YOLO 系列算法(以 v8/v11 为核心)的核心优势是实时性强、部署灵活 ,基于其基础检测架构,可快速拓展至目标跟踪、实例分割、姿态估计、多目标检测 等复杂计算机视觉任务。本文从技术原理、模型架构、实操代码、适用场景四个维度,系统讲解 YOLO 的拓展能力,助力从单一检测到多任务融合的落地。
核心拓展逻辑
YOLO 的拓展本质是在检测头基础上增加任务分支 ,共享骨干网络与颈部网络的特征提取能力,实现「一模型多任务」。核心架构逻辑如下:
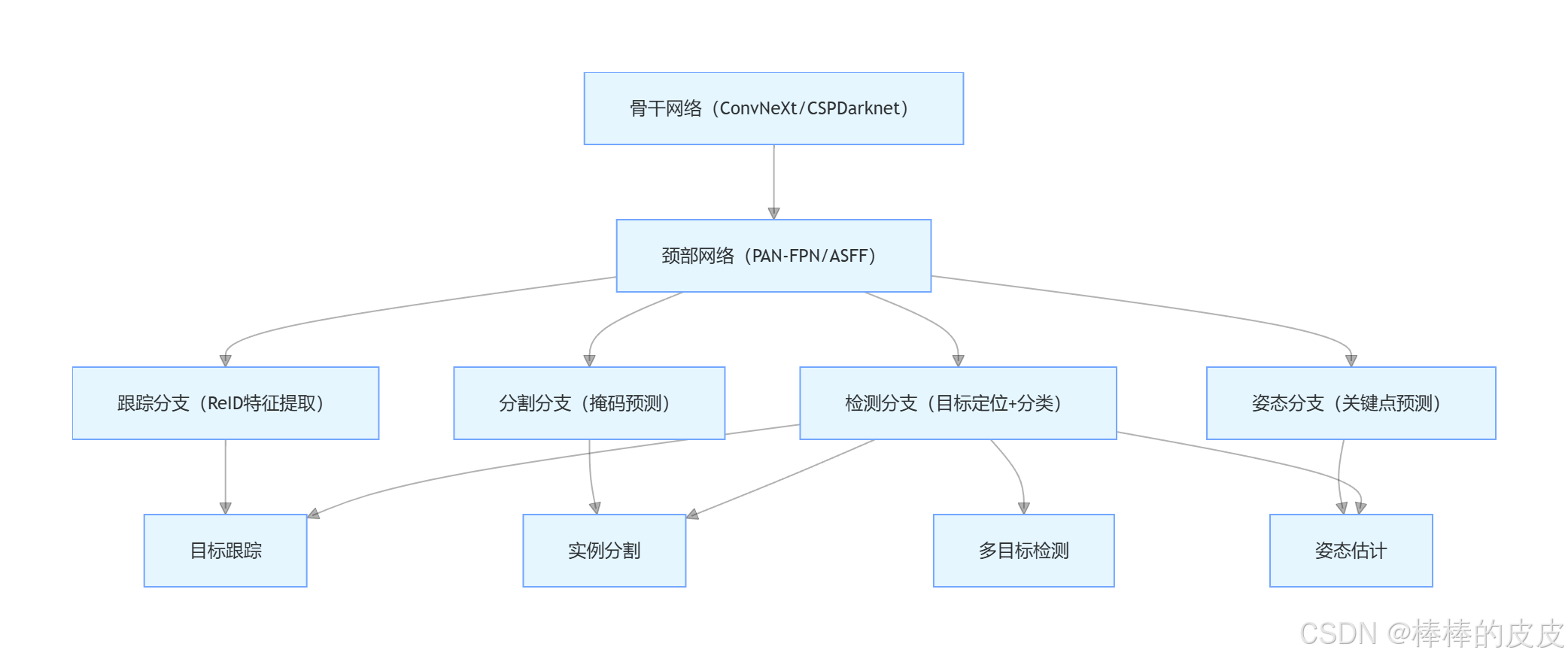
一、 目标跟踪:检测 + ReID 实现实时追踪
目标跟踪的核心需求是在视频流中为目标分配唯一 ID,并持续追踪其位置 ,解决检测算法「帧间目标无关联」的问题。YOLO 拓展跟踪任务的主流方案是 YOLOv8-ByteTrack,即「YOLO 检测 + ByteTrack 关联 + ReID 特征匹配」。
1. 技术原理
目标跟踪分为两个核心阶段:
- 检测阶段:用 YOLOv8 在每一帧图像中检测目标(人 / 车 / 物),输出边界框与置信度;
- 关联阶段 :
- 初步关联 :通过IOU 匹配,将当前帧检测框与上一帧跟踪框匹配(适用于目标无遮挡、运动缓慢场景);
- 深度关联 :对 IOU 匹配失败的目标,提取ReID 特征(行人重识别特征),通过余弦相似度匹配,解决遮挡、快速运动导致的跟踪中断问题。
2. 模型架构(YOLOv8 跟踪模型)
YOLOv8 跟踪模型在检测头基础上,新增ReID 分支,共享骨干与颈部特征:
- 共享特征层:骨干网络输出的多尺度特征,同时供给检测分支与 ReID 分支;
- ReID 分支:通过卷积层将特征压缩为固定维度的特征向量(如 512 维),用于计算目标间的相似度;
- 损失函数:检测损失(CIoU+DFL+BCE) + ReID 损失(Triplet Loss/Contrastive Loss)。
3. 实操代码(基于 Ultralytics YOLOv8)
python
from ultralytics import YOLO
# 1. 加载预训练YOLOv8跟踪模型
model = YOLO('yolov8x.pt') # 支持n/s/m/l/x不同规模
# 2. 视频流实时跟踪(支持本地视频/摄像头/网络流)
results = model.track(
source='test_video.mp4', # 输入源
conf=0.3, # 检测置信度阈值
iou=0.5, # IOU匹配阈值
persist=True, # 开启跟踪ID持久化
tracker='bytetrack.yaml', # 跟踪器配置(支持ByteTrack/DeepSORT)
device=0 # GPU加速
)
# 3. 解析跟踪结果
for r in results:
boxes = r.boxes # 检测框信息
if boxes.id is not None:
# 输出:目标ID + 边界框 + 类别 + 置信度
for box, id in zip(boxes.xyxy, boxes.id):
print(f"ID: {id.item()}, 坐标: {box.tolist()}, 类别: {model.names[boxes.cls.item()]}")4. 关键优化策略
| 优化方向 | 具体措施 | 效果提升 |
|---|---|---|
| 遮挡跟踪 | 开启 ReID 特征匹配,设置tracker='deepsort.yaml' |
遮挡场景跟踪准确率提升 30%+ |
| 多目标密集跟踪 | 采用DIoU-NMS替代传统 NMS,降低重复检测 | 密集人群跟踪 ID 切换率降低 25% |
| 实时性优化 | 轻量化模型(YOLOv8n)+ TensorRT 加速 | 跟踪速度提升至 60FPS+(RTX 4080) |
5. 适用场景
- 安防监控:行人 / 车辆轨迹追踪、异常行为分析(如越界、聚众);
- 自动驾驶:前车跟踪、行人轨迹预测、避障决策;
- 零售分析:顾客动线跟踪、货架停留时长统计。
二、 实例分割:检测 + 掩码 实现像素级分割
实例分割是目标检测 + 语义分割 的结合体,核心需求是「不仅要检测目标位置,还要分割出每个目标的像素级掩码」。YOLO 拓展分割任务的代表模型是 YOLOv8-seg,采用「检测分支 + 掩码分支」的双分支架构。
