文章目录
- 一、节点说明
- 二、配置节点间免密登录
- 三、JDK安装
- 四、Zookeeper安装
- 五、Hadoop安装
- 六、初始化及启动
- 七、集群验证
-
-
- [1、Web UI访问](#1、Web UI访问)
- [2、 功能测试](#2、 功能测试)
- 3、故障转移测试
-
一、节点说明
1、相关软件
| IP | 主机名 | 部署软件 |
|---|---|---|
| 192.168.10.102 | node02 | jdk,hadoop,zookeeper |
| 192.168.10.103 | node03 | jdk,hadoop,zookeeper |
| 192.168.10.104 | node04 | jdk,hadoop,zookeeper |
2、相关进程
| node02 | node03 | node04 | |
|---|---|---|---|
| HDFS | NameNode DFSZKFailoverController JournalNode DataNode | NameNode DFSZKFailoverController JournalNode DataNode | JournalNode DataNode |
| YARN | ResourceManager NodeManager | ResourceManager NodeManager | NodeManager |
| zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
二、配置节点间免密登录
参考本人此篇文章:Linux软件安装 ------ SSH免密登录
三、JDK安装
参考本人此篇文章:Linux软件安装 ------ JDK安装
四、Zookeeper安装
参考本人此篇文章:Linux软件安装 ------ zookeeper集群安装
五、Hadoop安装
1、基础环境准备
(1)下载安装包
下载地址:Apache Hadoop
本文使用版本为:hadoop-3.1.3.tar.gz
(2)上传并解压
shell
# 解压到安装目录
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
# 修改名称
mv hadoop-3.1.3/ hadoop(3)创建必要的目录
shell
mkdir -p /opt/module/hadoop/tmp
mkdir -p /opt/module/hadoop/journal
mkdir -p /opt/module/hadoop/pid
mkdir -p /opt/module/hadoop/nm-local-dir
mkdir -p /opt/module/hadoop/hdfs/name
mkdir -p /opt/module/hadoop/hdfs/data
mkdir -p /opt/module/hadoop/hdfs/namesecondary2、hadoop配置文件
以下配置文件均在/opt/module/hadoop/etc/hadoop下
(1)配置core-site.xml
xml
<configuration>
<!-- 指定HDFS的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 指定Hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 指定Zookeeper集群地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
</configuration>(2)配置hdfs-site.xml
xml
<configuration>
