1. 什么是可执行文件?
可执行文件是包含了CPU能够直接理解和执行的机器指令(二进制代码)的文件。
这就好比CPU的"母语"写成的菜谱,它拿到后不需要任何翻译就能立刻"照做",从而让程序运行起来。这区别于需要解释器(如Python脚本)或虚拟机(如Java字节码)间接执行的脚本或字节码文件。
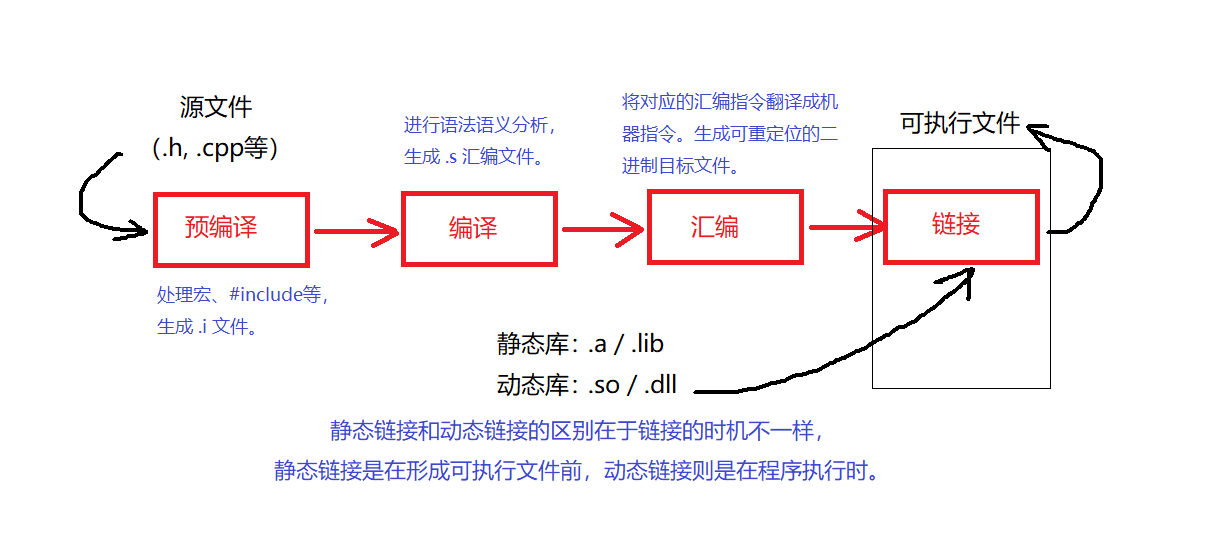
2.预处理、编译、汇编、链接
C/C++程序从源码到可执行文件的完整流程 :预处理 → 编译 → 汇编 → 链接;
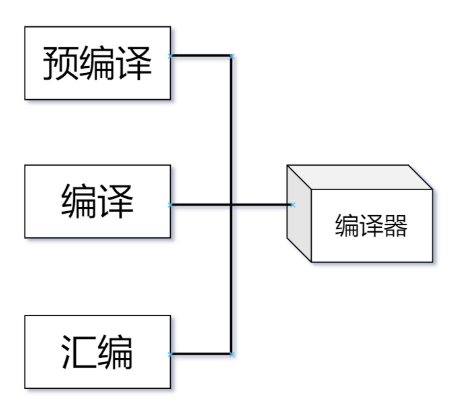
2.1 预处理(Preprocessing)
输入 :.c 源文件
输出 :.i 预处理后的纯C代码
工具 :预处理器(cpp 或 gcc -E)
作用: 预处理阶段针对源代码中"#"开头的预编译指令进行处理,主要包括如下:
(1)删除所有 #define 展开宏定义
(2)递归处理所有 #include 的文件 插入到源代码中
(3)对#if #elif #ifdef 等条件编译指令进行处理
(4)删除所有注释
使用如下命令 可以只对源代码进行预处理 生成对应的预处理文件(一般以.i为后缀)
如果想直接显示预处理后的代码形式,可以使用以下命令在Linux中
bash
gcc -E foo1.c -o foo1.i foo1.c 是源代码文件,foo1.i 是预处理后的源代码文件。
2.2编译(Compilation)
输入 :.i 预处理后的C代码
输出 :.s 汇编代码文件
工具 :编译器(gcc -S 或 cl.exe /S)
作用 : 编译是对预处理以后的文件进行 语法分析 词法分析 语义分析 源代码优化 目标代码生成和优化以后,生成汇编代码的过程。下面以如下赋值代码为例进行简单分析:
① 编译器像扫描仪一样逐个字符读入,识别出哪些字符组合在一起是一个"单词"。
例如:遇到 int position = initial + rate * 60;
它会识别出:int (关键字), position (标识符), = (赋值符), initial (标识符), + (加号), rate (标 识符), * (乘号), 60 (整数常量), ; (分号)。
丢弃空格、注释等无关字符。运用预定义的语法规则(类似自然语言的"主谓宾"结构), 检查记号序列是否能构成合法的句子。
② 例如:检查 position = initial + rate * 60 这个表达式。
