摘要:数据仓库分层是数据体系建设的基石,也是大数据领域最重要的设计理念之一。分层的核心思想在于通过解耦复杂的数据处理流程,将复杂问题简单化,让每一层只处理单一的步骤,本文将基于阿里巴巴的常用分层体系来分享各层次在数仓中的作用以及一些基础规范。
一、为何要进行数仓分层
数据仓库分层的设计是现代数据体系建设的基石,数仓分层的核心价值在于通过系统化的结构设计,将原本复杂的数据处理流程模块化、标准化,构建起清晰、高效、易维护的数据链路。合理的数仓分层主要有以下的几个关键好处:
·1 清晰数据结构,简化数据血缘追踪
数据从进入数仓开始到治理完成的整个过程划分如ODS、DWD、DWS、ADS等层次,每个层次都被赋予了明确的职责范围,一但治理过程中出现问题,开发人员能够快速的根据分层脉络追溯问题源头,评估影响范围等。
·2 减少重复开发,统一数据口径
通过开发通用的中间层数据(如DWD层进行明细表构建,DWS层汇聚基础指标)可以减少各个业务块或项目之间的重复数据治理开发工作,有效降低数据治理成本。同时,整个集群内部使用的都是同一来源的模型表,一定程度上解决了数据口径不一致的问题,有效避免了"各说各话"的窘境。
·3 降低数据治理难度
正因为有了明确的数仓分层,每一层都只需要专注于单一、具体的加工环节,实现"分而治之"将复杂的问题简单化,有效的降低了整个数仓的开发难度,同时当某个环节出错时,只需从该层开始修复即可,无需改动整个数据处理流程,大大的减少了系统的维护成本。
·4 减少数据源数据变更或异常带来的冲击
数仓通过ODS层和DWD层对上游业务进行了隔离和抽象,当上游数据发生变更(如表结构变更,字段更新等)其影响通常会被限制在数仓的底层,对于上游的应用以及数据分析师的使用这种下游的变更是趋向"无感"的,一定程度上提高了数仓的稳定性。如图1.4.1
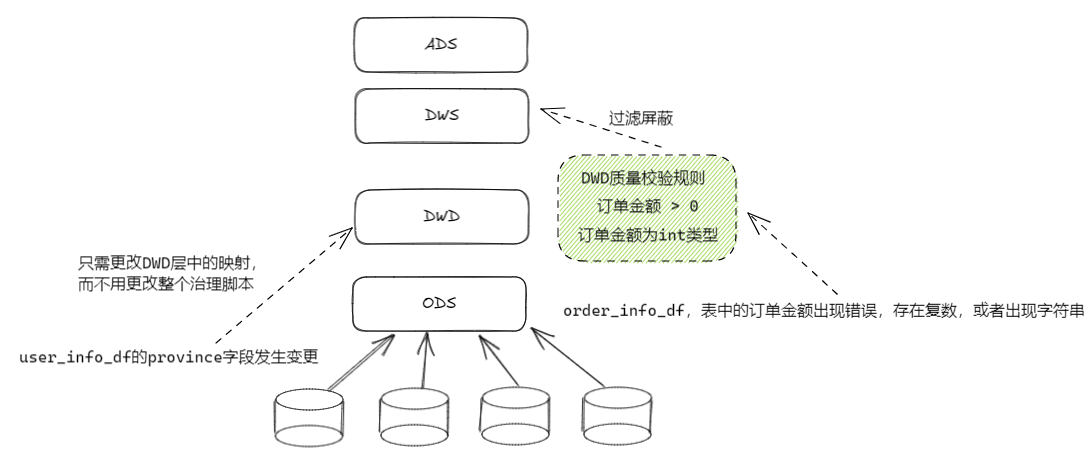 图1.4.1
图1.4.1
二、数据仓库的分层
参考阿里数仓分层架构,大致分为数据贴源层(ODS)数据公共层(CDM)数据应用层(ADS)其中数据公共层又划分有维度层DIM、明细数据层DWD、汇总数据层DWS三层。接下来会一一对每层进行阐述
·1 数据贴源层(ODS)
数据引入层(Operation Data Store)也常被叫作数据贴源层是整个数据仓库架构中的最底层,负责将原始数据几乎无修改的接入到数据仓库中,该层的数据结构等应与数据源保持一致,作为整个数据仓库的开始,同时也起到数据源隔离的作用。
在ODS层的设计中应区分增量存储/全量存储以及需要获取历史快照的情况下进行的拉链存储。
·增量存储:以天(固定时间)为单位的增量存储,以业务日期作为分区,每个分区存放日增量的业务数据,适合交易、日志等事务性较强的表。
·全量存储:以业务日期作为分区,每个分区存放截止到业务日期为止的全量业务数据,适合小数据量的缓慢变化维度数据。
·拉链存储:通过增加拉链起始时间和结束时间,保存历史变更状态,解决缓慢渐变维问题。
经验分享:
1.在该层可以优先以增量形式接入保存,避免每次/定期全量数据导入带来的采集压力。接入增量形式后再通过关联拼接的方法保留当前未发生变更和当日新增及更新的数据,形成最新的全量表,全量表的生命周期可以根据需要设定在一个较短的时间(无拉链需求的情况下),降低存储成本。
2.在ODS层表命名的规范应尽量保持与业务系统一致,同时尾部增加而外标识如di/df/st等来区分增量/全量表。
·2 数据公共层(CDM)
数据公共层是整个数仓的核心部分,负责存放明细事实数据、维表数据及公共指标汇总数据。整个CDM层又划分又三个子层:
·2.1 维度层(DIM)
维度层并行与DWD层,主要负责描述业务实体的相关维度信息,诸如用户属性、商品分类、省份城市,政务领域可能还会细化到具体区划等地域信息。
