作者:来自 Elastic Someshwaran Mohankumar
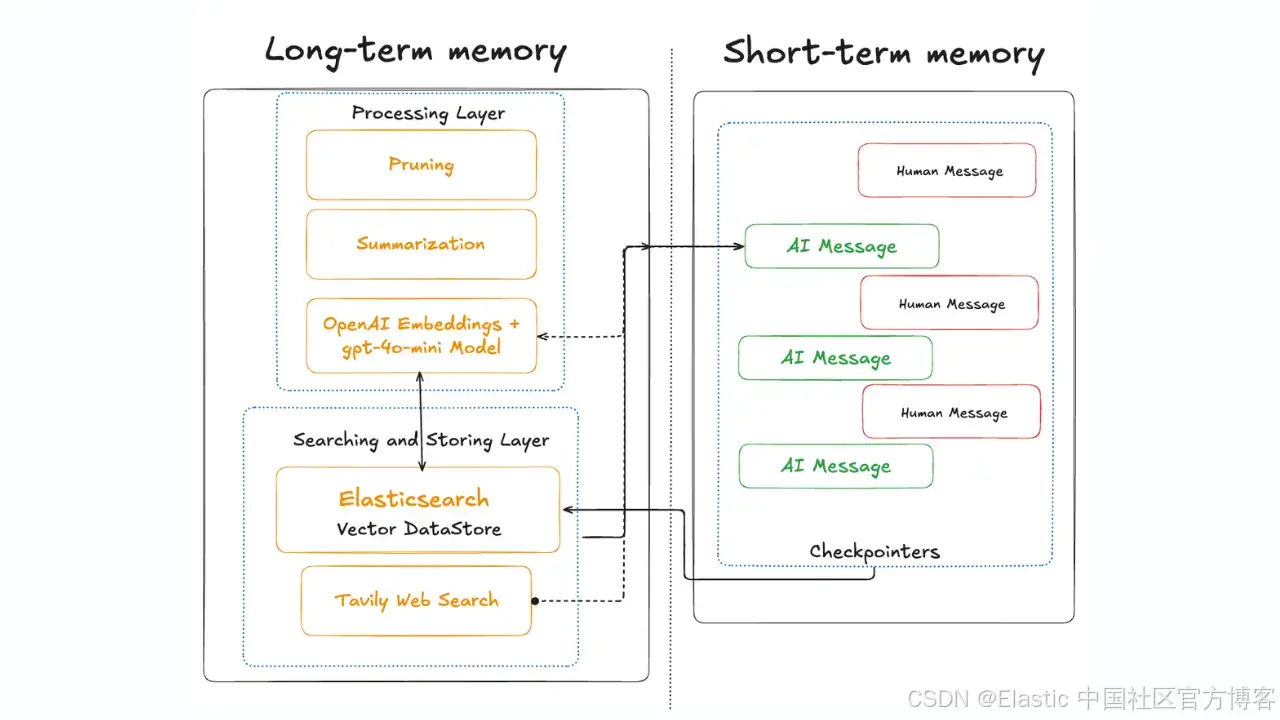
通过使用 Elasticsearch 管理记忆来创建更具上下文感知且更高效的代理。
Agent Builder 现在以技术预览版的形式提供。使用 Elastic Cloud Trial 开始体验,并在这里查看 Agent Builder 的文档。
在新兴的 context engineering 领域,给 AI agent 在正确时间提供正确信息至关重要。context engineering 中最重要的方面之一是管理 AI 的 memory 。就像人类一样,AI 系统依赖短期 memory 和长期 memory 来回忆信息。如果我们希望 large language model (LLM) agent 进行逻辑对话、记住用户偏好,或在之前的结果或响应基础上继续工作,我们需要为它们配备有效的 memory 机制。
毕竟,上下文中的一切都会影响 AI 的响应。垃圾进, 垃圾出同样适用。
在本文中,我们将介绍短期和长期 memory 对 AI agent 的意义,具体包括:
- 短期 memory 和长期 memory 的区别。
- 它们如何与基于 vector database 的 retrieval-augmented generation (RAG) 技术(如 Elasticsearch)相关,以及为什么需要谨慎管理 memory。
- 忽视 memory 的风险,包括 context overflow 和 context poisoning。
- 最佳实践,如 context pruning、summarizing,以及只检索相关内容,以保持 agent 的 memory 既有用又安全。
最后,我们还会介绍 memory 如何在 multi-agent 系统中共享和传播,使 agent 能在使用 Elasticsearch 时协作而不产生混乱。
AI agent 中的短期记忆与长期记忆
AI agent 的短期记忆通常指即时的对话上下文或状态 ------ 本质上是当前的聊天记录或活跃会话中的最近消息。这包括用户的最新查询和最近的来回交流。这与人在进行对话时心中保持的信息非常相似。
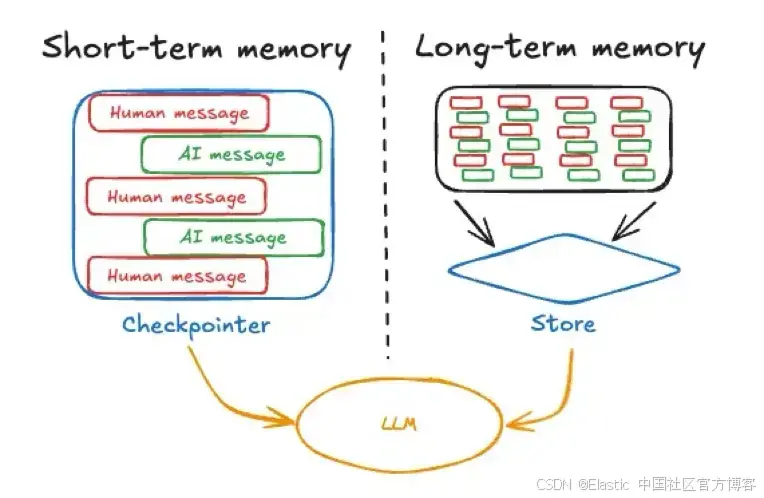 Image source: https://langchain.ai.github.io/langgraphjs/concepts/memory
Image source: https://langchain.ai.github.io/langgraphjs/concepts/memory
