0.Overview
让我们来实现一个为数据库内核服务的 cache。
本次 project 我们要实现 3 个 Task:
- 基于 ARC Algorithm 的调度器
- 一个磁盘调度器(Disk Scheduler)
- Buffer Pool Manager 和一大堆用于读写数据的 page_guard
本文不会给出具体的代码实现,而是用
///开头的注释替换对应代码部分,只给出等价的逻辑表述。
1.Task#1 - ARC 置换策略
一般来说适用于 cache 的策略有两种:LRU 和 LFU,前者淘汰最久未被访问的,后者淘汰访问频次最低的;但是这两种淘汰指标在不同场景下各有优势,而且 LFU 的实现难度比 LRU 会更高一些(因为要维护频次信息),因此 IBM 提出了兼顾"最近访问"以及"访问频次"的算法,即自适应(Adaptive)置换(Replacement)缓存(Cache)置换策略。
标准 ARC 算法维护以下四个变量:
- 最近访问列表(Most Recently Used)T1
- 最近频繁列表(Most Frequently Used)T2
- 记录了从 T1 中移除的项的列表 B1(MRU ghost),只存储键
- 记录了从 T2 中移除的项的列表 B2(MFU ghost),同上
我们要实现的 ArcReplacer 相较于标准 ARC 并没有做过多改变,所以具体流程不做过多阐述,课程 instruction 已经说的详尽到可以"directly transpiling English into C++ code"了。
但要注意的是,观察 BusTub 的类型设计我们不难发现,项目将 ArcReplacer 类型设计为了一个不持有数据、只专注置换策略实现的"视图类型";换言之,实际上的数据页的所有权属于别的类型。
因此 BusTub 有一个特殊的成员方法:SetEvictable(),它专门用于 pin 住某些页面,防止它们被置换策略淘汰。
这种设计与 std::hazard_pointer 异曲同工:因为数据库出于性能考虑必然是高并发设计,在多个线程同时访问一个页的时候总不能中途把这个页给淘汰掉了,因此必须得提供一个将其 pin 在内存中的手段,防止垂悬引用。
1.1 接口设计
我们被要求实现以下接口:
Size() -> size_t:返回当前可淘汰、且不在 ghost 列表中的 page 数量SetEvictable(frame_id_t frame_id, bool set_evictable):标记某个数据项不可/可以淘汰,同时要根据变更结果更新Size()的返回值RecordAccess(frame_id_t frame_id, page_id_t page_id):标记当前访问了哪个数据项,需要实现 cache hit、pseudo-hit 以及 cache miss 逻辑Evict() -> std::optional<frame_id_t>:根据置换策略淘汰数据项,并返回被淘汰的frame_idRemove(frame_id_t frame_id):上层调用者用于手动删除某些数据项,这一操作无视 ARC 置换策略,直接移除可驱逐的数据项
显然,我们要同时处理两种 id 类型:一个是页帧 frame_id_t,另一个是逻辑页 page_id_t。
页帧 frame_id 表示的是当前逻辑页所在的物理页帧,也就是用于存放 page 的 page,它一定在主存中;当数据项位于 MRU 或 MFU 中时,frame_id 与 page_id 构成一一对应关系,数据项被淘汰后与其对应的 frame_id 不再具有实际意义。
逻辑页 page_id 则是用于存放数据库数据的 page,它既可以存在主存里,也可以存在持久化存储当中。
RecordAccess 的置换策略实现直接阅读 writeup 对应部分(ARC Replacement Algorithm)即可。
淘汰策略写的比较隐晦,跟着一大段话塞到了 Implementation 里面;这里简单说一下。
调用 Evict() 时:
- 如果
MRU.size() < mru_target_size_,尝试从 MFU 的末尾开始逐出第一个 evictable_ 为 true 的数据项,成功被淘汰的项应该转移到对应的 ghost 列表中,并更新两个映射表;- 若找不到,则转而尝试淘汰 MRU 的末尾第一个满足条件的数据项;如果依然找不到,则返回
std::nullopt。
- 若找不到,则转而尝试淘汰 MRU 的末尾第一个满足条件的数据项;如果依然找不到,则返回
- 否则从 MRU 末尾开始淘汰,并且若 MRU 中没有可淘汰的,就尝试从 MFU 中淘汰;都找不到则返回
std::nullopt。
1.2 具体实现
代码预先定义了一些类型和成员,部分类型(例如 FrameStatus)不能说一点用没有,只能说是聊胜于无。
cpp
// 给懒得看代码的人复习一下
struct FrameStatus {
page_id_t page_id_;
frame_id_t frame_id_;
bool evictable_;
ArcStatus arc_status_;
// 还有一点:ArcStatus 是一个没有指定 underlying type 的 enum
// 所以它默认会用 int 类型表示(取决于具体编译器实现)
// 然后 arc_status_ 的位置被放在 bool 变量之后
// 这就导致 evictable_ 和 arc_status_ 之间会有 3 bytes 的 padding
// 虽然不影响 FrameStatus 的最终二进制大小,但如果之后往后面再加小于 3 bytes 的成员就会存在一点点空间浪费
FrameStatus(page_id_t pid, frame_id_t fid, bool ev, ArcStatus st)
: page_id_(pid), frame_id_(fid), evictable_(ev), arc_status_(st) {}
};FrameStatus 同时记录了 frame_id_t、page_id_t 和其他两个状态量,但当数据项处于 ghost 列表时对应的 frame_id 和 evictable_ 根本不起作用。
此外在 alive_map_ 和 ghost_map_ 中匪夷所思地用了一个 std::shared_ptr<FrameStatus> 存储状态量,实际上有些东西是完全不需要共享的,特别是 frame_id_t、page_id_t 和 ArcStatus 三个类型满足 std::trivially_copyable,将它们存储到一个指针中既没有必要,而且还增加了一次间接跳转开销,这对 CPU 缓存特别不友好。
根据我们上一节的分析可以发现:当 page 存在 mru_/mfu_ 中时,每个 page_id 与 frame_id 严格一一对应;所以 alive_map_ 和 mru_/mfu_ 只需要 evictable_ 标记它能否被驱逐。
但是在调用 Evict() 时,我们需要反向遍历 mru_/mfu_ 淘汰 page,此时必须取得被淘汰页面的两个 id,才能对应删除 alive_map_ 中的项,并将淘汰页面迁移到 ghost list 中;所以 mru_/mfu_ 得同时感知 frame_id 和 page_id。
最后,访问数据项时总是先去访问两个 std::unordered_map,所以我们要把位置信息存在这里;这包括一个 ArcStatus 和一个指向 mru_/mfu_ 结点的迭代器。
因此我们可以把一个 FrameStatus 类型拆解为以下两个类型定义:
cpp
struct FrameEntry {
frame_id_t frame_id_;
page_id_t page_id_;
bool evictable_{true};
// 因为 FrameEntry 只在数据项提升到 mru_/mfu_ 时被创建,因此 evictable_ 默认取 true 没什么问题
FrameEntry(frame_id_t fid, page_id_t pid) noexcept : frame_id_{fid}, page_id_{pid} {}
};
template <typename Entry>
struct PageRecord {
// 链表迭代器不会受到容器的非删除性更改(splice() 方法)影响而失效
typename std::list<Entry>::iterator item_;
ArcStatus arc_status_;
PageRecord(typename std::list<Entry>::iterator itm, ArcStatus st) noexcept : item_{itm}, arc_status_{st} {}
};
// 除非你喜欢多写一大堆尖括号和重复类型:PageRecord</* Entry */>( /* params... */ ),否则不要丢掉下面的 CTAD
template <typename It>
PageRecord(It, ArcStatus) -> PageRecord<typename std::iterator_traits<It>::value_type>;并把 ArcReplacer 中的成员定义修改一下:
cpp
class ArcReplacer {
// ...
std::list<FrameEntry> mru_{};
std::list<FrameEntry> mfu_{};
// 两个 ghost 不变,略
std::unordered_map<frame_id_t, PageRecord<FrameEntry>> alive_map_{};
std::unordered_map<page_id_t, PageRecord<page_id_t>> ghost_map_{};
// 注意到 PageRecord 总是作为 Map<id_t, PageRecord> 结构的值类型出现
// 显然在这种设计中,无论什么情况下,当我们拿到一个 PageRecord 时必然已知它的 frame_id 或 page_id
// 前者我们用不上 page_id,而后者我们已经知道了 page_id,因此我们根本没有必要额外在 PageRecord 中再额外存储 page_id
// 为了无锁访问 curr_size_(在 Size() 中),令其为原子量
std::atomic<size_t> curr_size_{0}; // 和 project0 同理,全程只需用 relaxed 的内存序
// 后面的成员也不变,下略
};此外,课程要求 ArcReplacer 的实现必须满足 thread-safe,为此成员定义中留了一把大锁 std::mutex;这点没什么好改的,因为 ArcReplacer 不像链表那样简单,里面涉及了多个哈希表和多个链表的状态处理,怎么想也没法用什么无锁架构设计。
即使惊为天人地手写了一个无锁链表和一个无锁哈希表,那也没法用于实现 replacer:因为单个表的读写原子性不能保证每次方法调用的完整原子性。
而且要说降低锁的粒度,把 std::mutex 换成 std::shared_mutex 同样不切实际:因为置换算法决定了访问行为也要更改类型内部状态,这意味着不管用什么锁,最后都一定要上一个 std::unique_lock,到头来还不如用最简单的 std::mutex + std::lock_guard。
总之,现在我们把所有状态都收束到一个最小范围,这非常有利于一些状态更改;例如在 RecordAccess() 中,page_id 可能与记录的不一致,这表示一次覆盖操作(没有在文档中指出,小坑);现在我们只需要更改一处数据就实现了记录的 page_id 的覆写:
cpp
void ArcReplacer::RecordAccess(frame_id_t frame_id, page_id_t page_id, [[maybe_unused]] AccessType access_type) {
std::lock_guard lock{latch_};
if (auto itr = alive_map_.find(frame_id); itr != alive_map_.end()) {
// cache hit
/// 根据 frame 所在位置更新 MFU 和 MRU
record.item_->page_id_ = page_id; // Note: page_id 可能会被覆盖
} else if (auto itr = ghost_map_.find(page_id); itr != ghost_map_.end()) {
// pseudo-hit
/// 更新 MFU 以及 alive_map_
/// 然后更新 mru_target_size_
} else {
// cache miss
/// 略,跟着 writeup 写就行,记得更新 curr_size_
}
}稍微抽象一下,合并一些重复代码,Evict() 可以这样写:
cpp
auto ArcReplacer::Evict() -> std::optional<frame_id_t> {
auto evict_from = [this](auto &src_list, auto &dest_ghost, ArcStatus dest_status) -> std::optional<frame_id_t> {
if (auto itr = std::find_if(src_list.rbegin(), src_list.rend(), [](const auto &frame) { return frame.evictable_; });
