这篇论文提出了一种名为 Restormer 的高效 Transformer 模型,专门用于高分辨率图像恢复任务。核心目标是解决传统 Transformer 在图像恢复中计算复杂度随空间分辨率二次增长的问题,同时保留其捕捉长程像素依赖的优势,最终在多种图像恢复任务中实现 state-of-the-art(SOTA)性能。以下是从头到尾的详细总结:
一、研究背景与问题
- 图像恢复的核心挑战 :图像恢复(去雨、去模糊、去噪等)需从退化图像中重建高质量图像,因问题的不适定性,需依赖强图像先验。传统方法效果有限,而卷积神经网络(CNNs)虽能从大规模数据中学习泛化先验,但存在两大缺陷:
- 感受野有限,无法建模长程像素依赖;
- 卷积核权重固定,难以自适应输入内容。
- Transformer 的优势与局限 :Transformer 的自注意力(SA)机制可捕捉长程依赖且自适应内容,在自然语言和高层视觉任务中表现出色。但 SA 的计算复杂度随空间分辨率二次增长
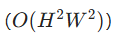 ,无法直接应用于高分辨率图像恢复。
,无法直接应用于高分辨率图像恢复。 - 现有改进的不足:部分方法通过限制 SA 在局部窗口(如 8×8 像素)或非重叠补丁(如 48×48)中计算以降低复杂度,但违背了 SA 捕捉全局依赖的核心目标,难以满足高分辨率图像恢复需求。

二、核心贡献
论文的三大核心创新的模块与策略,既保证效率又兼顾全局依赖建模:
- Restormer 架构:一种编解码器 Transformer,无需将高分辨率图像拆分为局部窗口,即可实现多尺度局部 - 全局特征学习,充分利用远距离图像上下文。
- 多深度卷积头转置注意力(MDTA):线性复杂度的注意力模块,通过跨特征通道计算协方差生成注意力图,而非直接建模像素间成对交互,同时融入深度卷积增强局部上下文。
- 门控深度卷积前馈网络(GDFN):改进传统前馈网络,加入门控机制筛选有用特征,结合深度卷积编码局部结构,控制信息流向以优化特征转换。
- 渐进式学习策略:训练初期用小补丁 + 大批次,后期逐步增大补丁尺寸并减小批次,兼顾全局统计学习与训练效率,提升模型在不同分辨率图像上的泛化能力。
三、方法细节
1. 整体架构
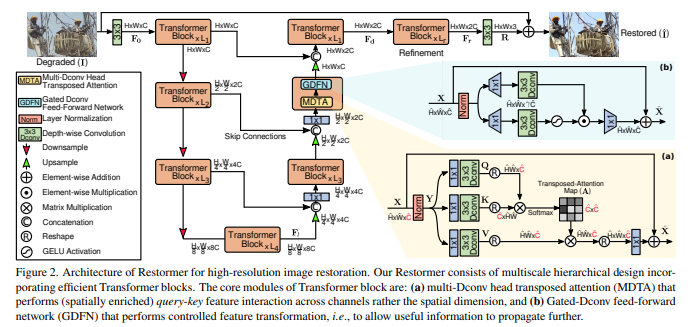
Restormer 采用 4 级对称编解码器结构,流程如下:
- 输入退化图像
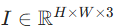 ,经卷积得到低维特征嵌入
,经卷积得到低维特征嵌入 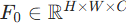
- 编码器通过像素重排(pixel-unshuffle)逐步降低空间尺寸、扩大通道数,解码器通过像素重排逆操作(pixel-shuffle)恢复高分辨率,编解码器特征通过跳跃连接(skip connection)融合(融合后用 1×1 卷积降维);
- refinement 阶段进一步富集高分辨率特征,最终通过卷积生成残差图像 R,恢复图像
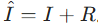 。
。 - 编解码器各层的 Transformer 块数量从顶层到底层逐步增加(如 1→2→4→8),平衡效率与特征表达能力。
2. 核心模块
- MDTA(多深度卷积头转置注意力)
- 核心设计:将 SA 的计算维度从 "空间维度" 转移到 "特征通道维度",复杂度降至线性(O(HCW))。
- 流程:
- 对层归一化后的特征 Y,通过 1×1 卷积聚合跨通道上下文,再通过 3×3 深度卷积编码局部空间上下文,生成查询(Q)、键(K)、值(V);
- 重塑 Q、K 为
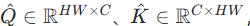 计算转置注意力图
