当软件开始"思考",工程如何"适应"
2026年的今天,软件系统的核心矛盾正在发生深刻转移。传统软件工程建立在一个基本假设之上:系统的行为是确定的,给定相同的输入,必然产生相同的输出。然而,大语言模型的引入彻底颠覆了这一假设------我们不再构建纯粹的逻辑系统,而是在与一个概率性的、涌现性的、黑箱化的智能体共舞。(扩展阅读:从CI/CD到CC/CD:AI应用不是"盖"出来的,是"种"出来的------解码大模型时代的软件工程范式革命)
作为亲历这场变革的架构师,我在过去两年中目睹了太多失败案例:团队将传统DevOps实践生搬硬套到AI应用开发中,结果陷入无休止的"热修复循环";产品经理期待"全自动驾驶"式的智能体,却收获用户信任崩塌;技术团队在"评估驱动"和"监控驱动"的虚假二分中迷失方向。
这一切的根源在于:我们试图用确定性的工程范式,驾驭不确定性的智能系统。
本文系统阐述大模型时代的新型软件工程范式------Continuous Calibration/Continuous Development(持续校准/持续开发,简称CC/CD)。这不是对传统CI/CD的替代,而是其在概率系统时代的必要延伸与重构。我们将从概念框架、技术实现、实践案例三个维度,揭示这场范式革命的内核。
传统范式的失效:确定性假设的崩塌
软件工程的三个时代
理解CC/CD的价值,需要先看清我们所处的历史坐标。朱少民、王千祥在《软件工程3.0》中系统梳理了软件工程的演进脉络:
-
软件工程1.0(结构化时代):以瀑布模型为核心,强调阶段划分与文档驱动。软件被视为可完全规划的工程产品。
-
软件工程2.0(敏捷/DevOps时代):以CI/CD/CD为核心,强调快速迭代与持续交付。软件被视为可不断演化的逻辑系统。
-
软件工程3.0(大模型时代):以大模型驱动为核心,软件开始具备"理解"和"生成"能力。软件开始具备"理解"和"生成"能力,系统行为从确定性走向概率性。
当前,我们正处于2.0向3.0过渡的关键期。这一过渡的核心挑战在于:2.0时代的工程范式,无法有效应对3.0时代智能组件的特殊性。
传统CI/CD的四个盲区
CI/CD(持续集成/持续交付/持续部署)在确定性软件领域已被证明是成功的范式。但当我们将它直接套用到AI应用开发时,四个根本性盲区浮现出来:
盲区一:非确定性输入
传统软件的用户交互路径是可预测的------用户在电商APP中,无非是点击商品、加入购物车、结算支付,这些路径在产品设计阶段就被明确映射。但大模型应用将这一层替换为流畅的自然语言界面。用户可以问"我的订单怎么还没到",也可以问"我上周买的那双鞋什么时候能送到",或者"能帮我查一下物流吗"------同样的意图,无穷的表达方式。
这意味着:我们无法穷举所有可能的输入来验证系统行为。
盲区二:非确定性输出
大模型作为概率性API,其输出对提示的措辞极其敏感。一个微小的prompt调整,可能导致回复风格、内容甚至正确性的巨大差异。更复杂的是,模型本身是黑箱------我们能看到输入和输出,但中间的推理过程无从追踪。
这意味着:我们无法保证相同输入永远产生相同输出。
盲区三:代理权与控制权的权衡
这是目前最被低估的挑战。AI practitioners Aishwarya Raanti和Kiti Bottom基于对超过50个AI产品部署的观察指出:每一次赋予AI系统决策能力,都意味着人类控制权的让渡。这形成了一个信任校准难题:系统必须首先证明其可靠性,才能被授予更高程度的自主权。
这意味着:从V1到Vn的演进路径,不再是单纯的功能堆叠,而是信任的渐进建立。
盲区四:评估的语义扩散
"评估"(evals)这个词已经失去了明确的含义。数据标注公司声称他们的专家在写评估------其实是在写错误分析笔记;产品经理被告知评估就是新的PRD;从业者用这个词指代从LLM裁判到模型基准测试的一切。有人声称自己在"做评估",实际上只是查看LM Arena和Artificial Analysis的基准测试------这是模型评估,而非应用评估。(扩展阅读:深度解读lmarena.ai排行榜:大模型竞技场的新标杆与未来趋势)
这意味着:我们需要重新定义:对于AI应用,什么才是有效的质量保障。
警示案例:过早自主化的代价
Raanti和Bottom分享了一个发人深省的案例:他们曾为一个客户构建端到端的客服智能体,最终被迫关闭。原因在于,他们一开始就赋予了系统完全的自主权。当问题涌现------幻觉、工具调用失败、数据质量问题------团队陷入无休止的热修复循环,每次修复都在没有系统方法的情况下应对新出现的问题。
另一个广为人知的案例是Air Canada事件:客服智能体幻觉出一项不存在的退款政策,公司最终被迫依法兑现。这不仅是技术失败,更是信任崩塌的典型案例。
这些教训揭示了一个核心洞见:**AI应用的开发路径,必须是从高控制低自主,向低控制高自主渐进演化的过程。**而这,正是Continuous Calibration/Continuous Development范式的设计起点。
范式革命:Continuous Calibration/Continuous Development 的概念框架
核心定义:什么是CC/CD?
