作者:来自 Elastic Tinsae Erkailo Tal Borenstein 及 Shahar Glazner

Elastic 中工作流自动化的实用入门。了解工作流是什么样子、它们如何工作,以及如何构建一个。
Elastic Workflows 是内置于 Elasticsearch 平台中的自动化引擎。你使用 YAML 来定义工作流:包括是什么触发它们(启动)、它们执行哪些步骤、执行哪些动作,平台负责执行过程。一个工作流可以查询 Elasticsearch、转换数据、基于条件进行分支、调用外部 API,并通过你已经配置好的连接器与 Slack、Jira、PagerDuty 等服务集成。
在这篇博客中,我们将介绍 Workflows 的核心概念,并一起构建一个示例工作流。
Workflows 是声明式的,并使用 YAML 定义
Workflows 是可组合的。你只需要定义应该发生什么,平台会处理执行、错误恢复和日志记录。每个工作流都以 YAML 定义,并存在于 Kibana 中。
一个工作流由几个关键部分组成:触发器、输入和步骤。
触发器 决定工作流何时运行。告警触发器会在 Kibana 告警规则触发时运行,并可完全访问告警上下文。计划触发器按时间间隔或 cron 模式运行。手动触发器可以从 UI 或 API 按需运行。一个工作流可以有多个触发器。
输入 定义在运行时可以传递给工作流的参数。这让你可以创建可复用的工作流,根据不同的调用方式接受不同的值。
步骤 是工作流执行的具体动作。步骤按顺序执行,每个步骤都可以引用前一个步骤的输出。步骤类型包括:
-
内部动作:在 Elasticsearch 和 Kibana 内执行的操作,例如查询索引、运行 Elasticsearch Query Language ( ES|QL )、创建 case 或更新告警。
