1、数据清洗
指发现并纠正文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值,以确保数据的准确性和可靠性
目的:删除重复信息、纠正存在的错误,并提供数据一致性
2.步骤
1)完整性:检查单条数据是否存在空值,统计的字段是否完善
2)全面性:观察某一列的全部数值,可以通过比较最大值,最小值,平均值,数据定义等来判断数据是否全面
3)合法性:检查数据的类型、内容、大小是否符合预设的规则
4)唯一性:检查数据是否重复记录
5)类别是否可靠
3、矿物数据清洗
思路:
1)数据读取与筛选
2)缺失值检查
3)特征与标签分离
4)标签编码
5)数据类型转换
6)z标准化
7)切分数据集
8)进行数据填充
9)过采样
10)保存清洗好的数据
python
import pandas as pd
import fill
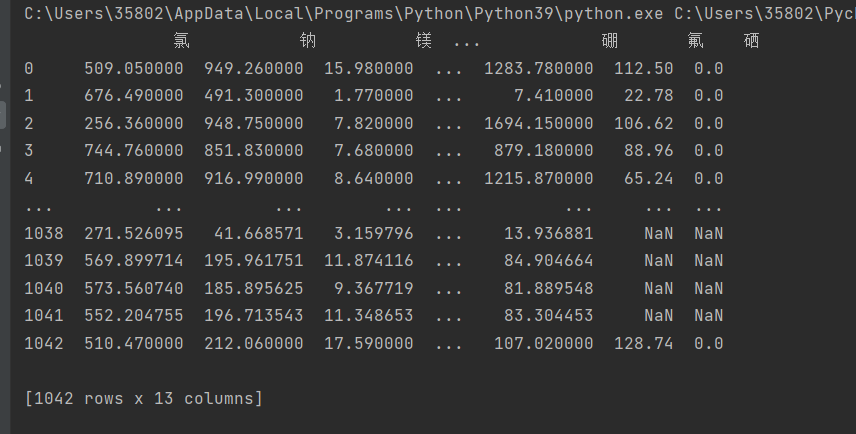
data=pd.read_excel('矿物数据.xls')
data=data[data['矿物类型'] != 'E']
null_num=data.isnull()
null_total=null_num.sum()
x_whole=data.drop(['矿物类型'],axis=1).drop(['序号'],axis=1)
y_whole=data['矿物类型']
label_dit={'A':0,'B':1,'C':2,'D':3}
num_label=[label_dit[label]for label in y_whole]
y_whole=pd.Series(num_label,name='矿物类型')
for column_name in x_whole.columns:
x_whole[column_name] = pd.to_numeric(x_whole[column_name], errors='coerce')#将无法解析为数字的值转换为 NaN
print(x_whole)
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_whole_z=scaler.fit_transform(x_whole)
x_whole=pd.DataFrame(x_whole_z,columns=x_whole.columns)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x_whole,y_whole,test_size=0.3,random_state=20)isnull()会返回一个相同形状的DataFrame,但其中的元素是布尔值(True或False)。
如果原始DataFrame中的某个位置是缺失值(通常是NaN),则对应位置在返回的DataFrame中会被标记为True;否则,标记为False。
注:在pandas中,读取Excel时的空白单元格通常会被自动转换为NaN
1)删除空值法
就是将数据中含有空缺值的那一行全部删除
python
def drop_train(train_data,train_label):
data=pd.concat([train_data,train_label],axis=1)
data=data.reset_index(drop=True)
da_fill=data.dropna()#删除缺失值
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
def drop_test(test_data,test_label):
data=pd.concat([test_data,test_label],axis=1)
data = data.reset_index(drop=True)
da_fill=data.dropna()
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
'''删除空值'''
x_train_fill,y_train_fill=fill.drop_train(x_train,y_train)
x_test_fill,y_test_fill=fill.drop_test(x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[删除缺失值].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[删除缺失值].xlsx',index=False)data_train = data_train.reset_index(drop=True)1. reset_index() 的作用
-
将当前索引重置为默认的整数索引(0, 1, 2, ...)
