本位旨在全面掌握 YOLO 模型的四大核心部署格式(PyTorch 模型、ONNX 格式、TensorRT 引擎、TFLite 格式),本文将从格式特性、适用场景、转换实操、推理部署、优劣对比五个维度展开,以 YOLOv8 为例(v5 通用),兼顾落地性与技术细节,帮助你根据部署场景选择最优格式。
核心逻辑
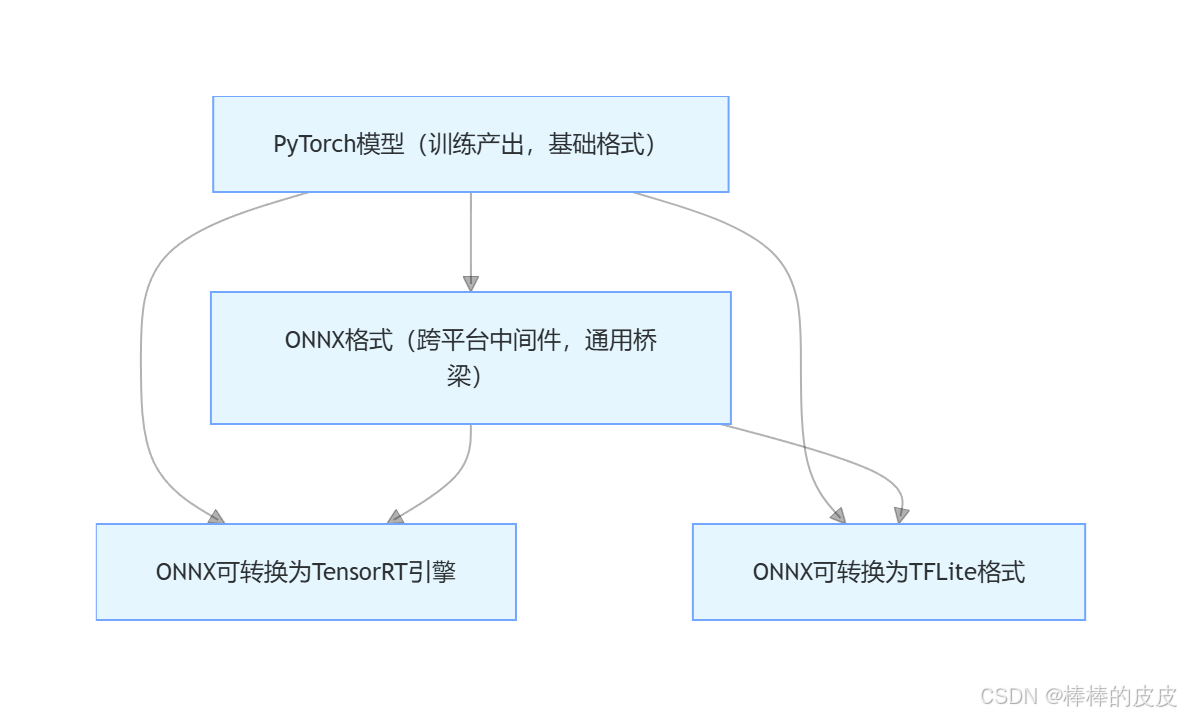
不同部署格式的设计初衷与硬件适配性差异显著,选择的核心原则是「场景适配优先、轻量化随行、精度损失可控(≤3%)」,格式间的转换与选型流程如下:
一、 PyTorch 模型(.pt/.pth)
1. 核心特性
- 本质:YOLO 训练过程中产出的原生模型格式(PyTorch 框架专属),存储了模型的网络结构、权重参数、优化器状态(部分)等信息;
- 精度:默认采用 FP32(32 位浮点数)存储,无精度损失,完全保留训练成果;
- 依赖:强依赖 PyTorch 框架,无法脱离 Python 环境与 PyTorch 库运行;
- 用途:主要用于「训练续跑、模型微调、格式转换、快速验证」,而非生产环境部署。
2. 适用场景
- 训练后的模型效果快速验证(无需格式转换);
- 模型二次微调、剪枝、知识蒸馏等后续优化;
- 作为原始模型转换为其他部署格式(ONNX/TensorRT/TFLite)的输入源;
- 非生产环境的桌面端演示(无严格实时性要求)。
3. 实操相关(训练导出 + 快速推理)
(1) 获得 PyTorch 模型
YOLO 训练完成后,会在runs/detect/train/weights目录下生成两个核心模型文件:
# 训练命令(产出.pt模型)
yolo detect train model=yolov8s.pt data=data.yaml epochs=50 batch=16 device=0
best.pt:验证集指标最优的模型(泛化能力最强,优先用于格式转换与部署);last.pt:最后一轮训练结束的模型(可能过拟合,仅用于续跑训练)。
(2) PyTorch 模型快速推理(验证效果)
from ultralytics import YOLO
# 加载.pt模型
model = YOLO("runs/detect/train/weights/best.pt")
# 推理(CPU/GPU自动适配,有GPU优先使用GPU)
results = model.predict(
source="test.jpg", # 输入源:图片/视频/文件夹/摄像头
imgsz=640, # 输入尺寸(32的倍数)
conf=0.3, # 置信度阈值
save=True # 保存预测结果
)
4. 优劣对比
| 优势 |
劣势 |
| 1. 无精度损失,完全保留训练成果;2. 操作简单,无需格式转换,快速验证;3. 支持后续模型优化(微调 / 剪枝 / 蒸馏);4. 自动适配 CPU/GPU,无需额外配置。 |
1. 强依赖 PyTorch 与 Python 环境,部署灵活性差;2. 推理速度慢(无专门优化,计算效率低);3. 模型体积较大(FP32 存储),占用内存 / 显存高;4. 不支持嵌入式 / 移动端等轻量化平台部署。 |
二、 ONNX 格式(.onnx)
1. 核心特性
- 本质:开放神经网络交换格式(Open Neural Network Exchange),跨框架、跨平台的「中间件格式」,是连接训练框架(PyTorch/TensorFlow)与部署框架(TensorRT/OpenVINO)的核心桥梁;
- 精度:支持 FP32(无精度损失)、FP16(精度损失≤1%,体积减半),不原生支持 INT8(需额外校准);
- 依赖:依赖 ONNX Runtime 推理框架,支持跨语言(Python/C++/Java)、跨硬件(CPU/GPU/ 嵌入式);
- 用途:生产环境通用部署、格式转换中间载体、跨平台推理落地。
2. 适用场景
- 通用桌面端 / 服务器部署(无专属 GPU 加速需求);
- Intel CPU / 集成显卡部署(搭配 OpenVINO 框架,提速显著);
- 作为转换为 TensorRT/TFLite 格式的中间文件;
- 对部署灵活性要求高的场景(需跨硬件、跨语言运行)。
3. 实操相关(模型转换 + 推理部署)
(1) YOLO 一键转换为 ONNX 格式
# 方案1:导出FP32格式(无精度损失,通用兼容)
yolo export model=best.pt format=onnx imgsz=640 simplify=True
# 方案2:导出FP16格式(速度更快,体积减半,仅支持GPU)
yolo export model=best.pt format=onnx imgsz=640 half=True device=0 simplify=True