基于OpenAI等机构一线实践者的经验总结,我们可以将CC/CD定义为:
Continuous Calibration/Continuous Development 是一种专为大模型驱动的软件系统设计的工程范式,它以"渐进式自主化"为核心原则,通过持续的行为校准 与能力开发的循环迭代,在保障用户体验和信任的前提下,逐步提升系统的智能程度与自主决策能力。
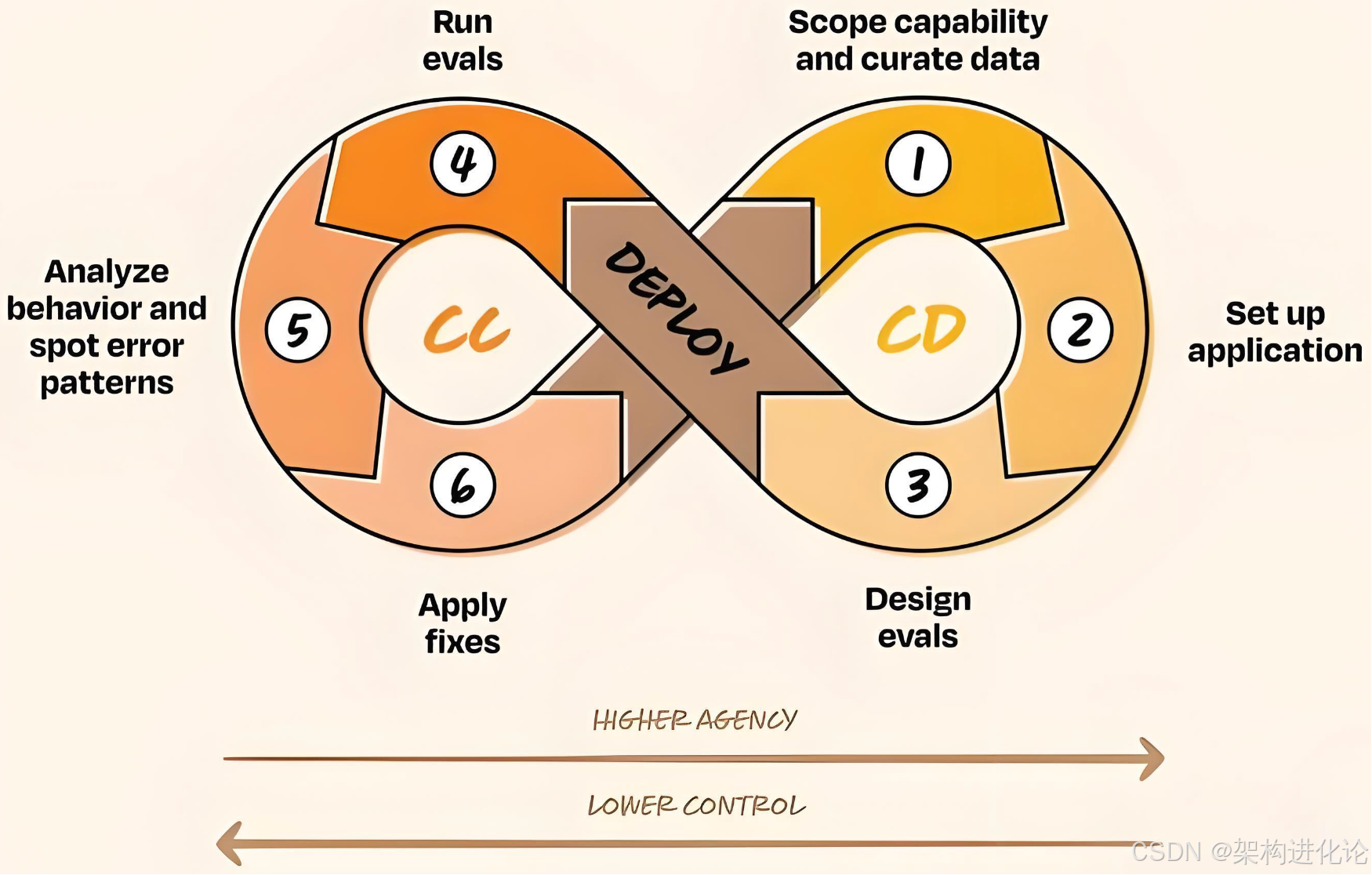
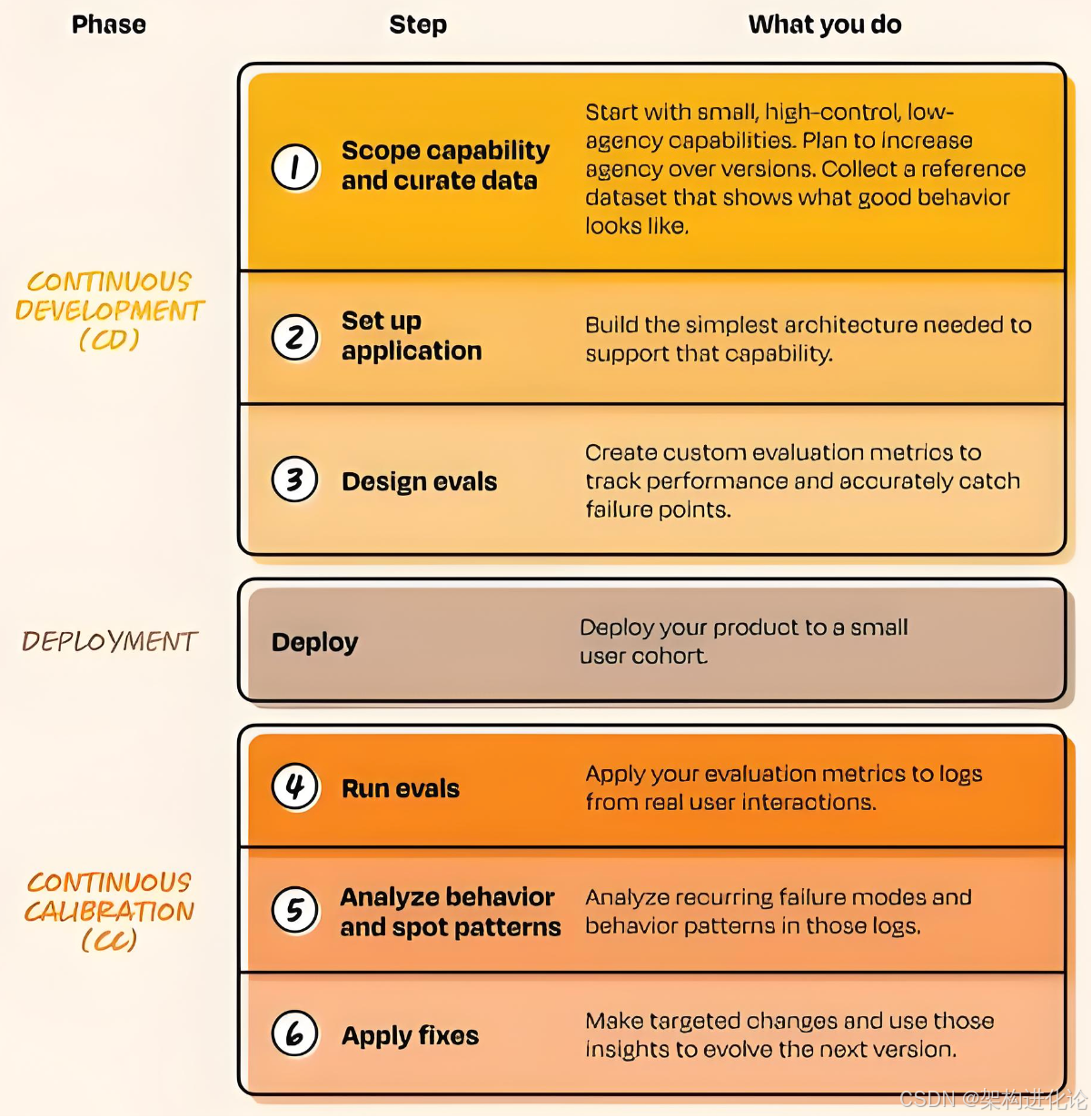
这一范式的两个核心阶段构成一个闭环:
-
Continuous Development(持续开发) :负责能力范围的界定、期望输入输出的数据集的构建、应用基础设施的搭建、以及初始评估指标的设计。这一阶段的产出是一个受控环境下的最小可行智能系统。
-
Continuous Calibration(持续校准) :负责生产环境中涌现行为的观测与分析、新型错误模式的识别与修复、以及基于真实反馈的评估指标扩展。这一阶段的产出是对系统行为边界的更深入理解 ,以及驱动下一轮开发的优化信号。
生活化案例:学车与自动驾驶
理解CC/CD的最佳方式,是借助一个生活化的类比:学车过程 vs. 自动驾驶研发。
传统CI/CD(如传统软件开发) 类似于驾校考试:
-
你学习标准操作流程(启动、换挡、停车);
-
你在标准场地(驾校考场)接受测试;
-
考官用预设项目(侧方停车、坡道起步)评估你是否合格;
-
一旦通过,你被授予驾照,默认具备在各种道路驾驶的能力。
问题是:驾校考场的通过,能否保证真实道路的安全?
