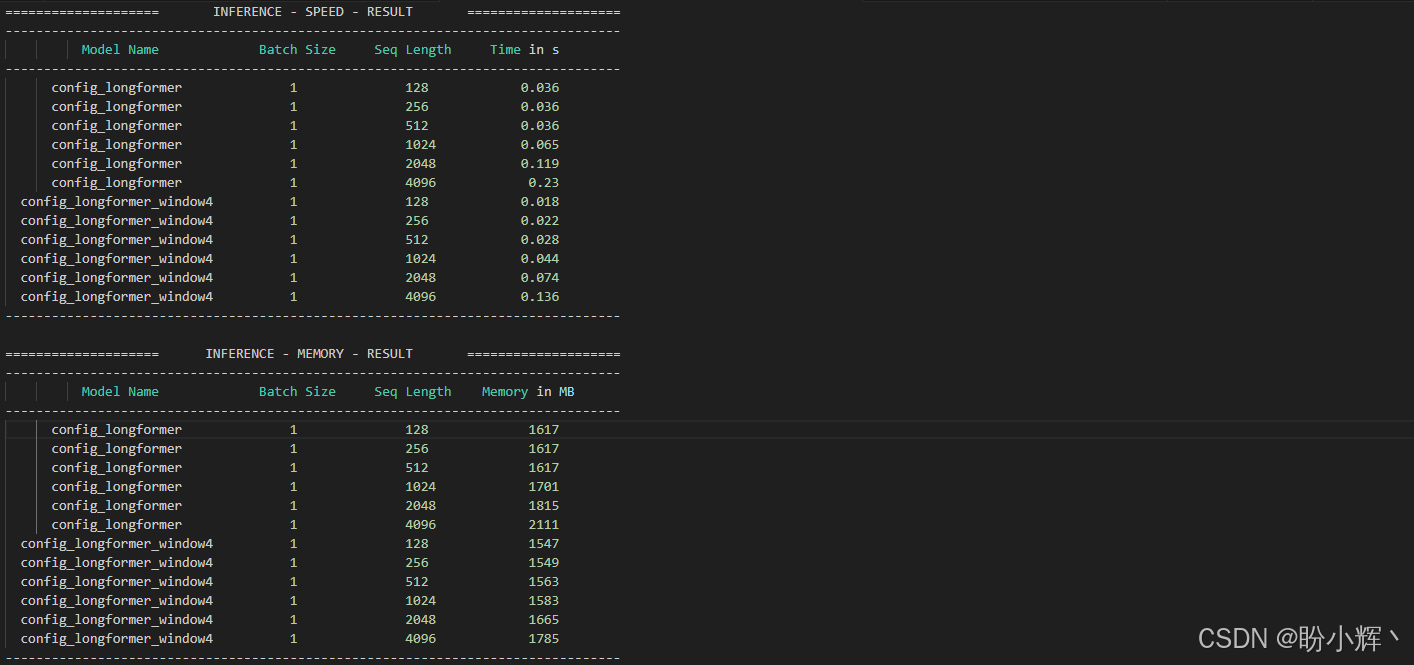
在 PyTorchBenchmarkArguments 中,如果希望查看训练和推理的性能,应该将 training 参数设置为 True (默认是 False);如果希望查看当前环境的信息,可以通过将 no_env_print 设置为 False 来实现(默认值是 True)。
(6) 为了更直观地展示性能,定义 plotMe() 函数。该函数用于绘制推理性能,包括运行时间复杂度和内存复杂度:
python
import matplotlib.pyplot as plt
def plotMe(results,title="Time"):
plt.figure(figsize=(8,8))
fmts= ["rs--","go--","b+-","c-o"]
q=results.memory_inference_result
if title=="Time":
q=results.time_inference_result
models=list(q.keys())
seq=list(q[models[0]]['result'][1].keys())
models_perf=[list(q[m]['result'][1].values()) for m in models]
plt.xlabel('Sequence Length')
plt.ylabel(title)
plt.title('Inference Result')
for perf,fmt in zip(models_perf,fmts):
plt.plot(seq, perf,fmt)
plt.legend(models)
plt.show() (7) 接下来,对比两个 Longformer 配置的计算性能:
python
plotMe(results)可视化结果如下所示:
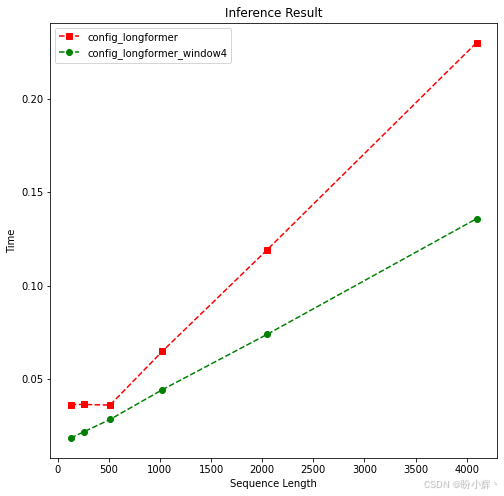
从长度 512 开始,重量级模型和轻量级模型之间表现出明显差异。上图中,以绿色显示了更轻量的 Longformer 模型(窗口长度为 4),其在时间复杂度上的表现更好,还可以看到,两个 Longformer 模型处理输入的时间复杂度均为线性。
(8) 接下来,评估这两个模型在内存性能方面的表现:
python
plotMe(results,"Memory")结果如下所示:
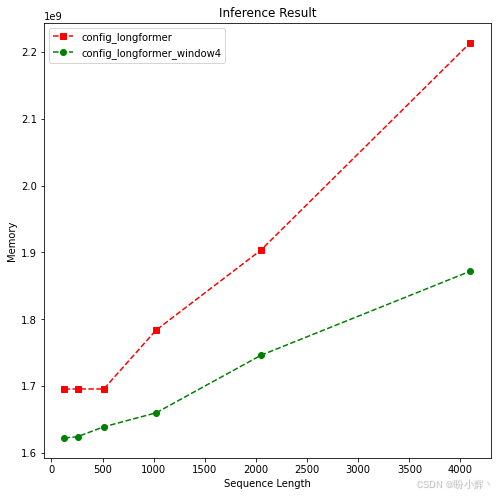
同样,在序列长度达到 512 之前,两者没有显著差异。而对于更长的序列,看到内存性能与时间性能表现类似。可以看出,Longformer 自注意力的内存复杂度是线性的。
利用 PyTorchBenchmark 脚本,我们可以对这两个模型进行了交叉验证。该脚本在选择语言模型的训练配置时非常有用,尤其是在实际开始语言模型训练和微调之前,它起到至关重要的作用。
