豆瓣电影数据爬虫分析:基于 Python 的豆瓣电影数据可视化分析系统
一、项目背景与目标
在影视行业数字化发展的背景下,豆瓣电影作为国内主流的电影评分与评论平台,沉淀了海量的电影数据。本项目旨在基于 Python 构建一套豆瓣电影数据可视化分析系统,通过数据爬取 - 清洗 - 分析 - 可视化的全流程,挖掘电影评分分布、类型趋势、导演 / 演员影响力、制片地区分布等核心信息,既为电影爱好者提供数据参考,也为行业从业者提供趋势洞察。
项目最终实现的核心能力:
- 自动化采集豆瓣电影多维度数据(基础信息、评分、评论、影片详情等);
- 结构化存储数据并完成清洗预处理;
- 针对核心维度(导演 / 演员、地区、类型、评分)做统计分析;
- 基于 Echarts/Matplotlib/Seaborn 实现交互式可视化展示。
二、核心数据维度说明
爬取的豆瓣电影核心字段如下(涵盖基础信息、详情、评论三大类):
| 字段分类 | 具体字段 | 说明 |
|---|---|---|
| 基础信息 | 电影名、评分、封面图、详情 URL、上映时间 | 核心标识与基础属性 |
| 制作信息 | 导演、主演、类型、制片国家 / 地区、语言、片长 | 影片制作维度特征 |
| 评价信息 | 星星评分比例、评价人数、前五条热评、评论时间 | 观众反馈维度 |
| 补充信息 | 电影简介、预告片、5 张详情图片 | 内容补充维度 |
三、核心技术实现流程
3.1 数据采集:豆瓣电影数据爬取
3.1.1 爬取逻辑
通过 Requests 库请求豆瓣电影列表页与详情页,结合 BeautifulSoup 解析 HTML 结构,提取目标字段;针对数组类型字段(导演、主演、类型等)做格式化处理,最终将数据标准化为可存储的结构。
3.1.2 核心爬取代码(优化版)
python
import requests
import re
import json
import random
from bs4 import BeautifulSoup
# 请求头(模拟浏览器,避免反爬)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
def crawl_movie_data(detailUrls, moveisInfomation):
"""
爬取豆瓣电影详情数据
:param detailUrls: 电影详情页URL列表
:param moveisInfomation: 列表页提取的基础信息列表
:return: 结构化的电影数据列表
"""
result_list = []
for i, move_info in enumerate(moveisInfomation):
try:
result_data = {}
# 列表页基础信息提取
result_data['detailLink'] = detailUrls[i] # 详情页URL
result_data['directors'] = ','.join(move_info['directors']) # 导演(转字符串存储)
result_data['rate'] = move_info['rate'] # 评分
result_data['title'] = move_info['title'] # 影片名
result_data['casts'] = ','.join(move_info['casts']) # 主演(转字符串存储)
result_data['cover'] = move_info['cover'] # 封面图URL
# 详情页深度信息提取
detail_res = requests.get(detailUrls[i], headers=headers, timeout=10)
detail_res.encoding = 'utf-8'
soup = BeautifulSoup(detail_res.text, 'lxml')
# 上映年份(正则提取)
year_elem = soup.find('span', class_='year')
result_data['year'] = re.findall(r'[(](.*?)[)]', year_elem.get_text())[0] if year_elem else ''
# 影片类型
type_elems = soup.find_all('span', property='v:genre')
types = [elem.get_text() for elem in type_elems]
result_data['types'] = ','.join(types)
# 制片国家/地区
country_elem = soup.find_all('span', class_='pl')[4].next_sibling.strip()
country = [c.strip() for c in country_elem.split('/')]
result_data['country'] = ','.join(country)
# 影片语言
lang_elem = soup.find_all('span', class_='pl')[5].next_sibling.strip()
lang = [l.strip() for l in lang_elem.split('/')]
result_data['lang'] = ','.join(lang)
# 上映时间(正则提取日期)
uptime_elems = soup.find_all('span', property='v:initialReleaseDate')
uptime_str = ''.join([elem.get_text() for elem in uptime_elems])
uptime = re.findall(r'\d*-\d*-\d*', uptime_str)[0] if uptime_str else ''
result_data['time'] = uptime
# 影片时长(无数据则随机填充合理范围)
runtime_elem = soup.find('span', property='v:runtime')
if runtime_elem:
result_data['movieTime'] = re.findall(r'\d+', runtime_elem.get_text())[0]
else:
result_data['movieTime'] = str(random.randint(80, 180)) # 修正原代码moveiTime拼写错误
# 评价人数
comment_len_elem = soup.find('span', property='v:votes')
result_data['comment_len'] = comment_len_elem.get_text() if comment_len_elem else '0'
# 星星评分比例
star_elems = soup.find_all('span', class_='rating_per')
stars = [elem.get_text() for elem in star_elems]
result_data['starts'] = ','.join(stars)
# 影片简介
summary_elem = soup.find('span', property='v:summary')
result_data['summary'] = summary_elem.get_text().strip() if summary_elem else ''
# 前五条热评(结构化存储)
comments = []
comment_info_elems = soup.find_all('span', class_='comment-info')[:5]
comment_content_elems = soup.find_all('span', class_='short')[:5]
for idx, (info_elem, content_elem) in enumerate(zip(comment_info_elems, comment_content_elems)):
comment = {}
comment['user'] = info_elem.contents[1].get_text() if len(info_elem.contents) > 1 else ''
comment['star'] = re.findall(r'(\d*)', info_elem.contents[5].attrs['class'][0])[7] if len(info_elem.contents) > 5 else ''