CC/CD范式 则更接近渐进式自动驾驶系统的研发:
-
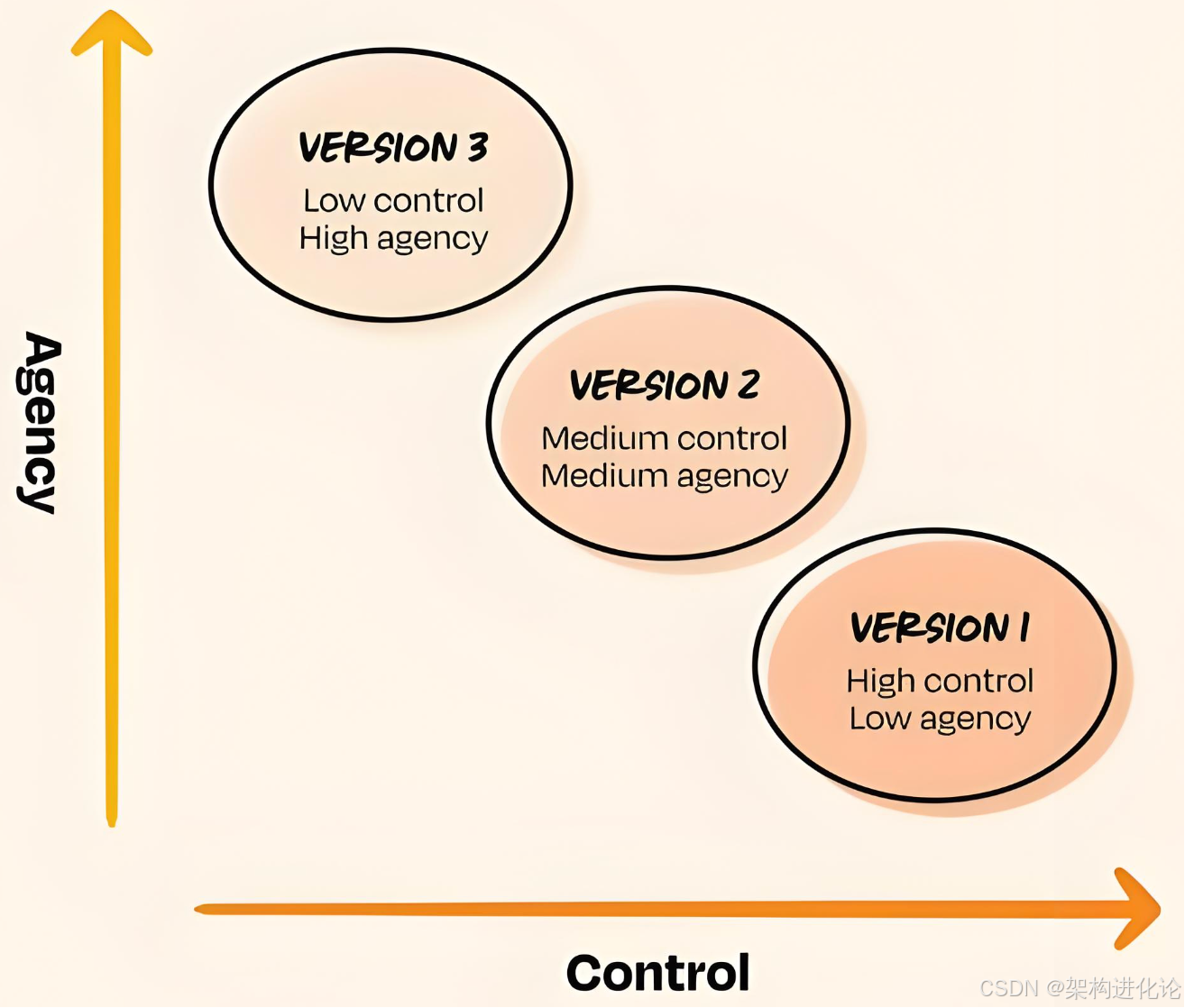
V1阶段(人类完全控制):你亲自驾驶,系统只提供环境感知提醒(如车道偏离预警)。这对应CC/CD的起点------高人类控制、低AI代理。
-
V2阶段(辅助驾驶):系统可以在高速公路上保持车道和车距,但你仍需全程监控,随时准备接管。系统记录你的每一次干预------什么时候你觉得系统判断有误?这些成为校准数据。
-
V3阶段(有条件的自动驾驶):系统可以在大多数场景下自主驾驶,但在复杂路口或恶劣天气时会请求你接管。系统的自主范围基于历史数据证明的安全性。
-
V4阶段(高度自动驾驶):系统可以在限定区域内完全自主,但你仍需在远程监控中心保持监督。
这一演进的核心逻辑是:**自主权的每一次提升,都必须基于前一阶段积累的"信任证据"------即系统已证明能够在当前边界内安全可靠地运行。**这正是Continuous Calibration的核心使命。
双C的协同机制:从评估到监测的反馈闭环
CC/CD框架中最精妙的设计,在于Continuous Calibration与Continuous Development之间的反馈机制:
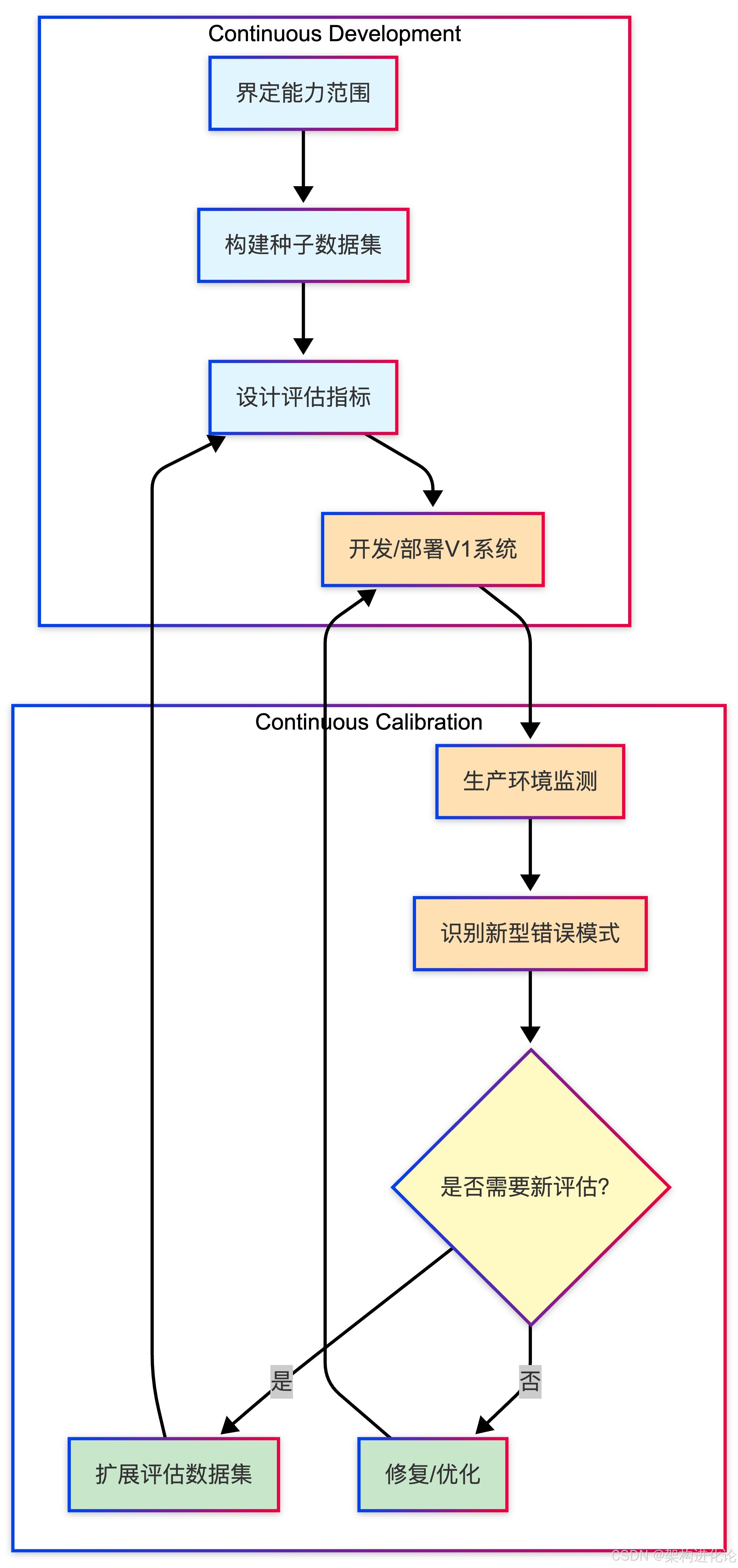
这一机制的核心洞见是:评估(Evals)只能捕捉你已经知道的错误类型;而生产监测(Monitoring)才能发现你未曾预见的失败模式。
-
评估集编码的是团队对系统行为的"已知期望"------那些团队认为系统必须正确处理的关键场景。它是产品知识的固化形态。
-
生产监测捕获的是真实用户的使用模式------包括显式反馈(点赞/点踩)和隐式信号(用户要求重新生成回答,这通常意味着初始回复未能满足期望)。
当生产监测发现新的失败模式时,团队需要判断:这是一个一次性问题,还是需要纳入评估集以防止未来回归的系统性风险?如果是后者,评估数据集就得到一次扩展。这个"生产发现 → 评估扩展 → 开发优化"的循环,正是系统持续进化的动力。
渐进式自主化:从V1到Vn的演进路径
CC/CD框架最实用的产出,是一张清晰的渐进式自主化路线图。Raanti和Bottom给出了多个领域的演进示例:
代码助手演进路径:
-
V1:行内补全、代码片段生成(人类完全审查)
-
V2:较大代码块生成(测试、重构),供人类审查
-
V3:自主应用变更并创建Pull Request(人类抽查)
营销助手演进路径:
-
V1:生成邮件/社交媒体文案草稿
-
V2:构建并运行多步骤营销活动(需人类审批)
-
V3:自主启动活动,并进行跨渠道A/B测试优化
客服助手演进路径:
-
V1:工单路由
-
V2:Copilot模式------基于SOP生成回复草稿,人类可修改
-
V3:端到端解决------自主回复并关闭工单
这张路线图的价值在于:它为产品经理、工程师、数据科学家提供了共同的路线图语言 ,帮助团队避免"一步到位"的陷阱,在每一个阶段都聚焦于证明系统已准备好进入下一阶段。
技术深潜:Continuous Calibration的核心能力建设
将CC/CD从理念落地为实践,需要构建一系列新型技术能力。以下从四个核心维度展开。
渐进式自主化设计:以客服智能体为例
让我们通过一个完整案例,具象化CC/CD的演进过程。
场景:某电商平台希望构建智能客服系统,处理用户咨询、订单查询、售后申请等任务。
阶段一:工单路由(V1)
第一版系统只做一件事:根据用户输入,判断应该分配给哪个部门------物流部门、售后部门还是商品咨询部门。
这个看似简单的功能,实际上蕴含着巨大的校准价值。Raanti和Bottom指出:企业的部门分类(taxonomy)往往是"层次混乱的遗产"------鞋子、女鞋、男鞋出现在同一层级,旁边还有冗余的"女士"和"男士"节点自2019年以来未更新。人类客服知道隐含规则------比如检查最后更新日期来识别失效节点------但这些规则没有任何文档。
路由阶段的核心价值 :迫使团队在高人类控制的环境下,暴露和修复数据质量问题。如果工单被错误路由,人工可以轻松纠正,同时记录下纠正的原因------这些原因将成为下一阶段的训练数据。
阶段二:Copilot模式(V2)
在路由准确率达到可接受水平后,系统进入第二阶段:基于标准操作流程(SOP)生成回复草稿。客服人员收到用户问题时,系统会展示一个建议回复,客服可以采纳、修改或完全重写。
这个阶段创造了关键的数据飞轮:通过记录草稿被修改的程度,系统获得免费的误差分析。如果客服经常修改某类问题的回复,说明系统对该类问题的处理有待优化------这些信号将驱动下一轮校准。
阶段三:端到端解决(V3)
只有当系统证明其草稿很少需要修改时,才被授予端到端解决的权限------自主回复用户问题并关闭工单。这标志着系统已经"毕业":它在足够多的场景中证明了可靠性,赢得了进入下一阶段的权利。
评估数据集的演化管理
在CC/CD范式中,评估数据集(Evaluation Dataset)不是一次性产物,而是需要持续演化的"活资产"。
python
# eval_dataset_evolution.py
"""
评估数据集演化管理 - 展示评估集如何基于生产发现持续扩展
"""
import json
import hashlib
from datetime import datetime
from typing import List, Dict, Optional
from dataclasses import dataclass, field
@dataclass
class TestCase:
"""测试用例 - 评估数据集的基本单元"""
id: str
input: str
expected_output: str
task_type: str
added_at: datetime
added_reason: str # 为什么添加这个用例(初始设计/生产发现/回归预防)
tags: List[str] = field(default_factory=list)
def __post_init__(self):
if not self.id:
content = f"{self.input}{self.expected_output}{self.added_at}"
self.id = hashlib.md5(content.encode()).hexdigest()[:8]
class EvaluationDataset:
"""评估数据集 - 支持版本化和演化追踪"""
def __init__(self, name: str, version: str = "1.0.0"):
