Zhang, T., Yuan, H., Qi, L., et al. (2024). Point Cloud Mamba: Point Cloud Learning via State Space Model. arXiv.
1. 背景与痛点:为什么要做这个?
txt
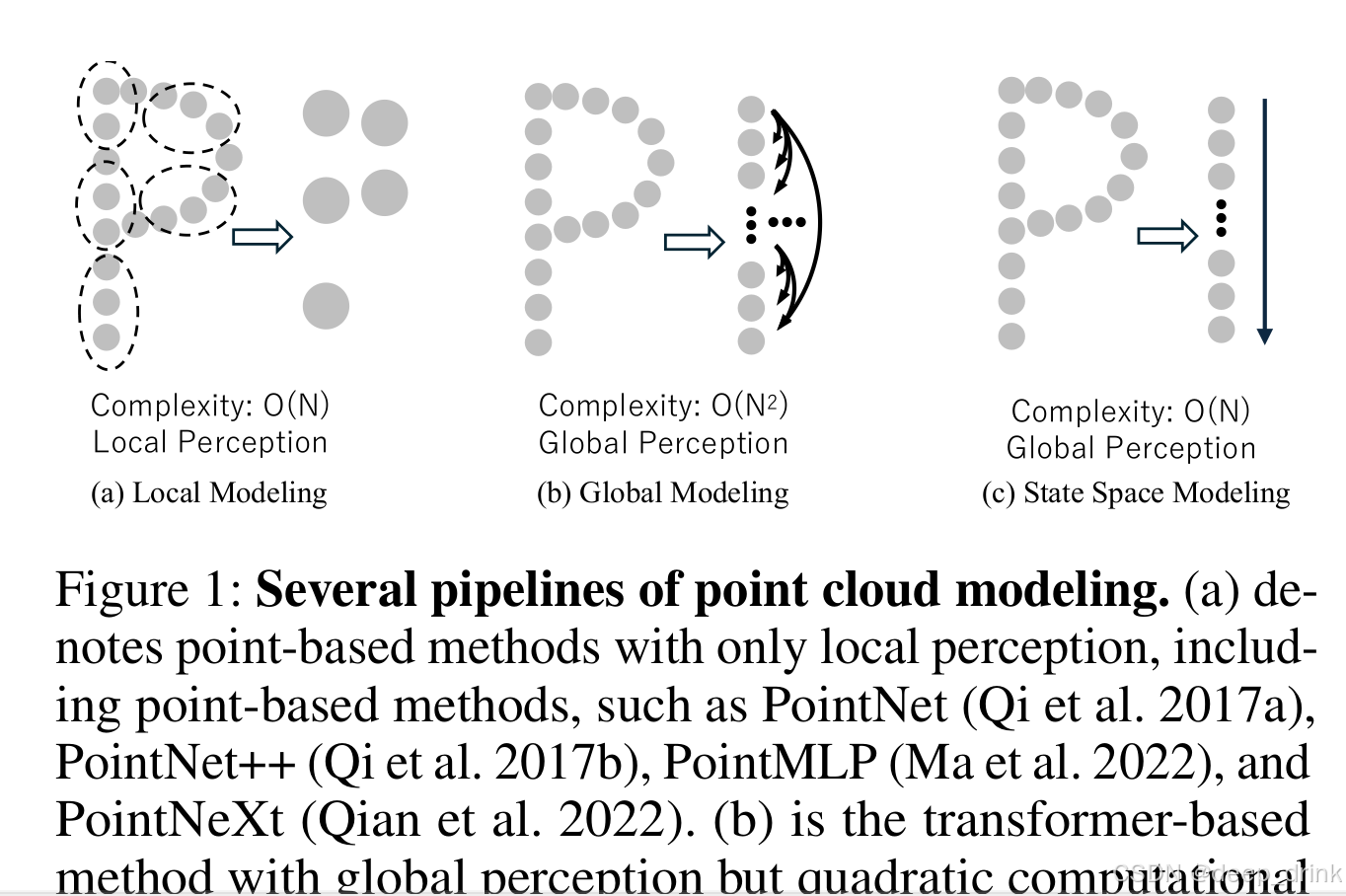
图 1: 三种点云建模范式的对比
(a) 局部建模 (Local Modeling)
代表模型:PointNet++, PointMLP, PointNeXt。
原理:如图中左侧虚线圈所示,这类方法通常通过 KNN 或球查询(Ball Query)将点云划分为一个个小的局部邻域,只在邻域内提取特征。
复杂度:O(N)(线性复杂度)。计算量随点数 N 线性增加,效率很高。
局限性:局部感知 (Local Perception)。模型像是在"管中窥豹",每次只能看到局部细节(比如只看到椅子的腿),很难捕捉到长距离的依赖关系(不知道这个腿属于一张椅子),缺乏对物体整体形状的理解。
(b) 全局建模 (Global Modeling)
代表模型:Point Transformer, Point-MAE(基于 Transformer 架构)。
原理:如图中中间部分所示,通过自注意力机制(Self-Attention),每一个点都要和所有其他点进行交互(箭头互相连接)。
优势:全局感知 (Global Perception)。模型拥有上帝视角,能捕捉点云中任意两点之间的关系,对整体形状理解深刻。
致命伤:O(N^2)(二次方复杂度)。计算量和显存占用随着点数 $N$ 的增加呈平方级爆炸。这使得它很难处理大规模点云(例如自动驾驶中的场景级点云)。
(c) 状态空间建模 (State Space Modeling) ------ 本文方法
代表模型:Point Cloud Mamba (PCM)。
原理:如图中右侧所示,它将点云排列成一个序列(通过 CTS 序列化),然后像扫描仪一样顺序处理(箭头向下流动)。Mamba 通过隐藏状态(State)记忆之前的历史信息,从而让当前点能"看到"之前的全局信息。
核心突破:"既要又要"。
它拥有 O(N) 的线性计算复杂度(像 (a) 一样快)。
它拥有 全局感知 (Global Perception) 能力(像 (b) 一样强)。
总结:Mamba 是目前唯一能在保持线性计算效率的同时,实现全局上下文建模的架构。在 3D 点云分析领域,长久以来存在着"鱼和熊掌不可兼得"的局面:
- 基于点/MLP 的方法 (如 PointNet++, PointNeXt) :
- 优势 :线性复杂度 O ( N ) O(N) O(N),推理速度快。
- 痛点:只能看局部(Local),缺乏全局感受野,难以捕捉长距离的形状依赖(比如椅子的左扶手和右后腿的关系)。
- 基于 Transformer 的方法 (如 PTv3) :
- 优势:拥有全局感受野(Global Perception)。
- 痛点 :Attention 机制带来的计算和显存开销是 O ( N 2 ) O(N^2) O(N2)。点数一多,显存直接爆炸,或者被迫切块导致全局性受损。
PCM (Point Cloud Mamba) 的核心思路 :引入 Mamba (SSM) 架构。
- 利用 Mamba 的 O ( N ) O(N) O(N) 线性复杂度 解决 Transformer 的重计算问题。
- 利用 Mamba 的 全局序列建模能力 解决 PointNet 的局部局限性。
- 核心挑战:Mamba 是为 1D 因果文本设计的,而 3D 点云是无序、非因果的空间数据。如何把"一团点"变成"一条线"且不丢失空间结构?这是 PCM 解决的核心问题。
