论文深度解析:基于大语言模型的城市公园多维度感知解码与公平性提升
原文:Beyond sentiment: Using large language models to decode multidimensional urban park perceptions for enhanced equality
摘要
本文针对城市公园感知测量的精细化不足与公平性评估缺口,提出了一套融合社交媒体数据与大语言模型(LLM)的创新分析框架。通过领域适配微调开发的Park-Perception-LLM模型,实现了对感知可达性、可用性、吸引力三大核心维度83%-91%的高精度分类。将该感知指标创新性地融入增强两步浮动集水区法(E2SFCA),以香港高密度城市为案例,系统揭示了公园质量与数量的空间不平等及错配模式。借助多元回归模型,深入挖掘了公园内部特征、宏观建成环境、微观街道景观及时间因素对感知的影响机制。研究为以公民体验为核心的绿地规划提供了可扩展的数据分析工具,对推动城市宜居性提升与社会公平具有重要理论与实践价值。
1. 引言(Introduction)
1.1 研究背景与核心意义
城市公园作为可持续城市发展的关键绿色基础设施,承担着多重生态与社会功能:改善城市微气候、维护生物多样性、提供休闲游憩空间,同时在促进居民身心健康(Callaghan et al., 2021)、缓解社会隔离(Heine et al., 2025)等方面发挥着不可替代的作用。随着联合国预测2050年全球超三分之二人口将聚居城市,确保所有居民公平获取高质量绿地资源已成为紧迫的全球议题,这与联合国可持续发展目标11.7(为各代人提供安全、包容的公共空间)高度契合。
传统城市公园规划与评估存在显著局限:一方面,规划多依赖"3-30-300"规则(3米宽绿道、30%绿地覆盖率、300米可达距离)等静态量化指标(Konijnendijk, 2023);另一方面,现有可达性评估聚焦公园数量(如面积、距离),却忽视了驱动居民实际使用的多维度质量属性(Battiston & Schifanella, 2024)。尽管部分研究尝试通过遥感数据提取绿地覆盖率、水体占比等客观指标衡量质量,但大量实证表明,客观条件与用户主观体验常存在显著偏差(Liu et al., 2024)。例如,面积相近的两个公园,可能因设施完善度、景观设计、可达便利性等差异,导致居民使用频率与满意度截然不同。这种"重数量、轻质量""重客观、轻主观"的评估模式,难以精准匹配公众需求,阻碍了真正以公民为中心的绿地规划实践。
1.2 研究缺口(Research Gaps)
现有研究在公园感知测量与公平性评估中存在三大核心缺口,构成了本文的研究出发点:
1.2.1 感知测量的维度局限
现有社交媒体数据分析多聚焦单一情感倾向(正面/负面)或视觉内容分类(Ghermandi et al., 2022),未能系统捕捉与城市规划直接相关的多维度感知(如"是否容易到达""设施是否好用""是否愿意主动前往")。尽管LLM在自然语言理解领域展现出强大潜力,但尚未有研究系统验证其在公园多维度感知分类中的性能,缺乏可推广的标准化测量方法。
1.2.2 公平性评估的整合不足
现有研究存在二元分裂:一类仅关注公园感知质量的空间分布(Huai et al., 2023),另一类仅基于公园面积等客观指标评估可达性(Cheng et al., 2019),均未将主观感知与可达性框架深度整合。少数尝试整合的研究,也仅将情感倾向或单一客观属性作为质量代理变量(Zou et al., 2024),无法揭示"高容量低质量""低容量高质量"等复杂空间错配,难以全面反映居民未被满足的需求。
1.2.3 影响机制的研究薄弱
现有研究多将环境变量与单一情感指标关联(Kong et al., 2023),缺乏对多维度感知(可达性、可用性、吸引力)影响因素的系统拆解。同时,宏观建成环境(如周边设施密度)、微观街道景观(如绿视率)、时间因素(如季节、温度)对感知的交互作用尚未被充分揭示,缺乏严谨的统计建模分析,导致规划建议缺乏精准的实证支撑。
1.3 研究目标与核心问题
本文围绕三大核心研究问题展开,旨在填补上述研究缺口:
- 如何融合领域知识微调大语言模型,实现对公园多维度感知(可达性、可用性、吸引力)的高精度、标准化评估?
- 如何构建感知加权的可达性框架,系统揭示公园质量与数量的空间不平等及错配模式?
- 公园内部特征、周边环境及时间因素如何影响多维度感知,其作用机制是什么?
研究通过"模型开发-可达性评估-影响因素分析"的三阶段 workflow(图1),形成完整的分析闭环,为城市公园规划提供数据驱动的决策支持。
2. 研究区域(Study Area)
本文选取香港作为高密度城市案例,其独特的城市特征为研究提供了理想场景:
2.1 区域核心特征
- 人口与空间分布:2023年香港总人口超750万,仅集中在25%的土地上(约278 km²),其余75%为郊野公园及保护区,空间紧凑度极高(C&SD., 2024)。
- 行政与规划背景:香港分为香港岛、九龙、新界三大区域,下辖18个行政区(图2)。空间规划以自上而下为主,新开放空间多布局在商业核心区或高端混合用途区域,普通居民区绿地供给不足,加剧了公园分配的不平等(Tang, 2017)。
- 规划标准局限:现行规划标准仍聚焦人均休闲空间面积等量化指标,对维护水平、使用便利性、景观美学等质性维度关注不足(Sheikh & van Ameijde, 2022)。
- 研究适配性:高密度环境下,公园质量对居民使用决策的影响显著高于距离因素(Wang et al., 2022),亟需突破传统数量导向的规划逻辑,验证感知驱动的评估框架有效性。
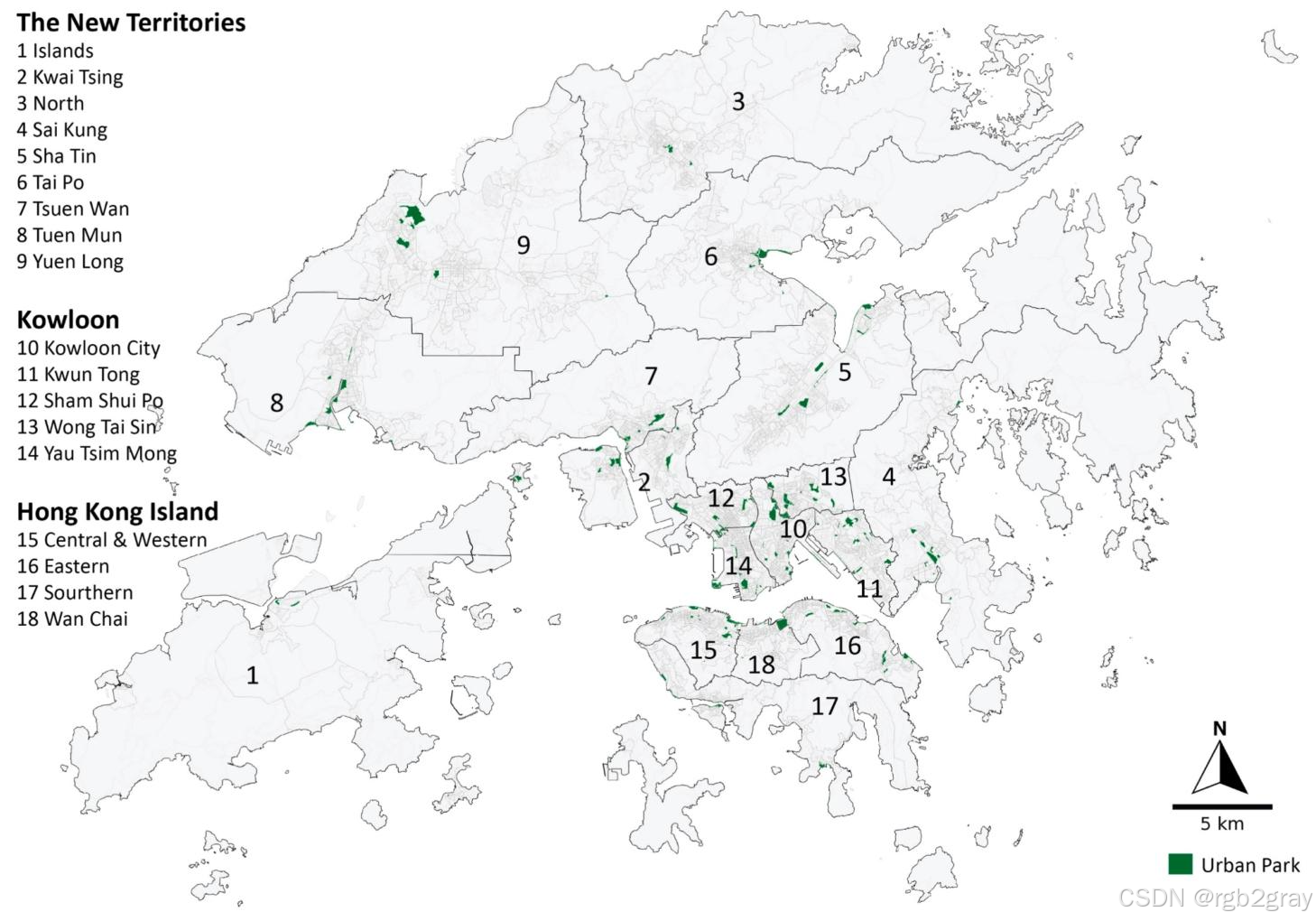