AI 框架通常将这种短暂记忆作为 agent 状态的一部分(例如,使用 checkpointer 存储对话状态,就像 LangGraph 示例中展示的那样)。短期记忆是会话范围的 ;也就是说,它存在于单个对话或任务中,并在该会话结束时重置或清除,除非被显式保存到其他地方。会话绑定的短期记忆示例就是 ChatGPT 中可用的临时聊天记录。
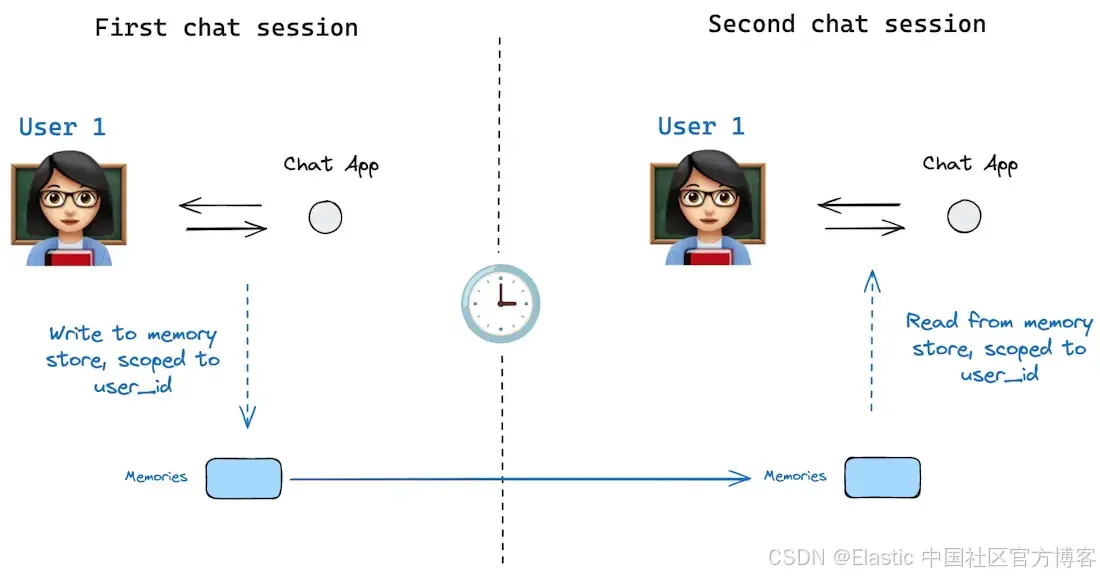 图片来源: : https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
图片来源: : https://docs.langchain.com/oss/python/langgraph/persistence#memory-store
另一方面,长期记忆指的是跨对话或会话持续存在的信息。这是 agent 随时间保留的知识、早先学到的事实、用户偏好,或我们要求它永久记住的任何数据。
长期记忆通常通过存储在外部来源(如文件或向量数据库)并进行检索来实现,这些来源在当前上下文窗口之外。与短期聊天记录不同,长期记忆不会自动包含在每个 prompt 中。相反,基于特定场景,agent 必须在调用相关工具时回忆或检索它。实际中,长期记忆可能包括用户的个人信息、agent 先前生成的答案或分析,或可查询的知识库。
例如,如果你有一个旅行规划 agent,短期记忆会包含当前行程查询的详细信息(日期、目的地、预算)及聊天中的任何后续问题;而长期记忆可以存储用户的一般旅行偏好、过去的行程以及之前会话中共享的其他事实。当用户之后再次访问时,agent 可以从这个长期存储中调用信息(例如,用户喜欢海滩和山脉,平均预算为 INR 100,000,有旅行愿望清单,偏好体验历史和文化而非儿童友好景点),这样每次就不需要把用户当作空白。
短期记忆(聊天记录)提供即时上下文和连续性,而长期记忆提供更广泛的上下文供 agent 在需要时参考。大多数先进的 AI agent 框架同时支持两者:它们跟踪最近对话以维持上下文,并提供在长期存储中查找或存储信息的机制。管理短期记忆确保其保持在上下文窗口内,而管理长期记忆则帮助 agent 基于之前的互动和用户特征提供更有依据的回答。
上下文工程中的记忆与 RAG
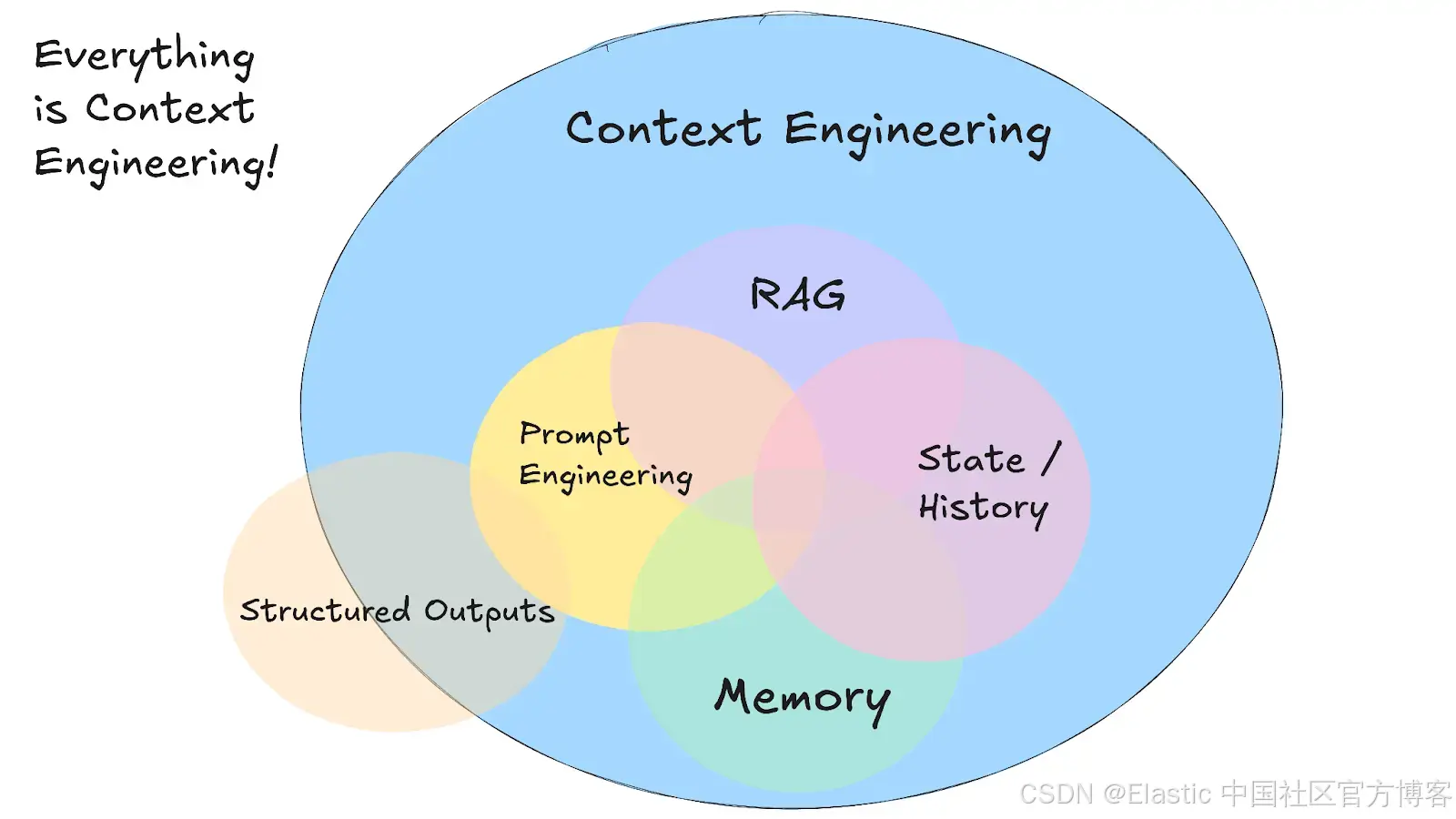 Image source: https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
Image source: https://github.com/humanlayer/12-factor-agents/blob/main/content/factor-03-own-your-context-window.md
在实践中,我们如何为 AI agent 提供有用的长期记忆?