itr != src_list.rend()) {
/// 将 page_id 插入到 dest_ghost 首部,并且更新 ghost_map_
const auto frame_id = itr->frame_id_;
// 注意:ritr.base() 的返回值指向的是该迭代器指向的顺序下一个元素
src_list.erase(std::prev(itr.base()));
/// 从 alive_map_ 中删除 frame_id,更新 curr_size_
return std::make_optional(frame_id);
}
return std::nullopt;
};
std::lock_guard lock{latch_};
if (mru_.size() >= mru_target_size_) {
/// 先检查 MRU 能否淘汰,若不能则转去淘汰 MFU
}
/// 否则和上面的淘汰顺序相反,先淘汰 MFU,不行再淘汰 MRU
}其他方法就不用多说了,遵循:先从 map 中找出对应项、再提取出链表结点拿到数据、最后根据实际需求处理它即可。
具体怎么写就看怎么理解最开始的类型定义和个人风格。
1.3 测试
记得删掉 *_test.cpp 中的 DISABLED_ 前缀。
2.Task#2 - 磁盘调度器
在并发执行为主的数据库内核中,一个事务可能会触发多次数据 IO,并且在此过程中发起多次 IO 请求(Request);为了处理同一时刻多个到来的请求,就需要有一个单独的调度器负责响应。
总之 Task#2 的任务是要实现 DiskScheduler 类型;这个类型实际上是一个线程池,只不过文档中只要求它单线程执行任务。
BusTub 中预先定义了一个线程安全的共享队列 Channel,文档说不介意的话可以直接用它实现 request 的转发存储,但也可以选择自己实现一个。
Channel 实现得挺一言难尽的,就是一个简单到不能再简单的、用 std::mutex + std::condition_variable 保护的一个 std::queue;它不能被尽情压榨,所以我们不用它。
如果你喜欢,还可以手写一个无锁队列。
虽然 DiskScheduler 还允许我们不使用标准库的 promise/future 组件实现异步编程;但其实这两个组件蛮好的,没必要改;除非这里改用了 C++20 的异步协程设计。
比较有意思的一点:
std::future的含义其实来自于"期货",也就是经典笑话 Options, Futures and Other Derivatives 中的期货 Futures。当然
std::promise就只是"承诺"的意思。
看不懂下面的分析可以直接跳转到 [2.5 测试](#2.5 测试)。
2.1 接口设计
我们只被要求实现两个方法:
Schedule(std::vector<DiskRequest> &requests):接收一组调度请求,将它们按顺序转移给后台线程能够访问的队列中StartWorkerThread():核心函数实现,后台的工作线程在创建时应该执行这个函数,而且DiskScheduler对象被析构之前这个函数不应该返回
首先我们要注意到 DiskScheduler 还额外持有了一个 DiskManager 类型指针,这个类型才是负责实现 in-memory 到 on-disk 数据交互的类型。
DiskManager 使用了一个 std::filesystem::path 对象指向文件系统中的一个数据库持久化存储文件,并用 std::fstream 作为与该文件的 IO 接口,然后使用了一个 std::unordered_map 负责映射每个逻辑 page 在该文件中的偏移量;整体实现上相对简单,没有涉及多文件读写操作。
实验文档指出,当我们响应一个 request 时,我们需要调用 DiskManager 的 ReadPage() 或 WritePage();而观察 DiskManager 的实现不难发现,DiskManager 本身、及其派生类 DiskManagerUnlimitedMemory 的 IO 交互是全局互斥的(也就是关键代码部分会用一个 std::mutex 保护)。
尽管文档只要求我们用一个后台线程完成请求的调度与执行,但同时它也指出:在满足 as-if 的情况下,我们可以自行决定实现细节。
所谓的
as-if是指:只要不影响执行结果,那么具体的执行细节可以是任意的。换句话说,只要保证结果顺序与提交时的一致,我们甚至可以把执行流程通过打印机打印出来,再找一大堆人帮我们手算结果,最后通过终端交互把执行结果填回程序中。
具体到调度器的实现中,满足
as-if就是提交的每个DiskRequest在逻辑上看来,它们执行结束的顺序与提交时满足顺序一致性(Sequentially Consistent)。这是一个比较复杂的概念,具体可以参阅 C++ Memory Order 理论模型 中对于异步顺序模型的解释。
简而言之,异步顺序可以分为三种情况:happens-before 、sequenced-before 以及 synchronizes-with ;在我们的异步调度算法实现中,synchronizes-with 因为
DiskManager的特殊性,在所有线程中总是成立。
因此只有一个后台线程是不够的,我们要提升调度处理的并行程度;为此我们先分析一下每个请求的结构特征
实验中的 DiskRequest 的定义如下:
cpp
struct DiskRequest {
/**
* Pointer to the start of the memory location where a page is either:
* 1. being read into from disk (on a read).
* 2. being written out to disk (on a write).
*/
char *data_;
/** Callback used to signal to the request issuer when the request has been completed. */
std::promise<bool> callback_;
/** ID of the page being read from / written to disk. */
page_id_t page_id_;
/** Flag indicating whether the request is a write or a read. */
bool is_write_;
// 原先的布局非常难绷,因为有一些无意义且可消除的 padding,调整布局后按照原先的样子写个构造函数转发一下
DiskRequest(bool is_write, char *data, page_id_t page_id,
std::promise<bool> &&callback) noexcept(std::is_nothrow_move_constructible_v<std::promise<bool> >)
: data_{data}, callback_{std::move(callback)}, page_id_{page_id}, is_write_{is_write} {}
// 调整后可以消除掉 8 bytes 的 padding
};is_write_ 字段标识了当前 request 是读取(记作 R)还是写回(记作 W);无论是哪种操作,所需的数据都由字段 data_ 指出。
虽然写回时不需要可修改权限。
然后因为 DiskManager 的 ReadPage() 或 WritePage() 主要是互斥实现,因此任意一个 DiskRequest 在被响应时,一定独占整个 DiskManager 的操作窗口。
也就是说,全局任意时刻下,至多只有 1 个线程能够执行写回/读出的操作;因此调度器后台只有一个线程是没什么毛病的。
但是,我们不难注意到:任务队列和 DiskManager 不使用同一把锁(其实是废话,因为任务队列的线程安全性要我们自己维护);这也就意味着在访问任务队列和执行 IO 操作之间,会存在一个微小的线程调度间隙:后台线程刚刚让出了任务队列,而还没有执行到 IO 操作;显然在这期间无论是任务队列还是 DiskManager 都是没有上锁的状态。
这里假定了你不会用同一把锁同时锁定任务队列的访问,以及调用
ReadPage()或WritePage()的过程。
因此尽管 DiskManager 只允许一个线程执行 IO,我们依然可以开出 2 个后台线程,让它们先后从任务队列中取出 request,然后轮流等待 IO 锁,这样我们可以最大化降低 DiskManager 的空闲时间。
如果
DiskManager允许多个线程同时调用ReadPage()而不互斥,这里的线程数量就可以直接扩充为 CPU 核心数或更多。顺便一提,在最后的 benchmark 测试中,如果 IO 是真实有延时(1ms)而不是在内存中一样立即写入,那么线程数量必须增多才能提升吞吐量。
不过要牢记一点:调度优化的前提是满足 as-if 原则,也就是说对于某些 request,我们不能将它提升为并行执行。
这是因为虽然我们允许一个线程 A 拿到 request 后立即执行 IO,而另一个线程 B 拿到 request 后在 IO 入口等待,但在 A 退出 IO、B 进入 IO 之间,依然可能因为线程调度问题,导致 A 退出 IO 后重新拿到任务并再次进入 IO,而 B 仍在保持等待。
如果期间线程 A 拿到的 request 对线程 B 手中的 request 构成某种"关系依赖",就会打破我们的
as-if原则。所以调度最优化是一个非常难的事。
2.2 顺序依赖
as-if 原则的核心是解决这种情况下的顺序依赖问题;事实上,顺序依赖场景会导致 request 的执行退化为单线程。
对于任意两个相邻的 request,它们可以构成如下四种关系:
- RAR:读后读
- RAW:读后写
- WAR:写后读
- WAW:写后写
在这其中,RAR 不存在依赖关系;如果两个 request 指向同一个 page,则 WAW、WAR 和 RAW 必须顺序执行。
换言之,在最终的任务队列中,如果队首中对某个 page 的第一操作是 W,那么这个 W 操作一定也必须满足 happens-before 于队列中同一 page 的其他所有操作(即需要在两个操作之间插入"写屏障")。
因为 DiskManager 只有一个,因此在提交这个请求的线程中,sequenced-before 被 happens-before 保证成立;也即,排在这个 W 操作之后的、对于同一个 page 的其他操作一定晚于该 W 操作发生。
在
DiskRequest中,读/写的数据来源是一个已存在的指针data_,我们可以据此认为每次 R/W 的目的数据地址总是不同的;或者说可能相同,但出现相同本身是一次稀有事件(具体见 [Buffer Pool Manager 的分析](#Buffer Pool Manager 的分析))。因此还可以得到一个推论,即对于不同 page 的先 R 后 W,或先 W 后 R,它们总是不构成顺序依赖关系。
所以我们可以得到一个判定 request 存在顺序依赖性的充要条件:相邻的两个 request,它们的 page_id 如果相同,则不允许存在 W 操作。
相邻 request 这一概念只出现在这种情况:线程 A 从队列中拿走一个 request,而线程 B 想要从队列中再拿走一个 request;此时 B 需要用 A 刚刚拿走的 request 进行顺序依赖分析。
相邻的 request 在队列中的位置并不一定相邻。
若存在顺序依赖性,那么 B 必须挂起以等待 A 的 IO 结束(等价于插入一个屏障),否则 B 拿走 request 等待 IO。
当 B 拿走了 request 之后,线程 A 必须在拿走新 request 之前,用 B 的信息分析顺序依赖性。
显然我们要有一个唯一的、用于记录刚刚拿走了哪个 request 的变量。
我们将它定义为这样:
cpp
/** The request which is in flight (during in I/O process). */
struct RequestInFlight {
page_id_t page_id_;
bool is_write_;
RequestInFlight(const DiskRequest &req) noexcept : page_id_{req.page_id_}, is_write_{req.is_write_} {}
/** 相同 page_id 的操作:R-W, W-R, W-W 存在数据依赖 */
[[nodiscard]] bool irrelevant_to(const DiskRequest &next) const noexcept {
// 因为每一个 Request 都附带了一个 data pointer,所以不同 page_id 我们认为一定不存在依赖性
return page_id_ != next.page_id_ || !(is_write_ || next.is_write_);
}
};为了最大化吞吐,如果队首的 request 不满足顺序一致性,我们可以跳过它并尝试提前取出 request 队列中间的请求。
2.3 具体实现
回到 DiskScheduler 的实现,从上面的分析可以看出,如果我们想要最大化系统吞吐量,那么就需要对 request queue 进行依赖性分析。
而且不难注意到的是,每次访问 queue 之后,我们都要更新记录的 RequestInFlight 信息,所以我们可以如下的成员定义:
cpp
class DiskScheduler {
// ...