-
默认行为:旧的索引会变成一个新列(名为"index")
2. drop=True 参数的含义
-
drop=True:丢弃旧的索引,不将其保存为新列 -
drop=False(默认):将旧的索引保存为一个新列
2)填充平均值
计算除标签外每一列的平均数,并将此平均数填充到对应列的缺失值处
注:在计算平均值时,需要每个类别都进行计算,而且在填充测试集的缺失值时,需要依赖于训练集的数据
python
def mean_train_meethod(data):
fill_values=data.mean()
return data.fillna(fill_values)#用各列的平均值填充缺失值
def mean_train(train_data,train_label):
data=pd.concat([train_data,train_label],axis=1)
data=data.reset_index(drop=True)
A=data[data['矿物类型']==0]
B=data[data['矿物类型']==1]
C=data[data['矿物类型']==2]
D=data[data['矿物类型']==3]
A=mean_train_meethod(A)
B=mean_train_meethod(B)
C=mean_train_meethod(C)
D=mean_train_meethod(D)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
def mean_test_meethod(data_train,data_test):
fill_values=data_train.mean()
return data_test.fillna(fill_values)
def mean_test(train_data,train_label,test_data,test_label):
data_train=pd.concat([train_data,train_label],axis=1)
data_train=data_train.reset_index(drop=True)
data_test = pd.concat([test_data, test_label], axis=1)
data_test = data_test.reset_index(drop=True)
A_train=data_train[data_train['矿物类型']==0]
B_train=data_train[data_train['矿物类型']==1]
C_train=data_train[data_train['矿物类型']==2]
D_train=data_train[data_train['矿物类型']==3]
A_test=data_test[data_test['矿物类型']==0]
B_test=data_test[data_test['矿物类型']==1]
C_test=data_test[data_test['矿物类型']==2]
D_test=data_test[data_test['矿物类型']==3]
A=mean_test_meethod(A_train,A_test)
B=mean_test_meethod(B_train,B_test)
C=mean_test_meethod(C_train,C_test)
D=mean_test_meethod(D_train,D_test)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
'''填充平均值'''
x_train_fill,y_train_fill=fill.mean_train(x_train,y_train)
x_test_fill,y_test_fill=fill.mean_test(x_train_fill,y_train_fill,x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[平均值].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[平均值].xlsx',index=False)3)填充中位数
计算除标签外每一列的中位数,并将此中位数填充到对应列的缺失值处
注:和平均值填充注意事项一致
python
def median_train_meethod(data):
fill_values=data.median()
return data.fillna(fill_values)
def median_train(train_data,train_label):
data=pd.concat([train_data,train_label],axis=1)
data=data.reset_index(drop=True)
A=data[data['矿物类型']==0]
B=data[data['矿物类型']==1]
C=data[data['矿物类型']==2]
D=data[data['矿物类型']==3]
A=median_train_meethod(A)
B=median_train_meethod(B)
C=median_train_meethod(C)
D=median_train_meethod(D)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
def median_test_meethod(data_train,data_test):
fill_values=data_train.median()
return data_test.fillna(fill_values)
def median_test(train_data,train_label,test_data,test_label):
data_train=pd.concat([train_data,train_label],axis=1)
data_train=data_train.reset_index(drop=True)
data_test = pd.concat([test_data, test_label], axis=1)
data_test = data_test.reset_index(drop=True)
A_train=data_train[data_train['矿物类型']==0]
B_train=data_train[data_train['矿物类型']==1]
C_train=data_train[data_train['矿物类型']==2]
D_train=data_train[data_train['矿物类型']==3]
A_test=data_test[data_test['矿物类型']==0]
B_test=data_test[data_test['矿物类型']==1]
C_test=data_test[data_test['矿物类型']==2]
D_test=data_test[data_test['矿物类型']==3]
A=median_test_meethod(A_train,A_test)
B=median_test_meethod(B_train,B_test)
C=median_test_meethod(C_train,C_test)
D=median_test_meethod(D_train,D_test)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