2. 前置知识:硬核科普 Mamba (数学视角)
要读懂 PCM,需要理解 Mamba 是如何把连续系统离散化并进行推理的。
2.1 状态空间方程 (SSM)
Mamba 的核心源于连续系统的状态方程:
h ′ ( t ) = A h ( t ) + B x ( t ) h'(t) = A h(t) + B x(t) h′(t)=Ah(t)+Bx(t)
y ( t ) = C h ( t ) y(t) = C h(t) y(t)=Ch(t)
其中 x ( t ) x(t) x(t) 是输入, h ( t ) h(t) h(t) 是隐藏状态, y ( t ) y(t) y(t) 是输出。这不仅是 RNN,更是控制理论的经典形式。
2.2 离散化 (Discretization)
计算机无法处理连续时间,必须使用零阶保持 (Zero-Order Hold) 进行离散化。根据论文公式 (5)-(6),引入时间尺度参数 Δ \Delta Δ:
A ˉ = exp ( Δ A ) \bar{A} = \exp(\Delta A) Aˉ=exp(ΔA)
B ˉ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B \bar{B} = (\Delta A)^{-1}(\exp(\Delta A) - I) \cdot \Delta B Bˉ=(ΔA)−1(exp(ΔA)−I)⋅ΔB
最终的递推形式为:
h t = A ˉ h t − 1 + B ˉ x t h_t = \bar{A} h_{t-1} + \bar{B} x_t ht=Aˉht−1+Bˉxt
PCM 的优势根源 :这个公式在推理时是线性的(类似 RNN),而在训练时可以通过全局卷积 K ˉ \bar{K} Kˉ 并行计算(类似 CNN),兼顾了效率和长序列能力。
3. 网络框架与数据流 (Pipeline & Dimensions)
PCM 采用了层级化(Encoder-Decoder)结构。我们以 Encoder 的一个 Stage 为例,拆解数据 Input 到 Output 的完整形变。
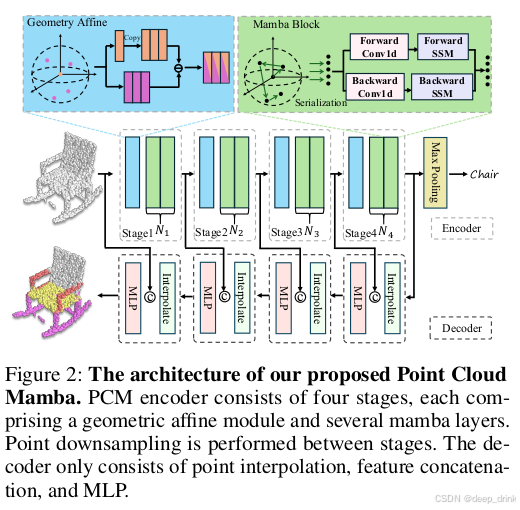
Step 1: Input → \rightarrow → Local Feature (局部建模)
- Input : 原始点云或上一层特征 P P P。
- Shape : ( B , N , 3 ) (B, N, 3) (B,N,3)。
- Module : Geometry Affine Module (GAM) (源自 PointMLP)。
- 作用:Mamba 擅长看全局,但对微小的局部几何不敏感。所以先用 KNN + MLP 提取局部特征。
- Output : 局部特征 F l o c a l F_{local} Flocal。
- Shape : ( B , N , C ) (B, N, C) (B,N,C)。
Step 2: Serialization (核心:3D 转 1D)
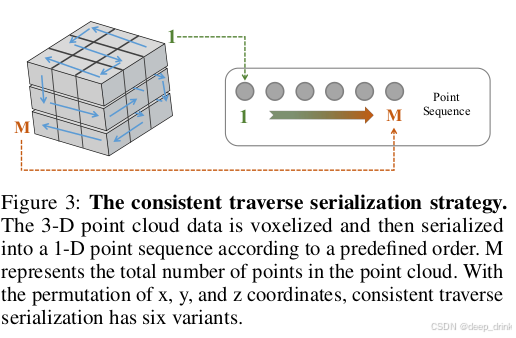
- Module : CTS (Consistent Traverse Serialization)。
- Process :将 3D 坐标 ( x , y , z ) (x,y,z) (x,y,z) 映射为 1D 排序索引
idx。 - Transformation : 根据
idx对特征 F l o c a l F_{local} Flocal 进行重排 (Reorder)。 - Output : 有序序列 F s e q F_{seq} Fseq。
