今天将为大家带来几种常见的排序算法,之前我们学习了冒泡排序法,选择排序算法,今天还会讲解几种常用的算法,那我们开始吧。
在讲解之前,我们先来回顾一下之前学到的算法,方便我们和后续排序算法作一个比较
1、冒泡排序
1.1 基本思想
-
每次比较相邻的两个元素,如果顺序错误就交换。
-
一轮下来,最大(或最小)的元素"冒泡"到序列一端。
-
进行 n-1 轮后,整个序列有序。
1.2 工作原理
-
从第一个元素开始,比较相邻的元素
-
如果第一个比第二个大,就交换它们
-
对每一对相邻元素做同样的工作,直到序列末尾
-
这样最大的元素就会"冒泡"到最后一个位置
-
重复步骤1-4,每次忽略已经排序好的尾部元素
1.3 代码实现
cs
int BubbleSort(int *arr, int len) {
for(int i = 0; i < len - 1; i++) {
int swapped = 0;
for(int j = 0; j < len - 1 - i; j++) {
if(arr[j] >arr[j + 1]) {
swapped = 1;
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if(!swapped) break;
}
return 0;
}1.4 复杂度
(1)时间复杂度:
-
最好:已经有序,只比较不交换 → O(n);
-
最坏:完全逆序,每次都交换 → O(n²);
-
平均:O(n²)。
(2)空间复杂度:
- O(1),原地排序。
(3)稳定性:
- 稳定:相邻相等元素不会被交换顺序
(4)特点:
- 简单直观
2、选择排序
2.1 基本思想
- 核心思想 :每次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
2.2 工作原理
-
第1趟:找到最小或最大的元素,放到数组首位;
-
第2趟:在剩下的元素里找到最小或最大的,放到第二个位置;
-
依此类推,直到待排序的数据元素全部排完。
2.3 代码实现
cs
int SelectSort(int *arr, int len) {
for(int i = 0; i < len - 1; i++) {
int min = i;
for(int j = i + 1; j < len; j++) {