-
外部动作:在外部系统上执行的操作,例如发送 Slack 消息或创建 Jira 工单。你可以使用在 Elastic 中配置好的任何 connector,也可以通过 HTTP 步骤灵活调用任意 API 或内部服务。
-
流程控制:使用条件、循环和并行执行来定义工作流逻辑。
-
AI:从向大语言模型 ( LLM ) 提示,到将 agent 作为工作流步骤启用,解锁 agentic 工作流用例。
实践一下:你的第一个工作流
让我们构建一个展示核心能力的工作流:操作 Elasticsearch 索引、使用条件逻辑,以及在步骤之间传递数据。我们将创建一个简单的演示,设置一个 National Parks 索引,加载示例数据,并对其进行搜索。
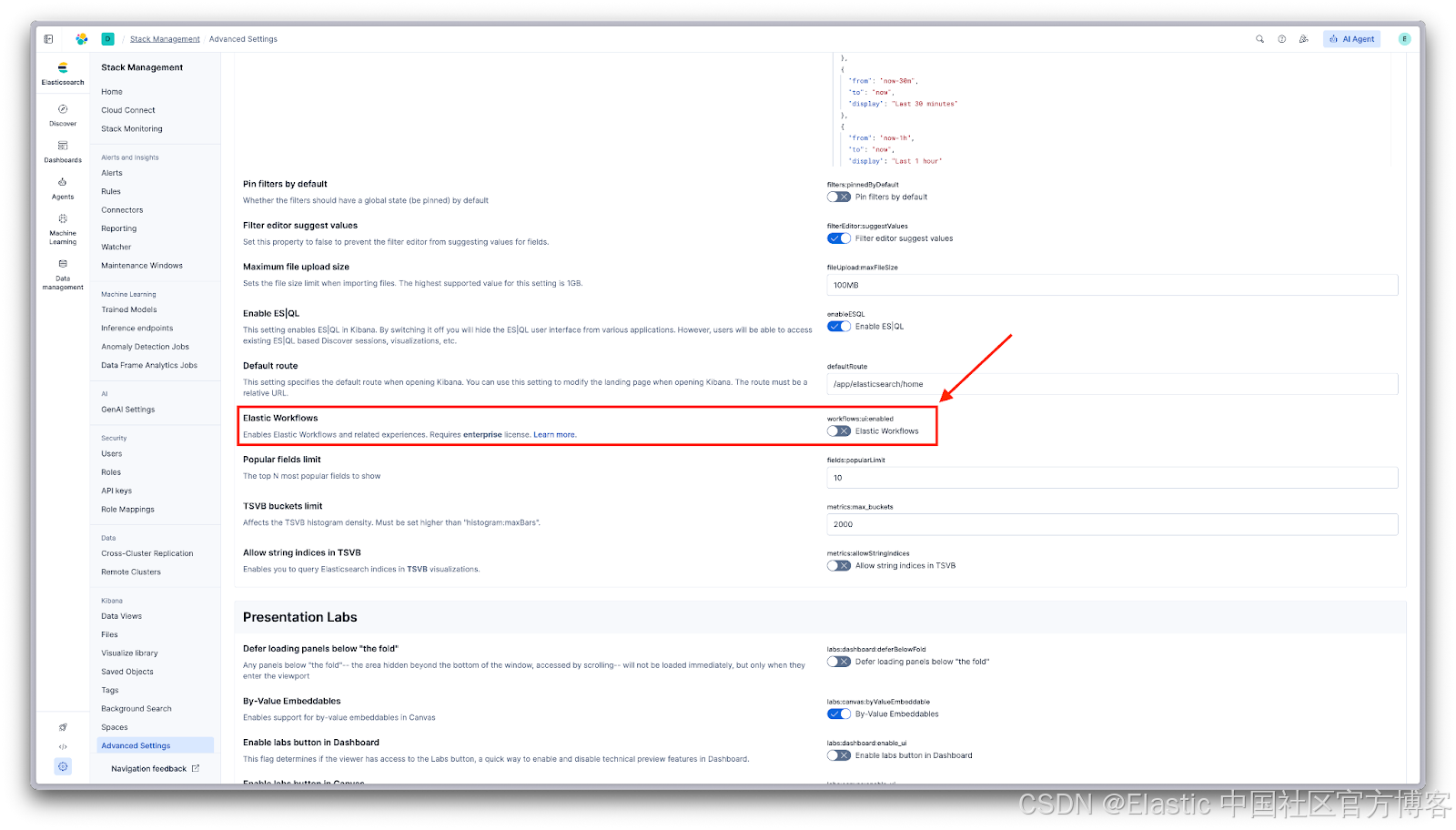
启用 Workflows
Workflows 在 Elastic 9.3 中可用( Technical Preview )。前往 Stack Management → Advanced Settings ,然后启用 Elastic Workflows。
创建一个工作流
在 Kibana 中导航到 Workflows。如果这是你第一次使用,你会看到 Get Started 界面:
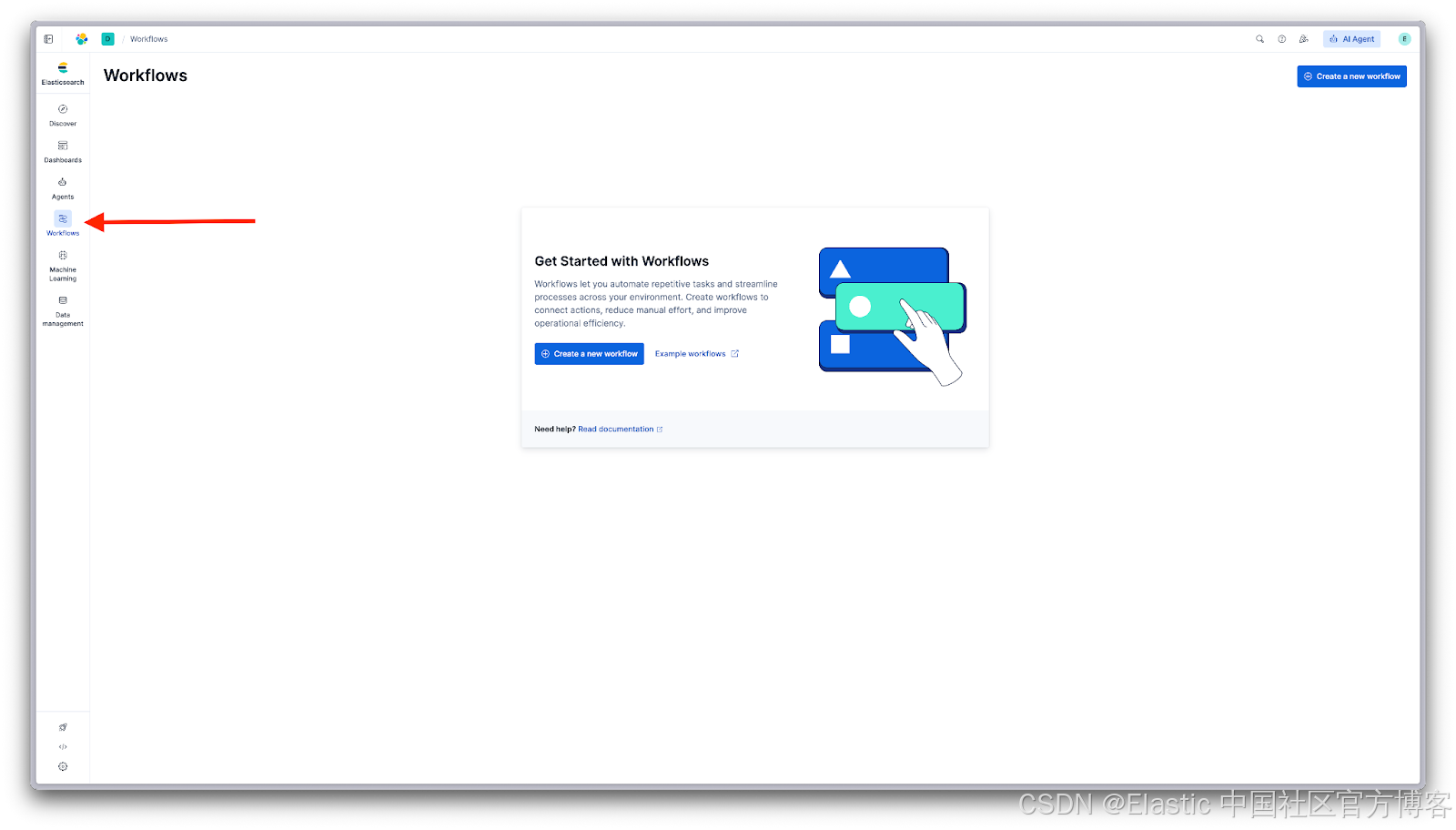
点击 Create a new workflow 打开编辑器。你也可以探索 Example workflows 来查看 Elastic Workflow Library,这是一个为 search、observability 和 security 用例准备的即用型工作流集合。