/* 由于 DiskManager 的并发语义设计,同一时刻至多只有一个线程能够执行 IO 操作
* 所以最多只需要 2 个线程就足够了,再多会导致无意义竞争 */
std::array<std::thread, 2> workers_;
// 如果队首 request 不满足需求,则尝试遍历列表找出下一个 request
std::deque<DiskRequest> request_pipe_{};
using ReadyRequest = std::deque<DiskRequest>::iterator;
std::condition_variable cond_var_{};
/* 由于互斥访问条件变量时总是要检查队列
* 所以这里使用同一把锁实现队列的保护以及条件变量的互斥访问 */
std::mutex latch_{};
/** 用于保护 inflight_ 的脏位标识,具体作用稍后再说 */
std::atomic<size_t> epoch_{0};
/** 如果请求队列中,前后两个 request 彼此无关,那么尽可能让它们"乱序发射" */
std::optional<RequestInFlight> inflight_{};
// 用于通知后台线程退出
bool quitting_{false};
// 为了方便查找下一个满足顺序一致性的 request,我们引入一个辅助方法
[[nodiscard]] auto Speculator() noexcept -> ReadyRequest;
}不得不吐槽的一点是,尽管 BusTub 中有一些实验性的 C++23 开发分支,但我们能写的实验代码被局限在了 C++17 中,这使得我们不能用 C++20 引入的
std::atomic::wait和std::atomic::notify组件,多少有点限制了并发表达。
Schedule() 方法的实现相当简单:上锁、将 requests 中的请求逐一移动 (注意:std::promise<bool> 是 move-only 类型)到 request_pipe_ 中、通知条件变量,然后退出函数。
复杂的地方在 StartWorkerThread() 中。
我们期望的行为是:多个 worker 线程并发尝试获取队列中的 request,拿到 request 后先通知其他线程现在的 RequestInFlight,然后放弃队列的独占,最后执行 IO 操作;当 IO 操作返回后,移除之前发布的 RequestInFlight。
此时出现了一个问题:RequestInFlight 只是简单地被保存在一个 std::optional 中,它不追踪自己是由哪个线程发布的。
而且我们希望吞吐量尽可能地高,因此另一个 worker 在拿到 latch_ 后,就会根据发布的 inflight_ 计算依赖性,如果依赖检查通过、
队列中的一个 request 被拿走(假定队列总是非空),这个 worker 也要通过 inflight_ 对外发布它拿到了哪个 request。
那么显然在 IO 操作返回后,线程没法知道 inflight_ 是否被修改,自然也不知道该不该将它移除,这是一个经典的 ABA 问题。
尽管 ABA 问题的主要语境是无锁数据结构。
为了解决这个问题,我们引入一个脏位标记:std::atomic<size_t> epoch_;它的具体作用是这样的:
cpp
void DiskScheduler::StartWorkerThread() {
do {
/// 上锁,等待条件变量,并且等待能拿到一个非空的 next_req
// 如果存在顺序依赖,那么线程不会离开 wait() 的范围,而是重新休眠
// 所以下面的 if 条件只需要简单检查队列是否为空即可
if (!request_pipe_.empty()) {
auto req = std::move(*next_req);
// 拿到一个新的 request,递增 epoch_ 获得一个独特标识
const auto epoch = epoch_.fetch_add(1, std::memory_order_release) + 1;
inflight_ = RequestInFlight(req);
request_pipe_.erase(next_req);
if (!request_pipe_.empty()) {
cond_var_.notify_one();
}
lock.unlock();
// 虽然此处的调度策略是基于 DiskManager 本身的互斥 IO 过程实现的
// 但不难知道,即使 DiskManager 的派生类的 IO 过程允许多个线程同时执行而不阻塞
// 这里的异步调度策略依然是安全的
/// 处理 IO,更新 req.callback_
// 设计中没说异常情况怎么处理,所以我们假装所有操作都满足 exception-free
// 非要说的话就是保持 StartWorkerThread 别在析构之前退出
// IO 操作结束后,与 epoch_ 进行一次 CAS,如果成功,表示在 IO 期间没有别的线程更改 inflight_
if (auto expected = epoch; epoch_.compare_exchange_strong(expected, epoch + 1, std::memory_order_acq_rel)) {
lock.lock();
// 同样的,CAS 成功 -> 上锁成功,这一过程之间也会存在调度间隙
// 所以要二次确认避免 pre_req_ 中途被修改
if (expected == epoch) {
// 如果 CAS 失败,expected 会被修改为 epoch_ 的实际值
// 此时会不等于我们记录的 epoch,直接退出进入下一迭代即可
inflight_.reset();
if (!request_pipe_.empty()) {
cond_var_.notify_one();
}
}
}
} else {
break;
}
} while (true);
}其中 Speculator() 负责从任务队列中乱序地提取一个不违背顺序一致性的 request,它的实现相当简单:如果 inflight_ 没有值,直接返回指向队首的迭代器;否则使用 std::find_if 遍历队列寻找第一个与 inflight_ 的 page_id 不同、或者与 inflight_ 不构成 RAW 或 WAR 或 RAR 关系的元素。
其他方法的实现都很简单,这里不做阐述。
2.4 Optimization (Optional)
值得我们注意的是,由于实验中大部分的磁盘管理器(例如 DiskManagerUnlimitedMemory)的实现都是互斥 IO,我们的乱序发射策略(out-of-order)被设计为至多使用 2 个后台线程;如果尝试将线程数量开到 2 个以上,那么会因为多个线程对应了同一个 inflight_ 数据,导致有些线程正在操作的数据被意外丢弃,因此会违背顺序一致性。
换句话说,如果 DiskManager 支持:并发读取、互斥写入(例如 DiskManagerMemory),那么我们就需要考虑扩展后台线程数量以提高读请求的吞吐量,但因为此时后台线程数量需要大于 2,我们在 2.3 中设计的异步调度模型就会失效。
实际上,此时的 IO 调度与 CPU 多级流水线的乱序发射异曲同工,只不过不同的地方在于,CPU 的 ROB(Reorder Buffer)是硬件实现的,我们只能用软件以及操作系统提供的锁实现;而且我们的 IO 调度中不存在假冒险。
顺便一提,上面实现调度策略其实是一种非常简单的 ScoreBoard 算法。
因此我们可以考虑重新设计一个调度算法,它能够提前预取任务队列中不违背顺序一致性的 request 的同时,还能支持 2 个以上线程的并发调度;在这种情况下,我们必须设计一种新的广播机制,能将多个 page 的读写操作信息广播给其他线程。
如果要分析一个 page 的读写冲突,我们只需要知道两个信息:是否有线程在读或有线程在写;其中读是可并发的,而写是独占的。
并且考虑到 page_id_t 实际上就是 int 的别名,而且短时间内发起的 request 不太可能超过 page 的数量,因此我们可以使用一个 uint32_t 类型的位向量作为读写冲突标识,其中最高位表示是否有线程在写,其他位表示共有几个线程在读。
其实
size_t也可以。
为此,我们可以参考 CPU 流水线的调度策略,引入一个基于 CAS 实现的无锁记分板(ScoreBoard)算法;其中的记分牌结构定义如下:
cpp
struct ScoreBoard {
using RWTag = size_t;
static_assert(sizeof(page_id_t) <= sizeof(RWTag));
std::atomic<RWTag> state_;
};我们可以这样实现读写冲突的广播:我们将每个 request 的 page_id_ 哈希映射到一个固定长度的哈希表中,这个哈希表的每个桶都是 ScoreBoard 类型。
哈希表的大小由 page_id_t 的位长决定:
cpp
class DiskScheduler {
// ...
// 不能太大,太大纯浪费空间,但太小会导致巨量哈希冲突
// 所以这里的大小自己权衡
static constexpr size_t SCOREBOARD_SIZE = 1 << (10 + static_cast<size_t>(sizeof(page_id_t) > 4));
static constexpr auto WRITER_MASK = static_cast<ScoreBoard::RWTag>(1) << ((sizeof(ScoreBoard::RWTag) * 8) - 1);
static constexpr auto READER_MASK = ~WRITER_MASK;
[[nodiscard]] static constexpr auto IndexOf(page_id_t page_id) noexcept -> size_t {
/// TODO: ...
}
std::vector<std::thread> workers_;
// ...
std::unique_ptr<ScoreBoard[]> scoreboard_{};
// ...
[[nodiscard]] auto Speculator() noexcept -> std::pair<ReadyRequest, size_t>;
}如果 request 是读操作,那么简单递增 state_ 后检查最高位 是否为 1,若是 1 则存在另一个线程宣称了该桶的写操作,放弃读尝试,并回撤操作;如果 request 是写操作,那么尝试直接对 state_ 做 CAS,使其最高位为 1,若成功表示写宣称成功,否则失败并放弃写尝试。
Speculator() 负责执行以上的查找和宣告逻辑,并且该函数返回后,StartWorkerThread() 会根据返回值判断查找是否成功,然后决定重新挂起还是进入 IO 调度。
这里有个关键点,是哈希函数 IndexOf() 的实现。
理论上,一个哈希函数应该对于一个整数的每个位都敏感,少数部分数据改变会导致结果的极大变化;但我们做的是 IO 调度,在实际 IO 调度中,我们更关心的、并且经常占据主导地位的一个性质,不是哈希冲突问题,而是空间局部性问题,尤其是当一个 page_id 指向的 page 共有 8KB 大小时。
我们可以大胆假设:在短时间内,多次 IO 访问实际上指向的是多个临近的 page_id,或者甚至是在对同一个 page 的访问(即所谓满足 zipfian 分布)。
所以我们的哈希函数应该将 page_id 的低位映射到相邻的桶中,这样我们自己在操纵 scoreboards_ 时也能满足空间局部性,高位则可以随便映射。
实际上,我们直接对 page_id 取 SCOREBOARD_SIZE 的模即可。
如果 SCOREBOARD_SIZE 选取的大小是 1024 或更高,很显然,在两次连续 request 发生时,上一个 request 的 page_id 相较于下一个的差值超过 1024 的情况是比较罕见的,更多情况下它们都会满足空间局部性。
因此我们没必要引入复杂的位扩散、雪崩操作等复杂的哈希逻辑,直接取模即可。
最后,由于记分板本身是无锁的,所以 IO 结束后我们直接根据哈希后的 page_id 定位对应的桶,然后用原子操作将我们的宣告清除即可;这无疑降低了锁的粒度。
既然记分板是无锁的,那么能否引入
std::shared_mutex(配合std::condition_variable_any)、并使用std::list作为任务队列,使得 request 的搜索本身(即Speculator()函数)也是并行的?答案是不太行,因为收益被
std::shared_mutex和std::list的负面效应抵消了。
2.5 测试
相较于实现复杂度,这个 Task 的测试用例就简洁太多了:只提供了一个最简单的测试用例;所以要完善地测试异步状态下的行为的话,需要自己补充一些测试用例。
当然了,BusTub 给我们写好的 Channel 也不是不能用,它本来就是一个阻塞式的共享队列,Schedule() 只需要不停往里面塞数据,而 StartWorkerThread() 不停往外读即可,全程只需要使用一个线程。
由于异步编程是一个比较出错的点,所以我们最好还是写一些详细的测试用例检查一下写好的类型能否正常工作,例如我自己追加了三个测试用例:
2.5.1 补充测试用例
虽然上面一大堆分析试图说明乱序调度是一种合理策略,但没有性能分析测试怎么也不是很有说服力。
基于我补充的三个测试用例,我分别进行了并发读、写和混合并发测试。
测试平台为 AMD Ryzen 5800H + docker;每个测试用例选取的 page 数量为 50000,随机数种子为 114514,线程数量为 std::thread::hardware_concurrency() / 2;访问列表生成方式见本节最末尾的测试用例代码。
这些测试用例所测试的类型,以及它们的测试结果分别如下。
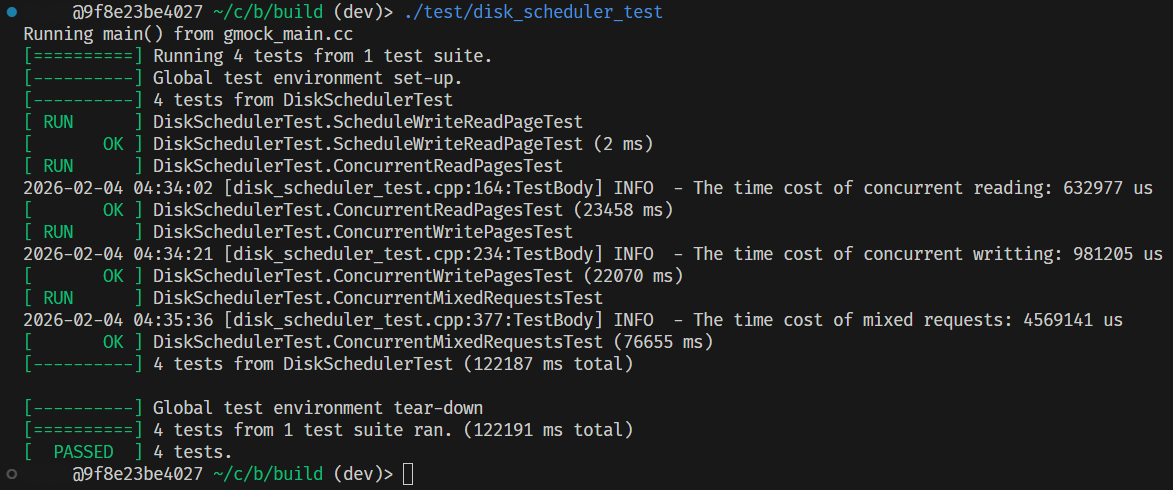
- 使用实验代码提供的
Channel实现的单线程线性(linearized)调度器:
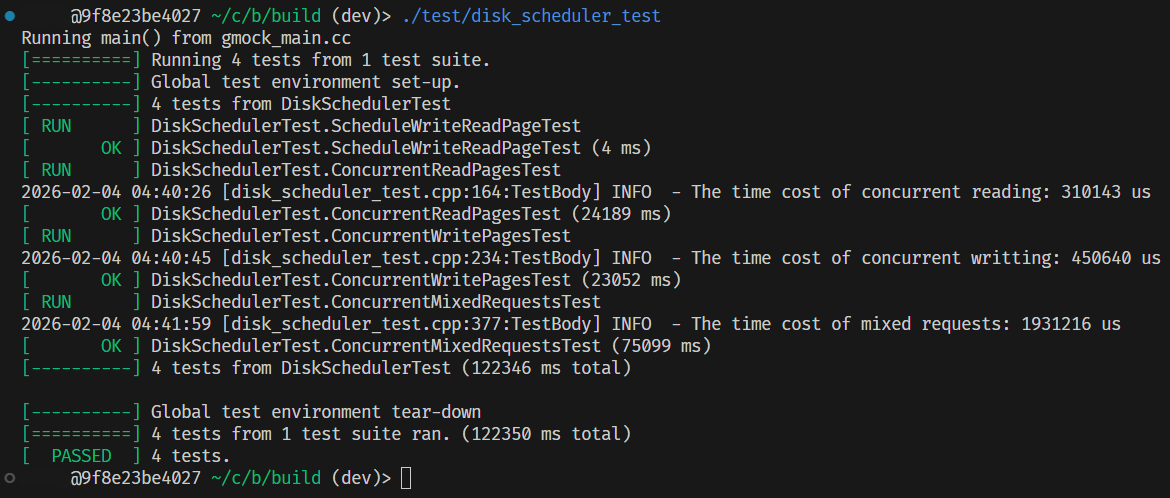
- 基于前述分析,选择
std::deque实现的乱序发射(out-of-order)调度器(不含优化):
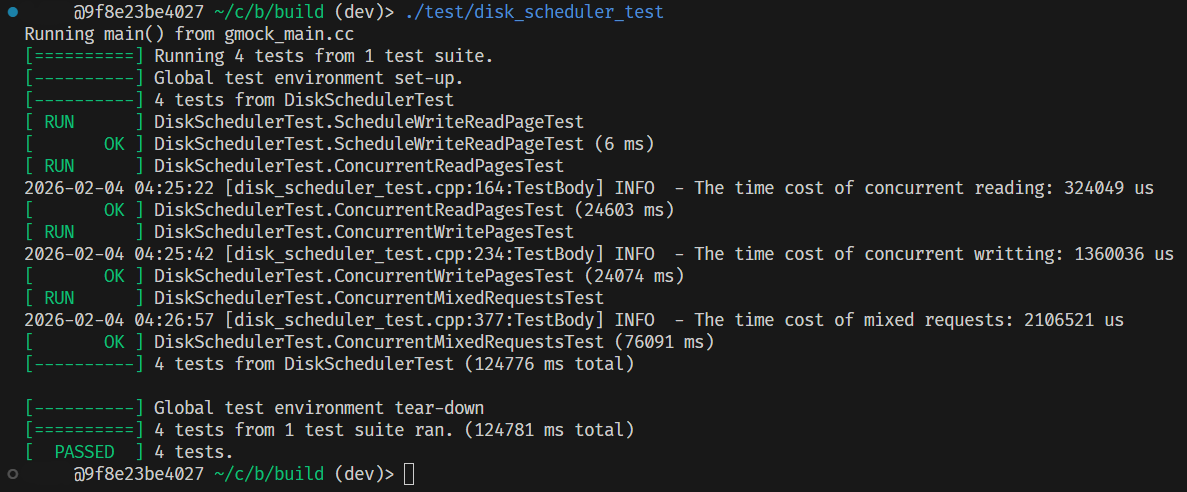
- 基于前述分析,但选择
std::list实现的乱序发射调度器(不含优化):
- 最终的优化实现:
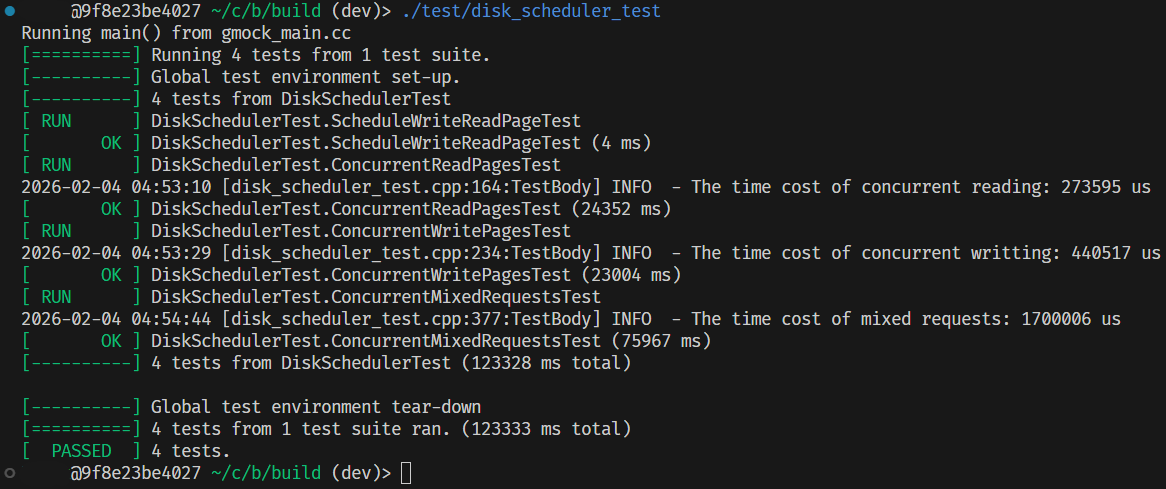
因为测试数据是随机生成的,而且这里分别只有一次测试结果,因此实际性能可能会有一定波动,故仅供参考。
而且我的测试场景主要集中在高并发压力,如果实际使用时 IO 请求是罕见事件,那么可能一个优化后的实现会不如原始的单线程实现。
可以看出,乱序发射调度可以在读密集、以及混合读写场景下发挥较大的优势;而写密集则因为退化为串行 IO、并且有一定的多线程上下文切换,因此性能上与线性调度拉不开差距。
并且显而易见的是,在 IO 调度这种高并发场景下,无锁实现一定优于有锁实现。
但不管怎么说,乱序调度依然能在绝大多数场景下取得一定收益,所以可以知道之前我们的分析确实是正确的。
以下是我自己补充的测试用例代码,包含性能分析部分:
cpp
// 缺失什么文件自己 include
inline auto RandomPage(std::mt19937 &rng) -> std::string {
std::uniform_int_distribution<char> dist{std::numeric_limits<char>::min(), std::numeric_limits<char>::max()};
std::string ret;
ret.reserve(BUSTUB_PAGE_SIZE);
std::generate_n(std::back_inserter(ret), BUSTUB_PAGE_SIZE, [&]() { return dist(rng); });
return ret;
}
inline auto RandomData(std::mt19937 &rng) -> std::unique_ptr<char[]> {
std::uniform_int_distribution<char> dist{std::numeric_limits<char>::min(), std::numeric_limits<char>::max()};
auto ret = std::make_unique<char[]>(BUSTUB_PAGE_SIZE);
std::generate_n(ret.get(), BUSTUB_PAGE_SIZE, [&]() { return dist(rng); });
return ret;
}
inline auto RandomDisk(size_t num_pages, std::mt19937 &rng) -> std::vector<std::string> {
// 生成随机初始数据
std::vector<std::string> disk;
disk.reserve(num_pages);
std::generate_n(std::back_inserter(disk), num_pages, [&rng]() { return RandomPage(rng); });
return disk;
}
inline auto ShuffleID(size_t num_pages, std::mt19937 &rng) -> std::vector<page_id_t> {
auto ret = std::vector<page_id_t>(num_pages);
std::iota(ret.begin(), ret.end(), 0);
std::shuffle(ret.begin(), ret.end(), rng);
return ret;
}
inline auto Concurrency() noexcept { return std::thread::hardware_concurrency() / 2; }
// NOLINTNEXTLINE
TEST(DiskSchedulerTest, ConcurrentReadPagesTest) {
// 并发读取测试:先同步写入若干随机 page,再打乱 id 列表并并发发起读请求
constexpr size_t num_pages = 50000;
std::mt19937 rng{std::random_device{}()};
auto dm = std::make_unique<DiskManagerUnlimitedMemory>();
auto disk_scheduler = std::make_unique<DiskScheduler>(dm.get());
const auto origin = RandomDisk(num_pages, rng);
// 先同步写入
for (size_t i = 0; i < num_pages; ++i) {
std::vector<DiskRequest> wreq;
auto &req = wreq.emplace_back(/*is_write=*/true, const_cast<char *>(origin[i].data()), /*page_id=*/i,
disk_scheduler->CreatePromise());
auto fut = req.callback_.get_future();
disk_scheduler->Schedule(wreq);
EXPECT_TRUE(fut.get());
}
// 打乱 id 列表
const auto ids = ShuffleID(num_pages, rng);
// 分配到多个线程并发发起读请求
const size_t nthreads = Concurrency();
std::vector<std::thread> visitors;
visitors.reserve(nthreads);
const auto chunk = num_pages / nthreads;
const auto remainder = num_pages % nthreads;
std::vector<std::chrono::high_resolution_clock::time_point> start, ending;
start.resize(nthreads + (remainder > 0));
ending.resize(nthreads + (remainder > 0));
auto read_out = std::vector<std::string>(num_pages);
const auto requester = [&](size_t nth_worker, auto head, auto tail) {
const auto num_requests = std::distance(head, tail);
std::vector<DiskRequest> rreqs;
std::vector<std::future<bool>> rfuts;
rreqs.reserve(num_requests);
rfuts.reserve(num_requests);
while (head != tail) {
const auto pid = *(head++);
read_out[static_cast<size_t>(pid)].resize(BUSTUB_PAGE_SIZE);
auto &rreq = rreqs.emplace_back(/*is_write=*/false, read_out[static_cast<size_t>(pid)].data(),
/*page_id=*/pid, disk_scheduler->CreatePromise());
rfuts.emplace_back(rreq.callback_.get_future());
}
start[nth_worker] = std::chrono::high_resolution_clock::now();
disk_scheduler->Schedule(rreqs);
for (auto &rfut : rfuts) {
EXPECT_TRUE(rfut.get());
}
ending[nth_worker] = std::chrono::high_resolution_clock::now();
};
for (size_t i = 0; i < nthreads; ++i) {
visitors.emplace_back(
[&, offset = i]() { requester(offset, ids.cbegin() + offset * chunk, ids.cbegin() + (offset + 1) * chunk); });
}
if (remainder > 0) {
visitors.emplace_back([&]() { requester(nthreads + 1, ids.cbegin() + nthreads * chunk, ids.cend()); });
}
std::for_each(visitors.begin(), visitors.end(), [](auto &vistor) {
if (vistor.joinable()) {
vistor.join();
}
});
LOG_INFO("The time cost of concurrent reading: %ld us",
std::chrono::duration_cast<std::chrono::microseconds>(*std::max_element(ending.cbegin(), ending.cend()) -
*std::min_element(start.cbegin(), start.cend()))
.count());
for (size_t pid = 0; pid < num_pages; ++pid) {
EXPECT_EQ(std::memcmp(read_out[pid].data(), origin[pid].data(), BUSTUB_PAGE_SIZE), 0);
}
disk_scheduler = nullptr;
dm->ShutDown();
}
// NOLINTNEXTLINE
TEST(DiskSchedulerTest, ConcurrentWritePagesTest) {
// 并发写入测试:生成打乱的 page_id 列表,并发发起写请求
constexpr size_t num_pages = 50000;
std::mt19937 rng{std::random_device{}()};
auto dm = std::make_unique<DiskManagerUnlimitedMemory>();
auto disk_scheduler = std::make_unique<DiskScheduler>(dm.get());
// 准备要写入的随机数据
const auto written_in = RandomDisk(num_pages, rng);
const auto ids = ShuffleID(num_pages, rng);
// 并发写:写完成后依次校验写入的数据是否一致
const auto nthreads = Concurrency();
const auto chunk = num_pages / nthreads;
const auto remainder = num_pages % nthreads;
std::vector<std::chrono::high_resolution_clock::time_point> start, ending;
start.resize(nthreads + (remainder > 0));
ending.resize(nthreads + (remainder > 0));
const auto requester = [&](size_t nth_worker, auto head, auto tail) {
const auto num_request = std::distance(head, tail);
std::vector<DiskRequest> reqs;
std::vector<std::future<bool>> futs;
reqs.reserve(num_request);
futs.reserve(num_request);
while (head != tail) {
const page_id_t pid = *(head++);
auto &req = reqs.emplace_back(/*is_write=*/true, const_cast<char *>(written_in[pid].data()), /*page_id=*/pid,
disk_scheduler->CreatePromise());
futs.emplace_back(req.callback_.get_future());
}
start[nth_worker] = std::chrono::high_resolution_clock::now();
disk_scheduler->Schedule(reqs);
for (auto &fut : futs) {
EXPECT_TRUE(fut.get());
}
ending[nth_worker] = std::chrono::high_resolution_clock::now();
};
std::vector<std::thread> writers;
writers.reserve(nthreads);
for (size_t i = 0; i < nthreads; ++i) {
writers.emplace_back(
[&, offset = i]() { requester(offset, ids.cbegin() + offset * chunk, ids.cbegin() + (offset + 1) * chunk); });
}
if (remainder > 0) {
writers.emplace_back([&]() { requester(nthreads + 1, ids.cbegin() + nthreads * chunk, ids.cend()); });
}
// 等写请求全部响应完毕后再检查
std::for_each(writers.begin(), writers.end(), [](auto &writer) {
if (writer.joinable()) {
writer.join();
}
});
LOG_INFO("The time cost of concurrent writting: %ld us",
std::chrono::duration_cast<std::chrono::microseconds>(*std::max_element(ending.cbegin(), ending.cend()) -
*std::min_element(start.cbegin(), start.cend()))
.count());
for (size_t i = 0; i < written_in.size(); ++i) {
auto buffer = std::string(BUSTUB_PAGE_SIZE, '\0');
std::vector<DiskRequest> rreq;
auto &rq = rreq.emplace_back(/*is_write=*/false, buffer.data(), /*page_id=*/static_cast<page_id_t>(i),
disk_scheduler->CreatePromise());
auto fut = rq.callback_.get_future();
disk_scheduler->Schedule(rreq);
EXPECT_TRUE(fut.get());
EXPECT_EQ(std::memcmp(written_in[i].data(), buffer.data(), BUSTUB_PAGE_SIZE), 0);
}
disk_scheduler = nullptr;
dm->ShutDown();
}
// NOLINTNEXTLINE
TEST(DiskSchedulerTest, ConcurrentMixedRequestsTest) {