if(arr[j] < arr[min]) {
min = j;
}
}
if(min != i) {
int tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}
}
return 0;
}2.4 复杂度
(1)时间复杂度:
-
比较次数 :无论如何都要比较
(n-1) + (n-2) + ... + 1 = n(n-1)/2 ≈ O(n²) -
交换次数:最多 n-1 次,比较适合交换代价大的场合。
-
最好:O(n²),最坏:O(n²),平均:O(n²)
(2)空间复杂度:
- O(1)(原地排序)
(3)稳定性:
- 不稳定:因为交换时可能打乱相同元素的相对排序
(4)特点:
-
实现简单,代码容易理解
-
原地排序,空间效率高
-
交换次数少(最多n-1次)
回顾过后大家是不是一下豁然开朗了呢,看着都是似曾相识的感觉,大家一定要牢记住这些基本的算法,很重要,对现阶段学习而言。那我们就继续学习一些新的排序方法吧。
3、插入排序
3.1 基本思想
核心思想 :将待排序的元素逐个插入到已经排好序的序列中的适当位置,直到所有元素都插入完毕。
3.2 工作原理
-
将第一个元素视为已排序序列
-
取出下一个元素,在已排序序列中从后向前扫描
-
如果已排序元素大于新元素,将该元素移到下一位置
-
重复步骤3,直到找到已排序元素小于或等于新元素的位置
-
将新元素插入到该位置
-
重复步骤2-5,直到所有元素都插入完毕
3.3 代码实现
cs
int InsertSort(int *arr, int len) {
for(int i = 1; i < len; i++) {
int key = arr[i];
int j = i;
while(j > 0 && arr[j - 1] > key) {
arr[j] = arr[j - 1];
j--;
}
arr[j] = key;
}
return 0;
}3.4 复杂度
(1)时间复杂度:
-
最好:已经有序,只比较不交换 → O(n);
-
最坏:完全逆序,每次都交换 → O(n²);
-
平均:O(n²)。
(2)空间复杂度:
- 只需要常数个辅助变量 → O(1),属于原地排序。
(3)稳定性:
- 稳定:相邻相等元素不会被交换顺序
(4)特点:
-
适合:数据量小 ,或数据基本有序的情况;