图2 香港18个行政区及158个样本公园的空间分布。黑点代表研究选取的城市公园,可见公园在香港岛、九龙等核心城区分布更为密集,新界部分区域存在明显的绿地供给缺口。
3. 公园感知维度定义(Park Perceptions of Interest)
基于Biernacka & Kronenberg(2018)的绿地供给理论框架,结合区域研究实践(Zhang & Tan, 2019; Zhao et al., 2024),本文定义了三个相互补充的核心感知维度,全面覆盖用户从"到达"到"使用"再到"偏好"的全流程体验:
| 感知维度 | 核心定义 | 关键影响因素 | 实践意义 |
|---|---|---|---|
| 感知可达性(Perceived Accessibility) | 访客对"到达公园难易程度"的主观判断,涵盖距离感知、交通便利性、步行路径舒适度等 | 实际距离、公交/地铁覆盖、步行道条件、感知障碍(如道路阻隔) | 比客观距离更能预测公园使用频率(Wang et al., 2015),是影响使用决策的核心前置因素 |
| 可用性(Usability) | 公园设施满足用户功能需求的程度,聚焦"使用过程中的实用性与舒适度" | 设施类型(卫生间、运动设施等)、设施维护状况、设施充足性、适配性(如儿童/老年友好) | 直接决定用户使用体验与满意度,是提升公园使用频率的关键(Moran et al., 2020) |
| 吸引力(Attractiveness) | 公园的整体魅力与"主动访问意愿",涵盖美学价值、自然体验、文化氛围等 | 景观设计、自然元素(水体、植被)、文化设施、安静度、美学多样性 | 驱动居民自愿前往与停留时长,符合"推-拉"理论中的"拉力因素"(Zhan et al., 2024) |
这三个维度的选择具有明确的理论依据:Biernacka & Kronenberg(2018)将绿地供给分为"可用性(Availability)、可达性(Accessibility)、吸引力(Attractiveness)"三个层次,其中"可用性"已通过传统可达性模型(如距离、容量)捕捉,本文聚焦更能反映主观体验的后三个维度,形成"感知可达性-可用性-吸引力"的完整评估体系。
4. 文献综述(Review of Related Studies)
4.1 景观感知研究的理论基础
景观感知研究源于环境心理学,核心关注人类与环境的互动机制,形成了多个经典理论框架,为本文感知维度的构建提供了坚实的理论支撑:
4.1.1 经典自然景观感知理论
- 注意力恢复理论(Attention Restoration Theory, ART):Kaplan & Kaplan(1989)提出,自然景观通过"远离性(Being Away)、延展性(Extent)、吸引力(Fascination)、兼容性(Compatibility)"四个维度,帮助人类恢复认知资源,缓解精神疲劳。该理论强调自然元素对感知体验的核心作用,为本文"吸引力"维度中自然元素的影响分析提供了理论依据。
- 前景-庇护理论(Prospect--Refuge Theory):Appleton(1975)从进化心理学视角出发,认为人类天生偏好"前景(开阔视野、可观察环境)"与"庇护(安全围合、可躲避风险)"兼具的环境。后续研究将其扩展至"神秘性(Mystery)""视觉复杂性(Visual Complexity)"等维度(Dosen & Ostwald, 2016),为公园景观设计与吸引力评估提供了理论参考。
- 复杂性-唤醒模型(Complexity--Arousal Model):Berlyne(1971)提出,人类对景观的美学偏好与视觉复杂性呈倒U型关系------适度的复杂性能激发最佳唤醒水平(Stimulation),过度简单或复杂则会降低偏好。这一理论解释了为何单调的街道景观会削弱公园吸引力(本文后续实证结果支持该结论)。
4.1.2 建成环境感知研究的延伸
随着研究焦点向城市空间转移,学者们将景观感知理论扩展至建成环境,形成了针对城市公共空间的感知评估框架:
- 步行环境感知维度:Ewing & Handy(2009)通过专家评估识别了步行环境的五大核心感知维度------人性化尺度(Human Scale)、围合感(Enclosure)、透明度(Transparency)、复杂性(Complexity)、可识别性(Imageability),为本文微观街道环境对公园感知的影响分析提供了参考。
- 大规模城市感知评估:Dubey et al.(2016)基于全球街景图像,通过众包方式构建了MIT Place Pulse 2.0数据集,实现了对"安全、美丽、无聊、富裕、压抑、活跃"六大主观感知的大规模量化,证明了通过图像与文本数据量化城市感知的可行性,为本文多源数据融合分析提供了方法借鉴。
4.2 公园感知量化研究的进展与局限
4.2.1 数据来源的演进
- 传统数据采集方法:早期公园感知研究主要依赖结构化问卷、实地访谈与专家评分(Stessens et al., 2020)。这类方法能获取深度质性信息,但存在劳动强度大、成本高、覆盖范围有限等问题,难以实现城市尺度的动态监测。
- 社交媒体数据(SMD)的崛起:随着移动互联网的普及,Google Maps、Instagram、Twitter等平台的地理标记内容(文本评论、图像、位置轨迹)成为感知研究的重要数据来源(Liu et al., 2015)。与传统数据相比,SMD具有实时性、低成本、大样本、高时空分辨率等优势,其中文本数据能直接反映用户主观体验,是挖掘公园感知的理想载体(Li et al., 2024)。
- SMD的局限性:需注意的是,SMD存在显著的代表性偏差------用户多为活跃互联网使用者,老年、儿童、低收入等群体的声音被低估(Hargittai, 2020; Heikinheimo et al., 2020)。这一局限在后续研究设计中需通过数据验证与结果解读加以规避。
