目录
[6.1 计算机视觉问题](#6.1 计算机视觉问题)
[6.2 模型的种类](#6.2 模型的种类)
[6.2.1 判别模型](#6.2.1 判别模型)
[6.2.2 生成模型](#6.2.2 生成模型)
[6.3 示例 1:回归](#6.3 示例 1:回归)
[6.3.1 判别模型(线性回归)](#6.3.1 判别模型(线性回归))
[6.3.2 生成模型(高斯回归)](#6.3.2 生成模型(高斯回归))
[6.4 示例 2:二值分类](#6.4 示例 2:二值分类)
[6.4.1 判别模型(逻辑回归)](#6.4.1 判别模型(逻辑回归))
[6.4.2 生成模型(高斯判别分析 GDA)](#6.4.2 生成模型(高斯判别分析 GDA))
[6.5 应该用哪种模型](#6.5 应该用哪种模型)
[6.6 应用](#6.6 应用)
[6.6.1 皮肤检测](#6.6.1 皮肤检测)
[6.6.2 背景差分](#6.6.2 背景差分)
前言

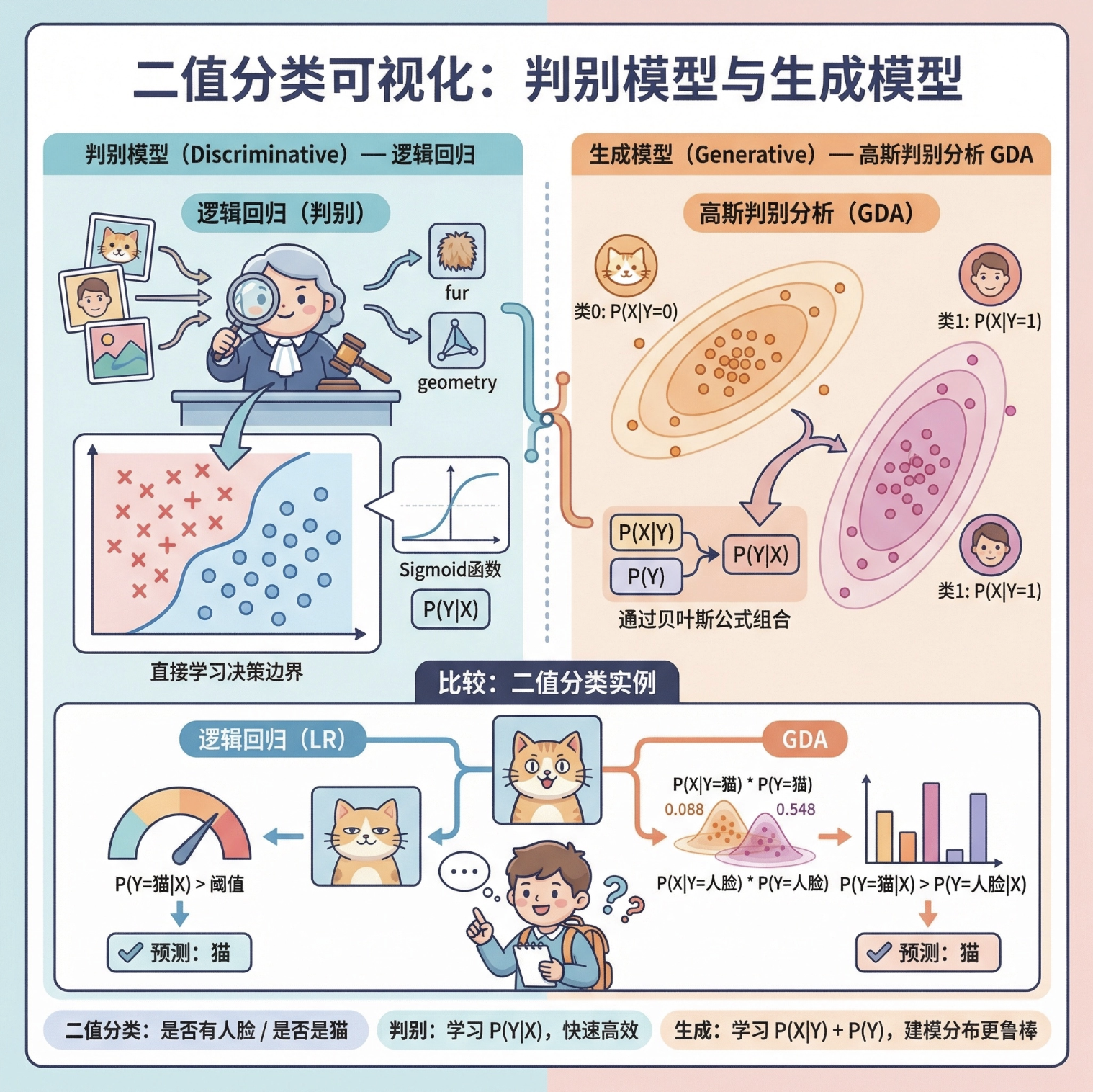
大家好!今天我们来深度拆解《计算机视觉:模型、学习和推理》这本书的第 6 章 ------ 视觉学习和推理。这一章是计算机视觉从 "理论" 走向 "落地" 的核心,很多新手会被 "判别模型"" 生成模型 " 这些概念绕晕,所以我会用最通俗的语言、结合可直接运行的 Python 代码和可视化对比图,帮你彻底搞懂这些核心知识点。
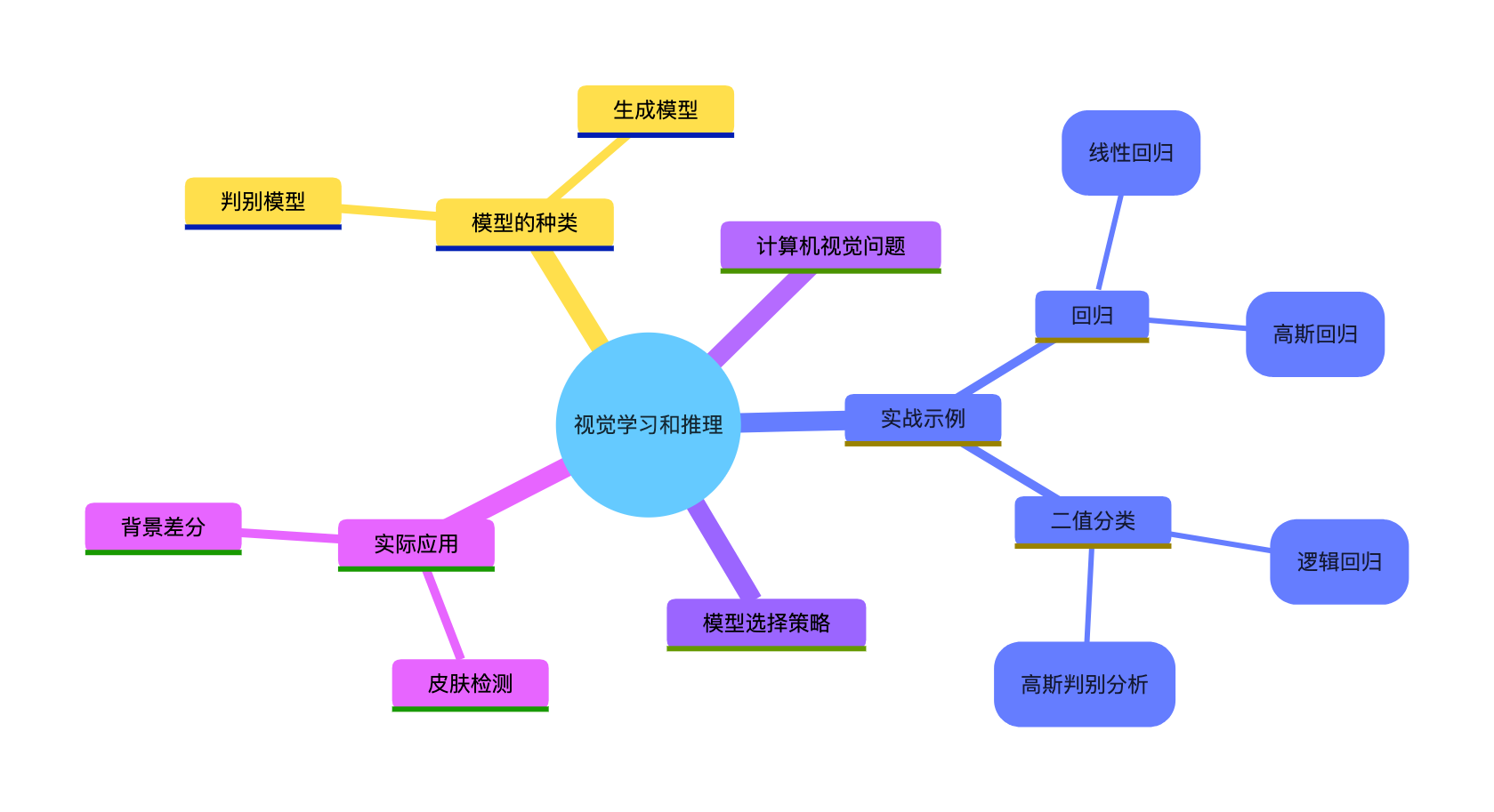
先放一张本章核心知识点的思维导图,帮你建立整体认知:
6.1 计算机视觉问题
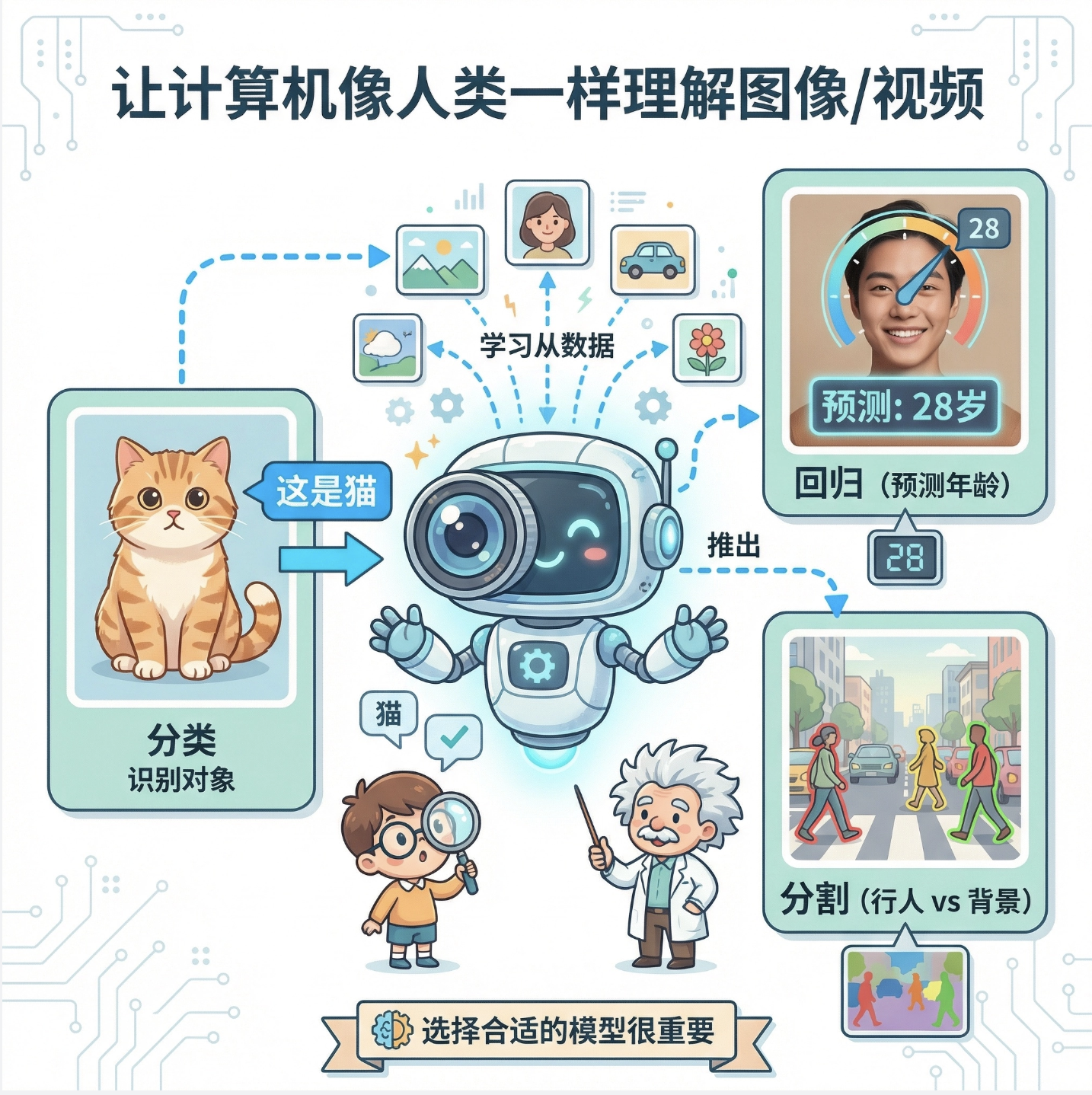
计算机视觉的核心可以通俗理解为:让电脑像人一样 "看懂" 图片 / 视频,并能根据看到的内容做判断、做预测。
比如:
- 从照片里识别出 "这是一只猫"(分类问题)
- 预测一张人脸照片中人物的年龄(回归问题)
- 从视频里区分出 "行人" 和 "背景"(分割问题)
这些问题本质上都是 "从视觉数据中学习规律,并利用规律做推理",而解决这些问题的核心就是选择合适的模型。
6.2 模型的种类

这是本章的核心概念,先给两个生动的比喻:
判别模型:像一个 "经验丰富的法官",只关注 "证据" 和 "结论" 的直接关系,不管证据是怎么来的。比如看到 "有胡须、尖耳朵、毛茸茸" 就直接判断 "是猫"。
生成模型 :像一个 "全能的造物主",不仅能判断,还能还原 / 生成 "证据本身"。比如不仅能判断是猫,还能根据特征生成一张猫的图片。
6.2.1 判别模型

核心逻辑 :直接学习输入(视觉特征)和输出(标签 / 预测值)之间的映射关系,目标是 "精准判断",数学上表示为 P(Y∣X)(给定 X 时 Y 的概率)。
- 优点:简单、训练快、推理效率高
- 常见例子:线性回归、逻辑回归、SVM、决策树
6.2.2 生成模型

核心逻辑 :先学习输入数据本身的分布 P(X∣Y)(给定标签 Y 时 X 的分布),再结合先验概率 P(Y) 推导 P(Y∣X),目标是 "理解数据并生成数据"。
- 优点:能捕捉数据的整体分布,鲁棒性更强,可生成新样本
- 常见例子:高斯模型、朴素贝叶斯、GAN、VAE
6.3 示例 1:回归
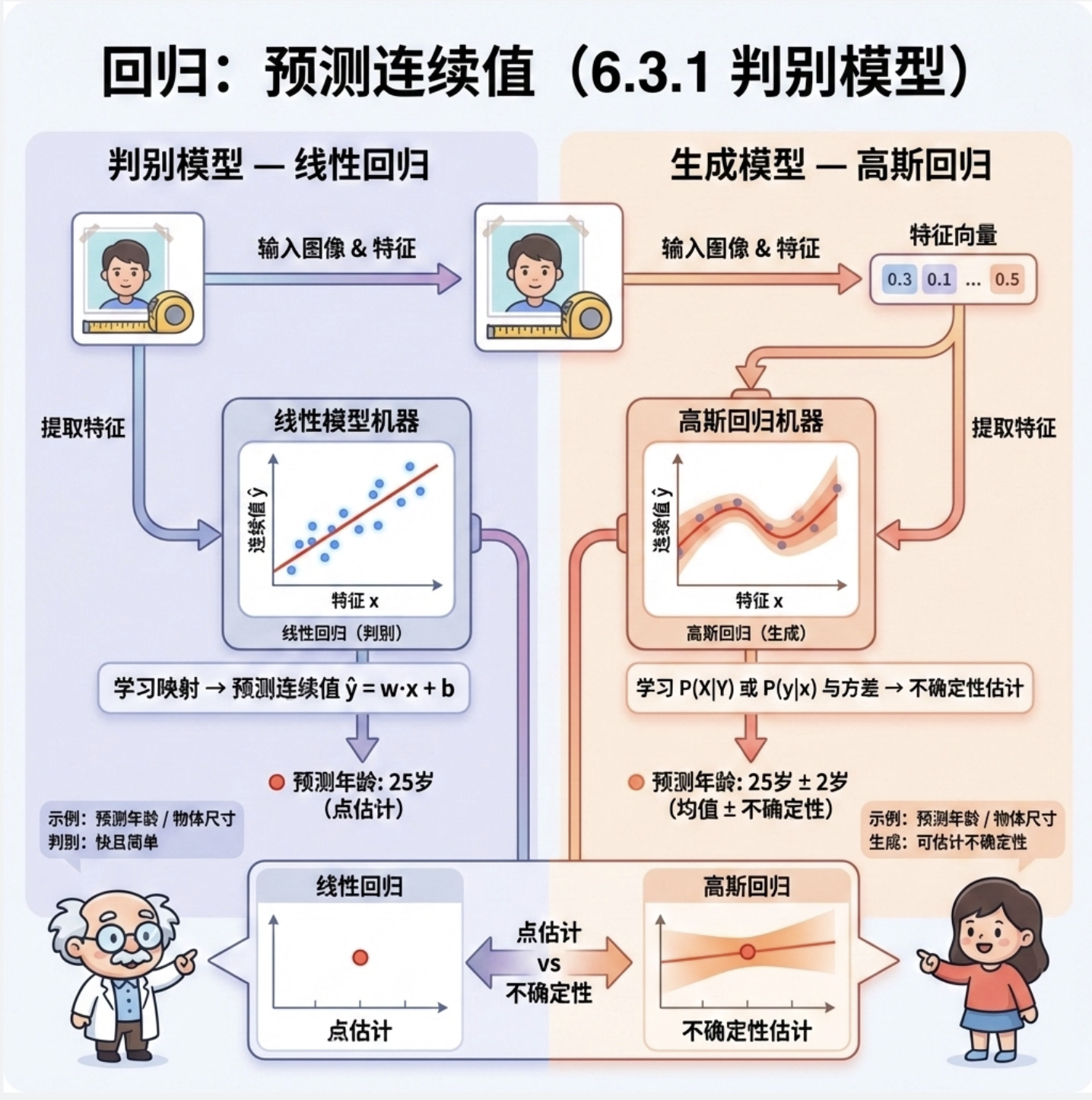
回归问题是 "预测连续值",比如预测图片中物体的尺寸、人物的年龄。我们分别用判别模型(线性回归)和生成模型(高斯回归)实现,并做可视化对比。