'''填充中位数'''
x_train_fill,y_train_fill=fill.mean_train(x_train,y_train)
x_test_fill,y_test_fill=fill.mean_test(x_train_fill,y_train_fill,x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[中位数].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[中位数].xlsx',index=False)4)填充众数
众数:每一列中出现次数最多的数据
计算除标签外每一列的众数,并将此众数填充到对应列的缺失值处
注:在计算众数时,需要每个类别都进行计算,而且在填充测试集的缺失值时,需要依赖于训练集的数据
python
def mode_train_meethod(data):
fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)
return data.fillna(fill_values)
def mode_train(train_data,train_label):
data=pd.concat([train_data,train_label],axis=1)
data=data.reset_index(drop=True)
A=data[data['矿物类型']==0]
B=data[data['矿物类型']==1]
C=data[data['矿物类型']==2]
D=data[data['矿物类型']==3]
A=mode_train_meethod(A)
B=mode_train_meethod(B)
C=mode_train_meethod(C)
D=mode_train_meethod(D)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
def mode_test_meethod(data_train,data_test):
fill_values = data_train.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)
return data_test.fillna(fill_values)
def mode_test(train_data,train_label,test_data,test_label):
data_train=pd.concat([train_data,train_label],axis=1)
data_train=data_train.reset_index(drop=True)
data_test = pd.concat([test_data, test_label], axis=1)
data_test = data_test.reset_index(drop=True)
A_train=data_train[data_train['矿物类型']==0]
B_train=data_train[data_train['矿物类型']==1]
C_train=data_train[data_train['矿物类型']==2]
D_train=data_train[data_train['矿物类型']==3]
A_test=data_test[data_test['矿物类型']==0]
B_test=data_test[data_test['矿物类型']==1]
C_test=data_test[data_test['矿物类型']==2]
D_test=data_test[data_test['矿物类型']==3]
A=mode_test_meethod(A_train,A_test)
B=mode_test_meethod(B_train,B_test)
C=mode_test_meethod(C_train,C_test)
D=mode_test_meethod(D_train,D_test)
da_fill=pd.concat([A,B,C,D])
da_fill=da_fill.reset_index(drop=True)
return da_fill.drop('矿物类型',axis=1),da_fill.矿物类型
'''填充众数'''
x_train_fill,y_train_fill=fill.mode_train(x_train,y_train)
x_test_fill,y_test_fill=fill.mode_test(x_train_fill,y_train_fill,x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[众数].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[众数].xlsx',index=False)5)线性回归
也可以使用线性回归的方式进行数据填充
原因:
-
线性回归特别适合连续数值特征
-
当特征高度相关时,可以用已知特征预测缺失特征
python
def lr_train(train_data,train_label):
data_train=pd.concat([train_data,train_label],axis=1)
data_train=data_train.reset_index(drop=True)
data_train_x=data_train.drop('矿物类型',axis=1)
null_num=data_train_x.isnull().sum()
null_num_sorted=null_num.sort_values(ascending=True)
tzmc=[]
for i in null_num_sorted.index:
tzmc.append(i)
if null_num_sorted[i]!=0:
x=data_train_x[tzmc].drop(i,axis=1)
y=data_train_x[i]
nullhang=data_train_x[data_train_x[i].isnull()].index.tolist()#获取某个特征列(第 i 列)中所有缺失值所在行的索引列表
x_train=x.drop(nullhang)
y_train=y.drop(nullhang)
x_test=x.iloc[nullhang]
lr=LinearRegression()
lr.fit(x_train,y_train)
y_pred=lr.predict(x_test)
data_train_x.loc[nullhang,i]=y_pred
return data_train_x,data_train.矿物类型
def lr_test(train_data, train_label,test_data, test_label):
data_train = pd.concat([train_data, train_label], axis=1)
data_train = data_train.reset_index(drop=True)
data_test = pd.concat([test_data, test_label], axis=1)
data_test = data_test.reset_index(drop=True)