4.2.2 自然语言处理(NLP)技术在感知分析中的应用
针对SMD文本数据的分析,形成了两大技术路径,各有优劣:
- 词典法(Lexicon-based Methods):通过将文本中的词汇与预设情感词典(如Liu et al.的情感词典)匹配,统计正负向词汇频率以推断情感倾向(Kong et al., 2022; Tang et al., 2023)。该方法简单高效,但仅能捕捉表面情感,无法理解复杂语义(如 sarcasm、隐喻),也难以实现多维度感知分类。
- 深度学习模型(Deep Learning Models) :
- 早期模型:以LSTM、CNN为代表的模型实现了对文本语义的深层挖掘,但在长文本依赖与复杂语义理解上存在局限。
- Transformer架构模型:BERT(Bidirectional Encoder Representations from Transformers)及其变体(如DeBERTa)通过双向注意力机制,显著提升了长文本处理与语义理解能力,在情感分析、主题分类等任务中表现优于传统模型(Huai et al., 2023; Zhao et al., 2024)。
- 大语言模型(LLMs):以GPT、DeepSeek为代表的生成式LLM,凭借数十亿级参数量与海量互联网训练数据,具备强大的跨领域泛化能力与语义理解能力(Brown et al., 2020)。已有研究证明LLM能从非结构化文本中挖掘细微的理论构念(Ziems et al., 2024),但在公园多维度感知分类中的应用尚属空白,其性能与适配方法亟待验证。
4.3 公园可达性与公平性评估研究现状
4.3.1 可达性评估模型的发展
可达性是衡量公园公平性的核心指标,其评估模型经历了从简单到复杂的演进:
- 距离法:以公园与居住区的直线距离或网络距离为核心指标,如"300米可达圈",方法简单但未考虑公园容量与人口需求。
- 机会指数法:结合公园容量(如面积)与人口数量,计算人均公园面积,但未考虑距离衰减效应。
- 两步浮动集水区法(2SFCA):通过"供给-需求"匹配,考虑距离衰减效应,成为绿地可达性评估的主流方法(Geurs & van Wee, 2004)。
- 增强两步浮动集水区法(E2SFCA):在2SFCA基础上优化了距离衰减函数与供给-需求匹配逻辑,能更好地适应多模式出行与复杂城市形态(Tao et al., 2023),是本文可达性模型的基础。
4.3.2 公平性评估的局限
现有公平性评估存在两大核心问题:
- 质量代理变量单一:多数研究以公园面积、绿地覆盖率等客观指标作为质量代理变量(Cheng et al., 2019; Liang et al., 2023),忽视了主观感知质量;少数研究尝试整合情感倾向(Zou et al., 2024),但未能覆盖多维度感知。
- 空间错配识别不足:现有研究多关注"有无公园""距离远近"的公平性,未能揭示"有公园但质量差""质量高但难以到达"等复杂错配模式,导致规划干预缺乏精准靶点。
4.4 研究缺口总结与本文创新点
综合上述文献分析,本文的创新点的如下:
- 方法创新:系统 benchmark 多类深度学习模型(多模态编码器、单模态文本编码器、LLM),通过领域适配微调开发高精度公园感知分类模型,填补LLM在该领域的应用空白。
- 框架创新:将多维度感知指标融入E2SFCA模型,构建"感知加权"的可达性评估框架,实现质量与数量的整合分析。
- 视角创新:通过双变量LISA分析识别"质量-数量""可达性-人口"双重错配,结合多元回归揭示感知影响机制,为规划干预提供精准实证支撑。
5. 数据与方法(Data & Methods)
本文采用"数据采集-模型开发-可达性评估-影响因素分析"的四阶段研究设计,整体分析框架如图1所示:
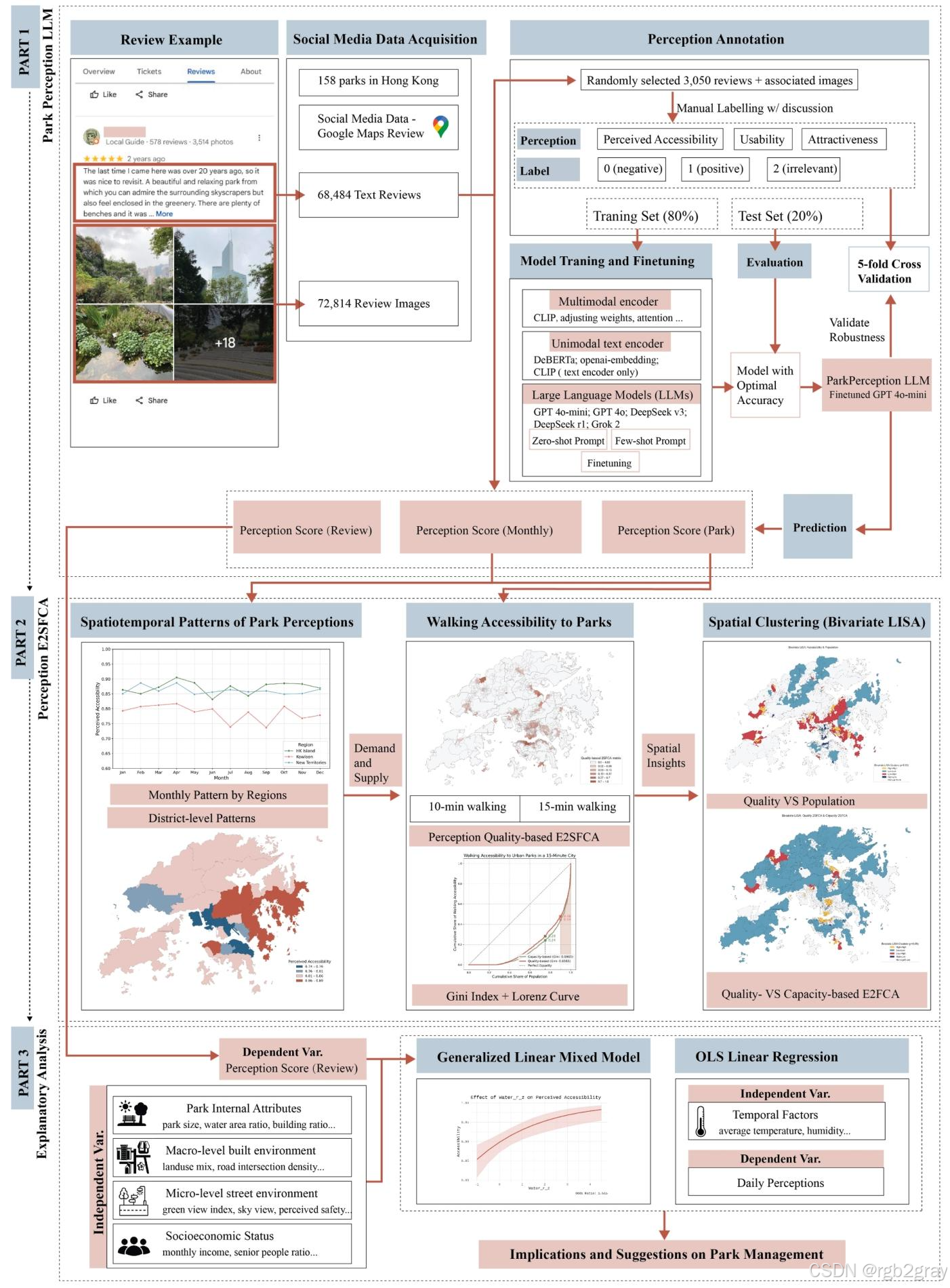
图1 研究整体分析框架,分为三大部分:1)基于社交媒体数据的感知标注与模型微调;2)公园感知时空模式分析与感知加权可达性计算;3)感知影响因素的统计建模,最终形成规划建议。
5.1 数据采集与预处理
5.1.1 公园样本筛选
基于香港地政总署iGeoCom 4.0数据库,提取"休闲设施(RSF)"类别下的"公园(PAR)",经过去重、合并冗余记录后,得到158个官方认可的城市公园(85%面积大于1公顷)。通过Google Places API获取每个公园的唯一place_id,用于后续评论数据采集。
5.1.2 社交媒体数据采集与预处理
- 数据来源:选择Google Maps评论作为核心数据来源------与TripAdvisor等旅游导向平台相比,Google Maps评论与具体场所强关联,更能反映本地居民的日常体验(Huai & Van de Voorde, 2022);且62%的评论由"Local Guides"贡献,用户动机为自愿反馈(无金钱激励),数据真实性较高(Rollison, 2021)。
- 采集周期:2015年1月-2024年12月(10年跨度),确保覆盖长期感知模式与季节变化。
- 数据量:共采集68,484条文本评论与72,814张关联图片。其中2015年后新建的14个公园贡献1,768条评论(占比2.5%),因占比低且采用多年聚合感知指标,对整体结果影响有限。
- 数据预处理:剔除无意义评论(如仅含表情、少于3个单词)、重复评论,最终保留有效文本评论68,484条,详细预处理流程见附录A。
5.1.3 辅助数据采集
为分析感知影响因素,采集多源辅助数据,具体如下表所示:
| 数据类别 | 核心指标 | 数据来源 | 处理方法 |
|---|---|---|---|