comment['time'] = info_elem.contents[7].attrs['title'] if len(info_elem.contents) > 7 else ''
comment['content'] = content_elem.get_text()
comments.append(comment)
result_data['comments'] = json.dumps(comments, ensure_ascii=False)
# 5张详情图片
img_elems = soup.select('.related-pic-bd img')
img_list = [elem['src'] for elem in img_elems[:5]]
result_data['imgList'] = ','.join(img_list)
result_list.append(result_data)
except Exception as e:
print(f"爬取第{i}条数据失败:{str(e)}")
continue
return result_list3.1.3 数据存储
爬取完成后,将结构化数据同步存储至CSV 文件 与MySQL 数据库,并记录爬取页数(避免重复爬取),核心逻辑:
- CSV:利用 Pandas 的
to_csv方法,指定编码为utf-8-sig(解决中文乱码); - MySQL:通过
pymysql库建立连接,批量插入数据(提升效率)。
3.2 数据结构化:Pandas 数据框构建
将爬取并清洗后的数据转换为 Pandas DataFrame,方便后续分析;修正原代码中 Pandas 别名不规范(ps改为通用的pd)、字段拼写错误等问题:
python
from . import homeData
import pandas as pd
# 构建DataFrame(标准化字段名与顺序)
df = pd.DataFrame(
homeData.getAllData(),
columns=[
'id', 'directors', 'rate', 'title', 'casts', 'cover', 'year', 'types',
'country', 'lang', 'time', 'movieTime', 'comment_len', 'starts',
'summary', 'comments', 'imgList', 'movieUrl', 'detailLink'
]
)
# 数据清洗:空值填充、类型转换
df['rate'] = pd.to_numeric(df['rate'], errors='coerce').fillna(0) # 评分转数值,空值填0
df['comment_len'] = pd.to_numeric(df['comment_len'], errors='coerce').fillna(0) # 评价人数转数值
df['movieTime'] = pd.to_numeric(df['movieTime'], errors='coerce').fillna(0) # 时长转数值3.3 数据分析:核心统计函数实现
针对导演 / 演员作品数量、制片地区分布等核心维度,实现统计函数,为可视化提供数据支撑。
3.3.1 演员参演电影数量统计
python
def get_actor_movie_count():
"""
统计参演电影数量TOP20的演员
:return: 演员名列表、对应作品数量列表
"""
# 拆分演员字段(原存储为逗号分隔字符串)
actor_series = df['casts'].str.split(',', expand=True).stack()
actor_count = actor_series.value_counts() # 统计每个演员出现次数
top20_actors = actor_count[-20:] # 取TOP20
# 拆分x/y轴数据
x = top20_actors.index.tolist()
y = top20_actors.values.tolist()
return x, y3.3.2 导演执导电影数量统计
python
def get_director_movie_count():
"""
统计执导电影数量TOP20的导演
:return: 导演名列表、对应作品数量列表
"""
# 拆分导演字段(原存储为逗号分隔字符串)
director_series = df['directors'].str.split(',', expand=True).stack()
director_count = director_series.value_counts() # 统计每个导演出现次数
top20_directors = director_count[-20:] # 取TOP20
# 拆分x/y轴数据
x = top20_directors.index.tolist()
y = top20_directors.values.tolist()
return x, y3.3.3 制片地区分布统计
python
def get_country_distribution():
"""
统计各制片地区的电影数量
:return: 地区列表、对应数量列表
"""
# 拆分地区字段(原存储为逗号分隔字符串)
country_series = df['country'].str.split(',', expand=True).stack()
country_count = country_series.value_counts()
# 拆分x/y轴数据
x = country_count.index.tolist()
y = country_count.values.tolist()
return x, y3.4 数据可视化
基于上述统计函数的结果,结合 Echarts(前端交互式可视化)、Matplotlib/Seaborn(Python 静态可视化)实现多维度展示:
- 导演 / 演员 TOP20:横向柱状图(对比数量差异);
- 制片地区分布:饼图(占比展示);
- 电影评分分布:直方图(评分区间分布);
- 类型与评分关联:热力图(不同类型电影的评分均值);
- 评论数与评分关联:散点图(分析热度与口碑的关系)。
示例(Matplotlib 实现导演 TOP20 可视化):
python
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False
# 获取统计数据
directors, counts = get_director_movie_count()
# 绘制横向柱状图
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(directors, counts, color='#1f77b4')
ax.set_xlabel('执导电影数量')
ax.set_ylabel('导演')
ax.set_title('豆瓣电影导演执导数量TOP20')
plt.tight_layout()
plt.savefig('director_top20.png', dpi=300)
plt.show()四、项目总结与拓展
4.1 项目亮点
- 全流程自动化:从数据爬取、清洗到分析可视化,实现端到端自动化;
- 数据标准化:统一字段格式,处理空值 / 异常值,保证分析准确性;
- 多维度分析:覆盖基础信息、制作维度、观众反馈等核心维度;
- 可视化交互性:结合 Echarts 实现前端交互式展示,支持自定义筛选。
4.2 可拓展方向
- 反爬优化:加入 IP 代理池、请求延迟随机化,提升爬取稳定性;
- 更多维度分析:新增 "上映时间与评分""演员与评分关联" 等分析维度;
- 可视化升级:接入 Dash/Streamlit 构建 Web 可视化平台,支持实时查询;
- 数据挖掘:基于机器学习实现电影评分预测、类型推荐等功能。
五、技术栈总结
| 技术分类 | 核心工具 / 库 | 用途 |
|---|---|---|
| 数据采集 | Requests、BeautifulSoup、re | 网页请求、HTML 解析、正则提取 |
| 数据处理 | Pandas、NumPy | 结构化清洗、数值计算 |
| 数据存储 | CSV、MySQL(pymysql) | 本地 / 数据库存储 |
| 可视化 | Matplotlib、Seaborn、Echarts | 静态 / 交互式可视化 |
| 辅助工具 | json、random | 数据格式化、异常值填充 |
数据库表信息:


