⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,"虽小必牢"(虽然你犯的事很小,但你肯定会坐牢)。
自动化渗透:强化学习在内网渗透测试(DQN/PPO)中的实验
您好,我是陈涉川,欢迎来到我的专栏。第 14 篇是将"单个点的漏洞利用"(Fuzzing/Exploit)扩展到"整个网络的战略攻防"的关键一章。
在这里,AI 不再是一个盯着汇编代码的显微镜,而是一个盯着网络拓扑图的指挥官。它需要决策、规划、甚至学会"牺牲"和"欺骗"。
这是**"战争游戏(WarGames)"**的现代重制版。我们将探讨如何训练一个能够自己在内网中摸爬滚打、自我进化的数字特工。
"在代码的丛林中,没有地图,只有战争迷雾。最优秀的猎人不是最强壮的,而是最擅长在迷雾中通过微弱的回声判断猎物方位的。"
引言:从脚本小子到数字幽灵
传统的内网渗透测试(Penetration Testing)是高度依赖人工的艺术。
攻击者进入内网后,需要手动运行 Nmap 扫描网段,用 BloodHound 分析域信任关系,用 Mimikatz 抓取凭证,然后像拼图一样,一步步规划通往域控(Domain Controller)的路径。
自动化的工具(如 Nessus 或 AutoSploit)虽然存在,但它们本质上是确定性的脚本------它们只知道"如果有 A 漏洞,就执行 B 攻击"。它们不懂变通,不懂潜伏,更不懂"长远规划"。
如果我们将渗透测试视为一场即时战略游戏(RTS),传统的自动化工具就像是只会在固定时间派兵的简单 AI。而我们需要的是 AlphaStar 级别的 AI。
强化学习(Reinforcement Learning, RL)的引入,彻底改变了这个格局。
我们不再编写攻击脚本,我们编写奖励函数(Reward Function)。
我们不再告诉 AI 如何攻击,我们将它扔进一个仿真的企业内网中,告诉它:"拿到域管权限给 1000 分,被发现扣 10000 分。"
经过数百万次的死亡与重启,它将学会人类黑客都不曾想到的攻击路径。本文中我们将这一数字特工称为 Agent (智能体)或红队 AI。
第一章 数学建模:将黑客思维映射为马尔可夫决策过程
要训练 AI,首先要将现实世界抽象为数学公式。渗透测试过程完美契合 马尔可夫决策过程(MDP) ,更准确地说,是 部分可观测马尔可夫决策过程(POMDP)。
1.1 状态空间(State Space, S):战争迷雾
在围棋中,AI 可以看到整个棋盘。但在渗透测试中,攻击者(Agent)最初只知道自己所在的受损主机(Compromised Host)。整个内网拓扑是未知的。
我们将状态定义为一个动态知识图谱(Dynamic Knowledge Graph):
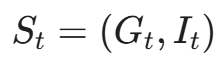
- G_t = (V, E) :当前已探索的网络拓扑图。
- V(节点):已发现的主机、服务、用户账号。
- E(边):已知的连接关系(如 CanRDP,AdminTo,HasSession)。
- I_t :Agent 自身的元数据。
- 当前拥有的权限集合(Privileges)。
- 当前拥有的凭证集合(Credentials)。
- 当前的隐蔽度(Stealth Level)。
1.2 动作空间(Action Space, A):杀伤链的原子化
动作空间定义了 Agent 能做什么。由于内网操作极其复杂,我们通常将其离散化为参数化的动作(Parameterized Actions)。
一个动作 a∈A 可以表示为元组 (type, target, tool):
- 侦察(Recon):
- ScanSubnet(target_ip): 扫描子网。
- EnumerateService(target_host): 枚举服务。
- 利用(Exploit):
- ExploitVuln(target_host, CVE-ID): 利用特定漏洞(如 MS17-010)。
- BruteForce(target_service, user_list): 暴力破解。
- 后渗透(Post-Exploitation):
- DumpCreds(host): 抓取内存凭证。
- Pivot(host): 建立跳板。
维度爆炸问题:
如果内网有 1000 台主机,每台主机有 10 个可能的漏洞,动作空间大小就是 1000 X 10 = 10000。这对于 RL 来说是巨大的挑战。我们将在后文探讨如何通过分层强化学习(HRL)来解决这个问题。
1.3 奖励函数(Reward Function, R):欲望的指引
这是塑造 Agent 行为的核心。
