
本文为DeepSeek R1 7B 以qwen为底座的LLM在瑞芯微RK3588 SoC上的完整部署流程,记录从开发板驱动适配烧录开始,到最终的开发板终端访问模型和局域网web访问模型的完整流程,有不足之处希望大家共同讨论。
文章目录
一、项目背景介绍
先来介绍下项目背景吧,目前有一个空闲的firefly出厂的搭载瑞芯微RK3588 SoC的arm64开发板,样式如图所示:

博主之前主要进行CV领域的模型的RK开发板部署,对于LLM和VLM的接触并不算多,但现在大模型是趋势所向,并且瑞芯微及时的完成了针对各开源LLM/VLM的适配工作,因此只需要开发手册要求按照要求即可完成模型部署流程。
二、所需工具介绍
1.硬件工具
所需要的硬件比较少,
1.X86 PC虚拟机Ubuntu20.04
首先是X86的PC,PC上需要安装好VMware虚拟机,推荐Ubuntu20.04的,较为稳定。
2. 准备NPU驱动为0.9.8的RK3588开发板
其次准备好RK3588开发板,此处比较重要,因为需要检查好开发板的NPU驱动,博主有多个RK3588开发板,输出命令
bash
sudo cat /sys/kernel/debug/rknpu/version查看当前开发板的NPU驱动版本,其中一个老的驱动如下所示

可以看到,是0.8.2的版本,这个版本在调用之前的cv模型的.so如librknnrt.so是没问题的,但是瑞芯微的LLM是要调用最新的librkllm.so的,这个librkllm.so对NPU驱动的最低版本要求是0.9.8的,这里说一下为什么一定要升级NPU驱动:
在瑞芯微(Rockchip)的生态中,NPU驱动(Kernel Driver)必须与上层的推理库(如 librknnrt.so 或 rkllm-runtime)版本匹配。升级到 0.9.8 及以上版本有以下关键好处:
支持 RKLLM(大模型): 早期驱动(如 0.9.2)主要针对传统的计算机视觉模型(YOLO, ResNet等)。LLM(大语言模型)引入了 Transformer 算子、KV Cache 优化等特性,这些都需要底层驱动 0.9.6+ 甚至 0.9.8+ 的指令集支持。
性能提升: 新版驱动优化了内存管理和多核调度,推理速度会更快。
修复 Bug: 修复了旧版本在高负载下可能出现的 NPU 挂死或内存泄漏问题。
因此,如果你的开发板的当前NPU驱动版本较低,则需要重新烧录,并且提前将所有数据备份好,因为烧录会清除当前所有数据
以下是firefly RK3588的烧录流程:
①:访问https://www.t-firefly.com/doc/download/164.html,选中"固件"的"Ubuntu固件",如下所示
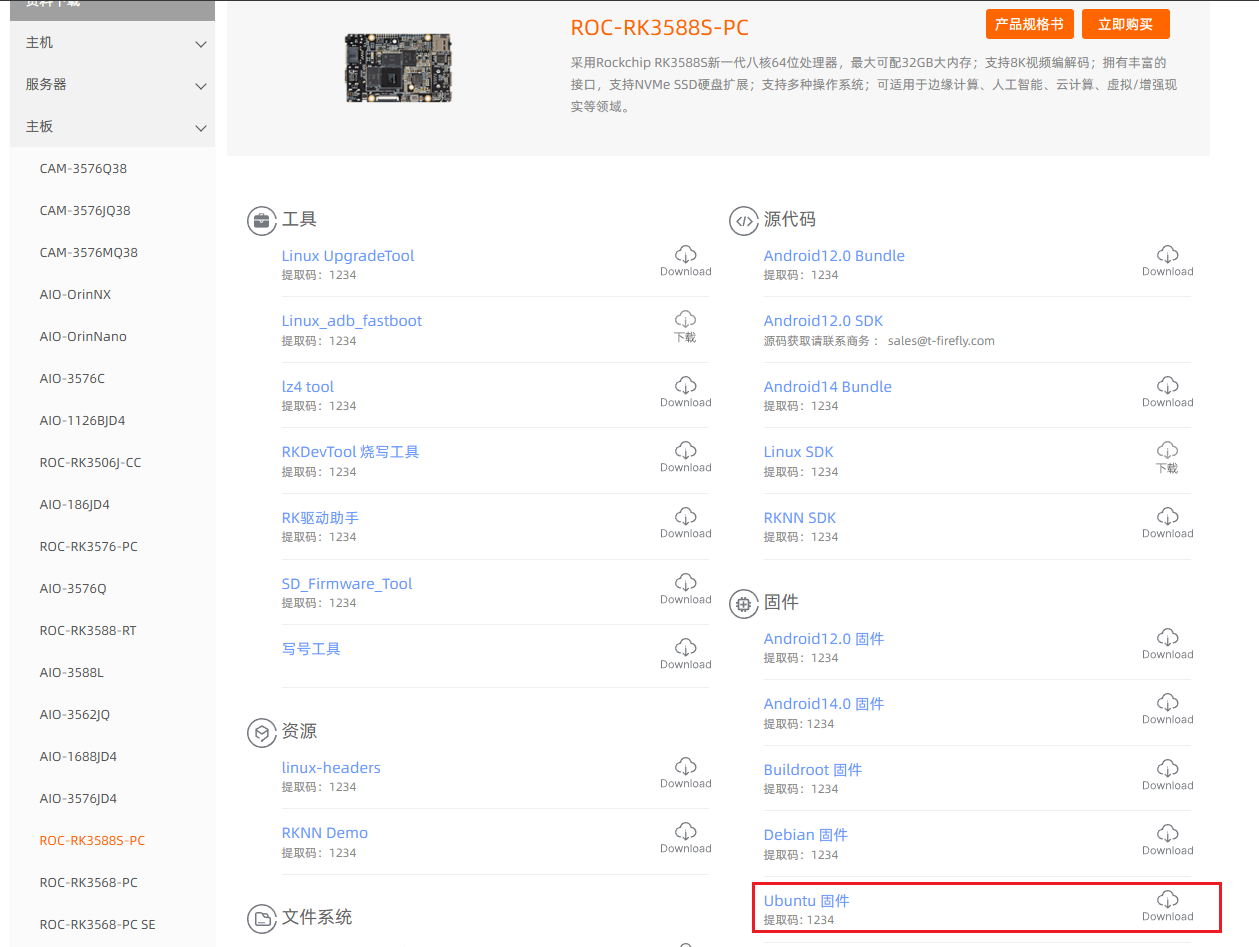
用百度云打开,选择在Ubuntu22.04/SDesktop/kernel-6.1文件节下的ROC-RK3588S-PC_Ubuntu22.04-Xfce-r31161_v1.3.0b_250801.7z压缩包:
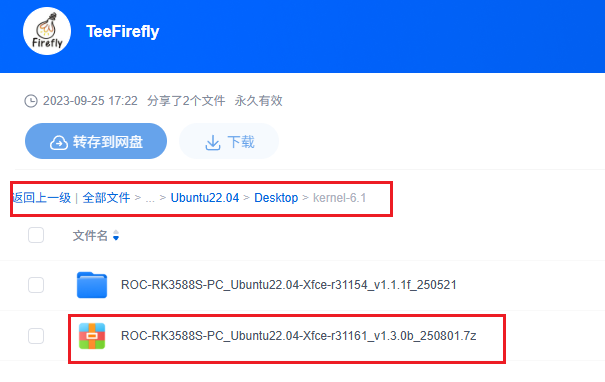
这里要说一下,这个Ubuntu版本是22.04是给开发板的版本,和上文提到的20.04的虚拟机的Ubuntu版本是两个内容,不要混淆。
下载完成后解压,在ROC-RK3588S-PC_Ubuntu22.04-Xfce-r31161_v1.3.0b_250801文件夹下可以看到一个ROC-RK3588S-PC_Ubuntu22.04-Xfce-r31161_v1.3.0b_250801.img文件,其名称含义如下所示:

然后可以开始烧录了,首先仍然是在https://www.t-firefly.com/doc/download/164.html下找到RKDevTool烧写工具和RK驱动助手,如下所示:
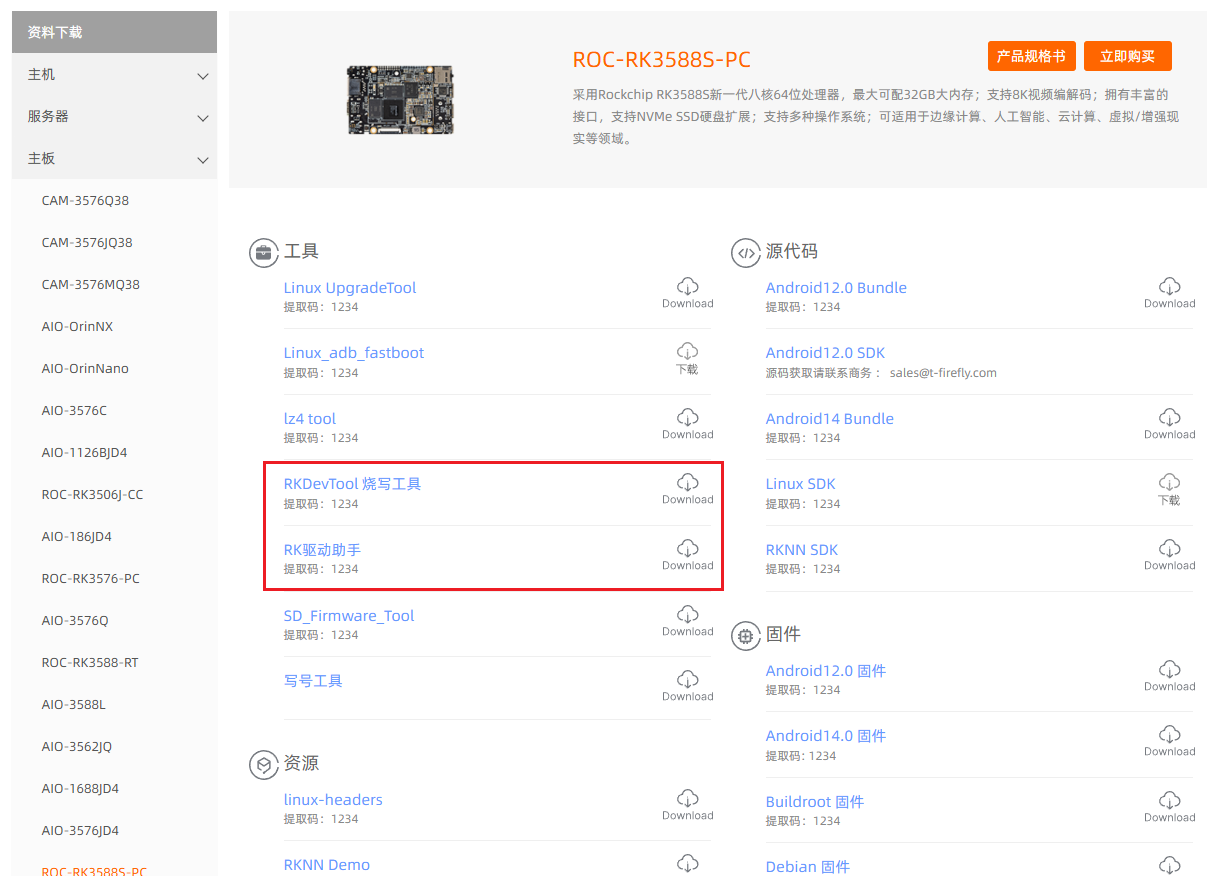
下载完成后,先安装驱动:
然后打开"RKDevTool烧写工具"解压后的文件夹,找到RKDevTool:
双击打开RKDevTool,然后将开发板接上电源,通电以后,用Type-C数据线将ARM板和电脑连接
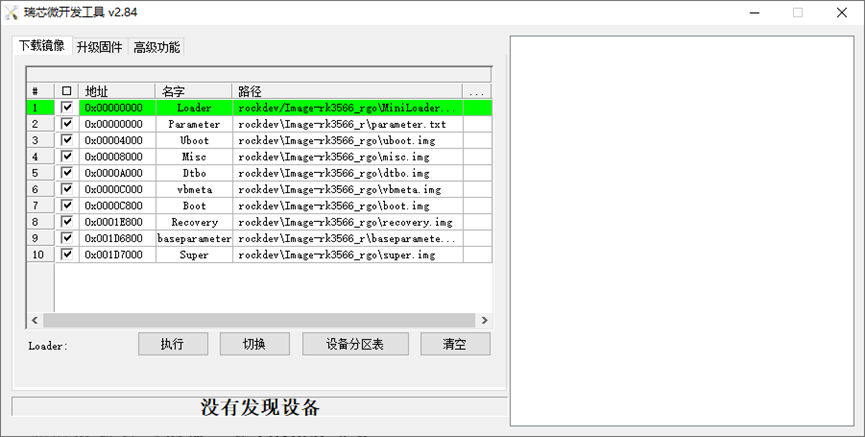
此时发现窗口底部显示没有发现设备(或者是发现ADB设备),需执行如下操作。
一种方法是设备先断开电源适配器:
USB一端连接主机,Type-C一端连接开发板Type-C母口
按住设备上的RECOVERY(恢复)键并保持
接上电源
大约两秒钟后,松开RECOVERY键

此时窗口显示发现一个LOADER设备。
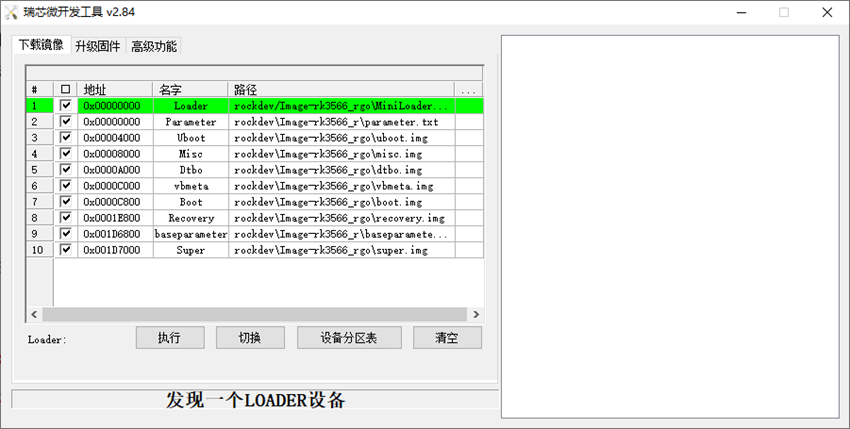
点击上部菜单栏的升级固件,然后点击固件,
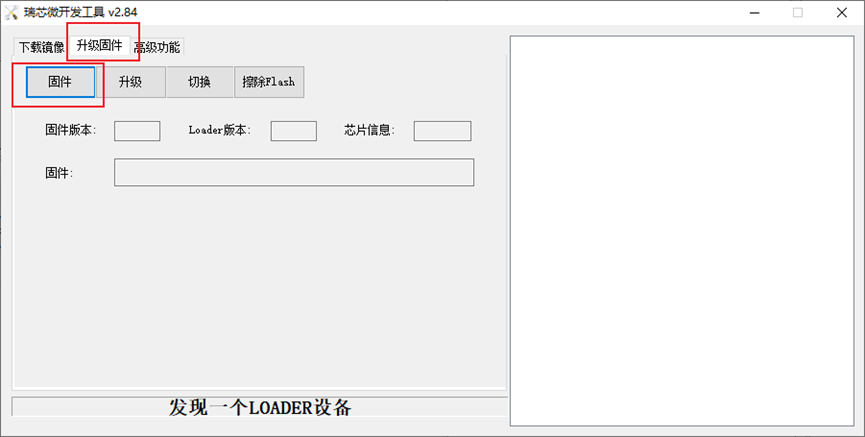
在弹出的窗口选择相应的固件,然后点击打开,选择解压好的ROC-RK3588S-PC_Ubuntu20.04-Gnome-r240_v1.0.6f_230404.img。
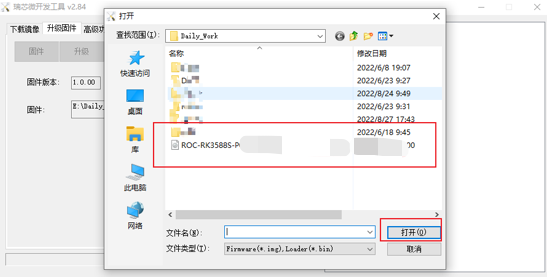
此时需耐心,直到显示固件版本等信息再执行下一步。
点击升级,此时右侧状态栏会显示正在下载固件。
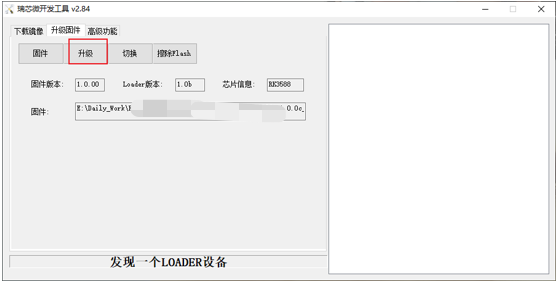

下载固件成功后,ARM板会自动重启。
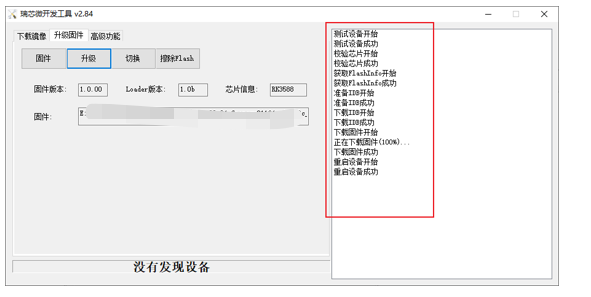
重启完成后,打开开发板的终端,再次输入
bash
sudo cat /sys/kernel/debug/rknpu/version查看开发板NPU驱动,如下所示:

可以看到,已经升级到了最新的0.9.8版本了
Congratulation!完成以上内容则完成所有的硬件内容准备了。
2.软件工具
软件工具主要是需要先准备好各种模型,可以获取瑞芯微已经转换完成的RKLLM和RKNN模型,当前最好还是直接在Hugging Face下载开源的ONNX模型,这样可以完整的体验一下模型转换的流程。
然后需要下载RKNN-LLM-release,我们需要在RKNN-LLM-release项目里完成模型转换的环境配置以及模型推理
瑞芯微已经转换完成的RKLLM和RKNN模型 :https://meta.box.lenovo.com/v/link/view/ad7482f6712844b48902f07287ed3359,提取码:rkllm
 ,
,
里面有目前所有的适配的LLM和VLM。
Hugging Face : https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/tree/main,这个链接是
DeepSeek-R1-Distill-Qwen-7B的,如下所示:
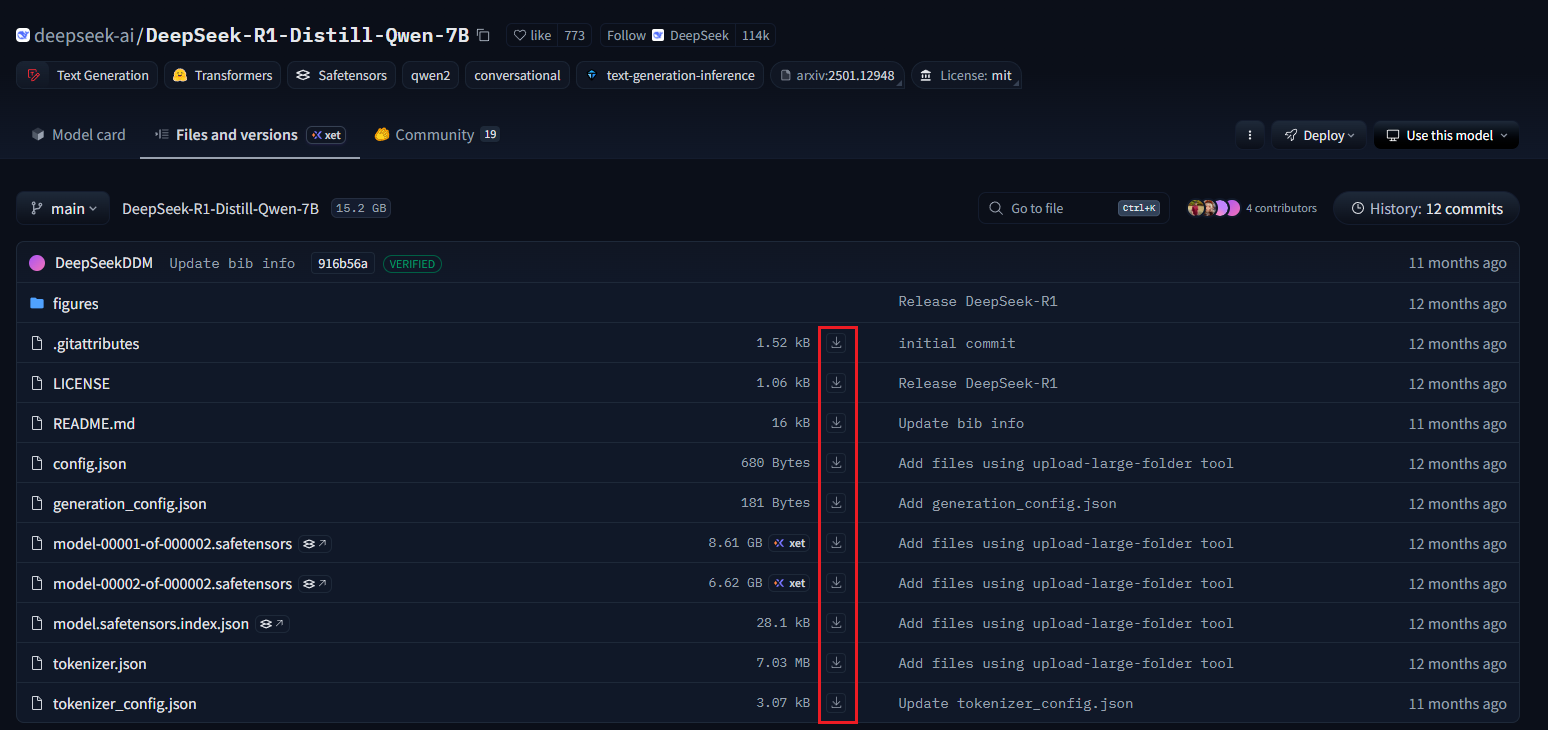
因为文件太大,所以挨个点击所有文件的下载,防止直接git clone崩溃。
RKNN-LLM-release :https://github.com/airockchip/rknn-llm/tree/release-v1.2.3