| 公园内部属性 | 面积、建筑比例、水域比例、内部道路交叉口密度、景观形状指数(LSI)、设施类型(卫生间、运动设施等) | 香港地政总署iGeoCom 4.0、OSM、Google Places | 空间数据标准化处理,设施类型编码为二元变量(有=1/无=0) |
| 宏观建成环境 | 400米缓冲区内公交站/地铁站密度、POI密度(餐饮、文化、商业等)、土地利用混合度(熵值) | 香港运输署、iGeoCom 4.0、3D网络数据 | 400米缓冲区(5分钟步行距离)内聚合计算,土地利用混合度通过熵值法计算 |
| 微观街道环境 | 绿视率(GVI)、天空开阔度(SVF)、街道感知(安全、美丽、无聊等) | Google街景图像、Place Pulse 2.0数据集 | 每50米采样街景图像,通过Mask2Former模型语义分割提取GVI/SVF;ResNet-50模型预测街道感知评分 |
| 社会经济数据 | 65岁以上人口比例、高等教育比例、家庭月收入中位数 | 2022年香港人口普查(LSUG级别) | 按公园所在区域聚合匹配 |
| 气象数据 | 日均温、降雨量、相对湿度、日照时长、季节 | 香港天文台 | 按日聚合,季节编码为虚拟变量(春/夏/秋/冬) |
5.2 感知标注(Labelling Park Perceptions)
由于缺乏香港公园感知的开源标签数据集,本文采用人工标注方法构建训练集,确保标签的准确性与针对性:
5.2.1 标注流程
- 样本筛选:从68,484条评论中随机抽取3,050条作为标注样本,确保样本覆盖不同公园、不同年份、不同情感倾向。
- 标注规则制定:采用三元编码体系------0=负面(如"交通不便""设施破旧")、1=正面(如"步行可达""卫生间干净")、2=无关(评论内容与该维度无关),针对"感知可达性、可用性、吸引力"三个维度分别标注。
- 标注人员选择:招募4名具有城市规划/设计背景且长期居住香港的专家作为标注员,确保标注员熟悉本地公园情况与专业术语,减少认知偏差。
- 标注一致性保障 :
- 预标注阶段:4名标注员共同标注1,000条重叠样本,针对分歧展开讨论,形成统一编码手册,明确各维度的标注边界(如"停车困难"归为感知可达性负面,"座椅不足"归为可用性负面)。
- 正式标注阶段:剩余2,050条样本由标注员独立标注,对不确定标注(如模糊表述)进行小组讨论决议。
- 一致性检验:通过Cohen's Kappa系数检验标注一致性,三个维度的Kappa系数均大于0.75,表明标注结果可靠。
5.2.2 标注结果统计
最终标注样本中,三个维度的有效标注分布如下:
- 感知可达性:相关评论1,452条(47.6%),其中正面1,218条(83.9%)、负面234条(16.1%);
- 可用性:相关评论2,012条(66.0%),其中正面1,798条(89.4%)、负面214条(10.6%);
- 吸引力:相关评论1,895条(62.1%),其中正面1,478条(77.9%)、负面417条(22.1%)。
5.3 模型微调与选择(Model Fine-tuning and Selection)
本文对比三类共16个模型,通过"零样本-少样本-有监督微调"三阶段训练,筛选最优感知分类模型:
5.3.1 模型类别与参数设置
| 模型类别 | 具体模型 | 核心参数与配置 |
|---|---|---|
| 多模态编码器 | CLIP(4种权重配置) | 基础模型:openai/clip-vit-base-patch16(预训练于4亿图文对);权重配置:文本-图像权重比1:1、2:1、4:1,以及Concat融合 |
| 单模态文本编码器 | CLIP-text、DeBERTa、OpenAI text-embedding-3-large | - CLIP-text:关闭CLIP图像通道,仅使用文本编码器; - DeBERTa:基于Hugging Face开源实现,学习率2e-5; - text-embedding-3-large:OpenAI开源文本嵌入模型,嵌入维度3,072 |
| 大语言模型(LLMs) | 商业模型:GPT-4o-mini、GPT-4o、Grok-2; 开源模型:DeepSeek-v3、DeepSeek-r1 | - GPT-4o-mini:采用2024年7月18日快照版; - 开源模型:基于Hugging Face部署,batch size=4 |
5.3.2 三阶段训练流程
- 零样本学习(Zero-shot Learning):仅通过提示词向模型提供三个感知维度的定义与编码规则(无标注示例),直接让模型对测试集评论进行分类,验证模型的基础泛化能力。
- 少样本学习(Few-shot Learning):在提示词中添加20个标注示例(覆盖正面/负面/无关三类),增强模型对任务的适配性。少样本学习无需重新训练模型,仅通过提示词优化即可提升性能,是成本高效的适配方法(Parnami & Lee, 2022)。
- 有监督微调(Supervised Fine-tuning) :选择少样本学习中表现最优的GPT-4o-mini,在全量标注训练集(3,050条×80%=2,440条)上进行有监督微调,开发定制化模型Park-Perception-LLM。
- 微调参数:epoch=5,batch size=8,学习率乘数=1.8,随机种子=42;
- 微调方式:通过OpenAI API上传jsonl格式训练数据,在远程服务器完成训练(确保数据安全与计算效率)。
模型训练的提示词设计示意图如下:
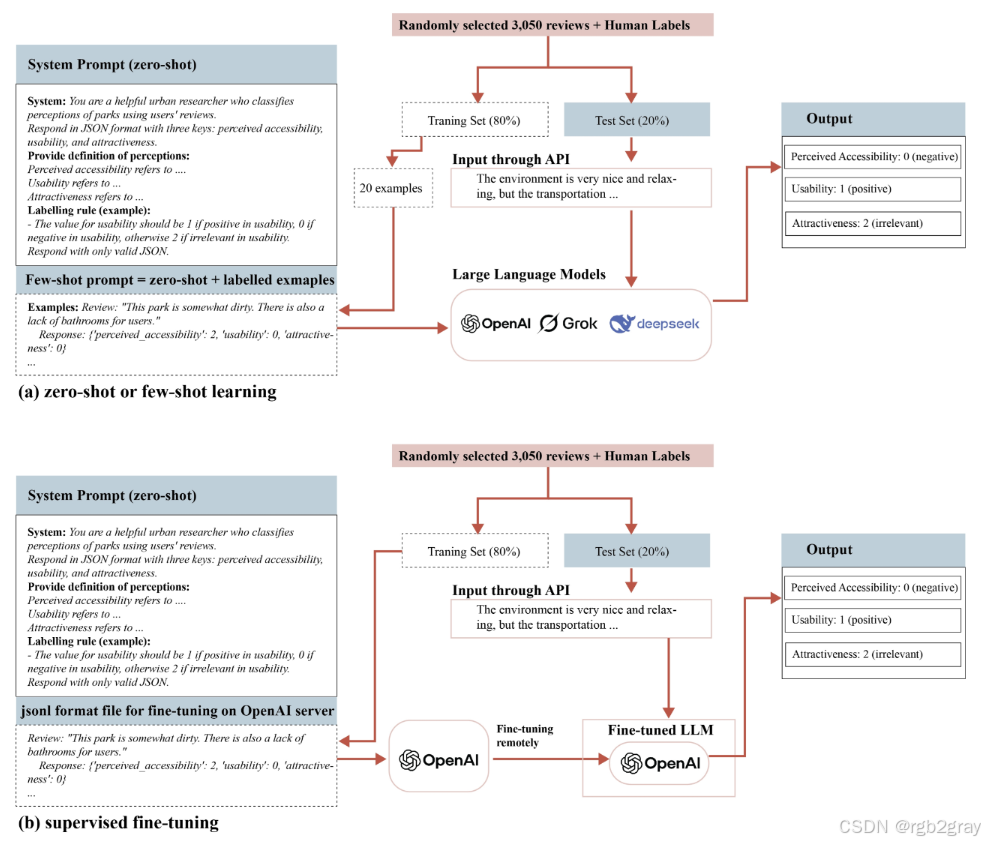
图3 LLM训练提示词设计:(a)零样本/少样本学习通过提示词定义任务与示例;(b)有监督微调将标注数据按jsonl格式上传至OpenAI服务器进行远程训练,确保模型适配领域任务。
5.3.3 模型评估方法
- 核心指标:Top-1准确率(预测类别与人工标注一致的比例),是分类任务的核心评估指标。