计算转置注意力图 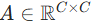 (而非传统
(而非传统 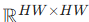 的大矩阵);
的大矩阵); - 注意力计算:
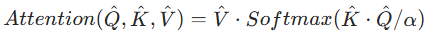 (α 为可学习缩放参数),最后通过 1×1 卷积投影并残差连接输入。
(α 为可学习缩放参数),最后通过 1×1 卷积投影并残差连接输入。
- GDFN(门控深度卷积前馈网络)
- 改进传统前馈网络(FN)的两点:
- 门控机制:通过两条并行路径(一条经 GELU 激活)的逐元素乘积筛选特征,抑制无效信息;
- 深度卷积:融入 3×3 深度卷积增强局部空间上下文建模。
- 公式:
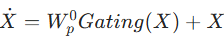
其中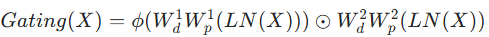 (ϕ 为 GELU 激活,LN 为层归一化)。
(ϕ 为 GELU 激活,LN 为层归一化)。
- 改进传统前馈网络(FN)的两点:
- 渐进式学习
- 训练策略:初期用 128×128 补丁、大批次;后期逐步增大补丁至 384×384,同时减小批次,保证每步优化时间与固定补丁训练相当。
- 核心目的:让模型先学习简单局部特征,再逐步掌握复杂全局统计,提升对高分辨率图像的恢复能力。
四、实验与结果
1. 实验设置
- 任务覆盖:图像去雨、单图运动去模糊、散焦去模糊(单图 + 双像素数据)、图像去噪(高斯灰度 / 彩色去噪、真实图像去噪);
- 基准数据集:16 个数据集(如 GoPro、SIDD、DND、Urban100 等);
- 评价指标:峰值信噪比(PSNR)、结构相似性(SSIM),以及计算量(FLOPs)和推理速度。
2. 核心结果

Restormer 在所有任务中均实现 SOTA 性能,关键对比:
- 去模糊(GoPro 数据集):PSNR 高于 MPRNet(CVPR21)、IPT(CVPR21)等方法,同时 FLOPs 更优;
- 去雨(HIDE 数据集):PSNR 达到 32.44 dB,显著优于 SOTA 方法;
- 高斯去噪(Urban100,σ=50):灰度去噪 PSNR 28.33 dB,比 DRUNet(TPAMI21)高 0.37 dB,比 SwinIR(ICCVW21)高 0.31 dB;彩色去噪 PSNR 30.02 dB,比 DRUNet 高 0.41 dB;
- 真实去噪(SIDD/DND 数据集):唯一 PSNR 突破 40 dB 的方法(SIDD 40.02 dB,DND 40.03 dB),且无需额外训练数据;
- 效率优势:与 SwinIR 相比,Restormer 的 FLOPs 减少 3.14 倍,推理速度快 13 倍。
3. 消融实验验证
- MDTA 的贡献:比基线注意力模块提升 0.32 dB,深度卷积的局部上下文建模可避免 PSNR 下降;
- GDFN 的贡献:比传统 FN 提升 0.26 dB,门控机制与深度卷积均为关键;
- 渐进式学习:比固定补丁训练提升 0.07 dB,且训练时间相当;
- 架构设计:decoder 的 concat 操作和 refinement 阶段可进一步提升 0.09 dB,有助于保留细纹理细节。
五、结论
Restormer 通过 MDTA、GDFN 和渐进式学习三大创新,解决了 Transformer 在高分辨率图像恢复中的效率瓶颈。该模型在 16 个基准数据集的 4 类图像恢复任务中均实现 SOTA 性能,且兼顾计算效率与推理速度,为高分辨率图像恢复提供了高效可行的解决方案。代码和预训练模型已开源(https://github.com/swz30/Restormer)。