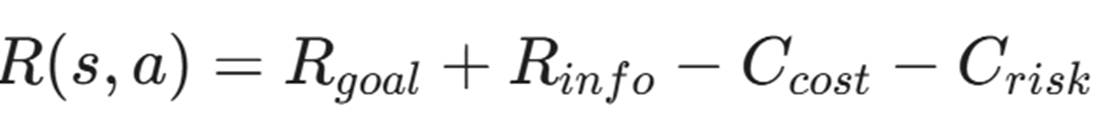
- R_{goal}(目标奖励): 拿到 Flag(如 /etc/shadow 或 ntds.dit)给予巨大奖励(+1000)。
- R_{info}(信息奖励): 发现新主机(+10)、发现新服务(+5)。这是为了鼓励探索(Exploration)。
- C_{cost}(时间成本): 每一步扣除微小分数(-1)。鼓励 Agent 寻找最短路径。
- C_{risk}(风险惩罚): 触发 IDS 报警或导致服务崩溃(-500)。鼓励 Agent 保持隐蔽(Stealth)。
第二章 虚拟靶场:构建 CyberBattleSim 仿真环境
要在真实的生产环境训练 AI 是不可能的(它会把业务搞挂)。我们需要一个高保真的仿真器。
微软开源的 CyberBattleSim 是目前该领域的标准 Gym 环境。
2.1 为什么不直接用 Docker?
虽然用 Docker 容器搭建真实靶场最逼真,但它的重置成本太高。
RL 训练需要几百万个 Episode。如果每次重启环境需要 1 分钟,训练完需要 100 年。
CyberBattleSim 是一个抽象仿真器。它不运行真实的 Linux 内核,而是维护一个状态机。它计算概率:"当你在 Windows 10 上运行 Mimikatz,且未开启 Defender 时,成功率为 90%。"
这使得训练速度可以达到每秒数千步。
2.2 构建一个自定义的企业拓扑
我们需要用 Python 定义一个典型的企业内网结构,用于训练 Agent。
python
import cyberbattle.simulation.model as model
from cyberbattle.simulation.model import CreatingNode, FirewallRule
def create_enterprise_network():
# 定义子网
internet = model.Subnet("Internet", cidr="0.0.0.0/0")
dmz = model.Subnet("DMZ", cidr="192.168.1.0/24")
office = model.Subnet("Office", cidr="192.168.2.0/24")
domain_controllers = model.Subnet("DC", cidr="192.168.10.0/24")
# 定义节点 (简化版)
# 1. 外部 Web 服务器 (入口点)
web_server = CreatingNode(
"WebServer",
services=[model.ListeningService("HTTPS", port=443, vulnerability="CVE-2023-XXXX")],
firewall_rules=[FirewallRule("Allow", port=443)]
)
# 2. 办公区员工 PC
workstation = CreatingNode(
"Workstation-01",
services=[model.ListeningService("SMB", port=445, vulnerability="SMB-Weak-Auth")],
properties={"OS": "Windows 10"}
)
# 3. 域控制器 (最终目标)
dc_server = CreatingNode(
"DC-01",
services=[model.ListeningService("LDAP", port=389)],
value=1000 # 高价值目标
)
# ... 定义连接关系 ...
# 这就是 Agent 将要面对的"迷宫"
return model.Environment(network_config=..., attacker_goal=...)在这个环境中,Agent 必须学会:
- 攻破 WebServer。
- 在 WebServer 上做信息收集,发现 Office 子网。
- 利用 Pivot 技术,通过 WebServer 攻击 Workstation-01。
- 在 Workstation-01 上抓取域管理员凭证。
- 最终登录 DC-01。
第三章 价值的计算:Deep Q-Networks (DQN) 的实战应用
环境准备好了,现在我们需要给 Agent 一个大脑。
首先尝试最经典的 Deep Q-Network (DQN)。它的核心思想是学习一个 Q 函数:

即:"在当前状态 s 下,如果我执行动作 a,未来能获得的预期总回报是多少?"