// 混合读写并发测试:生成包含每个 page_id 至少一次的打乱列表,按顺序对每个出现项以 50% 概率写入/读出数据
// 等所有请求完成后,逐页读取并与预期(最后一次写的数据或初始数据)比较
constexpr size_t num_pages = 50000;
std::mt19937 rng{std::random_device{}()};
auto dm = std::make_unique<DiskManagerUnlimitedMemory>();
auto disk_scheduler = std::make_unique<DiskScheduler>(dm.get());
// 初始磁盘数据
const auto origin = RandomDisk(num_pages, rng);
// 先线性写入
for (size_t i = 0; i < num_pages; ++i) {
auto prm = disk_scheduler->CreatePromise();
auto fut = prm.get_future();
std::vector<DiskRequest> req;
req.emplace_back(/*is_write=*/true, const_cast<char *>(origin[i].data()), /*page_id=*/i, std::move(prm));
disk_scheduler->Schedule(req);
EXPECT_TRUE(fut.get());
}
struct Item {
char *data_;
page_id_t page_id_;
bool is_write_;
Item(bool is_write, char *data, page_id_t pid) noexcept : data_{data}, page_id_{pid}, is_write_{is_write} {}
};
// 构造随机访问列表以及可能要写入的数据
const auto test_context = [&]() {
std::vector<Item> itm;
// 因为要转移 data 所有权,所以得找一个不支持 SSO 的数据结构存放待写入的数据
std::vector<std::unique_ptr<char[]>> rdata, wdata;
// 构造包含每个 page_id 至少一次的打乱列表
const auto ids = [&]() {
// 随机附加列表
const auto extra_size = std::uniform_int_distribution<size_t>{0, num_pages * 5}(rng);
std::vector<page_id_t> random_ids;
random_ids.reserve(num_pages + extra_size);
random_ids.resize(num_pages);
std::iota(random_ids.begin(), random_ids.end(), 0);
std::uniform_int_distribution<page_id_t> pid_dist{0, num_pages - 1};
std::generate_n(std::back_inserter(random_ids), extra_size, [&]() { return pid_dist(rng); });
// 打乱顺序
std::shuffle(random_ids.begin(), random_ids.end(), rng);
return random_ids;
}();
itm.reserve(ids.size());
std::bernoulli_distribution coin{0.5};
for (page_id_t pid : ids) {
if (coin(rng)) {
auto &buffer = wdata.emplace_back(RandomData(rng));
itm.emplace_back(/*is_write=*/true, buffer.get(), /*page_id=*/pid);
} else {
auto &buffer = rdata.emplace_back(std::make_unique<char[]>(BUSTUB_PAGE_SIZE));
itm.emplace_back(/*is_write=*/false, buffer.get(), /*page_id=*/pid);
}
}
return std::make_tuple(std::move(itm), std::move(rdata), std::move(wdata));
}();
// 在 lambda 中捕获结构化绑定的变量居然是一个 C++20 功能,所以这里只能自己手动绑定一下
const auto &visits = std::get<0>(test_context);
const size_t nthreads = Concurrency();
// 将请求划分到线程(连续区间),每个线程按其区间一次性提交一批请求并等待所有 future
const auto chunk = visits.size() / nthreads;
const auto remainder = visits.size() % nthreads;
std::vector<std::chrono::high_resolution_clock::time_point> start, ending;
start.resize(nthreads + (remainder > 0));
ending.resize(nthreads + (remainder > 0));
// 记录每个线程对每个 page 的最后一次读和最后一次写
std::vector<std::unordered_map<page_id_t, const char *>> last_read, last_written;
last_read.resize(nthreads + (remainder > 0));
last_written.resize(nthreads + (remainder > 0));
const auto requester = [&](size_t nth_worker, auto head, auto tail) {
const auto num_requests = std::distance(head, tail);
std::vector<DiskRequest> reqs;
std::vector<std::future<bool>> futs;
reqs.reserve(num_requests);
futs.reserve(num_requests);
for (; head != tail; ++head) {
auto &req = reqs.emplace_back(head->is_write_, head->data_, head->page_id_, disk_scheduler->CreatePromise());
if (head->is_write_) {
last_written[nth_worker][head->page_id_] = head->data_;
} else {
last_read[nth_worker][head->page_id_] = head->data_;
}
futs.emplace_back(req.callback_.get_future());
}
start[nth_worker] = std::chrono::high_resolution_clock::now();
disk_scheduler->Schedule(reqs);
for (auto &fut : futs) {
ASSERT_TRUE(fut.get());
}
ending[nth_worker] = std::chrono::high_resolution_clock::now();
};
std::vector<std::thread> workers;
workers.reserve(nthreads + (remainder > 0));
for (size_t i = 0; i < nthreads; ++i) {
workers.emplace_back([&, offset = i]() {
requester(offset, visits.cbegin() + offset * chunk, visits.cbegin() + (offset + 1) * chunk);
});
}
if (remainder > 0) {
workers.emplace_back([&]() { requester(nthreads, visits.cbegin() + nthreads * chunk, visits.cend()); });
}
std::for_each(workers.begin(), workers.end(), [](auto &worker) {
if (worker.joinable()) {
worker.join();
}
});
LOG_INFO("The time cost of mixed requests: %ld us",
std::chrono::duration_cast<std::chrono::microseconds>(*std::max_element(ending.cbegin(), ending.cend()) -
*std::min_element(start.cbegin(), start.cend()))
.count());
// 收集每个 page 在每个线程中最后一次读取和写入的值
std::vector<std::vector<const char *>> final_fetched, final_modified;
final_fetched.resize(num_pages);
final_modified.resize(num_pages);
for (size_t i = 0; i < workers.size(); ++i) {
for (auto [pid, data] : last_read[i]) {
final_fetched[static_cast<size_t>(pid)].push_back(data);
}
for (auto [pid, data] : last_written[i]) {
final_modified[static_cast<size_t>(pid)].push_back(data);
}
}
// 收集现在磁盘上的最终数据
std::vector<std::string> final_pages;
final_pages.reserve(num_pages);
for (page_id_t pid = 0; pid < static_cast<page_id_t>(num_pages); ++pid) {
std::vector<DiskRequest> req;
auto &buffer = final_pages.emplace_back(BUSTUB_PAGE_SIZE, '\0');
auto &rq = req.emplace_back(/*is_write=*/false, buffer.data(), /*page_id=*/pid, disk_scheduler->CreatePromise());
auto fut = rq.callback_.get_future();
disk_scheduler->Schedule(req);
ASSERT_TRUE(fut.get());
}
for (size_t pid = 0; pid < num_pages; ++pid) {
if (final_modified[pid].empty()) {
// 当前 page 没有被修改过,检查是否等于原始数据
ASSERT_EQ(std::memcmp(final_pages[pid].data(), origin[pid].data(), BUSTUB_PAGE_SIZE), 0);
// 并且检查对于所有线程,最后一次读到的当前页是否都等于原始数据
ASSERT_TRUE(std::all_of(final_fetched[pid].cbegin(), final_fetched[pid].cend(), [&](auto fetched) {
return std::memcmp(origin[pid].data(), fetched, BUSTUB_PAGE_SIZE) == 0;
}));
} else {
// 被更改过,比较磁盘上最终数据是否出现在最后一次写入中
ASSERT_GE(std::count_if(final_modified[pid].cbegin(), final_modified[pid].cend(),
[&](auto modified) {
return std::memcmp(final_pages[pid].data(), modified, BUSTUB_PAGE_SIZE) == 0;
}),
1);
}
}
disk_scheduler = nullptr;
dm->ShutDown();
}3.Task#3 - 缓冲池管理器
重头戏来了,现在我们终于要实现整个 BufferPoolManager 及其附属组件 FrameHeader、ReadPageGuard 和 WritePageGuard。
实际上 BufferPoolManager 就是一个在 disk 和 memory 之间的、专门服务于数据库内核的 cache,它和 CPU 的 cache 的作用相同:降低 IO 开销。
因此,每个 FrameHeader 就相当于一个 cache line,它必须持有引用计数和脏位,以示当前 cache line 是否允许失效,并且在失效时是否有必要把数据写回到 disk 上。
ReadPageGuard 与 WritePageGuard 则是访问行为在类型系统上的建模,每个 guard 对象表达了某个线程对于某个 page 的一次或若干次读/写操作,而且每个 guard 在构造时都必须在 FrameHeader 处登记一次引用计数,并在析构时回撤该引用计数(这和 std::shared_ptr 很类似)。
引用计数的更改决定了这个 frame 能否被 ArcReplacer 驱逐。
当 BufferPoolManager 需要引入新的 page、且发现空闲的 frame 不足时,需要使用之前实现的 ArcReplacer 驱逐某些页;显然引用计数大于 0 的情况下,这些 frame 不允许被逐出。
3.1 接口设计
首先先观察 FrameHeader,它就是用于存储实际数据页(page)的物理页帧(frame);所有数据都会存放在字段 std::vector<char> data_ 指向的内存区中。
一如既往的是,这里有很多难绷的数据成员排布,而且实际上每个 frame 的大小是固定的(8192 个字节,由 BUSTUB_PAGE_SIZE 给出),因此用 std::vector 作为数据存放区是毫无必要的(会多出来几个无意义的字段,例如 capacity)。
你可以像我一样重新设计 FrameHeader 的字段安排(记得调整构造函数的成员构造顺序):
cpp
class FrameHeader {
// ...