- Shape : ( B , N , C ) (B, N, C) (B,N,C),但此时相邻的 Token 在空间上也是相邻的。
Step 3: Embedding & Prompts (注入位置与规则)
- Module : Positional Embedding & Order Prompts。
- Process :
- 位置编码 :直接映射 x y z xyz xyz 坐标,就是一个Linear层,加到特征上。
- Prompt 拼接 :在序列的 头 (Begin) 和 尾 (End) 拼接可学习的 Token。
- Output : Mamba 输入张量 F r e a d y F_{ready} Fready。
- Shape : ( B , N + 2 N p , C ) (B, N + 2N_p, C) (B,N+2Np,C)。N p N_p Np 为 Prompt 长度。
Step 4: Mamba Block (全局建模)
- Module : Bidirectional Mamba。
- Process : 正向 SSM + 反向 SSM。这一步让第 1 个点能"看见"第 N N N 个点。
- Output : 全局特征 F m a m b a F_{mamba} Fmamba。
- Shape : ( B , N + 2 N p , C ) (B, N + 2N_p, C) (B,N+2Np,C)。
Step 5: Restoration (还原)
- Process :
- 切掉头尾的 Prompts。
- 逆序重排 (Inverse Reorder) :把序列按
idx还原回点云的原始顺序。 - 残差连接 : F o u t = F l o c a l + F r e s t o r e d F_{out} = F_{local} + F_{restored} Fout=Flocal+Frestored。
- Output : Stage 输出 F o u t F_{out} Fout。
- Shape : ( B , N , C ) (B, N, C) (B,N,C),准备进入下一阶段下采样。
4. 核心模块详解:公式与原理
4.1 模块一:CTS (一致遍历序列化)
痛点 :简单的 Z-order 或 Hilbert 曲线计算复杂且不一定完美适配点云的稀疏性。
PCM 解法:网格编码 + 蛇形扫描。
- 网格化 :将坐标归一化并取整:
{ c x g , c y g , c z g } = int ( { c x s , c y s , c z s } × GridSize ) \{c^g_x, c^g_y, c^g_z\} = \text{int}(\{c^s_x, c^s_y, c^s_z\} \times \text{GridSize}) {cxg,cyg,czg}=int({cxs,cys,czs}×GridSize) - 蛇形编码 (Code Generation) :
为了保证遍历不跳跃(从一行末尾跳到下一行开头),PCM 使用了类似"犁地"的逻辑:偶数行正向扫,奇数行反向扫 。
Code = Code_func ( ... ) \text{Code} = \text{Code\_func}(\dots) Code=Code_func(...)- 直观理解:这保证了 1D 序列中相邻的两个点,在 3D 网格里也是物理相邻的。
- 多视角变体 :
不仅用xyz顺序,还用xzy,yzx等 6 种排列。这相当于让 Mamba 从 6 个不同的方向去"观察"这个物体。
4.2 模块二:Order Prompts (顺序提示)
痛点 :既然有 6 种排序方式,Mamba 怎么知道当前序列是按 xyz 排的还是 zyx 排的?
