目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于图像处理与深度学习的油橄榄品种和成熟度检测算法研究
选题背景意义
油橄榄作为一种重要的经济作物,其品种和成熟度直接影响着橄榄油的品质和产量。传统的油橄榄品种和成熟度检测主要依靠人工观察和经验判断,这种方法不仅效率低下,而且容易受到人为因素的影响,导致检测结果不准确。随着计算机视觉和深度学习技术的快速发展,利用人工智能技术实现油橄榄品种和成熟度的自动检测成为可能深度学习技术在目标检测领域取得了显著的进展,特别是YOLO系列算法的出现,为实时目标检测提供了高效的解决方案。YOLOv8作为YOLO系列的最新版本,具有更高的检测精度和更快的检测速度,适合应用于农业领域的目标检测任务。同时,MobileNetV3等轻量化模型的发展,使得深度学习模型能够在资源受限的设备上高效运行,为油橄榄品种和成熟度检测系统的实际应用提供了技术支持本项目计划构建一个基于深度学习的油橄榄品种和成熟度检测系统,主要包括数据集构建、模型设计与训练、系统实现等环节。首先,收集油橄榄的图像数据,进行数据标注和预处理,构建油橄榄品种和成熟度检测数据集。然后,基于YOLOv8s算法设计检测模型,并结合MobileNetV3进行轻量化处理,提高模型的运行效率。最后,实现油橄榄品种和成熟度检测系统,验证模型的检测性能。该项目的研究对于提高油橄榄产业的自动化水平,促进油橄榄产业的发展具有重要意义。
数据集构建
数据获取
油橄榄品种和成熟度检测数据集的构建是项目的基础工作。数据获取主要包括图像采集和数据收集两个方面。图像采集可以通过数码相机、手机等设备在油橄榄种植基地进行拍摄,确保采集的图像具有不同的光照条件、角度和背景,以提高模型的鲁棒性。同时,也可以从公开的图像数据库中收集相关的油橄榄图像数据,丰富数据集的多样性在图像采集过程中,需要注意以下几点:一是确保采集的图像清晰,能够准确反映油橄榄的外观特征;二是采集不同成熟度的油橄榄图像,包括未成熟、半成熟和成熟等不同阶段;三是采集不同品种的油橄榄图像,确保数据集覆盖项目需要检测的所有品种;四是采集不同环境条件下的图像,包括不同的光照、背景和角度等,以提高模型的泛化能力。

油橄榄品种和成熟度检测数据集采用图像和标签文件的形式存储。图像文件为JPEG或PNG格式,标签文件为TXT格式。标签文件中包含油橄榄的类别信息和边界框坐标,每个标签文件对应一张图像数据集分为两个部分:品种检测数据集和成熟度检测数据集。品种检测数据集包含6个品种的油橄榄图像,分别为西蒙一号(Barnea)、克洛莱卡(Koroneiki)、济拉发(Giarffa)、拉维多科巴圆润(Leucoarpa Round)、皮瓜尔(Picual)和科比多(Codovil)。成熟度检测数据集包含3个成熟度等级的油橄榄图像,分别为未成熟、半成熟和成熟。
数据标注
数据标注是数据集构建的关键环节,直接影响模型的检测性能。数据标注主要包括油橄榄的边界框标注和类别标注。边界框标注需要标注出油橄榄在图像中的位置,通常采用矩形边界框,包含边界框的左上角和右下角坐标。类别标注需要标注出油橄榄的品种和成熟度数据标注可以使用专业的标注工具,如LabelImg、VGG Image Annotator等,提高标注效率和准确性。在标注过程中,需要注意以下几点:一是确保边界框准确包围油橄榄,不包含过多的背景信息;二是确保类别标注正确,避免误标;三是标注人员需要经过培训,熟悉油橄榄的品种和成熟度特征,提高标注的一致性。
数据处理
数据预处理是提高模型性能的重要步骤,主要包括图像增强、数据划分和数据格式转换等。图像增强可以通过旋转、缩放、翻转、亮度调整等方式增加数据集的多样性,提高模型的鲁棒性。数据划分将数据集分为训练集、验证集和测试集,通常采用8:1:1的比例划分,用于模型的训练、验证和测试。数据格式转换将数据集转换为模型训练所需的格式,如YOLO格式在数据预处理过程中,需要注意以下几点:一是图像增强的方式和程度要适当,避免过度增强导致图像失真;二是数据划分要随机,确保训练集、验证集和测试集的分布一致;三是数据格式转换要准确,确保模型能够正确读取和使用数据集。
功能模块介绍
图像采集模块
图像采集模块负责获取油橄榄的图像数据,为后续的检测和分析提供基础。该模块可以通过数码相机、手机等设备采集油橄榄的图像,也可以从公开的图像数据库中获取相关图像。图像采集模块需要确保采集的图像具有清晰的油橄榄特征,能够准确反映油橄榄的品种和成熟度信息图像采集模块的主要功能包括图像拍摄、图像传输和图像存储。图像拍摄功能可以通过控制相机参数,如焦距、曝光时间等,获取高质量的油橄榄图像。图像传输功能可以将采集的图像传输到计算机或服务器进行处理。图像存储功能可以将采集的图像存储在本地或云端,方便后续的访问和使用在实现图像采集模块时,需要考虑以下几个方面:一是选择合适的图像采集设备,确保设备的分辨率和性能能够满足需求;二是设计合理的图像传输方式,确保图像传输的稳定性和效率;三是建立安全可靠的图像存储系统,确保图像数据的安全性和完整性。