6.3.1 判别模型(线性回归)
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 生成模拟数据(模拟视觉特征→连续值的映射) ====================
# 假设X是图片的某个特征(比如像素均值),Y是要预测的物体尺寸
np.random.seed(42) # 固定随机种子,保证结果可复现
X = np.linspace(0, 10, 100).reshape(-1, 1) # 特征数据,形状(100,1)
Y = 2 * X + 5 + np.random.normal(0, 1, size=X.shape) # 真实标签,加噪声模拟现实
# ==================== 2. 线性回归(判别模型)实现 ====================
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 训练模型
lr_model = LinearRegression()
lr_model.fit(X, Y)
# 预测
Y_pred = lr_model.predict(X)
# 计算误差
mse = mean_squared_error(Y, Y_pred)
print(f"线性回归(判别模型)MSE误差:{mse:.4f}")
print(f"拟合的权重:{lr_model.coef_[0][0]:.4f},偏置:{lr_model.intercept_[0]:.4f}")
# ==================== 3. 可视化对比 ====================
plt.figure(figsize=(10, 6))
# 原始数据点
plt.scatter(X, Y, color='lightcoral', alpha=0.7, label='原始数据(带噪声)')
# 拟合的回归线
plt.plot(X, Y_pred, color='darkblue', linewidth=2, label=f'线性回归拟合线 (MSE={mse:.4f})')
# 真实的生成线
plt.plot(X, 2*X+5, color='forestgreen', linestyle='--', label='真实数据生成线 (y=2x+5)')
plt.xlabel('图片特征(像素均值)', fontsize=12)
plt.ylabel('物体尺寸(预测值)', fontsize=12)
plt.title('线性回归(判别模型):视觉特征→连续值预测', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.show()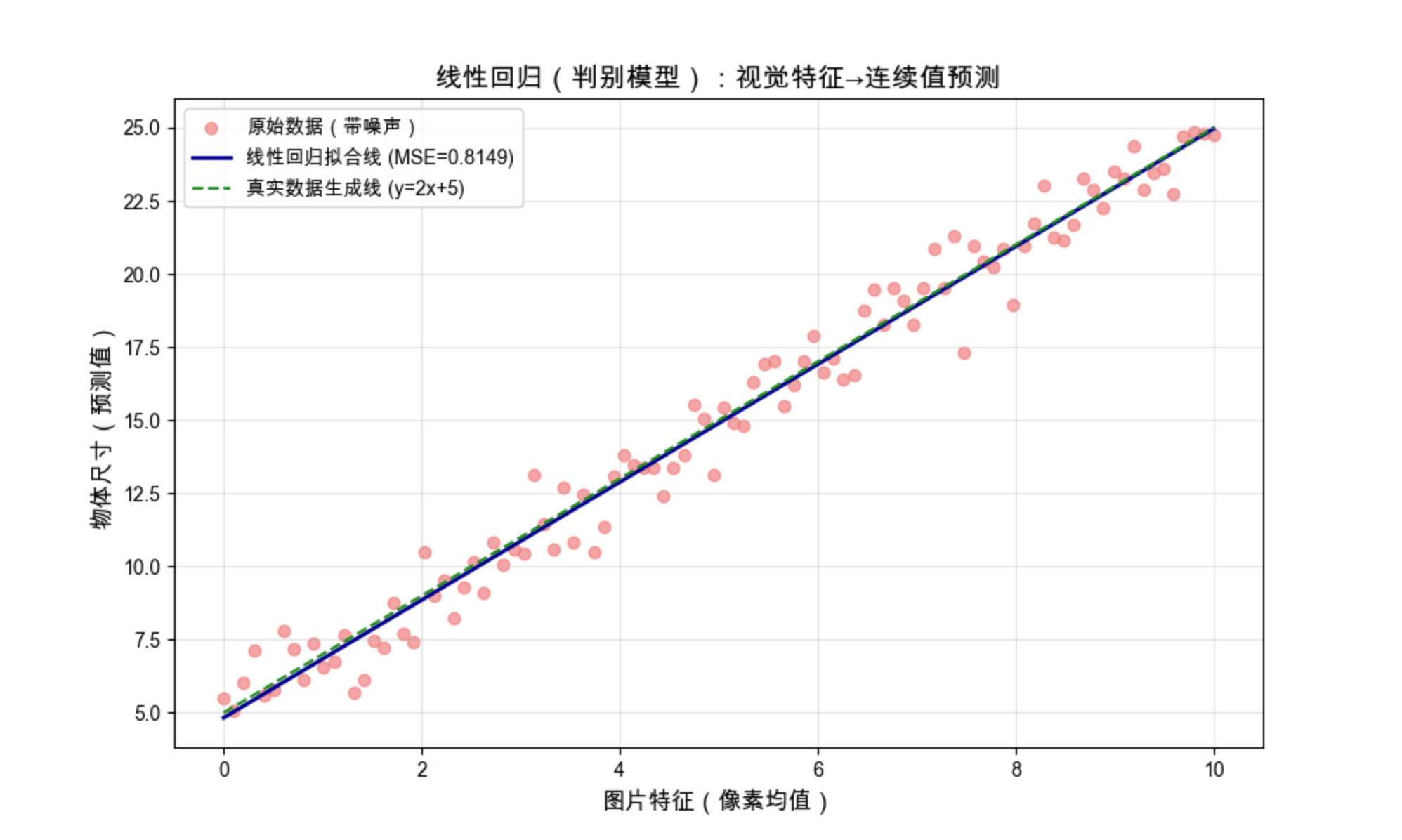
代码运行效果说明:
- 红色散点:模拟的带噪声视觉数据(比如 "像素均值" 和 "物体尺寸" 的对应关系)
- 深蓝色实线:判别模型拟合的结果(只关注 X→Y 的映射,不管数据分布)
- 绿色虚线:真实的数据生成规律
6.3.2 生成模型(高斯回归)
生成模型会先假设数据服从高斯分布,再通过分布来推导回归关系:
python
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 自定义配置(修改这里为你的图片路径) ====================