它会根据 表达式 -> 标识符 = 表达式、表达式 -> 表达式 + 表达式、表达式 -> 表达式 * 表达式、表达式 -> 标识符/常量 等规则,构建一棵树。
如果写成 position = initial + + rate;,这里多了一个+,语法分析器就会发现它不符合任何一条语法规则,报告"语法错误"。
bash
gcc -S foo1.i -o foo1.sgcc通过以上命令生成对应的汇编文件(一般以.s为后缀)
2.3 汇编(Assembly)
输入 :.s 汇编代码文件
输出 :.o 或 .obj 目标文件(二进制机器码)
工具 :汇编器(as 或 gcc -c)
作用: 汇编阶段编译器会将汇编代码翻译为对应的机器代码,生成可重定位目标文件(一般.o后缀)。生成命令如下所示:
text
// 输入 test.s (人类可读的汇编) mov eax, 10 add eax, 5 // 输出 test.o (机器码,十六进制表示) B8 0A 00 00 00 # mov eax, 10 的机器码 83 C0 05 # add eax, 5 的机器码
bash
gcc -c test.s -o test.o # 只汇编,生成目标文件2.4 链接(Linking)
输入 :多个 .o/.obj 文件 + 库文件
输出 :可执行文件(.exe 或无后缀)
工具 :链接器(ld 或 link.exe 或 gcc)
输入: main.o: 调用 printf, 调用 add add.o: 定义 add 函数 libc.a: 定义 printf 函数 输出: 完整可执行文件,所有函数调用地址都已确定
核心任务:
①合并段 :把所有 .o 文件的 .text 段合并,.data 段合并...
②符号解析 :把 main.o 中的 call (调用add)绑定到 add.o 中的实际地址
③重定位:修正所有跨文件的跳转地址
④添加启动代码 :_start 入口点,初始化环境
bash
gcc main.o add.o -o program # 链接多个目标文件2.5各阶段文件对比
| 阶段 | 文件扩展名 | 文件格式 | 是否可读 | 是否可执行 |
|---|---|---|---|---|
| 源码 | .c/.cpp |
文本 | 是 | 否 |
| 预处理后 | .i |
文本 | 是 | 否 |
| 编译后 | .s |
文本(汇编) | 是(懂汇编) | 否 |
| 汇编后 | .o/.obj |
二进制(目标文件) | 否(需反汇编) | 否 |
| 链接后 | 无/.exe |
二进制(可执行文件) | 否 | 是 |
2.6 为什么分四步而不是一步?