- 关键参数说明:
simplify=True:简化 ONNX 模型结构,去除冗余节点,提升推理速度;half=True:导出 FP16 格式,需指定device=0(GPU),仅支持 NVIDIA GPU 推理;imgsz:必须为 32 的倍数(YOLO 要求),否则会导致推理错误。
(2) ONNX 模型推理(基于 ONNX Runtime)
import cv2
import onnxruntime as ort
import numpy as np
# 1. 图像预处理(符合YOLOv8要求)
def preprocess(img_path, imgsz=640):
img = cv2.imread(img_path)
# 缩放+黑边填充,保持长宽比
scale = min(imgsz / img.shape[1], imgsz / img.shape[0])
new_w, new_h = int(img.shape[1] * scale), int(img.shape[0] * scale)
resized_img = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
input_img = np.zeros((imgsz, imgsz, 3), dtype=np.uint8)
input_img[:new_h, :new_w, :] = resized_img
# 格式转换:BGR→RGB、HWC→CHW、归一化[0,1]、添加批次维度
input_img = cv2.cvtColor(input_img, cv2.COLOR_BGR2RGB).transpose(2, 0, 1)
input_img = input_img.astype(np.float32) / 255.0
return np.expand_dims(input_img, axis=0), img, scale
# 2. 加载ONNX模型并推理
onnx_path = "best.onnx"
# 配置推理提供者(GPU优先,无GPU自动降级为CPU)
providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
sess = ort.InferenceSession(onnx_path, providers=providers)
input_name = sess.get_inputs()[0].name
# 3. 执行推理与结果输出
input_img, raw_img, scale = preprocess("test.jpg")
outputs = sess.run(None, {input_name: input_img})
print(f"ONNX推理完成,输出结果形状:{outputs[0].shape}")
4. 优劣对比
| 优势 |
劣势 |
| 1. 跨框架、跨平台兼容(支持 PyTorch/TensorFlow→各种部署硬件);2. 推理速度较 PyTorch 提升 20%-30%(FP32)/50%(FP16);3. 无额外精度损失(FP32),FP16 精度损失可控(≤1%);4. 支持简化优化,去除冗余节点,降低推理延迟。 |
1. 仍依赖 ONNX Runtime 框架,无法完全脱离推理库;2. 对嵌入式 / 移动端的适配性不如 TFLite;3. INT8 量化需额外校准,操作复杂度高于 TensorRT/TFLite;4. 无法充分利用 NVIDIA GPU 的极致算力(弱于 TensorRT)。 |
三、 TensorRT 引擎(.engine)
1. 核心特性
- 本质:NVIDIA 专属的推理引擎格式,基于 TensorRT 框架对模型进行「图优化、层融合、量化」等极致优化,最大化 NVIDIA GPU 的算力利用率;
- 精度:支持 FP32(无精度损失)、FP16(精度损失≤1%)、INT8(精度损失≤3%),其中 FP16/INT8 是生产环境主流选择;
- 依赖:仅支持 NVIDIA GPU(RTX 30/40 系列、Tesla T4/V100、Jetson 系列),依赖 TensorRT 框架与对应版本 CUDA/cuDNN;
- 用途:NVIDIA GPU 平台的高性能、低延迟推理部署(实时性要求高的场景)。
2. 适用场景
- 高性能 NVIDIA GPU 服务器部署(实时监控、视频流分析、自动驾驶);
- NVIDIA Jetson 系列嵌入式设备(Xavier NX/Orin NX,边缘端实时推理);
- 对推理延迟要求严格的场景(≤30ms)、批量高并发推理;