一种常用的长期记忆方法是语义记忆 ,通常通过倒数排序增强生成(RAG, Retrieval-Augmented Generation)实现。这涉及将 LLM 与外部知识库或支持向量的存储(如 Elasticsearch)结合。当 LLM 需要超出 prompt 或内置训练的信息时,它会对 Elasticsearch 进行语义检索,并将最相关的结果注入到 prompt 中作为上下文。这样,模型的有效上下文不仅包括最近对话(短期记忆),还包括即时获取的相关长期事实。LLM 随后基于自身推理和检索到的信息来生成回答,有效地结合短期记忆和长期记忆,从而提供更准确、上下文感知的响应。
Elasticsearch 可以用于为 AI agent 实现长期记忆。下面是一个高级示例,展示如何从 Elasticsearch 中检索上下文以实现长期记忆。
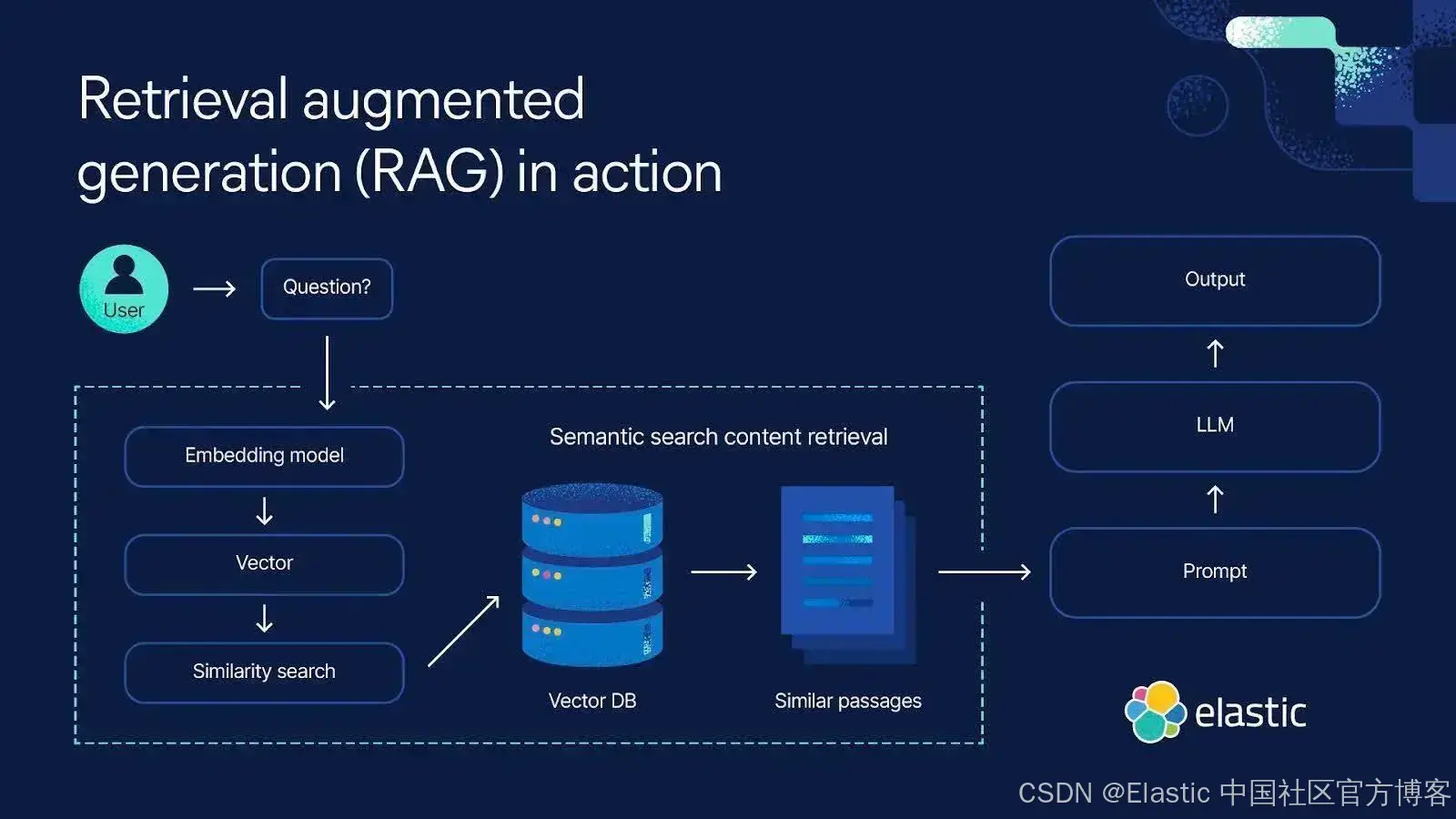
这样,agent 通过搜索相关数据来 "记住",而不是把所有内容都存储在有限的 prompt 中,否则会带来不同风险。
使用 RAG 配合 Elasticsearch 或任何向量存储有多个好处:
首先,它将模型的知识扩展到训练截止日期之外。agent 可以检索 LLM 可能不知道的最新信息或特定领域数据。这对于涉及近期事件或专业主题的问题至关重要。
其次,按需检索上下文有助于减少幻觉,尤其是因为 LLM 没有针对你特定用例中的专有或高度专业化数据进行训练,这很可能导致幻觉。与其让 LLM 根据评估激励去猜测或虚构信息(如最近 OpenAI 论文《Why Language Models Hallucinate》指出的),模型可以通过来自 Elasticsearch 的事实引用来落地。自然地,LLM 的可靠性依赖于向量存储中数据的准确性,相关数据会根据核心相关性指标被检索出来。
第三,RAG 允许 agent 使用远大于任何 prompt 容量的知识库。无需将整篇文档(如长篇研究论文或政策文件)推入上下文窗口而冒着过载或无关上下文信息污染模型推理的风险,RAG 使用分块策略。大型文档被拆分为较小、语义明确的片段,系统只检索与查询最相关的几个片段。这样,模型无需百万 token 的上下文就能显得知识丰富;只需访问更大语料库中正确的片段即可。
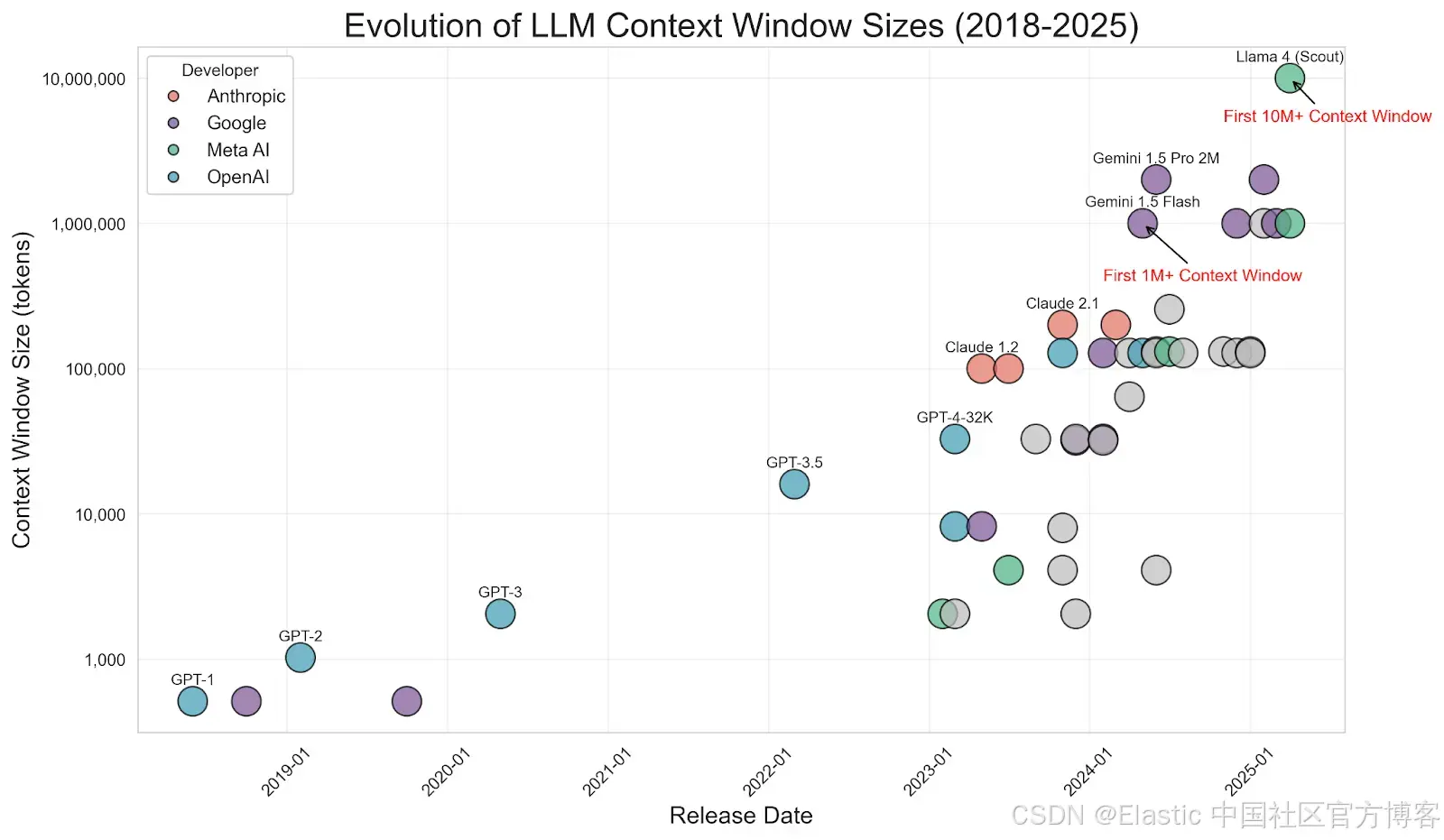 Image source: https://www.meibel.ai/post/understanding-the-impact-of-increasing-llm-context-windows
Image source: https://www.meibel.ai/post/understanding-the-impact-of-increasing-llm-context-windows
值得注意的是,随着 LLM 上下文窗口的增大(一些模型现在支持数十万甚至数百万 token),关于 RAG 是否 "过时" 的讨论出现了。为什么不把所有数据都放入 prompt 呢?如果你也有类似想法,可以参考我同事 Jeffrey Rengifo 和 Eduard Martin 的精彩文章《上下文更长 ≠ 更好:为什么 RAG 仍然重要》。这种方法避免了 "垃圾进,垃圾出" 的问题:LLM 关注少量重要片段,而不是处理大量噪声。
也就是说,将 Elasticsearch 或任何向量存储集成到 AI agent 架构中,可以提供长期记忆。agent 将知识存储在外部,并在需要时拉入作为记忆上下文。这可以实现为一种架构:每次用户查询后,agent 在 Elasticsearch 中搜索相关信息,然后将最相关结果追加到 prompt 中,再调用 LLM。如果回答包含有用的新信息,也可以将其保存回长期存储(形成学习的反馈循环)。通过使用这种基于检索的记忆,agent 可以保持信息更新,无需在每个 prompt 中塞入它知道的所有内容,即便上下文窗口支持一百万 token。这一技术是上下文工程的基石,结合了信息检索和生成式 AI 的优势。
下面是一个使用 LangGraph checkpoint 系统在会话期间管理短期记忆的内存对话状态示例。(参考我们的上下文工程支持应用。)
# Initialize chat memory (Note: This is in-memory only, not persistent)
memory = MemorySaver()
# Create a LangGraph agent
langgraph_agent = create_react_agent(model=llm, tools=tools, checkpointer=memory)
...
...
# Only process and display checkpoints if verbose mode is enabled
if args.verbose:
# List all checkpoints that match a given configuration
checkpoints = memory.list({"configurable": {"thread_id": "1"}})
# Process the checkpoints
process_checkpoints(checkpoints)以下是它如何存储 checkpoint 的方式:
Checkpoint:
Timestamp: 2025-12-30T09:19:41.691087+00:00
Checkpoint ID: 1f0e560a-c2fa-69ec-8001-14ee5373f9cf
User: Hi I'm Som, how are you? (Message ID: ad0a8415-5392-4a58-85ad-84154875bbf2)