①模块化 :每个.c文件独立编译,只重编译修改的文件
②调试:可以在不同阶段检查错误
a.预处理错误:宏定义问题
b.编译错误:语法错误
c.链接错误:未定义函数
③跨平台
**a.**预处理和编译与平台无关
b.汇编和链接与平台相关
④ 优化
**a.**在不同阶段应用不同优化策略
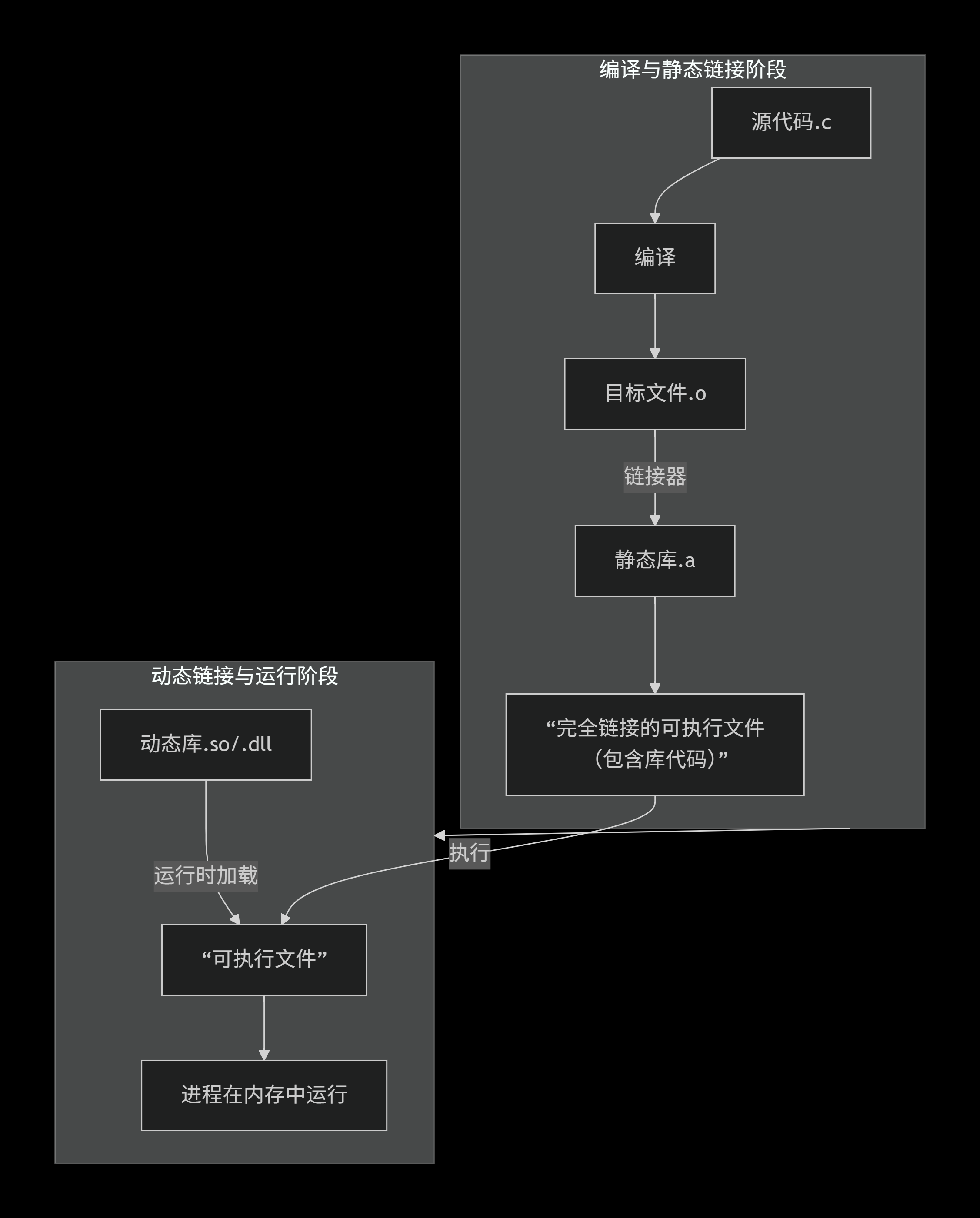
3.什么是库(Library)?