self.name = name
self.version = version
self.test_cases: Dict[str, TestCase] = {}
self.version_history: List[Dict] = []
self._record_version("initial_creation")
def add_test_case(self, test_case: TestCase):
"""添加新的测试用例"""
self.test_cases[test_case.id] = test_case
print(f"[数据集演化] 添加测试用例: {test_case.id}")
print(f" 输入: {test_case.input[:50]}...")
print(f" 原因: {test_case.added_reason}")
def add_from_production_failure(self,
user_input: str,
failure_description: str,
corrected_output: str,
task_type: str):
"""基于生产失败案例添加测试用例"""
test_case = TestCase(
id="",
input=user_input,
expected_output=corrected_output,
task_type=task_type,
added_at=datetime.now(),
added_reason=f"生产发现: {failure_description}",
tags=["from_production", "regression_prevention"]
)
self.add_test_case(test_case)
def _record_version(self, reason: str):
"""记录数据集版本变更"""
self.version_history.append({
"version": self.version,
"timestamp": datetime.now().isoformat(),
"reason": reason,
"test_case_count": len(self.test_cases)
})
def save_version(self, reason: str):
"""保存当前版本(模拟版本控制)"""
# 实际实现中,这里会将数据集保存到存储,并更新版本号
new_version = self._bump_version()
self._record_version(reason)
print(f"\n[数据集演化] 新版本已保存: {new_version}")
print(f" 原因: {reason}")
print(f" 测试用例数: {len(self.test_cases)}")
def _bump_version(self) -> str:
"""递增版本号(简化实现)"""
major, minor, patch = self.version.split(".")
new_patch = int(patch) + 1
self.version = f"{major}.{minor}.{new_patch}"
return self.version
def analyze_coverage(self) -> Dict:
"""分析数据集覆盖情况"""
task_types = {}
added_reasons = {}
for case in self.test_cases.values():
# 按任务类型统计
task_types[case.task_type] = task_types.get(case.task_type, 0) + 1
# 按添加原因统计
added_reasons[case.added_reason] = added_reasons.get(case.added_reason, 0) + 1
return {
"total_cases": len(self.test_cases),
"by_task_type": task_types,
"by_reason": added_reasons,
"version": self.version
}
# 使用示例
def eval_dataset_demo():
# 创建初始评估集
dataset = EvaluationDataset("客服意图识别", "1.0.0")
# 初始设计阶段添加的用例
dataset.add_test_case(TestCase(
id="",
input="我的订单什么时候到?",
expected_output="查询订单",
task_type="intent_classification",
added_at=datetime.now(),
added_reason="初始设计-常见用户问题"
))
dataset.add_test_case(TestCase(
id="",
input="我要退货,衣服尺码不对",
expected_output="申请售后",
task_type="intent_classification",
added_at=datetime.now(),
added_reason="初始设计-常见用户问题"
))
# 保存初始版本
dataset.save_version("初始设计完成")
# 模拟生产环境发现的失败案例
production_failures = [
{
"input": "你们客服电话多少",
"failure": "模型回复'客服电话可在官网查询',用户非常不满",
"corrected": "咨询联系方式",
"task": "intent_classification"
},
{
"input": "我上周买的那双鞋能换颜色吗",
"failure": "模型意图识别为'查询订单',实际应为'申请售后'",
"corrected": "申请售后",
"task": "intent_classification"
}
]
for failure in production_failures:
dataset.add_from_production_failure(
user_input=failure["input"],
failure_description=failure["failure"],
corrected_output=failure["corrected"],
task_type=failure["task"]