3.1 状态向量化:如何把图喂给神经网络?
传统的 DQN 处理的是像 Atari 游戏那样的图像像素。但我们的状态是一个图(Graph)。
直接将邻接矩阵展开为向量会丢失拓扑信息,且维度太高。
解决方案:图神经网络(GNN)嵌入
我们使用 GraphSAGE 或 GCN (Graph Convolutional Network) 来提取网络状态的特征。
- 节点特征编码: 每个节点(主机)由一个特征向量表示(操作系统类型、开放端口、是否已攻陷)。
- 消息传递(Message Passing):

Agent 能够感知到:"虽然这台主机本身没有漏洞,但它连接着一台有漏洞的数据库。"这种邻居信息的聚合至关重要。
- 全局池化(Global Pooling): 将所有节点特征聚合成一个固定长度的向量,代表整个网络的状态 S_t。
3.2 动作选择策略:Epsilon-Greedy 的黑客版
在训练初期,Agent 对网络一无所知。
- Exploration (\epsilon 概率): 随机乱试。可能会尝试对 Linux 服务器运行 Windows 漏洞利用,或者扫描一个不存在的 IP。这虽然笨,但能帮它发现意外的路径。
- Exploitation (1-\epsilon 概率): 选择 Q 值最高的动作。比如它学会了"只要看到 445 端口开放,就尝试 EternalBlue",因为它记得这样回报很高。
随着训练进行,\epsilon 逐渐减小,Agent 变得越来越老练,不再乱试,而是直奔要害。
3.3 DQN 算法流程代码(PyTorch 伪代码)
python
### GNN 增强版 PyTorch 伪代码
"""
注:为了处理变长的网络拓扑结构,我们不再使用简单的全连接层,
而是引入图卷积网络(GCN)来提取空间特征。
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
# 假设使用 PyTorch Geometric (PyG) 库
from torch_geometric.nn import GCNConv, global_mean_pool
class GNNBasedDQN(nn.Module):
def __init__(self, node_feature_dim, action_dim):
super(GNNBasedDQN, self).__init__()
# 1. 图神经网络层 (Feature Extractor)
# 输入:节点特征矩阵 X, 邻接关系 Edge_Index
self.conv1 = GCNConv(node_feature_dim, 64)
self.conv2 = GCNConv(64, 64)
# 2. 注意力机制 (可选,用于聚焦关键节点)
# self.attention = ...
# 3. 决策层 (Q-Head)
# 将图特征映射到具体的动作价值
self.q_head = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
def forward(self, state):
"""
state 包含:
- x: 节点特征矩阵 [Num_Nodes, Node_Features]
- edge_index: 边索引 [2, Num_Edges]
- batch: 用于区分 Batch 中不同图的索引
"""
x, edge_index, batch = state.x, state.edge_index, state.batch
# Step 1: 节点级特征提取 (Message Passing)
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
x = F.relu(x) # 此时 x 代表每个主机的 Embedding
# Step 2: 图级特征聚合 (Readout)
# 将所有节点特征平均或求和,得到整个网络的特征向量
graph_embedding = global_mean_pool(x, batch)
# Step 3: 计算 Q 值
return self.q_head(graph_embedding)
# 训练循环核心逻辑
def train_step(agent, batch_data):
# ... 前处理 ...
current_q = agent(state_batch)
target_q = reward_batch + gamma * agent(next_state_batch).max(1)[0]
loss = F.mse_loss(current_q.gather(1, action_batch), target_q.unsqueeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()第四章 稀疏奖励的诅咒:为什么 DQN 经常学不到东西?
