引言
时隔几个月,DeepSeek 又发布了 DeepSeek-OCR-2,与 v1 一样极具创新,在端到到的文档解析 VLM 中达到了 SOTA 的效果,并且极其高效,最多只需要 1120 个视觉 token,在这样的高效的输入下能达到最好的效果,确实不容易。那么,本文就趁这个机会把 v1 和 v2 放一起简单聊聊两者的一些架构、创新点等等。
v1:上下文光学压缩
架构
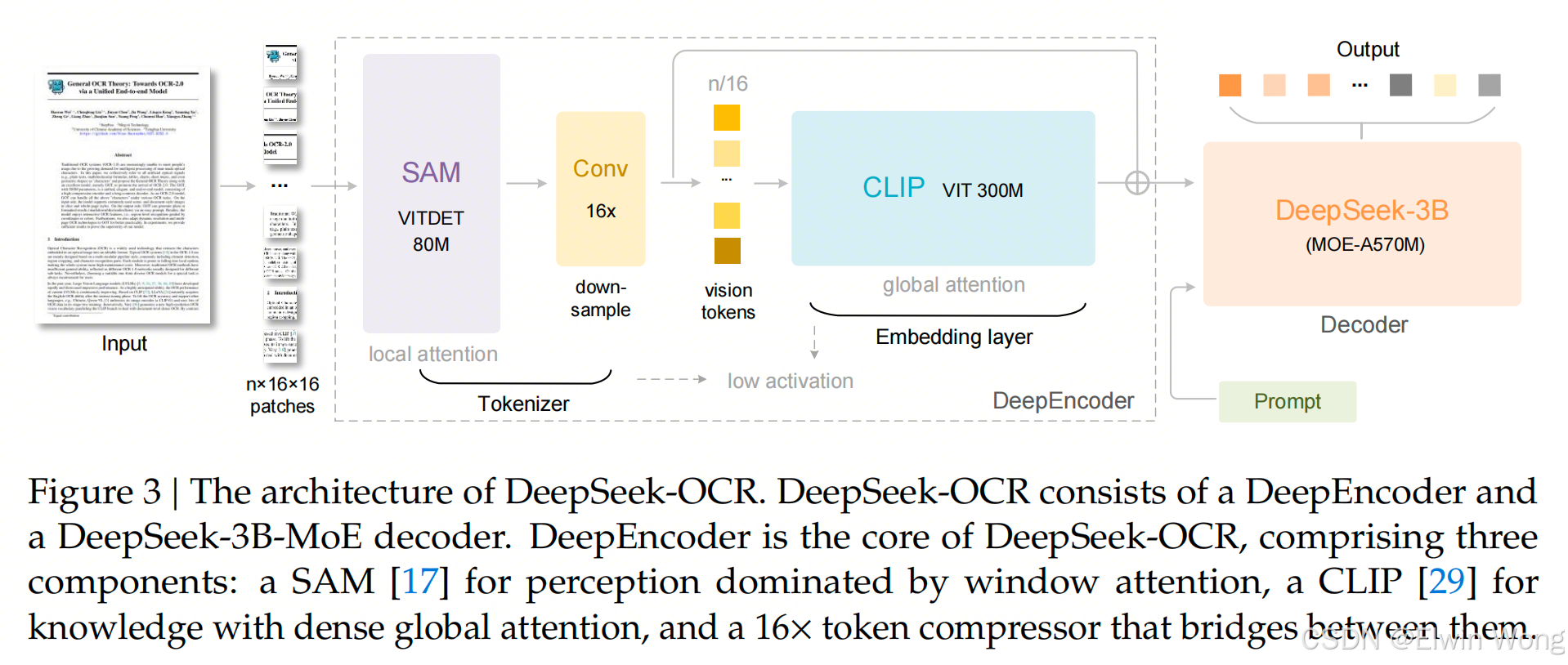
- DeepSeek-OCR 采用统一的端到端视觉语言模型(VLM)架构,包含一个编码器(Encoder)和一个解码器(Decoder)。
- 编码器称为 DeepEncoder,负责提取图像特征、进行图像分词(tokenization)以及压缩视觉表示。主要由两个组件串联组成:80M 的 SAM-base 模型和300M 的 CLIP-large 模型
- 解码器基于图像 token 和提示(prompts)生成所需结果。采用 3B MoE(Mixture of Experts)架构,激活参数量为 570M。
DeepEncoder
- 双组件结构:DeepEncoder 主要由两个部分组成:
- 视觉感知特征提取组件:主要使用窗口注意力(window attention)。
- 视觉知识特征提取组件:使用密集全局注意力(dense global attention)。
- 基础模型选择:
- 为了利用现有预训练模型的优势,第一部分主要基于 SAM-base (patch-size 16)。
- 第二部分主要基于 CLIP-large。
- 关键修改:对于 CLIP 模型,移除了第一层 patch embedding,因为其输入不再是原始图像,而是来自前一处理阶段(pipeline)的输出 token。
- 下采样模块:在两个组件之间,借鉴了 Vary 的设计,使用了一个 2 层卷积模块,对视觉 token 进行 16倍下采样。