修改为自己的数据库主机名和账号密码:

启动项目:

服务端口:5000 http://127.0.0.1:5000
用户注册 http://127.0.0.1:5000/registry

用户登录
首页页面展示:

还有电影数据,包括电影名、评分、片场、预告片等数据。

查看电影预告片
电影搜索

电影产量分析

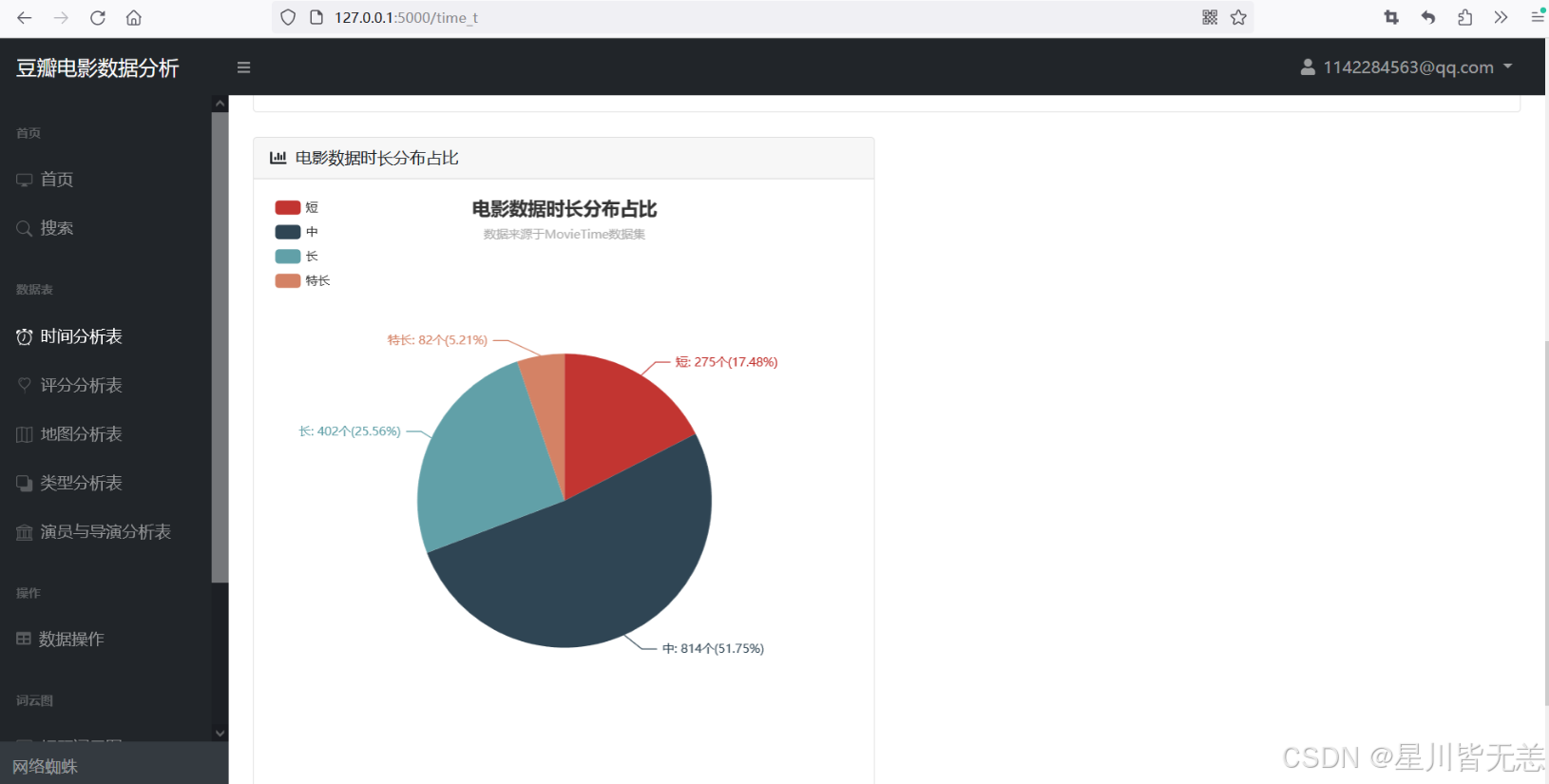
电影数据时长分布占比
电影评分统计分析


豆瓣评分星级饼状图、豆瓣年度评价评分柱状图