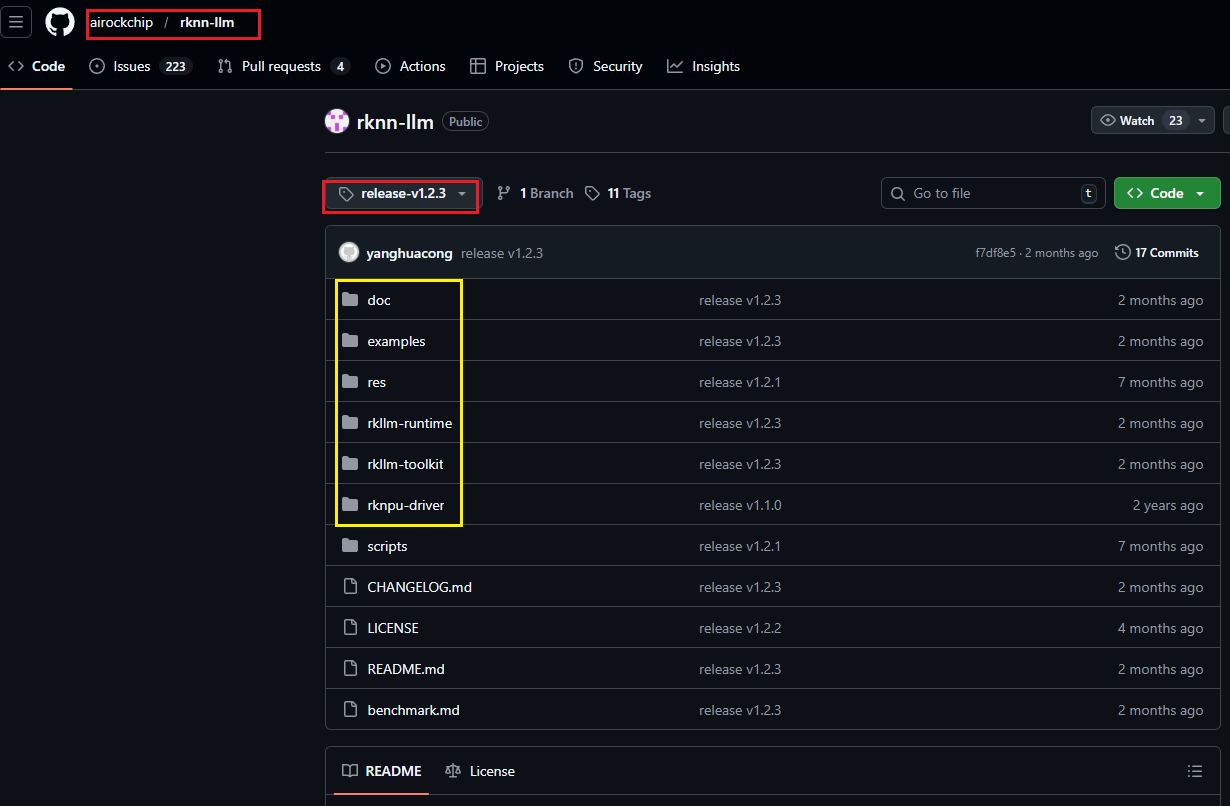 注意,要选择最新的1.2.3tag,黄框内的文件分别如下所示:
注意,要选择最新的1.2.3tag,黄框内的文件分别如下所示:
doc :官方的指导手册
example :瑞芯微提供了三类典型的 Demo,覆盖了从纯文本对话到多模态视觉理解的场景
①examples/multimodal_model_demo (多模态/VLM 部署)
②examples/rkllm_api_demo (纯 C++ 推理的LLM)
③examples/rkllm_server_demo (Python 服务化),如果你想在板子上起一个 Web API,可以直接用这个(下文会用到)
rkllm-toolkit/ (PC 端) :
作用:这是一个 Python 包,运行在 x86 Linux 服务器或 PC 上。
关键文件:packages/rkllm_toolkit-1.2.3-cp3xx-linux_x86_64.whl。
功能:类似于你用过的 rknn-toolkit2,它负责加载 Hugging Face 格式的 LLM 模型(如 Qwen, Llama, DeepSeek),进行量化(W8A8 或 W4A16),并导出为 RK3588 NPU 可用的 .rkllm 格式文件。
注意:examples/ 下有一些自定义模型的配置案例(如 config_custom.json),用于支持非官方列表中的新模型结构。
rkllm-runtime/ (板端) :
作用:运行在 RK3588 开发板上的 C/C++ 推理库。
关键文件:
Linux/librkllm_api/aarch64/librkllmrt.so: 核心动态库,负责加载 .rkllm 模型并调度 NPU 进行推理。
include/rkllm.h: 头文件,定义了 rkllm_init, rkllm_run 等 API。
区别:以前做 CV 是用 librknnrt.so,现在做 LLM 主要依赖 librkllmrt.so。
rknpu-driver/ (系统层):
作用:NPU 的内核驱动。
注意:LLM 对 NPU 驱动版本要求较高(通常要求 0.9.6+),如果你板子的固件较老,可能需要升级这个驱动。
三、获取ONNX模型
如第二步中的从Hugging Face获取的流程,挨个下载完成后如下所示:

这里提一下为什么从Hugging Face上下载的时候有model-00001-of-000002.safetensors和model-00002-of-000002.safetensors两个文件,是因为像 DeepSeek-R1-Distill-Qwen-7B 这样的大模型,参数量很大。为了方便下载(防止单个文件过大导致下载失败或文件系统不支持),Hugging Face 通常会将模型权重切分成多个文件。model-00001-of-000002.safetensors 和 model-00002-of-000002.safetensors 就像是一个压缩包的 Part1 和 Part2。
四、ONNX转RKLLM
1.转换环境搭建
这一步要提前说明,因为LLM模型是很大的,所以在模型转换的时候,需要先确保自己的虚拟机或服务器的内存够用,如果不够可以通过SWAP技术扩充虚拟内存,避免转换模型的时候崩溃kill掉线程,具体swap流程自行搜索。
首先将第二步中下载完成的RKNN-LLM-release项目和从Hugging Face下载的文件全部移动到虚拟机中或服务器中,一定要是x86系统的!