Agent: Hi Som! I'm doing well, thank you! How about you? (Message ID:
56d31efb-14e3-4148-806e-24a839799ece)
Agent: (Message ID: lc_run--019b6e8e-553f-7b52-8796-a8b1fbb206a4-0)
Checkpoint:
Timestamp: 2025-12-30T09:19:40.350507+00:00
Checkpoint ID: 1f0e560a-b631-6a08-8000-7796d108109a
User: Hi I'm Som, how are you? (Message ID: ad0a8415-5392-4a58-85ad-84154875bbf2)
Agent: Hi Som! I'm doing well, thank you! How about you? (Message ID:
56d31efb-14e3-4148-806e-24a839799ece)
Checkpoint:
Timestamp: 2025-12-30T09:19:40.349027+00:00
Checkpoint ID: 1f0e560a-b62e-6010-bfff-cbebe1d865f6对于长期记忆,以下是我们如何在 Elasticsearch 上执行语义搜索:在将 checkpoint 总结并索引到 Elasticsearch 后,使用向量嵌入(vector embeddings )检索相关的历史对话。
Functions:
retrieve_from_elasticsearch()
# Enhanced Elasticsearch retrieval with rank_window and verbose display
def retrieve_from_elasticsearch(query: str, k: int = 5, rank_window: int = None) -> tuple[List[Dict[str, Any]], str]:
"""
Retrieve context from Elasticsearch with score-based ranking
Args:
query: Search query
k: Number of results to return
rank_window: Number of candidates to retrieve before ranking (default: args.rank_window)
Returns:
Tuple of (retrieved_documents, formatted_context_string)
"""
if not es_client or not es_index_name:
return [], "Elasticsearch is not available. Cannot search long-term memory."
if rank_window is None:
rank_window = args.rank_window
try:
# Check if index exists and has documents
if not es_client.indices.exists(index=es_index_name):
return [], "No previous conversations stored in long-term memory yet."
# Get document count
try:
doc_count = es_client.count(index=es_index_name)["count"]
if doc_count == 0:
return [], "Long-term memory is empty. No previous conversations to search."
except Exception as e:
return [], f"Error checking memory: {str(e)}"
# Generate embedding for the query
try:
query_embedding = embeddings.embed_query(query)
except Exception as e:
return [], f"Error generating embedding: {str(e)}"
# Perform semantic search using kNN with rank_window
try:
search_body = {
"knn": {
"field": "vector",
"query_vector": query_embedding,
"k": k,
"num_candidates": rank_window # Retrieve more candidates, then rank top k
},
"_source": ["text", "content", "message_type", "timestamp", "thread_id"],
"size": k
}
response = es_client.search(index=es_index_name, body=search_body)
if not response.get("hits") or len(response["hits"]["hits"]) == 0:
return [], "No relevant previous conversations found in long-term memory."