豆瓣电影中外评分分布图

数据视图切换


电影拍摄地点统计图

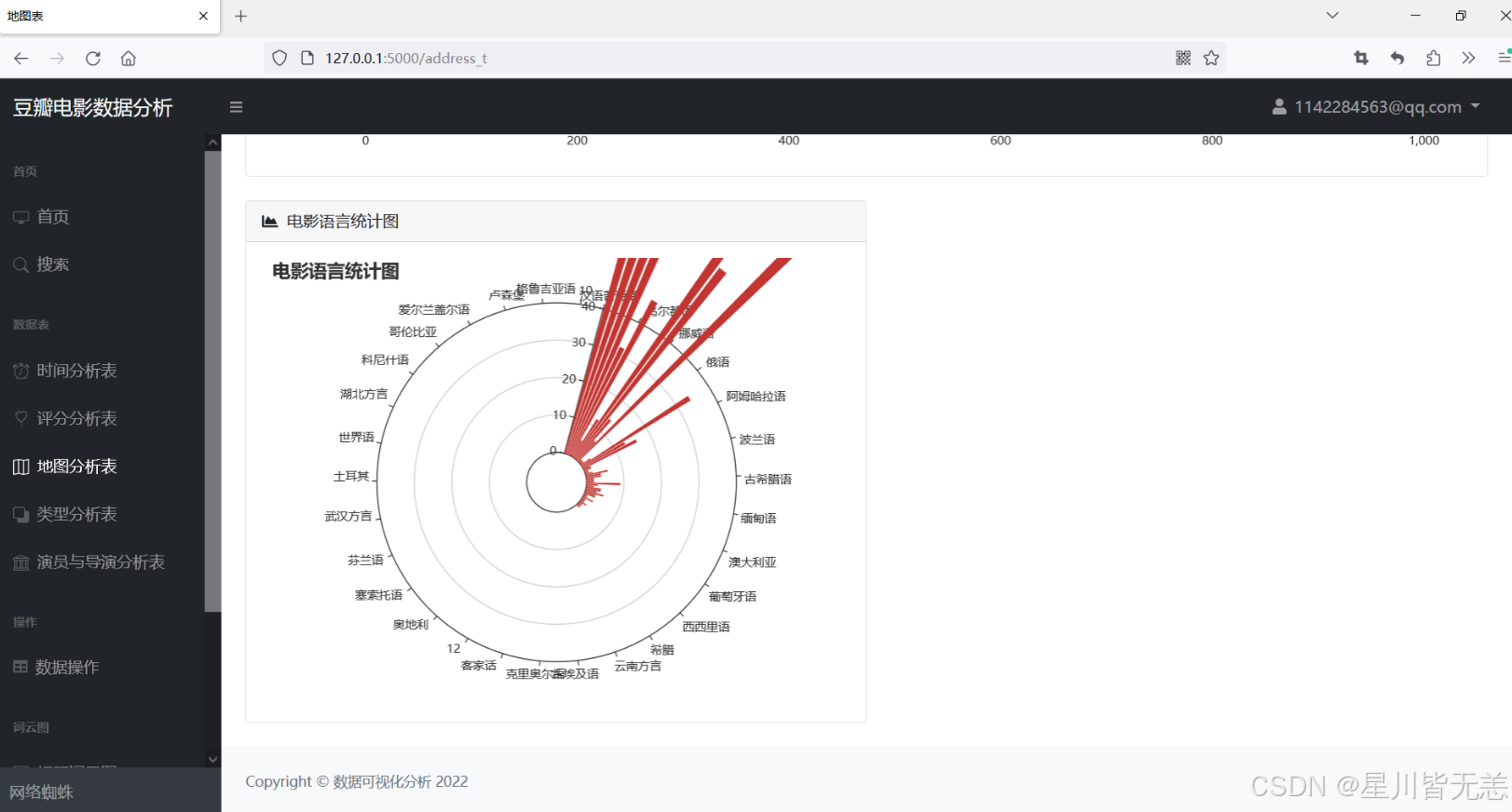
电影语言统计图
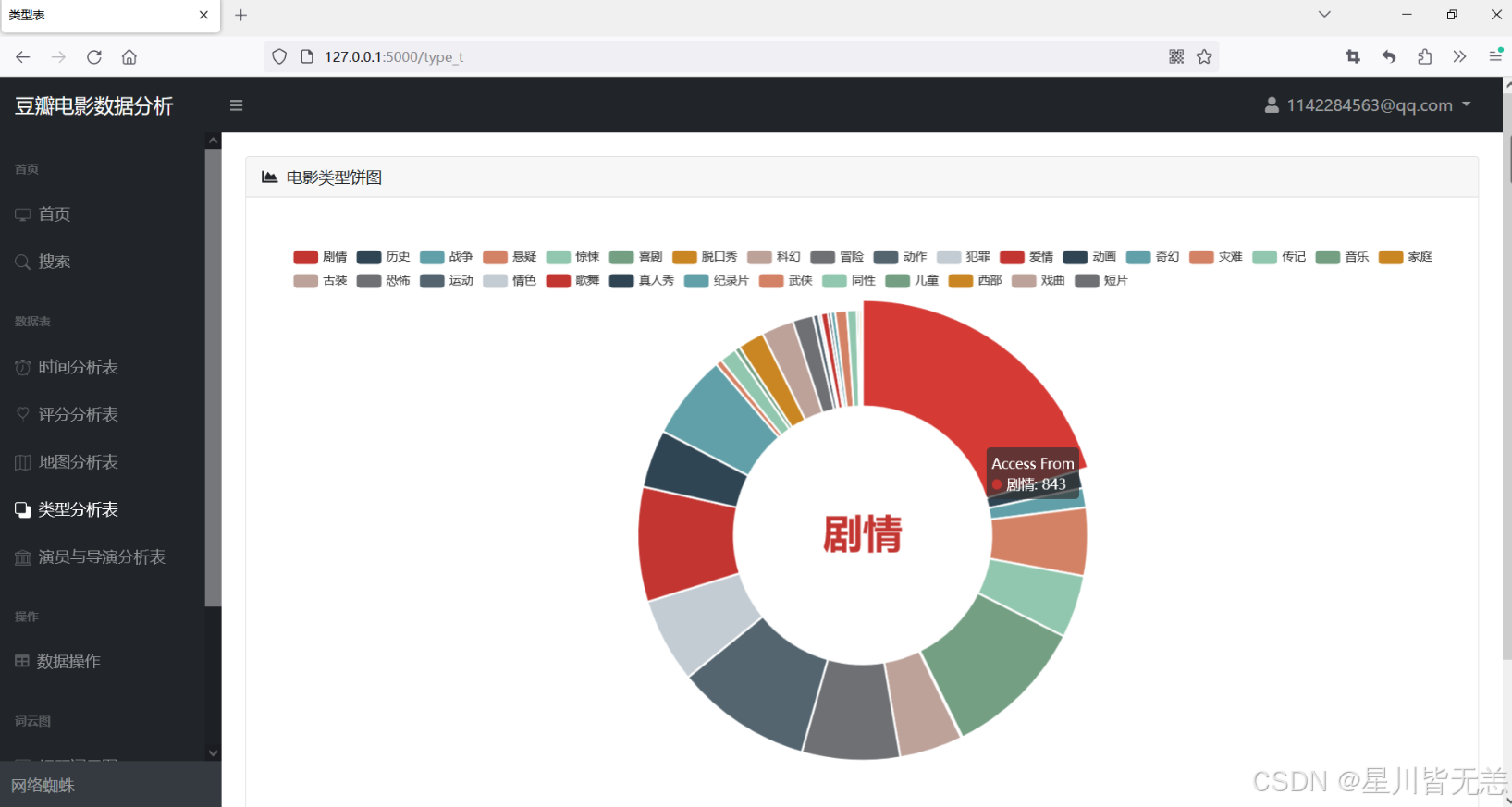