3.2 BigBird
另一个利用稀疏注意力机制取得优异表现的模型是 BigBird,其稀疏注意力机制(也称之为广义注意力机制)能够在保持原始 Transformer 完全自注意力机制功能的同时,将时间复杂度降低到线性级。BigBird 将注意力矩阵视为有向图,从而可以利用图论算法,BigBird 借鉴了图稀疏化算法中的思想,该算法通过减少边或顶点来近似给定的图 G 得到图 G'。
BigBird 是一种基于块状模式的注意力模型,可以处理最大长度为 4096 的序列。首先通过将查询和键打包在一起来分块注意力模式,然后在这些块上定义注意力。BigBird 结合了随机注意力、滑动窗口注意力和全局注意力。
(1) 接下来,加载并使用 BigBird 模型的预训练配置。Hugging Face Hub 上存在多个 BigBird 的预训练权重,本节选择使用基于 RoBERTa 权重的原始 BigBird 模型 google/bigbird-roberta-base。需要注意的是,我们并未下载模型权重,而是下载配置。使用 BigBirdConfig 能够比较全自注意力和稀疏注意力,从而可以验证稀疏化是否能够将全注意力的 O ( n 2 ) O(n^2) O(n2) 复杂度降低到较低水平。可以看到,直到序列长度为 512 时,都没有观察到平方级复杂度。从这个长度开始,可以看到复杂度的变化。将注意力类型设置为 original_full 将得到一个全自注意力模型。
为了进行对比,我们创建了两种配置:第一种是 BigBird 的原始稀疏方法,第二种是使用全自注意力机制的模型。将它们分别命名为 sparseBird 和 fullBird:
python
from transformers import BigBirdConfig
# Default Bird with num_random_blocks=3, block_size=64
sparseBird = BigBirdConfig.from_pretrained("google/bigbird-roberta-base")
# Fuyll attention Bird:
fullBird = BigBirdConfig.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")(2) 需要注意的是,对于长度不超过 512 的序列,BigBird 模型由于块大小和序列长度的不一致,实际上是以全自注意力模式运行的:
python
sequence_lengths=[256,512,1024,2048, 3072, 4096]
models=["sparseBird","fullBird"]
configs=[eval(m) for m in models]
