博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Python为开发语言,采用Spark大数据框架进行分布式处理,结合Hadoop实现HDFS分布式存储,通过Hive构建数据仓库进行结构化数据管理,使用selenium爬虫技术采集锦江酒店网站数据。后端采用Django框架,前端使用Vue框架配合Echarts可视化库,推荐模块基于协同过滤算法实现个性化推荐。
功能模块
· 数据采集模块
· 数据清洗与预处理模块
· 用户注册登录模块
· 可视化大屏展示模块
· 酒店信息查询模块
· 数据分析模块
· 个性化推荐模块
· 后台管理模块
项目介绍
本系统是一个基于Spark大数据框架的酒店数据分析与推荐平台,以北京地区酒店为核心分析对象,旨在为用户提供个性化推荐服务,同时为酒店运营者提供数据化决策支持。系统通过selenium爬虫技术从锦江酒店网站采集酒店数据,经HDFS存储后由Hive构建数据仓库实现结构化整理,再通过Spark完成数据清洗与特征提取。系统采用协同过滤推荐算法,基于用户历史行为生成个性化酒店推荐列表,并通过Echarts可视化技术将分析结果以可视化大屏、柱状图、饼图、热力地图、词云图等多种形式直观呈现。用户可通过注册登录进入系统,浏览酒店价格分布、评分情况、省市分布、类型占比等多维度分析结果,管理员可通过后台管理模块对用户信息进行维护。