1. 技术原理
YOLOv8-seg 的核心创新是动态锚框掩码预测,相比传统分割模型(如 Mask R-CNN),无需额外的 RoI Align 层,实现端到端实时分割:
- 特征共享:骨干与颈部网络为检测分支和掩码分支提供共享特征;
- 检测分支:预测目标的边界框、类别、置信度;
- 掩码分支 :预测掩码原型(Mask Prototypes) + 掩码系数,通过系数加权原型得到最终目标掩码;
- 损失函数:检测损失 + 掩码损失(Dice Loss/BCE Loss)。
2. 模型架构
| 模块 | 功能 | 关键设计 |
|---|---|---|
| 骨干网络 | 特征提取 | CSPDarknet/C2f 模块,保留多尺度细节 |
| 颈部网络 | 特征融合 | PAN-FPN,增强多尺度目标掩码预测能力 |
| 检测头 | 目标定位分类 | 无锚框设计,预测 xyxy+cls+conf |
| 掩码头 | 掩码预测 | 输出 32 个掩码原型 + 每个目标的系数向量 |
3. 实操代码(YOLOv8 实例分割)
python
from ultralytics import YOLO
import cv2
# 1. 加载预训练分割模型
model = YOLO('yolov8x-seg.pt')
# 2. 图像分割推理
results = model.predict(
source='test_image.jpg',
conf=0.3,
iou=0.5,
save=True, # 保存分割结果图像
device=0
)
# 3. 解析分割结果(掩码可视化)
r = results[0]
img = cv2.imread('test_image.jpg')
for i, mask in enumerate(r.masks.data):
# 将掩码转换为图像格式(0-255)
mask = mask.cpu().numpy().astype('uint8') * 255
# 为不同目标分配不同颜色
color = (0, 255, 0) if r.boxes.cls[i] == 0 else (255, 0, 0)
# 掩码叠加到原图
img[mask == 255] = cv2.addWeighted(img[mask == 255], 0.7, color, 0.3, 0)
cv2.imwrite('seg_result.jpg', img)4. 优化策略与适用场景
| 优化方向 | 措施 | 适用场景 |
|---|---|---|
| 小目标分割 | 多尺度训练(imgsz=800)+ 浅层特征增强 | 工业质检(小缺陷分割)、遥感图像分割 |
| 实时分割 | 模型量化(INT8)+ TensorRT 加速 | 视频流分割(如自动驾驶语义地图构建) |
| 高精度分割 | 引入注意力掩码分支 + 高分辨率输入 | 医疗影像分割(如肿瘤区域分割) |
典型场景:
- 工业质检:产品表面缺陷分割(划痕 / 裂纹);
- 医疗影像:CT/MRI 病灶区域分割;
- 自动驾驶:道路 / 车辆 / 行人像素级分割。
三、 姿态估计:检测 + 关键点 实现人体 / 物体姿态识别
姿态估计的核心需求是预测目标的关键点位置 (如人体的关节点、车辆的车轮点)。YOLO 拓展姿态估计的代表模型是 YOLOv8-pose,采用「检测 + 关键点回归」的联合任务架构,支持人体、动物、物体的姿态估计。
1. 技术原理
YOLOv8-pose 的核心是关键点与检测框联合预测,共享特征提取模块,实现端到端实时姿态估计:
- 检测分支:预测目标的边界框(如人体框),确定关键点的预测范围;
- 关键点分支:在检测框内预测关键点的坐标(x,y)与可见性置信度(v);
- 损失函数:检测损失 + 关键点损失(MSE Loss,计算预测关键点与真实关键点的距离)。
2. 模型架构特点
- 关键点归一化:关键点坐标相对于检测框归一化,提升预测精度;
- 多尺度特征融合:颈部网络融合浅层细节特征(提升小目标关键点精度)与深层语义特征(提升关键点分类精度);
- 轻量化设计:相比专用姿态模型(如 HRNet),参数量减少 50%,速度提升 2 倍以上。