工作流编辑器
编辑器提供带有自动补全和校验的 YAML 编辑功能。开始输入一个 step 类型,就会出现建议。使用快速操作菜单( Cmd+K / Ctrl+K )按类别浏览可用的 triggers、steps 和 actions:
构建工作流
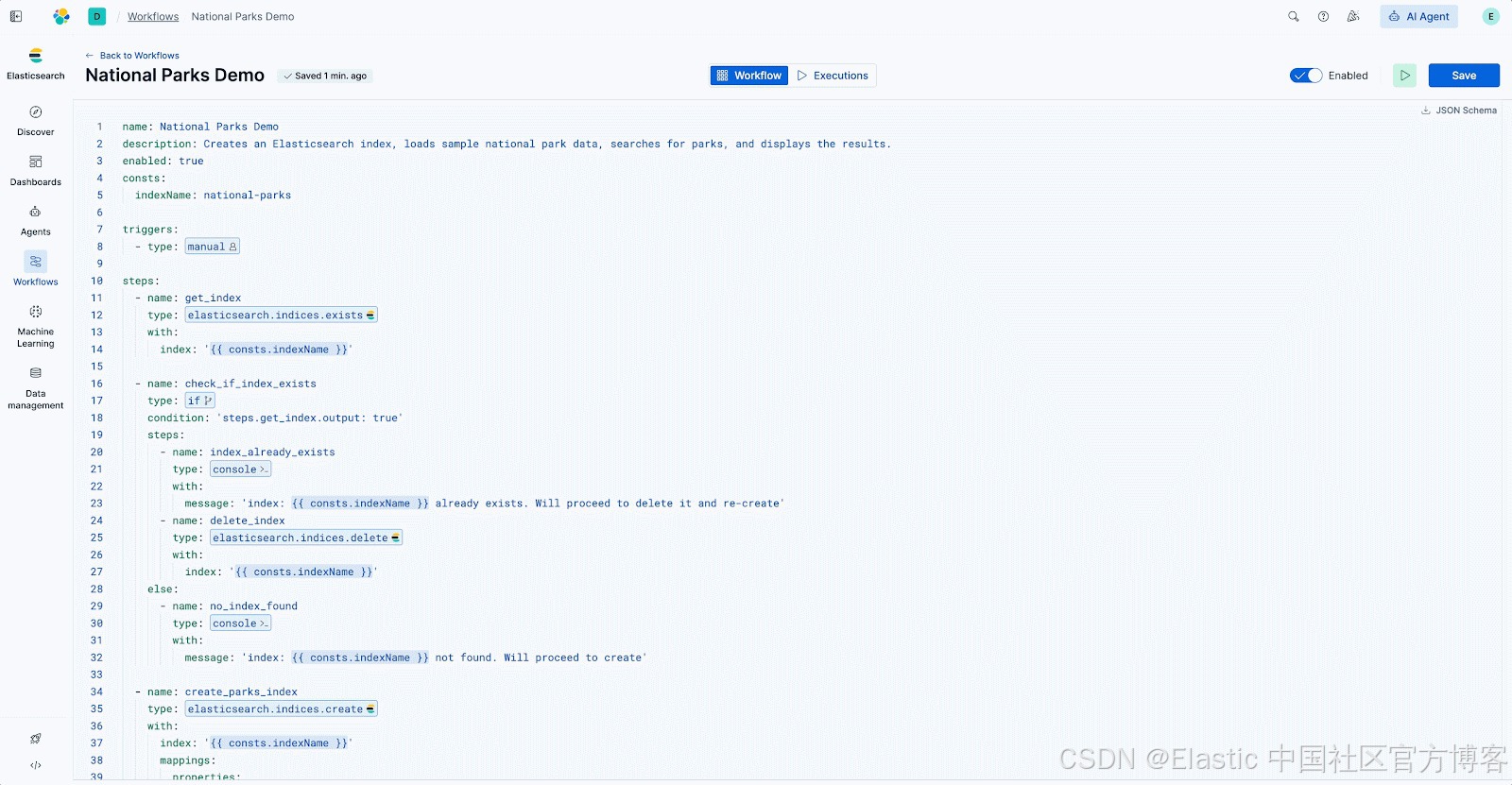
这是我们的 National Parks 演示工作流:
name: National Parks Demo
description: Creates an Elasticsearch index, loads sample national park data, searches for parks, and displays the results.
enabled: true
consts:
indexName: national-parks
triggers:
- type: manual
steps:
- name: get_index
type: elasticsearch.indices.exists
with:
index: '{{ consts.indexName }}'
- name: check_if_index_exists
type: if
condition: 'steps.get_index.output: true'
steps:
- name: index_already_exists
type: console
with:
message: 'index: {{ consts.indexName }} already exists. Will proceed to delete it and re-create'
- name: delete_index
type: elasticsearch.indices.delete
with:
index: '{{ consts.indexName }}'
else:
- name: no_index_found
type: console
with:
message: 'index: {{ consts.indexName }} not found. Will proceed to create'
- name: create_parks_index
type: elasticsearch.indices.create
with:
index: '{{ consts.indexName }}'
mappings:
properties:
name:
type: text
category:
type: keyword
description:
type: text
- name: index_park_data
type: elasticsearch.index
with:
index: '{{ consts.indexName }}'
id: yellowstone
document:
name: Yellowstone National Park
category: geothermal
description: "America's first national park, established in 1872, famous for Old Faithful geyser and diverse wildlife including grizzly bears, wolves, and herds of bison and elk."