benchmark_args = PyTorchBenchmarkArguments(
sequence_lengths=sequence_lengths,
batch_sizes=[1],
models=models)
benchmark = PyTorchBenchmark(
configs=configs,
args=benchmark_args)
results = benchmark.run()输出结果如下:
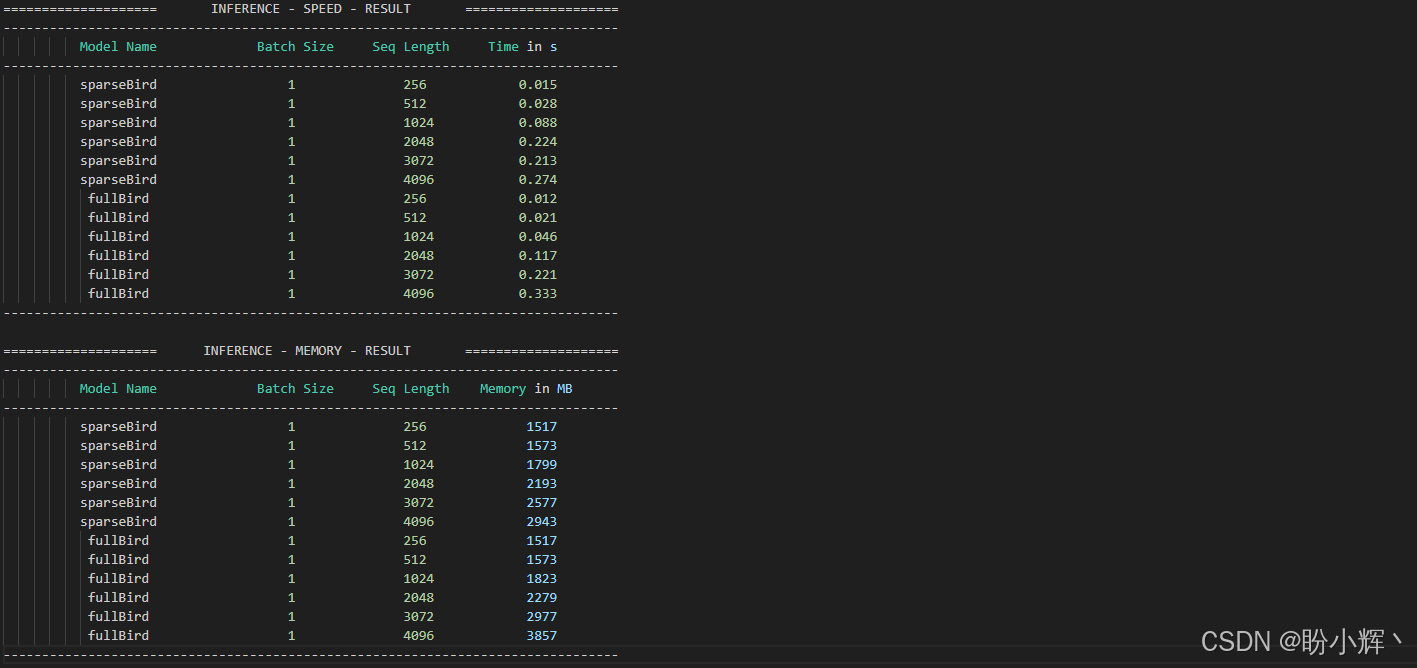
(3) 可视化性能表现:
python
plotMe(results)结果如下所示:
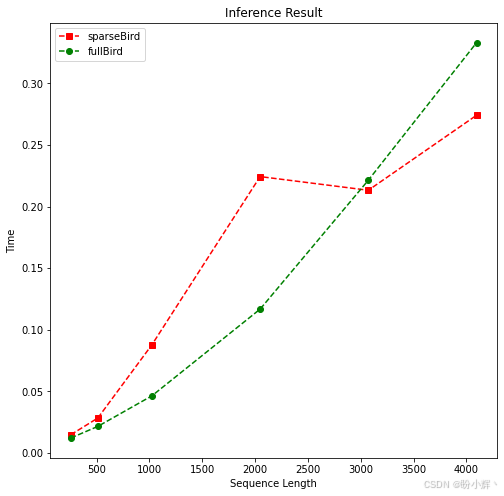
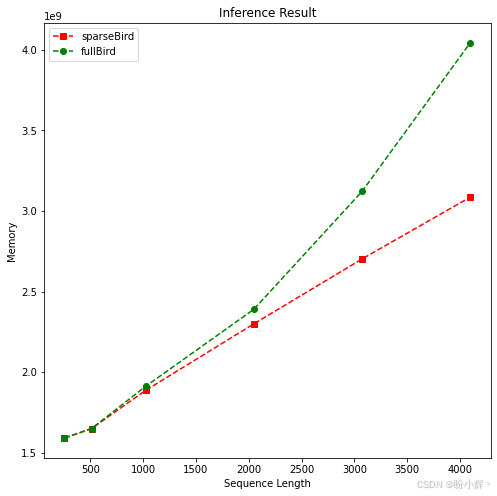
在一定范围内,全自注意力模型的表现优于稀疏模型。但我们可以观察到全自注意力模型 (fullBird) 呈平方级时间复杂度。因此,在达到临界点后,稀疏注意力模型的表现会超越全自注意力模型。
(4) 接下来,对比内存复杂度:
python
plotMe(results,"Memory")输出如下所示,可以清晰地看到全自注意力模型和稀疏模型分别呈线性和平方级内存复杂度:
接下来,我们将介绍可学习模式,并探索能够处理更长输入的模型。
4. 可学习模式
可学习模式是固定(预定义)模式的替代方案,以无监督、数据驱动的方式提取模式,利用一些技术来测量查询与键之间的相似性,从而对它们进行适当的聚类。这类 Transformer 模型首先学习如何对词元进行聚类,然后限制交互,以获得最优的注意力矩阵视图。
4.1 Reformer
接下来,我们将以 Reformer 为例介绍可学习模式,Reformer 是基于可学习模式的高效模型之一。
Reformer 使用局部自注意力 (Local Self Attention, LSA) 方法,通过将输入切分为 n 个块来降低复杂度瓶颈。但这种切分过程会导致边界词元无法关注其邻近词元。例如,在块 [a, b, c] 和 [d, e, f] 中,词元 d 无法关注其紧邻的上下文 c。为了解决这个问题,Reformer 在每个块中引入了额外的参数,允许块之间进行一定程度的信息传递,使其能够关注到前一个块的部分或整个邻近的上下文,进而缓解了由于切分带来的信息丢失问题。
Reformer 最重要的贡献是引入局部敏感哈希 (Locality Sensitive Hashing, LSH) 函数,该函数为相似的查询向量分配相同的值。注意力机制可以通过仅比较最相似的向量来近似,这有助于降低维度并对矩阵进行稀疏化。这一个操作基于以下原因,softmax 函数主要由较大的值主导,可以忽略不相似的向量。此外,Reformer 并不是为给定查询找到相关的键,而是找到相似的查询并将它们聚类。也就是说,一个查询的位置只能关注与其具有高余弦相似度的其他查询的位置。