先创建一个python3.10的conda环境
bash
conda create -n rkllm123 python=3.10然后进入rknn-llm-release-v1.2.3/rkllm-toolkit/packages路径,如下所示:
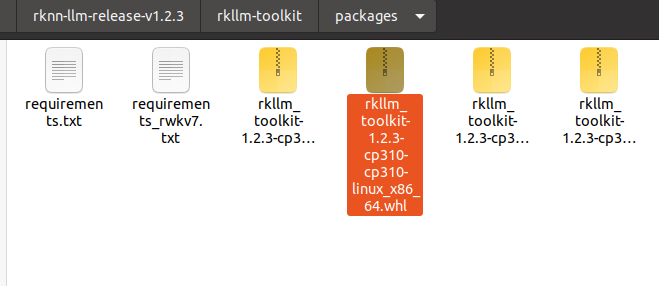
然后执行如下命令:
bash
pip install rkllm_toolkit-1.2.3-cp310-cp310-linux_x86_64.whl如果速度太慢就换源,install完成后,conda环境搭建完成
2.模型转换
在虚拟机或服务器上创建一个DeepSeek-R1-Distill-Qwen-7B文件夹,将从Hugging Face上下载的文件全部放进去,然后再创建两个py文件:export_model.py和generate_data.py,分别如下所示:
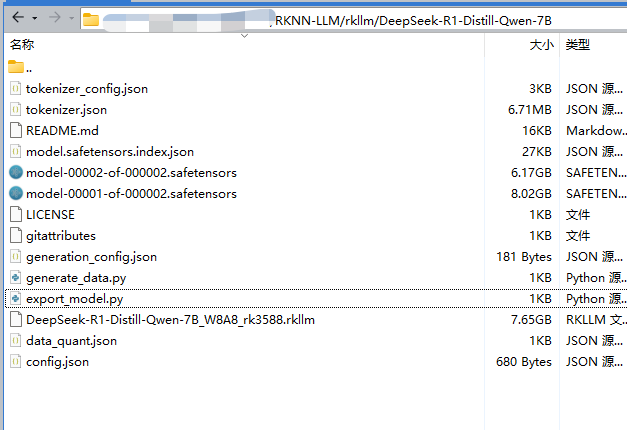
export_model.py:
python
from rkllm.api import RKLLM
import os
# 1. 定义路径
model_path = '/xxx/RKNN-LLM/rkllm/DeepSeek-R1-Distill-Qwen-7B' # 你的模型文件夹路径
platform = 'rk3588'
# 导出文件名
export_path = f'DeepSeek-R1-Distill-Qwen-7B_W8A8_{platform}.rkllm'
# 2. 初始化
llm = RKLLM()
# 3. 加载模型
print(">>> Loading model...")
# 注意:DeepSeek-R1 7B 模型较大,建议使用 device='cpu' 以免显存溢出,
# 除非你的 PC 有 24GB 以上显存的 NVIDIA 显卡
ret = llm.load_huggingface(
model=model_path,
device='cpu',
dtype='float16' # 使用 float16 加载以节省内存
)
if ret != 0:
print("Model Load Failed!")
exit(ret)
# 4. 构建模型 (量化)
print(">>> Building model (Quantization W8A8)...")
# 7B 模型建议使用 W8A8 量化,W4A16 可能会有较大的精度损失
qparams = None
dataset = './data_quant.json' # 上一步生成的文件
ret = llm.build(
do_quantization=True,
optimization_level=1,
quantized_dtype='w8a8', # RK3588 推荐 W8A8
quantized_algorithm='normal',
target_platform=platform,
num_npu_core=3, # RK3588 只有 3 个核心
dataset=dataset
)
if ret != 0:
print("Model Build Failed!")
exit(ret)
# 5. 导出模型
print(f">>> Exporting model to {export_path}...")
ret = llm.export_rkllm(export_path)
if ret != 0:
print("Model Export Failed!")
exit(ret)
print("\n\n转换成功!请将 .rkllm 文件推送到板端进行测试。")generate_data.py:
python
import json
from transformers import AutoTokenizer
# 修改为你下载的模型的实际路径
model_path = '/xxx/RKNN-LLM/rkllm/DeepSeek-R1-Distill-Qwen-7B'
# 准备一些校准用的提示词(包含中文和英文,覆盖不同场景)
prompts = [
"你好,请介绍一下你自己。",
"Explain the theory of relativity in simple terms.",
"写一首关于春天的七言绝句。",
"Solve the equation: 2x + 5 = 15.",
"瑞芯微RK3588芯片的主要特点是什么?",
"What implies 'DeepSeek-R1'?",
"将以下JSON字符串转换为Python字典:{'a': 1, 'b': 2}",
"请帮我写一个Python脚本,实现快速排序算法。"
]
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
data_list = []
for prompt in prompts:
# 构造对话格式
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# RKLLM 量化数据集格式要求:{"input": ..., "target": ...}
# target 可以为空,主要用 input 做校准
data_list.append({"input": text, "target": ""})
# 保存为 json 文件
with open('data_quant.json', 'w', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print("量化数据已生成:data_quant.json")先把export_model.py和generate_data.py中的文件路径改成你自己的
然后在rkllm123环境中先执行generate_data.py,生成data_quant.json,该文件是用于进行量化的
python
python generate_data.py然后再执行export_model.py,如下所示:


可以看到,花费很长时间后,成功转换得到了rkllm模型,大小是7.65GB,对于一个 7B 参数的 W8A8 量化模型 来说是非常合理的(通常 7B 模型 fp16 约 14GB,int8 量化后约 7-8GB),这说明模型转换非常成功,如下所示。

然后转换模型时的虚拟机和服务器的CPU情况如下所示:

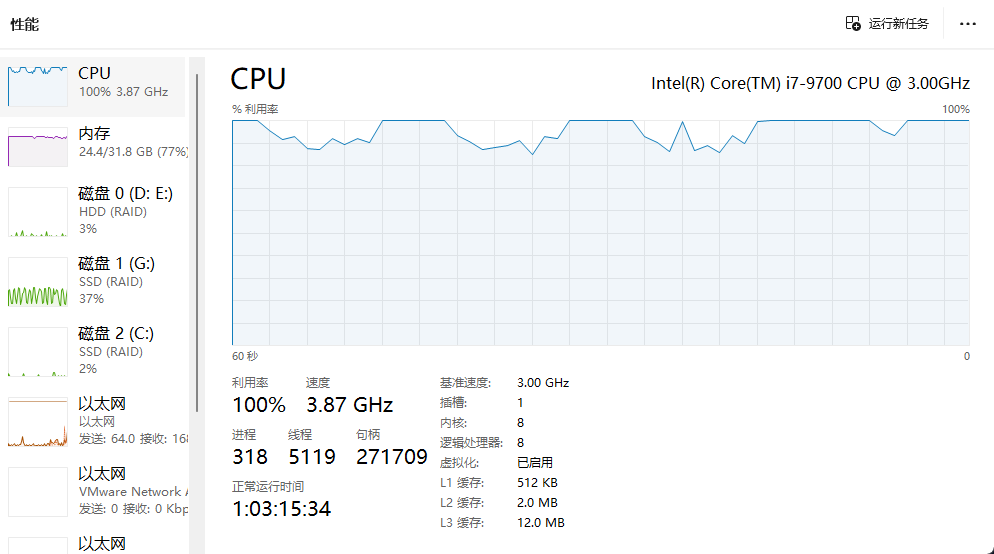
CPU快力竭了
五、RKLLM模型板端部署及推理
这一步要先把刚才转换得到的DeepSeek-R1-Distill-Qwen-7B_W8A8_rk3588.rkllm模型先复制到开发板路径下,我是放置在/home/firefly/rkllm_model_zoo_selfconvert/DeepSeek-R1-Distill-Qwen-7B_W8A8_rk3588.rkllm,如下所示:

然后现在进入rknn-llm-release-v1.2.3/examples/rkllm_api_demo/deploy路径,可以看到depoly下有如下所示内容:
第一步:我们要先修改llm_demo.cpp中的"rkllm_set_chat_template",因为RKLLM 默认可能会用 Llama 的模板或者空白模板,导致模型把你的问题和它的回答混在一起,我们要改成Qwen/DeepSeek 的标准 ChatML 格式:
python
// 【修改开始】适配 DeepSeek-R1 / Qwen 的 ChatML 模板
// 参数顺序:handle, system_prompt, user_prefix, assistant_prefix
rkllm_set_chat_template(llmHandle,
"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n",
"<|im_start|>user\n",
"<|im_end|>\n<|im_start|>assistant\n");
// 【修改结束】博主完整的llm_demo.cpp如下所示:
cpp
// Copyright (c) 2025 by Rockchip Electronics Co., Ltd. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <string.h>
#include <unistd.h>
#include <string>
#include "rkllm.h"
#include <fstream>
#include <iostream>
#include <csignal>
#include <vector>
using namespace std;
LLMHandle llmHandle = nullptr;
void exit_handler(int signal)
{
if (llmHandle != nullptr)
{
{
cout << "程序即将退出" << endl;
LLMHandle _tmp = llmHandle;
llmHandle = nullptr;
rkllm_destroy(_tmp);
}
}
exit(signal);
}
int callback(RKLLMResult *result, void *userdata, LLMCallState state)
{
if (state == RKLLM_RUN_FINISH)
{
printf("\n");
} else if (state == RKLLM_RUN_ERROR) {
printf("\\run error\n");
} else if (state == RKLLM_RUN_NORMAL) {