- 追求 GPU 算力极致释放的生产环境(替代 ONNX,进一步提速)。
3. 实操相关(模型转换 + 推理部署)
(1) YOLO 一键转换为 TensorRT 引擎
# 方案1:导出FP16格式(主流,平衡速度与精度,支持大部分GPU)
yolo export model=best.pt format=engine imgsz=640 half=True device=0 simplify=True
# 方案2:导出INT8格式(极致轻量化,需提供数据集校准,Jetson设备首选)
yolo export model=best.pt format=engine imgsz=640 int8=True data=data.yaml device=0
- 关键参数说明:
device=0:必须指定 GPU 设备,TensorRT 不支持 CPU 转换与推理;int8=True:需提供data.yaml(校准数据集),自动完成量化校准,无需额外操作;imgsz:固定输入尺寸(转换后不可修改),需根据业务场景提前确定(推荐 640/480)。
(2) TensorRT 引擎推理(基于 Ultralytics 封装,简化开发)
from ultralytics import YOLO
# 加载.engine模型(仅支持NVIDIA GPU)
model = YOLO("best.engine")
# 极致性能推理(开启流式推理,降低延迟,支持视频流/摄像头)
results = model.predict(
source="test.mp4", # 实时视频流输入
imgsz=640,
conf=0.3,
iou=0.45,
device=0,
stream=True # 流式推理,逐帧处理,降低显存占用与延迟
)
# 遍历流式推理结果
for result in results:
boxes = result.boxes # 检测框信息
print(f"检测框坐标:{boxes.xyxy},置信度:{boxes.conf}")
4. 优劣对比
| 优势 |
劣势 |
| 1. NVIDIA GPU 极致提速,较 ONNX 快 50%-100%(FP16)/100%-200%(INT8);2. 支持层融合、图优化、量化等多种优化,推理延迟最低;3. 模型体积小(INT8 格式仅为 PyTorch 的 1/4),显存占用低;4. YOLO 一键转换,无需复杂手动优化,落地便捷。 |
1. 排他性强,仅支持 NVIDIA GPU,不兼容 Intel/AMD 硬件;2. 输入尺寸固定,转换后无法修改(需重新转换);3. 依赖 TensorRT/CUDA/cuDNN 版本匹配,环境配置复杂;4. INT8 量化有轻微精度损失(≤3%),对部分高精度场景不适用。 |
四、 TFLite 格式(.tflite)
1. 核心特性
- 本质:Google 推出的轻量化推理格式,专为移动端、嵌入式设备优化,支持低算力、低功耗、离线推理;
- 精度:支持 FP32(无精度损失)、FP16(精度损失≤1%)、INT8(精度损失≤3%),INT8 是移动端 / 嵌入式主流选择;
- 依赖:支持 Android/iOS 移动端、树莓派、低功耗嵌入式设备,依赖 TFLite 推理框架(支持 NNAPI/ANE 硬件加速);
- 用途:端侧离线推理部署(隐私保护、无网络依赖、低功耗运行)。
2. 适用场景
- Android/iOS 移动端 APP 部署(手机 / 平板,端侧智能检测);
- 低功耗嵌入式设备(树莓派、Arduino、低算力开发板);
- 对隐私保护要求高的场景(数据不上云,端侧本地处理);
- 低功耗、便携化部署场景(电池供电设备,如智能手环、便携式检测仪)。
3. 实操相关(模型转换 + 推理部署)
(1) YOLO 一键转换为 TFLite 格式
# 方案1:导出INT8格式(移动端/嵌入式主流,极致轻量化、低功耗)
yolo export model=yolov8n.pt format=tflite imgsz=320 int8=True data=data.yaml simplify=True
# 方案2:导出FP16格式(平衡速度与精度,中高端移动端首选)
yolo export model=yolov8n.pt format=tflite imgsz=320 half=True simplify=True
- 关键参数说明:
- 优先选择
yolov8n.pt(超轻量化模型),适配移动端 / 嵌入式低算力;
imgsz=320(更小尺寸,32 的倍数),降低计算量,提升流畅度;int8=True:需提供data.yaml校准,自动完成量化,适配低算力设备。
(2) TFLite 模型推理(简化版,移动端适配)
import cv2