数据预处理模块
数据预处理模块负责对采集的图像数据进行处理,提高数据的质量和可用性。该模块的主要功能包括图像增强、数据标注、数据划分和数据格式转换等。图像增强可以通过旋转、缩放、翻转、亮度调整等方式增加数据集的多样性,提高模型的鲁棒性。数据标注可以使用专业的标注工具,标注出油橄榄的边界框和类别信息。数据划分将数据集分为训练集、验证集和测试集,用于模型的训练、验证和测试。数据格式转换将数据集转换为模型训练所需的格式数据预处理模块的设计需要考虑以下几个方面:一是选择合适的图像增强方法,确保增强后的图像能够准确反映油橄榄的特征;二是设计高效的数据标注流程,提高标注效率和准确性;三是合理划分数据集,确保训练集、验证集和测试集的分布一致;四是选择合适的数据格式转换方法,确保模型能够正确读取和使用数据集。
模型训练模块
模型训练模块负责训练油橄榄品种和成熟度检测模型。该模块基于YOLOv8s算法和MobileNetV3轻量化模型,设计检测模型,并使用构建的数据集进行训练。模型训练模块的主要功能包括模型配置、模型训练、模型评估和模型优化等在模型配置阶段,需要设置模型的参数,如学习率、批量大小、训练轮数等。在模型训练阶段,使用训练集对模型进行训练,通过反向传播算法更新模型的权重。在模型评估阶段,使用验证集对训练好的模型进行评估,计算模型的准确率、召回率、mAP等指标。在模型优化阶段,根据评估结果调整模型的参数和结构,提高模型的性能模型训练模块的设计需要考虑以下几个方面:一是选择合适的模型结构,确保模型具有良好的检测性能和运行效率;二是设置合理的训练参数,提高模型的训练效率和性能;三是设计有效的模型评估方法,准确评估模型的性能;四是采用合适的模型优化策略,提高模型的性能和泛化能力。
检测识别模块
检测识别模块负责对输入的油橄榄图像进行检测和识别,输出油橄榄的品种和成熟度信息。该模块使用训练好的模型,对输入的图像进行处理,检测出油橄榄的位置,并识别其品种和成熟度。检测识别模块的主要功能包括图像输入、模型推理、结果输出等在图像输入阶段,接收用户输入的油橄榄图像。在模型推理阶段,使用训练好的模型对图像进行推理,检测出油橄榄的边界框和类别信息。在结果输出阶段,将检测结果以可视化的方式展示给用户,包括油橄榄的位置、品种和成熟度等信息检测识别模块的设计需要考虑以下几个方面:一是设计友好的用户界面,方便用户输入图像和查看结果;二是优化模型推理速度,确保系统能够实时处理图像;三是提高检测结果的准确性和可靠性;四是设计合理的结果展示方式,方便用户理解和使用检测结果。
算法理论
YOLOv8s目标检测算法
YOLOv8是Ultralytics公司推出的YOLO系列最新版本,具有更高的检测精度和更快的检测速度。YOLOv8s是YOLOv8的中等尺度模型,在检测精度和运行速度之间取得了较好的平衡,适合应用于油橄榄品种和成熟度检测任务YOLOv8s采用了CSPDarknet作为主干网络,使用了特征金字塔网络(FPN)和路径聚合网络(PAN)进行特征融合,提高了模型对不同尺度目标的检测能力。同时,YOLOv8s采用了新的损失函数和优化策略,进一步提高了模型的检测精度在油橄榄品种和成熟度检测中,YOLOv8s可以同时检测图像中的多个油橄榄目标,并识别其品种和成熟度。通过调整模型的参数和结构,可以提高模型对油橄榄的检测精度和速度,满足实际应用的需求。
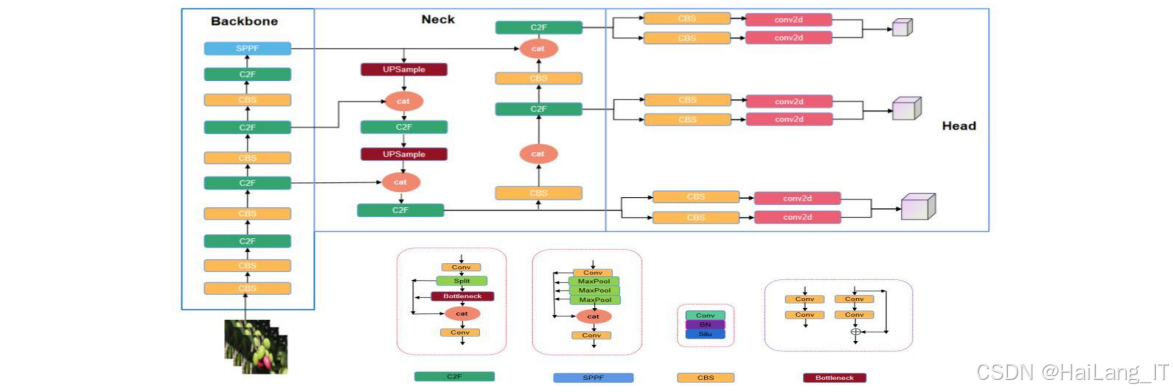
MobileNetV3轻量化模型
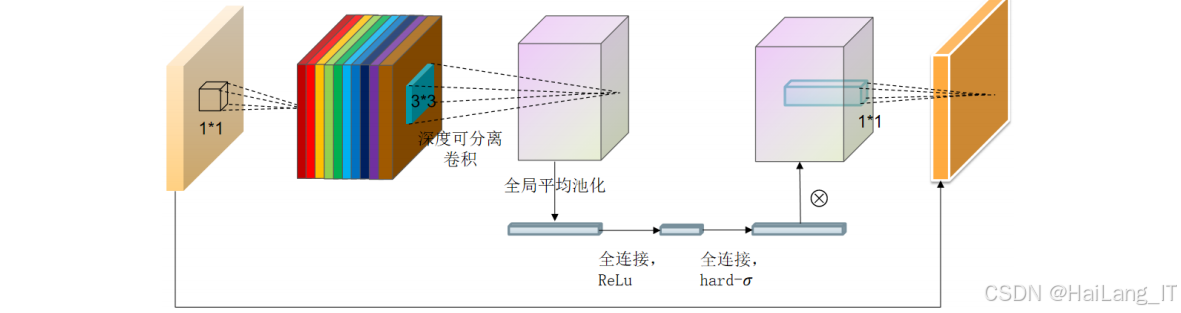
MobileNetV3是Google推出的轻量化卷积神经网络模型,具有较小的参数量和计算量,适合应用于资源受限的设备上。MobileNetV3采用了深度可分离卷积、挤压激励(SE)模块和h-swish激活函数等技术,在保证模型性能的同时,大幅减少了模型的参数量和计算量在油橄榄品种和成熟度检测系统中,结合MobileNetV3对YOLOv8s进行轻量化处理,可以提高模型的运行效率,使得模型能够在移动设备或嵌入式设备上高效运行。通过将YOLOv8s的主干网络替换为MobileNetV3,可以大幅减少模型的参数量和计算量,同时保持较好的检测性能轻量化处理后的模型不仅可以提高系统的运行效率,还可以降低系统的硬件成本,扩大系统的应用范围。在实际应用中,可以将轻量化模型部署在移动设备或嵌入式设备上,实现油橄榄品种和成熟度的现场检测。
特征融合技术