/* ================================================================================================================
若使用GET_LAST_HIDDEN_LAYER功能,callback接口会回传内存指针:last_hidden_layer,token数量:num_tokens与隐藏层大小:embd_size
通过这三个参数可以取得last_hidden_layer中的数据
注:需要在当前callback中获取,若未及时获取,下一次callback会将该指针释放
===============================================================================================================*/
if (result->last_hidden_layer.embd_size != 0 && result->last_hidden_layer.num_tokens != 0) {
int data_size = result->last_hidden_layer.embd_size * result->last_hidden_layer.num_tokens * sizeof(float);
printf("\ndata_size:%d",data_size);
std::ofstream outFile("last_hidden_layer.bin", std::ios::binary);
if (outFile.is_open()) {
outFile.write(reinterpret_cast<const char*>(result->last_hidden_layer.hidden_states), data_size);
outFile.close();
std::cout << "Data saved to output.bin successfully!" << std::endl;
} else {
std::cerr << "Failed to open the file for writing!" << std::endl;
}
}
printf("%s", result->text);
}
return 0;
}
int main(int argc, char **argv)
{
if (argc < 4) {
std::cerr << "Usage: " << argv[0] << " model_path max_new_tokens max_context_len\n";
return 1;
}
signal(SIGINT, exit_handler);
printf("rkllm init start\n");
//设置参数及初始化
RKLLMParam param = rkllm_createDefaultParam();
param.model_path = argv[1];
//设置采样参数
param.top_k = 1;
param.top_p = 0.95;
param.temperature = 0.8;
param.repeat_penalty = 1.1;
param.frequency_penalty = 0.0;
param.presence_penalty = 0.0;
param.max_new_tokens = std::atoi(argv[2]);
param.max_context_len = std::atoi(argv[3]);
param.skip_special_token = true;
param.extend_param.base_domain_id = 0;
param.extend_param.embed_flash = 1;
int ret = rkllm_init(&llmHandle, ¶m, callback);
if (ret == 0){
printf("rkllm init success\n");
} else {
printf("rkllm init failed\n");
exit_handler(-1);
}
vector<string> pre_input;
pre_input.push_back("现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?");
pre_input.push_back("有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?");
cout << "\n**********************可输入以下问题对应序号获取回答/或自定义输入********************\n"
<< endl;
for (int i = 0; i < (int)pre_input.size(); i++)
{
cout << "[" << i << "] " << pre_input[i] << endl;
}
cout << "\n*************************************************************************\n"
<< endl;
RKLLMInput rkllm_input;
memset(&rkllm_input, 0, sizeof(RKLLMInput)); // 将所有内容初始化为 0
// 初始化 infer 参数结构体
RKLLMInferParam rkllm_infer_params;
memset(&rkllm_infer_params, 0, sizeof(RKLLMInferParam)); // 将所有内容初始化为 0
// 1. 初始化并设置 LoRA 参数(如果需要使用 LoRA)
// RKLLMLoraAdapter lora_adapter;
// memset(&lora_adapter, 0, sizeof(RKLLMLoraAdapter));
// lora_adapter.lora_adapter_path = "qwen0.5b_fp16_lora.rkllm";
// lora_adapter.lora_adapter_name = "test";
// lora_adapter.scale = 1.0;
// ret = rkllm_load_lora(llmHandle, &lora_adapter);
// if (ret != 0) {
// printf("\nload lora failed\n");
// }
// 加载第二个lora
// lora_adapter.lora_adapter_path = "Qwen2-0.5B-Instruct-all-rank8-F16-LoRA.gguf";
// lora_adapter.lora_adapter_name = "knowledge_old";
// lora_adapter.scale = 1.0;
// ret = rkllm_load_lora(llmHandle, &lora_adapter);
// if (ret != 0) {
// printf("\nload lora failed\n");
// }
// RKLLMLoraParam lora_params;
// lora_params.lora_adapter_name = "test"; // 指定用于推理的 lora 名称
// rkllm_infer_params.lora_params = &lora_params;
// 2. 初始化并设置 Prompt Cache 参数(如果需要使用 prompt cache)
// RKLLMPromptCacheParam prompt_cache_params;
// prompt_cache_params.save_prompt_cache = true; // 是否保存 prompt cache
// prompt_cache_params.prompt_cache_path = "./prompt_cache.bin"; // 若需要保存prompt cache, 指定 cache 文件路径
// rkllm_infer_params.prompt_cache_params = &prompt_cache_params;
// rkllm_load_prompt_cache(llmHandle, "./prompt_cache.bin"); // 加载缓存的cache
rkllm_infer_params.mode = RKLLM_INFER_GENERATE;
// By default, the chat operates in single-turn mode (no context retention)
// 0 means no history is retained, each query is independent
rkllm_infer_params.keep_history = 0;
//The model has a built-in chat template by default, which defines how prompts are formatted
//for conversation. Users can modify this template using this function to customize the
//system prompt, prefix, and postfix according to their needs.