std::unique_ptr<char[]> data_{};
// Hint: GetPinCount() 中可以用 relaxed 内存序读取 pin_count_ 的值
std::atomic<size_t> pin_count_{0};
std::shared_mutex rwlatch_{};
const frame_id_t frame_id_;
// 设置为原子变量是为了保证在 ReadPageGuard 中有且仅有一个线程执行写回操作,降低 IO 次数
std::atomic<bool> is_dirty_{false};
};FrameHeader 有三个已经实现好的方法:GetData()、GetDataMut() 和 Reset(),它们是我们在实现其他几个组件时要使用的方法。
BufferPoolManager 的方法数量很多且很复杂,它们是:
Size() const -> size_t:返回当前管理器持有的 frame 数量,这是个固定值NewPage() -> page_id_t:申请一个新的 page_id,所有 page_id 在数值上满足单调递增DeletePage(page_id_t page_id) -> bool:同时从 disk 和 memory 上删除一个可被驱逐的 pageCheckedWritePage(page_id_t page_id, AccessType access_type) -> std::optional<WritePageGuard>:获取指定 page 的WritePageGuardCheckedReadPage(page_id_t page_id, AccessType access_type) -> std::optional<ReadPageGuard>:获取指定 page 的ReadPageGuardWritePage(page_id_t page_id, AccessType access_type) -> WritePageGuard和ReadPage(page_id_t page_id, AccessType access_type) -> ReadPageGuard:测试用的方法,已经实现好且不应该被修改FlushPageUnsafe(page_id_t page_id) -> bool:将指定 page 的内容无锁地写回到 disk 上FlushPage(page_id_t page_id) -> bool:将指定 page 的内容写回到 disk 上FlushAllPagesUnsafe():将所有在 memory 中的 page 的内容无锁地写回到 disk 上FlushAllPages():将所有在 memory 中的 page 的内容写回到 disk 上GetPinCount(page_id_t page_id) -> std::optional<size_t>:获取指定 page 的引用计数
其余两个 PageGuard 类型的方法就很简单,只简单提几个:
Flush():将当前 guard 指向的 page 的数据写回到 disk 上Drop():放弃当前 guard 指向的 page 的访问权
很显然,ReadPageGuard 对应的是 FrameHeader 中 rwlatch_ 的读锁,而 WritePageGuard 则对应了 FrameHeader 中 rwlatch_ 的写锁。
而且实际上在 BufferPoolManager,有且仅有 CheckedWritePage() 和 CheckedReadPage() 的逻辑最复杂,因为它们要处理以下三种情况的 guard 分配:
- 被访问 page 在 memory 中
- 被访问 page 不在 memory 中,但有空闲 frame
- 被访问 page 不在 memory 中,且没有空闲 frame
3.2 具体实现
代码注释提示我们,最好先实现了 ReadPageGuard 和 WritePageGuard 再回来补全 BufferPoolManager;因为两个 guard 类型比较简单。
显然,在两个 guard 类型之间会有非常多的重复代码,在实现前我们先要抽取一个基类 AccessPageGuard:
cpp
class AccessPageGuard {
public:
/// 省略一些公共接口声明
~AccessPageGuard() = default;
protected:
AccessPageGuard() = default;
AccessPageGuard(page_id_t page_id, std::shared_ptr<FrameHeader> &&frame, std::shared_ptr<ArcReplacer> &&replacer,
std::shared_ptr<std::mutex> &&bpm_latch, std::shared_ptr<DiskScheduler> &&disk_scheduler) noexcept;
// 复制语义会被移动语义自动抑制
AccessPageGuard(AccessPageGuard &&that) noexcept;
auto operator=(AccessPageGuard &&that) noexcept -> AccessPageGuard &;
/// 把两个 guard 的字段全部挪到基类中
};不要忘了在
FrameHeader中将这个新基类声明为友元。
然后剩下两个 guard 各自继承即可:
cpp
class ReadPageGuard : public AccessPageGuard {
friend class BufferPoolManager;
public:
/// 省略一些构造函数声明
void Drop();
};
class WritePageGuard : public AccessPageGuard {
friend class BufferPoolManager;
public:
/// 省略一些构造函数声明
auto GetDataMut() -> char *;
template <class T>
auto AsMut() -> T * {
return reinterpret_cast<T *>(GetDataMut());
}
void Drop();
}此处的设计难点在于同时处理好 BufferPoolManager(下称 bpm)中构造 guard 对象、guard 类型的构造函数以及 guard 类型的 Drop() 方法的实现;这里需要一些特别的注意力。
注意到一个事实:当我们调用 bpm 的 Checked* 方法时,我们需要执行一系列分配操作拿到一个 frame,或什么都拿不出来(返回空的 std::optional)。这个分配操作显然涉及到访问并修改 bpm 的成员,因此需要锁住 bpm_latch_。
接着,guard 对象需要根据它们的语义,锁住拿到的 FrameHeader 对象中的读写锁 rwlatch_,然后在它们自己的 Drop() 函数中释放。
因此我们可以这样设计上锁顺序:在 Checked* 方法中锁住 bpm_latch_,拿出或返回空的 std::shared_ptr<FrameHeader>,之后立即释放锁,并在拿到的 std::shared_ptr 非空的情况下,用它指向的 FrameHeader 对象构造对应的 guard 对象;rwlatch_ 的上锁将在构造函数中执行。
为什么要先锁住 bpm_latch_,然后在分配操作结束后立即释放它?是因为我们允许:多个线程同时调用不同的 Checked*,每个线程通过一次原子性分配操作拿到了对应的 frame,或者有的拿不到;拿到有效 frame 的线程可以立即递增 pin_count_ 表明有多个线程急迫地需要获得某个 page 的控制权,防止在未来这些线程拿到了 frame 却又目睹这些 frame 被错误淘汰。
之后这些急迫线程会平等地在构造函数中按需抢占 rwlatch_ 的读写锁,抢占成功的线程正常返回构造好的对象。
而且如果
bpm_latch_的上锁操作覆盖了 guard 的构造函数,那么会导致死锁。
注意到这点之后,guard 类型的实现就不再困难了:构造函数中仅上锁 rwlatch_,Drop() 中则递减 pin_count_ 并放弃锁。
虽然
pin_count_的递增和递减不由同一个对象执行多少有点反 RAII。
构造函数就是把参数转发给基类,然后自己上个锁,没什么好说的;我们来看看 Drop() 的实现:
cpp
void ReadPageGuard::Drop() {
// 因为 guard 类型被设计成 move-only,所以移动和析构不可能同时发生在多个线程中
if (is_valid_) {
/// 可以立即释放锁,然后再慢慢处理 pin_count_
if (frame_->pin_count_.fetch_sub(1, std::memory_order_release) == 1) {
// 不上锁的话这里的 SetEvictable() 会存在调度问题导致不一致的执行顺序
// 即:某个 Guard 调用 Drop()、递减 pin_count_,然后这个线程因为调度问题让出了 CPU
// 此时又有另一个 Guard 在另一个拿到了 CPU 的线程中递增 pin_count_ 并被构造
// 在这一时刻,两个 Guard 可以以任意顺序先后执行下面的 SetEvictable(),显然会存在问题
std::lock_guard lock{*bpm_latch_};
/// 然后二次检查 pin_count_,仅当真的为 0 时更新 Evictable
}
/// 更新 is_valid_
}
}
void WritePageGuard::Drop() {
/// 过程同上,略
}注释中说的很明白了,即使 replacer_ 是线程安全设计,但因为执行顺序一致性问题,我们必须再次依赖 bpm_latch_ 充当"仲裁"。
顺便一提,测试用例中要求我们处理 guard 类型的移动赋值函数的自赋值操作,虽然自赋值是非常有病的人才会写出来的东西。
在基类的 Flush() 中,代码注释说明了我们只需要将数据写回到磁盘上即可,所以可以利用 CAS 实现多个线程调用但只有一次 IO:
cpp
void AccessPageGuard::Flush() {
BUSTUB_ASSERT(is_valid_, "tried to flush an invalid page guard");
// 因为 ReadPageGuard 可以存在多个,所以 is_dirty_ 得改成原子量才能保证修改不出现 UB
if (auto expected = true; frame_->is_dirty_.compare_exchange_strong(expected, false, std::memory_order_relaxed)) {
/// 通过 disk_scheduler_ 发起 IO
// 注意所有 flush 操作在执行时,都必须至少持有 frame 的写锁,否则会出现 data race
}
}而且从 FrameHeader 的脏位设计中我们可以观察到一个现象:在 memory 上的 page 数据始终是最新的,而 disk 上的数据总是最旧的;这很符合"cache"的设计。
BufferPoolManager 中的 Flush() 方法实现与这里的相同,我们不再重复阐述;唯一要注意的是在 FlushAllPages() 方法中,我们可以一次构造所有 page 的 DiskRequest,然后在一次调度中发送给 DiskScheduler,这样可以减少调度时的上锁次数(别忘了 DiskScheduler 里面有锁)。
根据我们之前的上锁顺序分析,每个 Checked 方法中只需要拿到一个 std::shared_ptr<FrameHeader> 表示分配结果即可,若非空则表示分配成功;因此两个方法写起来都是相同的,此处略。
那么到了处理分配 frame 的逻辑,在这种情况下,我们要处理三种情况:
- 被访问 page 在 memory 中;
- 被访问 page 不在 memory 中,但有空闲 frame
- 被访问 page 不在 memory 中,且没有空闲 frame
情况 1 属于直接命中,我们立即返回这个 frame 即可;情况 2 需要取出空闲 frame,然后将 page 的数据加载到上面。
情况 3 比较复杂,我们要调用 ArcReplacer 逐出一个界面,将这个界面的数据写回到 disk 上,再加载数据。而且逐出一个 frame 时我们只能拿到 frame id,为了获取这个 frame 对应的 page,我们要额外在 BufferPoolManager 中加上一个 frame_table_(虽然实验建议是在 FrameHeader 中加入):
cpp
class BufferPoolManager {
// ...