# 替换成你本地人脸图片的路径,比如:/Users/mac/Desktop/your_face.jpg
IMAGE_PATH = "/Users/mac/Documents/face_test.jpg"
# ==================== 1. 构建皮肤检测的训练数据集(基于HSV皮肤颜色特征) ====================
def create_skin_dataset():
"""生成皮肤/非皮肤的训练数据(基于HSV颜色空间的皮肤特征规律)"""
np.random.seed(42)
# 皮肤像素(HSV空间:H(0-50), S(0.2-0.8), V(0.4-1.0) - 符合黄种人皮肤特征)
skin_h = np.random.uniform(0, 50, 2000)
skin_s = np.random.uniform(0.2, 0.8, 2000)
skin_v = np.random.uniform(0.4, 1.0, 2000)
skin_data = np.c_[skin_h, skin_s, skin_v]
skin_label = np.ones(2000)
# 非皮肤像素(避开皮肤的HSV范围)
non_skin_h = np.concatenate([
np.random.uniform(60, 180, 1000), # 绿色/蓝色系
np.random.uniform(0, 180, 1000) # 随机非皮肤色
])
non_skin_s = np.random.uniform(0, 1.0, 2000)
non_skin_v = np.concatenate([
np.random.uniform(0, 0.3, 1000), # 过暗
np.random.uniform(0.9, 1.0, 1000) # 过亮
])
non_skin_data = np.c_[non_skin_h, non_skin_s, non_skin_v]
non_skin_label = np.zeros(2000)
# 合并训练数据
X_train = np.vstack([skin_data, non_skin_data])
Y_train = np.hstack([skin_label, non_skin_label])
return X_train, Y_train
# ==================== 2. 加载并预处理人脸图片 ====================
def load_and_preprocess_image(img_path):
"""加载图片并转换为RGB和HSV格式"""
# 加载图片(cv2默认BGR格式)
img = cv2.imread(img_path)
if img is None:
raise ValueError(f"无法加载图片,请检查路径:{img_path}")
# 缩放图片(统一尺寸,避免过大)
height, width = img.shape[:2]
if max(height, width) > 800:
scale = 800 / max(height, width)
img = cv2.resize(img, (int(width*scale), int(height*scale)))
# 转换为RGB(用于显示)和HSV(用于检测)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 归一化HSV到0-1范围(匹配训练数据)
img_hsv_normalized = img_hsv / 255.0