<!-- 指定副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1和nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>node03:8020</value>
</property>
<!-- HTTP通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>node02:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>node03:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node02:8485;node03:8485;node04:8485/ns</value>
</property>
<!-- 指定JournalNode本地磁盘存放路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop/journal</value>
</property>
<!-- 开启NameNode故障自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop/hdfs/data</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>(3)配置yarn-site.xml
xml
<configuration>
<!-- NodeManager上运行的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>clusterrm</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node03</value>
</property>
<!-- 用户通过此地址访问YARN管理界面(如查看应用状态、资源使用情况) -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node02:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
<!-- 开启自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的状态信息存储在zookeeper上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 调度器类型配置:这里使用公平调度器(Fair Scheduler) -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 启用抢占功能 -->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<!-- 下面配置用来设置集群利用率的阀值, 默认值0.8f,最多可以抢占到集群所有资源的80% -->
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>1.0</value>
</property>
<!-- 虚拟内存与物理内存比例 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.2</value>
</property>
<!-- NodeManager本地目录 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/module/hadoop/nm-local-dir</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
xml
<!-- 以下配置根据服务器配置进行配置 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>26214</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>(4)配置mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(5)配置workers
node02
node03
node043、将hadoop分发到node03,node04
shell
scp -r /opt/module/hadoop/ root@node03:/opt/module/
scp -r /opt/module/hadoop/ root@node04:/opt/module/六、初始化及启动
1、环境变量配置
三节点都需要
shell
# 编辑环境变量,创建单独文件方便管理
vim /etc/profile.d/my_env.sh
# JAVA_HOME,JDK文章中已配置,此处不配,仅做展示
export JAVA_HOME=/opt/module/jdk8
export PATH=$PATH:$JAVA_HOME/bin
# ZOOKEEPER_HOME,zookeeper文章中已配置,此处不配,仅做展示
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_PID_DIR=/opt/module/hadoop/pid
export HADOOP_SECURE_PID_DIR=${HADOOP_PID_DIR}
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 退出后,刷新环境变量
source /etc/profile.d/my_env.sh2、启动zookeeper
shell
# 在三个节点分别启动zookeeper
zkServer.sh start
# 也可以用zookeeper文章中创建的一键启停脚本,在node02上执行
zookeeper.sh start
# 查看zookeeper状态
zookeeper.sh status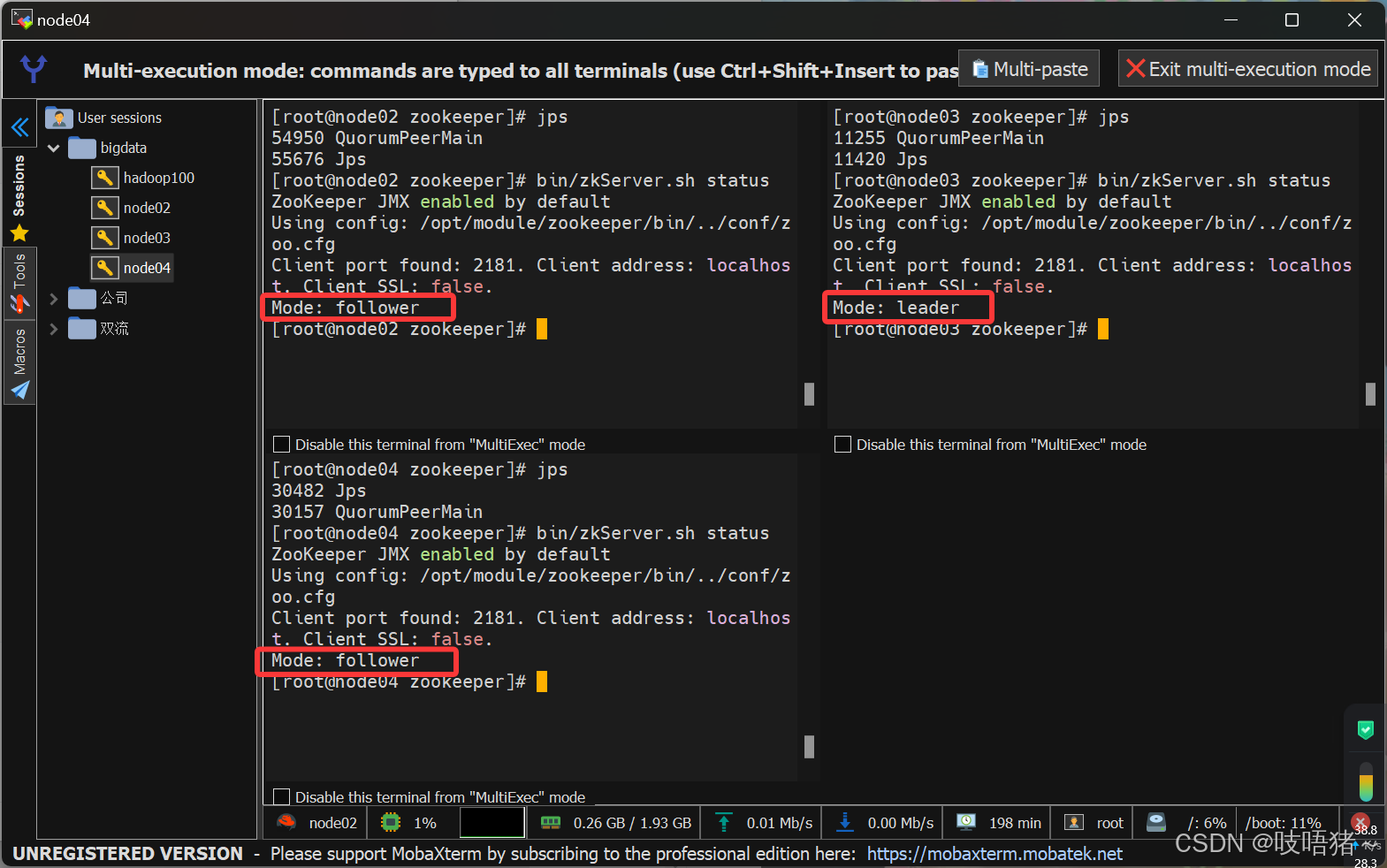
3、启动hdfs
shell
# 创建ZOOKEEPER中hadoop-ha命名空间,任意ZOOKEEPER节点执行,此处node02
hdfs zkfc -formatZK
# 启动journalnode,在node02,node03,node04分别执行如下命令
hadoop-daemon.sh start journalnode
# 初始化NameNode节点,任意一个NameNode节点,仅需要初始化一个,此处node02
hdfs namenode -format ns
# 启动当前NameNode,此处node02
hadoop-daemon.sh start namenode
# 在另一个NameNode节点执行同步元数据,此处node03
hdfs namenode -bootstrapStandby
# 启动当前NameNode,此处node03
hadoop-daemon.sh start namenode
# 在两个NameNode节点node02,node03启动zookeeper协同
hadoop-daemon.sh start zkfc
# 启动datanode,在node02,node03,node04分别执行如下命令
hadoop-daemon.sh start datanode此处因为第一次启动,涉及NameNode初始化,步骤相对多一点,后续启停步骤如下:
shell
###################### 一般步骤 ######################
# 启动journalnode,在node02,node03,node04分别执行如下命令
hadoop-daemon.sh start journalnode
# 启动NameNode,两个NameNode节点node02,node03
hadoop-daemon.sh start namenode
