文章目录
一、光流法运动轨迹跟踪
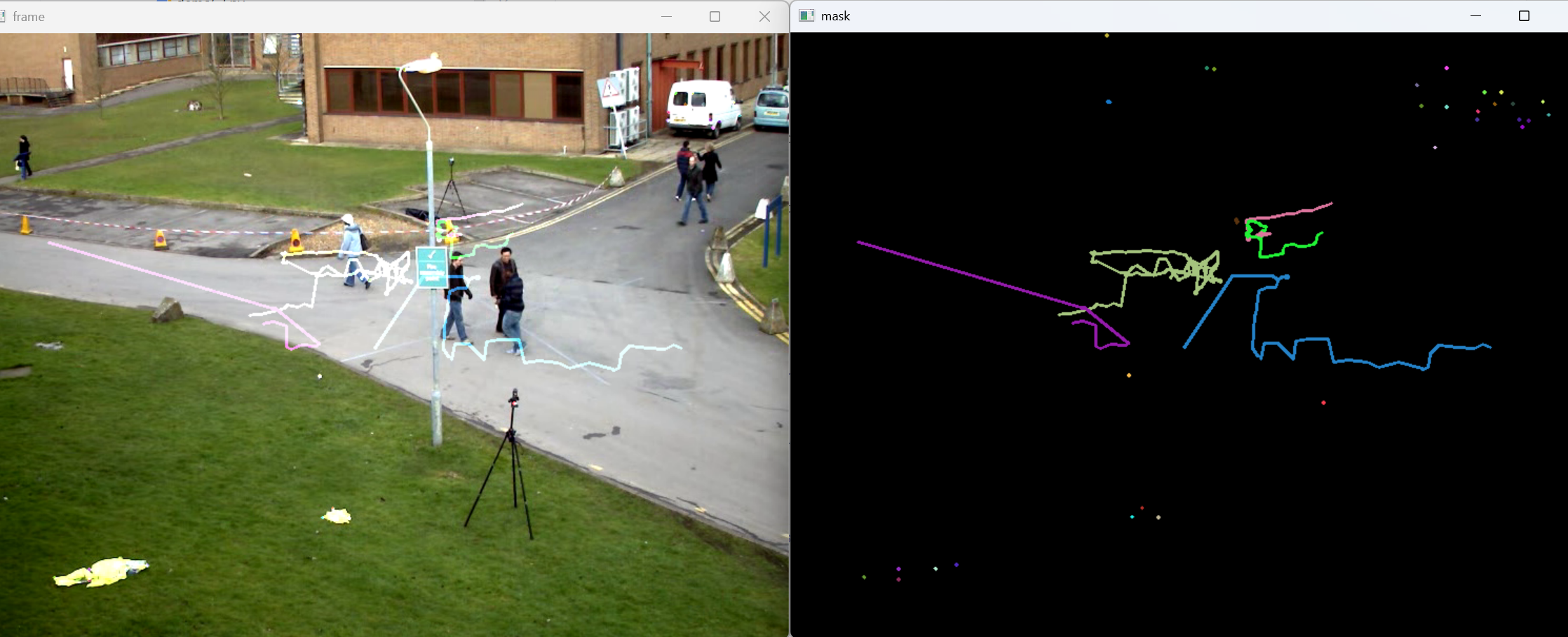
光流法是一种通过分析连续帧之间的像素变化来追踪物体运动轨迹的技术。下面的代码展示了如何使用Shi-Tomasi角点检测和Lucas-Kanade光流法实现运动跟踪:
python
import cv2
import numpy as np
# 读取视频文件
cap = cv2.VideoCapture('test.avi')
# Shi-Tomasi角点检测参数配置
feature_params = dict(
maxCorners=100, # 设置检测的最大角点数量
qualityLevel=0.3, # 角点质量阈值,值越小检测到的角点越多
minDistance=7 # 角点间的最小像素距离,避免角点过于密集
)
# Lucas-Kanade光流法参数配置
lk_params = dict(
winSize=(15, 15), # 搜索窗口大小,较大的窗口能处理更大的运动
maxLevel=2 # 金字塔层数,用于处理不同尺度下的运动
)
# 生成随机颜色用于绘制不同轨迹
color = np.random.randint(0, 255, (100, 3))
# 读取视频第一帧并转换为灰度图
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 检测初始角点作为跟踪起点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建与视频帧大小相同的黑色画布,用于绘制轨迹
mask = np.zeros_like(old_frame)
# 主循环:逐帧处理视频
while True:
ret, frame = cap.read()
if not ret:
break
# 当前帧转换为灰度图
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流:追踪p0点在当前帧中的新位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 筛选跟踪成功的点(状态为1表示跟踪成功)
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制运动轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 当前帧中的点坐标
c, d = old.ravel() # 上一帧中的点坐标
a, b, c, d = int(a), int(b), int(c), int(d)
# 在掩模上绘制连接线,显示运动路径
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
# 在当前帧上标记角点位置
cv2.circle(frame, (a, b), 5, color[i].tolist(), -1)
# 将轨迹叠加到当前帧上
img = cv2.add(frame, mask)
# 显示结果
cv2.imshow('frame', img)
# 更新前一帧数据和特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
# 检测ESC键退出
k = cv2.waitKey(150)
if k == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()关键技术分析
Shi-Tomasi角点检测:
maxCorners:控制检测角点的最大数量,平衡精度和性能qualityLevel:决定角点质量的阈值,值越小检测越敏感minDistance:确保角点分布均匀,避免聚集