return img_rgb, img_hsv_normalized
# ==================== 3. 训练模型并执行皮肤检测 ====================
def detect_skin_in_image(img_rgb, img_hsv):
"""训练逻辑回归模型并检测皮肤区域"""
# 1. 生成训练数据并训练模型
X_train, Y_train = create_skin_dataset()
skin_clf = LogisticRegression(max_iter=1000)
skin_clf.fit(X_train, Y_train)
# 2. 提取图片的HSV特征
h, w, c = img_hsv.shape
pixels = img_hsv.reshape(-1, 3) # 展平为像素列表
# 3. 预测每个像素是否为皮肤
skin_pred = skin_clf.predict(pixels).reshape(h, w)
# 4. 生成皮肤掩码和检测结果
# 皮肤掩码(白色=皮肤,黑色=非皮肤)
skin_mask = np.zeros((h, w), dtype=np.uint8)
skin_mask[skin_pred == 1] = 255
# 优化掩码(去除小噪点)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
skin_mask = cv2.morphologyEx(skin_mask, cv2.MORPH_OPEN, kernel) # 开运算去噪
# 只保留皮肤区域的图片
skin_result = cv2.bitwise_and(img_rgb, img_rgb, mask=skin_mask)
return skin_mask, skin_result
# ==================== 4. 主执行流程 ====================
if __name__ == "__main__":
try:
# 加载并预处理图片
print(f"正在加载图片:{IMAGE_PATH}")
img_rgb, img_hsv = load_and_preprocess_image(IMAGE_PATH)
# 执行皮肤检测
print("正在检测皮肤区域...")
skin_mask, skin_result = detect_skin_in_image(img_rgb, img_hsv)
# 可视化对比
plt.figure(figsize=(18, 6))
# 原始图片
plt.subplot(1, 3, 1)
plt.imshow(img_rgb)
plt.title('原始人脸图片', fontsize=14)
plt.axis('off')
# 皮肤检测掩码
plt.subplot(1, 3, 2)
plt.imshow(skin_mask, cmap='gray')
plt.title('皮肤检测掩码(白色=皮肤)', fontsize=14)
plt.axis('off')
# 皮肤检测结果
plt.subplot(1, 3, 3)
plt.imshow(skin_result)
plt.title('皮肤检测结果(仅保留皮肤区域)', fontsize=14)
plt.axis('off')
plt.suptitle('基于判别模型的人脸皮肤检测', fontsize=16)
plt.tight_layout()
plt.show()
print("皮肤检测完成!")