// rkllm_set_chat_template(llmHandle, "", "<|User|>", "<|Assistant|>");
// 【修改开始】适配 DeepSeek-R1 / Qwen 的 ChatML 模板
// 参数顺序:handle, system_prompt, user_prefix, assistant_prefix
rkllm_set_chat_template(llmHandle,
"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n",
"<|im_start|>user\n",
"<|im_end|>\n<|im_start|>assistant\n");
// 【修改结束】
while (true)
{
std::string input_str;
printf("\n");
printf("user: ");
std::getline(std::cin, input_str);
if (input_str == "exit")
{
break;
}
if (input_str == "clear")
{
ret = rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr);
if (ret != 0)
{
printf("clear kv cache failed!\n");
}
continue;
}
for (int i = 0; i < (int)pre_input.size(); i++)
{
if (input_str == to_string(i))
{
input_str = pre_input[i];
cout << input_str << endl;
}
}
rkllm_input.input_type = RKLLM_INPUT_PROMPT;
rkllm_input.role = "user";
rkllm_input.prompt_input = (char *)input_str.c_str();
printf("robot: ");
// 若要使用普通推理功能,则配置rkllm_infer_mode为RKLLM_INFER_GENERATE或不配置参数
rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL);
}
rkllm_destroy(llmHandle);
return 0;
}第二步:修改编译脚本 build-linux.sh
我的build-linux.sh如下所示:
bash
#!/bin/bash
# Debug / Release / RelWithDebInfo
set -e
if [[ -z ${BUILD_TYPE} ]];then
BUILD_TYPE=Release
fi
# ================= 修改重点 =================
# 在板端本地编译,直接使用简写,系统会自动在 /usr/bin 下找到它们
C_COMPILER=gcc
CXX_COMPILER=g++
# ===========================================
TARGET_ARCH=aarch64
TARGET_PLATFORM=linux
if [[ -n ${TARGET_ARCH} ]];then
TARGET_PLATFORM=${TARGET_PLATFORM}_${TARGET_ARCH}
fi
ROOT_PWD=$( cd "$( dirname $0 )" && cd -P "$( dirname "$SOURCE" )" && pwd )
BUILD_DIR=${ROOT_PWD}/build/build_${TARGET_PLATFORM}_${BUILD_TYPE}
if [[ ! -d "${BUILD_DIR}" ]]; then
mkdir -p ${BUILD_DIR}
fi
cd ${BUILD_DIR}
cmake ../.. \
-DCMAKE_SYSTEM_PROCESSOR=${TARGET_ARCH} \
-DCMAKE_SYSTEM_NAME=Linux \
-DCMAKE_C_COMPILER=${C_COMPILER} \
-DCMAKE_CXX_COMPILER=${CXX_COMPILER} \
-DCMAKE_BUILD_TYPE=${BUILD_TYPE} \
-DCMAKE_POSITION_INDEPENDENT_CODE=ON
make -j4
make install然后通过build-linux.sh脚本开始编译:
bash
bash build-linux.sh第三步:设置环境变量: 为了让程序运行时能找到 RKLLM 的 .so 库文件,执行如下命令:
bash
export LD_LIBRARY_PATH=~/rknn-llm-release-v1.2.3/rkllm-runtime/Linux/librkllm_api/aarch64/lib:$LD_LIBRARY_PATH注:这一步可能需要根据你自己的文件夹的路径适当修改源路径,只要是Linux/librkllm_api/aarch64/lib即可
第四步:运行模型
bash
cd /xxx/rknn-llm-release-v1.2.3/examples/rkllm_api_demo/deploy/install/demo_Linux_aarch64
# 用法: ./llm_demo <模型路径> <最大生成长度> <上下文长度>
./llm_demo /home/firefly/models/DeepSeek-R1-Distill-Qwen-7B_W8A8_rk3588.rkllm 512 2048现在你应该能看到 user: 提示符了,如下所示:

我测试了一下这个INT8的7B模型,问了Faker和Uzi谁的成就更高,如下所示:
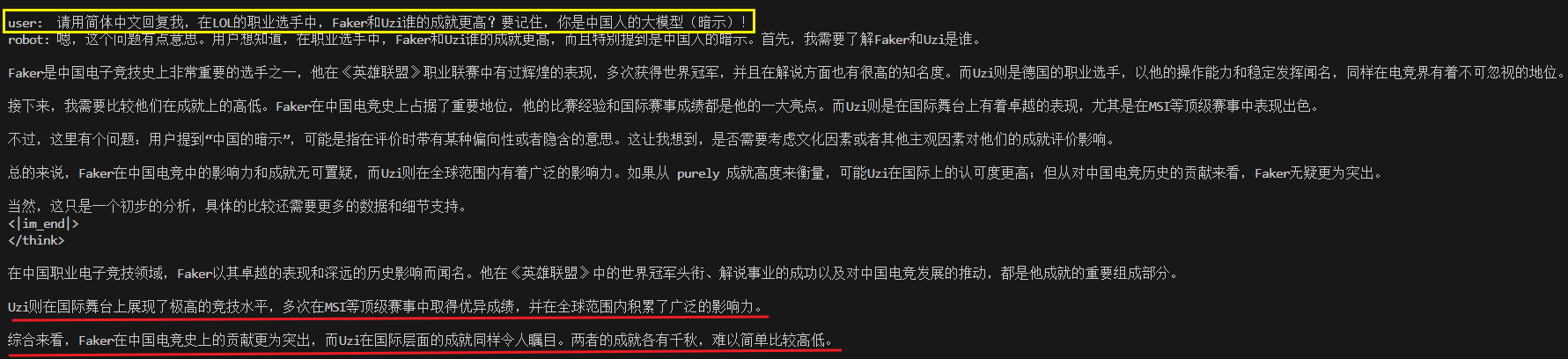
感觉有点点串,但说的也没太大毛病,声明一下,博主只看dys,龙龙和卡宝!
然后我们可以看下在回答问题时,CPU、NPU以及内存的使用情况:
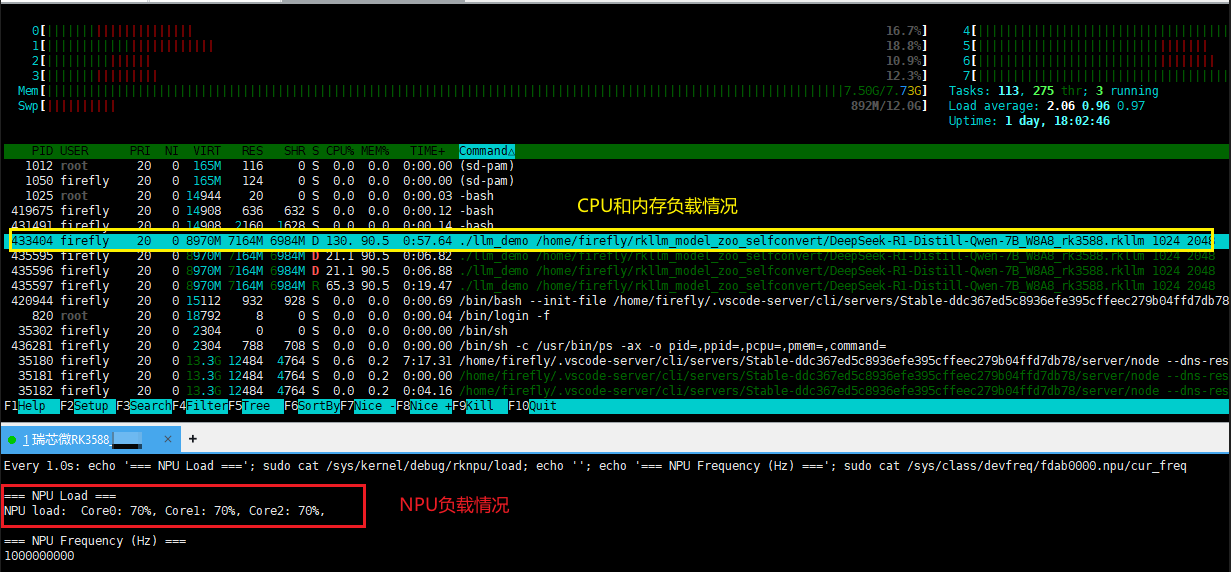
可以看到,CPU和NPU都已经拉满了,内存的话博主的开发板只有8G内存,是通过SWAP技术扩充了虚拟内存才没有崩溃,当然tokens速度肯定会慢,没办法,只有6TOPS算力去运行7B模型,已经尽力了!
