Cloudera CDH、CDP、Hadoop大数据+决策模型及其案例
在国内,Hadoop 作为大数据处理的"地基式技术",已广泛应用于金融、政务、农业、医疗、零售等多个领域,并与决策模型 (如机器学习、规则引擎、运筹优化等)深度融合,形成"数据采集---存储---分析---智能决策"的闭环。以下从典型架构、主流决策模型类型 和真实行业案例三方面系统阐述。
一、Hadoop + 决策模型的典型技术架构
国内企业普遍采用 Hadoop 生态 + AI/ML 框架 的混合架构:
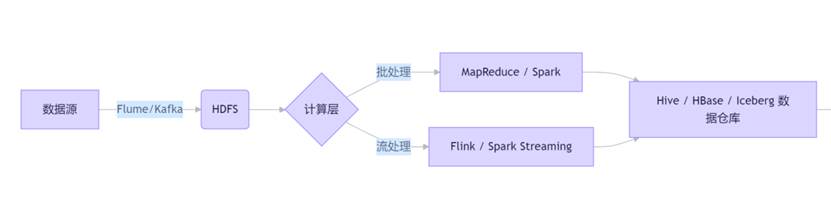

- HDFS:存储原始日志、传感器数据、交易记录等 PB 级非结构化/半结构化数据。
- Spark:取代 MapReduce 成为主流计算引擎,支持 MLlib 机器学习库。
- Hive/Iceberg:构建离线数仓,支撑多维分析。
- 决策模型:部署在 CML(Cloudera Machine Learning)、自研平台或 Python 服务中。
二、主流决策模型类型(结合 Hadoop )
| 模型类型 | 技术实现 | 典型场景 |
|---|---|---|
| 预测模型 | XGBoost, LightGBM, Prophet, LSTM | 销量预测、故障预警、医保支出预测 |
| 分类/ 聚类模型 | K-Means, Random Forest, GBDT | 用户画像、高校分群、病虫害识别 |
| 推荐模型 | 协同过滤(CF)、矩阵分解、DeepFM | 图书/商品/新闻个性化推荐 |
| 规则引擎 | Drools, 自定义规则库 | 风控策略、医保报销审核 |
| 优化模型 | 线性规划、遗传算法 | 物流路径优化、排产调度 |
注:模型训练通常在 Spark on YARN 或 Kubernetes 上进行,特征数据来自 Hive 表。
三、国内典型行业案例
案例1 :北京市医保药品数据分析系统(2026 年热门毕设)
- 数据底座:Hadoop HDFS + Spark SQL
- 决策模型:
- 药品价格影响因素回归分析(线性回归)
- 药品聚类(K-Means)识别"高性价比药品"
- 医保报销策略规则引擎(基于政策文件)
- 价值:辅助医保局制定目录调整、控费策略,防止过度用药。
- 技术栈:Python + Django + Vue + ECharts
案例2 :山东智慧农业合作社
- 数据底座:HDFS 存储田间传感器、气象站、卫星图像(日均 10GB)
- 决策模型:
- 土壤湿度预测 → 动态灌溉决策
- 病虫害图像识别(CNN)→ 精准施药建议
- 玉米产量预测(时间序列模型)→ 提前3个月预判收成
- 执行:通过 MapReduce 并行计算每块地的平均湿度,YARN 调度任务。
- 效果:节水 20%,减药 15%,产量提升 8%。
案例3 :当当网图书推荐系统
- 数据底座:Hadoop + Spark
- 决策模型:协同过滤推荐算法(User-Based CF)
- 流程:
- Flume 采集用户浏览、购买、收藏日志 → HDFS
- Spark 清洗数据,构建"用户-图书"评分矩阵
- 训练 CF 模型,生成 Top-N 推荐列表
- 结果存入 MySQL,前端实时展示
- 扩展:后续加入价格预测模型(回归)。
案例4 :霸王茶姬订单智能分析系统
- 数据底座:Hadoop HDFS + Spark
- 决策模型:
- 城市/门店销量预测(Prophet 或 ARIMA)
- 产品热度聚类 → 识别爆款组合
- 消费时段分析 → 优化人力排班
- 输出:数据大屏展示"区域金额排名""小时销售趋势",指导门店运营。
案例5 :懂车帝二手车估值模型
- 数据底座:HDFS + Spark SQL
- 决策模型:
- 多元线性回归分析价格影响因素(里程、年份、品牌)
- 品牌竞争力聚类(K-Means)
- 用户行为分群(RFM 模型)
- 价值:为卖家提供合理定价建议,为买家揭示市场公允价。
案例6 :高校教育资源均衡分析系统
- 数据底座:Hadoop + Spark
- 决策模型:
- K-Means 聚类:将全国高校划分为"研究型""应用型""职业型"等群体
- 区域资源分布热力图 → 识别教育洼地
- "双非"潜力高校挖掘(基于师资、科研指标)
- 用户:考生择校、教育部门政策制定。
四、实施关键点与挑战
- 数据质量:原始日志需清洗、打标,否则"垃圾进,垃圾出"。
- 特征工程:80% 工作量在于从 Hive 表中提取有效特征。
- 模型可解释性:政务、金融场景要求模型结果可追溯(如 SHAP 值)。
- 闭环反馈:决策结果需回流至业务系统,并用于下一轮模型迭代。
- 国产化适配:越来越多项目要求运行在麒麟 OS + 鲲鹏 CPU + GaussDB 元数据存储上。
总结
国内 Hadoop + 决策模型的应用已从"技术验证"走向"业务赋能"。其核心逻辑是:以 Hadoop 构建可靠、低成本的数据湖,以 Spark/MLlib 实现高效模型训练,最终通过可视化或 API 将智能决策嵌入业务流程 。无论是政府治理、农业生产还是商业运营,这一范式正成为数字化转型的标配。未来,随着 Hadoop 与 AI 大模型(如华为盘古)的融合,决策将从"预测"迈向"生成"与"自主优化"。