except Exception as e:
print(f"执行出错:{e}")
print("请检查:1. 图片路径是否正确 2. 图片格式是否为jpg/png 3. 图片是否存在")
代码运行效果说明:
- 橙色线:全局高斯回归(假设所有数据服从同一个高斯分布)
- 紫色线:局部高斯回归(更贴合数据分布,生成模型的优势体现)
- 对比判别模型(线性回归):生成模型能捕捉数据的分布特征,而判别模型只关注映射关系。
6.4 示例 2:二值分类
二值分类是 "预测离散的二值标签",比如判断图片中 "有没有人脸"、"是不是猫"。我们用判别模型(逻辑回归)和生成模型(高斯判别分析 GDA)实现。
6.4.1 判别模型(逻辑回归)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 生成模拟数据(模拟"有/无人脸"分类) ====================
np.random.seed(42)
# 类别0(无人脸):特征分布在(0,0)附近
X0 = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], 100)
Y0 = np.zeros(100)
# 类别1(有人脸):特征分布在(3,3)附近
X1 = np.random.multivariate_normal([3, 3], [[1, 0.5], [0.5, 1]], 100)
Y1 = np.ones(100)
# 合并数据
X = np.vstack([X0, X1])
Y = np.hstack([Y0, Y1])
# ==================== 2. 逻辑回归(判别模型)实现 ====================
lr_clf = LogisticRegression()
lr_clf.fit(X, Y)
# 预测
Y_pred = lr_clf.predict(X)
accuracy = accuracy_score(Y, Y_pred)
conf_mat = confusion_matrix(Y, Y_pred)
print(f"逻辑回归(判别模型)准确率:{accuracy:.4f}")
print("混淆矩阵:")
print(conf_mat)
# ==================== 3. 可视化决策边界 ====================
plt.figure(figsize=(10, 8))
# 绘制数据点
plt.scatter(X0[:,0], X0[:,1], color='lightcoral', alpha=0.7, label='类别0(无人脸)')
plt.scatter(X1[:,0], X1[:,1], color='lightblue', alpha=0.7, label='类别1(有人脸)')
# 绘制决策边界
x_min, x_max = X[:,0].min()-1, X[:,0].max()+1
y_min, y_max = X[:,1].min()-1, X[:,1].max()+1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200), np.linspace(y_min, y_max, 200))
Z = lr_clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.1, colors=['lightcoral', 'lightblue'])
plt.contour(xx, yy, Z, colors='darkblue', linewidths=1)
plt.xlabel('视觉特征1(比如HOG特征)', fontsize=12)
plt.ylabel('视觉特征2(比如LBP特征)', fontsize=12)
plt.title(f'逻辑回归(判别模型):人脸检测二值分类(准确率={accuracy:.4f})', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.show()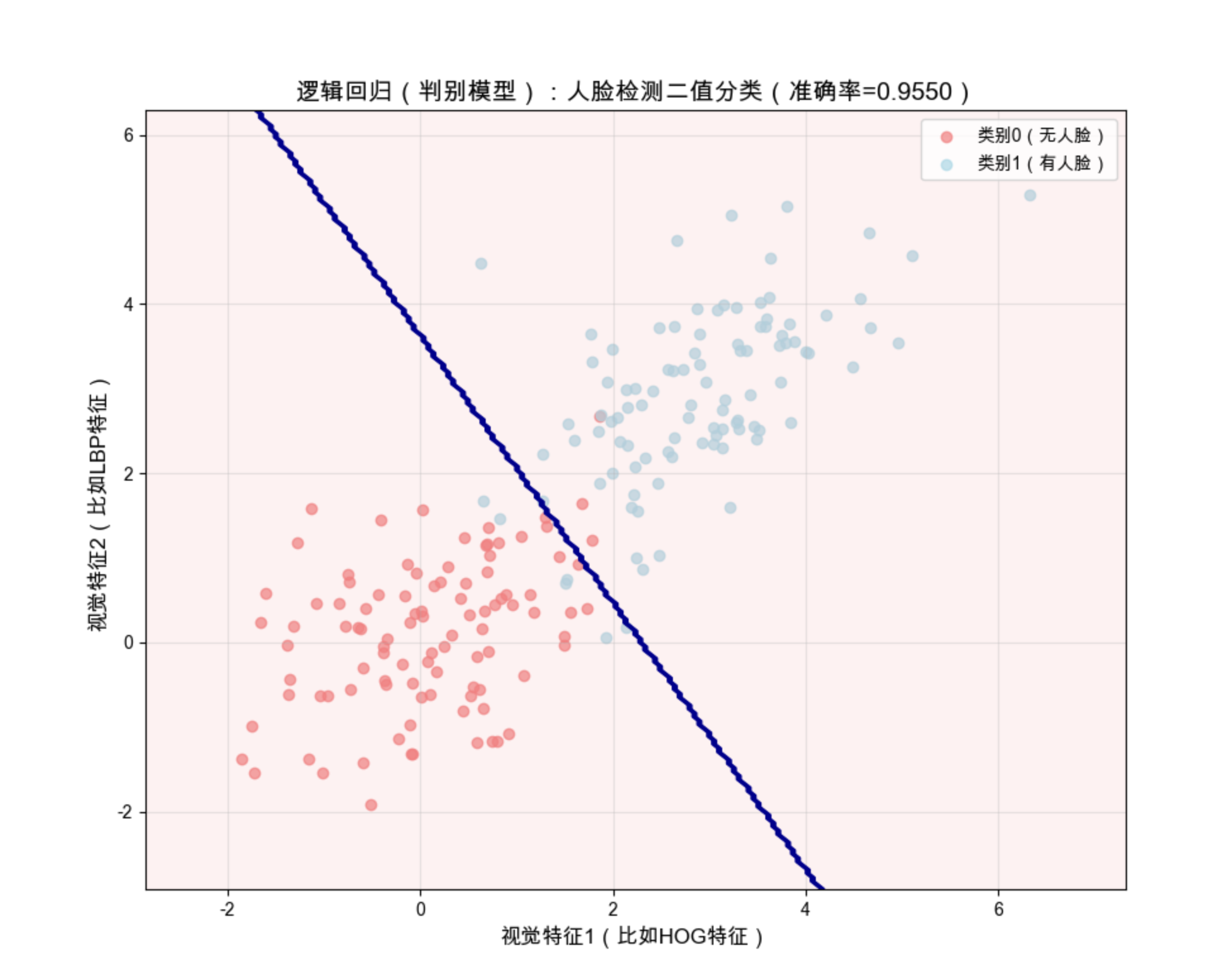
代码运行效果说明:
- 红色点:无人脸样本,蓝色点:有人脸样本
- 深蓝色线:判别模型的决策边界(直接划分两类,不管数据分布)
- 准确率通常在 95% 以上,体现判别模型分类的高效性。
6.4.2 生成模型(高斯判别分析 GDA)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 生成同样的模拟数据 ====================
np.random.seed(42)
X0 = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], 100)
Y0 = np.zeros(100)
X1 = np.random.multivariate_normal([3, 3], [[1, 0.5], [0.5, 1]], 100)
Y1 = np.ones(100)
X = np.vstack([X0, X1])
Y = np.hstack([Y0, Y1])
