PyTorch实战(24)------深度强化学习
0. 前言
机器学习通常可分为不同范式,例如监督学习、无监督学习、半监督学习、自监督学习以及强化学习。监督学习需要标注数据,是当前应用最广泛的机器学习范式。然而基于无监督和半监督学习的应用(仅需少量或无需标注)正持续增长,尤其是生成模型领域。更值得注意的是,大语言模型的崛起表明自监督学习(标签隐含在数据中)是一种更具前景的机器学习范式。
强化学习 (Reinforcement Learning, RL) 是机器学习的另一分支,被认为是最接近人类学习方式的范式。谷歌 DeepMind 开发的 AlphaGo 模型是一个典型的强化学习模型,它曾击败世界顶级围棋选手。
在监督学习中,我们通常为模型提供原子化的输入-输出数据对,期望模型学会从输入到输出的函数映射。而强化学习关注的并非这种一对一的函数关系,其核心在于学习一种策略 (policy),使我们能够从初始状态出发,通过一系列步骤(动作)最终达成目标或获得预期结果。例如:判断照片中是猫还是狗属于原子化的输入-输出任务,可通过监督学习解决;但观察棋盘局势并决策下一步棋以赢得比赛,则需要策略性思考,这类任务必须依赖强化学习。
我们已经学习了监督学习(如基于 MNIST 数据集构建手写数字分类器)和无监督学习(使用未标注文本语料构建文本生成模型)。在本节中,将重点解析强化学习与深度强化学习 (Deep Reinforcement Learning, DRL) 的基础概念,并聚焦于经典 DRL 模型------深度Q学习网络 (Deep Q-learning Network, DQN)。通过本节学习,将掌握使用 PyTorch 开展 DRL 项目所需的完整知识体系,并获得解决实际问题的 DQN 模型开发经验。
1. 强化学习概念
从某种意义上说,强化学习 (Reinforcement Learning, RL) 可以定义为基于奖励的学习。与监督学习中对每个数据实例都获得反馈不同,强化学习可能是在完成一系列动作后才获得反馈,下图展示了强化学习示意图:
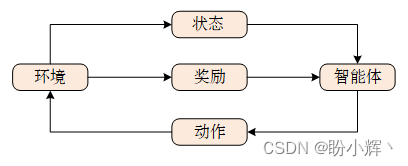
在强化学习框架中,通常存在一个进行学习的主体------智能体 (agent)。该智能体通过学习来制定决策并执行相应动作。其活动范围被限定在特定的环境 (environment) 中,这个环境可视为智能体生存、行动并从行动中学习的封闭世界。所谓动作 (action),本质上就是智能体基于所学知识对决策的具体实施。
与监督学习不同,强化学习并非每个输入都对应明确输出------即智能体并非每个动作都能获得显式反馈。智能体以状态 (state) 为单位开展工作,最佳情况下仅记录从初始状态到最终目标(奖励)之间经历的状态数量。假设智能体从初始状态 S 0 S_0 S0 出发,执行动作 a 0 a_0 a0 后状态转移至 S 1 S_1 S1,继而执行新动作 a 1 a_1 a1,如此循环往复(如下图所示)。这种状态-动作的连续演进过程构成了强化学习的核心机制。
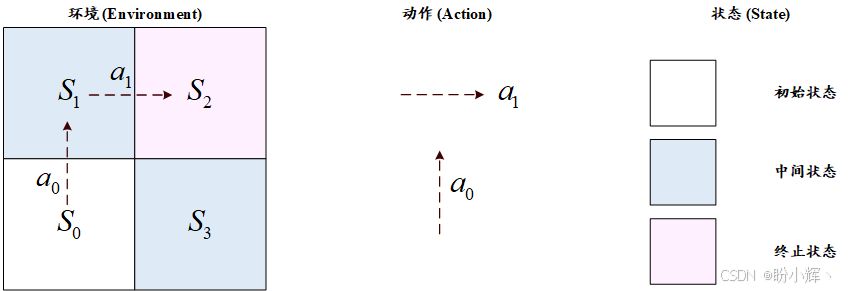
在强化学习过程中,智能体会根据其所处的状态周期性地获得奖励。智能体经历的状态与动作序列被称为轨迹 (trajectory)。假设智能体在状态 S 5 S_5 S5 获得了奖励,那么产生该奖励的完整轨迹可表示为: S 0 → a 0 → S 1 → a 1 → . . . → S 5 S_0→a_0→S_1→a_1→...→S_5 S0→a0→S1→a1→...→S5。需要注意的是,奖励可以是正数也可以是负数。
