目录
1、哈希表简介
空间消耗为O(n) 二分是logn的时间复杂度
1)是什么? 存储数据的容器
2)有什么用?快速查找某个元素---O(1)
3)什么时候用哈希表?
当频繁查找某一个数的时候,此时就要想到用哈希表这个容器
4)怎么用哈希表
直接使用语言提供的哈希表容器。
用数组模拟简易哈希表:1)当我们只关心字符串中的字符的时候 2)当数据范围很小的时候(int) (能用数组模拟哈希表就用)
2、1.两数之和

解法一:暴力解法:
1)先固定其中一个数 2)依次与该数之前的数相加
解法二:使用哈希表对暴力解法做优化

当指针指向11的时候,我们要去前面找,前面用指针全遍历一遍看看加起来是不是等于t,那么如果我们将前面的数都放进哈希表呢? 这样只需要在哈希表中找有没有t-cur的值 就好了
我们将指针移动之前先把这个位置的数放进哈希表中,移动之后,想去前面找,就是去hash表中找。不会出现重复的。
时间复杂度是on空间复杂度也是on
【补充】:
之前的暴力枚举是先固定一个数,往后面找,这样的话就需要先把后面的数全放到哈希表中,如果说当指针移动到4这个数时,t等于8,我们要去hash表中找4,就会找到自己,所以这种解法是要判断很多特殊情况的。
cpp
class Solution
{
public:
vector<int> twoSum(vector<int>& nums, int target)
{
unordered_map<int,int>hash;
for(int i = 0; i < nums.size(); i++)
{
int x = target - nums[i];//要去hash表里面找这个数
if(hash.count(x)) return {hash[x], i}; //hash[x]是要找的数的下标 i是我的下标
hash[nums[i]] = i; //把这个数放进hash中
}
return {-1, -1};
}
};3、面试题01.02.判断是否互为字符重拍