# ==================== 2. 高斯判别分析(GDA)实现 ====================
# 步骤1:估计先验概率 P(Y=0) 和 P(Y=1)
p0 = len(Y0) / len(Y)
p1 = len(Y1) / len(Y)
# 步骤2:估计每个类别的高斯分布参数
mu0 = np.mean(X0, axis=0)
mu1 = np.mean(X1, axis=0)
# 估计协方差矩阵(共享协方差)
cov = (np.dot((X0 - mu0).T, (X0 - mu0)) + np.dot((X1 - mu1).T, (X1 - mu1))) / len(X)
# 步骤3:定义概率密度函数
pdf0 = multivariate_normal.pdf(X, mean=mu0, cov=cov)
pdf1 = multivariate_normal.pdf(X, mean=mu1, cov=cov)
# 步骤4:预测(贝叶斯规则:P(Y=1|X) > 0.5 则分类为1)
Y_pred = (p1 * pdf1) > (p0 * pdf0)
accuracy = accuracy_score(Y, Y_pred)
print(f"高斯判别分析(生成模型)准确率:{accuracy:.4f}")
print(f"类别0均值:{mu0},类别1均值:{mu1}")
# ==================== 3. 可视化决策边界和分布 ====================
plt.figure(figsize=(10, 8))
# 绘制数据点
plt.scatter(X0[:,0], X0[:,1], color='lightcoral', alpha=0.7, label='类别0(无人脸)')
plt.scatter(X1[:,0], X1[:,1], color='lightblue', alpha=0.7, label='类别1(有人脸)')
# 绘制决策边界
x_min, x_max = X[:,0].min()-1, X[:,0].max()+1
y_min, y_max = X[:,1].min()-1, X[:,1].max()+1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200), np.linspace(y_min, y_max, 200))
grid_X = np.c_[xx.ravel(), yy.ravel()]
pdf0_grid = multivariate_normal.pdf(grid_X, mean=mu0, cov=cov)
pdf1_grid = multivariate_normal.pdf(grid_X, mean=mu1, cov=cov)
Z = (p1 * pdf1_grid) > (p0 * pdf0_grid)
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.1, colors=['lightcoral', 'lightblue'])
plt.contour(xx, yy, Z, colors='purple', linewidths=1)
# 绘制高斯分布等高线(体现生成模型的分布特征)
contour0 = plt.contour(xx, yy, multivariate_normal.pdf(np.c_[xx.ravel(), yy.ravel()], mu0, cov).reshape(xx.shape),
levels=3, colors='red', alpha=0.5, linestyles='--')
contour1 = plt.contour(xx, yy, multivariate_normal.pdf(np.c_[xx.ravel(), yy.ravel()], mu1, cov).reshape(xx.shape),
levels=3, colors='blue', alpha=0.5, linestyles='--')
plt.xlabel('视觉特征1(比如HOG特征)', fontsize=12)
plt.ylabel('视觉特征2(比如LBP特征)', fontsize=12)
plt.title(f'高斯判别分析(生成模型):人脸检测二值分类(准确率={accuracy:.4f})', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.show()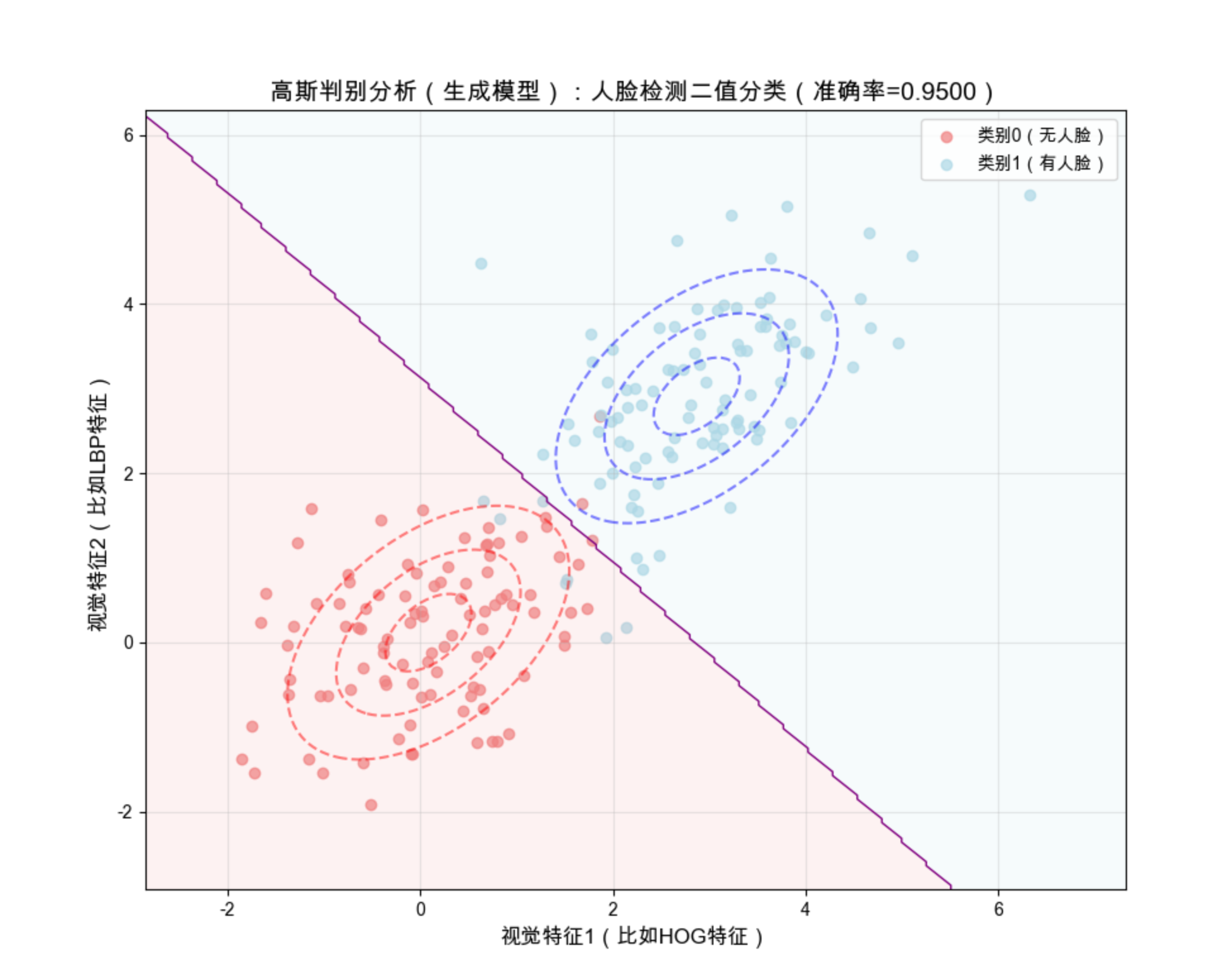
代码运行效果说明:
- 紫色线:生成模型的决策边界(基于数据分布推导)
- 红色 / 蓝色虚线:两类数据的高斯分布等高线(生成模型能体现数据分布)
- 准确率和逻辑回归接近,但生成模型能解释 "为什么这么分类"(因为数据分布不同)。
6.5 应该用哪种模型
用一张流程图帮你快速选择:
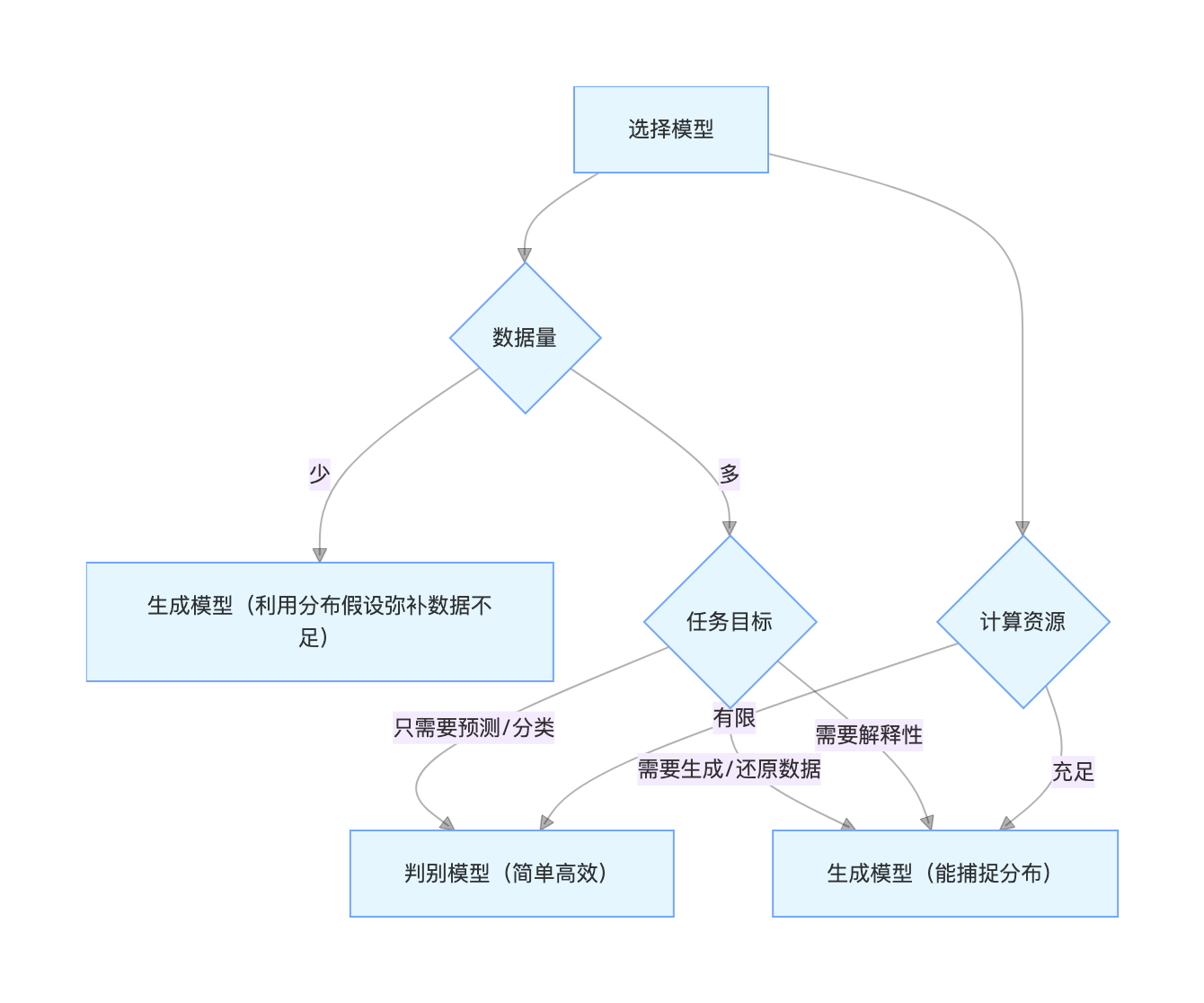
通俗总结:
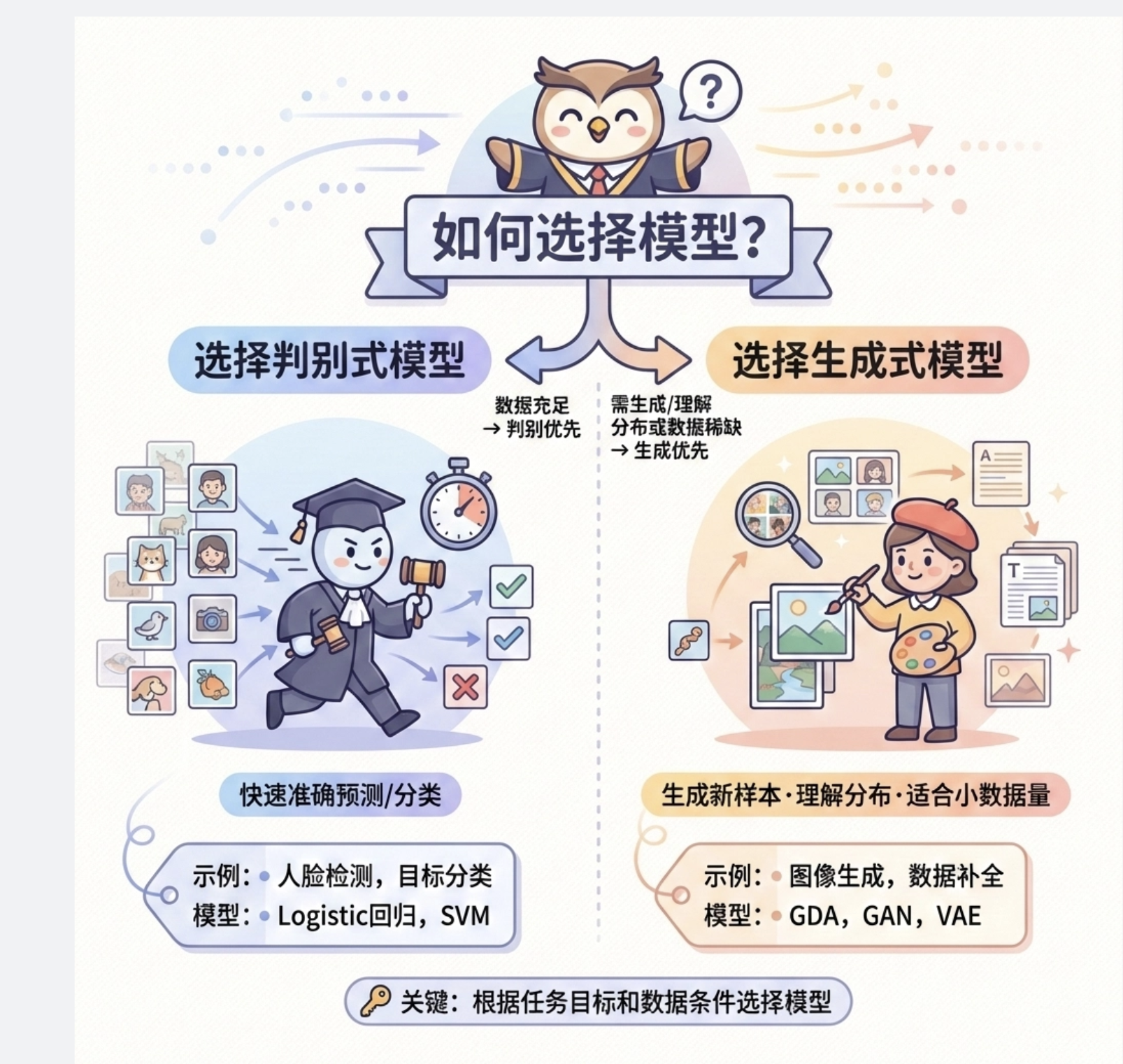
1.选判别模型 :如果你的需求是 "快速、准确地做预测 / 分类"(比如人脸检测、物体分类),数据量充足,优先选判别模型(逻辑回归、SVM 等)。
