在大模型快速演进的今天,真正拉开产品差距的,不只是模型效果,而是系统的独立性、可控性与可持续演进能力。
qKnow 商业版 v2.6.1 正式发布。
这是一次里程碑式的重大版本更新。
本次版本,我们完成了一件"难但正确"的事情:
👉 全面移除对第三方知识库与 LLM 应用开发框架的依赖,构建完全自主可控的大语言模型与知识库集成体系。
这不是一次简单的功能替换,而是一场底层能力的重构。
🧭 为什么要做这次"去依赖"?
在过去一段时间里,第三方 LLM 应用开发框架在快速验证、快速落地阶段发挥了重要作用。但随着业务规模扩大、场景复杂度提升,我们越来越清晰地看到一些长期问题:
- 框架能力边界受限,深度定制困难
- 多模型、多向量库适配灵活性不足
- 技术栈被锁定,升级节奏受制于人
- 在政企、行业场景下,自主可控成为硬要求
qKnow 不是一个 Demo,而是要长期服务企业与行业的知识平台。
因此,从 v2.6.1 开始,我们选择了一条更难、但更稳的路。
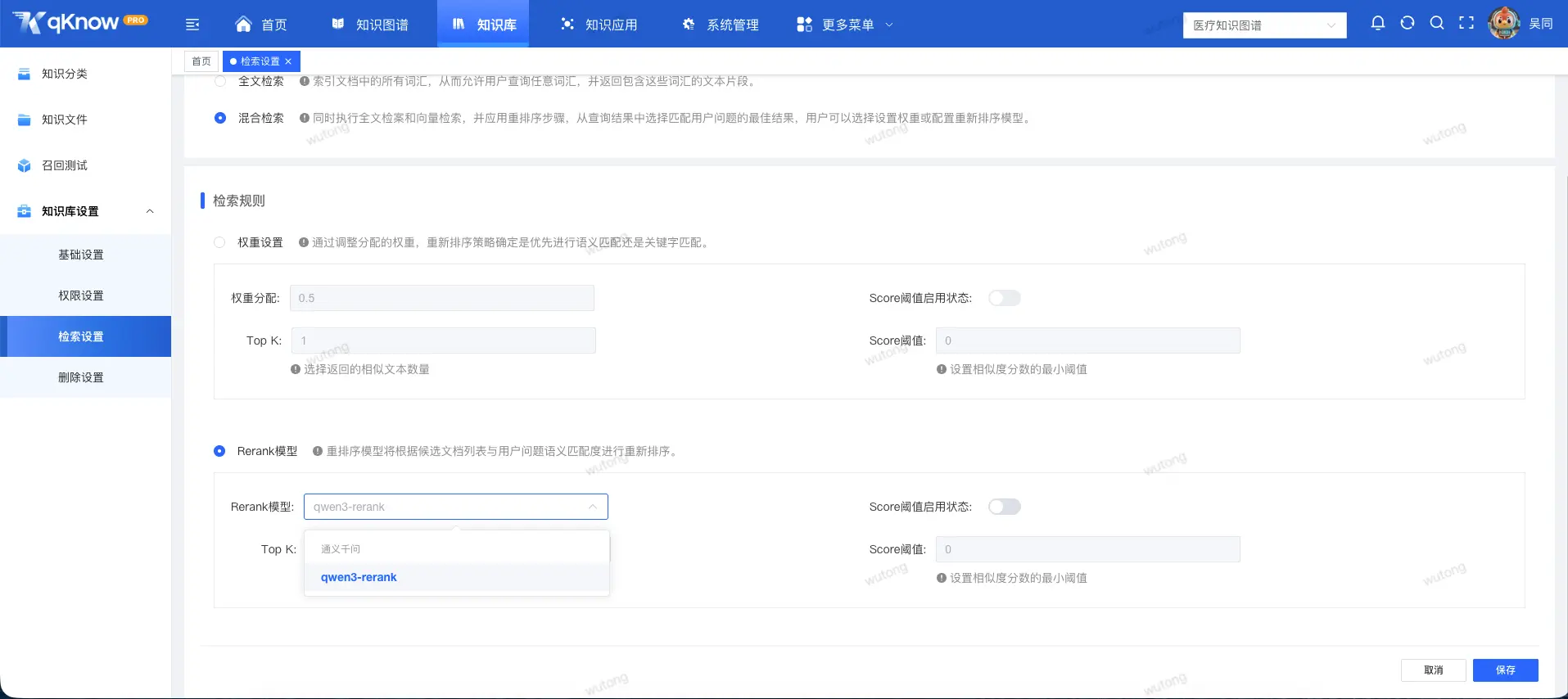
🛠 一、知识库能力全面剔除第三方框架依赖
1️⃣ 本地化向量数据库:引入 Weaviate
在 qKnow 知识平台商业版 v2.6.1 中,我们完成了向量检索能力的自主化重构:
- 本地搭建 Weaviate 向量数据库
- 文档上传后进行拆分、向量化并存储