库是预先编写好的、可复用的代码集合,它封装了特定功能,供程序员在开发时直接调用,而无需重新"造轮子"。
这是一个非常好的问题,它触及了编译链接过程的核心。库的使用主要发生在链接阶段,但不同类型的库,其"使用"的时机和方式有细微差别。
简单来说:静态库在编译时(链接阶段)被合并,动态库在运行时才被加载。
4.符号表
符号表存在的根本原因 :因为C/C++支持分离编译,每个源文件独立编译时,编译器不知道其他文件有什么,所以需要符号表来:
①记录自己定义了哪些符号
②记录自己需要哪些外部符号
③让链接器在链接时进行匹配和解析
没有符号表会怎样:链接器不知道哪个文件提供什么函数,无法将多个目标文件正确连接起来,所有多文件项目都无法编译。
5.什么是静态库
静态库是预编译的代码集合文件,在程序编译链接阶段直接被整体嵌入到最终的可执行文件中。它以.a(Linux/Unix)或.lib(Windows)为扩展名,包含一系列已编译的目标文件(.o文件),通过静态链接器与用户代码结合。静态库的优点是生成的可执行文件独立性强,无需依赖外部库文件即可运行,且执行效率较高。缺点是会导致最终文件体积较大,且库内容更新时需要重新编译整个程序。常用于对程序独立性要求高或需避免运行时环境依赖的场景。
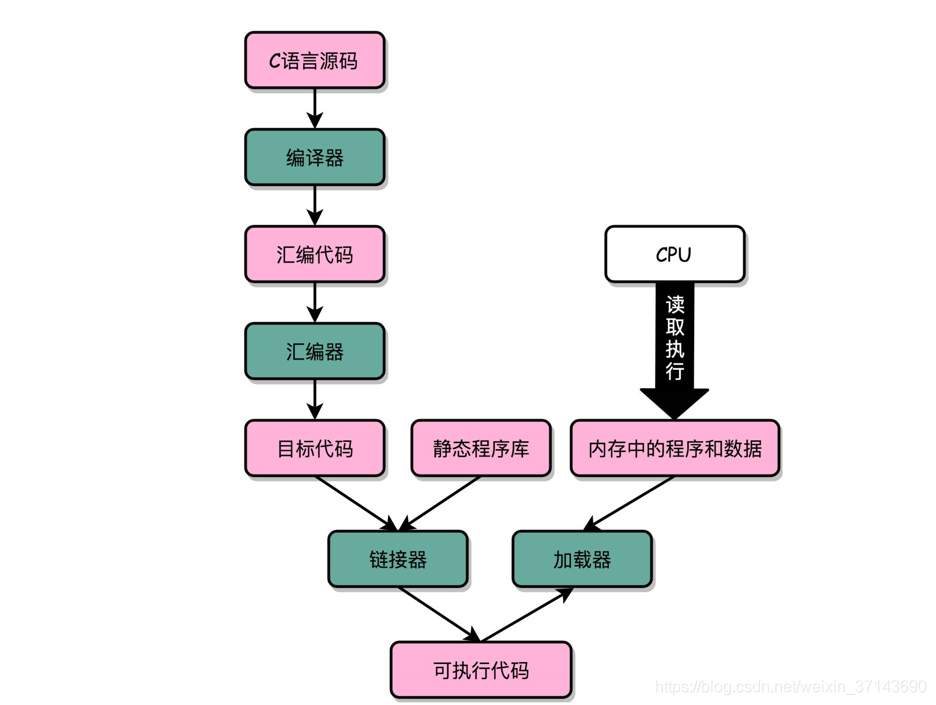
6.什么是动态库
动态库(也称为共享库)是一种在程序运行时才被加载和链接的代码库。与静态库将代码直接嵌入可执行文件不同,动态库以独立的文件(在Windows上为.dll,在Linux/Unix上为.so,在macOS上为.dylib)存在。
它的核心工作原理和特点如下:
运行时链接:程序启动时或运行到需要某个函数时,由操作系统的动态链接器在内存中查找并 加载所需的动态库。
代码共享:多个正在运行的程序可以共享同一个动态库在内存中的同一份副本,极大地节省了 系统内存和磁盘空间。
独立更新:更新库的功能或修复漏洞时,只需替换新的动态库文件,所有依赖它的程序在下一 次运行时即可自动使用新版本,无需重新编译程序本身。这使得软件维护和升级非常方便。
依赖管理:程序的可执行文件体积小巧,因为它不包含库的代码。但程序发布时必须确保目标 系统上存在正确版本的动态库,否则程序将无法启动(即产生"依赖地狱"问题)。
7.1 ldd命令的作用
ldd命令用于列出指定程序或共享库文件运行时所需的全部动态链接库及其完整路径,是排查依赖缺失、版本冲突以及部署环境问题的核心工具。

7.2 file命令的作用