- 稳健性验证:对最优模型(Park-Perception-LLM)进行五折交叉验证,将标注样本随机分为5份,轮流以4份为训练集、1份为测试集,评估模型在不同数据分区的性能稳定性。
5.4 感知加权可达性模型(Perception-based Park Accessibility)
本文基于E2SFCA模型,将传统"公园面积"供给指标替换为"多维度感知得分",构建感知加权可达性模型,具体流程如下:
5.4.1 公园感知得分计算
将最优模型Park-Perception-LLM应用于全部68,484条评论,对每个公园的三个感知维度分别计算得分:
Perception Score=Positive ReviewsRelevant Reviews \text{Perception Score} = \frac{\text{Positive Reviews}}{\text{Relevant Reviews}} Perception Score=Relevant ReviewsPositive Reviews
其中,Positive Reviews为该维度下正面评论数,Relevant Reviews为该维度下相关评论数(排除无关评论),得分范围为0-1,越接近1表示感知越好。
对于评论数少于10条的公园(约5%),采用同行政区公园感知均值填充,确保空间分析的完整性。
5.4.2 E2SFCA模型优化与计算
-
供给指标定义 :将三个感知维度得分之和作为公园供给指标(Sj),替代传统面积指标:
Sj=Saccess+Susability+Sattractiveness S_j = S_{\text{access}} + S_{\text{usability}} + S_{\text{attractiveness}} Sj=Saccess+Susability+Sattractiveness其中,SaccessS_{\text{access}}Saccess为感知可达性得分,SusabilityS_{\text{usability}}Susability为可用性得分,SattractivenessS_{\text{attractiveness}}Sattractiveness为吸引力得分。
-
距离衰减函数 :采用指数衰减函数,考虑步行距离对可达性的影响:
Gk,j={e−(12)×(dkd0)−e−(12)1−e−(12),dk≤d00,dk>d0 G_{k,j} = \begin{cases} \frac{e^{-\left(\frac{1}{2}\right) \times \left(\frac{d_k}{d_0}\right)} - e^{-\left(\frac{1}{2}\right)}}{1 - e^{-\left(\frac{1}{2}\right)}}, & d_k \leq d_0 \\ 0, & d_k > d_0 \end{cases} Gk,j=⎩ ⎨ ⎧1−e−(21)e−(21)×(d0dk)−e−(21),0,dk≤d0dk>d0其中,dkd_kdk为社区k到公园入口j的网络距离,d0d_0d0为步行阈值(本文采用800米≈10分钟、1200米≈15分钟,符合"15分钟城市"理念)。
-
供给-需求比计算 :对每个公园入口j,计算其服务范围内的供给-需求比(Rj):
Rj=Sj∑k∈{dk≤d0}Pk×Gk,j R_j = \frac{S_j}{\sum_{k \in \{d_k \leq d_0\}} P_k \times G_{k,j}} Rj=∑k∈{dk≤d0}Pk×Gk,jSj其中,PkP_kPk为社区k的人口数量。
-
社区可达性得分 :对每个社区i,汇总其服务范围内所有公园入口的供给-需求比,得到社区可达性得分(Ai):
Ai=∑p∈{di,p≤d0}Gi,p×Rp A_i = \sum_{p \in \{d_{i,p} \leq d_0\}} G_{i,p} \times R_p Ai=p∈{di,p≤d0}∑Gi,p×Rp其中,di,pd_{i,p}di,p为社区i到公园入口p的网络距离,Gi,pG_{i,p}Gi,p为对应的距离衰减系数。
5.4.3 公平性评估方法
-
洛伦兹曲线与基尼系数 :用于衡量可达性的总体公平性。洛伦兹曲线以累计人口比例为横轴、累计可达性比例为纵轴,偏离45°线越远表示公平性越差;基尼系数取值0-1,越接近1表示公平性越差,计算公式如下:
Gini Index=1−∑i=1n(Pi−Pi−1)×(Ai+Ai−1) \text{Gini Index} = 1 - \sum_{i=1}^n (P_i - P_{i-1}) \times (A_i + A_{i-1}) Gini Index=1−i=1∑n(Pi−Pi−1)×(Ai+Ai−1)其中,PiP_iPi为累计人口比例,AiA_iAi为累计可达性比例。
-
双变量LISA分析:用于识别空间聚类与错配模式:
- 第一类:感知加权可达性与人口密度的双变量LISA,识别"高人口-低可达性""低人口-高可达性"等错配区域;
- 第二类:感知加权可达性与传统容量加权可达性的双变量LISA,识别"高容量-低质量""低容量-高质量"等错配区域。
5.5 感知影响因素分析(Factors Influencing Park Perceptions)
采用"广义线性混合模型(GLMM)+ 普通最小二乘回归(OLS)"的组合,分别分析空间因素与时间因素对感知的影响:
5.5.1 多重共线性检验
首先计算所有自变量的方差膨胀因子(VIF),剔除VIF>10的变量(本文无高多重共线性变量),避免回归结果失真。
5.5.2 广义线性混合模型(GLMM)
- 因变量:评论层面的感知维度(二分类变量:正面=1,负面=0);
- 自变量:公园内部属性、宏观建成环境、微观街道环境、社会经济特征;