如果你直接运行上面的代码,你会发现 Agent 经常在原地打转,或者总是试图扫描同一个子网。
这是渗透测试 RL 中最著名的问题:稀疏奖励(Sparse Reward)。
4.1 问题本质
在《超级马里奥》中,你每走一步都有金币,每杀一个怪都有分。反馈是密集的。
在《渗透测试》中,你可能执行了 50 个步骤(扫描、枚举、失败的 Exploit),奖励都是 0。直到第 51 步你成功拿到了 Root,突然给了 +1000 分。
对于 DQN 来说,由于长期的 0 反馈,它无法建立起第 1 步(扫描)和第 51 步(拿到 Root)之间的因果联系(Credit Assignment)。它会觉得前面的 50 步都是无用的废操作。
4.2 解决方案一:课程学习(Curriculum Learning)
不要一开始就让"婴儿"去打"Boss"。
- 阶段一(幼儿园): 只有一个节点,只要扫描到开放端口就给大奖励。Agent 学会了扫描。
- 阶段二(小学): 两个节点,通过漏洞利用跳到第二台机器给奖励。Agent 学会了 Exploit。
- 阶段三(中学): 引入防火墙,只有绕过防火墙给奖励。
- 阶段四(大学): 完整的企业内网。
4.3 解决方案二:事后经验回放(Hindsight Experience Replay, HER)
这是一个极其聪明的技巧。
假设 Agent 的目标是 攻陷 Host-A。它尝试了一顿操作,结果失败了,最后误打误撞攻陷了 Host-B。
在标准的 RL 中,这是失败(Reward=0)。
但是在 HER 中,我们会欺骗 Agent:"嘿,其实你一开始的目标就是 Host-B!你看,你成功了!"
我们将这次"失败的尝试"标记为"成功的经验"存入记忆库。
这对渗透测试极其有效: 攻击者往往不知道哪个漏洞能打通。一次失败的尝试(例如发现目标 patched)本身就是一种有效的信息收集。HER 能够充分利用这些"失败"的数据。
第五章 动作空间的优化:分层强化学习(HRL)
面对成千上万个可能的动作,DQN 的输出层会变得极其庞大且难以收敛。人类黑客不是这样思考的。
人类黑客的思维是分层的:
- 高层策略(High-Level Policy): "这台机器搞不定,我应该去搞它的邻居。"(决定目标)
- 底层策略(Low-Level Policy): "要搞它的邻居,我要用 Nmap 扫端口,然后用 Metasploit 打 MS08-067。"(决定具体操作)
5.1 选项框架(The Options Framework)
我们设计两个 Agent:
- Master Agent (Meta-Controller):
- Input: 全局图状态。
- Action: 选择一个子目标(Sub-goal),例如 Target=192.168.1.5。
- Reward: 子目标是否被攻陷。
- Sub-Agent (Controller):
- Input: 局部状态 + Master 指定的目标。
- Action: 具体的原子动作(Scan, Exploit, CredDump)。
- Reward: 是否完成 Master 的指令。
这种分层结构极大地缩小了搜索空间。Master Agent 只需要关注战略布局,而 Sub-Agent 只需要关注战术执行。这与军事指挥链如出一辙。
至此,我们已经构建了一个能够在虚拟靶场中进行简单横向移动的 AI Agent。 我们解决了如何用数学描述黑客攻击(POMDP),如何将网络拓扑喂给神经网络(GNN),以及如何让 AI 在极度挫败的尝试中通过"自我欺骗"(HER)来学习。
但是,DQN 有一个致命弱点:它是确定性的,且在处理连续动作空间或极度复杂的策略时表现不佳。而且,我们现在的环境是静态的------没有蓝队(防御者)。 一个不会还手的靶子,练不出真正的狙击手。
