文章目录
- 一、节点说明
- 二、配置节点间免密登录
- 三、JDK安装
- 四、Zookeeper安装
- 五、Hadoop安装
- 六、Flink安装
- 七、集群测试
-
-
- 1、启动zookeeper,hadoop
- [2、Yarn Session测试](#2、Yarn Session测试)
- 3、Per-Job测试
-
一、节点说明
1、相关软件
| IP | 主机名 | 部署软件 |
|---|---|---|
| 192.168.10.102 | node02 | jdk,hadoop,zookeeper,flink |
| 192.168.10.103 | node03 | jdk,hadoop,zookeeper,flink |
| 192.168.10.104 | node04 | jdk,hadoop,zookeeper,flink |
2、相关进程
| node02 | node03 | node04 | |
|---|---|---|---|
| HDFS | NameNode DFSZKFailoverController JournalNode DataNode | NameNode DFSZKFailoverController JournalNode DataNode | JournalNode DataNode |
| YARN | ResourceManager NodeManager | ResourceManager NodeManager | NodeManager |
| zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| flink |
二、配置节点间免密登录
参考本人此篇文章:Linux软件安装 ------ SSH免密登录
三、JDK安装
参考本人此篇文章:Linux软件安装 ------ JDK安装
四、Zookeeper安装
参考本人此篇文章:Linux软件安装 ------ zookeeper集群安装
五、Hadoop安装
参考本人此篇文章:Linux软件安装 ------ Hadoop高可用安装(集成Zookeeper)
六、Flink安装
1、基础环境准备
(1)下载安装包
官方文档:Downloads | Apache Flink 一直拉倒最后就会显示所有历史版本
本文使用版本为:flink-1.13.6-bin-scala_2.12.tgz
(2)上传并解压
shell
# 加压到安装目录
tar -zxvf flink-1.13.6-bin-scala_2.12.tgz -C /opt/module/
# 修改名称
mv flink-1.13.6/ flink2、修改配置
(1)配置zookeeper