data_train_x = data_train.drop('矿物类型', axis=1)
data_test_x = data_test.drop('矿物类型', axis=1)
null_num = data_test_x.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
tzmc = []
for i in null_num_sorted.index:
tzmc.append(i)
if null_num_sorted[i] != 0:
x_train = data_train_x[tzmc].drop(i, axis=1)
y_train = data_train_x[i]
x_test = data_test_x[tzmc].drop(i, axis=1)
nullhang = data_test_x[data_test_x[i].isnull()].index.tolist()
x_test = x_test.iloc[nullhang]
lr = LinearRegression()
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
data_test_x.loc[nullhang, i] = y_pred
return data_test_x, data_test.矿物类型
'''线性回归'''
x_train_fill,y_train_fill=fill.lr_train(x_train,y_train)
x_test_fill,y_test_fill=fill.lr_test(x_train_fill,y_train_fill,x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[线性回归].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[线性回归].xlsx',index=False)null_num=data_train_x.isnull().sum()
null_num_sorted=null_num.sort_values(ascending=True)统计所有列缺失值的数量,并按从小到大的顺序排列,若ascending=False,则按从大到小排列
6)随机森林
python
def rf_train(train_data,train_label):
data_train=pd.concat([train_data,train_label],axis=1)
data_train=data_train.reset_index(drop=True)
data_train_x=data_train.drop('矿物类型',axis=1)
null_num=data_train_x.isnull().sum()
null_num_sorted=null_num.sort_values(ascending=True)
tzmc=[]
for i in null_num_sorted.index:
tzmc.append(i)
if null_num_sorted[i]!=0:
x=data_train_x[tzmc].drop(i,axis=1)
y=data_train_x[i]
nullhang=data_train_x[data_train_x[i].isnull()].index.tolist()
x_train=x.drop(nullhang)
y_train=y.drop(nullhang)
x_test=x.iloc[nullhang]
rf=RandomForestRegressor()
rf.fit(x_train,y_train)
y_pred=rf.predict(x_test)
data_train_x.loc[nullhang,i]=y_pred
return data_train_x,data_train.矿物类型
def rf_test(train_data, train_label,test_data, test_label):
data_train = pd.concat([train_data, train_label], axis=1)
data_train = data_train.reset_index(drop=True)
data_test = pd.concat([test_data, test_label], axis=1)
data_test = data_test.reset_index(drop=True)
data_train_x = data_train.drop('矿物类型', axis=1)
data_test_x = data_test.drop('矿物类型', axis=1)
null_num = data_test_x.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
tzmc = []
for i in null_num_sorted.index:
tzmc.append(i)
if null_num_sorted[i] != 0:
x_train = data_train_x[tzmc].drop(i, axis=1)
y_train = data_train_x[i]
x_test = data_test_x[tzmc].drop(i, axis=1)
nullhang = data_test_x[data_test_x[i].isnull()].index.tolist()
x_test = x_test.iloc[nullhang]
rf = RandomForestRegressor()
rf.fit(x_train, y_train)
y_pred = rf.predict(x_test)
data_test_x.loc[nullhang, i] = y_pred
return data_test_x, data_test.矿物类型
'''随机森林'''
x_train_fill,y_train_fill=fill.rf_train(x_train,y_train)
x_test_fill,y_test_fill=fill.rf_test(x_train_fill,y_train_fill,x_test,y_test)
'''过采样'''
from imblearn.over_sampling import SMOTE
oversampl=SMOTE(k_neighbors=1,random_state=40)
os_x_train,os_y_train=oversampl.fit_resample(x_train_fill,y_train_fill)
data_train=pd.concat([os_x_train,os_y_train],axis=1).sample(frac=1,random_state=3)
data_test=pd.concat([x_test_fill,y_test_fill],axis=1)
'''保存数据'''
data_train.to_excel(r'.//填充后的数据//训练数据集[随机森林].xlsx',index=False)
data_test.to_excel(r'.//填充后的数据//测试数据集[随机森林].xlsx',index=False)运行结果