# 启动zookeeper协同,两个NameNode节点node02,node03
hadoop-daemon.sh start zkfc
# 启动datanode,在node02,node03,node04分别执行如下命令
hadoop-daemon.sh start datanode
# 停止为上述相同节点相反步骤依次执行
###################### 一键启停(官方提供) ######################
# 启动hdfs集群
start-dfs.sh
# 停止hdfs集群
stop-dfs.sh4、启动yarn集群
shell
###################### 一般步骤 ######################
# 启动resourcemanager,两个resourcemanager节点node02,node03
yarn-daemon.sh start resourcemanager
### 启动nodemanager,在node02,node03,node04分别执行如下命令
yarn-daemon.sh start nodemanager
###################### 一键启停(官方提供) ######################
# 启动hdfs集群
start-yarn.sh
# 停止hdfs集群
stop-yarn.sh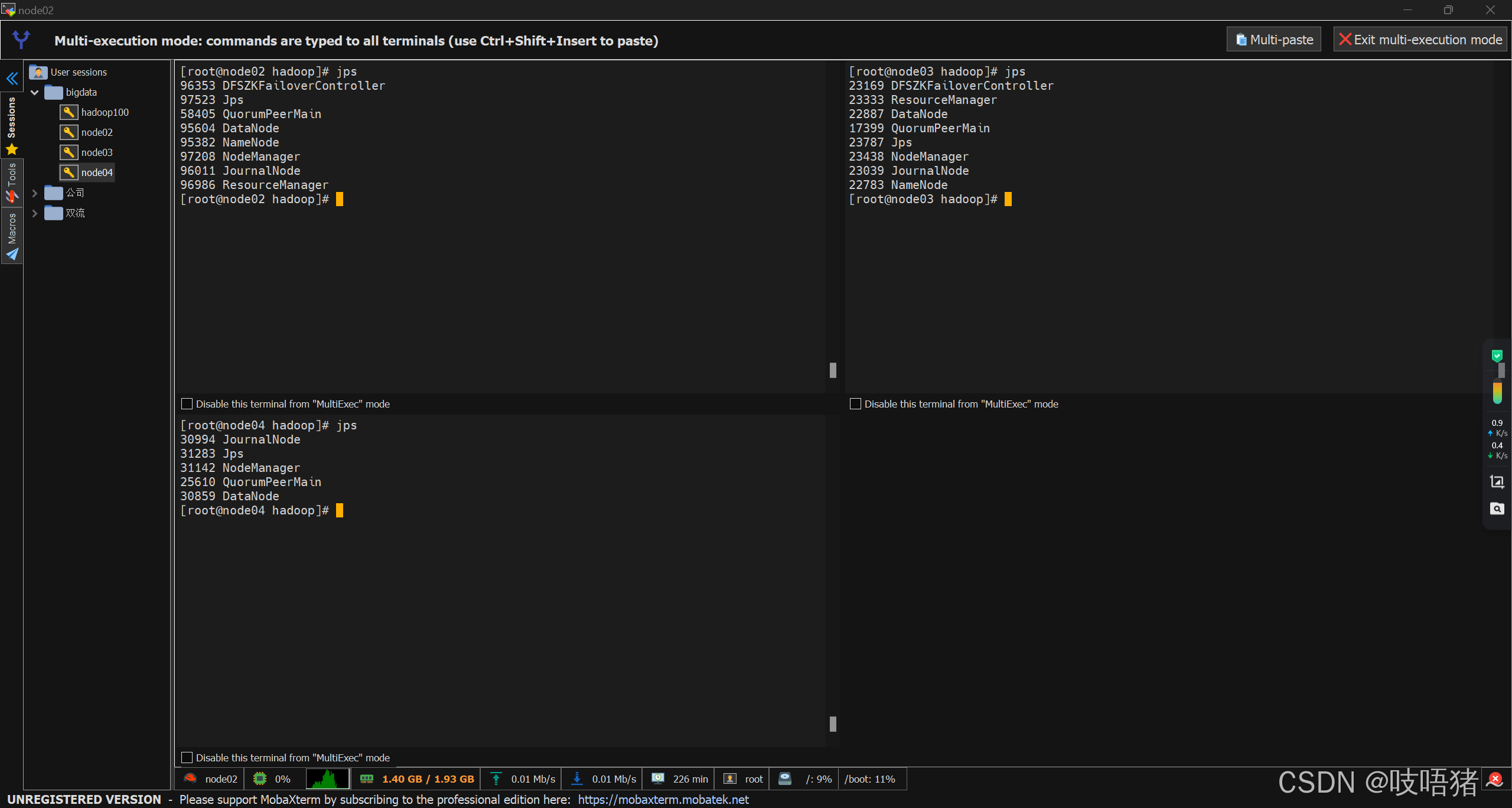
七、集群验证
1、Web UI访问
(1)HDFS NameNode UI:
- Active NameNode: http://node02:9870
- Standby NameNode: http://node03:9870
(2)YARN ResourceManager UI:
- Active ResourceManager: http://node02:8088
- Standby ResourceManager: http://node03:8088
2、 功能测试
shell
# 1. 创建HDFS目录
hdfs dfs -mkdir /test
hdfs dfs -mkdir /input
# 2. 上传文件测试
echo "Hello Hadoop HA Cluster" > test.txt
hdfs dfs -put test.txt /test/
# 3. 查看文件
hdfs dfs -ls /test
hdfs dfs -cat /test/test.txt
# 4. 运行MapReduce测试
# 创建测试文件
echo "apple orange banana apple orange" > word.txt
echo "hadoop spark hive hadoop" >> word.txt
hdfs dfs -put word.txt /input/
# 运行WordCount示例,版本号以自己的版本为准
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input/word.txt /output/
# 查看结果
hdfs dfs -cat /output/part-r-000003、故障转移测试
shell
# 1. 查看当前Active NameNode
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
# 2. 手动故障转移
hdfs haadmin -transitionToStandby nn1
hdfs haadmin -transitionToActive nn2
# 3. 模拟故障(杀死Active NameNode进程)
# 找到Active NameNode的进程ID并kill
# 4. 观察自动故障转移
# 大约30秒后,Standby NameNode会自动切换为Active