智能体会根据获得的奖励不断调整自身行为,其目标是通过特定的动作策略实现长期奖励的最大化------这正是强化学习的核心要义。在给定环境状态和奖励机制的条件下,智能体通过学习最终掌握最优行动策略(即实现奖励最大化)。
电子游戏是诠释强化学习的绝佳范例。以乒乓球模拟游戏《Pong》为例,其游戏画面截图如下:
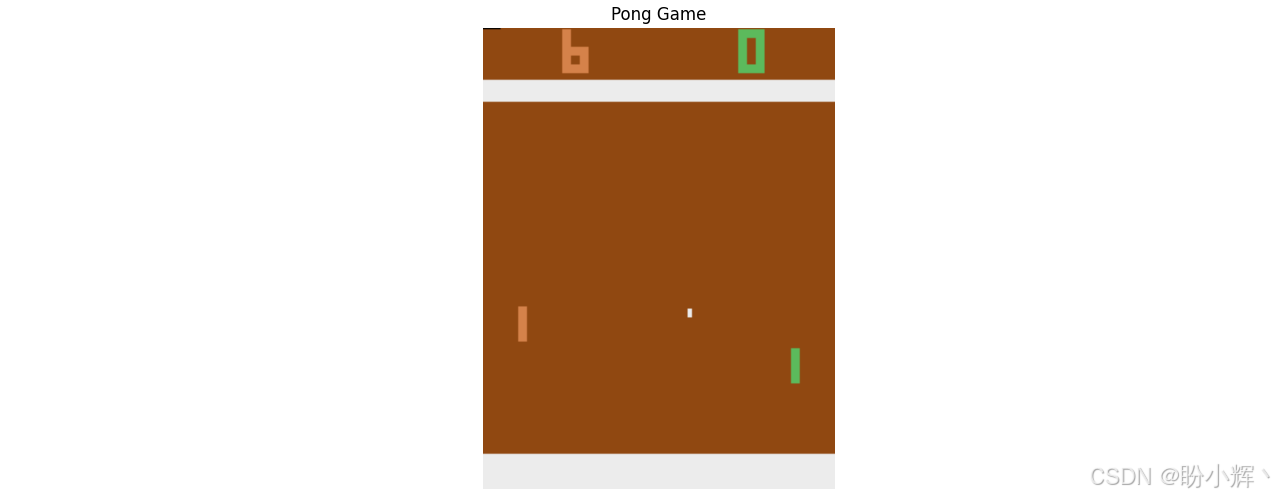
假设右侧玩家代表智能体(即短竖线)。可以看到,这里存在一个明确定义的环境:这个环境包含由棕色像素构成的游戏区域、由白色像素表示的球体、作为边界的灰色条纹(球体碰撞时会反弹的场边),以及位于左侧、与智能体隔网相对的外形相似的对手。
在强化学习设定中,智能体在特定状态下通常拥有有限的动作选择,称为离散动作空间(与连续动作空间相对)。本节中,智能体在绝大多数状态下只有两个可选动作------上移或下移,但存在两个例外:当处于最高位置(状态)时只能下移,处于最低位置(状态)时只能上移。
此处的奖励机制可直接类比真实乒乓球比赛:若未能接球,对手得分。先获得 21 分者赢得比赛并获正奖励,败者获负奖励。得分或失分则分别对应较小的正/负即时奖励。从 0-0 开始直至任一方获得 21 分的完整对局称为一个回合 (episode)。
通过强化学习训练智能体进行《Pong》游戏,本质上等同于从零开始培养乒乓球选手。训练最终会产生一套游戏策略------在任何给定情境下(包括球的位置、对手位置、比分板及前期奖励),成功训练的智能体会通过上下移动来最大化获胜概率。此时,策略已内化为智能体的条件反射:当球以特定角度飞来时,它会不假思索地移动到最佳接球位置。
我们已经通过举例介绍了 RL 基本概念。在此过程中,我们介绍了策略 (policy) 和学习等概念。智能体通过 RL 模型学习策略,模型基于预定义的算法。接下来,我们将探讨不同类型的 RL 算法。
2. 强化学习算法分类
总体而言,强化学习算法可分为以下两大类:
- 基于模型 (
Model-based) - 无模型 (
Model-free)
2.1 基于模型 (Model-based) 的强化学习算法
顾名思义,基于模型 (Model-based) 的强化学习算法中智能体知晓环境模型。此处的"模型"指代能够预估奖励及状态转移规律的数学函数。由于智能体对环境存在先验认知,可有效缩减动作选择的采样空间,从而提升学习效率。
但现实中,预建环境模型通常难以直接获取。若坚持采用基于模型的方法,需让智能体通过自身经验学习环境模型------这极易导致模型表征出现偏差,使其在真实环境中表现欠佳。正因如此,基于模型的方法在强化学习系统中应用较少,常见无模型算法包括:
- 结合无模型微调的基于模型深度强化学习 (
Model-Based DRL with Model-Free Fine-Tuning,MBMF) - 面向高效无模型学习的基于模型价值估计 (
Model-Based Value Estimation,MBVE) - 采用想象增强机制的深度强化学习智能体 (
Imagination-Augmented Agent,I2A) - 击败国际象棋与围棋冠军的著名
AI------AlphaZero
2.2 无模型 (Model-Free) 强化学习算法
无模型方法不依赖于环境的模型,当前已成为强化学习研发的主流范式。在无模型强化学习中,智能体训练主要存在两种路径:
- 策略优化 (
Policy optimization) - Q学习 (
Q-learning)
2.2.1 策略优化 (Policy Optimization)
策略优化 (Policy Optimization) 方法将策略表述为当前状态下动作的函数,其数学表达如下:
P o l i c y = F β ( a ∣ S ) Policy = F_{\beta} (a|S) Policy=Fβ(a∣S)