file 是 Linux/Unix 下的核心文件类型检测工具,它通过分析文件的二进制签名和头部信息,精确识别文本、可执行文件、库、压缩包等几乎所有格式,并常显示其架构、链接方式等关键元数据。 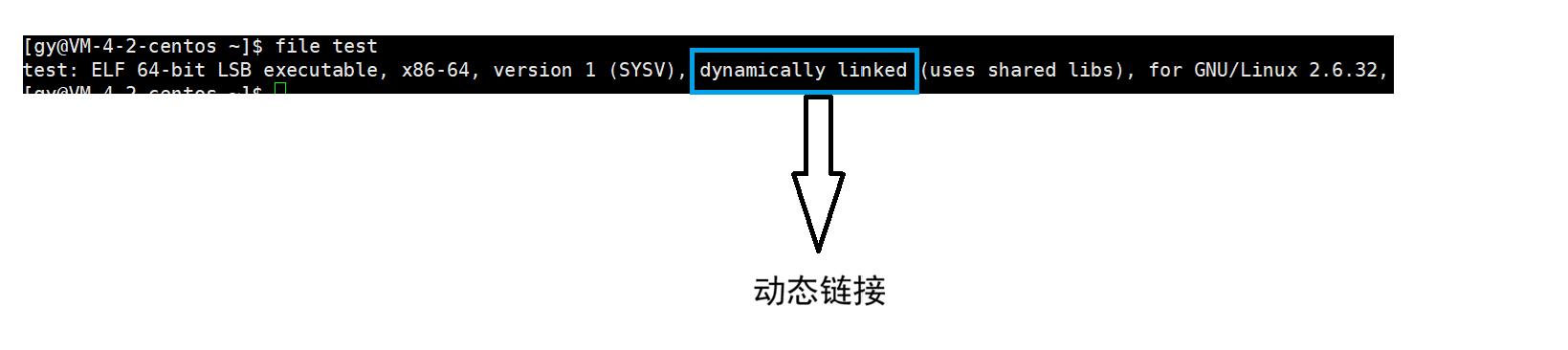
7.3 ls -usr include 命令的作用
查看标准头文件:/usr/include 是系统级的 C/C++ 标准头文件 和核心开发库头文件的默认存放目录。执行此命令可以看到如 stdio.h、stdlib.h、string.h 等所有可用的头文件列表。

7.动静库的就区别
| 对比维度 | 静态库 | 动态库 |
|---|---|---|
| 文件扩展名 | .a (Linux/Unix), .lib (Windows) |
.so (Linux), .dylib (macOS), .dll (Windows) |
| 链接时机与方式 | 编译时 静态链接。库代码被完整地复制到最终的可执行文件中。 | 运行时 动态链接。库代码不进入可执行文件,仅在运行时由系统加载到内存。 |
| 可执行文件 | 体积大。包含了所有需要的库代码,独立完整。 | 体积小。只包含调用引用,不包含库代码本身。 |
| 运行时依赖性 | 无依赖。可单独运行,不担心库文件丢失或版本问题。 | 有依赖。必须确保目标系统上有正确版本的动态库文件,否则程序无法启动。 |
| 内存使用 | 内存占用高。每个程序都有一份库代码的独立副本在内存中。 | 内存占用低。多个程序可以共享内存中同一份库代码的副本。 |
| 部署与更新 | 部署简单,更新麻烦 。库更新后,所有依赖程序必须重新编译链接才能使用新版本。 | 部署稍复杂,更新方便 。库更新后,通常只需替换库文件,所有依赖程序自动使用新版本(需注意接口兼容性)。 |
| 性能考量 | 加载运行快。启动时无链接开销,但现代操作系统优化使差距很小。 | 略有加载开销。首次加载有链接成本,但代码共享节省总体内存。 |
| 适用场景 | 1. 对程序独立性、可移植性要求极高。 2. 程序尺寸不重要。 3. 避免库版本冲突。 | 1. 大型系统,强调代码共享和节省资源。 2. 需要模块化热更新(如插件系统)。 3. 系统级库(如 glibc, Windows API)。 |
8.动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在⼀个源⽂件中,所以会出现多个源⽂件,⽽且多个源文件之间不是独立的,而会存在多种依赖关系,如⼀个源文件可能要调用另⼀个源⽂件中定义的函数, 但是每个源⽂件都是独⽴编译的,即每个*.c⽂件会形成⼀个*.o⽂件,为了满⾜前⾯说的依赖关系,则 需要将这些源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序。这个链接的过程就是静 态链接。静态链接的缺点很明显:
• 浪费空间:因为每个可执⾏程序中对所有需要的⽬标⽂件都要有⼀份副本,所以如果多个程序对
同⼀个⽬标⽂件都有依赖,如多个程序中都调⽤了printf()函数,则这多个程序中都含有
printf.o,所以同⼀个⽬标⽂件都在内存存在多个副本;
• 更新比较困难:因为每当库函数的代码修改了,这个时候就需要重新进⾏编译链接形成可执⾏程
序。但是静态链接的优点就是,在可执⾏程序中已经具备了所有执⾏程序所需要的任何东西,在
执⾏的时候运⾏速度快。
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对 独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,⽽不是像静态链接⼀样把所有程序模块都链接成⼀个单独的可执⾏⽂件。 动态链接其实远⽐静态链接要常⽤得多。
9.动态链接和静态链接的对比
| 特性 | 静态链接 | 动态链接 |
|---|---|---|
| 链接时机 | 编译/链接时完成 | 运行时完成 |
| 库代码处理 | 库代码直接拷贝到可执行文件中 | 库代码不拷贝,只记录引用信息 |
| 生成文件 | 单个独立可执行文件,体积大 | 可执行文件体积小,但附带依赖的库文件 |
| 运行时依赖 | 无,可独立运行 | 必须有相应的动态库文件 |
| 内存使用 | 多个程序运行相同库时,内存冗余 | 多个程序共享 内存中的同一份库代码,省内存 |
| 库更新 | 必须重新编译链接整个程序 | 直接替换库文件即可(需接口兼容) |
| 加载速度 | 程序启动快(无需加载库) | 程序启动稍慢(需查找并加载库) |
| 兼容性问题 | 无库版本冲突问题 | 可能存在"DLL Hell"版本冲突 |
| 常用扩展名 | .a (Linux), .lib (Windows) |
.so (Linux), .dll (Windows), .dylib (macOS) |
| 编译命令示例 | gcc -o code_static code.c -static | gcc -o code_d code.c |

一般我们输入这个命令会报错,这是因为云服务器默认没有安装C/C++的标准静态库
所以我们需要以下命令安装
bash
sudo yum install -y glibc-static