refresh: wait_for
- name: search_park_data
type: elasticsearch.search
with:
index: '{{ consts.indexName }}'
query:
term:
_id: yellowstone
- name: log_results
type: console
with:
message: 'Found {{ steps.search_park_data.output.hits.total.value }} park with doc id of yellowstone.'此工作流演示了若干功能:
- 常量 /Constants :定义可复用的值,如
indexName,可在整个工作流中引用。 - Elasticsearch 操作:检查索引是否存在、删除索引、创建带映射的索引、索引文档和执行搜索。
- 带分支的条件逻辑:如果索引存在,记录消息并删除它;如果不存在,记录未找到的消息。无论哪种情况,都继续创建索引。
- 数据流 :每个步骤使用
steps.<name>.output引用前一步骤的输出。
注意整个工作流中使用的 {``{ }} 语法。这是 Liquid 模板,用于在步骤之间传递数据。consts 包含工作流常量,steps.<name>.output 引用前一步骤的输出。
运行工作流
保存工作流后,点击 Save 按钮旁的 Play 按钮执行它。
工作流开始执行,你会在执行视图中看到每个步骤。每个步骤在侧边面板中显示运行状态和耗时:
点击任意步骤即可查看其输入和输出。侧边面板会显示工作流在每一步接收和生成的精确数据。这让调试变得非常直观:你可以看到输入是什么,输出是什么,如果某个步骤失败,问题出在哪里。
扩展工作流
让我们用 AI 和外部通知扩展此工作流。我们将在 log_results 之后添加一个步骤,使用 LLM 生成关于公园的诗歌,然后将其发送到 Slack。
在 log_results 之后添加这些步骤:
- name: generate_poem
type: ai.prompt
with:
prompt: >
Write a short, fun poem about {{ steps.search_park_data.output.hits.hits[0]._source | json }}.
Include something about its famous features. No other formatting.
- name: share_poem
type: slack
connector-id: my-slack-connector
with:
message: |
🏔️ *Poem of the Day about Yellowstone*
{{ steps.generate_poem.output.content }}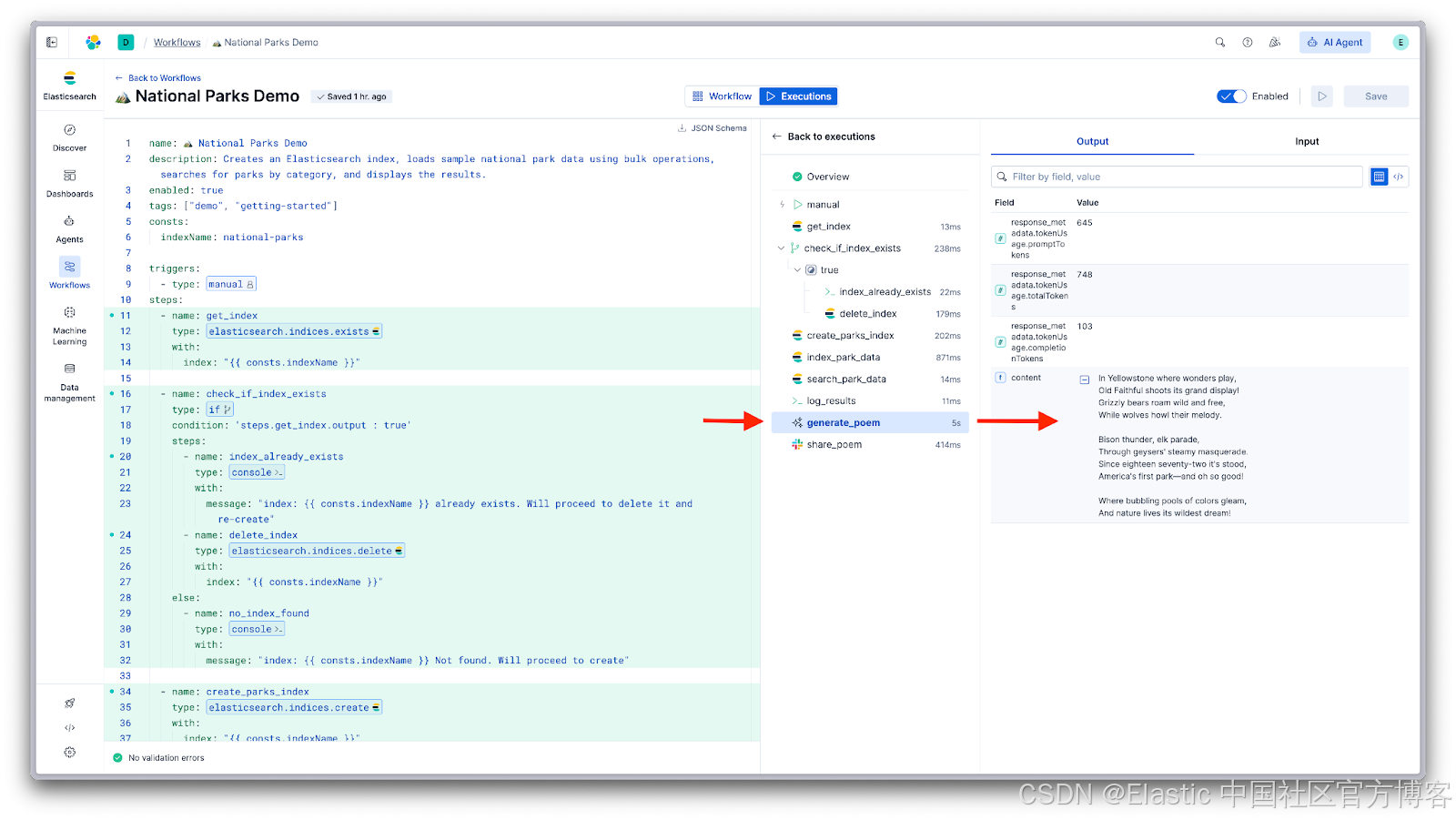
现在工作流会创建索引、加载数据、搜索数据、使用 AI 生成诗歌,并将其分享至 Slack。相同的模式贯穿始终:添加步骤、引用其输出,让工作流处理执行。