- 随机效应:公园标识(Park ID),控制不同公园的个体异质性;
- 链接函数:逻辑斯蒂函数(Logit),适配二分类因变量;
- 模型评估:采用边际R²(Marginal R²,仅固定效应解释力)与条件R²(Conditional R²,固定效应+随机效应总解释力)评估模型拟合度。
5.5.3 普通最小二乘回归(OLS)
- 因变量:日度聚合的感知得分(对数转换,确保正态分布);
- 自变量:气象因素(日均温、降雨量、相对湿度、日照时长)与季节虚拟变量;
- 目的:分析时间因素对感知的影响。
6. 研究结果(Results)
6.1 模型性能对比(Comparison of Model Performances)
6.1.1 各类模型准确率排名
16个模型在三个感知维度的Top-1准确率如下表所示(***表示最优模型):
| 模型类别 | 具体模型 | 感知可达性准确率 | 可用性准确率 | 吸引力准确率 |
|---|---|---|---|---|
| 多模态编码器 | CLIP MHA 1:1 | 0.757 | 0.769 | 0.800 |
| CLIP Concat 1:1 | 0.758 | 0.732 | 0.809 | |
| CLIP MHA 2:1 | 0.754 | 0.763 | 0.794 | |
| CLIP MHA 4:1 | 0.762 | 0.769 | 0.812 | |
| 单模态文本编码器 | CLIP-text encoder | 0.773 | 0.768 | 0.794 |
| DeBERTa | 0.798 | 0.779 | 0.879 | |
| OpenAI text-embedding-3-large | 0.812 | 0.803 | 0.831 | |
| LLMs(零样本) | GPT-4o mini | 0.818 | 0.754 | 0.790 |
| GPT-4o | 0.816 | 0.754 | 0.788 | |
| DeepSeek v3 | 0.818 | 0.727 | 0.739 | |
| DeepSeek r1 | 0.811 | 0.752 | 0.790 | |
| Grok-2 | 0.821 | 0.765 | 0.772 | |
| LLMs(少样本) | GPT-4o mini | 0.850 | 0.757 | 0.827 |
| GPT-4o | 0.832 | 0.754 | 0.844 | |
| DeepSeek v3 | 0.813 | 0.778 | 0.808 | |
| DeepSeek r1 | 0.804 | 0.742 | 0.821 | |
| Grok-2 | 0.824 | 0.785 | 0.819 | |
| LLMs(微调) | Park-Perception-LLM(Fine-tuned GPT-4o mini) | 0.867*** | 0.834*** | 0.911*** |
6.1.2 最优模型稳健性验证
五折交叉验证结果显示,Park-Perception-LLM在三个维度的平均准确率分别为:
- 感知可达性:86.3% ± 1.7%
- 可用性:85.1% ± 1.6%
- 吸引力:88.8% ± 1.4%
与测试集准确率(86.7%、83.4%、91.1%)高度一致,表明模型性能稳定,泛化能力优异。
6.1.3 关键发现
- 单模态文本模型优于多模态模型:CLIP等多模态模型的准确率(73%-81%)低于单模态文本模型与LLM,原因可能是:① 评论图文语义不一致,图像引入噪声;② CLIP模型的文本长度限制(77-token)导致长评论信息丢失。
- LLM性能最优:LLM的零样本准确率(72.7%-82.1%)已优于传统深度学习模型,少样本学习(添加20个示例)进一步提升准确率,有监督微调后达到最优(83.4%-91.1%),验证了领域适配的重要性。
- 吸引力维度分类最易:三个维度中,吸引力的模型准确率最高(最优模型91.1%),可能因吸引力相关评论的语义表达更鲜明(如"风景优美""很吸引人");可用性维度准确率最低(83.4%),可能因设施评价的语义更复杂(如"座椅不够""卫生间较干净但需排队")。
6.2 公园感知特征分析(Analysis of Park Perceptions)
6.2.1 整体感知分布
将Park-Perception-LLM应用于全部68,484条评论,得到三个维度的整体感知分布:
- 感知可达性:21.0%的评论(14,409条)涉及该维度,其中83.9%为正面(12,082条),16.1%为负面(2,327条);
- 可用性:49.8%的评论(34,109条)涉及该维度,其中89.6%为正面(30,558条),10.4%为负面(3,551条);
- 吸引力:83.9%的评论(57,569条)涉及该维度,其中78.0%为正面(44,894条),13.9%为负面(7,902条),8.1%为无关(4,773条)。
整体来看,香港市民对公园的可用性与吸引力评价较高,但对可达性存在显著担忧(负面评论占比16.1%),这与香港高密度城市的交通拥堵、步行路径不连续等问题密切相关。
6.2.2 空间分布模式
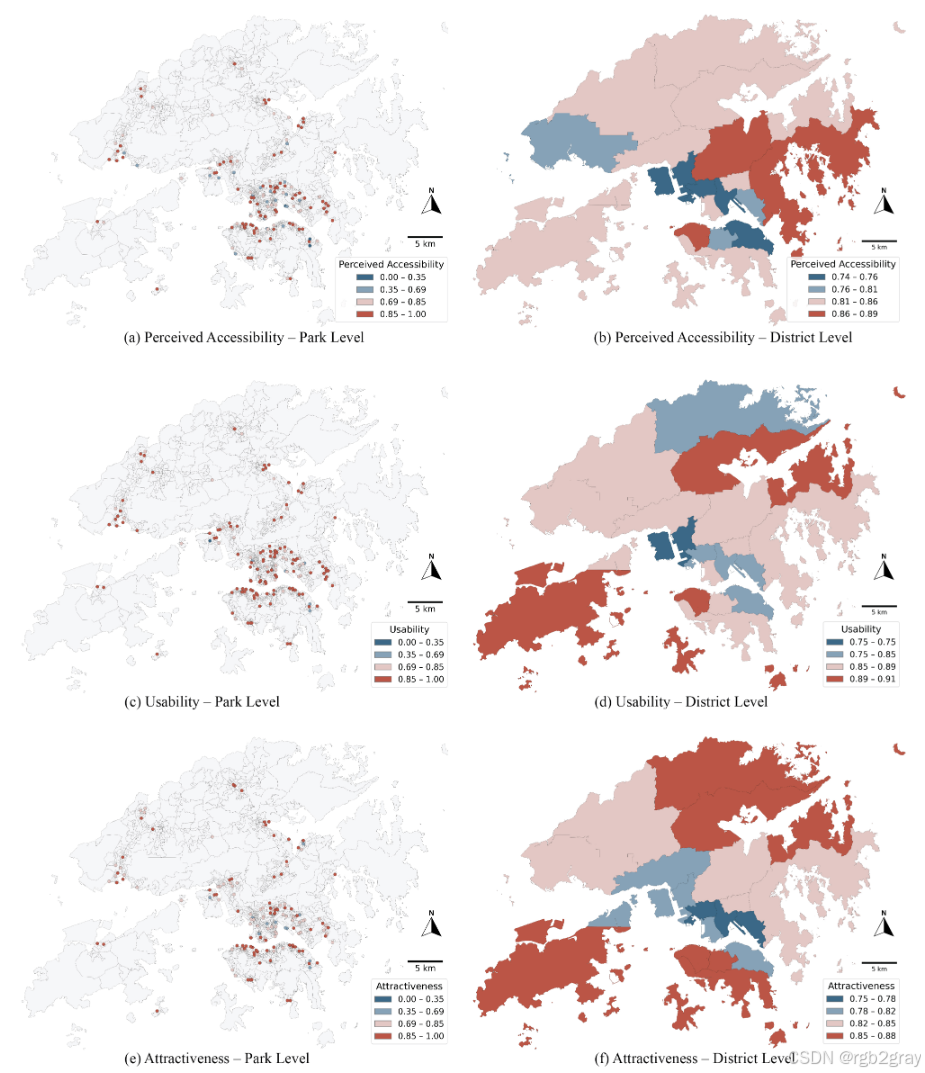
图4 三个感知维度的空间分布:(a)感知可达性:九龙、香港岛及新界西部(屯门)得分较低,主要因这些区域人口密集、交通拥堵、步行路径受道路阻隔;(b)可用性:低分区集中在九龙城、观塘、黄大仙,这些区域公园建成年代较早,设施老化且维护不足;(c)吸引力:低分区集中在九龙及邻近区域(葵青、港岛东区),这些区域公园多为小型社区公园,景观设计单一、自然元素缺乏。
6.3 可达性与公平性分析(Park Accessibility and Equality Analysis)
