目录规划
为了将这所有博客里的知识点逻辑顺畅地串联起来,特此设计了以下目录结构。这个顺序遵循了"概念引入 -> 基础回归 -> 分类进阶 -> 无监督学习"的学习路径:
- 第一章:启蒙篇------人工智能与机器学习的宏观版图
- 来源博客:人工智能和机器学习
- 核心内容:AI、ML、DL的关系,机器学习的分类(监督/无监督/强化),基本工作流程。
- 第二章:基石篇------预测连续值的线性回归
- 来源博客:线性回归
- 核心内容:一元/多元线性回归,损失函数,梯度下降,代码实战。
- 第三章:进阶篇------解决分类问题的逻辑回归
- 来源博客:逻辑回归
- 核心内容:从回归到分类的跨越,Sigmoid函数,决策边界,代码实战。
- 第四章:直觉篇------基于距离的K-近邻 (KNN)
- 来源博客:KNN算法
- 核心内容:KNN原理,K值选择,距离计算,优缺点分析,代码实战。
- 第五章:探索篇------发现数据内在结构的聚类算法
- 来源博客:聚类算法
- 核心内容:K-Means原理,簇的概念,与分类的区别,应用场景。
- 第六章:总结与展望
- 综合对比五大算法,如何选择适合的模型。
文章目录
- 目录规划
- 第三章:进阶篇------解决分类问题的逻辑回归
-
- [3.1 为什么线性回归不能直接用于分类?](#3.1 为什么线性回归不能直接用于分类?)
- [3.2 核心引擎:Sigmoid 函数](#3.2 核心引擎:Sigmoid 函数)
-
- [1. 函数公式](#1. 函数公式)
- [2. 函数特性](#2. 函数特性)
- [3. 逻辑回归的最终假设](#3. 逻辑回归的最终假设)
- [3.3 损失函数:为什么不能用 MSE?](#3.3 损失函数:为什么不能用 MSE?)
- [3.4 决策边界 (Decision Boundary)](#3.4 决策边界 (Decision Boundary))
- [3.5 代码实战:手写数字识别(二分类)](#3.5 代码实战:手写数字识别(二分类))
- [3.6 逻辑回归 vs 线性回归:关键区别总结](#3.6 逻辑回归 vs 线性回归:关键区别总结)
- [3.7 优缺点分析](#3.7 优缺点分析)
-
- [✅ 优点](#✅ 优点)
- [❌ 缺点](#❌ 缺点)
- [3.8 本章小结](#3.8 本章小结)
第三章:进阶篇------解决分类问题的逻辑回归
导读:在上一章中,我们学会了用线性回归预测"房价是多少"这样的连续数值。但如果问题变成了"这封邮件是不是垃圾邮件?"或者"这个肿瘤是良性还是恶性?",线性回归就束手无策了。
本章基于文档《04_逻辑回归.pdf》,带你走进逻辑回归 (Logistic Regression)的世界。尽管名字里带有"回归",但它其实是机器学习中最经典、最常用的分类算法之一。我们将揭示它如何通过一个神奇的函数,将连续的预测值转化为离散的类别概率。
3.1 为什么线性回归不能直接用于分类?
假设我们要根据"肿瘤大小"预测"恶性肿瘤 (1)"还是"良性肿瘤 (0)"。
如果我们强行使用线性回归 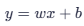 :
:
- 输出范围不可控 :线性回归的输出可以是任意实数
 。但分类问题我们需要的是 0 或 1 ,或者是 0 到 1 之间的概率 。如果模型预测出
。但分类问题我们需要的是 0 或 1 ,或者是 0 到 1 之间的概率 。如果模型预测出 ,这在分类任务中是没有意义的。
,这在分类任务中是没有意义的。 - 阈值敏感 :如果我们设定
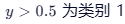 ,那么只要数据中增加一个极端的异常点,拟合的直线就会发生剧烈倾斜,导致原本分类正确的点被分错。
,那么只要数据中增加一个极端的异常点,拟合的直线就会发生剧烈倾斜,导致原本分类正确的点被分错。
我们需要什么?
我们需要一个函数,它能接收线性回归的输出 (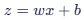 ),然后将其压缩 到 (0, 1) 区间内,代表属于某一类的概率。
),然后将其压缩 到 (0, 1) 区间内,代表属于某一类的概率。
3.2 核心引擎:Sigmoid 函数
逻辑回归的秘诀就在于引入了 Sigmoid 函数(也叫 Logistic 函数)。
1. 函数公式

2. 函数特性
- 形状:呈"S"形曲线。

3. 逻辑回归的最终假设

形象理解 :线性部分 ( w x + b wx+b wx+b) 负责打分,分数可正可负;Sigmoid 函数负责把分数"挤压"成概率,分数越高,概率越接近 100%。
3.3 损失函数:为什么不能用 MSE?
在线性回归中,我们使用均方误差 (MSE)。但在逻辑回归中,由于 Sigmoid 函数的非线性特性,如果使用 MSE,损失函数会变成非凸函数(有很多个局部最低点),梯度下降很容易陷入局部最优,找不到全局最佳解。
因此,逻辑回归使用 对数损失函数 (Log Loss) ,也称为 交叉熵损失 (Cross-Entropy Loss)。
公式