特征融合技术是目标检测算法中的重要技术之一,用于融合不同层次的特征信息,提高模型对不同尺度目标的检测能力。在YOLOv8s中,采用了特征金字塔网络(FPN)和路径聚合网络(PAN)进行特征融合,将高层特征和低层特征进行融合,提高了模型的检测精度FPN通过自顶向下的路径,将高层特征的语义信息传递到低层特征,提高了低层特征的语义表达能力。PAN通过自底向上的路径,将低层特征的位置信息传递到高层特征,提高了高层特征的定位精度。通过FPN和PAN的结合,YOLOv8s可以充分利用不同层次特征的优势,提高对不同尺度目标的检测能力在油橄榄品种和成熟度检测中,特征融合技术可以帮助模型更好地提取油橄榄的特征信息,提高检测的准确性。特别是对于不同成熟度和品种的油橄榄,其外观特征存在差异,特征融合技术可以帮助模型更好地识别这些差异。
相关代码介绍
数据预处理代码
数据预处理是模型训练的重要步骤,主要包括图像增强、数据划分和格式转换等。以下是数据预处理的核心代码,用于对油橄榄图像数据集进行处理,提高数据的质量和可用性。
python
import os
import cv2
import random
import shutil
from tqdm import tqdm
# 图像增强函数
def augment_image(image):
# 随机旋转
angle = random.randint(-15, 15)
h, w = image.shape[:2]
M = cv2.getRotationMatrix2D((w/2, h/2), angle, 1.0)
image = cv2.warpAffine(image, M, (w, h))
# 随机缩放
scale = random.uniform(0.9, 1.1)
image = cv2.resize(image, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
# 随机翻转
if random.random() > 0.5:
image = cv2.flip(image, 1) # 水平翻转
# 随机亮度调整
brightness = random.uniform(0.8, 1.2)
image = cv2.convertScaleAbs(image, alpha=brightness, beta=0)
return image
# 数据划分函数
def split_dataset(image_dir, label_dir, output_dir, train_ratio=0.8, val_ratio=0.1):
# 创建输出目录
train_image_dir = os.path.join(output_dir, 'train', 'images')
train_label_dir = os.path.join(output_dir, 'train', 'labels')
val_image_dir = os.path.join(output_dir, 'val', 'images')
val_label_dir = os.path.join(output_dir, 'val', 'labels')
test_image_dir = os.path.join(output_dir, 'test', 'images')
test_label_dir = os.path.join(output_dir, 'test', 'labels')
os.makedirs(train_image_dir, exist_ok=True)
os.makedirs(train_label_dir, exist_ok=True)
os.makedirs(val_image_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
os.makedirs(test_image_dir, exist_ok=True)
os.makedirs(test_label_dir, exist_ok=True)
# 获取所有图像文件
image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg') or f.endswith('.png')]
random.shuffle(image_files)
# 计算划分数量
total = len(image_files)
train_num = int(total * train_ratio)
val_num = int(total * val_ratio)
# 划分数据集
for i, image_file in tqdm(enumerate(image_files)):
image_path = os.path.join(image_dir, image_file)
label_file = os.path.splitext(image_file)[0] + '.txt'