为了减少内存占用,Reformer 模型使用可逆残差层。它不需要存储所有层的激活值,因为任何一层的激活值都可以从下一层的激活值中恢复。
需要注意的是,Reformer 模型和许多其他高效变换器模型一样,只有当输入长度非常长时,它们才比原始 Transformer 更高效。
4.2 实现 Reformer
接下来,我们将实现 Reformer 模型,transformers 库提供了 Reformer 的实现及其预训练权重。
(1) 加载原始权重 google/reformer-enwik8 的配置,并调整一些设置以使其在全自注意力模式下运行。当我们将 lsh_attn_chunk_length 和 local_attn_chunk_length 设置为 16384 (Reformer 可以处理的最大长度)时,Reformer 实例将无法进行局部优化,并像原始 Transformer 一样使用全注意力,我们称之为 fullReformer;对于原始 Reformer,使用默认参数进行实例化,并称之为 sparseReformer:
python
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
fullReformer = ReformerConfig.from_pretrained("google/reformer-enwik8",
lsh_attn_chunk_length=16384,
local_attn_chunk_length=16384)
sparseReformer = ReformerConfig.from_pretrained("google/reformer-enwik8")需要注意的是,Reformer 模型最多可以处理长度为 16384 的序列。但是,如果由于环境中的硬件限制,在全自注意力模式下,注意力矩阵无法完全加载到 GPU 中,会出现 CUDA 内存不足的警告,在这种情况下,可以适当减小最大长度值(例如 12000)。
(2) 接下来,进行基准性能测试:
python
sequence_lengths=[256, 512, 1024, 2048, 4096, 8192, 12000]
models=["fullReformer","sparseReformer"]
configs=[eval(e) for e in models]
benchmark_args = PyTorchBenchmarkArguments(
sequence_lengths=sequence_lengths,
batch_sizes=[1],
models=models)
benchmark = PyTorchBenchmark(