如果不去挑战比自己更强的对手,剑锋就会生锈。对于 AI 而言,最强的对手不是系统管理员,而是另一个为了守护而生的 AI。
举个例子: Master Agent 就像指挥官,它下令:"拿下那台文件服务器!"(只关心结果)。而 Sub-Agent 就像特种兵,它思考:"我应该先用 nmap 扫一下,如果不通就换个端口,再不行就尝试钓鱼..."(关心具体过程)。Master 不关心特种兵开了几枪,只关心阵地有没有拿下来。
5.2 战术与战略的解耦:指挥官与特种兵
为了更好地理解 HRL,让我们看一个具体的实战场景:从 Web 区突破到数据区。
在这个场景中,Master Agent(指挥官)和 Sub-Agent(特种兵)是这样协同工作的:
- 宏观决策(Master View):
- 现状: Master 看到当前我们控制了 WebServer-01,且发现内网有一台 DB-Server(IP: 10.0.1.50)。
- 指令: Master 不关心具体怎么打,它只向 Sub-Agent 下达一个高层指令:"Goal: Compromise 10.0.1.50"。
- 挂起: Master 进入等待状态,每一步消耗微小的时间成本。
- 微观执行(Sub-Agent View):
- Sub-Agent 接收到目标 10.0.1.50。它开始在一个受限的动作空间内尝试:
- Step 1: 运行 Nmap 扫描端口 -> 发现 1433 (MSSQL)。
- Step 2: 尝试 Exploit_EternalBlue -> 失败(目标已打补丁)。
- Step 3: 切换策略,尝试 BruteForce_MSSQL 使用之前在 WebServer 抓到的弱口令字典。
- Step 4: 成功! 获得 Shell。
- Sub-Agent 向 Master 发送信号:"Mission Complete"。
- Sub-Agent 接收到目标 10.0.1.50。它开始在一个受限的动作空间内尝试:
- 奖励分配:
- Master 获得奖励: 因为离域控更近了一步,获得战略奖励(+100)。
- Sub-Agent 获得奖励: 因为完成了 Master 的指令,获得执行奖励(+50)。
通过这种解耦,Master Agent 可以在 100 步内规划完整个攻击路径,而不需要在 10000 步的扫描与爆破细节中迷失方向。
第六章 策略的进化:从 DQN 到 PPO (Proximal Policy Optimization)
在上一章中,我们使用了 DQN(深度 Q 网络)。DQN 是基于**价值(Value-Based)**的方法,它试图计算每一个动作的"价值"。但在渗透测试这种高度复杂的环境中,DQN 经常表现出极大的不稳定性。
比如,Agent 可能会突然忘记之前学会的"先扫描后攻击"的策略,转而开始疯狂地撞墙。这是因为 DQN 对超参数极其敏感,且属于 Off-Policy(异策略)学习,容易在训练数据分布发生变化时(例如 Agent 突然进入了一个新的子网)导致训练崩溃。
为了解决这个问题,我们需要引入 OpenAI 提出的 PPO(近端策略优化)。这是目前强化学习领域的"默认王者"。
6.1 策略梯度(Policy Gradient)的直觉
与 DQN 试图计算"这一步值多少分"不同,PPO 是基于策略(Policy-Based)的方法。它直接学习一个策略函数 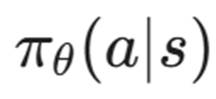 ,即:"在状态 s 下,我有多大概率执行动作 a?"
,即:"在状态 s 下,我有多大概率执行动作 a?"