Lucas-Kanade光流法:
winSize:搜索窗口大小,影响运动检测的敏感度maxLevel:图像金字塔层数,用于处理多尺度运动
二、基于深度学习的艺术风格迁移
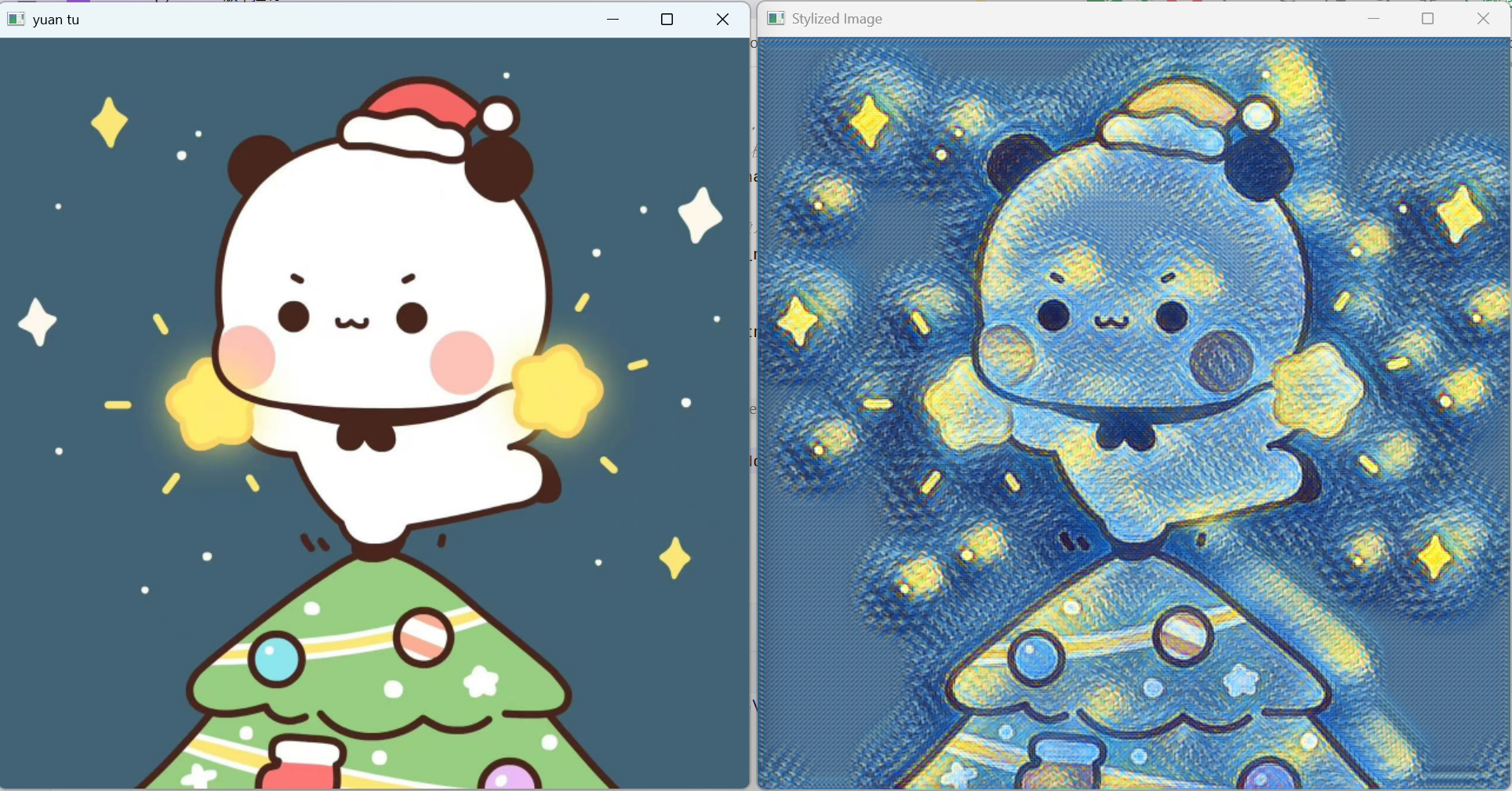
OpenCV的dnn模块支持加载预训练的深度学习模型,实现艺术风格转换:
python
import cv2
# 读取并调整输入图像大小
image = cv2.imread(r"picture_1.jpg")
image = cv2.resize(image, None, fx=0.5, fy=0.5)
# 显示原始图像
cv2.imshow('yuan tu', image)
cv2.waitKey(0)
# 获取图像尺寸
(h, w) = image.shape[:2]
# 图像预处理:创建神经网络输入格式
blob = cv2.dnn.blobFromImage(
image, # 输入图像
scalefactor=1, # 像素值缩放因子
size=(w, h), # 输出blob的尺寸
mean=(0, 0, 0), # 各通道的均值(不进行均值减法)
swapRB=False, # 不交换R和B通道(OpenCV使用BGR格式)
crop=False # 不进行裁剪
)
# 加载预训练的艺术风格模型
# 支持多种框架格式:Caffe、TensorFlow、PyTorch、Darknet等
net = cv2.dnn.readNet(r'model\starry_night.t7') # PyTorch格式的星空风格模型
# 设置网络输入
net.setInput(blob)
# 前向传播:获得风格化输出
out = net.forward()
# 输出数据处理:四维转三维
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 数据归一化到[0,1]范围
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 调整维度顺序:CHW → HWC
result = out_new.transpose(1, 2, 0)
# 显示风格化结果
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()blobFromImage函数详解
cv2.dnn.blobFromImage()是将图像转换为神经网络输入格式的关键函数:
- scalefactor:每个像素值的缩放倍数,常用于数据归一化
- size:指定输出blob的宽度和高度,通常与网络输入层匹配
- mean:各通道的均值,用于均值减法(数据标准化)
- swapRB:OpenCV使用BGR格式,而大多数模型使用RGB,此参数控制是否交换通道
- crop:是否在调整大小后进行中心裁剪
三、实时目标跟踪
OpenCV提供多种跟踪算法,CSRT跟踪器在准确性和速度之间取得良好平衡:
python
import cv2
# 创建CSRT跟踪器实例
tracker = cv2.TrackerCSRT_create()
# 跟踪状态标志
tracking = False
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
# 读取摄像头帧
ret, frame = cap.read()
if not ret:
break
# 按下's'键开始跟踪,选择ROI区域
if cv2.waitKey(1) == ord('s'):
tracking = True