其中, β \beta β 表示该函数的内部参数,通过梯度上升法更新以优化策略函数。目标函数由策略函数和奖励共同定义,在某些情况下也可使用目标函数的近似值进行优化。此外,优化过程中有时会采用策略函数的近似替代实际策略函数。
这类方法通常采用同策略 (on-policy) 优化,即参数更新基于最新策略版本所收集的数据。常见的基于策略优化的强化学习算法包括:
- 策略梯度 (
Policy gradient):最基础的策略优化方法,直接使用梯度上升法优化策略函数。该策略函数在每个时间步输出下一步采取不同动作的概率分布 - 演员-评论家 (
Actor-Critic):由于策略梯度算法的优化是基于当前策略的,因此每次迭代都需要更新策略,这会耗费大量时间。演员-评论家方法同时引入价值函数和策略函数------演员建模策略函数,评论家建模价值函数。借助评论家,策略更新过程得以加速 - 信任域策略优化 (
Trust Region Policy Optimization,TRPO):与策略梯度方法类似,TRPO采用在同策略优化方法。在策略梯度中,我们通过梯度更新策略函数参数 β \beta β。由于梯度是一阶导数,对于函数曲率突变区域可能产生噪声,导致策略更新幅度过大,进而破坏智能体的学习轨迹稳定性。为解决此问题,TRPO引入了信任域机制------设定策略单次更新幅度的上限,从而确保优化过程的稳定性 - 近端策略优化 (
Proximal Policy Optimization,PPO):与TRPO类似,PPO旨在稳定优化过程。策略梯度法对每个数据样本单独执行梯度上升更新,而PPO采用替代目标函数,支持批量样本的联合更新。这种机制能更保守地估计梯度,有效提升梯度上升算法的收敛概率
策略优化方法直接作用于策略改进,具有极强的直观性。但由于这类算法多属同策略性质,每次策略更新后都需重新采样数据,这成为解决强化学习问题的制约因素。接下来我们将讨论另一种样本效率更高的无模型算法------Q学习。
2.2.2 Q学习 (Q-learning)
与策略优化算法不同,Q学习的核心在于价值函数而非策略函数。接下来,将详细探讨Q学习的基本原理。
3. Q学习
策略优化与Q学习之间的主要区别在于,Q学习并不是直接优化策略,而是优化一个价值函数。是指以智能体当前所处状态为输入,输出该状态到当前回合结束时期望获得累计奖励的函数------这正是强化学习"智能体在状态-动作轨迹中追求最大总奖励"核心理念的数学体现。
Q学习优化的是一种特殊价值函数:动作价值函数 (action-value function)。该函数同时依赖于当前状态和采取的动作,记为 Q ( S , a ) Q(S,a) Q(S,a),故亦称Q函数。其物理意义是:在给定状态 S S S 下,智能体采取动作 a a a 后直至回合结束所能获得的长期奖励(即Q值)。
所有(状态,动作)组合对应的Q值可以存储在一个二维表格中,其中两个维度分别是状态和动作。例如,若存在四个可能状态 S 1 S_1 S1、 S 2 S_2 S2、 S 3 S_3 S3、 S 4 S_4 S4 和两个可能动作 a 1 a_1 a1、 a 2 a_2 a2,那么八个Q值将存储在一个 4 x 2 的表格中。因此,Q学习的目标就是构建这个Q值表格。
一旦获得该表格,智能体就能查询给定状态下所有可能动作的Q值,并选择具有最大Q值的动作。Q值的计算可以根据贝尔曼方程,贝尔曼方程数学表达式如下所示:
Q ( S t , a t ) = R + γ ∗ Q ( S t + 1 , a t + 1 ) Q(S_t, a_t)=R+ \gamma * Q (S_{t+1}, a_{t+1}) Q(St,at)=R+γ∗Q(St+1,at+1)