一般面试/笔试的时候,我们开始并不知道要用什么方法来解决,我们需要通过一步一步优化的出来。
方法一:模拟:把abc的所有全排列,找出来和s2进行比较,如果比较有,就说明可以。但是时间复杂度是指数级别的。
方法二:如果s1和s2中字符出现的个数是相等的,就说明可以。我们需要统计s1中每个字符出现的个数,和s2中每个字符出现的个数。那么统计字符个数就可以用到哈希表。
hash1用来统计s1中每个字符出现的个数 hash2用来统计s2中每个字符出现的个数。
如果使用容器哈希表的话hash1<char, int> hash2<char, int> 用指针遍历到第一个字符时,分别去hash1和hsah2中找int值,看两个int值是否相等,但是比较的时候很繁琐。
我们使用数组模拟哈希表。 数组大小为26,每一位的值对应这个字符串的个数,我们进行比较的时候只需要判断两个哈希数组是否相等即可。 0-->a 1 -->b .....
优化:只使用一个哈希表(一个哈希数组)。 仅使用一个大小为26的数组来统计s1中字符出现的个数。然后用指针去遍历s2,只要在哈希表中出现的就给这个字符的个数减一,如果说到最后全为0,就代表个数相同。 当减到最后发现为负数的时候就代表有新的字符或者是多余的字符,我们就跳出循环返回false。判断之前先比较一下两个字符串是否相等,不相等就不用进行后面的操作了。
cpp
class Solution
{
public:
bool CheckPermutation(string s1, string s2)
{
if(s1.size() != s2.size()) return false;
int hash[26] = {0};//建一个哈希数组
//统计第一个字符串的信息
for(auto ch : s1)
{
hash[ch - 'a']++;//我们要将a映射到下标为0
}
//扫面第二个字符串是否能重排
for(auto ch : s2)
{
hash[ch - 'a']--;//遍历到一个字符的时候 先给hash表中的字符个数--
if(hash[ch - 'a'] < 0) return false; //减完之后如果个数小于0 就返回
}
return true;
}
};4、217.存在重复元素
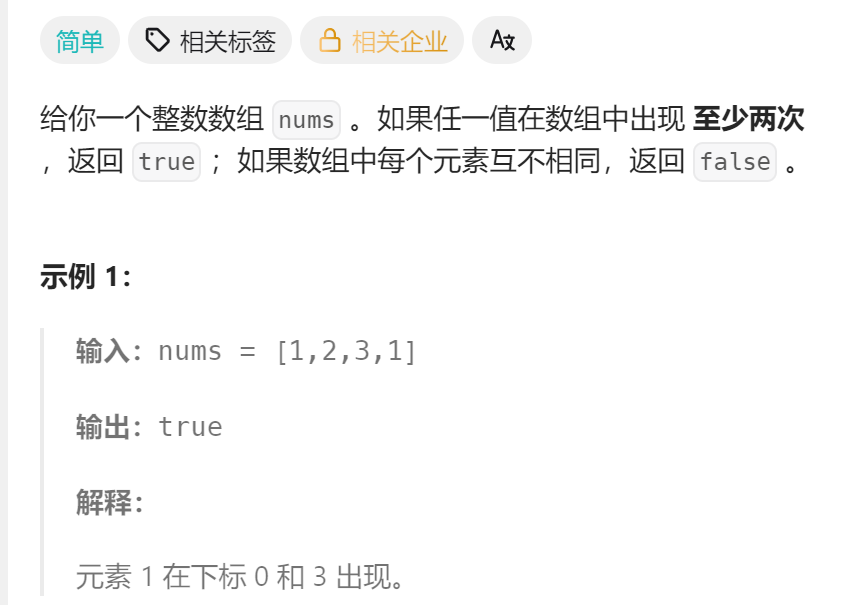
哈希表:从第一个元素开始往后遍历,每个元素都去哈希表里面看看有有没有,有就返回true,没有就房间hash表中。
cpp
class Solution
{
public:
bool containsDuplicate(vector<int>& nums)
{
unordered_set<int> hash;//创建一个哈希表
for(auto x : nums)
{
if(hash.count(x)) return true; //如果有就返回
else hash.insert(x); //没有就插入哈希表中
}
return false;
}
};5、219.存在重复元素Ⅱ
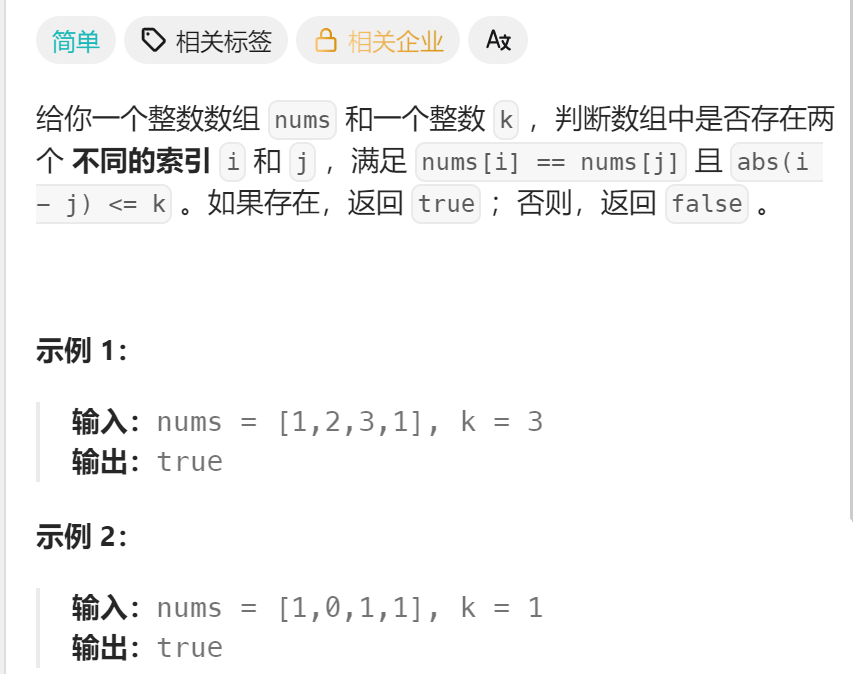
差的绝对值小于等于k
我们使用指针从前到后遍历,并创建一个哈希表,存元素和他对应的下标。 我们用这个数和哈希表中的元素进行比较,如果哈希表中没有就把这个数放进去,如果有这个数就找出他的下标,因为指针也可以定位下标,求出下标的差值是否小于等于k,满足就返回。不满足就继续往后找,如果面出现了相同的元素需要放进去,就会出现覆盖原先元素下标的情况,这种情况有影响吗?答案是没有。因为是找差值的绝对值,肯定是越小越好,前面的不满足,后面的满足了就好,不影响。
cpp
class Solution
{
public:
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_map<int,int> hash;
for(int i = 0; i < nums.size(); i++)
{
if(hash.count(nums[i])) //如果nums[i]在hash表中存在
{
if(i - hash[nums[i]] <= k) return true;
}
hash[nums[i]] = i;
}
return false;
}
};6、49.字母异位词分组

首先判断是不是字母异位词,然后再放到一起之后输出。
1)判断两个字符是不是字母异位词 排序方法
2)如何对异位词进行分组:创建一个哈希表<string,string\[\]> 字符串,如果有一个字符串哈希表中没有,就把这个字符串放进key值,再放进value值。如果后面再碰到这个字符串的异位词,就放到他的value里面,value是一个字符串数组。这样的话,当我们遍历完hash表里面的value就是我们最终要的结果。最后我们遍历一遍哈希表,把value提取出来就是我们想要的结果。
cpp
class Solution
{
public:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string, vector<string>> hash;
//1、把所有的字母异位词进行分组
for(auto& s : strs)
{
string tmp = s;//为什么要来一个tmp变量, 因为key是tmp(排序过的,要一样的);key是原数组的字符串
sort(tmp.begin(), tmp.end());
hash[tmp].push_back(s);//放入哈希表的键是排序后的字符串
}
//2、把结果提取出来
vector<vector<string>> ret;
for(auto& [x, y] : hash) //这样是把hash表中的key放到x value放到y
{
ret.push_back(y);
}
return ret;
}
};补充:hashtmp.push_back(s)和hashtmp = x都是给哈希表中存数据,有什么区别?
用不同的方法对哈希表进行存数据,是因为hash表的value值的类型不同。
用第一个前提是哈希表的value必须是可以插入类型。比如vector<>、list、deque.这样的作用是将相同的key值得元素追加到同一个容器得value中,实现一键多值得映射。 不会覆盖原始数据。
第二个方法:对普通类型得value进行赋值或者进行覆盖
如果tmp值不存在,就把tmp放入哈希表,再value进行赋值x
如果tmp已经存在,就把value值进行覆盖