使用flink内置zookeeper才配,自己搭的不用配此项
shell
# 编辑flink中的zookeeper文件
vim /opt/module/flink/conf/zoo.cfg
# 添加data和log位置
dataDir=/opt/module/flink/flink-zookeeper/data
dataLogDir=/opt/module/flink/flink-zookeeper/logs
# 修改zookeeper集群信息
server.2=node02:2888:3888
server.3=node03:2888:3888
server.4=node04:2888:3888(2)配置flink-conf.yaml
yaml
# 备份原始文件
cp flink-conf.yaml flink-conf.yaml.bak
# 编辑flink-conf.yaml文件
vim /opt/module/flink/conf/flink-conf.yaml
# ==================== 基础配置 ====================
# JobManager节点,指定node02为JobManager
jobmanager.rpc.address: node02
jobmanager.rpc.port: 6123
# JobManager堆内存(根据实际内存调整,建议4G以上)
jobmanager.memory.process.size: 1024m
# TaskManager堆内存(根据实际内存调整)
taskmanager.memory.process.size: 1024m
# 每个TaskManager的slot数量(根据CPU核心数调整)
taskmanager.numberOfTaskSlots: 1
# 并行度默认值
parallelism.default: 1
web.tmpdir: /opt/module/flink/flink-jar
blob.storage.directory: /opt/module/flink/flink-blob
yarn.maximum-failed-containers: 200
taskmanager.tmp.dirs: /opt/module/flink/flink-data
flink_log_bak_dir: /opt/module/flink/logs
flink_log_dir: /opt/module/flink/logs
# ==================== 高可用配置 ====================
high-availability: zookeeper
high-availability.zookeeper.quorum: node02:2181,node03:2181,node04:2181