)
# 保存新版本
dataset.save_version("基于生产失败案例扩展")
# 分析覆盖情况
coverage = dataset.analyze_coverage()
print("\n[数据集覆盖分析]")
print(f"总用例数: {coverage['total_cases']}")
print("按任务类型:", coverage['by_task_type'])
print("按添加原因:", coverage['by_reason'])
# 运行示例
eval_dataset_demo()生产监测与错误模式识别
生产监测在CC/CD框架中扮演着"传感器"的角色------它不仅收集数据,更重要的是识别新型错误模式,驱动评估集的演化。
python
# production_monitoring.py
"""
生产监测系统 - 识别新型错误模式并触发校准
"""
from datetime import datetime, timedelta
from typing import List, Dict, Optional
from dataclasses import dataclass
import random
from collections import Counter
@dataclass
class InteractionLog:
"""用户交互日志"""
timestamp: datetime
user_input: str
model_output: str
user_feedback: Optional[int] # 1-5分,None表示无反馈
regenerated: bool # 用户是否要求重新生成
task_type: str
latency_ms: int
session_id: str
class ErrorPatternDetector:
"""错误模式检测器 - 从日志中发现新型错误"""
def __init__(self, lookback_hours: int = 24):
self.lookback = timedelta(hours=lookback_hours)
self.logs: List[InteractionLog] = []
self.known_patterns: Dict[str, Dict] = {} # 已识别的模式
self.alert_threshold = 5 # 同一模式出现5次触发告警
def add_log(self, log: InteractionLog):
"""添加新的交互日志"""
self.logs.append(log)
def analyze_recent(self) -> List[Dict]:
"""分析近期日志,识别错误模式"""
cutoff = datetime.now() - self.lookback
recent = [log for log in self.logs if log.timestamp >= cutoff]
# 识别负面信号
negative_logs = [
log for log in recent
if (log.user_feedback and log.user_feedback <= 2) or log.regenerated
]
if len(negative_logs) < self.alert_threshold:
return []
# 聚类分析(简化版:按输入模式聚类)
patterns = self._cluster_by_input_pattern(negative_logs)
# 过滤掉已知模式
new_patterns = []
for pattern in patterns:
pattern_id = self._generate_pattern_id(pattern)
if pattern_id not in self.known_patterns:
pattern["id"] = pattern_id
pattern["first_seen"] = datetime.now()
pattern["occurrence_count"] = pattern["logs_count"]
new_patterns.append(pattern)
self.known_patterns[pattern_id] = pattern
return new_patterns
def _cluster_by_input_pattern(self, logs: List[InteractionLog]) -> List[Dict]:
"""按输入模式聚类(简化实现)"""
# 实际应用中,这里会使用文本聚类算法
# 这里模拟返回两个聚类结果
clusters = [
{
"pattern_description": "用户询问联系方式",
"keywords": ["电话", "客服", "联系", "人工"],
"logs_count": 3,
"sample_input": "你们客服电话多少",
"typical_output": "客服电话可在官网查询",
"error_type": "信息缺失"
},
{
"pattern_description": "用户表达不满时回复生硬",
"keywords": ["投诉", "差评", "生气", "不满"],
"logs_count": 4,
"sample_input": "你们服务太差了,我要投诉",
"typical_output": "已记录您的投诉,将转交相关部门",
"error_type": "情感不匹配"
}
]
return clusters
def _generate_pattern_id(self, pattern: Dict) -> str:
"""生成模式唯一ID"""
content = f"{pattern['pattern_description']}{pattern['error_type']}"
import hashlib
return hashlib.md5(content.encode()).hexdigest()[:8]
class CalibrationTrigger:
"""校准触发器 - 基于错误模式触发校准流程"""
def __init__(self, detector: ErrorPatternDetector):
self.detector = detector
self.calibration_events = []
def run_periodic_check(self):
"""周期性检查并触发校准"""