# 交互式选择跟踪区域
roi = cv2.selectROI('Tracking', frame, showCrosshair=False)
# 初始化跟踪器
tracker.init(frame, roi)
# 如果正在跟踪,更新跟踪器位置
if tracking:
success, box = tracker.update(frame)
if success:
# 提取边界框坐标
x, y, w, h = [int(v) for v in box]
# 绘制跟踪框
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示跟踪结果
cv2.imshow('Tracking', frame)
# 按下ESC键退出
if cv2.waitKey(1) == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()跟踪器工作流程
- 初始化阶段:用户通过鼠标选择感兴趣区域(ROI)
- 跟踪阶段:跟踪器根据目标的纹理、颜色等特征在后续帧中定位目标
- 更新阶段 :
tracker.update()返回跟踪状态和边界框坐标
四、多风格实时艺术滤镜
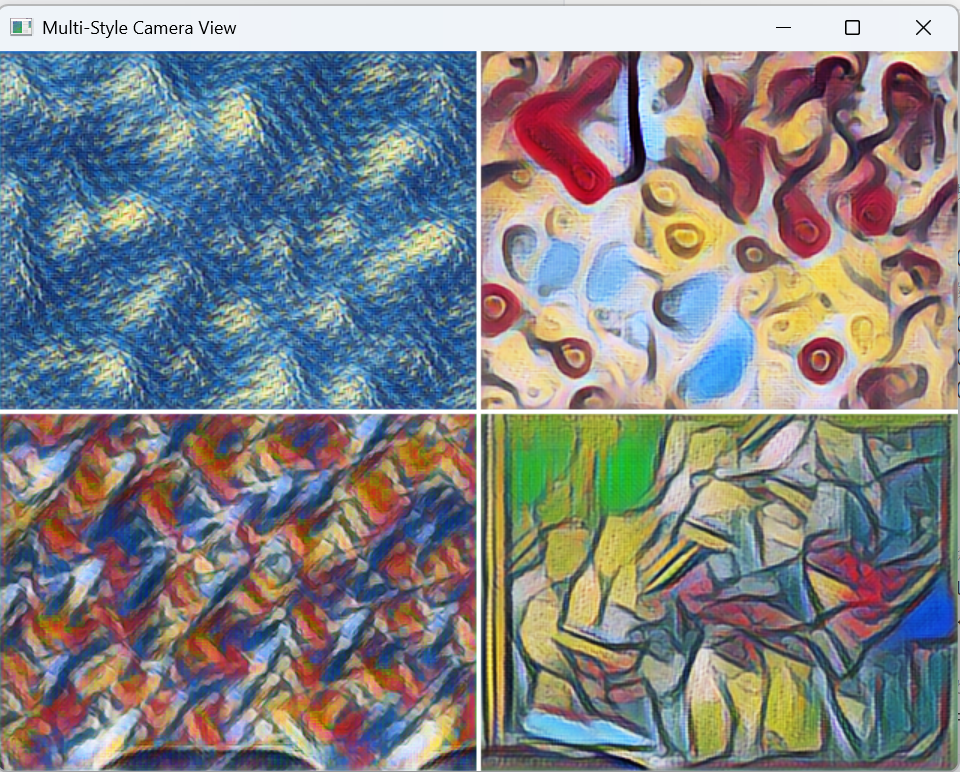
将摄像头画面分割为四个区域,分别应用不同的艺术风格:
python
import cv2
import numpy as np
import threading
from queue import Queue
# 加载四种不同的艺术风格模型
def load_models():
models = [
cv2.dnn.readNet(r'model\starry_night.t7'), # 梵高星空风格
cv2.dnn.readNet(r'model\candy.t7'), # 糖果风格
cv2.dnn.readNet(r'model\composition_vii.t7'), # 康定斯基风格
cv2.dnn.readNet(r'model\la_muse.t7') # 缪斯风格
]
return models
# 对单个图像块应用风格迁移
def apply_style(image_block, model):
(h, w) = image_block.shape[:2]
# 图像预处理
blob = cv2.dnn.blobFromImage(
image_block,
scalefactor=1.0,
size=(w, h),
mean=(0, 0, 0),
swapRB=False,
crop=False
)
# 模型推理
model.setInput(blob)
out = model.forward()
# 后处理
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
result = np.uint8(result * 255) # 转换为8位图像
return result
# 并行处理器类:使用多线程加速处理
class StyleProcessor:
def __init__(self, models):
self.models = models
self.results = [None] * 4
def process_block(self, block_idx, block, model):
result = apply_style(block, model)
self.results[block_idx] = result
def process_all_blocks(self, blocks):
threads = []
for i in range(4):
# 为每个区域创建独立线程
thread = threading.Thread(