# Zookeeper中Flink的根路径
high-availability.zookeeper.path.root: /flink
# JobManager元数据存储路径(使用HDFS)
high-availability.zookeeper.storageDir: hdfs:///flink/recovery
fs.hdfs.hadoopconf: /opt/module/hadoop/etc/hadoop
fs.hdfs.hdfssite: /opt/module/hadoop/etc/hadoop/hdfs-site.xml
# ==================== 故障恢复、checkpoint ====================
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 5 s
state.backend: rocksdb
state.backend.incremental: true
state.checkpoint-storage: filesystem
state.checkpoints.dir: hdfs:///flink/flink-checkpoints
state.checkpoints.num-retained: 1
state.savepoints.dir: hdfs:///flink/flink-savepoints
# =============== 禁用flink类加载器,优先使用用户上传===============
classloader.check-leaked-classloader: false
classloader.resolve-order: child-first(3)配置workers
shell
vim workers
node02
node03
node04(4)创建必要的目录
shell
mkdir -p /opt/module/flink/flink-data
mkdir -p /opt/module/flink/flink-blob
mkdir -p /opt/module/flink/flink-jar
mkdir -p /opt/module/flink/flink-zookeeper/data
mkdir -p /opt/module/flink/flink-zookeeper/logs(5)配置环境变量
shell
# 编辑环境变量,创建单独文件方便管理
vim /etc/profile.d/my_env.sh
# JAVA_HOME,JDK文章中已配置,此处不配,仅做展示
export JAVA_HOME=/opt/module/jdk8