- 卷积层参数:核大小为 3,步幅为 2,填充为 1,通道数从 256 增加到 1024。
- 数据流与计算量示例:
- 输入一张 1024 × 1024 1024 \times 1024 1024×1024 的图像。
- DeepEncoder 将其分割成 ( 1024 / 16 ) × ( 1024 / 16 ) = 4096 (1024/16) \times (1024/16) = 4096 (1024/16)×(1024/16)=4096 个 patch token。
- 由于前半部分(窗口注意力部分)只有 80M 参数,这种激活开销是可以接受的。
- 压缩过程:这 4096 个 token 经过压缩模块后,数量变为 4096 / 16 = 256 4096 / 16 = 256 4096/16=256。这使得整体的激活内存变得可控。
核心要点总结:
DeepEncoder 通过结合 SAM 和 CLIP 的优势,并引入一个下采样模块来高效处理高分辨率图像,将大量的图像 patch token 压缩为更少的数量(例如从 4096 压缩到 256),从而在保持强大视觉理解能力的同时,控制住了计算和内存成本。
v2:视觉因果流
提出了一种新的编码器 DeepEncoder V2,该编码器能够根据图像的语义(image semantics)动态重排(dynamically reordering)视觉 token。这么做的目的是为了克服现有方法的局限性:
- 传统做法:现有的视觉语言模型(VLMs)在输入大语言模型(LLMs)时,通常以固定的光栅扫描顺序(从左到右、从上到下)处理视觉 token。
- 矛盾点:这种僵化的顺序与人类的视觉感知相矛盾。
- 人类视觉:人类遵循的是灵活且语义连贯的扫描模式,这种模式由内在的逻辑结构驱动,特别是对于复杂布局的图像,人类视觉表现出因果感知的序列处理。
受上述人类认知机制的启发,DeepEncoder V2 被设计用来赋予编码器因果推理(causal reasoning)能力。它能在基于 LLM 的内容理解之前,智能地重排视觉 token。