/** 反向映射 frame_id_t -> page_id_t */
std::unordered_map<frame_id_t, page_id_t> frame_table_;
// 我们等会再谈论这个成员的作用
std::unordered_map<page_id_t, std::future<void>> inflight_page_;
// 我们总是在队尾插入而在队首提出,没必要用 std::list,可以换一个对 cache 更友好的
std::deque<frame_id_t> free_frames_;
};在页分配的三种情况中,第一种直接命中,立即返回;第二种取出空闲 frame,加载数据并返回;第三种则需要驱逐 frame,写回数据再加载数据后返回。
这里面有许多重复的代码,例如加载 page 数据到 frame 中,以及将 frame 数据写回到 disk 上;我写了三个辅助方法:
cpp
// 写回 disk
void BufferPoolManager::CommitPage(page_id_t page_id, FrameHeader &frame) {
/// 和 guard 类型中的 Flush 方法相同,构造一个 DiskRequest 即可,略
}
// 将数据加载到 frame 上
void BufferPoolManager::LoadPage(page_id_t page_id, FrameHeader &frame) {
BUSTUB_ASSERT(frame.is_dirty_ == false, "load the data into a frame that has not yet been written back");
/// 构造一个 DiskRequest 即可,略
}
// 情况 3 的替换操作
void BufferPoolManager::ReplacePage(page_id_t old_pid, page_id_t new_pid, FrameHeader &frame,
std::promise<void> &¬ifier, std::future<void> &&fence) {
// Note: 注意到本次 IO 操作(写回-读取)是对同一个 frame 进行的
// 这违背了 DiskScheduler 中关于两次 Request 的目的地址必然不重叠的假设
// 所以我们必须拿另一个指针作为数据缓存区,防止错误的 IO 顺序冲突导致数据竞争
std::unique_ptr<char[]> replacement;
// 要是有 small_vector 的话就好了
std::array<std::optional<std::future<bool>>, 2> futs;
{
std::vector<DiskRequest> reqs; // 一次发出多个请求
reqs.reserve(2);
if (auto expected = true; frame.is_dirty_.compare_exchange_strong(expected, false, std::memory_order_relaxed)) {
/// 当脏位有效时,我们调用 make_unique 构造临时缓冲区 replacement
/// 然后将其与现在的 frame 中的 data_ 交换,使得写回操作直接作用在新构造的缓冲区上,从而跳过无意义的数据拷贝
/// 之后构造写回请求,该请求的 data 应该直接来自于 replacement(因为发生了一次交换)
}
/// 构造读取请求
// 注意 fence 要在发起调度前使用
if (fence.valid()) {
fence.get();
}
disk_scheduler_->Schedule(reqs);
}
if (futs.front().has_value()) {
futs.front()->get();
// 而 notifier 要在写回发生之后调用
notifier.set_value();
}
// 显然 back() 一定非空
futs.back()->get();
}在 SelectFrame() 方法中,我们要判断一个 page 是否在内存中,其实就是在检查 BufferPoolManager 的 page_table_ 是否记录了这个 page:
cpp
auto BufferPoolManager::SelectFrame(page_id_t page_id, AccessType access_type) -> std::shared_ptr<FrameHeader> {
std::shared_ptr<FrameHeader> space;
std::unique_lock lock1{*bpm_latch_};
// 辅助 lambda,用于给查找过程收尾
const auto pin_frame = [=](auto &bpm_ownership, FrameHeader &frame) {
if (frame.pin_count_.fetch_add(1, std::memory_order_release) == 0) {
/// 先登记再设置 evictable,不然可能此时 frame 还不存在于 replacer 中
bpm_ownership.unlock();
} else {
bpm_ownership.unlock();
/// 因为 frame 现在一定是不可驱逐的,所以可以并发登记此次访问
}
};
if (const auto itr = page_table_.find(page_id); itr != page_table_.end()) {
// 被选中的 page 在内存上,pin 住 frame 后立即返回
pin_frame(lock1, *(space = frames_[static_cast<size_t>(itr->second)]));
} else if (!free_frames_.empty()) {
// 被选中的 page 不在内存上,但有空闲 frame
/// 从 free_frames_ 中选出 idle_frame,并赋值给 space
// 必须在释放 bpm_latch_ 之前上锁,不然会导致同步失效
std::lock_guard lock2{space->rwlatch_};
pin_frame(lock1, *space);
LoadPage(page_id, *space);
} else if (auto evicted = replacer_->Evict(); evicted.has_value()) {
// 被选中的 page 不在内存上,而且不存在空闲 frame
// 永远只有 pin_count_ == 0 的 frame 才会被标记为 evictable
// 因此被驱逐的 frame 一定不被任何线程所"急迫地需要"
/// 更新 page_table_,并且把 frame_table_ 中的 old_pid 替换为新的 pid
// 显然仅当页面不足、需要 evict 时才会存在有 page 尚未被写入的情况,所以只在这个分支中会尝试构造临时 promise
std::promise<void> io_notifier;
std::future<void> io_fence;
space = frames_[static_cast<size_t>(*evicted)];
if (space->is_dirty_.load(std::memory_order_relaxed)) {
/// 更新屏障表 inflight_page_,广播 evicted_pid 发生了一次写回
}
if (/** 然后检查 inflight_page_ 中是否存在我们将要加载的 page_id 的表项 */) {
/// 若有则赋值给 io_fence,表示我们必须等待这个 page_id 写回
}
std::lock_guard lock2{space->rwlatch_};
pin_frame(lock1, *space);
ReplacePage(evicted_pid, page_id, *space, std::move(io_notifier), std::move(io_fence));
}
return space;
}结合代码注释,在之前的 BufferPoolManager 成员定义展示中,我定义了一个 std::unordered_map<page_id_t, std::future<void>> inflight_page_ 成员,并在 SelectFrame() 的驱逐部分、以及 ReplacePage() 方法中使用它。
因为在我的设计中,我总是先在 bpm_latch_ 的保护下查找到可以用于存放新 page 的 frame,然后立即更新元数据(page_table_ 之类的东西),声明这个 page 在逻辑上 被丢弃了,之后锁住 frame 的 rwlatch_ 并立即放弃 bpm_latch_,再实际写回数据与加载数据,进而从物理意义上完成数据页的置换。
显然我们可以发现一个问题:在放弃了 bpm_latch_ 后、数据实际写回之前,这段时间内刚被抛弃的 page 在逻辑上不存在于 BufferPoolManager 的记录中,但是最新数据又还没写回到 disk 上。因此,如果这个时候某个线程立即 Checked 刚刚被抛弃的 page,那么就有可能导致 BufferPoolManager 抢在数据写回之前把 disk 上的旧数据读回来了,产生了一次脏读。
虽然这个问题可以通过在 SelectFrame() 函数内全程持有 bpm_latch_ 解决,但这样会使得锁的粒度太大;因而我们要引入一个 IO 屏障记录,用于阻塞那些"逻辑上消失",但"物理上动作尚未完成"的 page 加载操作。
这一解决方案的核心思想是:仅在需要 eviction 的情况下 ,在 bpm_latch_ 的保护下检查需要被加载的新 page 是否存在于 inflight_page_ 当中,若存在则拿走其中的 std::future<void>。接着,同样在 bpm_latch_ 的保护,将被驱逐的 frame 上保存的 page 记录到 inflight_page_ 中,再让出 bpm_latch_。
之后在调用 Schedule() 之前,先等待被淘汰的 page 的 IO 执行完毕,然后再发出调度请求,并在调度结束后立即更新自己持有的 std::promise<void>。
这么一套操作下来,我们能有效缩小 bpm_latch_ 的保护范围的同时,解决数据一致性问题。
顺便一提,这里不能像 scoreboard 一样用简单的定长无锁 hash table 实现 IO 屏障。
因为如果存在某次被替换的 page 和需要访问的 page 的 id 发生哈希冲突,那么会导致自我等待(死锁)。
如果改用拉链法及其改进版本的定长 hash table 就太复杂了,更推荐直接用
std::unordered_map。