export PATH=$PATH:$JAVA_HOME/bin
# ZOOKEEPER_HOME,zookeeper文章中已配置,此处不配,仅做展示
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# HADOOP_HOME,hadoop文章中已配置,此处不配,仅做展示
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_PID_DIR=/opt/module/hadoop/pid
export HADOOP_SECURE_PID_DIR=${HADOOP_PID_DIR}
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# FLINK_HOME
export FLINK_HOME=/opt/module/flink
export PATH=$PATH:$FLINK_HOME/bin
# 退出后,刷新环境变量
source /etc/profile.d/my_env.sh3、分发flink
shell
# 将配好的flink分发到node03,node04
scp -r flink/ root@node03:/opt/module/
scp -r flink/ root@node04:/opt/module/七、集群测试
1、启动zookeeper,hadoop
shell
# 启动zookeeper,三个节点分别启动
zkServer.sh start
# 启动hadoop,node02
# 启动hdfs集群
start-dfs.sh
# 启动hdfs集群
start-yarn.sh2、Yarn Session测试
(1)模式介绍
YARN Session模式特点:
- 先启动一个长期运行的Flink集群
- 在该集群上可以提交多个作业
- 适合短作业频繁提交的场景
- 资源共享,启动速度快
(2)准备测试资源
shell
# 创建测试用的HDFS目录
hdfs dfs -mkdir -p /flink/test/input
hdfs dfs -mkdir -p /flink/test/output
# 上传测试数据到HDFS
echo "hello world hello flink
flink is fast
hello hadoop
flink streaming" > test.txt
hdfs dfs -put test.txt /flink/test/input/(3)启动YARN Session
shell
# 在node02上执行(作为客户端)
cd $FLINK_HOME
# 方法1:交互式启动(推荐测试用)
./bin/yarn-session.sh -d