探索一种新范式:是否可以通过两级级联的 1D 因果推理结构来有效实现 2D 图像理解,从而有望实现真正的 2D 推理。
架构
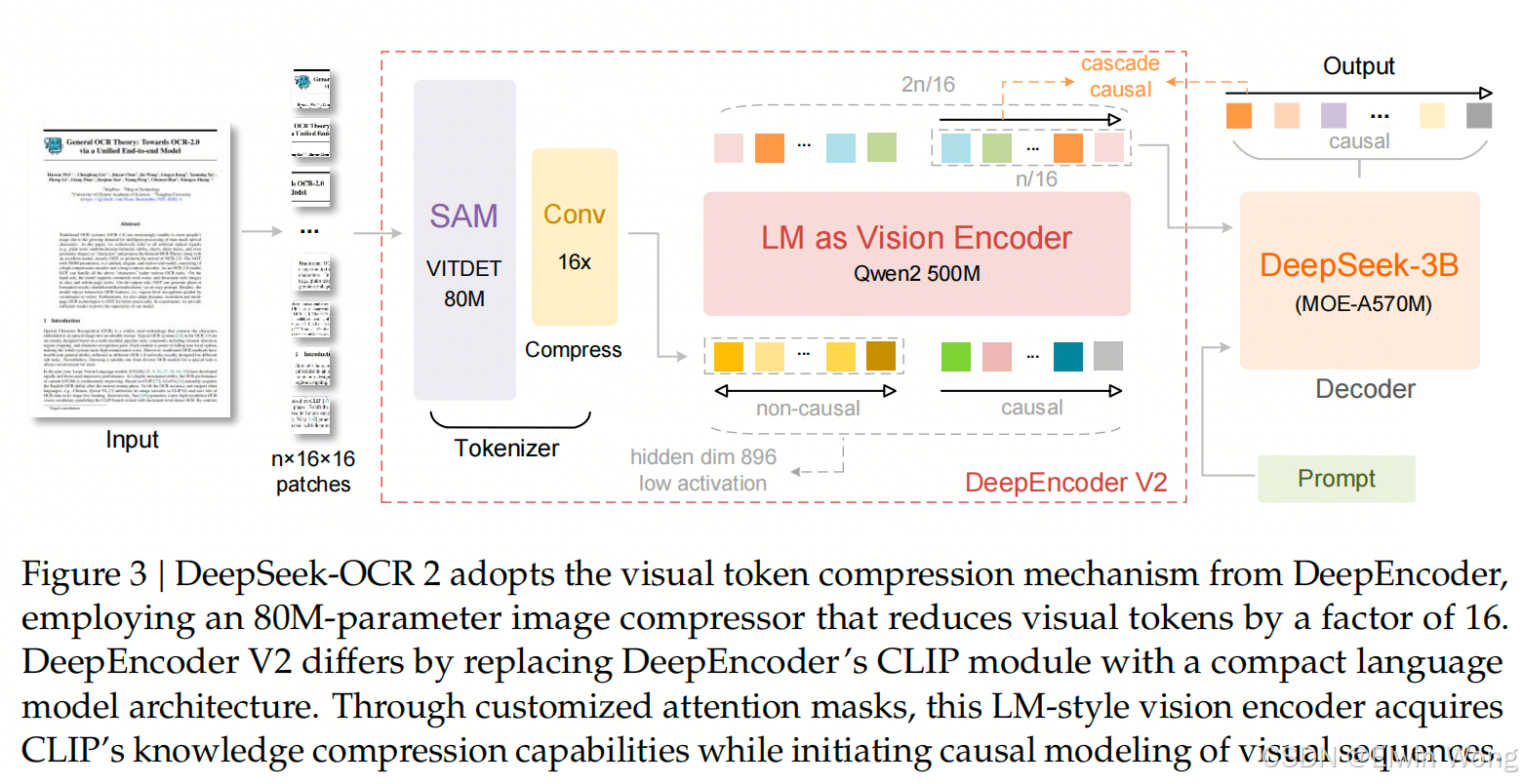
整体架构继承性
- 继承设计:DeepSeek-OCR 2 继承了初代 DeepSeek-OCR 的整体架构。
- 组成结构:依然采用编码器(Encoder)+ 解码器(Decoder)的结构。
- 编码器:负责将图像离散化(discretizes)为视觉 token。
- 解码器:基于这些视觉 token 和文本提示(text prompts)来生成输出结果。
核心改进点
- 关键区别:两代模型的主要区别在于编码器部分。
- 升级内容:将原有的 DeepEncoder 升级为了 DeepEncoder V2。
- 新特性:DeepEncoder V2 在保留前代所有能力的基础上,通过一种新颖的架构设计,引入了因果推理(causal reasoning)能力。
DeepEncoder V2
-
要解决的问题:传统的编码器将2D图像块(Patches)强制展平为1D序列,并施加基于文本的绝对位置编码(如RoPE)。这种预定义的光栅扫描顺序(从左到右、从上到下)引入了不恰当的归纳偏置,忽略了图像内部的语义逻辑。如下图所示:
Input Image (H x W x C) Grid of Patches (P x P)
+---------------------+ +---+---+---+
| | | 1 | 2 | 3 |
| 原始图像 | ---> |---+---+---| 划分 Patch
| (例如 224x224x3) | | 4 | 5 | 6 |
| | |---+---+---|
+---------------------+ | 7 | 8 | 9 |
+---+---+---+
|
v
Flatten Patches (展平)
|