-
不适合:大规模、无序数据
4、希尔排序
4.1 基本思想
核心思想 :是直接插入排序的改进版,通过分组插入排序来提升效率。
先将整个待排序序列分割成若干子序列,分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行一次直接插入排序。
4.2 工作原理
-
选择一个初始步长
gap = n/2; -
把整个数组分为若干组(相隔 步长gap 的元素为一组),对每组做插入排序;
-
缩小 gap(通常 gap = gap/2 等);
-
重复直到 gap = 1。
这里给大家做一个基础演示吧:
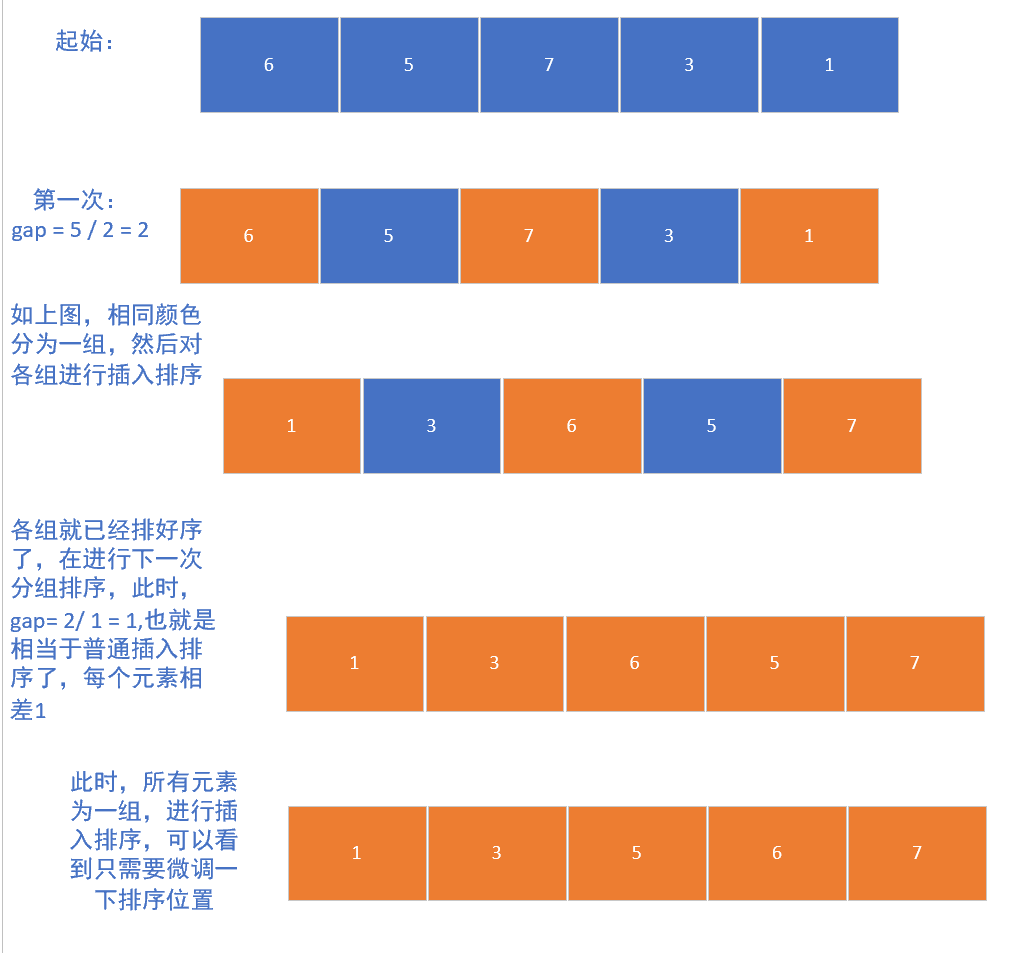
4.3 代码实现
cs
int ShellSort(int *arr, int len) {
for(int gap = len / 2; gap > 0; gap /= 2) {
for(int i = gap; i < len; i++) {
int key = arr[i];
int j = i;
while(j >= gap && arr[j - gap] > key) {
arr[j] = arr[j - gap];
j -= gap;
}
arr[j] = key;
}
}
return 0;
}4.4 复杂度
(1)时间复杂度:
-
依赖于步长序列的选择。
-
最好情况(基本有序):接近 O(n log n);
-
最坏情况:接近 O(n²);
-
实际平均性能远优于插入排序,常见实现为 O(n^1.3 ~ n^1.5)。
(2)空间复杂度:
- 只需要常数个辅助变量 → O(1),属于原地排序。
(3)稳定性:
- 不稳定:因为分组插入时,可能打乱相等元素的顺序
(4)特点:
-
适合:中等规模的数据(比如几万级别以内),比插入排序快很多;
-
缺点:复杂度分析困难,且最坏情况仍然是 O(n²)。
-
希尔排序能显著优化直接插入排序。
5、快速排序
5.1 基本思想
-
分治法:选一个"基准元素"(pivot),将序列划分为两部分:
-
小于 pivot 的放左边;
-
大于 pivot 的放右边;
-
-
递归排序左右两部分。
5.2 工作原理
-
选择基准:从序列中选择一个元素作为基准(pivot)
-