贝尔曼方程是一种递归计算Q值的方法。在这个方程中, R R R 表示在状态 S t S_t St 采取动作 a t a_t at 所获得的即时奖励;而 γ γ γ (gamma)是折扣因子,它是一个介于 0 和 1 之间的标量值。该方程的核心含义是:当前状态 S t S_t St 和动作 a t a_t at 对应的Q值,等于立即获得的奖励 R R R,加上下一状态 S t + 1 S_{t+1} St+1 最优动作 a t + 1 a_{t+1} at+1 对应Q值的折现值(乘以折扣因子)。折扣因子 γ γ γ 决定了即时奖励与长期未来奖励的权衡比重------ γ γ γ 越接近 1 表示越重视长期奖励,越接近 0 则越关注即时奖励。
在理解Q学习的基础概念后,我们通过一个具体示例来演示其运作机制。下图展示了一个包含五个可能状态的环境:

在该环境中存在两种可选动作------右移 ( a 1 a_1 a1) 或左移 ( a 2 a_2 a2)。各状态对应的奖励值从 S 4 S_4 S4 的 +2 到 S 0 S_0 S0 的 -1 不等。每个训练回合都从初始状态 S 2 S_2 S2 开始,最终在 S 0 S_0 S0 或 S 4 S_4 S4 终止。由于存在 5 个状态和 2 个动作, Q Q Q 值可以用 5 x 2 的矩阵存储。在 Python 中表示奖励和Q值:
python
rwrds = [-1, 0, 0, 0, 2]
Qvals = [[0.0, 0.0],
[0.0, 0.0],
[0.0, 0.0],
[0.0, 0.0],
[0.0, 0.0],]我们将所有Q值初始化为 0。此外,由于存在两个特定的终止状态,需要用列表形式进行指定:
python
end_states = [1, 0, 0, 0, 1]这表示状态 S 0 S_0 S0 和 S 4 S_4 S4 是终止状态。在运行完整Q学习循环前,还需要了解最后一个关键点。在Q学习的每个步骤中,智能体对下一步动作有两种选择:
- 选择具有最高Q值的动作
- 随机选择下一步的动作
如果智能体始终根据Q值选择动作,可能会陷入反复选择短期即时高回报动作的困境。因此,偶尔采取随机动作能帮助智能体摆脱这种次优状态。
我们已经明确智能体在每个步骤中有两种可能的动作选择方式,现在需要决定采用哪种方式。这时就需要引入ε-贪婪动作 (epsilon-greedy-action) 机制,其工作原理如下图所示:
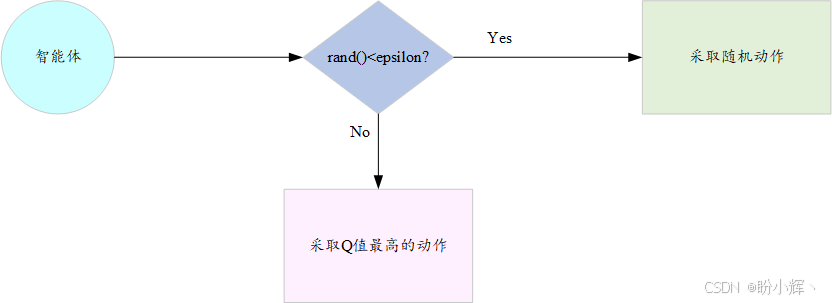
在该机制下,每个训练回合开始前会预设一个介于 0 到 1 之间的 ε ε ε 值。在具体回合中,智能体每次选择动作时都会生成一个 0 到 1 之间的随机数。若该随机数小于预设的 ε ε ε 值,智能体会从可选动作中随机选取;反之,则从Q值表中检索所有可能动作对应的Q值,并选择Q值最高的动作:
python
def eps_greedy_action_mechanism(eps, S):
rnd = np.random.uniform()
if rnd < eps:
return np.random.randint(0, 2)
else:
return np.argmax(Qvals[S])通常,我们会在第一个训练回合将 ε ε ε 初始值设为 1,随后随着回合推进线性递减。这样设计的核心理念是:初期我们希望智能体充分探索各种可能性,但随着学习进程深入,智能体逐渐减少陷入短期奖励陷阱的概率,从而能更有效地利用Q值表进行决策。
编写Q学习主循环:
python
n_epsds = 100
eps = 1
gamma = 0.9
for e in range(n_epsds):
S_initial = 2
S = S_initial