电影类型饼图
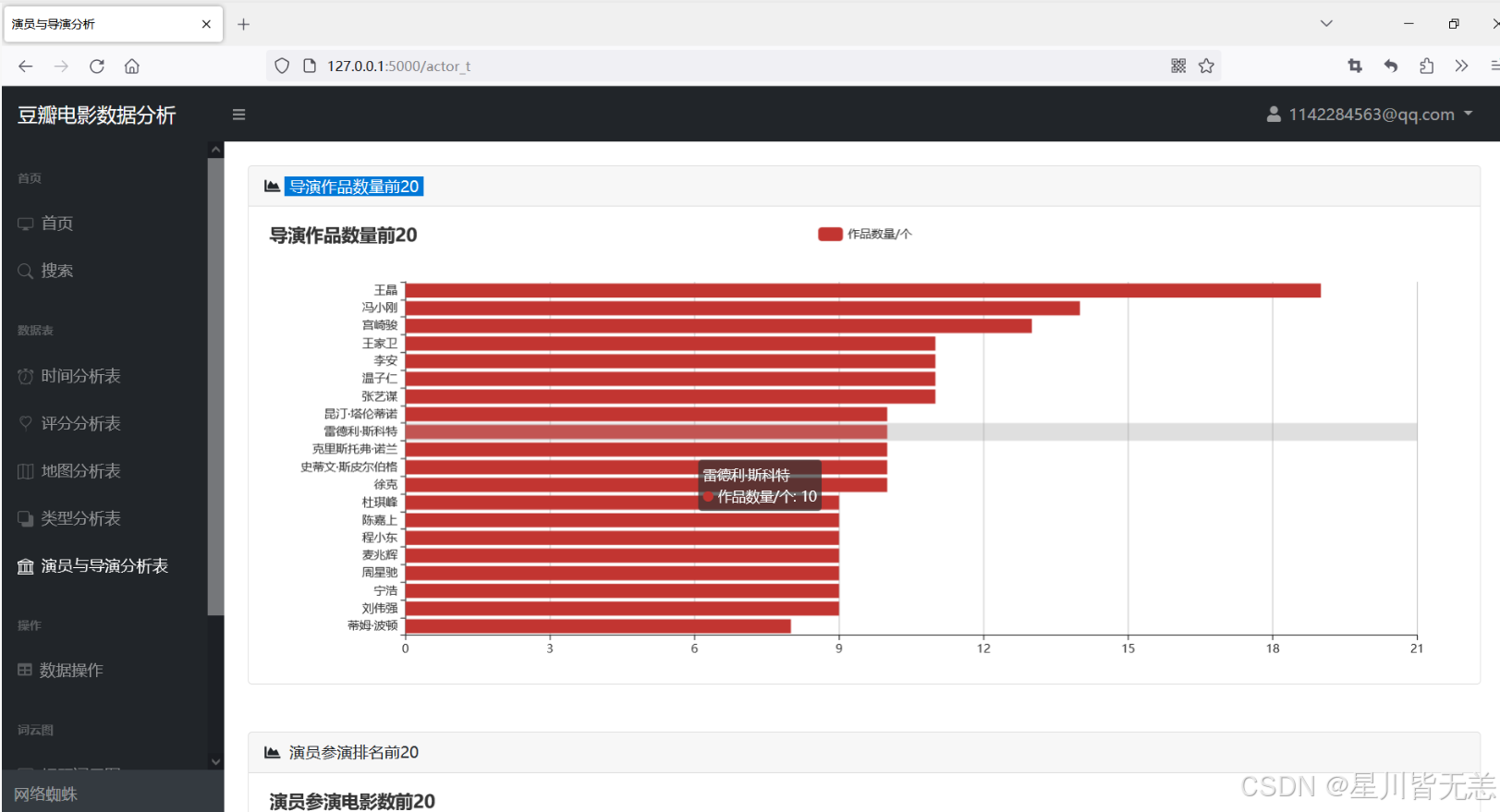
导演作品数量前20
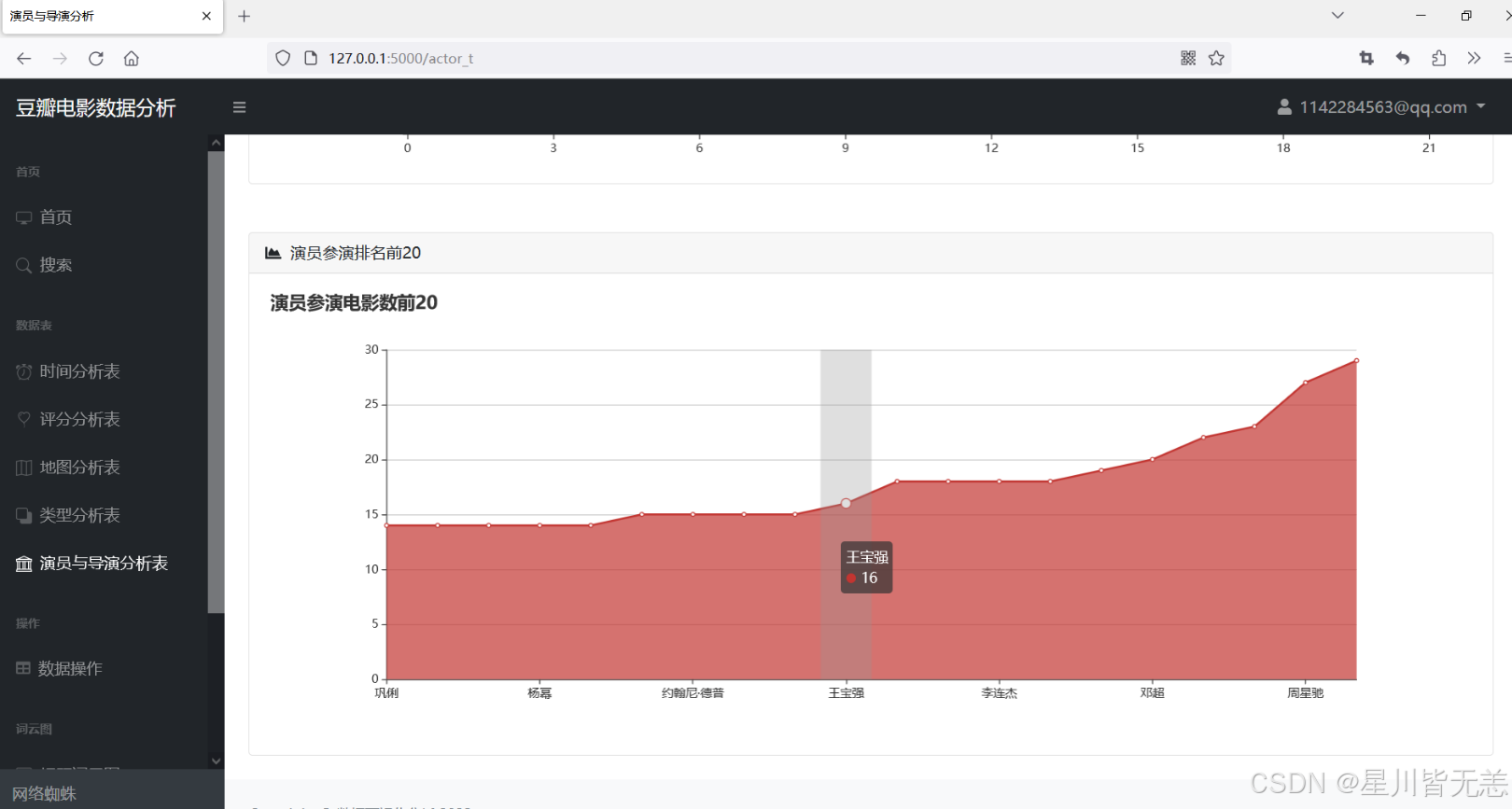
数据表操作