系统目前已实现数据采集、分布式处理、可视化展示与智能推荐等核心功能,为用户提供清晰的酒店选择依据,为运营者输出精准的市场分析报告。
2、项目界面
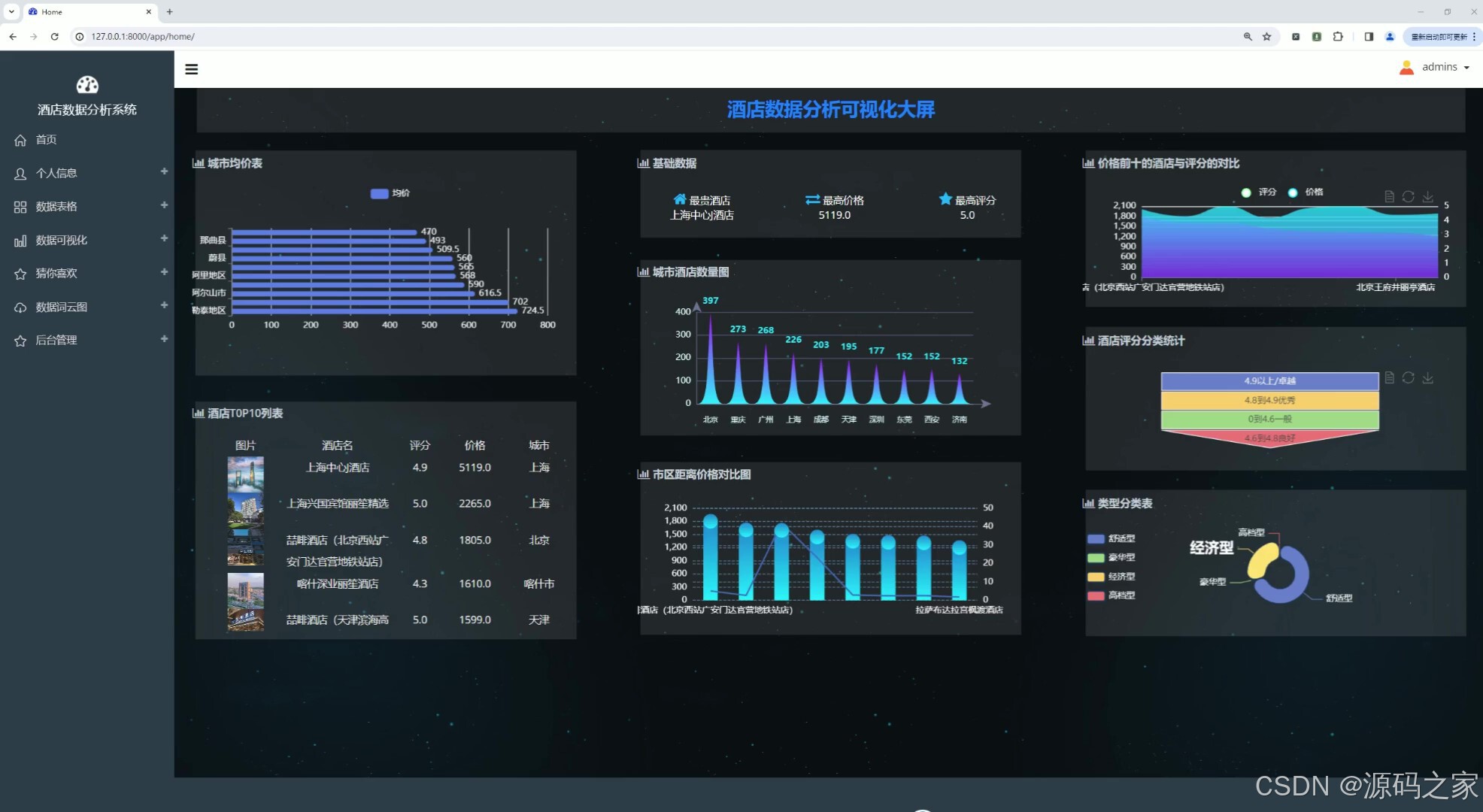
(1)酒店数据可视化分析大屏
该页面为酒店数据分析可视化大屏,集成城市均价柱状图、基础数据卡片、酒店数量柱状图、距离价格对比图、评分对比面积图、评分分类统计表及类型分类饼图,从价格、评分、数量、距离等维度直观呈现酒店数据特征与分布结构。
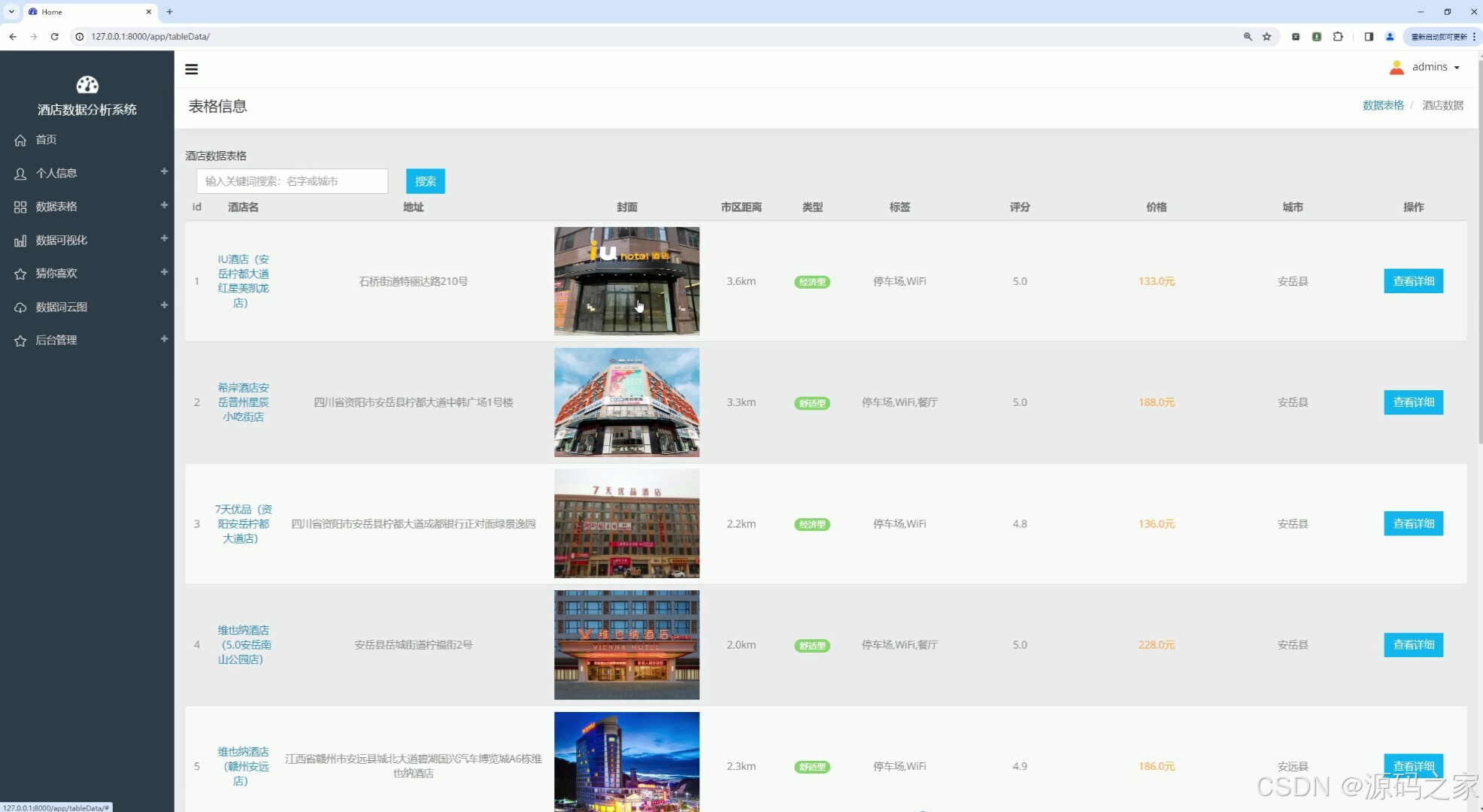
