import math
import torch
from torch import nn
from torch.nn import functional as F
import test_53LanguageModel
batch_size,num_steps=32,35
train_iter,vocab=test_53LanguageModel.load_data_time_machine(batch_size,num_steps)
# print(F.one_hot(torch.tensor([0,2]),len(vocab)))#对下标数字转成向量,方便神经网络处理#初始化模型参数
def get_params(vocab_size,num_hiddens,device):
num_inputs=num_output=vocab_size
def normal(shape):
return torch.randn(size=shape,device=device)*0.01
W_xh=normal((num_inputs,num_hiddens))
W_hh=normal((num_hiddens,num_hiddens))
b_h=torch.zeros(num_hiddens,device=device)
W_hy=normal((num_hiddens,num_output))
b_y=torch.zeros(num_output,device=device)
params=[W_xh,W_hh,b_h,W_hy,b_y]
for param in params:
param.requires_grad_(True)
return params#初始化隐藏层,对于0时刻,没有上一时刻的隐藏状态,因此需要初始化
def init_rnn_state(batch_size,num_hiddens,device):
return (torch.zeros(batch_size,num_hiddens,device=device),)#sltm有两个张量,统一化,rnn只有一个
#一个时间布更新隐藏状态和输出
def rnn(inputs,state,params):
W_xh, W_hh, b_h, W_hy, b_y=params
H,=state
outputs=[]
for X in inputs:
H=torch.tanh(torch.mm(X,W_xh)+torch.mm(H,W_hh)+b_h)
Y=torch.mm(H,W_hy)+b_y
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)
class RNNModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_rnn_state,forward_fn):
self.vocab_size=vocab_size
self.forward_fn=forward_fn
self.num_hiddens=num_hiddens
self.params=get_params(vocab_size,num_hiddens,device)
self.init_rnn_state=init_rnn_state
def __call__(self,X,state):
X=F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.forward_fn(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_rnn_state(batch_size,self.num_hiddens,device)
#验证
num_hiddens=512
net=RNNModelScratch(len(vocab),num_hiddens,d2l.try_gpu(),get_params,init_rnn_state,rnn)
state=net.begin_state(X.shape[0],d2l.try_gpu())
Y,new_state=net(X.to(d2l.try_gpu()),state)
print(Y.shape,len(new_state),new_state[0].shape)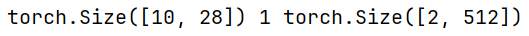
def predict_ch8(prefix,num_preds,net,vocab,device):
state=net.begin_state(batch_size=1,device=device)#一次只生成一条序列
outputs=[vocab[prefix[0]]]#将前缀第一个字符放到预测中
get_input=lambda :torch.tensor([outputs[-1]],device=device).reshape(1,1)#“自回归生成”:用上一次生成的 token 当下一次输入
for y in prefix[1:]:#遍历前缀的剩余字符
_,state=net(get_input(),state)#将上一次生成的喂到网络,更新state
outputs.append(vocab[y])#将已知序列直接放入输出中,减少误差
for _ in range(num_preds):
y,state=net(get_input(),state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])#将字符串穿起来中间不加间隔
m=predict_ch8('time traveller',10,net,vocab,d2l.try_gpu())
print(m)
可以看出结果可以正常输出,但是由于网络没有很好训练,所以结果几乎是乱猜
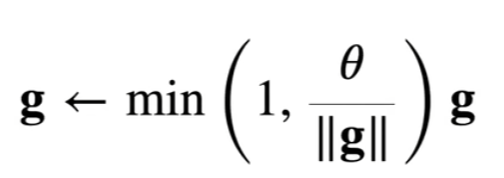
#梯度剪裁
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params=[p for p in net.parameters() if p.requires_grad]
else:
params=net.params
norm=torch.sqrt(sum(torch.sum((p.grad**2))for p in params))
if norm>theta:
for param in params:
param.grad[:]*=theta/normdef train_epoch_ch8(net,train_iter,loss,updater,device,use_random_iter):
state,timer=None,TIME1.Timer()
metric=d2l.Accumulator(2)
for X,Y in train_iter:
if state is None or use_random_iter:#batch之间不连续,则初始化
state=net.begin_state(batch_size=X.shape[0],device=device)
else:
if isinstance(net,nn.Module) and not isinstance(state,(list,tuple)):
state.detach_()
else:
for s in state:
s.detach_()
y=Y.T.reshape(-1)
X,y=X.to(device),y.to(device)
y_hat,state=net(X,state)
l=loss(y_hat,y.long()).mean()
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net,1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
updater(batch_size=1)
metric.add(l*y.numel(),y.numel())
return math.exp(metric[0]/metric[1])def train_ch8(net,train_iter,vocab,lr,num_epochs,device,use_random_iter=False):
loss=nn.CrossEntropyLoss()
animator=d2l.Animator(xlabel='epoch',ylabel='perplexity',legend=['train'],xlim=[10,num_epochs])
if isinstance(net,nn.Module):
updater=torch.optim.SGD(net.parameters(),lr)
else:
updater=lambda batch_size: d2l.sgd(net.params,lr,batch_size)
predict=lambda prefix: predict_ch8(prefix,50,net,vocab,device)
#训练
for epoch in range(num_epochs):
ppl,speed=train_epoch_ch8(net,train_iter,loss,updater,device,use_random_iter)
if (epoch+1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch+1,[ppl])
print(f'困惑度{ppl:1f},{speed:1f}词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('time'))
num_epochs=500
lr=1
train_ch8(net,train_iter,vocab,lr,num_epochs,d2l.try_gpu())