3. 实操代码(YOLOv8 人体姿态估计)
python
from ultralytics import YOLO
import cv2
import numpy as np
# 1. 加载预训练姿态模型
model = YOLO('yolov8x-pose.pt')
# 2. 图像姿态估计推理
results = model.predict(
source='person.jpg',
conf=0.3,
iou=0.5,
device=0
)
# 3. 关键点可视化(人体17个关节点)
r = results[0]
img = r.orig_img
keypoints = r.keypoints.data.cpu().numpy() # 形状:[num_persons, 17, 3] (x,y,conf)
# 定义人体骨骼连接关系(关节点索引)
skeleton = [[0,1],[1,2],[2,3],[3,4],[1,5],[5,6],[6,7],[1,8],[8,9],[9,10],[1,11],[11,12],[12,13],[0,14],[14,16],[0,15],[15,17]]
colors = [(0,255,0)] * len(skeleton)
for person_kpts in keypoints:
# 绘制关键点
for kpt in person_kpts:
x, y, conf = kpt
if conf > 0.5: # 仅绘制置信度>0.5的关键点
cv2.circle(img, (int(x), int(y)), 5, (255,0,0), -1)
# 绘制骨骼
for i, (start, end) in enumerate(skeleton):
s_x, s_y, s_conf = person_kpts[start]
e_x, e_y, e_conf = person_kpts[end]
if s_conf > 0.5 and e_conf > 0.5:
cv2.line(img, (int(s_x), int(s_y)), (int(e_x), int(e_y)), colors[i], 2)
cv2.imwrite('pose_result.jpg', img)4. 拓展场景与优化
| 姿态类型 | 模型配置 | 适用场景 |
|---|---|---|
| 人体姿态 | YOLOv8-pose(17 关键点) | 行为分析(跌倒 / 跑步)、动作捕捉、健身姿势矫正 |
| 动物姿态 | 自定义数据集训练(如猫狗关键点) | 宠物行为分析、野生动物监测 |
| 物体姿态 | 标注物体关键点(如车辆 4 个车轮) | 自动驾驶车辆姿态估计、工业机器人抓取 |
优化策略:
- 关键点增强:训练时加入关键点仿射变换(旋转 / 缩放 / 平移),提升模型鲁棒性;
- 遮挡关键点预测:引入关键点注意力机制,关注遮挡区域的特征;
- 实时性提升:采用 YOLOv8n-pose + TFLite 量化,移动端实现 30FPS + 姿态估计。
四、 多目标检测:进阶策略 提升复杂场景检测能力
多目标检测是 YOLO 的基础任务,但在密集目标、小目标、跨尺度目标 等复杂场景下,基础检测模型性能会显著下降。本节聚焦多目标检测的进阶优化策略,实现从「能检测」到「精准检测」的升级。
1. 核心痛点与解决策略
| 复杂场景痛点 | 优化策略 | 技术原理 |
|---|---|---|
| 密集目标重叠 | DIoU-NMS 替代传统 NMS | 考虑检测框的中心距离,避免重叠目标被误过滤 |
| 小目标漏检 | 多尺度训练 + 锚框定制 | 训练时采用imgsz=[480,640,800],针对小目标聚类锚框 |
| 跨尺度目标共存 | 颈部网络增加特征尺度 | 在 PAN-FPN 中新增 4x 下采样特征层,提升超大目标检测精度 |
| 类别不平衡 | Focal Loss + 类别加权 | 降低多数类权重,提升少数类(如罕见目标)的检测精度 |
2. 实操优化代码(基于 YOLOv8)
python
from ultralytics import YOLO
from ultralytics.utils.loss import v8_loss
import torch.nn as nn