+------------------------+-------------------------+
| | | | |
[Patch 1] [Patch 2] ... [Patch N] (维度: PPC)
| | |
v v v
+--------------------------------------------------+
| Linear Projection of Flattened Patches |
| (线性映射层: 全连接层/Conv2d) |
+--------------------------------------------------+
| | |
v v v
[Embed 1] [Embed 2] ... [Embed N] (维度: D)
| | |
+------------+-----------+------------+
| 拼接
[Class Token] |
| |
v v
[Token 0] [Token 1] [Token 2] ... [Token N]
+ + + +
[Pos Emb 0] [Pos Emb 1] [Pos Emb 2] ... [Pos Emb N] (位置编码)
| | | |
v v v v
+============================================================+
| Transformer Encoder 输入序列 |
+============================================================+ -
设计目标:DeepEncoder V2 旨在打破这种刚性顺序,通过引入因果推理(Causal Reasoning)能力,使模型能够根据图像的语义内容动态地重排视觉 Token。
DeepEncoder V2 设计细节与核心功能可分为以下 4 个关键部分:
视觉分词器 (Vision Tokenizer)
- 架构继承:沿用 DeepEncoder 的设计思路,采用 "80M 参数 SAM-base(Segment Anything Model)+ 两层卷积层" 的组合架构;但将最终卷积层的输出维度从 DeepEncoder 的 1024 调整为 896,以适配后续 LLM 风格编码器的输入需求。
- 功能与优势:
- 高效压缩:利用窗口注意力机制(Window Attention)实现 16倍 Token 压缩。
- 参数轻量化:在极低参数量(80M)下完成特征提取,显著降低了后续全局注意力模块的计算成本和激活内存。
- 可替换性:该压缩式 tokenizer 并非强制设计,可替换为简单的图像块嵌入(patch embedding),具备架构灵活性。
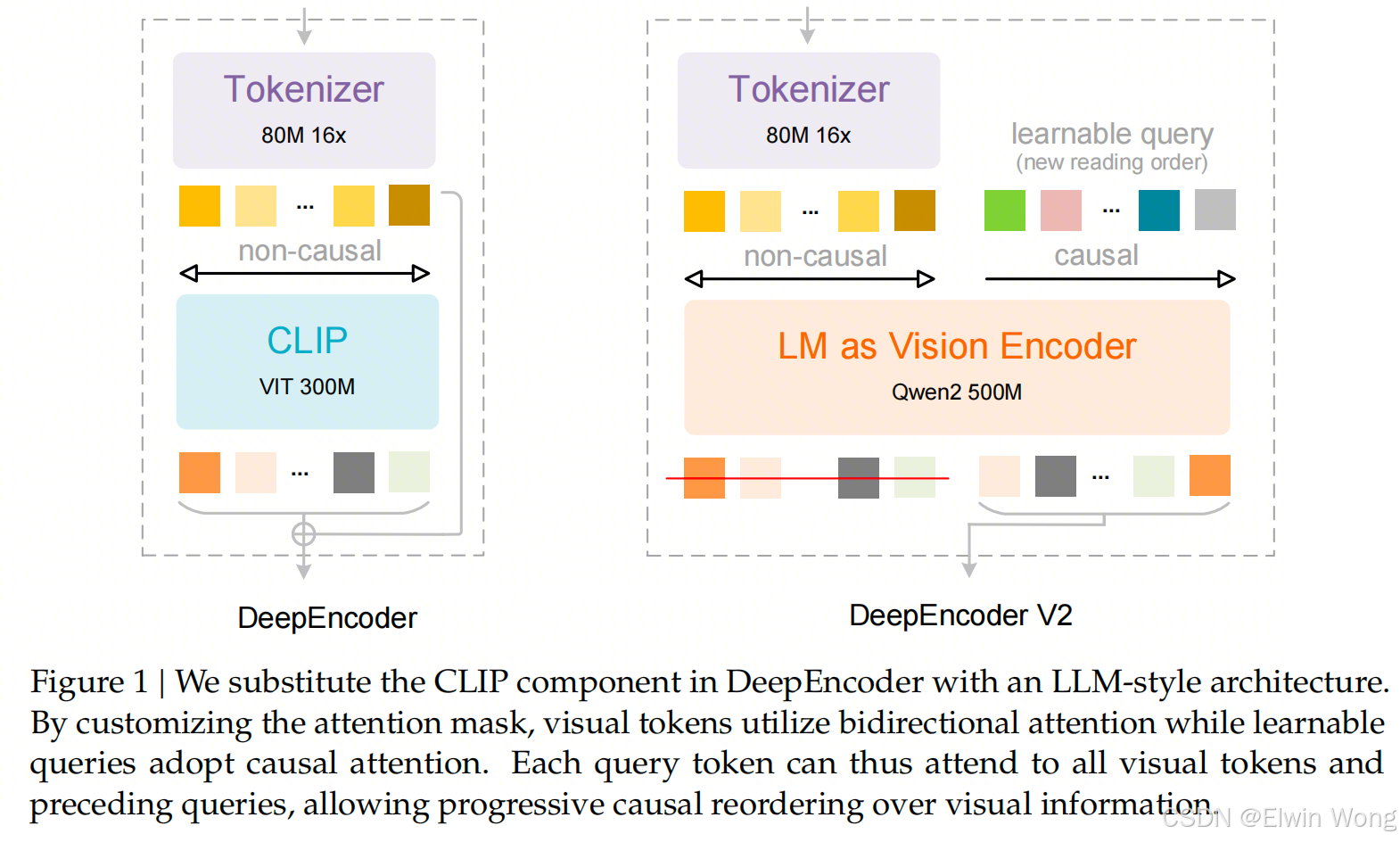
作为视觉编码器的语言模型 (Language Model as Vision Encoder)
这是 V2 版本最核心的创新点,用类似 LLM 的架构替代了原有的 CLIP 模型。
- 架构选型:基于 Qwen2-0.5B(5亿参数)构建,其参数规模与 CLIP ViT(300M 参数)接近,在保留全局建模能力的同时,避免引入过度计算开销。
- 双流注意力机制(Dual-stream Attention):
- 视觉 Token(前缀):采用双向注意力(Bidirectional Attention),保持类似 ViT 的全图像感受野,用于保留全局视觉知识。
- 因果流查询(Causal Flow Queries,后缀):采用因果注意力(Causal Attention)(即单向三角掩码),每个查询只能关注之前的 Token。
- 工作流:
- 视觉 Token 作为前缀输入。
- 可学习的查询(Queries)作为后缀附加。
- 每个查询关注所有视觉 Token 和之前的查询。
- 保持查询数量与视觉 Token 数量一致(等基数),通过语义排序对视觉特征进行蒸馏。
- 输出:仅将因果查询(Causal Query)的输出传递给后续的 LLM 解码器,从而实现"带有因果感知的视觉理解"。