# 方法2:分离模式启动
./bin/yarn-session.sh -d -jm 1024m -tm 2048m -s 2 -nm "FlinkYarnSession"
# 参数说明:
# -d: 分离模式(后台运行)
# -jm: JobManager内存(默认1024m)
# -tm: 每个TaskManager内存(默认1024m)
# -s: 每个TaskManager的slot数量(默认1)
# -nm: YARN应用名称
# -qu: YARN队列名称
# -D: 传递Flink配置参数
# 示例:指定更多资源
./bin/yarn-session.sh \
-d \
-jm 2048m \
-tm 4096m \
-s 4 \
-nm "FlinkTestSession" \
-D taskmanager.memory.network.min=128mb \
-D taskmanager.memory.network.max=256mb \
-D parallelism.default=4(4)查看YARN Session状态
shell
# 查看YARN上的应用
yarn application -list
# 查找Flink Session应用ID
yarn application -list | grep Flink
# 查看应用详情
yarn application -status <application_id>
# 也可以直接打开yarn页面查看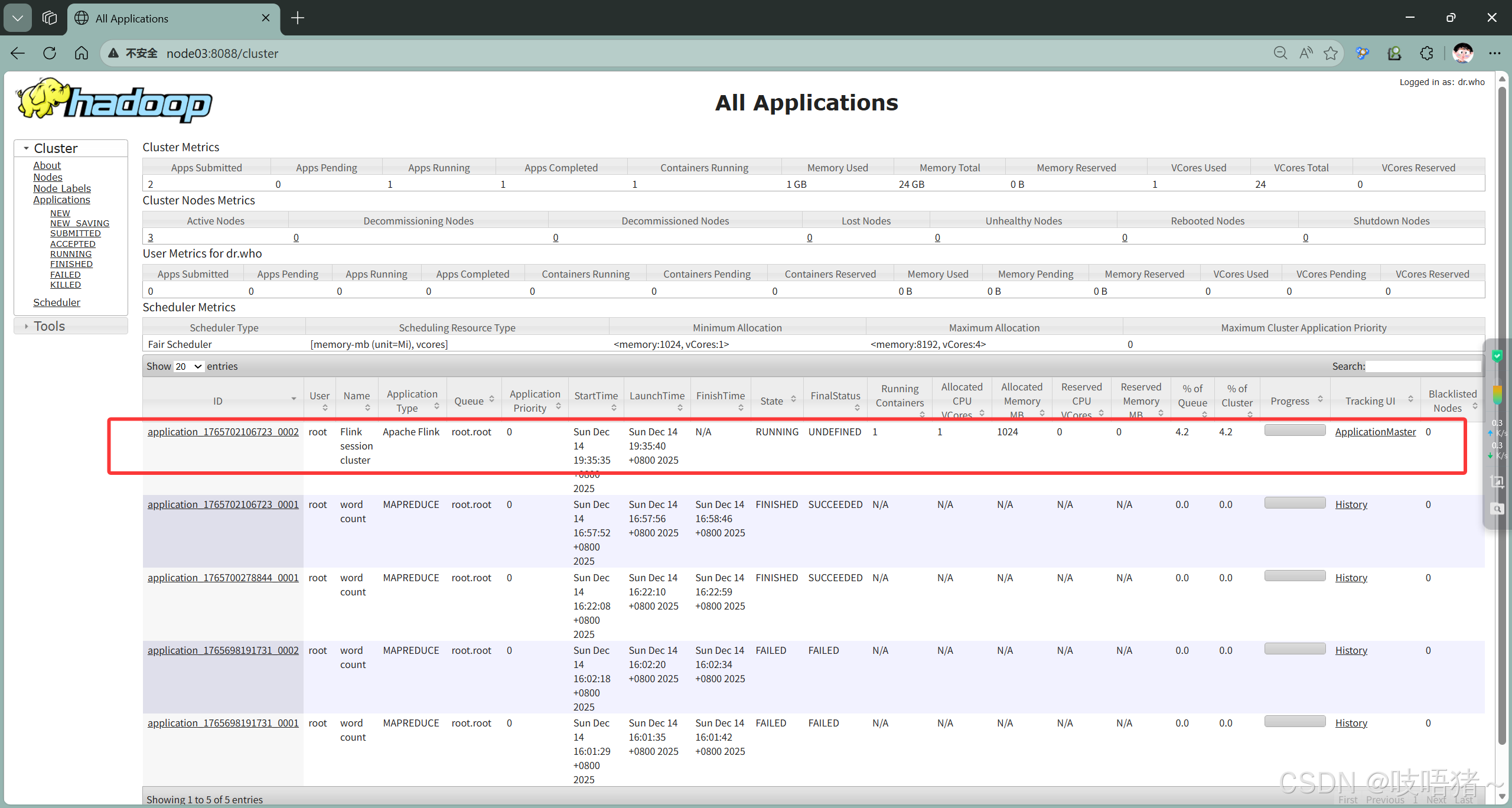
(5)提交作业
shell
# 首先找到刚刚启动的session,获取YARN应用ID
yarn application -list
# 测试1:提交WordCount示例作业
./bin/flink run \
-m yarn-cluster \
-yid application_1765702106723_0004 \
./examples/streaming/WordCount.jar \
--input hdfs://ns/flink/test/input/test.txt \
--output hdfs://ns/flink/test/output/wordcount_result
# 测试2:提交Socket作业(需要先启动netcat)
# 在一个终端启动netcat
nc -lk 9999
# 在另一个终端提交Socket作业
./bin/flink run \
-m yarn-cluster \
-yid application_1765702106723_0004 \
./examples/streaming/SocketWindowWordCount.jar \
--hostname node02 \