import tensorflow as tf
import numpy as np
# 1. 加载TFLite模型并初始化推理器
tflite_path = "yolov8n.tflite"
interpreter = tf.lite.Interpreter(model_path=tflite_path)
interpreter.allocate_tensors()
# 2. 获取输入/输出张量信息
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_shape = input_details[0]['shape']
# 3. 图像预处理(适配TFLite输入要求)
img = cv2.imread("test.jpg")
input_img = cv2.resize(img, (input_shape[1], input_shape[2]))
input_img = cv2.cvtColor(input_img, cv2.COLOR_BGR2RGB).astype(np.float32) / 255.0
input_img = np.expand_dims(input_img, axis=0)
# 4. 执行推理
interpreter.set_tensor(input_details[0]['index'], input_img)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
print(f"TFLite推理完成,输出结果形状:{output_data.shape}")
4. 优劣对比
| 优势 |
劣势 |
| 1. 极致轻量化,模型体积最小(INT8 格式仅为 PyTorch 的 1/8),占用存储 / 内存低;2. 低功耗运行,适配电池供电设备,移动端 / 嵌入式友好;3. 支持离线推理,无网络依赖,保护用户隐私;4. 支持 NNAPI(Android)/ANE(iOS)硬件加速,提升端侧速度。 |
1. 推理速度低于 TensorRT(仅能发挥端侧硬件算力);2. 仅支持轻量化模型(优先 YOLOv8n),大模型适配性差;3. INT8 量化有轻微精度损失(≤3%),高精度场景受限;4. 后处理复杂,YOLO 检测结果解析需手动编写(无成熟封装)。 |
五、 四大格式核心对比与选型指南
| 格式名称 |
后缀 |
核心优势 |
核心劣势 |
适用硬件 |
精度损失 |
推理速度(相对值) |
推荐场景 |
| PyTorch 模型 |
.pt/.pth |
无精度损失、操作简单、支持微调 |
速度慢、依赖 PyTorch、兼容性差 |
CPU/GPU(桌面端) |
0% |
1x(基准) |
快速验证、模型微调、格式转换 |
| ONNX 格式 |
.onnx |
跨平台、跨框架、兼容广、平衡速度 |
依赖 ONNX Runtime、GPU 优化不足 |
CPU/GPU/ 通用服务器 |
0%(FP32)/≤1%(FP16) |
2x-3x |
通用服务器、无专属 GPU、跨平台部署 |
| TensorRT 引擎 |
.engine |
NVIDIA GPU 极致提速、低延迟、低显存 |
仅支持 NVIDIA、环境复杂、尺寸固定 |
NVIDIA GPU/ Jetson |
≤1%(FP16)/≤3%(INT8) |
10x-20x |
高性能 GPU 服务器、边缘 Jetson、实时视频分析 |
| TFLite 格式 |
.tflite |
极致轻量化、低功耗、端侧离线 |
速度一般、仅支持小模型、后处理复杂 |
手机 / 平板 / 树莓派 |
≤1%(FP16)/≤3%(INT8) |
3x-5x |
移动端 APP、低功耗嵌入式、隐私保护场景 |
核心选型原则
- 先看硬件:有 NVIDIA GPU 优先选 TensorRT,移动端选 TFLite,通用硬件选 ONNX,快速测试选 PyTorch;
- 再看需求:实时性要求高选 TensorRT,隐私保护选 TFLite,跨平台兼容选 ONNX,二次开发选 PyTorch;
- 最后看精度:高精度场景选 FP32(PyTorch/ONNX),平衡速度与精度选 FP16(TensorRT/ONNX),轻量化场景选 INT8(TensorRT/TFLite)。
总结
- 格式关系:PyTorch 是「训练 / 基础格式」,ONNX 是「跨平台中间格式」,TensorRT/TFLite 是「硬件专属优化格式」;
- 选型核心:无万能格式,只有适配场景的最优格式,优先保证「部署落地性」与「速度 / 精度平衡」;
- 落地关键:YOLO 一键转换降低了格式转换门槛,生产环境中需重点关注「环境配置」与「后处理优化」,确保推理结果的准确性与流畅性。