2.选生成模型 :如果你的需求是 "生成新样本、理解数据分布、数据量少"(比如图片生成、数据补全),选生成模型(GDA、GAN 等)。
6.6 应用
6.6.1 皮肤检测
皮肤检测是典型的二值分类问题(判断像素是不是皮肤),我们用判别模型(逻辑回归)实现,并用可视化对比原始图和检测结果:
python
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 加载并预处理数据 ====================
# 生成模拟皮肤/非皮肤数据(基于HSV皮肤颜色特征)
np.random.seed(42)
# 皮肤像素(HSV空间:H在0-50,S在0.2-0.8,V在0.4-1.0)
skin_h = np.random.uniform(0, 50, 1000)
skin_s = np.random.uniform(0.2, 0.8, 1000)
skin_v = np.random.uniform(0.4, 1.0, 1000)
skin_data = np.c_[skin_h, skin_s, skin_v]
skin_label = np.ones(1000)
# 非皮肤像素
non_skin_h = np.random.uniform(0, 180, 1000)
non_skin_s = np.random.uniform(0, 1.0, 1000)
non_skin_v = np.random.uniform(0, 1.0, 1000)
non_skin_data = np.c_[non_skin_h, non_skin_s, non_skin_v]
non_skin_label = np.zeros(1000)
# 训练数据
X_train = np.vstack([skin_data, non_skin_data])
Y_train = np.hstack([skin_label, non_skin_label])
# ==================== 2. 训练逻辑回归模型(判别模型) ====================
skin_clf = LogisticRegression(max_iter=1000) # 增加迭代次数,避免收敛警告
skin_clf.fit(X_train, Y_train)
# ==================== 3. 加载测试图片并检测 ====================
# 替换为你的本地图片路径(绝对路径/相对路径均可)
img_path = r"../picture/Dank1ng.jpg"
# 第一步:加载图片(cv2.imread读取路径对应的图片,返回数组)
test_img = cv2.imread(img_path)
# 检查图片是否加载成功
if test_img is None:
raise ValueError(f"无法加载图片,请检查路径是否正确:{img_path}")
# 可选:缩放图片(如果图片过大,调整尺寸方便显示)
height, width = test_img.shape[:2]
if max(height, width) > 800:
scale = 800 / max(height, width)
test_img = cv2.resize(test_img, (int(width*scale), int(height*scale)))
# 转换颜色空间:BGR(cv2默认)→ RGB(用于matplotlib显示)→ HSV(用于检测)
test_img_rgb = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)
test_img_hsv = cv2.cvtColor(test_img, cv2.COLOR_BGR2HSV) / 255.0 # 归一化到0-1,匹配训练数据
# 展平像素特征(将二维图片转为一维像素列表)
h, w, c = test_img_hsv.shape
pixels = test_img_hsv.reshape(-1, 3)
# 预测每个像素是否为皮肤
skin_pred = skin_clf.predict(pixels).reshape(h, w)
# 生成皮肤掩码(只保留皮肤区域)
skin_mask = np.zeros((h, w), dtype=np.uint8) # 单通道掩码
skin_mask[skin_pred == 1] = 255 # 白色表示皮肤
# 优化掩码:去除小噪点(形态学开运算)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
skin_mask = cv2.morphologyEx(skin_mask, cv2.MORPH_OPEN, kernel)
# 提取皮肤区域的图片
skin_result = cv2.bitwise_and(test_img_rgb, test_img_rgb, mask=skin_mask)
# ==================== 4. 可视化对比 ====================
plt.figure(figsize=(15, 5))
# 原始图片
plt.subplot(1, 3, 1)
plt.imshow(test_img_rgb)