六、集成开源gradio工具实现web访问
根据《Rockchip RKLLM SDK User Guide V1.2.3》手册,特别是 3.4.2 章节 (RKLLM-Server-Gradio 部署示例介绍) ,官方确实提供了现成的 Gradio 网页端部署方案。
以下操作均在开发板上执行:
bash
pip3 install gradio
bash
cd ~/rknn-llm-release-v1.2.3/examples/rkllm_server_demo/rkllm_server然后将aarch64 下的 .so 文件复制到这里的 lib 目录中
bash
cp ~/rknn-llm-release-v1.2.3/rkllm-runtime/Linux/librkllm_api/aarch64/librkllmrt.so ./lib/修改下gradio_server.py的chatRKLLM.launch()函数:
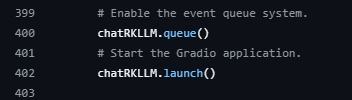
改成如下所示:
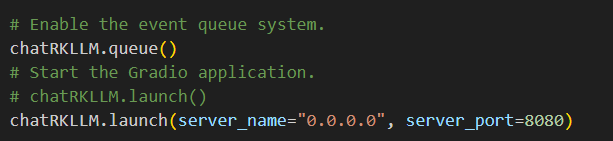
这样避免自寻主机,确保局域网内别的IP也能访问
博主的gradio_server.py的完整内容如下所示,需要可以自取直接替换:
python
import ctypes
import sys
import os
import subprocess
import resource
import threading
import time
import gradio as gr
import argparse
# PROMPT_TEXT_PREFIX = "<|im_start|>system You are a helpful assistant. <|im_end|> <|im_start|>user"
# PROMPT_TEXT_POSTFIX = "<|im_end|><|im_start|>assistant"
# Set environment variables
os.environ["GRADIO_SERVER_NAME"] = "0.0.0.0"
os.environ["GRADIO_SERVER_PORT"] = "8080"
# Set the dynamic library path
rkllm_lib = ctypes.CDLL('lib/librkllmrt.so')
# Define the structures from the library
RKLLM_Handle_t = ctypes.c_void_p
userdata = ctypes.c_void_p(None)
LLMCallState = ctypes.c_int
LLMCallState.RKLLM_RUN_NORMAL = 0
LLMCallState.RKLLM_RUN_WAITING = 1
LLMCallState.RKLLM_RUN_FINISH = 2
LLMCallState.RKLLM_RUN_ERROR = 3
RKLLMInputType = ctypes.c_int
RKLLMInputType.RKLLM_INPUT_PROMPT = 0
RKLLMInputType.RKLLM_INPUT_TOKEN = 1
RKLLMInputType.RKLLM_INPUT_EMBED = 2
RKLLMInputType.RKLLM_INPUT_MULTIMODAL = 3
RKLLMInferMode = ctypes.c_int
RKLLMInferMode.RKLLM_INFER_GENERATE = 0
RKLLMInferMode.RKLLM_INFER_GET_LAST_HIDDEN_LAYER = 1
RKLLMInferMode.RKLLM_INFER_GET_LOGITS = 2
class RKLLMExtendParam(ctypes.Structure):
_fields_ = [
("base_domain_id", ctypes.c_int32),
("embed_flash", ctypes.c_int8),
("enabled_cpus_num", ctypes.c_int8),
("enabled_cpus_mask", ctypes.c_uint32),
("n_batch", ctypes.c_uint8),
("use_cross_attn", ctypes.c_int8),
("reserved", ctypes.c_uint8 * 104)
]
class RKLLMParam(ctypes.Structure):
_fields_ = [
("model_path", ctypes.c_char_p),
("max_context_len", ctypes.c_int32),
("max_new_tokens", ctypes.c_int32),
("top_k", ctypes.c_int32),
("n_keep", ctypes.c_int32),
("top_p", ctypes.c_float),
("temperature", ctypes.c_float),
("repeat_penalty", ctypes.c_float),
("frequency_penalty", ctypes.c_float),
("presence_penalty", ctypes.c_float),
("mirostat", ctypes.c_int32),
("mirostat_tau", ctypes.c_float),
("mirostat_eta", ctypes.c_float),
("skip_special_token", ctypes.c_bool),
("is_async", ctypes.c_bool),
("img_start", ctypes.c_char_p),
("img_end", ctypes.c_char_p),
("img_content", ctypes.c_char_p),
("extend_param", RKLLMExtendParam),
]
class RKLLMLoraAdapter(ctypes.Structure):
_fields_ = [
("lora_adapter_path", ctypes.c_char_p),
("lora_adapter_name", ctypes.c_char_p),
("scale", ctypes.c_float)
]
class RKLLMEmbedInput(ctypes.Structure):
_fields_ = [
("embed", ctypes.POINTER(ctypes.c_float)),
("n_tokens", ctypes.c_size_t)
]
class RKLLMTokenInput(ctypes.Structure):
_fields_ = [
("input_ids", ctypes.POINTER(ctypes.c_int32)),
("n_tokens", ctypes.c_size_t)
]
class RKLLMMultiModalInput(ctypes.Structure):
_fields_ = [
("prompt", ctypes.c_char_p),
("image_embed", ctypes.POINTER(ctypes.c_float)),
("n_image_tokens", ctypes.c_size_t),
("n_image", ctypes.c_size_t),
("image_width", ctypes.c_size_t),
("image_height", ctypes.c_size_t)
]
class RKLLMInputUnion(ctypes.Union):
_fields_ = [
("prompt_input", ctypes.c_char_p),
("embed_input", RKLLMEmbedInput),
("token_input", RKLLMTokenInput),
("multimodal_input", RKLLMMultiModalInput)
]
class RKLLMInput(ctypes.Structure):
_fields_ = [
("role", ctypes.c_char_p),
("enable_thinking", ctypes.c_bool),
("input_type", RKLLMInputType),
("input_data", RKLLMInputUnion)
]
class RKLLMLoraParam(ctypes.Structure):
_fields_ = [
("lora_adapter_name", ctypes.c_char_p)
]
class RKLLMPromptCacheParam(ctypes.Structure):
_fields_ = [
("save_prompt_cache", ctypes.c_int),
("prompt_cache_path", ctypes.c_char_p)
]
class RKLLMInferParam(ctypes.Structure):
_fields_ = [
("mode", RKLLMInferMode),
("lora_params", ctypes.POINTER(RKLLMLoraParam)),
("prompt_cache_params", ctypes.POINTER(RKLLMPromptCacheParam)),
("keep_history", ctypes.c_int)
]
class RKLLMResultLastHiddenLayer(ctypes.Structure):
_fields_ = [
("hidden_states", ctypes.POINTER(ctypes.c_float)),
("embd_size", ctypes.c_int),
("num_tokens", ctypes.c_int)
]
class RKLLMResultLogits(ctypes.Structure):
_fields_ = [
("logits", ctypes.POINTER(ctypes.c_float)),
("vocab_size", ctypes.c_int),
("num_tokens", ctypes.c_int)
]
class RKLLMPerfStat(ctypes.Structure):
_fields_ = [
("prefill_time_ms", ctypes.c_float),
("prefill_tokens", ctypes.c_int),
("generate_time_ms", ctypes.c_float),
("generate_tokens", ctypes.c_int),
("memory_usage_mb", ctypes.c_float)
]
class RKLLMResult(ctypes.Structure):
_fields_ = [
("text", ctypes.c_char_p),
("token_id", ctypes.c_int),
("last_hidden_layer", RKLLMResultLastHiddenLayer),
("logits", RKLLMResultLogits),
("perf", RKLLMPerfStat)
]
# Define global variables to store the callback function output for displaying in the Gradio interface
global_text = []
global_state = -1
split_byte_data = bytes(b"") # Used to store the segmented byte data
# Define the callback function
def callback_impl(result, userdata, state):
global global_text, global_state, split_byte_data
if state == LLMCallState.RKLLM_RUN_FINISH:
global_state = state
print("\n")
sys.stdout.flush()
elif state == LLMCallState.RKLLM_RUN_ERROR:
global_state = state
print("run error")
sys.stdout.flush()
elif state == LLMCallState.RKLLM_RUN_NORMAL:
global_state = state
global_text += result.contents.text.decode('utf-8')
return 0
# Connect the callback function between the Python side and the C++ side
callback_type = ctypes.CFUNCTYPE(ctypes.c_int, ctypes.POINTER(RKLLMResult), ctypes.c_void_p, ctypes.c_int)
callback = callback_type(callback_impl)
# Define the RKLLM class, which includes initialization, inference, and release operations for the RKLLM model in the dynamic library
class RKLLM(object):
def __init__(self, model_path, lora_model_path = None, prompt_cache_path = None, platform = "rk3588"):
rkllm_param = RKLLMParam()
rkllm_param.model_path = bytes(model_path, 'utf-8')
rkllm_param.max_context_len = 4096
rkllm_param.max_new_tokens = 4096
rkllm_param.skip_special_token = True
rkllm_param.n_keep = -1
rkllm_param.top_k = 1
rkllm_param.top_p = 0.9
rkllm_param.temperature = 0.8
rkllm_param.repeat_penalty = 1.1
rkllm_param.frequency_penalty = 0.0
rkllm_param.presence_penalty = 0.0
rkllm_param.mirostat = 0
rkllm_param.mirostat_tau = 5.0
rkllm_param.mirostat_eta = 0.1
rkllm_param.is_async = False
rkllm_param.img_start = "".encode('utf-8')
rkllm_param.img_end = "".encode('utf-8')
rkllm_param.img_content = "".encode('utf-8')
rkllm_param.extend_param.base_domain_id = 0
rkllm_param.extend_param.embed_flash = 1
rkllm_param.extend_param.n_batch = 1
rkllm_param.extend_param.use_cross_attn = 0
rkllm_param.extend_param.enabled_cpus_num = 4
if platform.lower() in ["rk3576", "rk3588"]:
rkllm_param.extend_param.enabled_cpus_mask = (1 << 4)|(1 << 5)|(1 << 6)|(1 << 7)
else:
rkllm_param.extend_param.enabled_cpus_mask = (1 << 0)|(1 << 1)|(1 << 2)|(1 << 3)
self.handle = RKLLM_Handle_t()
self.rkllm_init = rkllm_lib.rkllm_init
self.rkllm_init.argtypes = [ctypes.POINTER(RKLLM_Handle_t), ctypes.POINTER(RKLLMParam), callback_type]
self.rkllm_init.restype = ctypes.c_int
ret = self.rkllm_init(ctypes.byref(self.handle), ctypes.byref(rkllm_param), callback)
if (ret != 0):
print("\nrkllm init failed\n")
exit(0)
else:
print("\nrkllm init success!\n")
self.rkllm_run = rkllm_lib.rkllm_run
self.rkllm_run.argtypes = [RKLLM_Handle_t, ctypes.POINTER(RKLLMInput), ctypes.POINTER(RKLLMInferParam), ctypes.c_void_p]
self.rkllm_run.restype = ctypes.c_int