print(f"\n[校准检查] {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
new_patterns = self.detector.analyze_recent()
if not new_patterns:
print(" 未发现新型错误模式")
return
print(f" 发现 {len(new_patterns)} 个新型错误模式")
for pattern in new_patterns:
self._trigger_calibration(pattern)
def _trigger_calibration(self, pattern: Dict):
"""触发校准流程"""
event = {
"timestamp": datetime.now(),
"pattern_id": pattern["id"],
"pattern_description": pattern["pattern_description"],
"occurrence_count": pattern["occurrence_count"],
"status": "pending"
}
self.calibration_events.append(event)
print(f"\n🚨 [校准触发] 新型错误模式")
print(f" 模式ID: {pattern['id']}")
print(f" 描述: {pattern['pattern_description']}")
print(f" 出现次数: {pattern['occurrence_count']}")
print(f" 示例输入: {pattern['sample_input']}")
print(f" 错误类型: {pattern['error_type']}")
print(f" 建议操作: 评估是否需要纳入评估集")
# 使用示例
def monitoring_demo():
# 创建检测器和触发器
detector = ErrorPatternDetector(lookback_hours=24)
trigger = CalibrationTrigger(detector)
# 模拟添加一些日志
now = datetime.now()
# 正常日志
for i in range(50):
detector.add_log(InteractionLog(
timestamp=now - timedelta(hours=random.randint(1, 23)),
user_input=f"查询订单{i}",
model_output="订单状态正常",
user_feedback=5,
regenerated=False,
task_type="order_query",
latency_ms=random.randint(500, 1500),
session_id=f"session_{i}"
))
# 负面日志 - 联系方式类
for i in range(3):
detector.add_log(InteractionLog(
timestamp=now - timedelta(hours=random.randint(1, 23)),
user_input="客服电话多少",
model_output="客服电话可在官网查询",
user_feedback=1,
regenerated=True,
task_type="general_inquiry",
latency_ms=800,
session_id=f"session_bad_{i}"
))
# 负面日志 - 投诉类
for i in range(4):
detector.add_log(InteractionLog(
timestamp=now - timedelta(hours=random.randint(1, 23)),
user_input="你们服务太差了,我要投诉",
model_output="已记录您的投诉,将转交相关部门",
user_feedback=2,
regenerated=True,
task_type="complaint",
latency_ms=950,
session_id=f"session_bad2_{i}"
))
# 运行检查
trigger.run_periodic_check()
# 运行示例
monitoring_demo()知识校准:超越微调的另一种可能
CC/CD框架中,"校准"(Calibration)一词还有更深层的技术含义。近期研究提出了"知识校准"(Knowledge Calibration)的概念,为模型优化提供了微调之外的新路径。
Calico系统的研究显示:大语言模型在代码任务中的性能不足,往往源于"知识缺口"------模型未能理解代码结构中的某些关键信息。Calico采用进化式方法,通过知识校准和缺陷诊断,自动重构代码以融入被忽视的知识,从而提升模型性能。实验表明,该方法可将ChatGPT在代码任务上的性能提升20%,达到与微调模型相当的水平,同时避免了高昂的计算成本。
这一思路对CC/CD的启示在于:校准不一定意味着重新训练模型。在许多场景下,通过优化输入(如提示工程、知识注入、检索增强)来"校准"模型行为,可能比微调更高效、更可持续。
代码示例:基于知识校准的缺陷诊断
python
# knowledge_calibration.py
"""
知识校准示例 - 展示如何通过知识注入修复模型缺陷
"""
from typing import Dict, List, Optional
import ast
class CodeKnowledgeCalibrator:
"""代码知识校准器 - 识别并注入被忽视的知识"""
def __init__(self, model):
self.model = model # 实际应用中这里是大模型
self.knowledge_base = self._init_knowledge_base()
def _init_knowledge_base(self) -> Dict:
"""初始化知识库"""
return {
"python_patterns": {
"list_comprehension": "列表推导式比for循环更高效,但复杂逻辑应保留for循环以提高可读性",
"context_manager": "使用with语句确保资源正确释放",
"type_hints": "类型提示有助于代码可读性和静态检查"
},
"common_pitfalls": {