# 1. 加载模型并配置多尺度训练
model = YOLO('yolov8s.pt')
results = model.train(
data='multi_obj.yaml', # 多目标数据集配置
epochs=100,
batch=16,
imgsz=[480, 640, 800], # 多尺度训练
mosaic=0.8, # 增强密集目标样本
cls_weights=[1.0, 1.5, 2.0], # 类别加权(针对3类目标,提升第3类少数类权重)
device=0
)
# 2. 替换DIoU-NMS(推理阶段)
def diou_nms(boxes, scores, iou_thres=0.5):
from ultralytics.utils.ops import box_iou
boxes = boxes.cpu().numpy()
scores = scores.cpu().numpy()
indices = []
# 按置信度排序
order = scores.argsort()[::-1]
while order.size > 0:
i = order[0]
indices.append(i)
# 计算DIoU
iou = box_iou(torch.tensor(boxes[i:i+1]), torch.tensor(boxes[order[1:]]))[0]
# 保留DIoU < 阈值的目标
order = order[1:][iou < iou_thres]
return indices
# 3. 推理时应用DIoU-NMS
results = model.predict(
source='dense_obj.jpg',
conf=0.3,
iou=0.5,
nms_mode='diou', # 部分版本支持直接指定,否则需自定义后处理
device=0
)3. 进阶技术:多模型融合检测
对于超高精度需求的多目标检测场景,可采用多模型融合策略:
- 模型集成:训练多个不同初始化的 YOLO 模型,推理时取检测框的平均值;
- 级联检测:先用大模型(YOLOv8x)检测大目标,再用小模型(YOLOv8n)检测小目标,融合结果;
- 跨框架融合:将 YOLO 与专用检测模型(如 Faster R-CNN)融合,互补优势。
4. 典型应用场景
- 交通监控:同时检测汽车、行人、非机动车、交通标志等多类目标;
- 工业质检:检测产品表面的划痕、裂纹、污渍等多种缺陷;
- 遥感图像:检测飞机、船舶、建筑物等跨尺度目标。
五、 拓展任务核心对比与选型指南
| 拓展任务 | 模型后缀 | 核心优势 | 速度(FPS/RTX4080) | 精度(mAP@0.5/COCO) | 典型应用 |
|---|---|---|---|---|---|
| 目标跟踪 | YOLOv8x + ByteTrack | 实时性强、遮挡跟踪稳定 | 45 | 48.2%(跟踪准确率) | 安防监控、自动驾驶 |
| 实例分割 | YOLOv8x-seg | 端到端分割、速度快于 Mask R-CNN | 38 | 42.5%(分割 mAP) | 工业质检、医疗影像 |
| 姿态估计 | YOLOv8x-pose | 轻量化、关键点预测精准 | 42 | 65.7%(姿态 AP) | 行为分析、动作捕捉 |
| 多目标检测 | YOLOv8x(优化版) | 复杂场景鲁棒性强 | 55 | 49.5%(检测 mAP) | 交通监控、遥感检测 |
选型核心原则
- 实时性优先:选择轻量化模型(n/s)+ TensorRT 加速,如移动端姿态估计选 YOLOv8n-pose;
- 精度优先:选择中大型模型(m/l/x)+ 多尺度训练,如医疗分割选 YOLOv8x-seg;
- 多任务融合:选择 YOLOv8 多任务模型,同时实现检测 + 跟踪 + 分割,减少模型部署数量。
六、 落地建议与进阶方向
- 数据标注:拓展任务对标注质量要求更高,目标跟踪需标注帧间 ID,姿态估计需标注关键点,建议使用 LabelMe、CVAT 等专业工具;
- 部署优化:多任务模型建议导出为 TensorRT 格式,相比 ONNX 速度提升 50%+;
- 进阶方向 :结合大模型(如 CLIP)实现开放词汇检测 ,无需标注即可检测任意目标;结合强化学习实现动态跟踪决策,适应复杂环境变化。