label_path = os.path.join(label_dir, label_file)
if i < train_num:
dst_image_path = os.path.join(train_image_dir, image_file)
dst_label_path = os.path.join(train_label_dir, label_file)
elif i < train_num + val_num:
dst_image_path = os.path.join(val_image_dir, image_file)
dst_label_path = os.path.join(val_label_dir, label_file)
else:
dst_image_path = os.path.join(test_image_dir, image_file)
dst_label_path = os.path.join(test_label_dir, label_file)
shutil.copy(image_path, dst_image_path)
shutil.copy(label_path, dst_label_path)
# 主函数
if __name__ == '__main__':
image_dir = 'data/olive/images'
label_dir = 'data/olive/labels'
output_dir = 'data/olive_processed'
# 数据划分
split_dataset(image_dir, label_dir, output_dir)
# 图像增强示例
sample_image = cv2.imread(os.path.join(image_dir, os.listdir(image_dir)[0]))
augmented_image = augment_image(sample_image)
cv2.imwrite('augmented_sample.jpg', augmented_image)这段代码实现了数据预处理的主要功能。首先,定义了图像增强函数augment_image,通过随机旋转、缩放、翻转和亮度调整等方式增强图像数据。然后,定义了数据划分函数split_dataset,将数据集分为训练集、验证集和测试集。最后,在主函数中调用这些函数,实现数据预处理的流程数据预处理代码的设计考虑了以下几个方面:一是使用了OpenCV库进行图像处理,确保处理的高效性和准确性;二是采用了随机化的增强方式,提高数据集的多样性;三是实现了自动化的数据划分,减少了人工操作;四是使用了tqdm库显示处理进度,提高了用户体验。
YOLOv8s模型训练代码
YOLOv8s模型训练代码用于训练油橄榄品种和成熟度检测模型。以下是模型训练的核心代码,基于Ultralytics库实现。
python
from ultralytics import YOLO
import os
# 加载预训练模型
model = YOLO('yolov8s.pt')
# 模型配置
config = {
'data': 'data/olive.yaml', # 数据集配置文件
'epochs': 100, # 训练轮数
'batch': 16, # 批量大小
'imgsz': 640, # 图像大小
'lr0': 0.01, # 初始学习率
'lrf': 0.01, # 最终学习率
'momentum': 0.937, # 动量
'weight_decay': 0.0005, # 权重衰减
'warmup_epochs': 3.0, # 预热轮数
'warmup_momentum': 0.8, # 预热动量
'warmup_bias_lr': 0.1, # 预热偏置学习率
'box': 7.5, # 边界框损失权重
'cls': 0.5, # 类别损失权重
'dfl': 1.5, # 分布焦点损失权重
'patience': 50, # 早停 patience
'device': '0', # 使用的GPU设备
'workers': 8, # 数据加载线程数
'project': 'runs/train', # 项目名称
'name': 'olive_detection', # 实验名称
'exist_ok': True, # 如果存在则覆盖
'pretrained': True, # 使用预训练模型
'optimizer': 'SGD', # 优化器
'verbose': True, # 详细输出
'seed': 42, # 随机种子
'deterministic': True, # 确定性训练
'single_cls': False, # 是否单类别
'rect': False, # 是否矩形训练
'cos_lr': False, # 是否余弦学习率