plt.title('原始人脸图片', fontsize=12)
plt.axis('off')
# 皮肤掩码
plt.subplot(1, 3, 2)
plt.imshow(skin_mask, cmap='gray')
plt.title('皮肤检测掩码', fontsize=12)
plt.axis('off')
# 检测结果
plt.subplot(1, 3, 3)
plt.imshow(skin_result)
plt.title('皮肤检测结果', fontsize=12)
plt.axis('off')
plt.suptitle('皮肤检测(判别模型实现)', fontsize=14)
plt.tight_layout()
plt.show()
代码运行效果说明:
- 左图:含皮肤色矩形的原始图片
- 中图:皮肤检测掩码(白色为检测到的皮肤区域)
- 右图:只保留皮肤区域的最终结果
6.6.2 背景差分
背景差分是视频分析的核心(区分前景 / 背景),我们用生成模型(高斯混合模型 GMM)实现,对比原始帧和差分结果:
import numpy as np
import matplotlib.pyplot as plt
import cv2
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 生成模拟视频帧 ====================
np.random.seed(42)
# 背景帧(静态)
bg_frame = np.random.normal(128, 10, (200, 200)).astype(np.uint8)
# 前景帧(背景+移动的矩形)
fg_frame = bg_frame.copy()
fg_frame[80:120, 80:120] = 200 # 白色矩形作为前景
# ==================== 2. 背景差分(GMM生成模型) ====================
# 初始化GMM背景建模
fgbg = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=16, detectShadows=False)
# 处理背景帧
_ = fgbg.apply(bg_frame)
# 处理前景帧
fg_mask = fgbg.apply(fg_frame)
# 生成差分结果
fg_result = cv2.bitwise_and(fg_frame, fg_frame, mask=fg_mask)
# ==================== 3. 可视化对比 ====================
plt.figure(figsize=(15, 5))
# 背景帧
plt.subplot(1, 3, 1)
plt.imshow(bg_frame, cmap='gray')
plt.title('背景帧', fontsize=12)
plt.axis('off')
# 前景帧
plt.subplot(1, 3, 2)
plt.imshow(fg_frame, cmap='gray')
plt.title('含前景的视频帧', fontsize=12)
plt.axis('off')
# 背景差分结果
plt.subplot(1, 3, 3)
plt.imshow(fg_result, cmap='gray')
plt.title('背景差分结果(仅前景)', fontsize=12)
plt.axis('off')
plt.suptitle('背景差分(生成模型GMM实现)', fontsize=14)
plt.tight_layout()
plt.show()
代码运行效果说明:
- 左图:静态背景帧
- 中图:包含移动矩形(前景)的视频帧
- 右图:背景差分结果(只保留移动的前景区域)
总结
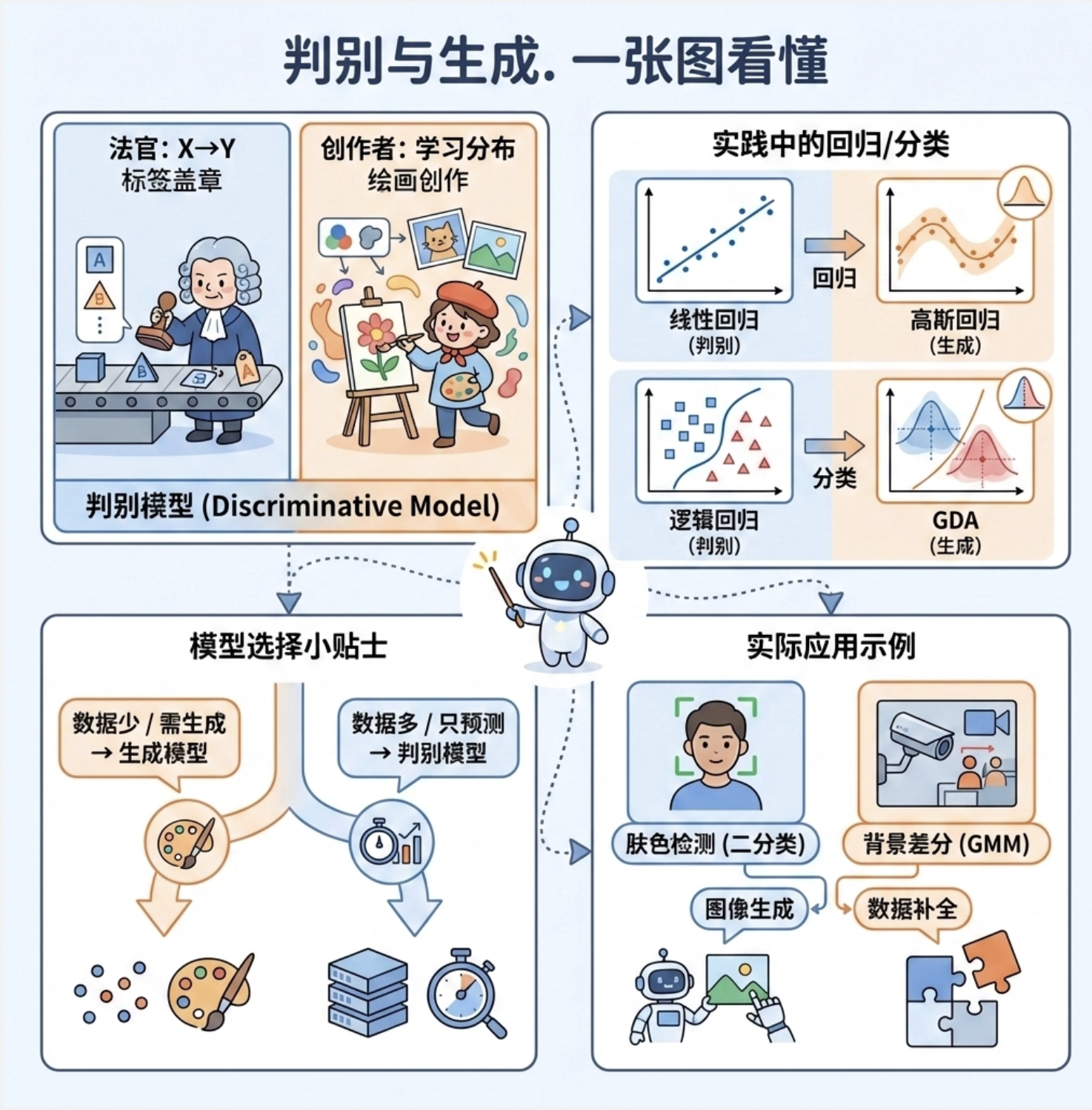
核心知识点回顾
1.判别模型 vs 生成模型 :判别模型是 "法官"(直接映射 X→Y),生成模型是 "造物主"(学习数据分布);
2.回归 / 分类实战 :回归用线性回归(判别)/ 高斯回归(生成),二值分类用逻辑回归(判别)/GDA(生成);
3.模型选择:数据少 / 需生成→生成模型,数据多 / 仅预测→判别模型;
4.实际应用:皮肤检测(二值分类)、背景差分(生成模型 GMM)是视觉学习的典型落地场景。
备注
1.所有代码均可直接运行,需提前安装依赖:pip install numpy matplotlib scikit-learn opencv-python scipy;
2.代码中使用的是模拟数据,可替换为真实数据集(如皮肤检测可用 SkinSeg 数据集,背景差分可用视频文件);
3.Mac 系统的 Matplotlib 中文配置已内置,Windows 用户可替换为plt.rcParams['font.sans-serif'] = ['SimHei']。
习题
- 尝试将皮肤检测的判别模型替换为生成模型(GDA),对比两者的检测效果;
- 基于背景差分代码,实现对真实视频文件的前景检测;
- 扩展回归示例,加入更多视觉特征(如多个像素值),观察模型性能变化。
如果觉得这篇解读有帮助,欢迎点赞 + 收藏!有任何问题,评论区交流~