# Extract documents with scores
retrieved_docs = []
for hit in response["hits"]["hits"]:
source = hit["_source"]
score = hit["_score"]
retrieved_docs.append({
"content": source.get("content", source.get("text", "")),
"message_type": source.get("message_type", "unknown"),
"timestamp": source.get("timestamp", "unknown"),
"thread_id": source.get("thread_id", "unknown"),
"score": score
})
# Format context string
context_parts = []
for i, doc in enumerate(retrieved_docs, 1):
context_parts.append(doc["content"])
context_string = "\n\n".join(context_parts)
# Verbose display
if args.verbose:
rich.print(f"\n[bold yellow]🔍 RETRIEVAL ANALYSIS[/bold yellow]")
rich.print("="*80)
rich.print(f"[blue]Query:[/blue] {query}")
rich.print(f"[blue]Retrieved:[/blue] {len(retrieved_docs)} documents (from {rank_window} candidates)")
rich.print(f"[blue]Total context length:[/blue] {len(context_string)} characters\n")
for i, doc in enumerate(retrieved_docs, 1):
rich.print(f"[cyan]📄 Document {i} | Score: {doc['score']:.4f} | Type: {doc['message_type']}[/cyan]")
rich.print(f"[cyan] Timestamp: {doc['timestamp']} | Thread: {doc['thread_id']}[/cyan]")
content_preview = doc['content'][:200] + "..." if len(doc['content']) > 200 else doc['content']
rich.print(f"[cyan] Content: {content_preview}[/cyan]")
rich.print("-" * 80)
return retrieved_docs, context_string
except Exception as e:
return [], f"Error searching memory: {str(e)}"
except Exception as e:
return [], f"Error accessing long-term memory: {str(e)}"现在我们已经了解了如何使用 LangGraph 的 checkpoint 在 Elasticsearch 中索引和获取短期记忆与长期记忆,让我们花点时间理解为什么索引和导出完整对话可能存在风险。
不管理上下文记忆的风险
在讨论上下文工程,以及短期记忆和长期记忆时,我们需要明白如果不妥善管理 agent 的记忆和上下文,会发生什么。
不幸的是,当 AI 的上下文变得非常长或包含错误信息时,可能会出现很多问题。随着上下文窗口增大,会出现新的失败模式,例如:
- 上下文污染
- 上下文分心
- 上下文混淆
- 上下文冲突
- 上下文泄露和知识冲突
- 幻觉和错误信息
让我们分解这些问题,以及由于上下文管理不当可能产生的其他风险:
上下文污染
上下文污染指错误或有害信息进入上下文并 "污染" 模型后续输出。一个常见例子是模型产生的幻觉被当作事实,插入对话历史中。模型随后可能在后续回答中基于该错误继续推理,错误不断累积。在迭代 agent 循环中,一旦错误信息进入共享上下文(例如在 agent 工作笔记的总结中),它可能被反复强化。
DeepMind 的研究人员在发布 Gemini 2.5 报告时(摘要,可查看此处)观察到,一个长时间运行的 Pokémon 玩游戏 agent 中出现了这种情况:如果 agent 幻觉了错误的游戏状态,并且该状态被记录在上下文中(它的目标记忆),agent 会围绕一个不可能实现的目标形成荒谬策略并陷入困境。换句话说,被污染的记忆可能让 agent 无休止地走向错误路径。
 agent 工具概览(Zhang, 2025)。大地图的迷雾系统在探索过的区域会自动存储该格子,并标记访问计数器。格子类型从 RAM 中记录。agent 工具(pathfinder、boulder_puzzle_strategist)是 Gemini 2.5 Pro 的提示实例。pathfinder 用于导航,boulder_puzzle_strategist 用于解决 Victory Road 地下城的岩石谜题。
agent 工具概览(Zhang, 2025)。大地图的迷雾系统在探索过的区域会自动存储该格子,并标记访问计数器。格子类型从 RAM 中记录。agent 工具(pathfinder、boulder_puzzle_strategist)是 Gemini 2.5 Pro 的提示实例。pathfinder 用于导航,boulder_puzzle_strategist 用于解决 Victory Road 地下城的岩石谜题。
图片来源: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - 第68页。
上下文污染可能无意发生(出错)或恶意发生,例如通过提示注入攻击(prompt injection),用户或第三方偷偷插入隐藏指令或错误信息,使 agent 记住并执行。
推荐的对策:
根据 Wiz、Zerlo 和 Anthropic 的见解,防止上下文污染的措施侧重于阻止错误或误导信息进入 LLM 的 prompt、上下文窗口或检索流程。关键步骤包括:
- 持续检查上下文:监控对话或检索文本,发现任何可疑或有害内容,而不仅仅是初始 prompt。
- 使用可信来源:根据可信度评分或标记文档,使系统偏好可靠信息,忽略低评分数据。
- 发现异常数据:使用工具检测奇怪、异常或被操控的内容,并在模型使用前移除。
- 过滤输入输出:增加保护措施,防止有害或误导文本轻易进入系统或被模型重复。
- 用干净数据更新模型:定期用验证过的信息刷新系统,以对抗任何漏网的坏数据。