'close_mosaic': 10, # 关闭马赛克增强的轮数
'resume': False, # 是否 resume 训练
'amp': True, # 是否使用混合精度训练
'fp16': True, # 是否使用 FP16
'fraction': 1.0, # 训练数据比例
'profile': False, # 是否分析模型
'freeze': None, # 冻结的层
}
# 模型训练
results = model.train(**config)
# 模型验证
metrics = model.val()
# 模型保存
model.save('olive_detection_model.pt')这段代码实现了YOLOv8s模型的训练流程。首先,加载预训练的YOLOv8s模型。然后,配置模型的训练参数,包括数据集路径、训练轮数、批量大小、学习率等。接着,调用模型的train方法进行训练,并使用val方法进行验证。最后,保存训练好的模型模型训练代码的设计考虑了以下几个方面:一是使用了Ultralytics库提供的YOLOv8实现,简化了模型训练的流程;二是配置了详细的训练参数,确保模型能够充分训练;三是实现了模型验证和保存功能,方便后续的使用;四是采用了混合精度训练等技术,提高了训练效率。
模型推理代码
模型推理代码用于使用训练好的模型进行油橄榄品种和成熟度检测。以下是模型推理的核心代码。
python
from ultralytics import YOLO
import cv2
import numpy as np
# 加载模型
model = YOLO('olive_detection_model.pt')
# 类别名称
class_names = {
0: 'Barnea',
1: 'Codovil',
2: 'Giarffa',
3: 'Koroneiki',
4: 'Leucoarpa Round',
5: 'Picual',
6: 'Unripe',
7: 'Half-ripe',
8: 'Ripe'
}
# 推理函数
def detect_olive(image_path):
# 读取图像
image = cv2.imread(image_path)
if image is None:
print(f'无法读取图像: {image_path}')
return None
# 模型推理
results = model(image)
# 处理结果
detected_image = image.copy()
for result in results:
boxes = result.boxes
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)
# 获取类别和置信度
cls = int(box.cls[0])
conf = float(box.conf[0])
# 绘制边界框
color = (0, 255, 0) if conf > 0.7 else (0, 0, 255)
cv2.rectangle(detected_image, (x1, y1), (x2, y2), color, 2)
# 添加标签
label = f'{class_names[cls]}: {conf:.2f}'
cv2.putText(detected_image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
return detected_image
# 主函数
if __name__ == '__main__':
# 测试图像路径
test_image_path = 'test_olive.jpg'
# 模型推理
detected_image = detect_olive(test_image_path)
if detected_image is not None:
# 显示结果
cv2.imshow('Detection Result', detected_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 保存结果
cv2.imwrite('detection_result.jpg', detected_image)这段代码实现了模型推理的主要功能。首先,加载训练好的模型。然后,定义了类别名称字典,将模型输出的类别索引映射为实际的品种和成熟度名称。接着,定义了推理函数detect_olive,用于对输入的图像进行推理,绘制边界框和标签。最后,在主函数中调用推理函数,实现模型推理的流程模型推理代码的设计考虑了以下几个方面:一是使用了Ultralytics库提供的YOLOv8推理接口,简化了推理流程;二是实现了结果可视化功能,方便用户查看检测结果;三是添加了置信度阈值判断,提高了检测结果的可靠性;四是保存了检测结果图像,方便后续的分析和使用。