- 核心价值:构建 "两阶段级联因果推理":
- 第一阶段(编码器):通过因果流动查询对视觉 token 进行语义排序;
- 第二阶段(LLM 解码器):对排序后的 token 进行自回归推理;该设计打破了传统编码器通过位置编码强加的 "固定空间顺序",使 token 排序适配图像语义,同时自然对齐 LLM 的单向注意力模式,弥合 2D 图像结构与 1D 语言因果建模的差距。
因果流查询 (Causal Flow Query)
- 多分辨率策略:为了适应不同尺寸的图像,采用了多裁剪(Multi-crop)策略。
- 全局视图(Global View):固定分辨率为 1024 × 1024 ,生成 256 1024 \times 1024,生成 256 1024×1024,生成256 个查询嵌入。
- 局部视图(Local Views):固定分辨率为 768 × 768 768 \times 768 768×768,所有局部视图共享 144 个查询嵌入。局部裁剪数量 k k k 可在 0-6 之间调整(当图像宽高均小于 768 时,不进行局部裁剪)。
- Token 数量计算:
- 输入到 LLM 解码器的 "重排序视觉 token 总数" = k × 144 + 256 k \times 144 + 256 k×144+256。
- 总 Token 数量范围控制在 256(0 个局部视图)到 1120(6 个局部视图)之间之间,既保证了压缩率,又匹配了 LLM 的上下文窗口限制(与 Gemini-3 Pro 的预算一致)。
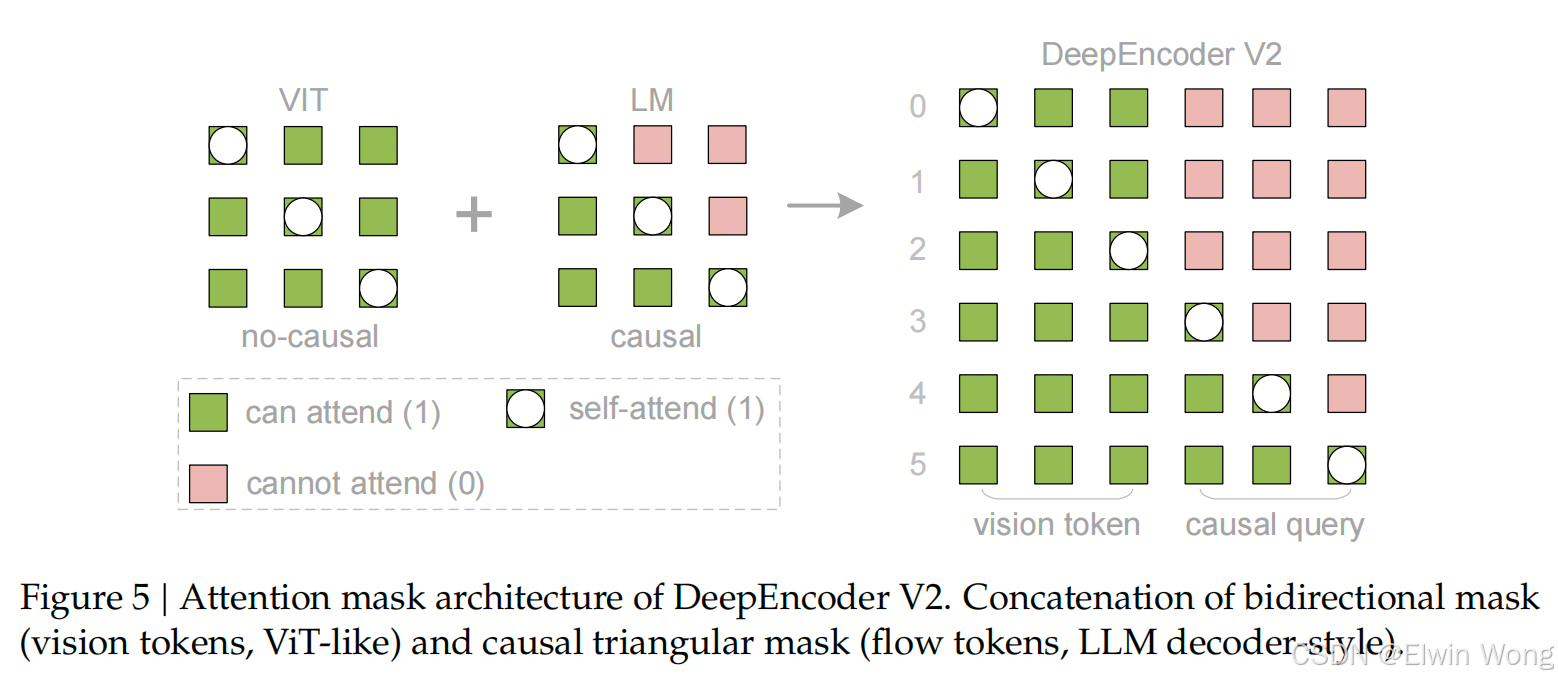
注意力掩码 (Attention Mask)
- 掩码结构:拼接了两个区域的掩码:
- 左侧区域(视觉 Token):全连接(双向),允许 Token 之间完全可见。
- 右侧区域(流 Token):因果三角掩码(Causal Triangular Mask),强制自回归顺序。
附AI摘要