"mutable_default": "不要使用可变对象作为函数默认参数",
"exception_hiding": "避免捕获所有异常却不处理",
"race_condition": "多线程环境下注意共享资源的同步访问"
}
}
def analyze_code(self, code: str) -> Dict:
"""分析代码,识别潜在的知识缺口"""
try:
tree = ast.parse(code)
except SyntaxError:
return {"error": "代码语法错误"}
findings = []
# 遍历AST,检查常见模式
for node in ast.walk(tree):
# 检查函数定义中的可变默认参数
if isinstance(node, ast.FunctionDef):
for arg, default in zip(node.args.args[-len(node.args.defaults):], node.args.defaults):
if isinstance(default, (ast.List, ast.Dict, ast.Set)):
findings.append({
"type": "mutable_default",
"location": node.lineno,
"knowledge": self.knowledge_base["common_pitfalls"]["mutable_default"],
"severity": "high"
})
# 检查裸的except
if isinstance(node, ast.ExceptHandler):
if node.type is None:
findings.append({
"type": "exception_hiding",
"location": node.lineno,
"knowledge": self.knowledge_base["common_pitfalls"]["exception_hiding"],
"severity": "medium"
})
return {
"code": code,
"findings": findings,
"has_issues": len(findings) > 0
}
def calibrate_code(self, code: str) -> Dict:
"""校准代码 - 基于知识注入优化代码"""
analysis = self.analyze_code(code)
if not analysis["has_issues"]:
return {"status": "no_calibration_needed", "code": code}
# 生成校准建议
suggestions = []
for finding in analysis["findings"]:
suggestions.append({
"issue": finding["type"],
"location": finding["location"],
"knowledge": finding["knowledge"],
"suggestion": self._generate_suggestion(finding)
})
# 实际应用中,这里会基于建议重新生成代码
calibrated_code = self._apply_suggestions(code, suggestions)
return {
"status": "calibrated",
"original_code": code,
"calibrated_code": calibrated_code,
"suggestions": suggestions,
"finding_count": len(analysis["findings"])
}
def _generate_suggestion(self, finding: Dict) -> str:
"""生成具体的修改建议"""
if finding["type"] == "mutable_default":
return "将可变默认参数改为None,在函数体内初始化"
elif finding["type"] == "exception_hiding":
return "指定具体的异常类型,或至少记录异常信息"
else:
return "参考知识库进行调整"
def _apply_suggestions(self, code: str, suggestions: List) -> str:
"""应用建议生成校准后代码(简化实现)"""
# 实际应用中,这里会调用大模型进行代码重构
lines = code.split("\n")
# 模拟修改:添加注释说明问题
for suggestion in suggestions:
if suggestion["issue"] == "mutable_default":
lines.insert(
suggestion["location"],
f"# TODO: {suggestion['knowledge']} - {suggestion['suggestion']}"
)
return "\n".join(lines)
# 使用示例
def knowledge_calibration_demo():
calibrator = CodeKnowledgeCalibrator(model=None)
# 有问题的代码
problematic_code = '''
def add_item(item, items=[]):
items.append(item)
return items
def process_data(data):
try:
result = data.process()
return result
except:
return None
'''
print("原始代码:")
print(problematic_code)
result = calibrator.calibrate_code(problematic_code)
print("\n" + "="*50)
print("校准结果:")
print(f"状态: {result['status']}")
print(f"发现的问题数: {result['finding_count']}")
for suggestion in result.get('suggestions', []):
print(f"\n问题类型: {suggestion['issue']}")
print(f"知识: {suggestion['knowledge']}")