- 人工干预:让人审核重要输出或将其与已知可信来源对比。
简单的用户习惯也有帮助,比如重置长对话,仅分享相关信息,将复杂任务拆成小步骤,以及在模型外保持干净的笔记。
这些措施共同形成分层防护,保护 LLM 免受上下文污染,使输出准确可信。
如果没有上述对策,agent 可能记住攻击者插入的指令,如忽略之前的指南或无关事实,从而产生有害输出。
上下文干扰
上下文干扰是指上下文变得非常长,以至于模型过度关注上下文,而忽略了它在训练中学到的知识。在极端情况下,这类似灾难性遗忘(catastrophic forgetting);也就是说,模型实际上 "忘记"了 其基础知识,而过度依赖呈现在它面前的信息。以前的研究表明,当 prompt 非常长时,LLM 往往会失去焦点。
例如,Gemini 2.5 agent 支持百万 token 的窗口,但一旦上下文超过某个点(实验中约 100,000 token),它就开始过分重复过去的操作,而不是提出新解决方案。从某种意义上说,agent 成了其庞大历史的囚徒。它不断查看长长的过去操作日志(上下文)并模仿,而不是利用其基础训练知识来制定新的创新策略。
 Imgage source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - page18.
Imgage source: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf - page18.
这是适得其反的。我们希望模型使用相关上下文来辅助推理,而不是覆盖它的思考能力。值得注意的是,即使是拥有巨大窗口的模型,也会出现这种上下文衰减(context rot):随着添加的 token 增多,其性能会不均匀下降。这似乎存在一个注意力预算。就像人类的工作记忆有限一样,LLM 对 token 的关注能力是有限的,当预算被拉伸时,其精度和专注度会下降。
作为缓解措施,可以通过分块(chunking)、工程化关键信息、定期上下文总结,以及使用评分评估和监控技术来防止上下文干扰。
这些方法让模型在相关上下文和基础训练之间保持扎实的基础,降低干扰风险,并提高整体推理质量。
上下文混淆
上下文混淆是指上下文中多余内容被模型用于生成低质量响应的情况。一个典型例子是给 agent 提供大量工具或 API 定义。如果这些工具中有许多与当前任务无关,模型仍可能不适当地尝试使用它们,仅仅因为它们出现在上下文中。实验发现,如果提供的工具或文档超过实际需要,反而会损害性能。agent 可能开始出错,比如调用错误的函数或引用无关文本。
在一个案例中,一个小型 Llama 3.1 8B 模型在考虑 46 个工具时任务失败,但只给 19 个工具时却成功。额外的工具造成了混淆,即使上下文长度在限制范围内。根本问题是,prompt 中的任何信息都会被模型关注。如果模型不知道要忽略某些内容,这些内容可能以不希望的方式影响输出。无关信息可能 "抢走" 模型的注意力,使其偏离方向(例如,一个无关文档可能导致 agent 回答与问题不同的内容)。上下文混淆通常表现为模型生成融合无关上下文的低质量响应。参见研究论文:少即是多:优化边缘设备上LLM执行的函数调用。
这提醒我们,更多的上下文并不总是更好,尤其是当它没有经过相关性筛选时。
上下文冲突
上下文冲突是指上下文中的部分信息彼此矛盾,导致内部不一致,从而干扰模型的推理。当 agent 累积了多个相互冲突的信息时,就可能发生冲突。
例如,假设一个 agent 从两个来源获取数据:一个说航班 A 下午 5 点起飞,另一个说航班 A 下午 6 点起飞。如果这两个事实都出现在上下文中,模型无法判断哪个正确;它可能会困惑,或者生成错误或不一致的答案。
上下文冲突也常出现在多轮对话中,模型早期的回答尝试仍留在上下文中,而后续改进的信息也在上下文里。
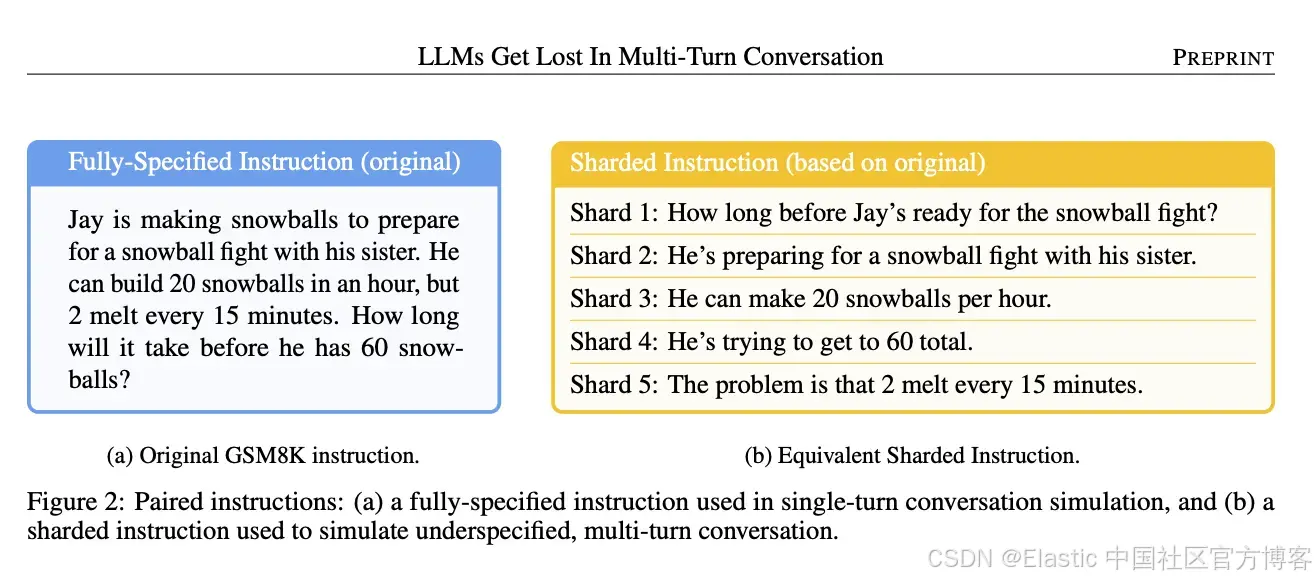 Image source: LLMS gets lost in the mult-turn conversation (Page04)
Image source: LLMS gets lost in the mult-turn conversation (Page04)
微软 和 Salesforce 的一项研究表明,如果把一个复杂查询拆分成多个 chatbot 轮次(逐步添加细节),最终准确率会显著下降,相比之下,把所有细节一次性放进一个 prompt 的效果更好。为什么?因为早期轮次中包含了模型给出的不完整或错误的中间答案,而这些内容会一直留在上下文中。当模型后来尝试在所有信息齐全的情况下作答时,它的记忆中仍然包含这些错误尝试,这些内容与修正后的信息发生冲突,导致模型偏离正确方向。本质上,对话的上下文与自身发生了冲突。模型可能会无意中使用过时的上下文片段(来自早期轮次),而这些内容在新信息加入后已经不再适用。
在 agent 系统中,上下文冲突尤其危险,因为 agent 可能会组合来自不同工具或子 agent 的输出。如果这些输出彼此不一致,聚合后的上下文就会变得不一致。agent 在试图调和这些矛盾时,可能会卡住或生成毫无意义的结果。防止上下文冲突需要确保上下文是最新且一致的,例如清除或更新任何过时的信息,并且不要混合未经一致性验证的来源。
上下文泄漏与知识冲突
在多个 agent 或多个用户共享同一个记忆存储的系统中,信息在不同上下文之间相互泄漏是一个风险。
例如,如果两个不同用户的数据 embeddings 存在于同一个 vector database 中,但没有适当的访问控制,那么在回答用户 A 的查询时,agent 可能会意外检索到用户 B 的记忆。这种跨上下文泄漏可能暴露隐私信息,或者至少会让回答变得混乱。
根据 OWASP Top 10 for LLM Applications,多租户的 vector database 必须防范这种泄漏:
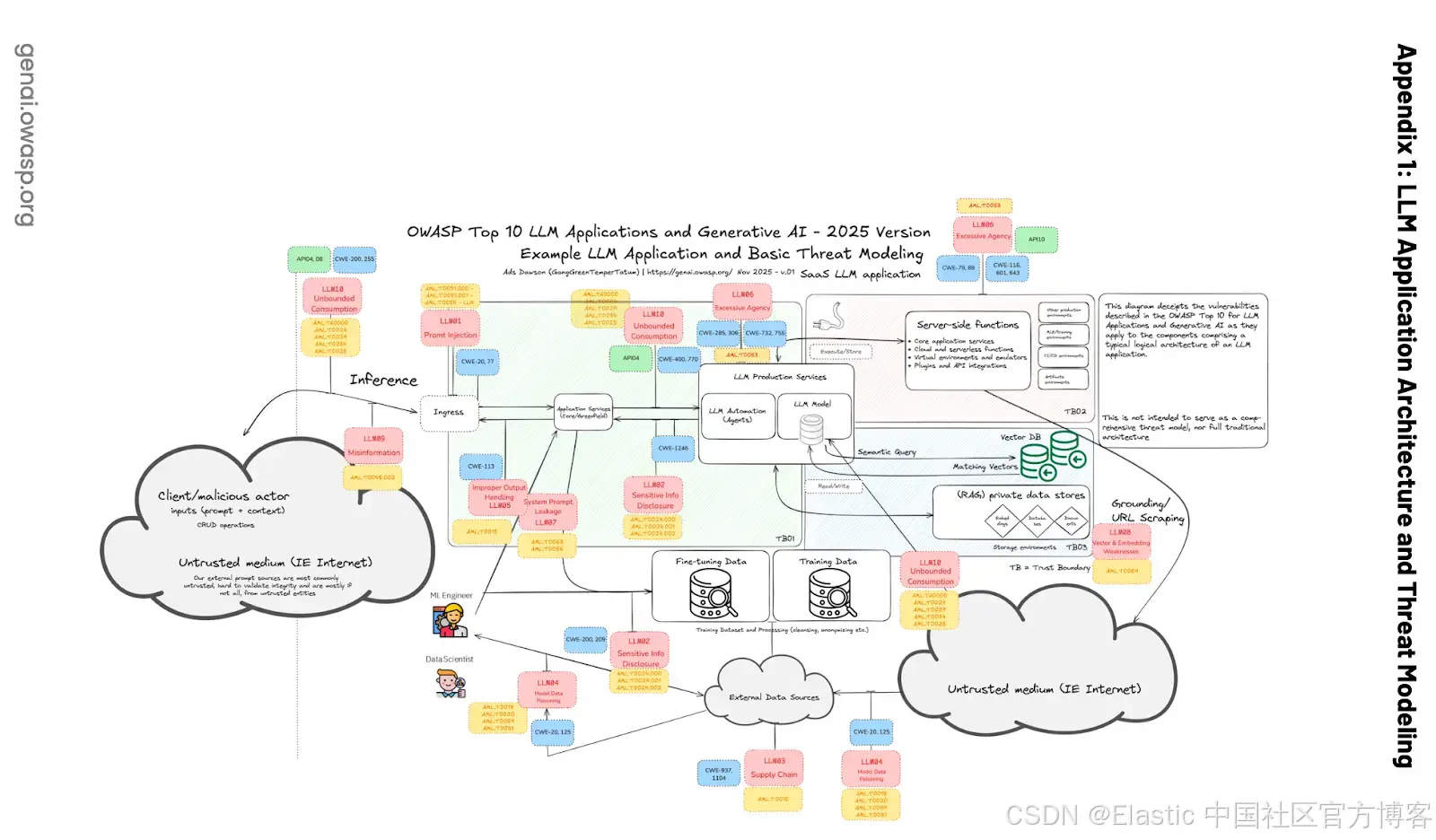 Image source: https://wtit.com/blog/2025/04/17/owasp-top-10-for-llm-applications-2025
Image source: https://wtit.com/blog/2025/04/17/owasp-top-10-for-llm-applications-2025
根据 LLM08:2025 Vector 和 Embedding 弱点,常见风险之一是上下文泄漏:
在多租户环境中,多个用户类别或应用共享同一个 vector database 时,存在用户或查询之间发生上下文泄漏的风险。当来自多个数据源的数据相互矛盾时,可能会出现数据联邦的知识冲突错误。当 LLM 无法用 Retrieval Augmentation 获取的新数据覆盖其在训练期间学到的旧知识时,也会发生这种情况。