while not end_states[S]:
a = eps_greedy_action_mechanism(eps, S)
R, S_next = take_action(S, a)
if end_states[S_next]:
Qvals[S][a] = R
else:
Qvals[S][a] = R + gamma * max(Qvals[S_next][a])
S = S_next
eps = eps - 1/n_epsds首先设定智能体将进行 100 个回合的训练。初始 ε ε ε 值设为 1,折扣因子 γ γ γ 设为 0.9。接着运行Q学习循环,该循环会遍历所有训练回合。每个回合迭代中,智能体会完整执行一个训练回合:回合开始时,首先将智能体状态初始化为 S 2 S_2 S2。接着运行另一个内部循环,该循环仅在智能体到达终止状态时才会跳出。在此内部循环中,我们通过ε-贪婪动作机制决定智能体的下一步动作。智能体执行该动作后,将转移到新状态并可能获得奖励:
python
def take_action(S, a):
if a == 0:
S_next = S - 1
else:
S_next = S + 1
return rwrds[S_next], S_next当获取奖励和新状态后,更新当前状态-动作对的Q值。此时新状态成为当前状态,循环重复进行。每个训练回合结束时, ε ε ε 值会线性递减。当整个Q学习循环完成后,我们将得到一个Q值表。这张表本质上就是智能体在该环境中运作以获得最大长期回报所需的全部依据。
以本例而言,训练完善的智能体应当始终选择向下移动以获取 S 4 S_4 S4 位置的 +2 最大奖励,同时会避开含 -1 负奖励的 S 1 S_1 S1 位置。
本小节中,介绍了Q学习的原理,以上代码应该能在提供的简单环境中开始使用Q学习。对于更复杂和现实的环境,比如视频游戏,这种方法将无法奏效。
Q学习的核心在于构建Q值表。在本节示例中,仅有 5 种状态和 2 个动作,因此Q值表仅需 10 个存储单元,完全在可控范围内。但在类似《Pong》这类视频游戏中,可能存在的状态数量呈指数级增长。这将导致Q值表规模爆炸性扩张,使得传统Q学习算法需要消耗极高的内存资源,从而不具备实际可行性。
但我们依然可以运用Q学习的核心理念,同时避免内存耗尽的问题------解决方案就是将Q学习与深度神经网络相结合,由此诞生了深度Q网络 (Deep Q-Network, DQN) 算法。在下一节中,我们将探讨 DQN 的基础原理及其创新特性。
4. 深度Q学习
深度Q网络 (Deep Q-Network, DQN) 通过深度神经网络 (Deep Neural Network, DNN) 直接输出给定状态-动作对的Q值,从而取代了传统的Q值表构建方式。这种方法特别适用于视频游戏等复杂环境,这类场景中状态数量十分庞大,无法用Q值表进行有效管理。视频游戏的当前图像帧用来表示当前状态,并与当前动作一起输入到底层的 DNN 模型中,该 DNN 会为每个输入输出对应的Q值。实际应用中,DQN 并不是只传递当前的图像帧,而是会将某一时间窗口内的 N 个相邻图像帧作为输入传递给模型。
当使用 DNN 解决强化学习问题时,存在一个本质性矛盾:传统 DNN 训练要求独立同分布 (independent and identically distributed, iid) 的数据样本,而强化学习中每个当前输出都会影响后续输入。以Q学习为例,贝尔曼方程本身就表明当前状态-动作对的Q值取决于下一状态-动作对的Q值。
这意味着我们面对的是一个持续变动的目标,且目标与输入之间存在高度相关性。DQN 通过两个创新设计来解决这些问题:
- 使用两个独立的
DNN - 经验回放缓冲区 (