- 查询阶段对用户问题进行向量化
- 基于语义相似度,从向量库中检索最相关内容作为参考上下文
这一改造让 qKnow 的知识库能力具备了:
- ✅ 更强的可控性
- ✅ 更好的性能可调优空间
- ✅ 更灵活的部署与扩展能力
2️⃣ 统一模型与向量接入层:引入 Spring AI Alibaba
在模型与向量数据库对接层,我们引入了 Spring AI Alibaba 作为基础框架:
- 统一对接各类大语言模型提供商
- 统一对接向量数据库能力
- 将模型调用、向量检索纳入一致的工程体系中
这意味着:
👉 模型可换、向量库可换、策略可调,但 qKnow 的核心能力不变。
3️⃣ 文档分块能力全面升级:为"可用的知识库"打基础
真正好用的知识库,从来不是"把文档丢进去就完了"。
针对大模型上下文长度限制问题,qKnow 在 v2.6.1 中对文档分块机制进行了系统化设计:
🔹 通用分块策略
- 先按指定分隔符进行语义分段
- 段落超长时,按最大长度再次切分
- 在前后块之间引入语义重叠,保证上下文连续性
🔹 QA 分块策略
- 基于通用分块结果
- 使用大模型自动生成「问题-答案」对
- 检索阶段优先匹配"问题",返回其对应答案作为参考
这种方式显著提升了:
- 检索命中率
- 语义理解准确性
- 知识问答的可解释性
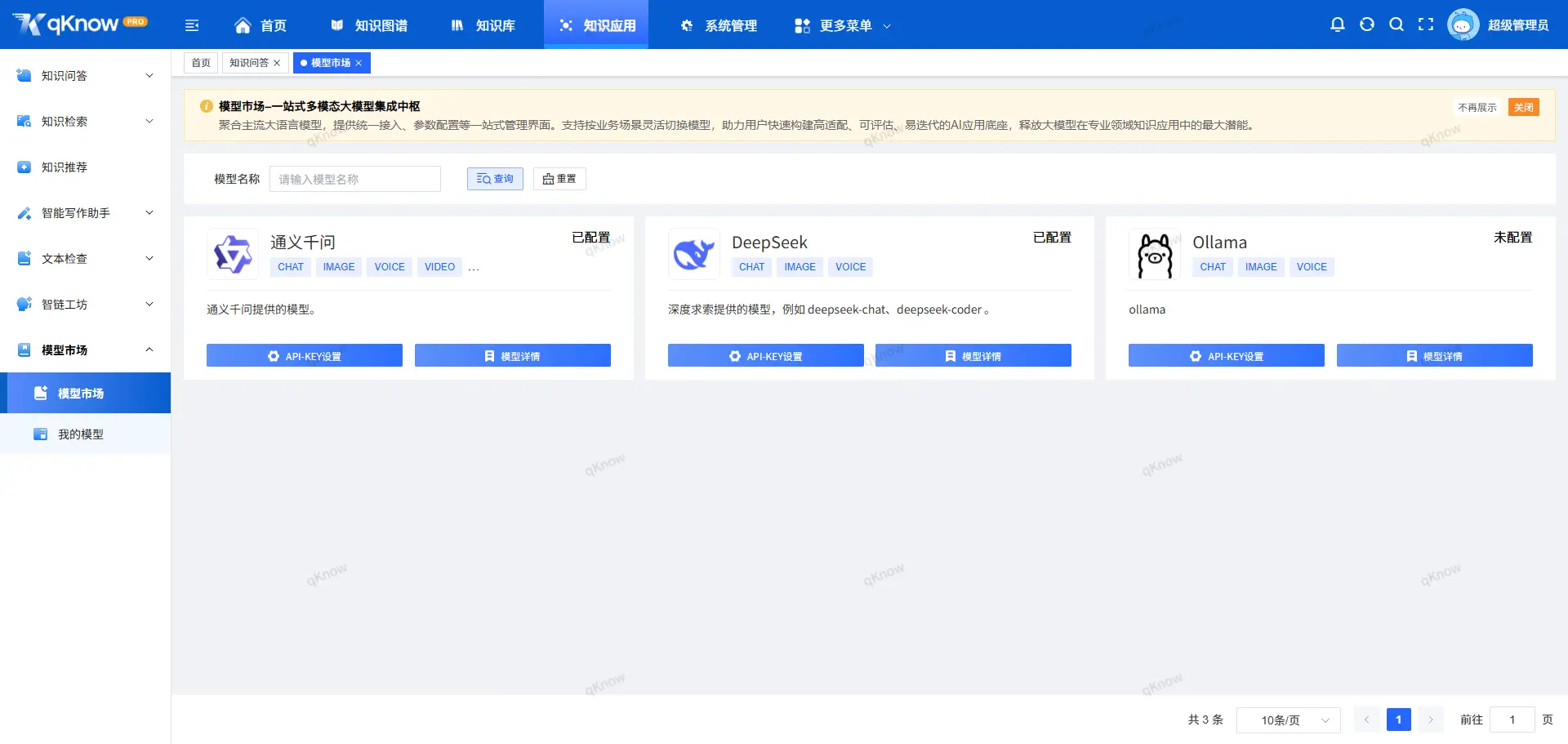