结论 :对数损失函数是一个凸函数,保证梯度下降能找到全局最优解。
3.4 决策边界 (Decision Boundary)
逻辑回归本质上还是线性的。
- 决策边界由
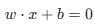 定义。
定义。 - 在二维平面上,这是一条直线。
- 在高维空间中,这是一个超平面。
- 这条线将空间划分为两部分:一边预测为 0,一边预测为 1。

3.5 代码实战:手写数字识别(二分类)
为了展示逻辑回归的威力,我们用 sklearn 来实现一个经典的二分类任务:识别手写数字是"0"还是"1"。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
# 1. 加载数据
# load_digits 包含 0-9 的手写图片,我们只取 0 和 1 来做二分类
digits = load_digits()
X = digits.data # 特征:每张图 64 个像素点
y = digits.target # 标签:0-9
# 过滤数据,只保留 0 和 1
mask = (y == 0) | (y == 1)
X = X[mask]
y = y[mask]
print(f"数据形状: {X.shape}, 标签分布: {np.bincount(y)}")
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 实例化并训练模型
# C 参数是正则化强度的倒数,默认即可
model = LogisticRegression()
model.fit(X_train, y_train)
# 4. 预测与评估
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test) # 获取概率值
print("\n--- 模型评估 ---")
print(f"准确率 (Accuracy): {model.score(X_test, y_test):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 5. 可视化:看看模型是怎么"看"数字的
# 我们可以画出权重 w,看看哪些像素对区分 0 和 1 最重要
weights = model.coef_[0]
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.imshow(weights.reshape(8, 8), cmap='coolwarm')
plt.title('模型学到的权重 (Weight Map)\n红色有助于判为1,蓝色有助于判为0')
plt.colorbar()
plt.subplot(1, 2, 2)
# 随机选一张测试图展示
idx = 0
plt.imshow(X_test[idx].reshape(8, 8), cmap='gray')
true_label = y_test[idx]
pred_prob = y_prob[idx][1] # 属于类别1的概率
plt.title(f'真实: {true_label}\n预测为1的概率: {pred_prob:.2f}')
plt.axis('off')
plt.tight_layout()
plt.show()代码深度解析:
- 数据准备:我们使用了 sklearn 自带的Digits数据集,并人工筛选了 0 和 1,构建了一个二分类问题。
predict_proba:这是逻辑回归的神器。它不仅告诉你结果是 0 还是 1,还告诉你置信度(概率)。比如输出 0.98,说明模型非常有把握;输出 0.51,说明模型很犹豫。- 权重可视化 :
- 逻辑回归的
coef_告诉我们每个像素点对结果的贡献。 - 在生成的热力图中,红色区域 表示如果这里有墨迹,模型倾向于认为是"1";蓝色区域表示如果有墨迹,倾向于认为是"0"。
- 你会发现,权重图往往长得很像"1"和"0"的差异部分(例如"0"的圆圈部分权重为负,"1"的竖线部分权重为正)。这再次证明了逻辑回归极强的可解释性。
- 逻辑回归的
3.6 逻辑回归 vs 线性回归:关键区别总结

3.7 优缺点分析
✅ 优点
- 计算代价低:训练和预测速度非常快,适合大规模数据。
- 可解释性强:可以通过权重系数清楚地看到每个特征对结果的影响方向和程度。
- 输出概率:不仅给出分类结果,还给出概率,方便后续根据业务需求调整阈值(例如在医疗诊断中,为了不漏诊,可以将阈值从 0.5 降到 0.3)。
- 不易过拟合:配合正则化(L1/L2),效果很稳健。
❌ 缺点
- 特征与目标需线性相关:本质还是线性分类器,处理复杂的非线性关系能力较弱(除非手动做特征组合)。
- 特征数量巨大时表现一般:相比 SVM 或神经网络,在超高维特征空间下可能不是最优解。
- 对多重共线性敏感:如果特征之间高度相关,权重估计会不稳定。
3.8 本章小结
- 逻辑回归 虽然名字带"回归",实则是分类算法之王。
- 它通过 Sigmoid 函数 将线性输出映射为概率。
- 它使用 对数损失函数 来优化模型,确保找到全局最优。
- 它的最大优势在于简单、快速且可解释,是工业界(如广告点击率预估、风控评分卡)应用最广泛的模型之一。
掌握了线性回归和逻辑回归,我们就解决了机器学习中两大基础任务:预测数值 和二分类。但是,如果我们的邻居不只两个,或者有十个类别怎么办?如果数据没有标签,我们该怎么分组?
接下来,我们将学习一种基于"直觉"和"距离"的算法------K-近邻 (KNN),看看它如何处理多分类问题,以及它与前面两种基于"公式"的算法有何不同。
下一章预告:《第四章:直觉篇------基于距离的 K-近邻 (KNN) 算法》,我们将抛弃复杂的公式推导,用最朴素的"近朱者赤"思想来解决分类难题。