分区操作:重新排列序列,所有比基准小的放在左边,比基准大的放在右边
-
递归排序:递归地对左右两个子序列进行快速排序
具体步骤:
-
选定一个基准值(pivot),通常取数组第一个元素。
-
设置左右指针:
left指向数组开头,right指向结尾。 -
从右往左找第一个小于pivot的元素,如果找到放入left指向的位置;在从左往右找第一个大于pivot的元素,如果找到放在right指向的位置。
-
重复上述步骤3,直到左右指针相遇。
-
把pivot放到左右指针相遇的位置。
-
递归对pivot左边和右边的子数组分别进行快速排序。
这里也给大家画个图展示一下吧:
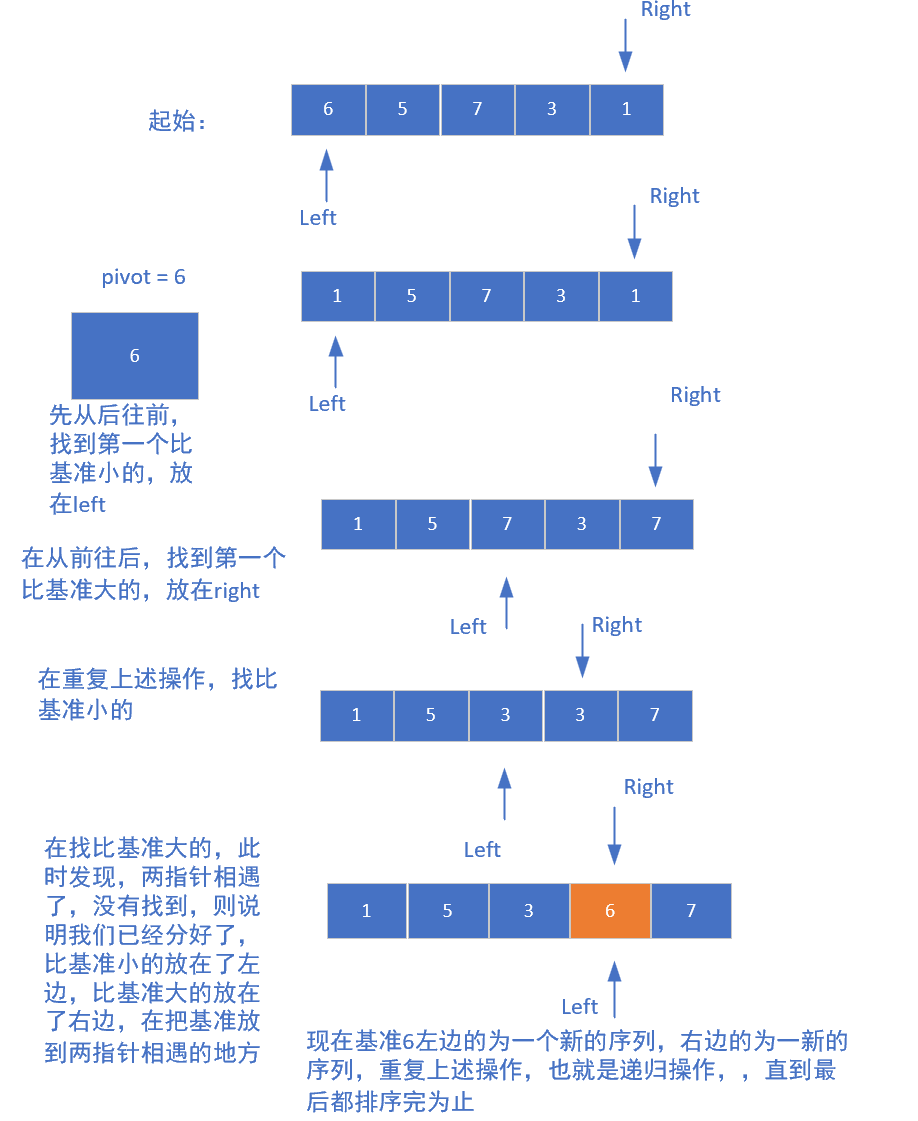
5.3 代码实现
cs
int QuickSort(int *arr, int left, int right) {
if(left >= right) return 0;
int pivot = arr[left];
int i = left;
int j = right;
while(i < j) { //覆盖法
while(i < j && arr[j] >= pivot) j--;
arr[i] = arr[j];
while(i < j && arr[i] <= pivot) i++;
arr[j] = arr[i];
}
arr[i] = pivot;
QuickSort(arr, left, i - 1);
QuickSort(arr, i + 1, right);
return 0;
}5.4 复杂度
(1)时间复杂度:
-
最好:每次平衡划分 → O(n log n);
-
最坏:划分极不平衡(例如有序数组 + 选首元素)→ O(n²);
-
平均:O(n log n)。
(2)空间复杂度:
- 递归栈空间:O(log n)(最好),最坏 O(n)
(3)稳定性:
- 不稳定:划分过程中可能交换相等元素的顺序。
(4)特点:
-
平均性能好,是实际应用中最常用的排序算法之一;
-
适用于大规模数据。
在C语言中,可以使用qsort函数来实现排序,内部就是使用的快速排序的思想。
C语言:使用qsort
cs
#include <stdio.h>
#include <stdlib.h>
// 比较函数,升序
int cmp(const void *a, const void *b) {