🧠 二、自主实现大语言模型深度集成
彻底告别 Dify 与第三方 LLM 应用框架
qKnow v2.6.1 中,我们全面移除了对 Dify 及其他第三方 LLM 应用开发框架的依赖,自主构建了大模型集成与编排能力。
这一步,意味着:
- 不再受限于第三方工作流设计
- 不再被固定的能力模型约束
- 真正掌握"如何用好模型"的主动权
全面重构核心 AI 能力模块
基于新的模型集成体系,qKnow 对以下核心能力模块进行了整体替换与重构:
- 知识问答
- 意图检索
- 语义检索
- 智能写作
- 三元组抽取
- 文本检查
- 知识图谱模型抽取
这些能力不再是"拼装结果",而是围绕 qKnow 自身知识体系与业务场景深度优化 的原生能力。
🏁 这是一次版本升级,更是一次战略选择
qKnow v2.6.1,并不是追逐热点的"炫技版本"。
它的意义在于:
- 🧱 打牢长期演进的技术底座
- 🔐 满足政企与行业场景对自主可控的核心要求
- 🧠 为后续更复杂的知识推理、智能体、行业模型奠定基础
从这一版本开始,qKnow 不再依赖外部框架"替我们思考",
而是真正成为一个可以持续生长的知识与智能平台。
如果你关心的是:
- 企业级知识库如何真正落地
- 大模型如何与业务深度结合
- AI 系统如何长期可控、可演进
那么,qKnow 知识平台商业版 v2.6.1,是一个值得关注的起点。
👉 欢迎体验,也欢迎交流。