深度学习网络从入门到入土 深度卷积神经网络alexnet
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
- [深度学习网络从入门到入土 深度卷积神经网络alexnet](#[深度学习网络从入门到入土] 深度卷积神经网络alexnet)
- 个人导航
- 参考资料
- 背景
- 架构(公式)
- 创新点
-
-
-
- [1. ReLU 取代传统激活函数](#1. ReLU 取代传统激活函数)
- [2. GPU 并行训练](#2. GPU 并行训练)
- [3. 大模型 + 大数据](#3. 大模型 + 大数据)
- [4. 数据增强](#4. 数据增强)
- [5. Dropout](#5. Dropout)
-
-
- [拓展 - 局部响应归一化LRN](#拓展 - 局部响应归一化LRN)
- 代码实现
- 项目实例
参考资料
ImageNet Classification with Deep Convolutional Neural Networks
背景
AlexNet 的核心意义不在于"用了 CNN",而在于它首次证明: 在大数据 + GPU 条件下,深层 CNN 可以显著击败传统方法
-> 第一个把深度学习真正跑通并跑赢传统方法的系统工程
AlexNet 作用于 ImageNet 2012:
- Top-5 error 从 ~26% 直接降到 ~15%
- 断层式领先,直接改变研究范式
架构(公式)
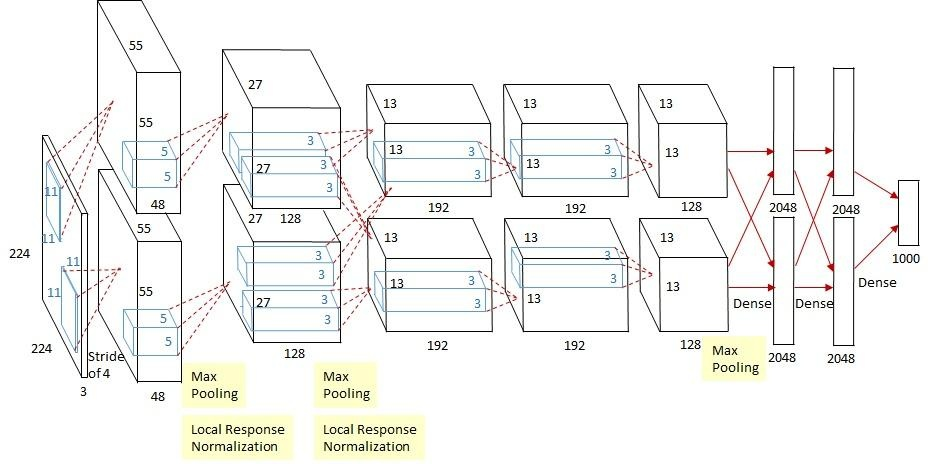
AlexNet 是一个 8 层可学习参数网络:
- 5 个卷积层
- 3 个全连接层
整体结构可概括为:
Input → Conv → ReLU → LRN → Pool → ⋯ → FC → Softmax \text{Input} \rightarrow \text{Conv} \rightarrow \text{ReLU} \rightarrow \text{LRN} \rightarrow \text{Pool} \rightarrow \cdots \rightarrow \text{FC} \rightarrow \text{Softmax} Input→Conv→ReLU→LRN→Pool→⋯→FC→Softmax
1.输入
原论文输入尺寸:
3 × 227 × 227 3 \times 227 \times 227 3×227×227
2.卷积层
标准二维卷积:
y i , j , k = ∑ c ∑ u , v w u , v , c , k ⋅ x i + u , j + v , c + b k y_{i,j,k} = \sum_{c}\sum_{u,v} w_{u,v,c,k} \cdot x_{i+u,j+v,c} + b_k yi,j,k=c∑u,v∑wu,v,c,k⋅xi+u,j+v,c+bk
AlexNet 的关键不是公式,而是规模:
- Conv1: 11 × 11 11 \times 11 11×11,stride=4
- Conv2: 5 × 5 5 \times 5 5×5
- Conv3--5: 3 × 3 3 \times 3 3×3
3.激活函数(ReLU)
首次大规模使用 ReLU :
f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
对比 tanh / sigmoid:
- 避免梯度饱和
- 显著加快收敛速度
4.局部响应归一化(LRN)
AlexNet 特有(后续模型基本弃用):
b x , y i = a x , y i ( k + α ∑ j = i − n / 2 i + n / 2 ( a x , y j ) 2 ) β b_{x,y}^i = \frac{a_{x,y}^i} {\left(k + \alpha \sum_{j=i-n/2}^{i+n/2}(a_{x,y}^j)^2\right)^\beta} bx,yi=(k+α∑j=i−n/2i+n/2(ax,yj)2)βax,yi
本质:
- 引入跨通道竞争
- 模拟生物神经元侧抑制
5.池化层
重叠 最大池化(overlapping max pooling):
y = max ( u , v ) ∈ Ω x u , v y = \max_{(u,v)\in \Omega} x_{u,v} y=(u,v)∈Ωmaxxu,v
stride < kernel size \text{stride} < \text{kernel size} stride<kernel size: 减少过拟合,同时保留更多空间信息
6.全连接层
最后三层:
y = W x + b \mathbf{y} = \mathbf{W}\mathbf{x} + \mathbf{b} y=Wx+b
最后一层使用 Softmax:
p i = e z i ∑ j e z j p_i = \frac{e^{z_i}}{\sum_j e^{z_j}} pi=∑jezjezi
创新点
1. ReLU 取代传统激活函数
- 训练速度数量级提升
- 为更深网络铺路
2. GPU 并行训练
- 使用两张 GPU
- 网络结构被"强行拆分"到不同 GPU 上
3. 大模型 + 大数据
- 参数量 ~ 60M
- ImageNet 规模首次被充分利用
4. 数据增强
- 随机裁剪
- 水平翻转
- RGB 颜色扰动(PCA jittering)
5. Dropout
- 首次在大规模 CNN 中系统使用
- 主要用于全连接层
h ~ i = r i h i , r i ∼ Bernoulli ( p ) \tilde{h}_i = r_i h_i,\quad r_i \sim \text{Bernoulli}(p) h~i=rihi,ri∼Bernoulli(p)
拓展 - 局部响应归一化LRN
在通道维度(channel)上做"邻域竞争/抑制"
-> 某个位置上,如果某些通道响应很大,会抑制同一位置附近通道的响应,从而"强调强响应、压制弱响应"
LRN 在 AlexNet 之后逐渐不用了,主要原因是:
- 效果一般、计算开销不小
- BatchNorm/LayerNorm/GroupNorm 更稳定、训练更快、更有效
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0):
-
size=5: 通道邻域窗口大小 (跨通道的局部范围)5表示每个通道会参考它自己以及左右各 2 个通道的能量(平方和) -
alpha=1e-4: 归一化强度系数 (越大,分母里那项越大,抑制越强) -
beta=0.75: 指数幂 (越大,抑制的非线性越强) -
k=2.0: 分母的基底常数项 (防止分母太小导致数值爆炸,也控制整体缩放)
代码实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class B_AlexNet_Paper(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
# =========
# 特征提取部分
# =========
self.conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4)