这是一个简单示例,但相同方法可扩展到真实用例。将 national parks 替换为安全警报、可观测性指标,或 Elasticsearch 中的任何数据。将诗歌替换为 AI 总结或评估。将 Slack 替换为 Jira、PagerDuty 或任何你已配置的连接器。
工作流与 Elastic Agent Builder
National Parks 示例展示了 Workflows 的核心组件:触发器、步骤、条件逻辑、数据流、AI 提示和外部通知。这些组件可组合构建自动化流程,协调 Elasticsearch、Kibana、外部系统和 AI 中的操作结果。
上述流程适用于已知步骤的场景。但对于步骤未知、正确操作取决于发现内容,而发现内容又取决于查询位置的流程呢?
这正是 Agent Builder 扩展自动化能力的地方。一个基于你操作上下文的 agent 可以执行分析师或开发者通常手动完成的初步分析或调查。它可以探索、跨数据源推理并呈现发现,然后工作流继续执行后续结构化步骤。
Workflows 可与 Agent Builder 集成,且集成支持双向操作。
将 agent 用作工作流步骤
使用 ai.agent 可在工作流中调用 agent:
- name: analyze
type: ai.agent
with:
agent_id: my-analyst-agent
message: 'Analyze this data and recommend next steps: {{ steps.search.output | json }}'agent 使用其配置的工具查询索引、关联数据,并对结果进行推理。工作流等待发现结果,然后继续执行下一步。
工作流作为 agent 工具
将工作流暴露给 Agent Builder,agent 就可以调用它来执行操作。
agent 可能会决定:"我需要创建一份报告并发送给团队。" 与其直接调用 API、承担不可预测性,不如调用一个可靠执行的工作流。
这种分离很重要。agent 擅长推理和探索,工作流擅长确定性执行。结合起来,你就拥有了既能推理又能可靠执行的 AI。
展望未来
此技术预览将 Workflows 确立为 Elasticsearch 平台的核心能力。基础已搭建完成:触发器、步骤、数据流、AI 集成以及与 Agent Builder 的双向连接。
接下来将基于此基础进行扩展。可期待更多步骤类型、扩展连接器支持以及改进的可视化创作工具。除此之外,Workflows 将整合到 Elastic 的特定解决方案体验中。
对于开发者而言,这意味着 AI 助手不再仅限于对话。agent 可以实际操作:查询系统、更新记录、触发流程并返回结果。推理由可靠执行支撑。
在可观测性领域,这意味着关联日志、指标和追踪信号,揭示可能的根因,协调修复步骤,实现从检测到解决的闭环,无需等待人工干预。
在安全领域,这意味着在警报触发的瞬间开始调查。利用内部和外部来源丰富发现结果。协调各工具的响应操作。更新案件并通知相关人员。过去需要人工完成的工作,现在可自动化处理。
你今天学到的模式可直接应用于这些场景。Workflows 是使这些自动化成为可能的核心层。
开始使用 Elastic Workflows
Elastic Workflows 现已作为技术预览提供。开始试用 Elastic Cloud 并查看文档。