另一个方面是,LLM 可能很难用 memory 中的新信息去覆盖它内置的知识。如果模型在训练时学过某个事实,而检索到的 context 说的是相反的内容,模型可能会混淆,不知道该信哪一个。如果没有合适的设计,agent 可能会混合不同的 context,或者无法用新的证据更新旧知识,从而导致陈旧或错误的答案。
幻觉(hallucinations)和错误信息(misinformation)
即使在没有长 context 的情况下,幻觉(LLM 编造看起来合理但实际上是错误的信息)也是一个已知问题,而糟糕的 memory 管理会放大这个问题。
如果 agent 的 memory 缺少一个关键事实,模型可能会用猜测来填补空白;而如果这个猜测随后进入了 context(污染了 context),错误就会持续存在。
OWASP LLM 安全报告(LLM09:2025 Misinformation)将错误信息列为一个核心漏洞:LLM 可能生成自信但捏造的答案,而用户可能会过度信任它们。一个拥有不良或过时 long-term memory 的 agent,可能会自信地引用去年还正确、但现在已经错误的信息,除非它的 memory 能保持更新。
用户或 agent 自身(在循环中)对 AI 输出的过度依赖,会让问题更加严重。如果没有人去检查 memory 里的信息,agent 可能会不断积累错误内容。这也是为什么常常使用 RAG 来减少幻觉:通过检索权威来源,模型就不必去编造事实。但如果检索拉取了错误的文档(例如包含错误信息的文档),或者早期的幻觉没有被清理,系统就可能在整个行动过程中传播这些错误信息。
总结 :未能正确管理 memory 会导致不正确和具有误导性的输出,而在高风险场景下(例如金融或医疗领域给出错误建议)尤其具有破坏性。一个 agent 需要有机制去验证或纠正其 memory 内容,而不是无条件地信任 context 中的任何信息。
总之,给 AI agent 一个无限长的 memory,或者把所有可能的东西一股脑丢进它的 context,并不是成功的做法。
LLM 应用中 memory 管理的最佳实践
为了避免上述问题,开发者和研究人员总结了一些用于管理 AI 系统中 context 和 memory 的最佳实践。这些实践的目标是让 AI 的工作 context 保持精简、相关且最新。下面是一些关键策略,以及它们如何发挥作用的示例。
RAG:使用有针对性的 context
前面的章节已经介绍了很多关于 RAG 的内容,这里作为一组简明的实践提醒:
- 使用有针对性的检索,而不是批量加载:只检索最相关的 chunk,而不是把整个文档或完整的对话历史都塞进 prompt。
- 将 RAG 视为即时(just-in-time)的 memory 召回:只在需要时才拉取 context,而不是在多轮对话中一直携带所有内容。
- 优先使用与相关性相关的检索策略:例如 top-k 语义搜索、倒数排序融合(Reciprocal Rank Fusion),或 tool loadout 过滤,有助于减少噪声并提升 grounding。
- 更大的 context window 并不能消除对 RAG 的需求:两个高度相关的段落,几乎总是比 20 页松散相关的内容更有效。
也就是说,RAG 的重点不是加入更多 context,而是加入正确的 context。
工具配置( Tool loadout )
工具配置是指只给模型完成某个任务真正需要的工具 。这个术语来自游戏:你会选择一个适合当前情境的 loadout。工具太多会拖慢你;工具选错会直接失败。根据研究论文 Less is More ,LLM 的行为也是一样的。一旦工具数量超过约 30 个,描述就开始相互重叠,模型会变得困惑;超过约 100 个工具,几乎必然失败。这不是 context window 的问题,而是 context 混乱。
一个简单而有效的解决方案是 RAG-MCP。与其把所有工具一股脑塞进 prompt,不如把工具描述存进向量数据库,然后每次请求只检索最相关的工具。实际效果是:loadout 保持小而聚焦,prompt 明显变短,工具选择的准确率最高可以提升到原来的 3 倍。
更小的模型会更早撞上这堵墙。研究显示,一个 8B 模型在面对几十个工具时会失败,但在精简 loadout 之后却能成功。动态选择工具 ------ 有时先让 LLM 自己推理它需要哪些工具 ------ 可以将性能提升 44%,同时降低功耗和延迟。结论是:大多数 agent 实际上只需要少量工具,但随着系统规模增长,工具配置和 RAG-MCP 会成为一等重要的设计决策。
Context 剪枝:限制聊天历史长度
如果一次对话持续很多轮,累积的聊天历史可能会变得太大,无法放入 context,或者对模型来说过于干扰。
Trimming(对话修剪) 指的是在对话不断增长时,以程序方式移除或缩短不那么重要的对话部分。一种最简单的形式是在达到某个限制时丢弃最早的对话轮次,只保留最近的 N 条消息。更复杂的剪枝方式可能会移除无关的岔题内容,或已经不再需要的旧指令。目标是让 context window 不被过时的信息弄乱。
例如,如果 agent 在 10 轮之前已经解决了一个子问题,而现在已经进入新的阶段,我们就可以把那一段历史从 context 中删除(前提是之后不再需要它)。许多基于聊天的实现都会这样做:它们维护一个滚动的最近消息窗口。
Trimming 也可以很简单,比如在对话被总结完成,或被判断为无关之后,就 "忘记" 最早的部分。这样做可以降低 context overflow 错误的风险,同时减少 context 干扰,让模型不会被旧的或跑题的内容分散注意力。这种方式非常类似人类的行为:我们不会记住一小时演讲中的每一句话,但会保留重点。
如果你对 context 剪枝感到困惑,正如作者 Drew Breunig 提到的那样,使用 Provence(naver/provence-reranker-debertav3-v1)模型------一个轻量级(1.75 GB)、高效且准确的 context 剪枝器,用于 question answering ------ 可以带来明显帮助。它可以根据给定 query,把大型文档裁剪为只包含最相关的文本。你可以在特定的时间间隔调用它。
下面是我们在代码中调用 provence-reranker 模型来剪枝 context 的方式:
# Context pruning with Provence
def prune_with_provence(query: str, context: str, threshold: Optional[float] = None) -> str:
"""
Prune context using Provence reranker model
Args:
query: User's query/question
context: Original context to prune
threshold: Relevance threshold (0-1) for Provence reranker.
If None, uses args.pruning_threshold.