return (*(int*)a - *(int*)b);
}
int main() {
int arr[] = {5, 2, 9, 1, 3};
int n = sizeof(arr) / sizeof(arr[0]);
// 排序
qsort(arr, n, sizeof(int), cmp);
// 输出结果
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}6、堆排序
6.1 基本思想
核心思想 :利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆的性质:父节点的值总是大于(或小于)其子节点的值。
大根堆:任意父节点 ≥ 子节点。
小根堆:任意父节点 ≤ 子节点。
6.2 工作原理
-
建堆:将待排序序列构建成一个大顶堆(或小顶堆)
-
交换:将堆顶元素(最大值)与末尾元素交换
-
调整:将剩余n-1个序列重新调整成堆
-
重复:重复步骤2-3,直到所有元素有序
如何去理解呢,这里依旧给大家画个图,理解一下:
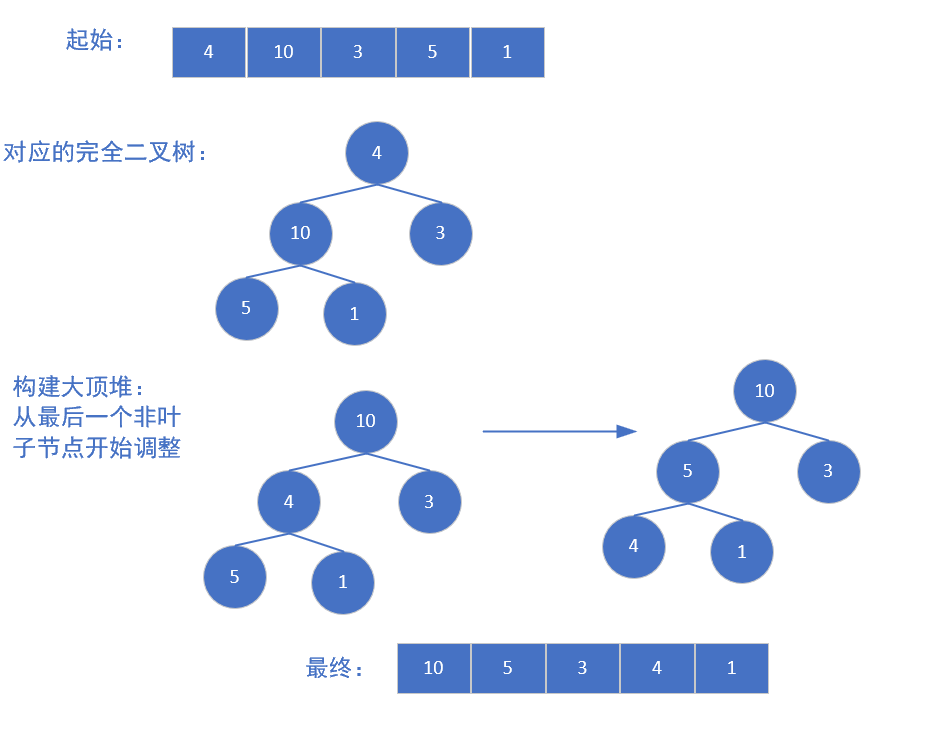
建好堆之后,我们开始进行交换和调整:
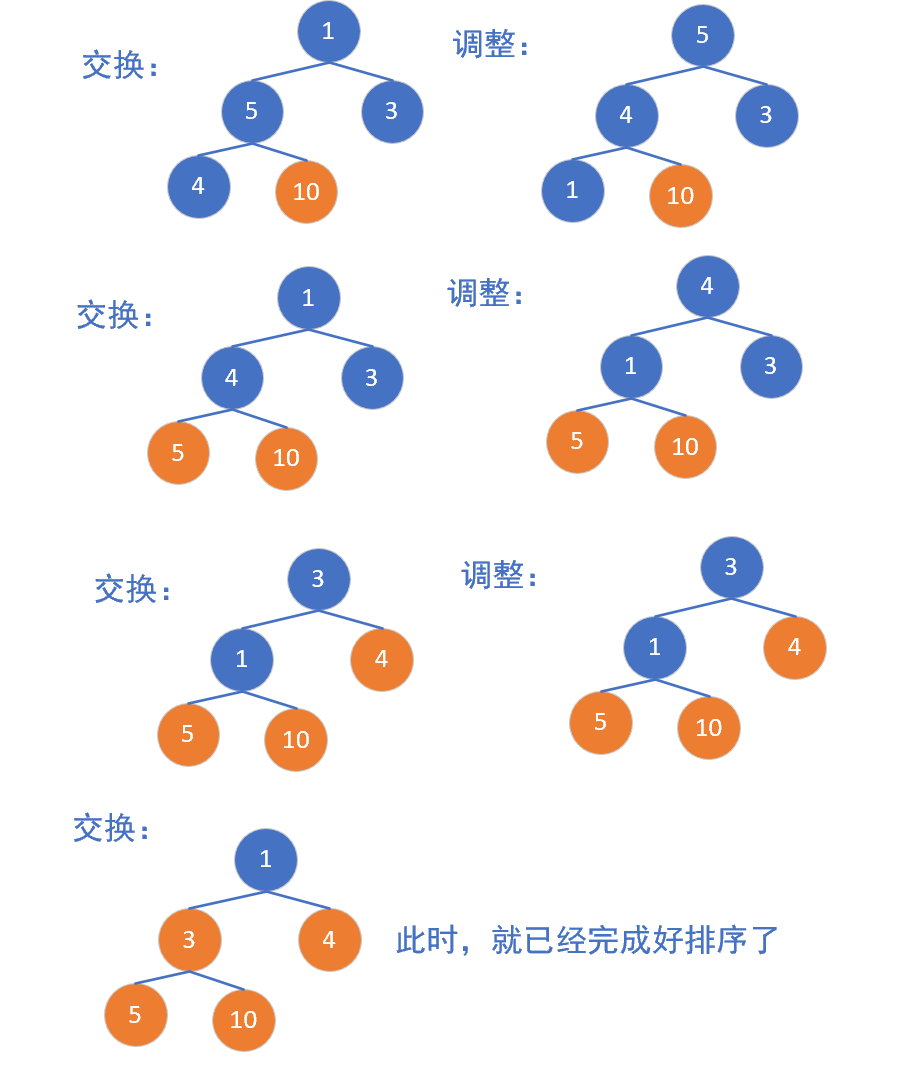
交换调整也就是一个递归操作,大家看完图之后是不是觉得就很简单了呢,那我们再来看看如何编码的吧:
6.3 代码实现
cs
// 调整堆(大根堆)
int Heapify(int *arr, int n, int i) {
int largest = i; // 根节点
int left = 2*i + 1; // 左子节点
int right = 2*i + 2; // 右子节点
if(left < n && arr[left] > arr[largest]) largest = left;
if(right < n && arr[right] > arr[largest]) largest = right;
// 如果最大值不是根节点,则交换,并递归调整被交换的子树
if(largest != i) {
int tmp = arr[i];
arr[i] = arr[largest];
arr[largest] = tmp;