target=self.process_block,
args=(i, blocks[i], self.models[i])
)
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
return self.results
# 主函数(优化版本)
def main_optimized():
# 初始化模型和处理器
models = load_models()
processor = StyleProcessor(models)
# 设置摄像头
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
print("按ESC键退出程序...")
while True:
ret, frame = cap.read()
if not ret:
break
# 统一图像尺寸
frame = cv2.resize(frame, (640, 480))
height, width = frame.shape[:2]
# 计算分割点
mid_h, mid_w = height // 2, width // 2
# 将画面分割为四个区域
blocks = [
frame[0:mid_h, 0:mid_w], # 左上区域
frame[0:mid_h, mid_w:width], # 右上区域
frame[mid_h:height, 0:mid_w], # 左下区域
frame[mid_h:height, mid_w:width] # 右下区域
]
# 并行处理四个区域
styled_blocks = processor.process_all_blocks(blocks)
# 创建输出画布
output_frame = np.zeros_like(frame)
# 拼接处理后的区域
output_frame[0:mid_h, 0:mid_w] = styled_blocks[0]
output_frame[0:mid_h, mid_w:width] = styled_blocks[1]
output_frame[mid_h:height, 0:mid_w] = styled_blocks[2]
output_frame[mid_h:height, mid_w:width] = styled_blocks[3]
# 绘制区域分割线
cv2.line(output_frame, (mid_w, 0), (mid_w, height), (255, 255, 255), 2)
cv2.line(output_frame, (0, mid_h), (width, mid_h), (255, 255, 255), 2)
# 显示多风格画面
cv2.imshow('Multi-Style Camera View', output_frame)
if cv2.waitKey(1) & 0xFF == 27:
break
# 清理资源
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main_optimized()多线程优化策略
- 区域分割:将摄像头画面均匀分为四个独立区域
- 并行处理:每个区域使用独立线程应用不同的风格模型
- 结果拼接:将处理后的区域重新组合为完整画面
性能优化技巧
- 降低分辨率:减小处理数据量,提高实时性
- 多线程处理:充分利用多核CPU并行计算
- 模型选择:选择轻量级模型或优化模型大小
- 帧率控制:可适当降低处理帧率,平衡质量和速度
这些代码示例展示了OpenCV在计算机视觉领域的多样化应用,从传统的运动跟踪到基于深度学习的艺术创作,体现了计算机视觉技术的强大功能和广泛应用前景。