文章目录
-
-
- [🔍 先明确:图片里的公式是什么](#🔍 先明确:图片里的公式是什么)
- [🧩 强化学习的三大主流路线](#🧩 强化学习的三大主流路线)
- [🎯 总结:"最大期望"的不同角色](#🎯 总结:“最大期望”的不同角色)
- [🎯 针对大模型RLHF的高效学习路径](#🎯 针对大模型RLHF的高效学习路径)
- [💡 Q-Learning 要不要学?](#💡 Q-Learning 要不要学?)
- [🚀 为实习准备的行动建议](#🚀 为实习准备的行动建议)
-
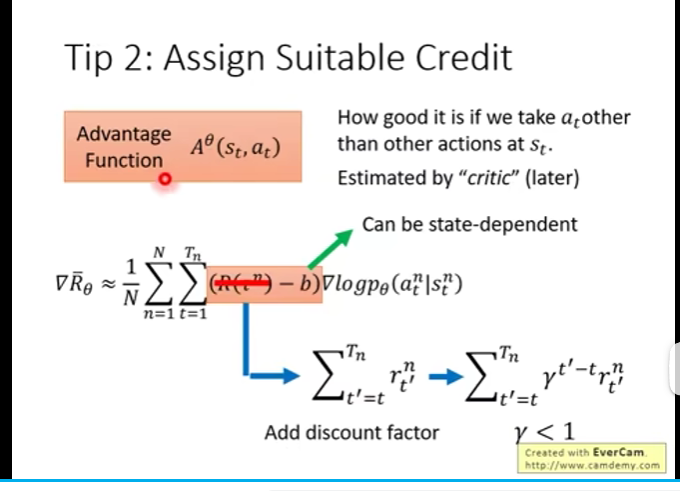
图片来源 李宏毅深度强化学习课程
不完全是这样哦~强化学习的范畴比"只围绕计算这个最大期望公式"要广得多,这个公式其实只是**策略梯度(Policy Gradient)**这类方法的核心,而强化学习还有很多其他流派和思路。
🔍 先明确:图片里的公式是什么
你贴的这个公式是策略梯度的梯度估计式 ,它的目标是直接优化策略 (\pi_\theta),让期望回报 (R_\theta) 最大化。它属于策略优化这条技术路线。
🧩 强化学习的三大主流路线
-
基于策略优化(Policy-Based)
- 代表算法:REINFORCE、Actor-Critic、PPO、TRPO
- 核心:直接对策略参数 (\theta) 求导,用梯度上升最大化期望回报。你图片里的公式就是这类方法的核心表达式。
- 特点:适合连续动作空间,策略更稳定,收敛性好。
-
基于价值函数(Value-Based)
- 代表算法:Q-Learning、SARSA、DQN
- 核心:不直接优化策略,而是学习状态/动作的价值函数 (V(s)) 或 (Q(s,a)),再通过价值函数间接得到最优策略。
- 特点:适合离散动作空间,价值函数可以用动态规划或时序差分(TD)方法迭代更新,完全不需要求导。
-
模型基(Model-Based)强化学习
- 代表算法:Dyna、World Models
- 核心:先学习环境的动态模型 (P(s',r|s,a)),再用这个模型规划或生成虚拟经验,来辅助策略或价值函数的学习。
- 特点:可以大幅减少与真实环境的交互,适合样本效率要求高的场景,但模型误差可能会影响性能。
🎯 总结:"最大期望"的不同角色
- 在策略优化中:它是直接的优化目标,公式就是核心工具。
- 在价值函数方法中:目标是找到能最大化长期价值的动作,而不是直接对策略求导。
- 在模型基方法中:目标是学习环境模型,再用模型来规划最优行为,期望回报是通过模型推演得到的。
所以,强化学习并不是"都围绕这一个公式",而是围绕"如何让智能体在环境中获得最大累计回报"这个核心问题,发展出了多种不同的技术路径。
如果你想更清晰地看到这些流派的区别,我可以帮你整理一份强化学习主流算法分类与核心思路对照表,让你一眼看清它们的关系。需要吗?
好的,结合你尽快跑大模型后训练项目、找实习这个核心目标,我帮你把优先级和路线重新梳理得更精准一些。
🎯 针对大模型RLHF的高效学习路径
你的核心需求是快速上手**大模型后训练(RLHF/RLAIF)**相关的算法,所以学习顺序必须向这个目标倾斜。
-
先学 Critic → 再学 PPO
- 你已经懂了策略梯度的公式,接下来 Critic 是 PPO 的直接前置知识。Critic 里的**优势估计(GAE)**正是 PPO 中用来计算策略更新权重的核心。
- PPO 是目前大模型 RLHF 中最主流的策略优化算法(比如 ChatGPT 早期就用了 PPO),必须吃透。
- 这一步的重点是:理解 PPO 的Clip 目标函数 和优势函数估计,能看懂代码里的实现逻辑。
-
立刻学 DPO
- DPO(Direct Preference Optimization)是 PPO 在大模型场景下的替代方案,它更简洁、训练更稳定,目前在开源社区(如 Llama 3、Mistral)中非常火。
- 它的理论基础是策略梯度 + 人类偏好建模,你有了 PPO 和 Critic 的基础,理解 DPO 会非常快。
- 这是你跑大模型后训练项目的核心工具,优先级最高。
-
GRPO 可作为补充
- GRPO 是更新的算法,思路上是对 PPO 和 DPO 的改进,但目前工业界落地还不如前两者广泛。
- 可以等你把 PPO 和 DPO 跑通项目后,再作为拓展学习。
💡 Q-Learning 要不要学?
短期内可以不用学,等实习稳定后再补。
- Q-Learning 属于"基于价值函数"的强化学习,和大模型后训练用的"策略梯度"是两条技术线,对当前目标帮助不大。
- 大模型 RLHF 场景几乎用不到 Q-Learning 或 DQN,所以你可以把时间完全投入到 PPO → DPO 这条线上。
- 如果后续你想做通用强化学习(比如机器人、游戏AI),再回头补 Q-Learning 也完全来得及。
🚀 为实习准备的行动建议
- 跟着老师把 PPO 学透:重点关注如何用 PPO 处理语言模型的输出(比如 token 级别的策略优化)。
- 动手跑开源项目 :找一个用 PPO/DPO 做大模型对齐的开源仓库(如
trlx、axolotl),跑通一个小例子(比如用 DPO 微调 LLaMA-2)。 - 重点理解关键概念:偏好数据格式、奖励模型(RM)训练、优势估计(GAE)、DPO 的损失函数。
我可以帮你整理一份大模型RLHF核心算法速查表,把 PPO、DPO 的核心公式、适用场景和开源工具都列出来,让你学的时候能直接对照项目代码。需要吗?