而且在 FlushPage() 和 FlushAllPage() 中,还可以顺便更新 inflight_page_,把每个写回到 page 从 inflight_page_ 当中移除(若有)。
最后是 DeletePage() 的实现,这个方法要求同时删掉 memory 和 disk 上的数据,并且不允许删除引用计数不为 0 的 page。
cpp
auto BufferPoolManager::DeletePage(page_id_t page_id) -> bool {
std::unique_lock lock1{*bpm_latch_};
if (const auto itr = page_table_.find(page_id); itr != page_table_.end()) {
auto &frame = *frames_[static_cast<size_t>(itr->second)];
if (frame.pin_count_.load(std::memory_order_acquire) > 0) {
return false;
}
/// 从所有元数据中删除 page_id 的记录
// 我额外给 FrameHeader 定义了一个 Clear() 方法
// 与 Reset() 的区别在于这个方法不会对 data_ 写零
// 这是因为磁盘上的 page 也要被移除,我们不需要将数据写回到 disk 上
// 而且后续复用这个 frame 时一定会重新把数据从 disk 加载到 frame 上
frame.Clear();
// 防止后续又有线程拿着保存的 pid 重新要一个这个 page
// 然后 IO 在先加载后删除和先删除后加载之间顺序不定(因为已经让出了 bpm_latch_)
// 所以持有一个 frame 的写锁确保这个 page 一定先删掉数据
std::lock_guard lock2{frame.rwlatch_};
/// 顺便更新一下 IO 屏障表
lock1.unlock();
disk_scheduler_->DeallocatePage(page_id);
}
return true;
}就这样,我们实现了 BufferPoolManager,project1 告一段落。
3.3 测试
实现了 BufferPoolManager 后,我们有两个测试可以执行:bpm 的单元测试以及 page_guard 自己的单元测试,和一个 bpm-bench 性能分析测试。
要注意的是,所有本地测试用例都是不完整的,完整测试用例将会在提交到 Gradescope 后执行。
4.提交
提交之前记得先用 clang-tidy 检查代码风格是否符合项目要求;然后本次提交需要先签署一个提交协议:python3 gradescope_sign.py。
在没有对 ArcReplacer 进行针对性优化(利用 AccessType 参数)的情况下,我的提交拿到了第 16 名(默认排序,2026-02-09 第一次提交)。

需要注意的是,leaderboard 中有几个指标是互相矛盾的:(scan|get)_qps_(large|small) 和 (scan|get)_qps_1ms。
当前者的吞吐量(qps)提升时,后者会下降(像我一样,前四个指标非常高,最后两个非常低);而后者吞吐量上升时前者会下降。
本质上是因为前者的 IO 过程不含有任何延时,它们实际上就是在与内存进行交互(使用 DiskManagerUnlimitedMemory),内存的 IO 耗时不足以让多个线程预取任务并等待 IO,反而会引入大量的上下文竞争,所以会降低程序性能;而后者则加入了模拟磁盘 IO 的 1ms 延时,因此此时线程数量就显得尤为重要。
但无论是哪个指标的提升,都必须依靠 IO 并行化。
5.最优化吞吐量
在上一节的提交中,我的 (scan|get)_qps_(large|small) 数值很高,但是 (scan|get)_qps_1ms 以及总 QPS 非常低,而且 leadboard 上排行前几(默认排序)的数据中有好几个和我情况是一样的。
实际上,真实的 disk IO 一定会存在延时,而且从 QPS 计算公式上可以看出,带 1ms 延时的测试结果在总 QPS 中的权重相当大,也就是说追求 (scan|get)_qps_(large|small) 的大数字没有一点意义,我们必须尽可能提升延时情况下的 QPS。
我们逐一优化 project1 中实现过的组件。
5.1 ArcReplacer
优化先从最简单的开始。
显然课程代码中提供的 AccessType 我们还没用上,因此我们要好好使用它。
观察 tools/bpm_bench/bpm_bench.cpp 的代码可以发现,性能测试只用到了 AccessType::Scan 和 AccessType::Lookup,由于 AccessType::Lookup 和 AccessType::Index 是两个语义上相对模糊的访问模式(可能第一个的局部性更好?不太懂),因此我们可以只利用 AccessType::Scan 实现优化。
但必须注意的是,优化过程一定要保持 ARC 算法的不变性,也就是说不能在遇到一个类型为 AccessType::Scan 的访问就直接丢弃,否则会导致算法工作预期不正常。
不过你可以把这次访问的 page 丢到队列尾部或者保持不动。
5.2 BufferPoolManager
首先要说明 PageGuard 是没什么优化空间的,因为它就是一个 std::lock_guard 的近似实现,只不过需要提供一些数据交互手段。
但是在分配页面时我们可以做一些小小的优化。
首先值得注意的是,在我的实现中,ReplacePage() 方法内部会构造一个临时数据缓冲区 replacement,然后将它和 FrameHeader 中的 data_ 交换,使得读取和写回可以同时发生。
但众所周知,内存分配是比较慢的,而且在分配时需要上一个全局锁;因此我们可以考虑额外维护一个内存池,每次需要获得新的缓冲区时先从池子中获取内存,如果获取不到再尝试请求内存分配。
其次,我使用了一个 std::unordered_map<page_id_t, std::future<void>> inflight_page_ 字段作为 IO 屏障,以维护不同线程之间先写回后加载的顺序一致性;不难发现的是,这个屏障的使用总是伴随着对应 page 的写回。
所以我们不应该额外构造一个 std::future<void>,而是应该直接使用来自 DiskScheduler 的 std::future<bool>;又因为写回总是会伴随临时缓冲区 replacement 的获取,所以我们可以将它们两个绑定到一起,维护一个同时保存了 std::unique_ptr<char[]> 及其对应 IO 响应 std::shared_future<bool> 的内存池。
为什么是 std::shared_future<bool> 呢?是因为在原本实现中,ReplacePage() 总是要等待被淘汰的 page 的写回操作完成再返回,但这是没必要的。我们可以只等待需要被加载的 page 的写回操作完成(若有),然后发起 IO 请求,之后 return 我们临时构造的 replacement 给上层调用者即可。
因此这个被淘汰的 page 的写回操作(若有)的 future 会被同时放入内存池以及 inflight_page_ 当中,而 std::future 是不能共享的,所以我们要将它提升为 std::shared_future。
讲起来可能比较抽象,具体结合代码领悟即可,实际上并不复杂。
5.3 DiskScheduler
IO 是性能瓶颈,而负责处理 IO 的 DiskScheduler 则是整个 project1 瓶颈的瓶颈;很大程度上,DiskScheduler 的实现直接决定了性能测试中 QPS 的大小。
由于我们已经实现了 BufferPoolManager,因此我们可以注意到一个新的事实:此前我们担心的数据依赖问题不存在了。
在 BufferPoolManager 中,我们总是确保一个 IO 已经完成(无论是写回还是读取),再将 page 交付给用户,因此在单次 IO 结束之前,用户不可能同时发起对于同一个 page 的写回以及读取,但可以同时发起多个写回(这一点也被我们用原子变量 + CAS 规避了)。
这使得 DiskScheduler 永远不会遇到需要同时处理同一个 page 的写回和读取的情况;所以我们可以去掉此前实现的 ScoreBoard 算法,以支持完全乱序发射。
但必须注意的是:这个假定在
DiskScheduler自己的单元测试中是不成立的,我也不知道为什么要这么设计测试用例。而且我自己写的测试用例同样没有考虑到这一点;所以在去掉了 ScoreBoard 算法后,
DiskScheduler的单元测试通过变成了一个概率性事件。不过性能评估测试
bpm_bench是能稳定通过的,这侧面证明我们的推断是正确的。
这样做依然不够,因为现在的设计中,我们开设的多个线程在同时竞争一个队列,这里有非常严重的锁竞争问题。
为了改善锁竞争,我们可以为每个线程分配一个属于自己的任务队列,然后将 page_id 分派到不同的任务队列中,进而降低锁粒度。
又因为单次 IO 实际上是一个开销比较大的事件,所以我们可以让其他线程使用 cv.wait_for() 方法临时休眠,在醒来后、自己队列中没有任务时,转而"窃取"别的线程的队列中未被提出的任务,加速 IO 完成。
任务窃取能够有效的核心点在于我们可以完全乱序执行 IO 请求。
此时跑一遍 perf 拿到火焰图后会发现性能瓶颈在条件变量的唤醒以及锁的获取上,为此我们可以加入多个原子变量,用于指示某个线程的队列是否为空、线程本身是否被条件变量挂起,从而实现无锁的快速嗅探,以跳过无意义的锁竞争。
当然,改到现在我已经黔驴技穷了,如果读者有什么更高明的 DiskScheduler 设计的话欢迎告诉我。
5.4 性能评估
经过以上优化,我的 QPS 指标变成了下面这样:

显然有些指标有了极大提升。
但必须要清楚的是:leaderboard 只是一个参考用的评分测试系统,它不能代表真实情况下的 IO 请求。
因为 bpm-bench 本质上是在用多个线程不间断地发起 IO 请求,且持续时间长达 30 秒;这种超高并发在真实情况下几乎是不太可能出现的。
为什么这么说?因为我能在 DiskScheduler 中,使用最简单的自旋调度实现配合过量线程数,在真实 IO 模拟和总 QPS 指标上打爆榜单上的所有人:
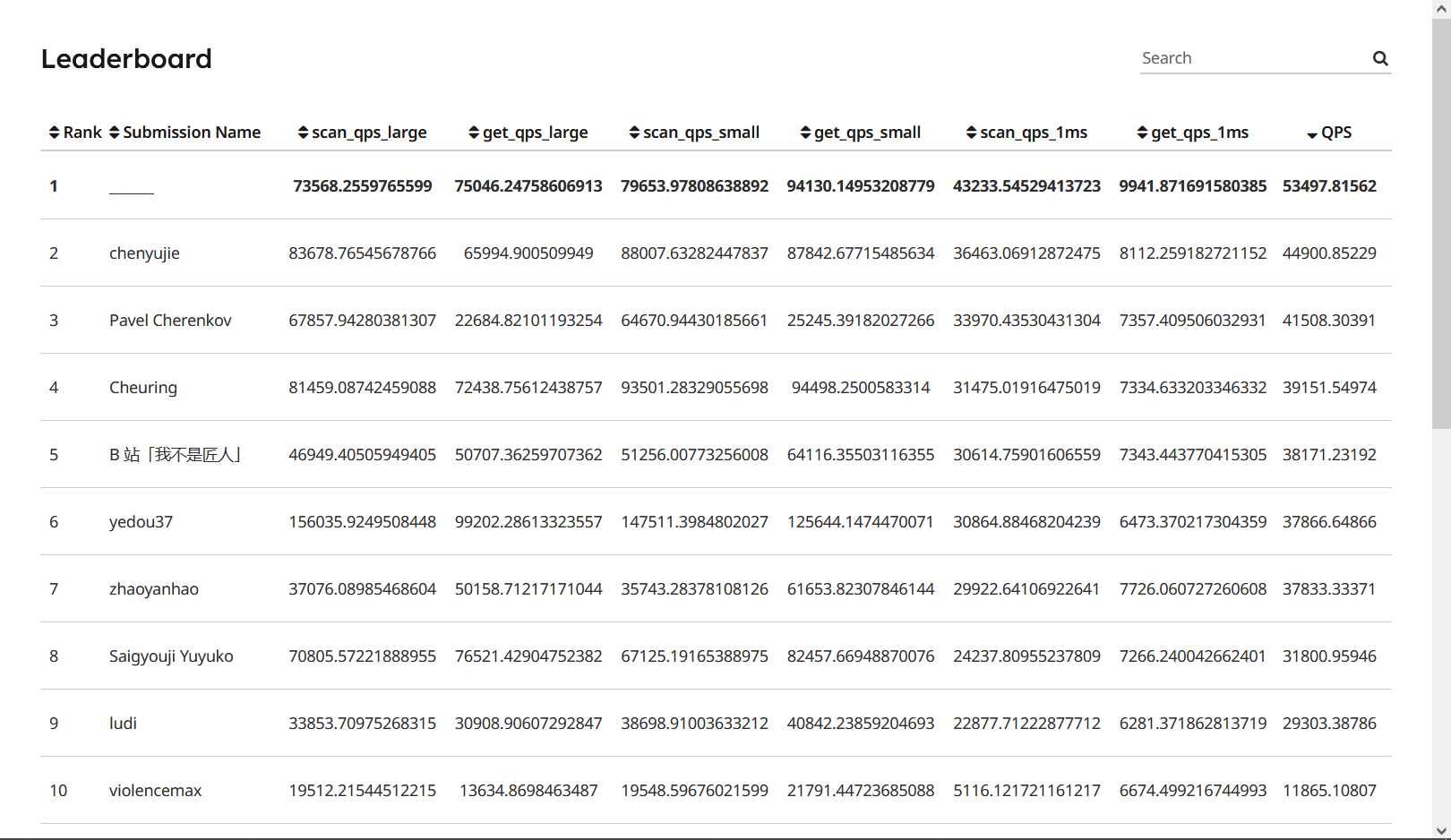
这意味着 leaderboard 需要的是不是多么优秀的设计,而尽可能快的响应,你只需要有多个能在任意时刻下立即响应 IO 请求的线程在后台自旋忙等,就可以把 QPS 拉满。
所以很多情况下,如果你拉高
DiskScheduler的线程数量,那么可以立即得到可观的 QPS 提升;但这是有极限的。
因此这也是不少攻略中,表现优秀的实现会在某些测试用例上超时的核心原因------自旋+超量分发线程导致 CPU 一直在处理上下文切换。
6.总结
这玩意的难度比我想得要高一点。