heapify(arr, n, largest);
}
return 0;
}
int HeapSort(int arr, int n) {
// 1. 建堆:从最后一个非叶子节点开始,向上调整
for(int i = n / 2 - 1; i >= 0; i++)
Heapify(arr, n, i);
// 2. 取出堆顶元素(最大值),放到数组末尾,然后调整剩余堆
for(int i = n - 1; i > 0; i--) {
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
Heapify(arr, i, 0); // 只调整前 i 个元素
}
return 0;
}6.4 复杂度
(1)时间复杂度:
-
建堆:O(n)
-
调整(Heapify):O(log n) 每次交换后调整堆,做 n-1 次 → O(n log n)
-
总复杂度:O(n log n)
-
最优 / 平均 / 最坏时间复杂度均为 O (nlogn),实际运行比快排慢
(2)空间复杂度:
- O(1),原地排序。
(3)稳定性:
- 不稳定:因为堆调整时会改变相同元素的相对位置。
(4)特点:
- 适用于大规模数据。
7、归并排序
8、基数排序
9、二分查找
我们一般在查找一个数据时,都是通过遍历这个数组去实现的,如果数据量大,就会特别浪费时间,因为它的时间复杂度为O(n),所以我们就想到了一种更高效的方法,也就是二分法,
基本思想:
就是每次取中间的那个数和我们查找的数据进行比较,如果比这个数据大,就说明可能在前半部分,如果比这个数据小,说明就可能在后半部分,再次递归去取半查找,直到找到为止。
代码实现:
cs
int MidSearch(int *arr, int left, int right, int tmpData) {
if(left > right) return -1;
int mid = (left + right) / 2;
if(arr[mid] > tmpData) {
return MidSearch(arr, left, mid - 1, tmpData);
}else if(arr[mid] < tmpData) {
return MidSearch(arr, mid + 1, right, tmpData);
}
return mid;
}