这更符合人类黑客的直觉:
- 面对 Windows 7,我有 80% 的概率尝试 MS17-010。
- 面对开放的 22 端口,我有 60% 的概率尝试弱口令爆破,40% 的概率尝试 SSH 密钥复用。
6.2 PPO 的核心:信任区域(Trust Region)
PPO 的核心创新在于它限制了策略更新的幅度。
在渗透测试训练中,Agent 可能会偶尔发现一个"捷径"(例如某个特定环境下的 Bug),如果它根据这个捷径大幅修改自己的策略,它就会**"灾难性遗忘(Catastrophic Forgetting)**"通用的攻击技巧。
PPO 引入了一个剪切目标函数(Clipped Surrogate Objective),通过 clip 操作强制限制更新幅度::
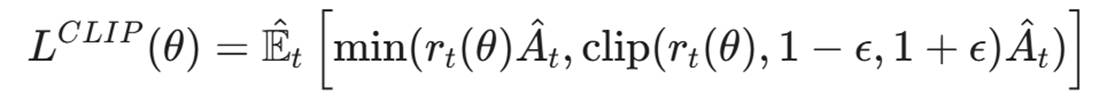
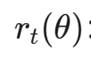 :新策略与旧策略的比率
:新策略与旧策略的比率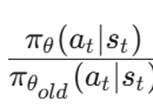 。
。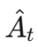 :优势函数(Advantage Function),表示当前动作比平均情况好多少。
:优势函数(Advantage Function),表示当前动作比平均情况好多少。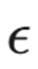 :一个超参数(例如 0.2)。
:一个超参数(例如 0.2)。
这一公式的含义是:当新策略带来的改变(r_t)超过了规定范围(例如(0.8, 1.2))时,多出来的收益将不被计入 。这就像给 AI 上了一个保险:
即使 Agent 发现了一次"偶然的成功"(例如撞上了随机打开的 3389 端口),它也只能微调(Incremental Update)自己的策略,而不能彻底推翻之前学到的"稳健侦察"的策略。这保证了在面对复杂多变的内网环境时,渗透测试 Agent 的策略是平滑且可泛化(Robust Generalization)的。
6.3 实现细节:Actor-Critic 架构
为了在渗透测试中结合 Value-Based 和 Policy-Based 的优点,我们采用 Actor-Critic 架构:
- Actor(行动者): 输出一个概率分布,例如 Scan: 0.2, Exploit: 0.7, DumpCreds: 0.1。
- Critic(批评者): 输出一个单一的数值(Value),即"当前状态 s 到底有多危险/有多好"。
Actor 的更新依赖于 Critic 的反馈:
- 如果 Actor 选了一个动作,结果 Critic 发现这个状态变得更差了(例如被 IDS 发现了),Critic 会给 Actor 一个负的 Advantage,告诉它:"下次别这么干了。"
第七章 战争迷雾:图神经网络(GNN)的深入整合
在上一章我们提到了"图神经网络(Graph Neural Network, GNN)"。这里我们深入探讨如何让 AI " 看懂" 内网拓扑。
7.1 节点嵌入(Node Embedding):数字化的指纹
内网中的每一台主机,都有无数的属性。我们需要将这些属性转化为神经网络能够理解的向量。
- Host OS Type: Windows Server 2016 → 0, 0, 1, 0, ... (One-hot Encoding).
- Open Ports: 21, 22, 80, 445 → 1, 1, 0, 1, ... (Multi-hot Encoding).
- Known Vulnerabilities: CVE-2017-0144 → 0, 1, 0, ... (Embedding Layer).
- Privilege Level: User / Admin / SYSTEM → Scaled value 0.3, 0.7, 1.0.