标题词云图

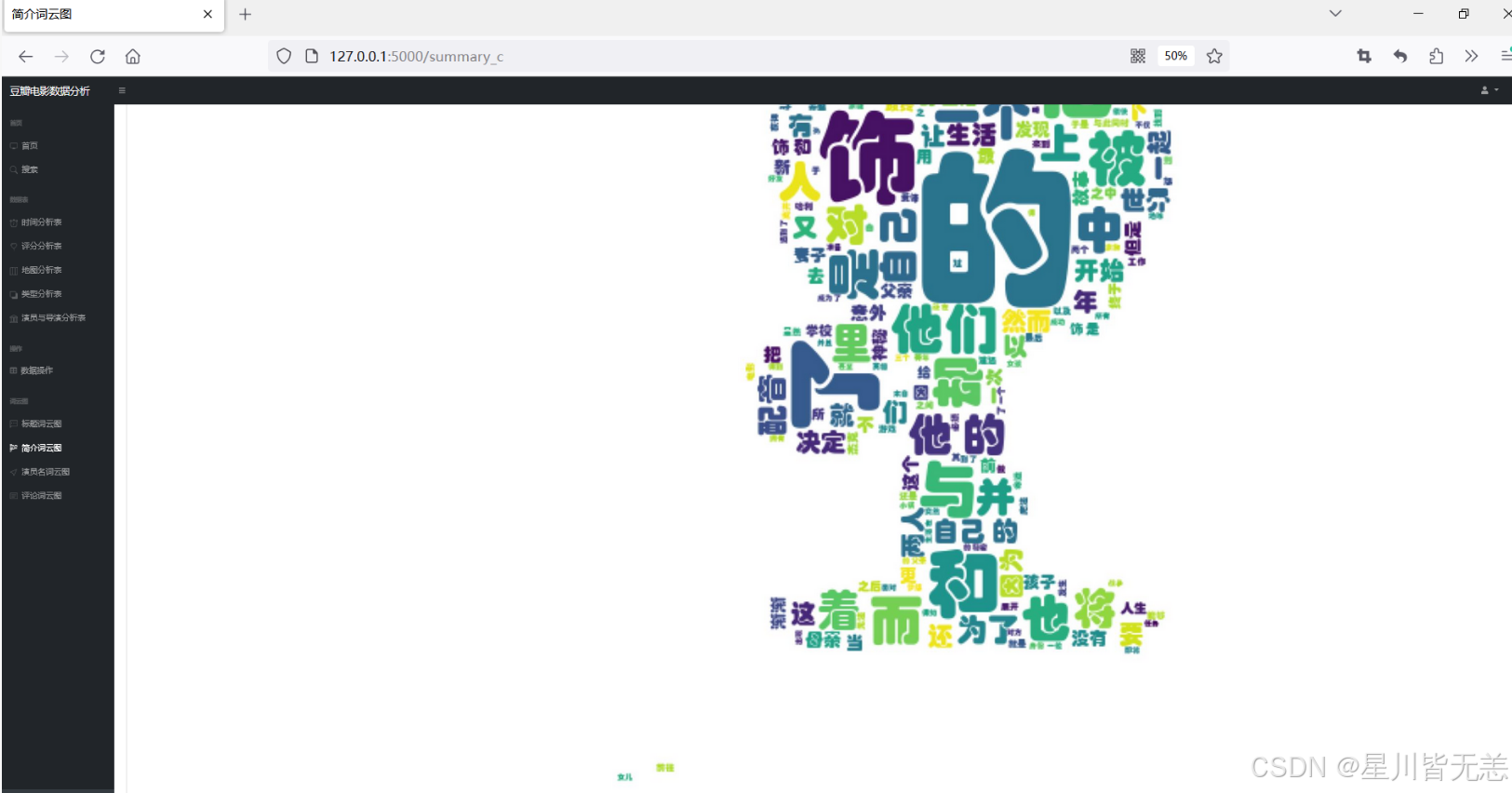
简介词云图
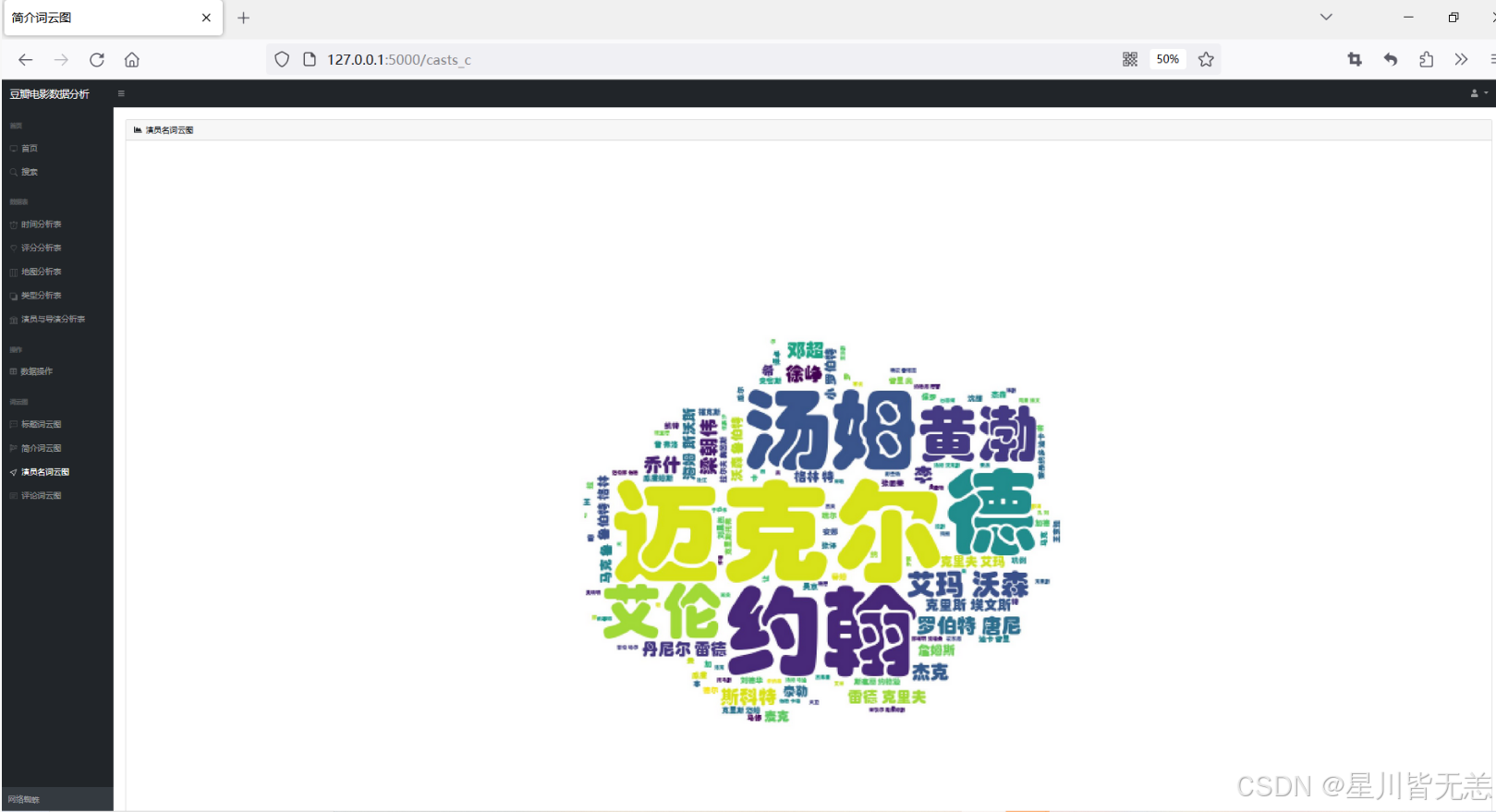
演员名词云图
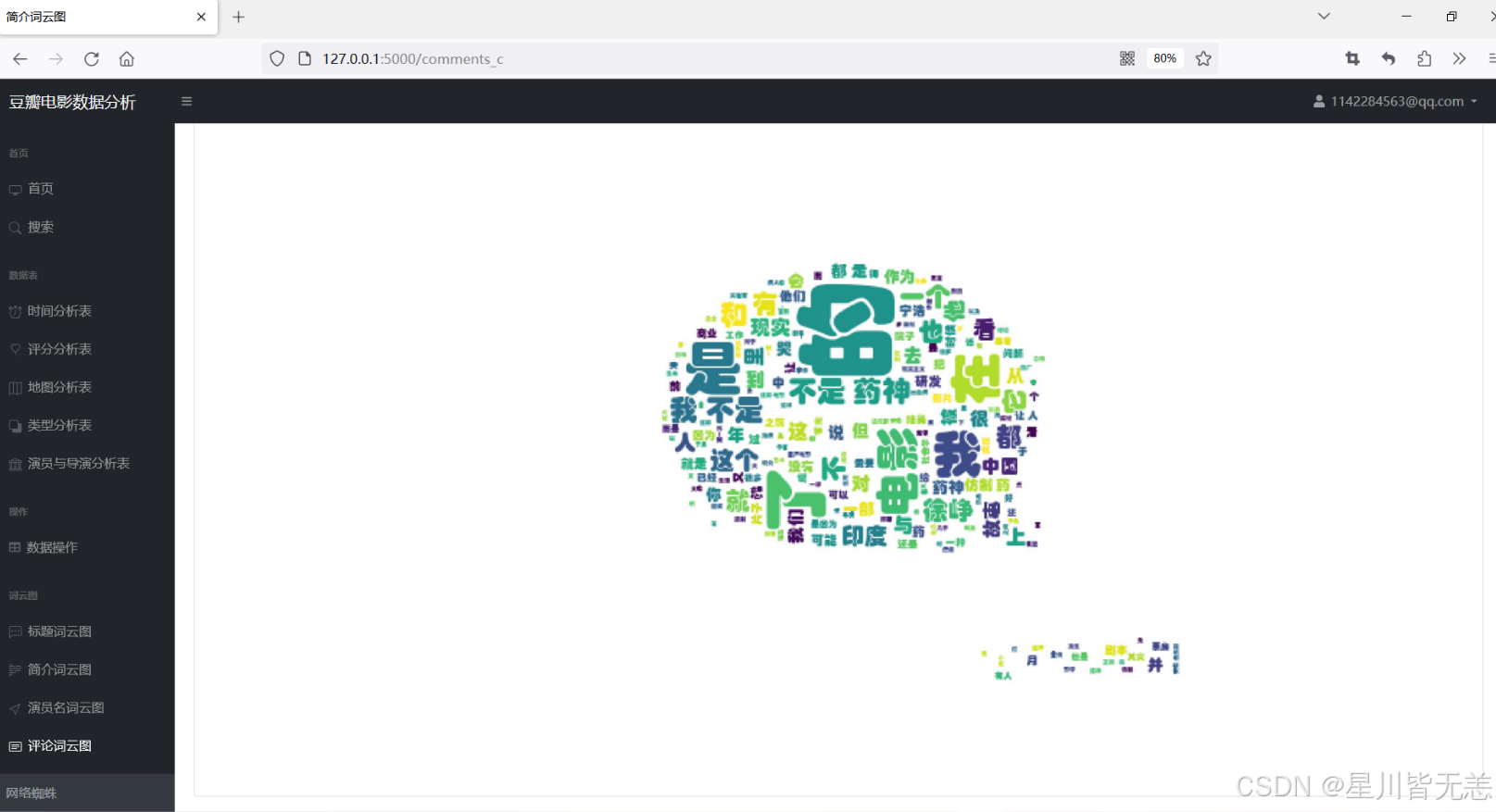
评论词云图

通过本项目,完整落地了 "数据采集 - 处理 - 分析 - 可视化" 的大数据分析流程,既掌握了 Python 爬虫与数据分析的核心技能,也实现了对豆瓣电影数据的深度洞察,为影视行业分析提供了可复用的技术框架。
项目源码文档解析等资料/解析/商业合作/交流探讨~等
可以评论留言或者私信 /添加下面个人名片
感谢各位的喜欢与支持!