configs=configs,
args=benchmark_args)
results = benchmark.run()输出结果如下所示:
(3) 可视化时间性能结果:
python
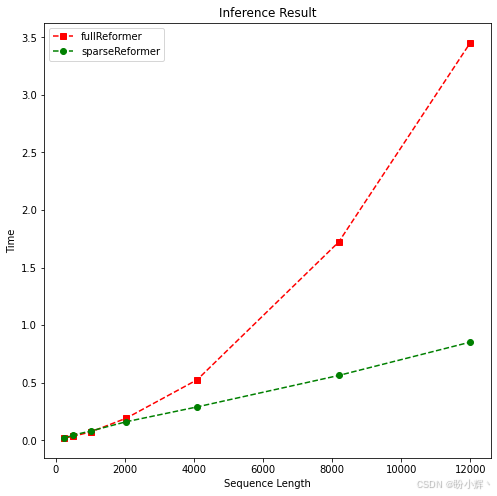
plotMe(results)可视化结果如下所示,可以看到 fullReformer 和原始 Reformer 模型分别呈线性和平方级复杂度:
(4) 观察内存占用情况:
python
plotMe(results,"Memory Footprint")可视化结果如下所示:
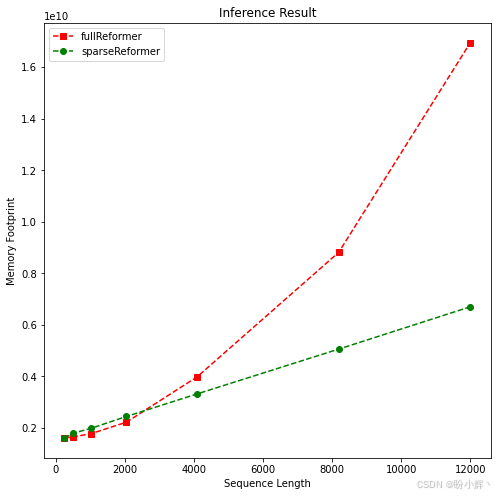
可以看到,使用稀疏注意力的 Reformer 属于轻量级模型。然而,在一定长度范围内难以观察到平方级/线性复杂度。结果表明,高效 Transformer 够缓解长文本处理的时间和内存复杂度。
接下来,我们继续介绍稀疏化之外的其他类型的高效 Transformer 模型。
5. 低秩分解、核方法及其他方法
高效模型的最新趋势是利用全自注意力矩阵的低秩近似。这些模型被认为是最轻量级的,因为它们可以将自注意力的计算时间和内存复杂度从 O ( n 2 ) O(n^2) O(n2) 降低到 O ( n ) O(n) O(n)。通过选择一个非常小的投影维度 k k k (满足 k < < n k<<n k<<n),内存和空间复杂度可以大幅降低。Linformer 和 Synthesizer 是通过低秩分解高效近似完全注意力机制的模型,通过线性投影分解了原始 Transformer 的点积 N × N 注意力矩阵。
核注意力是另一种提高效率的方法,它通过核化视角来看待注意力机制。核函数是一种以两个向量为参数并返回它们在特征空间中投影乘积的函数。它使我们能够在高维特征空间中操作,而无需计算数据在该空间中的坐标,因为在该空间中的计算成本较高。基于核化的高效模型使我们能够重写自注意力机制,避免显式计算 N × N 矩阵。在机器学习领域,支持向量机是经常使用核技巧的算法。在处理非线性问题时,径向基函数核或多项式核等核函数尤为重要。对于 Transformer 来说,最著名的例子包括 Performer 和 Linear Transformers。
小结
在本节中,我们学习了如何在硬件资源受限的情况下减轻运行大模型的负担,介绍了高效的稀疏 Transformer 模型,通过近似技术(如 Linformer、BigBird 和 Performer) 用稀疏矩阵替代全自注意力矩阵。并观察它们在各种基准测试中的表现,例如计算复杂度和内存复杂度。结果表明,这些方法可以在不牺牲性能的情况下将平方级复杂度降低到线性复杂度。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