我们将所有特征拼接(Concatenate)起来,得到一个高维向量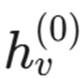 ,代表节点 v 的初始状态。
,代表节点 v 的初始状态。
7.2 边嵌入(Edge Embedding):关系的本质
主机之间的连接同样重要。
- CanRDP: 主机 A 可以 RDP 到主机 B。
- AdminTo: 用户 A 是主机 B 的管理员。
- HasSession: 用户 A 在主机 B 上有活动会话。
我们需要用一个额外的向量 e_{uv} 来表示这些关系。这就构成了一个异构图(Heterogeneous Graph)。
7.3 注意力机制(Graph Attention Network, GAT)
在庞大的内网中,并不是所有节点都重要。
如果 Agent 当前在 DMZ 区的一台 Web Server 上,它应该重点关注"能够通往内网数据库"的那条连接,而不是去关注那个通往打印机的连接。
我们引入 Attention Mechanism:
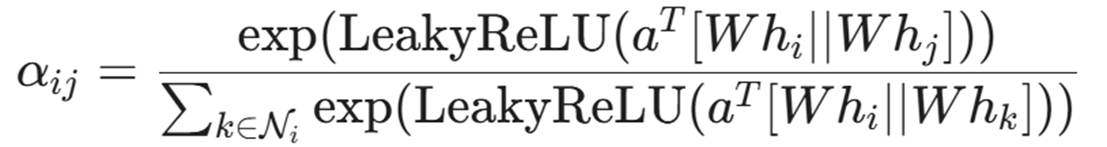
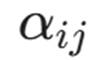 就是 Agent 对邻居 j 的**"关注度"**。
就是 Agent 对邻居 j 的**"关注度"**。
通过训练,AI 会学会给那些通往域控(Domain Controller)的关键跳板赋予更高的权重,从而在数千个节点中迅速锁定攻击路径。
第八章 红蓝对抗:多智能体强化学习(MARL)与零和博弈
如果只是让红队 AI 去打一个静态的靶场,它很快就会过拟合(Overfitting)。它会背下来所有漏洞的位置,而不是学会如何寻找漏洞。
我们需要引入一个对手:AI 蓝队(Defender Agent)。
8.1 蓝队动作空间(Defender Action Space)
蓝队 Agent 的目标是守护网络,它的动作包括:
- Patching: 修复特定主机的特定 CVE(有成本,可能导致服务中断)。
- Isolating: 切断某台主机的网络连接(如果怀疑被黑)。
- ResetCreds: 强制重置域管理员密码。
- Deception: 部署蜜罐(Honeypot)或蜜标(Honeytoken)。
8.2 博弈论建模:从纳什均衡到协同进化
我们将渗透测试建模为一个零和博弈(Zero-Sum Game)。
红队的收益 = 蓝队的损失。
但在实际训练中,如果蓝队太强(一开始就全网封锁),红队就学不到东西;如果蓝队太弱,红队就只会用脚本小子战术。
我们需要设计一个课程学习(Curriculum Learning)机制:
- Phase 1 (Easy): 蓝队只会被动打补丁(每 10 步修复一个漏洞)。红队学会基本的 Exploit。
- Phase 2 (Medium): 蓝队引入规则引擎(基于 Snort/Suricata 规则进行封锁)。红队学会绕过 WAF 和 IDS。
- Phase 3 (Hard): 蓝队变成一个 PPO Agent,它会根据网络流量异常主动切断连接。红队必须学会"Low and Slow"(低频慢速)攻击,模拟 APT 行为。
8.3 结果分析:涌现的战术
在数百万个 Episode 的对抗演练后,我们观察到了令人惊讶的现象:
- 红队学会了"声东击西": 它会故意扫描一个无关紧要的子网来吸引蓝队的注意力(触发报警),然后悄悄从另一个方向渗透。
- 蓝队学会了"诱敌深入": 它故意留下一个看似有漏洞的 Web Server(其实是蜜罐),并在红队拿下 Shell 后监控其行为,收集攻击特征。
这就是**多智能体强化学习(MARL)**的魅力:不需要人类教它们兵法,它们自己在博弈中重新发现了《孙子兵法》。
第九章 跨越鸿沟:Sim-to-Real (仿真到现实) 的挑战
这是所有 RL 项目面临的最大难题。在 CyberBattleSim 里练出来的"神",扔进真实的 Windows 域环境里,可能连 dir 命令都输不对。
9.1 域随机化(Domain Randomization)
既然我们无法完美模拟现实,那就让仿真环境变得极其混乱。
我们在训练时随机改变环境参数:
- 网络延迟在 10ms 到 500ms 之间波动。
- 某些 Exploit 的成功率在 30% 到 90% 之间波动。