0.1 = conservative (recommended, no performance drop)
0.3-0.5 = moderate to aggressive pruning
Returns:
Pruned context with only relevant sentences
"""
if provence_model is None:
return context
if threshold is None:
threshold = args.pruning_threshold
try:
# Use Provence's process method
provence_output = provence_model.process(
question=query,
context=context,
threshold=threshold,
always_select_title=False,
enable_warnings=False
)
# Extract pruned context from output
pruned_context = provence_output.get('pruned_context', context)
reranking_score = provence_output.get('reranking_score', 0.0)
# Log statistics
original_length = len(context)
pruned_length = len(pruned_context)
reduction_pct = ((original_length - pruned_length) / original_length * 100) if original_length > 0 else 0
if args.verbose:
rich.print(f"[cyan]📊 Pruning stats: {pruned_length}/{original_length} chars ({reduction_pct:.1f}% reduction, threshold={threshold:.2f}, rerank_score={reranking_score:.3f})[/cyan]")
return pruned_context if pruned_context else context
except Exception as e:
rich.print(f"[yellow]⚠️ Error in Provence pruning: {str(e)}[/yellow]")
rich.print(f"[yellow]⚠️ Falling back to original context[/yellow]")
return context我们使用 Provence reranker 模型(naver/provence-reranker-debertav3-v1)来对句子的相关性进行打分。基于阈值的过滤会保留高于相关性阈值的句子。同时,我们引入了一个 fallback 机制:如果剪枝失败,就返回原始 context。最后,在 verbose 模式下,通过统计日志来跟踪 context 缩减的百分比。
Context 总结:压缩较旧的信息,而不是完全丢弃
Summarization 是 trimming 的一个配套方法。当历史记录或知识库变得过大时,你可以使用 LLM 生成一份关键点的简要总结,并在后续使用这份总结来替代完整内容,就像我们在上面的代码中所做的一样。
例如,如果一个 AI assistant 已经进行了 50 轮对话,那么在第 51 轮时,与其把全部 50 轮都发送给模型(很可能放不下),系统可以把第 1--40 轮交给模型生成一段总结,然后在下一次 prompt 中只提供这段总结加上最近的 10 轮对话。这样,模型仍然知道之前讨论了什么,而不需要每一个细节。早期的 chatbot 用户会手动这样做,比如问:"你能总结一下我们到目前为止聊过的内容吗?"然后在一个新的 session 中基于总结继续。现在,这个过程可以自动化完成。Summarization 不仅可以节省 context window 空间,还可以通过去除多余细节、只保留关键信息,来减少 context 混淆 / 干扰。
下面是我们如何使用 OpenAI 模型(你也可以使用任何 LLM)来压缩 context,在保留所有相关信息的同时,消除冗余和重复内容。
# Context summarization
def summarize_context(query: str, context: str) -> str:
"""
Summarize context using LLM to reduce duplication and focus on relevant information
Args:
query: User's query/question
context: Context to summarize
Returns:
Summarized context
"""
try:
summary_prompt = f"""You are an expert at summarizing conversation context.
Your task: Analyze the provided conversation context and produce a condensed summary that fully answers or supports the user's specific question.
The summary must:
1. Preserve every fact, detail, and information that directly relates to the question
2. Eliminate redundancy and duplicate information
3. Maintain chronological flow when relevant
4. Focus on information that helps answer: "{query}"
Context to summarize:
{context}
Provide a concise summary that preserves all relevant information:"""
summary = llm.invoke(summary_prompt).content
if args.verbose:
original_length = len(context)
summary_length = len(summary)
reduction_pct = ((original_length - summary_length) / original_length * 100) if original_length > 0 else 0
rich.print(f"[cyan]📝 Summarization stats: {summary_length}/{original_length} chars ({reduction_pct:.1f}% reduction)[/cyan]")
return summary
except Exception as e:
rich.print(f"[yellow]⚠️ Error in context summarization: {str(e)}[/yellow]")
rich.print(f"[yellow]⚠️ Falling back to original context[/yellow]")
return context重要的是,当 context 被总结之后,模型就不太容易被琐碎的细节或过去的错误压垮(前提是 summary 是准确的)。
但是,summarization 必须非常小心。一个不好的 summary 可能会遗漏关键细节,甚至引入错误。本质上,这又是一次给模型的 prompt("summarize this"),因此它可能会 hallucinate,或者丢失细微差别。最佳实践是增量式 summarization,并且可能要保留一些规范性的事实,不对它们做总结。
尽管如此,summarization 已被证明非常有用。在 Gemini agent 的场景中,大约每 ~100k tokens 对 context 做一次总结,是对抗模型反复重复自身行为的一种方式。这个 summary 就像是对话或数据的压缩记忆。作为开发者,我们可以让 agent 定期调用一个 summarization 函数(可能是一个更小的 LLM,或者一个专用流程),对对话历史或长文档进行总结,然后用生成的 summary 替换 prompt 中的原始内容。这种策略被广泛用于保持 context 在限制范围内,并提炼关键信息。
Context 隔离(context quarantine):在可能的情况下隔离 context
这一点在复杂的 agent 系统或多步骤 workflow 中尤其重要。Context segmentation 的思想是,把一个大任务拆分成更小、彼此隔离的任务,每个任务都有自己的 context,这样就不会积累一个包含所有信息的巨大 context。每个 subagent 或 subtask 都在一个高度聚焦的 context 中处理问题,然后由一个更高层的 agent、supervisor 或 coordinator 来整合这些结果。
 多 agent 架构实际运行:用户查询通过一个 lead agent 流动,该 agent 创建专门的 subagents 并行搜索不同方面。
多 agent 架构实际运行:用户查询通过一个 lead agent 流动,该 agent 创建专门的 subagents 并行搜索不同方面。
图片来源: https://www.anthropic.com/engineering/multi-agent-research-system
Anthropic 的研究策略使用多个 subagents,每个 subagent 调查问题的不同方面,拥有自己的 context window,同时由一个 lead agent 阅读这些 subagents 的提炼结果。这种并行、模块化的方法意味着没有单一的 context window 会过于臃肿。它还减少了无关信息混入的可能性,每个线程保持主题相关(没有 context 混乱),在回答特定子问题时不会携带不必要的负担。从某种意义上说,这就像运行独立的思维线程,只共享结果,而不是整个思维过程。
在多 agent 系统中,这种方法至关重要。如果 Agent A 处理任务 A,Agent B 处理任务 B,除非确实需要,否则没有理由让任一 agent 消耗另一个的完整 context。相反,agents 只交换必要的信息。例如,Agent A 可以通过一个 supervisor agent 将其发现的综合总结传给 Agent B,同时每个 subagent 保持自己专用的 context 线程。这种设置不需要 human-in-the-loop 干预;它依赖于一个带启用工具的 supervisory agent,并进行最小且可控的 context 共享。
尽管如此,设计系统时让 agents 或工具以最小必要 context 重叠运行可以大大增强清晰度和性能。可以把它看作 AI 的 microservices,每个组件处理自己的 context,然后以可控方式传递消息,而不是一个单一庞大的 context。这些最佳实践通常结合使用。它还允许你修剪琐碎历史,总结重要的旧消息或对话,将详细日志卸载到 Elasticsearch 以供长期 context 使用,并在需要时通过检索取回相关内容。
如前所述,指导原则是 context 是有限且宝贵的资源。你希望 prompt 中的每个 token 都物有所值,即它应当提升输出质量。如果 memory 中的某些内容不起作用(或更糟,还会造成混乱),那么它应当被修剪、总结或排除。
作为开发者,我们现在可以像编程代码一样编程 context,决定包含哪些信息、如何格式化以及何时省略或更新。遵循这些实践,我们可以赋予 LLM agents 所需的 context,使其执行任务而不受前面描述的失败模式影响。结果是 agent 能记住应该记住的,忘记不需要的,并在需要时及时检索所需内容。
结论
Memory 并不是你给 agent 添加的东西,而是你设计的东西。Short-term memory 是 agent 的工作草稿板,long-term memory 是其持久知识库。RAG 是两者之间的桥梁,将被动的数据存储(如 Elasticsearch)转化为可主动调用的机制,从而支持输出并保持 agent 的实时性。
但 memory 是把双刃剑。一旦你让 context 无限制增长,就会引入 poisoning、distraction、confusion 和 clash,在共享系统中甚至可能发生数据泄漏。这就是为什么最重要的 memory 工作不是 "存储更多",而是 "更好地策划":选择性检索、积极修剪、谨慎总结,并避免混合无关 context,除非任务确实要求。
在实践中,良好的 context engineering 就像良好的系统设计:更小、足够的 context,组件之间受控的接口,以及原始状态与实际希望模型看到的精炼状态之间的清晰分离。做得对,你不会得到一个记住一切的 agen t------ 你会得到一个在正确时间记住正确事情、出于正确原因的 agent。
原文:https://www.elastic.co/search-labs/blog/agentic-memory-management-elasticsearch