(2)酒店信息数据
该页面为酒店数据分析系统的数据表格界面,提供关键词搜索功能,以表格形式展示酒店名称、地址、封面、市区距离、类型、标签、评分、价格、城市等信息,支持查看酒店详细内容,可便捷查询与浏览酒店基础数据。
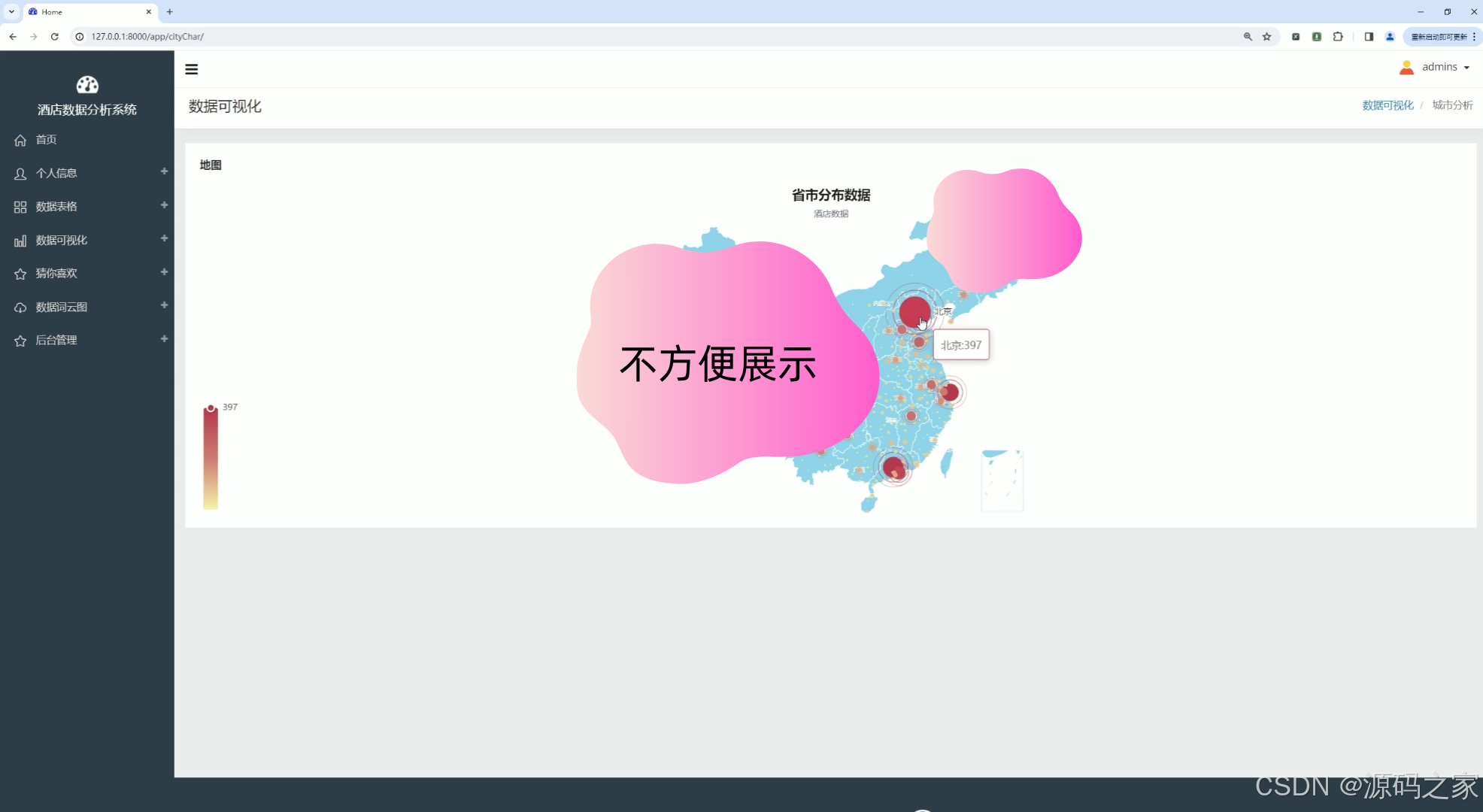
(3)酒店数据省市分布
该页面为酒店数据分析系统的数据可视化界面,以热力地图结合气泡标记的形式展示酒店数据的省市分布情况,可直观呈现不同区域酒店数量的分布差异与聚集特征,辅助分析酒店市场的区域布局。
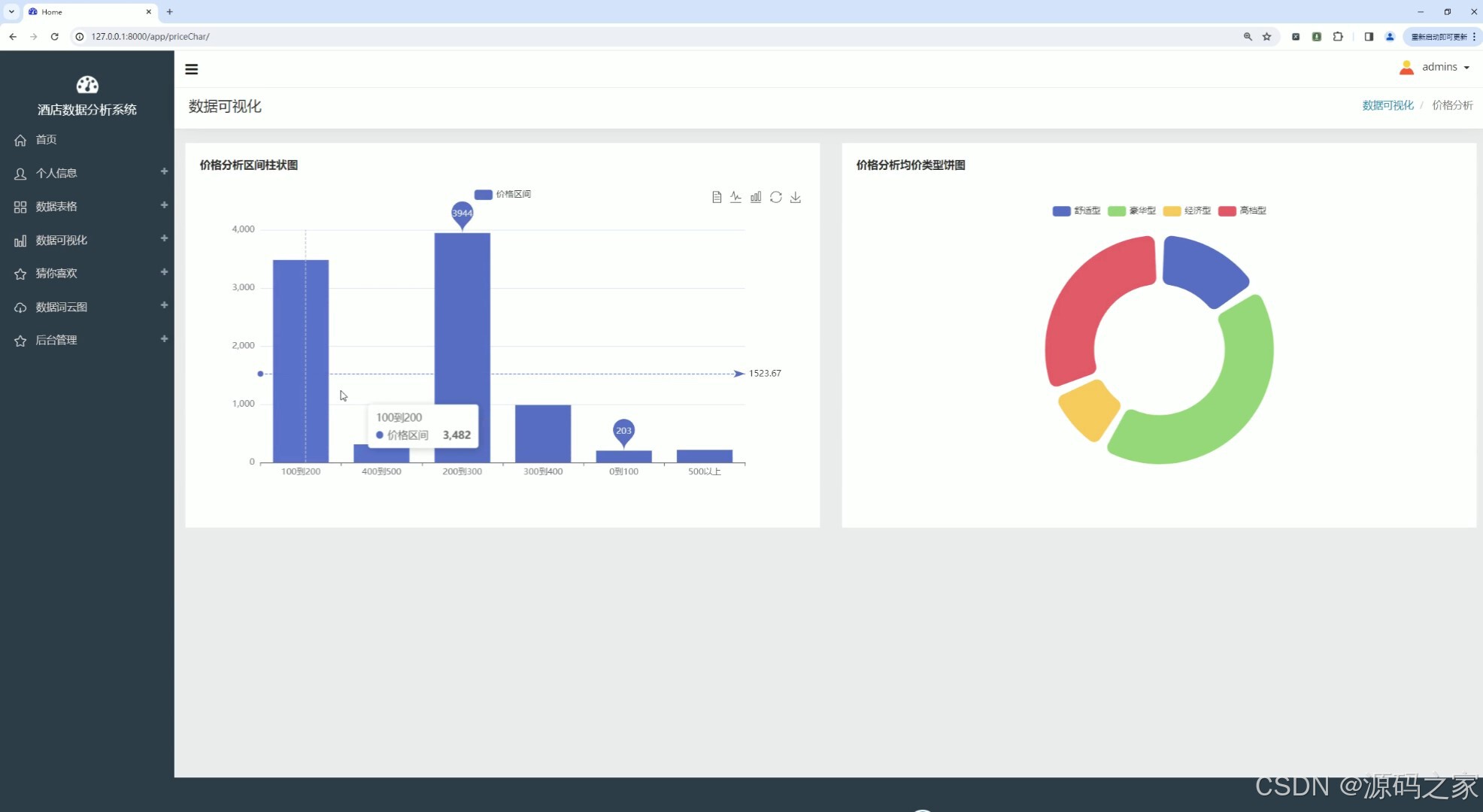