6.3.1 感知加权可达性空间格局
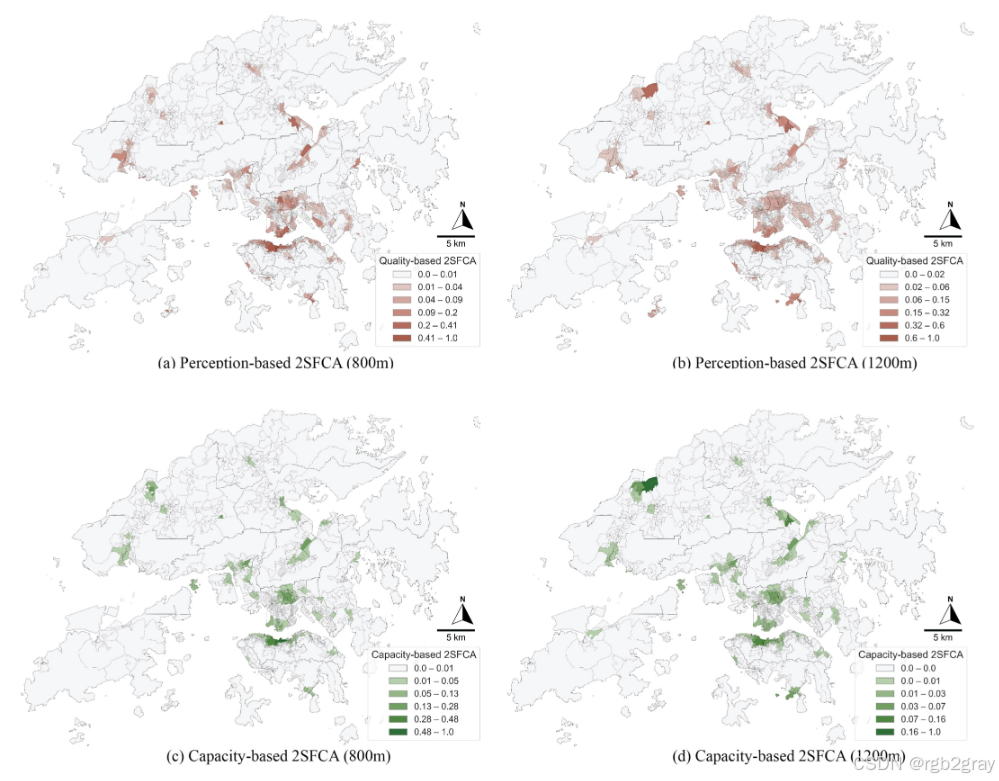
图5 不同步行阈值下的感知加权可达性分布:(a)800米阈值(10分钟步行):高可达性集中在香港岛核心区(中西区、湾仔、东区)及九龙中部(油尖旺、深水埗部分区域),这些区域公园密度高且感知质量好;(b)1200米阈值(15分钟步行):高可达性区域向周边扩展,新界的荃湾、沙田、屯门出现中等可达性口袋,但北部新界仍为低可达性集中区;(c)(d)为传统容量加权可达性分布,与感知加权结果存在局部差异(如部分区域容量高但感知质量低),验证了质量-数量错配的存在。
6.3.2 公平性量化结果
洛伦兹曲线与基尼系数分析显示,香港公园可达性存在严重的空间不平等:
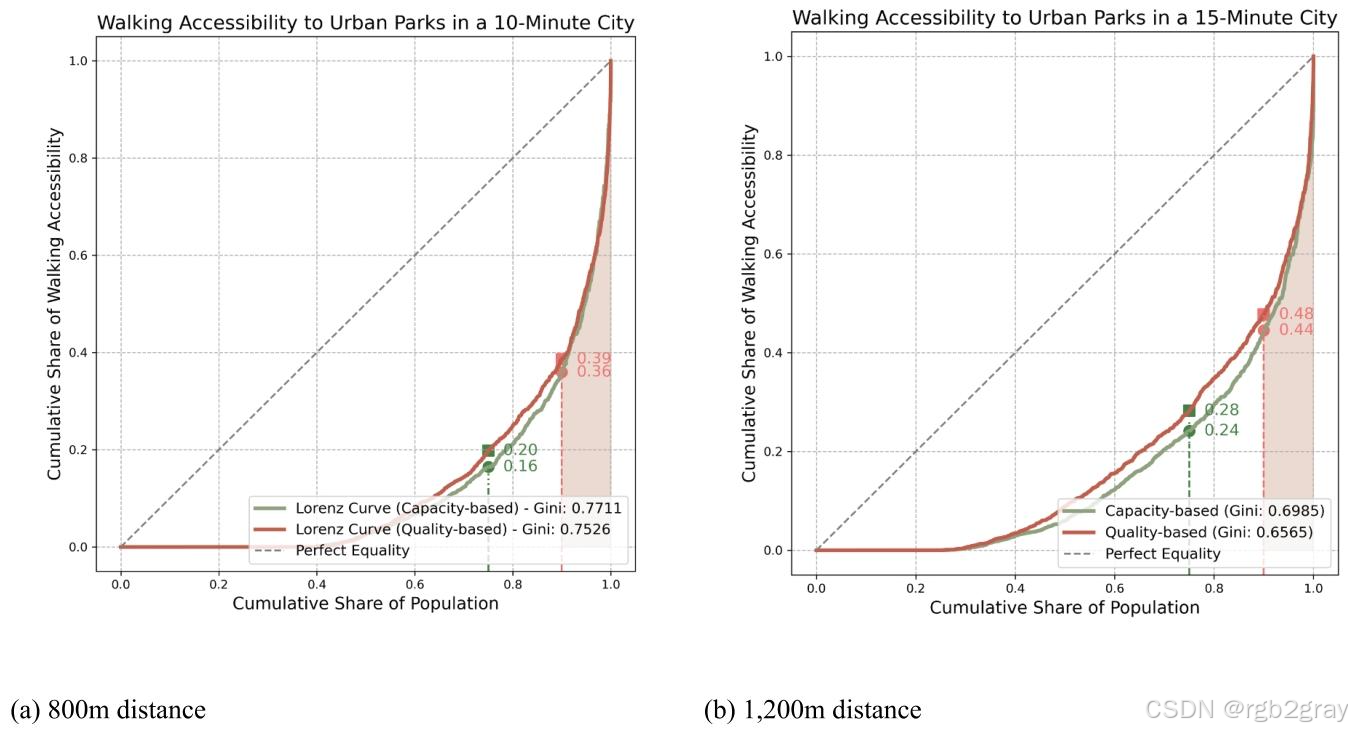
图6 不同阈值下的洛伦兹曲线:(a)800米阈值:前10%的居民占据52.3%的可达性资源,后75%的居民仅占18.7%,基尼系数0.756;(b)1200米阈值:前10%的居民占据59.8%的可达性资源,后75%的居民占29.3%,基尼系数0.656。尽管1200米阈值下公平性略有提升,但整体仍处于高度不平等状态(基尼系数>0.6)。
6.3.3 空间错配分析
- 可达性与人口需求错配(双变量LISA):
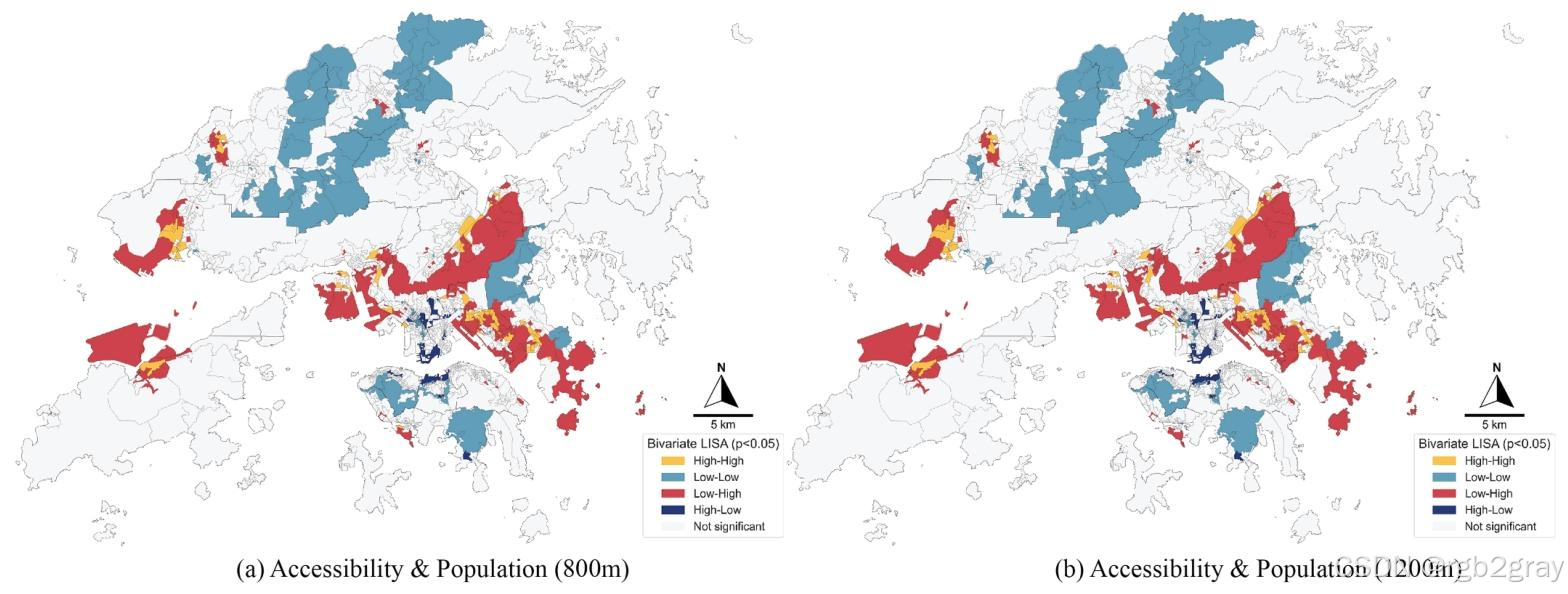
图7 感知加权可达性与人口密度的双变量LISA聚类:
- 高-高聚类:观塘、深水埗、沙田部分区域,公园质量与人口需求匹配,空间协调;
- 低-低聚类:港岛南部、新界北部,低质量+低人口,需整体提升公园供给与质量;
- 低-高聚类:荃湾、屯门、元朗、观塘东部,高人口+低质量,是规划干预的核心靶点,需优先提升公园质量;
- 高-低聚类:港岛南部、屯门部分区域,高质量+低人口,资源利用不足,可通过宣传推广或功能优化提升使用率。
- 质量与容量错配(双变量LISA):
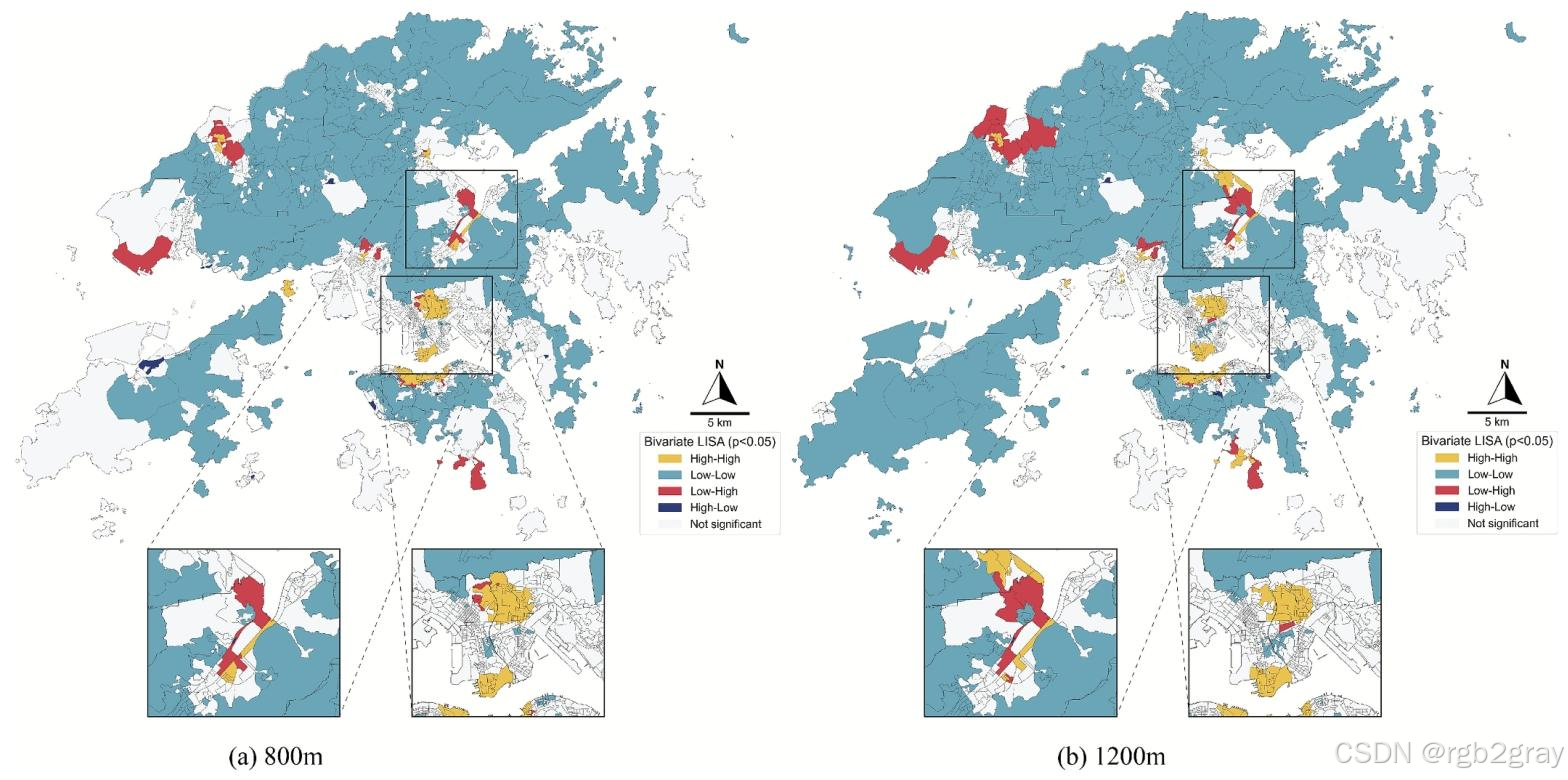
图8 感知加权可达性与容量加权可达性的双变量LISA聚类:
- 低-高聚类:沙田、屯门、元朗,高容量公园(面积大)但低感知质量,主要因设施维护不足、景观设计单一、步行可达性差(如被道路阻隔);
- 高-低聚类:港岛南部、屯门部分区域,低容量公园(面积小)但高感知质量,这类公园多为社区口袋公园,设施完善、景观优美,可作为高密度城市公园规划的典范。
6.4 感知影响因素分析(Impact of Spatial and Temporal Factors)
6.4.1 空间因素影响(GLMM结果)
模型解释力:可用性的条件R²最高(0.369),其次是感知可达性(0.360)与吸引力(0.341),表明公园属性与环境特征能较好地解释感知差异。
三个维度的关键影响因素(显著水平p<0.05)如下:
| 感知维度 | 正向影响因素(系数为正,OR>1) | 负向影响因素(系数为负,OR<1) |
|---|---|---|
| 感知可达性 | 儿童设施(OR=1.645)、现场服务(OR=1.824)、水域比例(OR=1.515)、文化设施密度(OR=1.164)、街景绿视率(OR=1.308)、公园评分(OR=3.194) | 公园面积(OR=0.586) |
| 可用性 | 运动设施(OR=1.181)、卫生间(OR=1.193)、儿童设施(OR=1.509)、现场服务(OR=1.240)、街景绿视率(OR=1.516)、高等教育比例(OR=1.111)、公园评分(OR=3.789) | 土地利用多样性(OR=0.869)、街道美学评分(OR=0.903)、家庭收入(OR=0.886) |
| 吸引力 | 卫生间(OR=1.631)、现场服务(OR=1.083)、建筑比例(OR=1.073)、老年人口比例(OR=1.059)、高等教育比例(OR=1.191)、公园评分(OR=3.451) | 公园面积(OR=0.811)、土地利用多样性(OR=0.835)、无聊感街道(OR=0.860)、高收入家庭密度(OR=0.910) |
关键发现:
- 公园内部设施(儿童设施、卫生间、现场服务)对三个维度均有显著正向影响,是提升感知质量的核心抓手;
- 自然元素(水域比例、街景绿视率)能显著提升感知,验证了注意力恢复理论;
- 公园面积与感知呈负相关,可能因香港大型公园多位于郊区,可达性差且设施维护不足;
- 高收入家庭对公园质量的评价更苛刻(负向影响),表明不同社会经济群体的感知差异需在规划中重点考虑。
6.4.2 时间因素影响(OLS结果)
时间因素对感知的影响如下表所示(***p<0.01,**p<0.05):
| 变量 | 感知可达性(ln) | 可用性(ln) | 吸引力(ln) |
|---|---|---|---|
| 常数项 | -0.0335(不显著) | -0.0816*** | -0.0482** |
| 日均温(℃) | -0.0005(不显著) | -0.0029*** | -0.0044*** |
| 降雨量(mm) | -0.0009(不显著) | -0.0001(不显著) | 0(不显著) |
| 日照时长(h) | 0.0004(不显著) | 0.001(不显著) | 0.0013(不显著) |
| 相对湿度(%) | -0.002(不显著) | 0.0004(不显著) | -0.0001(不显著) |
| 春季(虚拟变量) | 0.0715(不显著) | 0.0049(不显著) | -0.005(不显著) |
| 夏季(虚拟变量) | -0.0456(不显著) | 0.004(不显著) | 0.0052(不显著) |
| 冬季(虚拟变量) | -0.0042(不显著) | -0.0083(不显著) | -0.0308*** |