PCM 解法:借鉴 LLM 的 System Prompt。
- 定义 :为每种排序方式初始化一组可学习参数 P ∈ R N p × C P \in \mathbb{R}^{N_p \times C} P∈RNp×C。
- 操作 :
Input = P begin , Point_Seq , P end \text{Input} = P_{\\text{begin}}, \\text{Point\\_Seq}, P_{\\text{end}} Input=Pbegin,Point_Seq,Pend
在序列首尾各加一组 Prompt。 - 作用:这相当于告诉 Mamba 核心:"注意,接下来的序列是按 Z 轴优先排列的,请调整状态转移矩阵 A 及其选择性机制"。
4.3 模块三:Coordinate-based PE (坐标位置编码)
痛点 :Transformer 里的 RoPE 是基于 Index(第1个,第2个...)的。但在点云里,序列上相邻的第 i i i 和 i + 1 i+1 i+1 个点,物理距离可能忽远忽近(取决于序列化的质量)。
PCM 解法:回归本质,显式注入几何信息。
Emd p o s = Linear ( { c x , c y , c z } ) \text{Emd}_{pos} = \text{Linear}(\{c_x, c_y, c_z\}) Emdpos=Linear({cx,cy,cz})
PCM 发现,与其搞复杂的可学习 PE 或 RoPE,不如直接把 x y z xyz xyz 坐标通过一个线性层投影并加到特征上。这是最简单但最有效的方案,直接告诉模型每个 Token 在空间中的绝对位置。
5. 实验:尤其是消融实验 📊
PCM 的实验结果证明了 Mamba 在 3D 领域的统治力。
5.1 主实验:SOTA 表现
- ScanObjectNN (最难的分类榜单) :PCM 达到 88.1% OA 。
- 超越 PointNeXt (87.7%)。
- 超越 Transformer 架构的 PTv3 (86.4%)。
- S3DIS (语义分割) :
- PCM + DeLA (增强局部特征) 达到 79.6 mIoU。
- 相比 PTv3 (74.7 mIoU) 提升了 4.9 mIoU,这是一个巨大的 Gap。
5.2 消融实验:为什么这三个模块有效?
1. 序列化策略对比 (Table 5)
- 单视角 (Only xyz):OA 86.71%。
- 多视角 (6 variants) :OA 87.10%。
- 结论:多视角序列化显著提升了模型的鲁棒性,相当于做了一种 Test-time Augmentation 的训练版。
2. Positional Embedding 选择 (Table 7)
- RoPE (旋转位置编码):OA 86.95% ------ 效果最差,证明序列 Index 不适合点云。
- Linear (坐标映射) :OA 87.32% ------ 简单粗暴最有效。
3. Order Prompts 的数量 (Table 8)
- 0 Prompts: OA 86.64%。
- 6 Prompts : OA 87.47%。
- 结论:如果不加 Prompt,模型会混淆不同的排序逻辑。加上 Prompt 后,性能提升显著。
6. 总结
Point Cloud Mamba (PCM) 是一篇极具工程价值的论文。它没有停留在"把 Transformer 换成 Mamba"的简单替换上,而是深入思考了 1D 模型处理 3D 数据的本质难点:
- 3D → \to → 1D :通过 CTS 解决了空间邻域到序列邻域的映射。
- Context 提示 :通过 Order Prompts 解决了多视角输入的歧义性。
- 位置感知 :通过 Linear PE 弥补了序列化带来的几何信息损失。
最终,PCM 证明了在 3D 点云领域,O ( N ) O(N) O(N) 的 Mamba 完全有能力击败 O ( N 2 ) O(N^2) O(N2) 的 Transformer。
📚 参考文献
1 Zhang, T., et al. Point Cloud Mamba: Point Cloud Learning via State Space Model. arXiv 2024.
💬 互动话题:
- 关于序列化:你觉得 CTS 这种网格排序是"最优解"吗?有没有可能用 Hilbert 曲线或者可学习的排序网络来替代?
- 关于未来:Mamba 在 3D 分割上赢了,但在生成任务(Generation)上会有优势吗?
📚 附录:点云 Mamba 系列导航
🔥 欢迎订阅专栏 :【点云特征分析_顶会论文代码硬核拆解】持续更新中...
本文为 CSDN 专栏【点云特征分析_顶会论文代码硬核拆解】原创内容,转载请注明出处。