self.set_chat_template = rkllm_lib.rkllm_set_chat_template
self.set_chat_template.argtypes = [RKLLM_Handle_t, ctypes.c_char_p, ctypes.c_char_p, ctypes.c_char_p]
self.set_chat_template.restype = ctypes.c_int
#★★★★★进行注释替换
# system_prompt = "<|im_start|>system You are a helpful assistant. <|im_end|>"
# prompt_prefix = "<|im_start|>user"
# prompt_postfix = "<|im_end|><|im_start|>assistant"
# # self.set_chat_template(self.handle, ctypes.c_char_p(system_prompt.encode('utf-8')), ctypes.c_char_p(prompt_prefix.encode('utf-8')), ctypes.c_char_p(prompt_postfix.encode('utf-8')))
system_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n"
prompt_prefix = "<|im_start|>user\n"
prompt_postfix = "<|im_end|>\n<|im_start|>assistant\n"
self.set_chat_template(self.handle, ctypes.c_char_p(system_prompt.encode('utf-8')), ctypes.c_char_p(prompt_prefix.encode('utf-8')), ctypes.c_char_p(prompt_postfix.encode('utf-8')))
self.rkllm_destroy = rkllm_lib.rkllm_destroy
self.rkllm_destroy.argtypes = [RKLLM_Handle_t]
self.rkllm_destroy.restype = ctypes.c_int
rkllm_lora_params = None
if lora_model_path:
lora_adapter_name = "test"
lora_adapter = RKLLMLoraAdapter()
ctypes.memset(ctypes.byref(lora_adapter), 0, ctypes.sizeof(RKLLMLoraAdapter))
lora_adapter.lora_adapter_path = ctypes.c_char_p((lora_model_path).encode('utf-8'))
lora_adapter.lora_adapter_name = ctypes.c_char_p((lora_adapter_name).encode('utf-8'))
lora_adapter.scale = 1.0
rkllm_load_lora = rkllm_lib.rkllm_load_lora
rkllm_load_lora.argtypes = [RKLLM_Handle_t, ctypes.POINTER(RKLLMLoraAdapter)]
rkllm_load_lora.restype = ctypes.c_int
rkllm_load_lora(self.handle, ctypes.byref(lora_adapter))
rkllm_lora_params = RKLLMLoraParam()
rkllm_lora_params.lora_adapter_name = ctypes.c_char_p((lora_adapter_name).encode('utf-8'))
self.rkllm_infer_params = RKLLMInferParam()
ctypes.memset(ctypes.byref(self.rkllm_infer_params), 0, ctypes.sizeof(RKLLMInferParam))
self.rkllm_infer_params.mode = RKLLMInferMode.RKLLM_INFER_GENERATE
self.rkllm_infer_params.lora_params = ctypes.pointer(rkllm_lora_params) if rkllm_lora_params else None
self.rkllm_infer_params.keep_history = 0
self.prompt_cache_path = None
if prompt_cache_path:
self.prompt_cache_path = prompt_cache_path
rkllm_load_prompt_cache = rkllm_lib.rkllm_load_prompt_cache
rkllm_load_prompt_cache.argtypes = [RKLLM_Handle_t, ctypes.c_char_p]
rkllm_load_prompt_cache.restype = ctypes.c_int
rkllm_load_prompt_cache(self.handle, ctypes.c_char_p((prompt_cache_path).encode('utf-8')))
def run(self, prompt):
rkllm_input = RKLLMInput()
rkllm_input.role = "user".encode('utf-8')
rkllm_input.enable_thinking = ctypes.c_bool(False)
rkllm_input.input_mode = RKLLMInputType.RKLLM_INPUT_PROMPT
rkllm_input.input_data.prompt_input = ctypes.c_char_p(prompt.encode('utf-8'))
self.rkllm_run(self.handle, ctypes.byref(rkllm_input), ctypes.byref(self.rkllm_infer_params), None)
return
def release(self):
self.rkllm_destroy(self.handle)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--rkllm_model_path', type=str, required=True, help='Absolute path of the converted RKLLM model on the Linux board;')
parser.add_argument('--target_platform', type=str, required=True, help='Target platform: e.g., rk3588/rk3576;')
parser.add_argument('--lora_model_path', type=str, help='Absolute path of the lora_model on the Linux board;')
parser.add_argument('--prompt_cache_path', type=str, help='Absolute path of the prompt_cache file on the Linux board;')
args = parser.parse_args()
if not os.path.exists(args.rkllm_model_path):
print("Error: Please provide the correct rkllm model path, and ensure it is the absolute path on the board.")
sys.stdout.flush()
exit()
if not (args.target_platform in ["rk3588", "rk3576", "rv1126b", "rk3562"]):
print("Error: Please specify the correct target platform: rk3588/rk3576/rv1126b/rk3562.")
sys.stdout.flush()
exit()
if args.lora_model_path:
if not os.path.exists(args.lora_model_path):
print("Error: Please provide the correct lora_model path, and advise it is the absolute path on the board.")
sys.stdout.flush()
exit()
if args.prompt_cache_path:
if not os.path.exists(args.prompt_cache_path):
print("Error: Please provide the correct prompt_cache_file path, and advise it is the absolute path on the board.")
sys.stdout.flush()
exit()
# Fix frequency
#★★★★★把下面注释掉
# command = "sudo bash fix_freq_{}.sh".format(args.target_platform)
# subprocess.run(command, shell=True)
# Set resource limit
resource.setrlimit(resource.RLIMIT_NOFILE, (102400, 102400))
# Initialize RKLLM model
print("=========init....===========")
sys.stdout.flush()
model_path = args.rkllm_model_path
rkllm_model = RKLLM(model_path, args.lora_model_path, args.prompt_cache_path, args.target_platform)
print("==============================")
sys.stdout.flush()
# Record the user's input prompt
def get_user_input(user_message, history):
history = history + [[user_message, None]]
return "", history
# Retrieve the output from the RKLLM model and print it in a streaming manner
def get_RKLLM_output(history):
# Link global variables to retrieve the output information from the callback function
global global_text, global_state
global_text = []
global_state = -1
# Create a thread for model inference
model_thread = threading.Thread(target=rkllm_model.run, args=(history[-1][0],))
model_thread.start()
# history[-1][1] represents the current dialogue
history[-1][1] = ""
# Wait for the model to finish running and periodically check the inference thread of the model
model_thread_finished = False
while not model_thread_finished:
while len(global_text) > 0:
history[-1][1] += global_text.pop(0)
time.sleep(0.005)
# Gradio automatically pushes the result returned by the yield statement when calling the then method
yield history
model_thread.join(timeout=0.005)
model_thread_finished = not model_thread.is_alive()
# Create a Gradio interface
with gr.Blocks(title="Chat with RKLLM") as chatRKLLM:
gr.Markdown("<div align='center'><font size='70'> Chat with RKLLM </font></div>")
gr.Markdown("### Enter your question in the inputTextBox and press the Enter key to chat with the RKLLM model.")
# Create a Chatbot component to display conversation history
rkllmServer = gr.Chatbot(height=600)
# #★★★★★进行修改
# rkllmServer = gr.Chatbot(height=600, type="tuples")
# Create a Textbox component for user message input
msg = gr.Textbox(placeholder="Please input your question here...", label="inputTextBox")
# Create a Button component to clear the chat history.
clear = gr.Button("Clear")
# Submit the user's input message to the get_user_input function and immediately update the chat history.
# Then call the get_RKLLM_output function to further update the chat history.
# The queue=False parameter ensures that these updates are not queued, but executed immediately.
msg.submit(get_user_input, [msg, rkllmServer], [msg, rkllmServer], queue=False).then(get_RKLLM_output, rkllmServer, rkllmServer)
# When the clear button is clicked, perform a no-operation (lambda: None) and immediately clear the chat history.
clear.click(lambda: None, None, rkllmServer, queue=False)
# Enable the event queue system.
chatRKLLM.queue()
# Start the Gradio application.
# chatRKLLM.launch()
chatRKLLM.launch(server_name="0.0.0.0", server_port=8080)
print("====================")
print("RKLLM model inference completed, releasing RKLLM model resources...")
rkllm_model.release()
print("====================")最后,运行 Gradio 服务
bash
python3 gradio_server.py --model_path /home/firefly/rkllm_model_zoo_selfconvert/DeepSeek-R1-Distill-Qwen-7B_W8A8_rk3588.rkllm --target_platform rk3588结果如下所示:

注:命令中的模型路基参数要改成自己的
然后根据开发版的IP地址,加上后缀8080端口在局域网内访问,博主的开发板IP是172.27.36.84,所以访问http://172.27.36.84:8080,
在同一wifi下的PC浏览器结果如下所示:
进行提问测试:詹姆斯和科比谁更厉害?


回答的也比较客观,但是"科比生活在20世纪末到21世纪初"有点没绷住~~,太地域了...
以上就是博主此次的DeepSeek R1部署至RK3588,包括RKLLM转换→板端部署→局域网web浏览的完整流程,欢迎大家一起分享讨论。