print(f"建议: {suggestion['suggestion']}")
if 'calibrated_code' in result:
print("\n校准后代码:")
print(result['calibrated_code'])
# 运行示例
knowledge_calibration_demo()CC/CD与传统DevOps的融合:双轨并行
融合架构全景图
CC/CD不是对传统DevOps的替代,而是其在大模型时代的必要延伸。两者应形成协同工作的双轨体系:
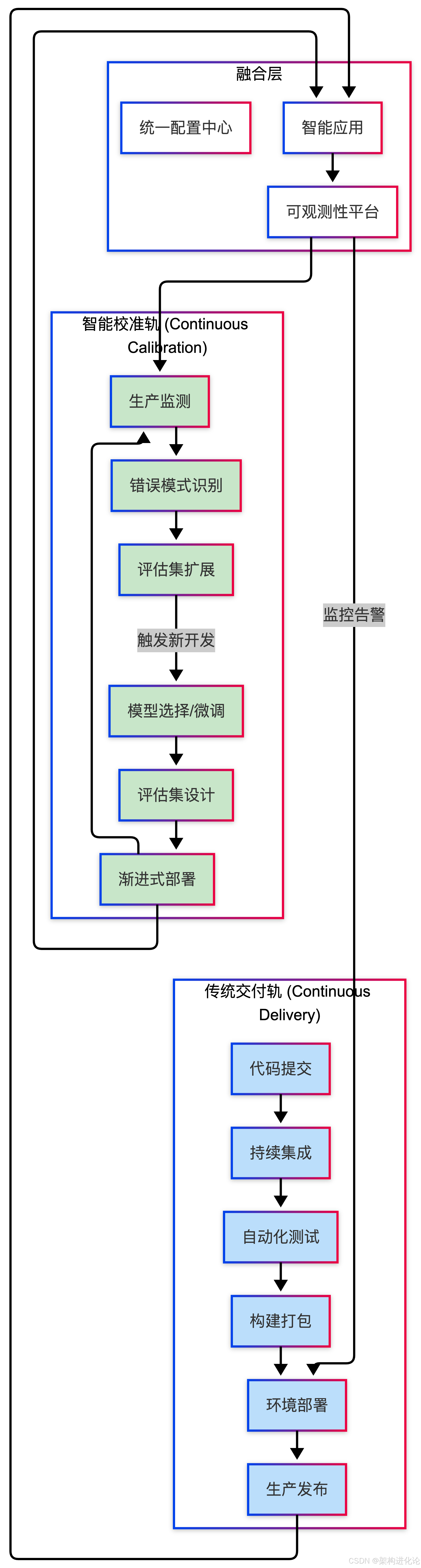
双轨的协同机制
两条轨道的协同体现在三个层面:
第一层:部署协同
传统CD轨负责应用的基础设施和确定性代码的部署;校准轨负责模型版本、提示模板、RAG知识库等智能组件的部署。两者在统一配置中心的协调下,实现平滑的版本升级。
第二层:监测协同
传统可观测性平台(指标、日志、追踪)与校准轨的行为理解层协同工作。当校准轨识别到新型错误模式时,可以触发传统CD轨的应急响应流程(如自动回滚或金丝雀发布)。(扩展阅读:从定性到量化:为何指标是非功能性需求的灵魂与尺度、解读运维四大关键指标:MTTR、MTTA、MTTF、MTBF、微服务架构的可观测性三要素:从监控到洞察的架构演进、微服务可观测性的"1-3-5"理想:从理论到实践的故障恢复体系)
第三层:数据协同
校准轨积累的高质量交互数据,不仅用于模型优化,也可以反馈给传统开发团队,用于改进产品设计、完善SOP文档、优化业务流程。
组织能力的重塑
双轨体系的成功实施,需要组织能力的相应调整。Raanti和Bottom指出,成功的AI采纳有三个维度:领导力、文化、技术执行。
领导力维度:领导者需要重建过去10-15年积累的直觉。他们引用了一个案例:某CEO每天凌晨4-6点专门用于"追赶AI",周末进行白板讨论。这不是为了亲自实现,而是为了重建决策直觉------这需要勇气接受"我是房间里最无知的人"并愿意向所有人学习。
文化维度:必须强调赋能而非替代恐惧。领域专家对AI产品成功至关重要,但当他们感到威胁时往往会抗拒参与。成功的组织将AI定位为能力放大器------将生产力提升10倍、打开新机会------而非替代者。
技术执行维度:成功的团队痴迷于理解工作流程,识别适合自动化的片段与需要人工参与的环节。他们认识到,大多数自动化是机器学习模型、LLM能力和确定性代码的组合,而不是纯粹的AI解决方案。
实践指南:CC/CD的实施路线图
基于上述分析,我们可以勾勒出一条CC/CD的实施路线图。
阶段一:诊断与规划(1-2个月)
核心任务:
-
识别适合渐进式自主化的业务场景
-
绘制当前工作流程,标记关键决策点
-
设计V1阶段的高控制、低自主方案
-
构建种子评估数据集
关键产出:渐进式自主化路线图、V1评估集
阶段二:V1构建与部署(2-3个月)
核心任务:
-
实现V1功能(如工单路由、草稿生成)
-
建立生产监测体系
-
部署系统,开始收集真实交互数据
-
建立人工反馈机制
关键产出:可运行的V1系统、生产监测基线
阶段三:校准循环(持续)
核心任务:
-
定期分析生产监测数据
-
识别新型错误模式
-
扩展评估数据集
-
优化系统行为
-
评估是否具备进入下一阶段的条件
关键产出:持续扩展的评估集、行为优化记录
阶段四:渐进式升级(按需)
核心任务:
-
当V1系统证明可靠性后,设计V2方案
-
适度提升系统自主权
-
重复校准循环
关键产出:新版本系统、升级决策记录
Raanti和Bottom强调:可靠AI产品通常需要4-6个月的工作,即使在数据和基础设施层最优的情况下也是如此。他们对承诺"一键智能体"并能立即带来显著ROI的供应商持明确怀疑态度,称这纯粹是营销话术。挑战不在于模型能力,而在于企业数据的混乱------名为"get_customer_data_v1"和"get_customer_data_v2"的函数并存、技术债务积累、复杂的隐含规则。智能体需要时间学习这些系统怪癖,就像人类员工需要入职培训一样。
校准完成指标
如何判断系统已准备好进入下一阶段?Raanti和Bottom提出的标准是:最小化意外。当日度或双日度校准会议不再发现新的数据分布模式,用户行为趋于一致,信息增益接近零时,就表明系统已具备进入下一自主权阶段的条件。
但校准可能被以下事件中断:
-
模型变更:GPT-4退役强制迁移到GPT-4.5,新模型具有不同特性,需要重新校准
-
用户行为演化:用户被解决某一任务的能力激发,自然尝试将系统应用于相邻问题,而不意识到需要架构变更
挑战与未来展望
当前挑战
技术挑战:
-
多智能体系统的校准复杂性:许多团队试图通过分解问题为子智能体责任,期望通过"八卦协议"式的点对点通信实现协调成功------但这在实践中很少奏效
-
评估与监测的平衡:找到适合具体应用场景的评估-监测配比仍是艺术
-
数据飞轮的冷启动:初期缺乏高质量反馈数据
组织挑战:
-
角色边界消融:产品经理、工程师、数据专业人员现在需要一起检查智能体追踪轨迹,共同做出产品行为决策
-
期望管理:管理层对AI能力的不切实际预期
-
技能结构转型:从编码能力转向"训练+校准+调试"的复合能力
未来趋势
展望未来三年,CC/CD范式将向以下方向演进:
趋势一:校准自动化:基于强化学习和用户行为分析的新型错误模式自动识别与修复
趋势二:个性化校准:针对不同用户群体、不同使用场景的差异化校准策略
趋势三:联邦校准:在保护隐私的前提下,跨组织共享校准洞见和错误模式库
趋势四:校准即服务:校准能力平台化,成为AI基础设施的核心组件
从交付到校准的认知跃迁
大模型时代的软件工程范式革命,本质上是从"交付确定性"到"校准概率性"的认知跃迁。
传统CI/CD追求的是:将确定性的代码变更,通过标准化的流水线,稳定地交付到生产环境。它的核心隐喻是流水线------输入原材料,经过一系列工序,产出标准产品。
CC/CD追求的是:将概率性的智能体,通过渐进的信任建立,安全地融入业务流程。它的核心隐喻是驯鹰------你无法"构建"一只鹰,但可以通过持续的训练、反馈、校准,让它学会在可控范围内自主狩猎,同时始终在需要时召回。
这一隐喻的背后,是人类与智能系统关系的重新定义。我们不再是事无巨细的指令发出者,而是把握方向的引导者。在CC/CD范式中,每一次校准都是信任的积累,每一次演进都是能力的提升。
作为从业者,我们需要同时拥抱两种思维:工程师的严谨(对可观测性、可复现性的坚持)与园丁的耐心(对不确定性、渐进性的接纳)。在这条从流水线走向驯鹰的路上,CC/CD为我们提供了一份路线图------剩下的,需要在真实的生产环境中,一步一个脚印地走完。