·2.2 明细数据层(DWD)
DWD层承接ODS层数据,基于业务特点构建最细粒度的明细事实表,该层主要解决数据质量问题包括对ODS层数据进行过滤、转换、异常值处理、Json拉平等操作。模型粒度应与ODS层保持一致。
经验分享:该层中允许进行一些冗余存储,便于减少后续使用中的关联操作,在政务领域中有些业务场景下不需要复杂的聚合加工逻辑,在该层把需要的信息提前关联,简化后续的加工步骤即可透出服务。
·2.3 汇总数据层(DWS)
DWS层会基于主题形成业务宽表,同时作为轻度汇总层,会对DWD层进行一些初步的聚合工作,以便于后续ADS层的上卷下钻等统计分析工作。
经验分享:如果业务场景中有大量标签指标开发工作且标签复杂度较低,可以在此层进行开发存储,形成类似标签指标空间。统一开发、统一存储。上层各应用再根据需要从此空间出,对应需要的标签指标,这样一是可以提高标签指标的复用性减少重复开发。二是可以控制对不同的应用指定透出哪些标签指标信息,便于权限管控。
·3 数据应用层(ADS)
数据应用层根据CDM层加工生成,也是数仓中的顶层,这一层直接面向应用,提供包括数据报表、数据分析、数据产品等个性化服务需求。常见的一些业务发展类指标也可在此层进行统计。以电商数据为例,CDM层中可能统计出了某地区的日销售额,ADS层可能会进行上卷统计对应年/月/周的销售额度。
经验分享:ADS层的核心特点是与业务需求高度贴合,下游可能是一些业务数据库(比如Mysql、RDS、polardb等)所以该层还可能涉及到一些数据格式或表结构的更改以适应下游需求。比如有些标签指标为了便捷存储在数仓中,会利用bitmap格式进行存储,在该层需要转换成常规的行/列存储或者下游数据库要求的格式进行存储和同步。
三、数据仓库建设规范
良好的数据仓库架构往往伴随着严格且全面的数仓建设规范,这里仅针对个人感觉较为重要的几条规范进行分享
1)整个数仓中禁止反向开发或反向依赖,比如DWS开发完毕后,DWD层中反向依赖DWS的结果表。包括同级依赖原则上也应该尽量避免。
2)原则上ODS层的表仅能被DWD应用,后续各层应避免直接使用ODS层表。
3)建表时应避免大范围建设无生命周期的表,应根据数据的历史价值和使用频率以及表的类型合理设置生命周期。可以参考阿里生命周期建设等级(P0\P1\P2\P3)
|----|-----------------------|---------------------|
| 等级 | 数据类型描述 | 典型数据示例 |
| P0 | 非常重要的且不可恢复的主题域数据或应用数据 | 重要的交易、日志数据、集团KPI数据等 |
| P1 | 重要且不可恢复的业务或应用数据 | 重要的业务产品数据 |
| P2 | 重要且可恢复的业务或应用数据 | ETL产生的中间过程数据 |
| P3 | 不重要的业务或应用数据 | 其余不重要可恢复数据 |
[生命周期管理]
4)应规定统一的命名规范,名称要言简意赅,便于使用者理解同时减少开发者开发过程中的命名难度。
- 数仓中进行模型建设时,尽可能的将重复复杂的处理逻辑下沉至数仓底层,提高数据的复用性降低开发成本。
6)健全良好的代码评审机制,可以有效的提高代码逻辑的正确性,同时可以甄别出部分执行性能较低的代码进行整改,提升整体运行效率。
四、数据仓库建设小结
阿里巴巴的OneData方法论未数据仓库的分层提供了详细的理论指导和建设框架,本文也基于此方法论进行了一些个人的认知分享。然而在实际工作中数据仓库的建设并不局限于某一种具体框架,企业应根据自身的业务特点和数据规模情况,灵活调整出最适合自身需求的数据架构,秉持着"参考但不盲从"的思想,构建出真正适合自身情况的数仓体系。