- 随机丢包、随机断连。
如果 Agent 能在这种地狱难度的随机环境中生存下来,它在现实中就会非常稳健(Robust)。它学会了:"只要 Shell 没弹回来,我就多试几次,或者换个 Payload。"
9.2 动作抽象化:Atomic Red Team (TTPs)
我们不让 Agent 直接输出命令行字符串(如 nmap -sS -p 445 192.168.1.5),因为命令行的参数组合是无限的。
我们将动作抽象为 TTPs (Tactics, Techniques, and Procedures),对应 MITRE ATT&CK 矩阵。
- RL Output: Execute T1046 (Network Service Scanning)
- Executor (中间件): 这是一个脚本层,它接收到指令后,根据当前环境自动调用 nmap 或 masscan,并处理输出结果,将标准化的结果(JSON)返回给 Agent。
这样,Agent 只需要学习战略层面的决策(什么时间用什么 TTP),而具体的战术执行交给传统的脚本来做。这是目前工业界最可行的 Sim-to-Real 方案。
9.3 反馈闭环:C2 也就是 AI 的眼睛
在仿真中,获取结果是瞬时的。但在现实中,我们必须依赖 C2 (Command & Control) 架构(如 Cobalt Strike 或 Slyver)。
- Action: Agent 指令下发给 C2 Server。
- Execution: C2 Server 也就是"中控",控制受害机上的 Implant 执行命令。
- Observation: Implant 将执行结果(如"密码哈希")回传给 C2,C2 再解析为 JSON 格式喂回给 RL Agent。 没有这个异步的反馈回路,Sim-to-Real 就是空谈。
这使得 AI 不再是实验室里的花瓶,而是能通过 C2 管道遥控僵尸网络的幕后主脑。
9.4 人机协同(Human-in-the-Loop RL)
在部署初期,我们不让 AI 全自动攻击。
AI 输出一个 Top-3 Action List,由人类渗透测试专家选择执行哪一个。
- 人类的选择被记录下来,作为专家示范(Expert Demonstration)。
- 通过模仿学习(Imitation Learning),AI 会逐渐向人类专家的风格靠拢,修正它那些愚蠢的决策。
第十章 可解释性:打开黑盒的 XRL (Explainable RL)
作为一名 CISO,你不敢部署一个你看不懂的 AI。
当 AI 决定攻击打印机时,你必须知道为什么。
10.1 显著性图(Saliency Maps)
对于 GNN,我们可以计算梯度显著性。
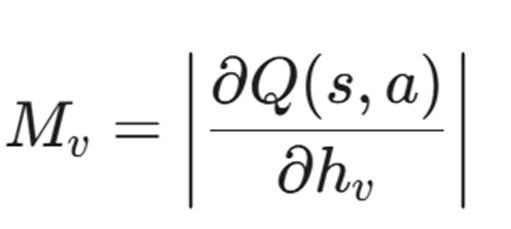
这告诉我们:在当前决策中,哪些节点对 AI 的判断影响最大。
我们在界面上高亮显示这些节点。你会看到,AI 之所以攻击打印机(Node A),是因为它通过图结构发现打印机连接着域管理员的 PC(Node B),且存在一条 PrintSpooler 的信任路径。
10.2 决策树提取(Decision Tree Extraction)
我们可以用一颗决策树来拟合训练好的 PPO 策略网络。虽然会损失精度,但能提取出人类可读的规则:
- IF (SMB_Open AND Not_Patched) THEN Exploit_EternalBlue
- ELSE IF (Has_User_Creds) THEN RDP_Login
- ELSE Scan_Subnet
这让安全团队可以审查 AI 的逻辑是否符合合规要求(RoE)。
结语:自动化的终局与新的起点
至此,我们完成了对自动化渗透测试的深度探索。
从马尔可夫决策过程的建模,到 GNN 对网络拓扑的感知,再到 PPO 和 MARL 在对抗中的进化,最后通过 Sim-to-Real 走向实战。
我们看到的不仅仅是一个工具的升级,而是网络安全范式的转移。
未来的渗透测试,将不再是按人天计费的服务,而是按算力计费的持续对抗。
企业将不再每半年做一次渗透测试,而是部署一个 24/7 运行的红队 AI,时刻在内网中寻找裂缝;同时也部署一个蓝队 AI,时刻在修补裂缝。
人类安全专家将从繁琐的扫描和测试中解放出来,去思考更高维度的战略,去设计更完善的博弈规则。
陈涉川
2026年01月30日