--port 9999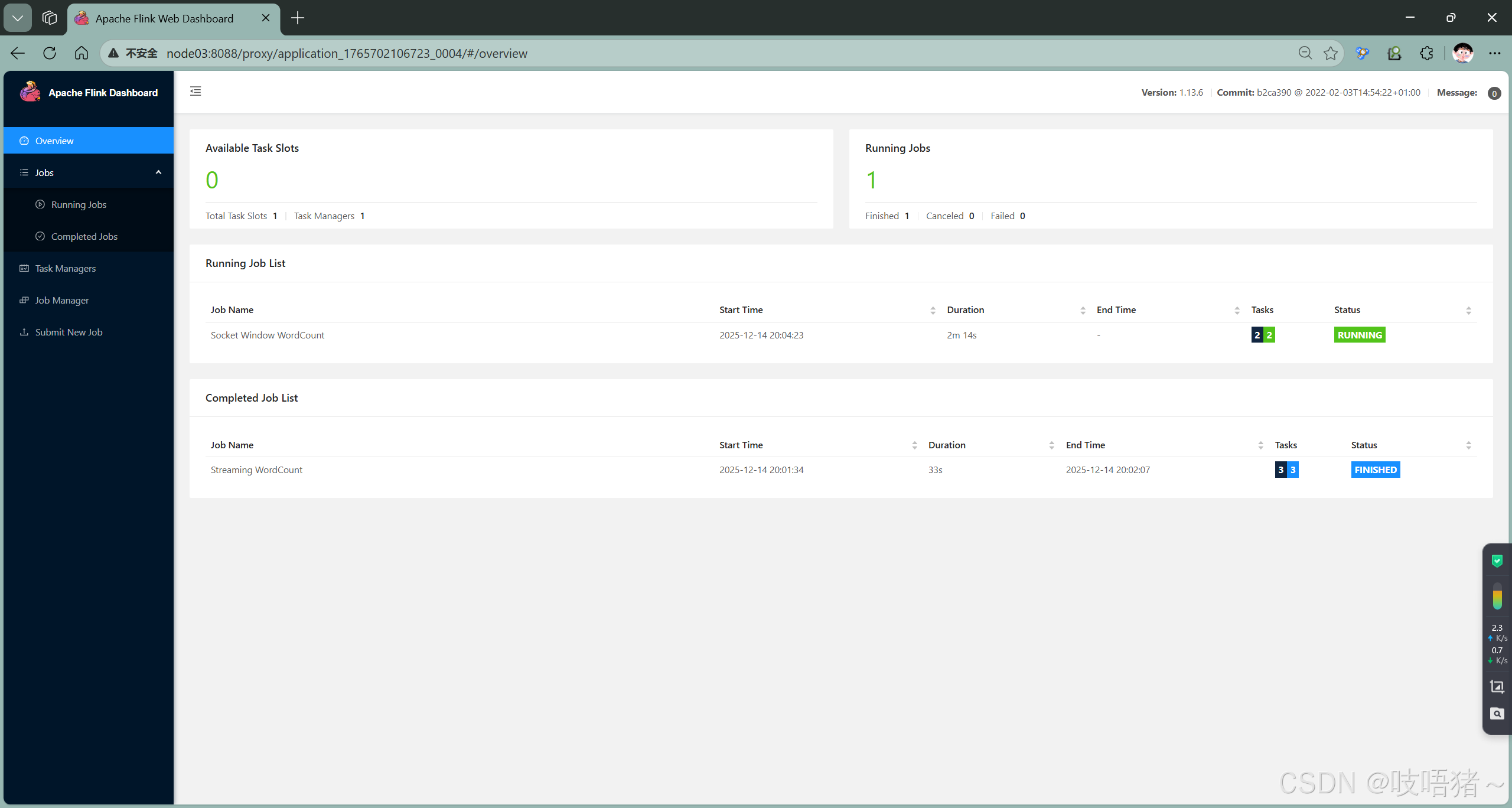
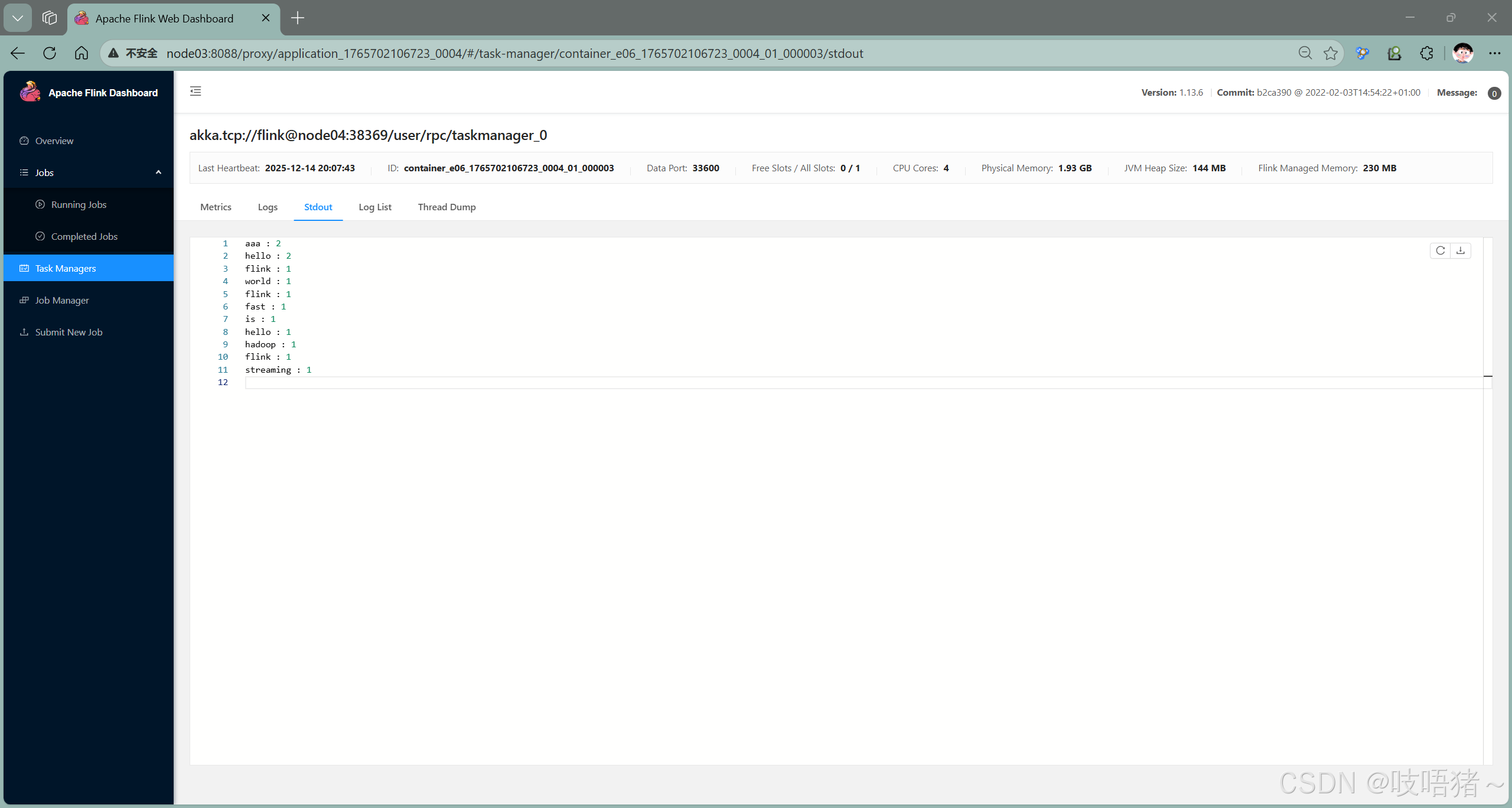
(6)停止YARN Session
shell
# 方法1:通过YARN命令停止
yarn application -kill application_1765702106723_0004
# 方法2:通过Flink命令停止
echo "stop" | ./bin/yarn-session.sh -id application_1765702106723_0004
# 方法3:在Web UI中停止
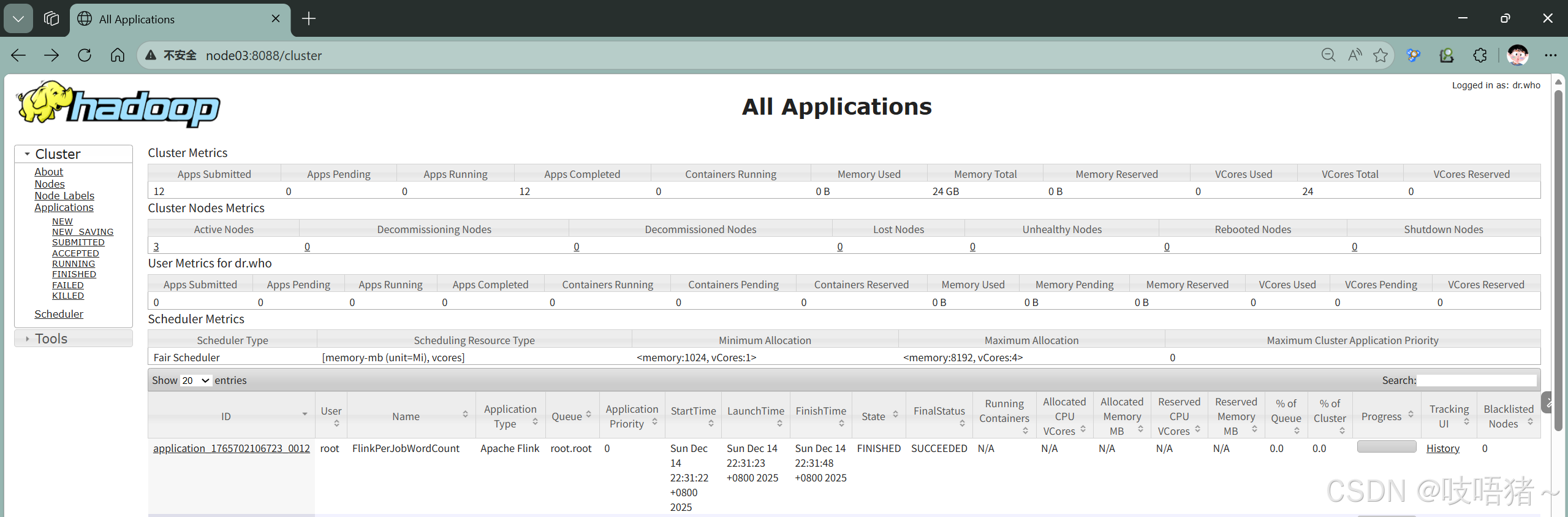
# 访问ApplicationMaster Web UI -> Cluster -> Stop Cluster3、Per-Job测试
(1)Per-Job模式介绍
Per-Job模式特点:
- 每个作业独立启动一个Flink集群
- 作业完成后集群自动释放资源
- 资源隔离性好
- 适合长时间运行的生产作业
(2)提交per-job作业
shell
./bin/flink run -d \
-m yarn-cluster \
-ynm "FlinkPerJobWordCount" \
-yjm 1024m \
-ytm 1024m \
-ys 1 \
-p 1 \
./examples/batch/WordCount.jar \
--input hdfs://ns/flink/test/input/test.txt \
--output hdfs://ns/flink/test/output/perjob_wordcount
nc -lk 9999
# 在另一个终端提交Socket作业
bin/flink run -d \
-m yarn-cluster \
-ynm "FlinkPerJobWordCount" \
-yjm 1024m \
-ytm 1024m \
-ys 1 \
-p 1 \
./examples/streaming/SocketWindowWordCount.jar \
--hostname node02 \
--port 9999
# 参数详细说明:
# -m yarn-cluster: 指定YARN Per-Job模式
# -ynm: YARN应用名称
# -yjm: JobManager内存
# -ytm: TaskManager内存
# -ys: 每个TaskManager的slot数量
# -yqu: YARN队列名称
# -p: 作业并行度
# -yD: 传递动态参数,如:-yD taskmanager.memory.network.min=128mb