Experience Replay Buffer)
4.1 双网络架构设计
重写 DQN 的贝尔曼方程:
Q ( S t , a t , θ ) = R + γ ∗ Q ( S t + 1 , a t + 1 , θ ) Q (S_t, a_t, \theta) =R+ \gamma*Q (S_{t+1},a_{t+1},\theta) Q(St,at,θ)=R+γ∗Q(St+1,at+1,θ)
该方程与Q学习基本一致,但引入了一个新参数 θ θ θ。 θ θ θ 代表 DQN 模型用于计算Q值的神经网络权重。
观察以上方程,可以看到 𝜃 𝜃 𝜃 同时出现在方程左右两侧。这意味着每一步迭代中,我们使用同一个神经网络同时计算当前状态-动作对和下一状态-动作对的Q值。这导致我们实际上在追逐一个不断移动的目标------因为每次 θ θ θ 更新时,方程两侧会同时发生变化,从而造成学习过程的不稳定性。
通过查看损失函数,我们可以更清晰地理解这个问题( DNN 将通过梯度下降最小化该损失函数):
L = E ( R + γ ∗ Q ( S t + 1 , a t + 1 , θ ) − Q ( S t , a t , θ ) ) 2 \mathcal L=E(R+ \\gamma\*Q (S_{t+1},a_{t+1},\\theta)-Q (S_t, a_t, \\theta))\^2 L=E(R+γ∗Q(St+1,at+1,θ)−Q(St,at,θ))2
这个损失称为时序差分损失 (Temporal Difference Loss),是 DQN 的核心基础概念之一。如果暂时忽略奖励 ( R R R),若使用完全相同的网络同时计算当前和下一状态-动作对的Q值,将导致损失函数剧烈波动------因为两项参数会持续同步变化。为解决这个问题,DQN 创新性地采用双网络架构:一个主 DNN 和一个目标 DNN,两个 DNN 的架构完全相同。
主 DNN 用于计算当前状态-动作对的Q值,而目标 DNN 用于计算下一个状态-动作对的Q值。虽然两个网络结构完全相同,但主网络权重在每个训练步骤都会更新,而目标网络权重保持冻结状态,每经过 K 次梯度下降迭代后,将主网络权重同步至目标网络。这一机制使得训练过程相对稳定,目标网络提供相对稳定的Q值预测基准,阶段性权重同步避免预测偏差累积,同时能够有效阻断误差信号的循环依赖。
4.2 经验回放缓冲区
由于深度神经网络 (Deep Neural Network, DNN) 需要独立同分布 (independent and identically distributed, iid) 的数据输入,我们采用以下缓存机制:将最近 X 步的游戏画面帧存入缓冲存储器,然后从中随机抽取批量数据。这些随机采样的数据批次能模拟 iid 数据的分布特性,从而有效稳定 DNN 的训练过程。
若不采用这种缓冲技术,DNN 接收到的将是高度关联的数据,这将导致优化效果显著下降。
实践证明,上述两项关键技术(双网络架构和经验回放缓冲)对 DQN 的成功至关重要。
小结
强化学习 (Reinforcement Learning, RL) 是机器学习的一个基本分支,是当前最热门的研究与发展领域之一。本节系统介绍了强化学习与深度强化学习 (Deep Reinforcement Learning, DRL) 的核心概念,并介绍了基于模型和无模型的两类主流算法,其中无模型的Q学习通过价值函数间接优化策略,而深度Q网络通过神经网络近似Q函数,结合双网络架构和经验回放缓冲区解决了高维状态空间的挑战。强化学习在游戏AI、机器人控制等领域展现出强大潜力,是实现通用人工智能的重要路径之一。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