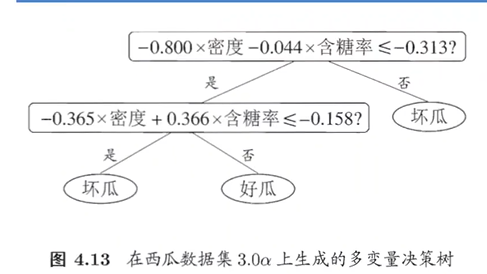
定义:监督学习方法,树状结构递归划分特征空间,最终实现分类和回归。
4.1基本流程
在出现以下三种情形会出现递归返回:
当前节点所有样本属于同一类别
当前可用特征集为空
样本划分结果为空,直接用原划分集合作为该结果
4.2划分选择
下三种计算方法是衡量决策树属性划分有效性的指标,但衡量标准不一样。
4.2.1信息增益

熵、噪音的定义
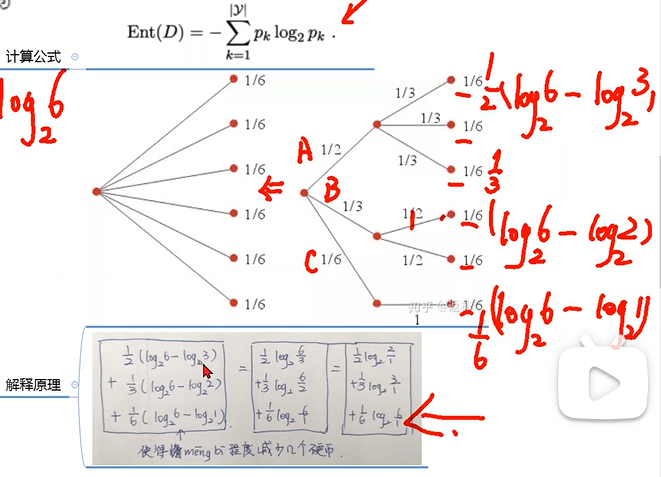
重点记住信息熵定义的计算公式。
下图为信息增益的概念理解:计算二层划分对于第一层直接算的熵值(需要消耗值)的提升。
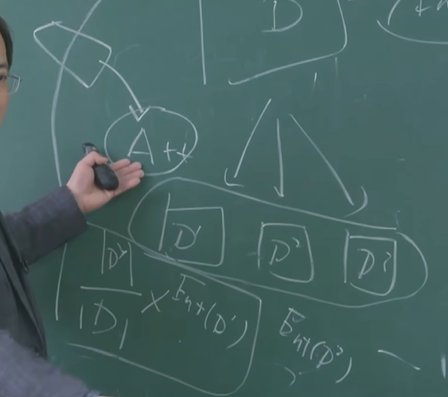

上图详细给出信息增益的公式。在ID3决策树中,就是每次选择信息增益最大的属性进行划分,训练速度更快,成本更低。
4.2.2增益率

其中分母IV(a)起到了规范化的作用,方便进行数据比较。优化了信息增益对可取值数目较多属性的偏好。
4.2.3基尼指数

4.3剪枝处理
剪枝是缓解决策树过拟合的主要方法。

预剪枝:基于贪心算法,自上而下,当划分后验证集精度下降,就需要避免此划分。好处:不仅降低过拟合风险,还减少决策树的训练时间和测试时间开销。坏处:贪心算法,可能带来欠拟合风险。
后剪枝:根据生成后的决策树,好处:欠拟合风险小,泛化性能好于预剪枝。坏处:训练时间开销大于未剪枝和预剪枝。
4.4连续与缺失值
4.4.1连续值处理

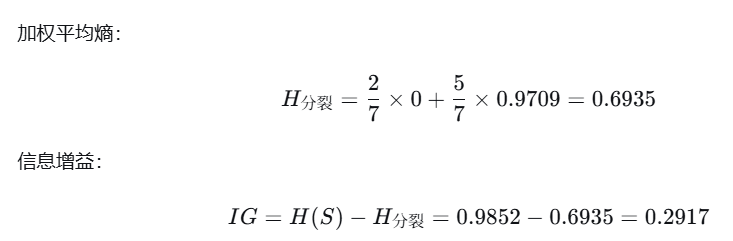
就是每个间隔处都视为分割点,依次算出最大的信息增益,作为该属性的信息增益
4.4.2缺失值处理

只有最后算数据集信息增益时,需要乘以ρ,只算无缺失值的权重。
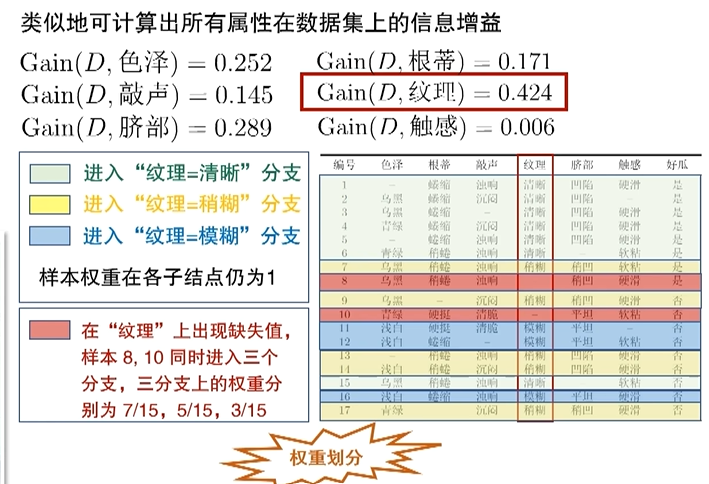
算增益率时,注意各样本权重的赋予。