self.relu1 = nn.ReLU(inplace=True)
self.lrn1 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, padding=2)
self.relu2 = nn.ReLU(inplace=True)
self.lrn2 = nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2.0)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv3 = nn.Conv2d(256, 384, kernel_size=3, padding=1)
self.relu3 = nn.ReLU(inplace=True)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, padding=1)
self.relu4 = nn.ReLU(inplace=True)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, padding=1)
self.relu5 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
# =========
# 分类器部分(保持不变)
# 256*6*6 对齐 227×227 输入
# =========
self.classifier = nn.Sequential(
nn.Dropout(p=0.5), # 仅在model.train()训练时才启用
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5), # 仅在model.train()训练时才启用
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
# =========
# 1) 输入尺寸对齐:224 -> 227
# =========
if x.shape[-2:] == (224, 224):
x = F.pad(x, (1, 2, 1, 2), mode="constant", value=0.0)
# =========
# 2) Conv1 -> ReLU -> LRN -> Pool
# =========
x = self.conv1(x) #
x = self.relu1(x)
x = self.lrn1(x)
x = self.pool1(x)
# =========
# 3) Conv2 -> ReLU -> LRN -> Pool
# =========
x = self.conv2(x)
x = self.relu2(x)
x = self.lrn2(x)
x = self.pool2(x)
# =========
# 4) Conv3 -> ReLU
# =========
x = self.conv3(x)
x = self.relu3(x)
# =========
# 5) Conv4 -> ReLU
# =========
x = self.conv4(x)
x = self.relu4(x)
# =========
# 6) Conv5 -> ReLU -> Pool
# =========
x = self.conv5(x)
x = self.relu5(x)
x = self.pool3(x)
# =========
# 7) Flatten + classifier
# =========
x = x.flatten(1)
x = self.classifier(x)
return x
if __name__ == '__main__':
net = B_AlexNet_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)项目实例
库环境:
numpy==1.26.4
torch==2.2.2cu121
byzh-core==0.0.9.21
byzh-ai==0.0.9.50
byzh-extra==0.0.9.12
...AlexNet训练Oxford_IIIT_Pet数据集:
py
import torch
from byzh.ai.Btrainer import B_Classification_Trainer
from byzh.ai.Bdata import B_Download_Oxford_IIIT_Pet, b_get_dataloader_from_tensor
from byzh.ai.Bmodel.study_cnn import B_AlexNet_Paper
from byzh.ai.Butils import b_get_device
##### data #####
downloader = B_Download_Oxford_IIIT_Pet(save_dir='D:/study_cnn/datasets/Oxford_IIIT_Pet')
data_dict = downloader.get_data()
X_train = data_dict['X_train_standard']
y_train = data_dict['y_train']
X_test = data_dict['X_test_standard']
y_test = data_dict['y_test']
num_classes = data_dict['num_classes']
train_dataloader, val_dataloader = b_get_dataloader_from_tensor(X_train, y_train, X_test, y_test)
##### model #####
model = B_AlexNet_Paper(num_classes=num_classes)
##### else #####
epochs = 10
lr = 1e-3
device = b_get_device(use_idle_gpu=True)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
##### trainer #####
trainer = B_Classification_Trainer(
model=model,
optimizer=optimizer,
criterion=criterion,
train_loader=train_dataloader,
val_loader=val_dataloader,
device=device
)
trainer.set_writer1('./runs/log.txt')
##### run #####
trainer.train_eval_s(epochs=epochs)
##### calculate
trainer.draw_loss_acc('./runs/loss_acc.png', y_lim=False)
trainer.save_best_checkpoint('./runs/alexnet_best.pth')
trainer.calculate_model()