| R² | 0.085 | 0.011 | 0.017 |
| F统计量 | 2.013(不显著) | 2.138*** | 5.969*** |
关键发现:
- 感知可达性不受时间因素影响,符合其"路径便利性"的核心属性;
- 可用性受温度显著影响(温度升高,可用性下降),可能因高温导致设施使用舒适度降低(如座椅发烫、无遮阳);
- 吸引力受温度与季节显著影响:高温(系数-0.0044)与冬季(系数-0.0308)均会降低吸引力,可能因高温导致景观枯萎、冬季植被多样性下降。
7. 讨论(Discussion)
7.1 微调LLM在公园感知分类中的优势与价值
本文通过三阶段训练验证了LLM在公园多维度感知分类中的卓越性能,其核心优势体现在:
-
语义理解能力强:LLM能捕捉复杂语义表达(如隐喻、 sarcasm),优于传统词典法与BERT类模型。例如,评论"虽然公园很大,但绕了半天才找到入口,太不方便了",LLM能准确识别为"感知可达性负面",而传统模型可能因"很大"误判为正面。
-
领域适配效率高:少样本学习仅需20个标注示例即可实现80%以上的准确率,大幅降低标注成本;有监督微调后准确率进一步提升至83%-91%,验证了LLM的强适配性。
-
应用门槛低:通过OpenAI API即可实现模型微调与推理,无需复杂的本地硬件部署,便于规划从业者与研究者使用。
-
局限性与优化方向:
- 闭源LLM存在可复制性与数据安全问题,未来可 benchmark 开源LLM(如DeepSeek、Llama),构建可复现的分析流程;
- 评论图文语义不一致导致多模态模型性能不佳,未来可优化图像筛选策略(如仅保留与文本强相关的图像),提升多模态融合效果。
7.2 公园感知的影响机制与规划启示
7.2.1 公园内部特征:设施与自然元素是核心
- 设施多样性:儿童设施、卫生间、现场服务对三个感知维度均有显著正向影响,表明公园规划应注重"全人群适配"------不仅要满足普通居民的休闲需求,还要关注儿童、老年人、残障人士等特殊群体的使用需求(如增设无障碍设施、儿童游乐设备)。
- 自然元素:水域比例与街景绿视率的正向影响,验证了注意力恢复理论,提示公园设计应增加自然元素(如人工湖、喷泉、乡土植物),提升景观多样性与生态价值。
- 规模优化:公园面积与感知呈负相关,表明高密度城市应优先发展"小而精"的社区口袋公园,而非追求大规模公园,以提升可达性与使用效率。
7.2.2 周边环境:文化设施与街道景观的协同作用
- 文化设施协同:周边文化设施密度提升感知可达性与可用性,表明公园规划应与文化设施(如图书馆、社区中心)联动布局,形成"公园+文化"的复合空间,提升使用频率。
- 街道景观优化:街景绿视率的正向影响与无聊感街道的负向影响,提示公园周边步行路径的景观设计至关重要------应增加街道绿化、优化步行道铺装、减少单调建筑立面,打造"公园-街道"一体化的优质体验。
7.2.3 时间因素:气候适应性设计不可忽视
- 高温与冬季对可用性、吸引力的负面影响,提示公园规划应注重气候适应性设计:如增设遮阳棚、喷雾降温设施、冬季常绿植物种植、室内活动空间等,提升全季节使用舒适度。
7.3 公平性提升与空间错配治理
7.3.1 核心错配区域治理策略
- 低-高聚类(高人口+低质量):荃湾、屯门、元朗等区域,应优先投入资源提升公园质量------更新老化设施、增加自然元素、优化步行路径,快速响应高密度人口的需求。
- 低-高聚类(高容量+低质量):沙田、元朗的大型公园,应重点改善感知可达性与可用性------增设出入口、优化周边步行道、增加设施类型(如运动设施、卫生间),充分发挥公园容量优势。
- 高-低聚类(高质量+低人口):港岛南部的小型公园,应通过宣传推广、举办社区活动、优化功能定位(如打造亲子主题、康养主题),提升资源利用率。
7.3.2 公平性评估框架优化
本文构建的"感知加权E2SFCA"框架,突破了传统客观指标的局限,能更精准地识别公平性缺口。未来规划应将该框架纳入常规评估体系,定期通过社交媒体数据更新感知指标,实现动态监测与精准干预。
7.4 研究局限性与未来方向
- 感知维度扩展:本文聚焦三个核心维度,未来可增加热舒适度、维护状况、拥挤度等维度,实现更全面的感知评估。
- 数据代表性提升:SMD存在互联网使用者偏差,未来可结合问卷调查、实地访谈,补充老年、儿童等群体的感知数据,提升结果代表性。
- 干预效果评估:未来可采用"前后对比"设计,分析公园改造、政策实施对感知的影响,验证规划干预的有效性。
- 跨区域验证:本文以香港为案例,未来可将框架应用于不同密度、不同文化背景的城市(如纽约、上海、新加坡),验证框架的通用性与适应性。
8. 结论(Conclusion)
本文基于社交媒体数据与大语言模型,构建了城市公园多维度感知分析与公平性评估框架,核心结论如下:
- 模型性能卓越:通过领域适配微调开发的Park-Perception-LLM模型,在感知可达性、可用性、吸引力三个维度的准确率达83%-91%,显著优于传统深度学习模型,为公园感知量化提供了高精度工具。
- 公平性缺口显著:香港公园可达性存在严重空间不平等(基尼系数0.656-0.756),且存在"高人口-低质量""高容量-低质量"等复杂错配模式,需针对性规划干预。
- 影响机制明确:公园内部设施(儿童设施、卫生间)、自然元素(水域、绿视率)、周边文化设施是提升感知的核心因素;高温与冬季会降低可用性与吸引力;高收入群体对公园质量的评价更苛刻。
- 规划启示精准:高密度城市应优先发展"小而精"的社区口袋公园,注重设施多样性与气候适应性设计,联动文化设施布局,通过"感知加权可达性"框架实现动态公平监测。
本文的研究框架与方法可为全球城市公园规划提供参考,助力实现"以公民体验为核心"的绿色空间公平供给,提升城市宜居性与居民生活质量。