重难点和创新点
重难点
油橄榄品种和成熟度检测系统的开发面临着一些重难点问题。首先,数据集的构建是一个难点。油橄榄的品种和成熟度特征复杂,需要大量的标注数据才能训练出准确的模型。同时,不同品种和成熟度的油橄榄在外观上存在相似性,增加了数据标注的难度其次,模型的设计和优化是一个重点。需要选择合适的目标检测算法,并对其进行优化,以提高检测精度和速度。同时,需要考虑模型的轻量化,使得模型能够在资源受限的设备上高效运行最后,系统的实际应用是一个难点。油橄榄种植环境复杂,存在不同的光照、背景和角度等因素,对模型的鲁棒性提出了很高的要求。同时,系统需要具备实时处理能力,能够满足实际生产的需求。
创新点
本项目的创新点主要体现在以下几个方面:一是结合了YOLOv8s和MobileNetV3模型,实现了高精度和高效率的油橄榄品种和成熟度检测。YOLOv8s具有较高的检测精度,MobileNetV3具有较小的参数量和计算量,两者的结合能够在保证检测精度的同时,提高模型的运行效率二是构建了专门的油橄榄品种和成熟度检测数据集,包含了不同品种、不同成熟度和不同环境条件下的油橄榄图像,为模型的训练提供了丰富的数据支持。数据集的构建考虑了数据的多样性和代表性,提高了模型的鲁棒性三是实现了一个完整的油橄榄品种和成熟度检测系统,包括图像采集、数据预处理、模型训练和检测识别等模块。系统的设计考虑了实际应用的需求,能够在资源受限的设备上高效运行,为油橄榄产业的自动化生产提供了技术支持。
总结
本项目针对油橄榄品种和成熟度检测需求,设计实现了一个基于深度学习的检测系统。项目的主要工作包括数据集构建、模型设计与训练、系统实现等环节。首先,构建了包含不同品种和成熟度的油橄榄图像数据集,并进行了数据预处理。然后,基于YOLOv8s算法和MobileNetV3轻量化模型,设计了油橄榄品种和成熟度检测模型,并进行了训练和优化。最后,实现了完整的检测系统,验证了模型的检测性能本项目的研究对于提高油橄榄产业的自动化水平,促进油橄榄产业的发展具有重要意义。通过使用深度学习技术,实现了油橄榄品种和成熟度的自动检测,提高了检测效率和准确性。同时,项目的研究成果也为其他农产品的检测和识别提供了参考在未来的研究中,可以进一步改进模型的性能,提高模型对复杂环境的适应能力。同时,可以将系统部署到移动设备或嵌入式设备上,实现油橄榄品种和成熟度的现场检测。此外,还可以扩展系统的功能,实现油橄榄的质量评估和分级等功能,进一步提高系统的应用价值。
相关文献
1 Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detectionC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
2 Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal speed and accuracy of object detectionJ. arXiv preprint arXiv:2004.10934, 2020.
3 Jocher G, Stoken A, Borovec J, et al. Ultralytics YOLOv5J. arXiv preprint arXiv:2011.08036, 2020.
4 Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applicationsJ. arXiv preprint arXiv:1704.04861, 2017.
5 Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted residuals and linear bottlenecksC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
6 Howard A, Sandler M, Chu G, et al. Searching for MobileNetV3C//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 1314-1324.
7 Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentationC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8759-8768.
8 He K, Zhang X, Ren S, et al. Deep residual learning for image recognitionC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.