(4)酒店价格区间柱状图分析和酒店类型饼图分析
该页面为酒店数据分析系统的价格分析可视化界面,以柱状图展示不同价格区间的酒店数量分布,以环形图呈现不同类型酒店的均价占比,可从价格区间与酒店类型维度直观分析酒店价格结构与分布特征。
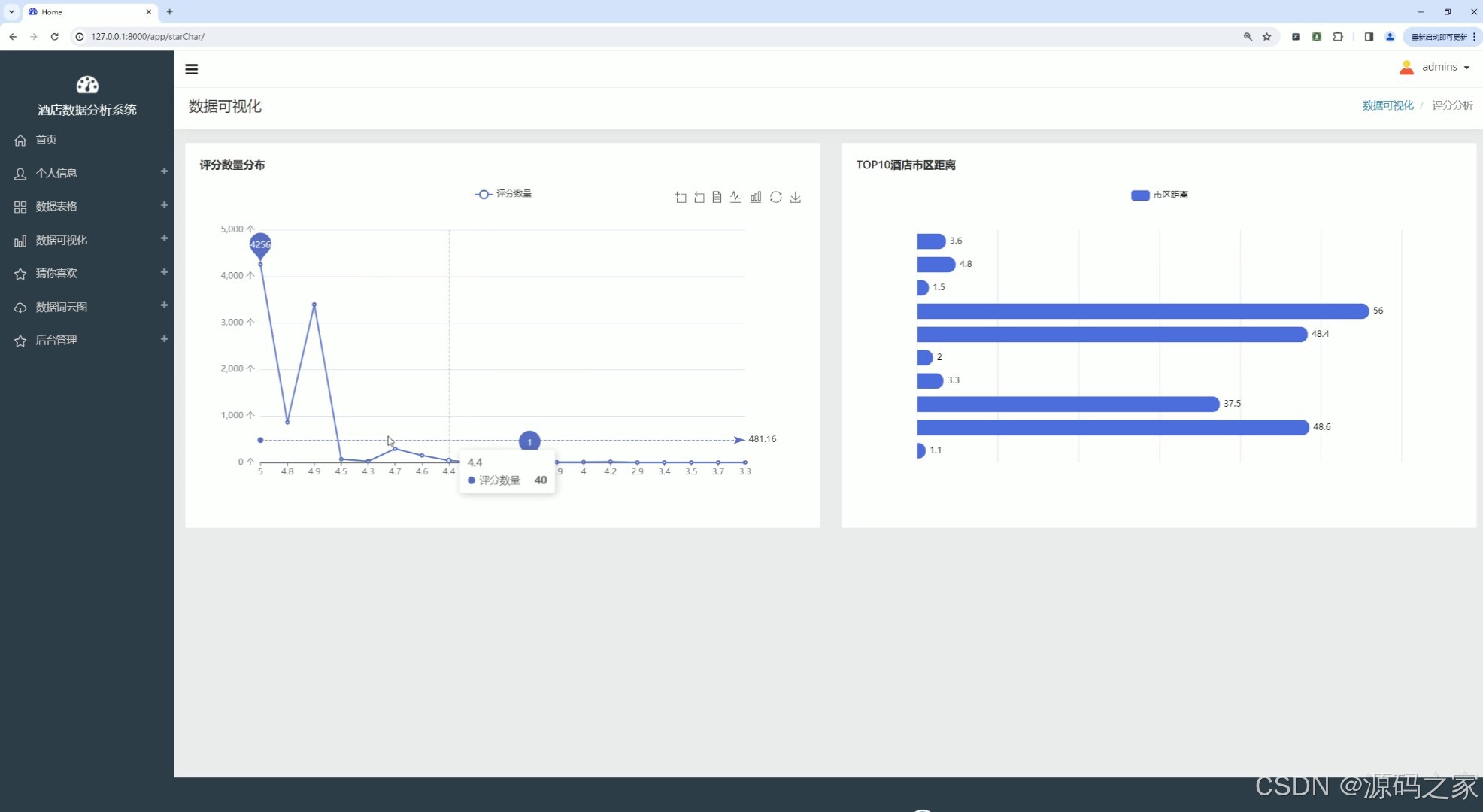
(5)酒店评分数量分布、酒店市区距离分布
该页面为酒店数据分析系统的评分分析可视化界面,以折线图展示不同评分区间的酒店数量分布,以横向柱状图呈现top10酒店的市区距离情况,可从评分与区位维度直观分析酒店的服务质量与地理分布特征。
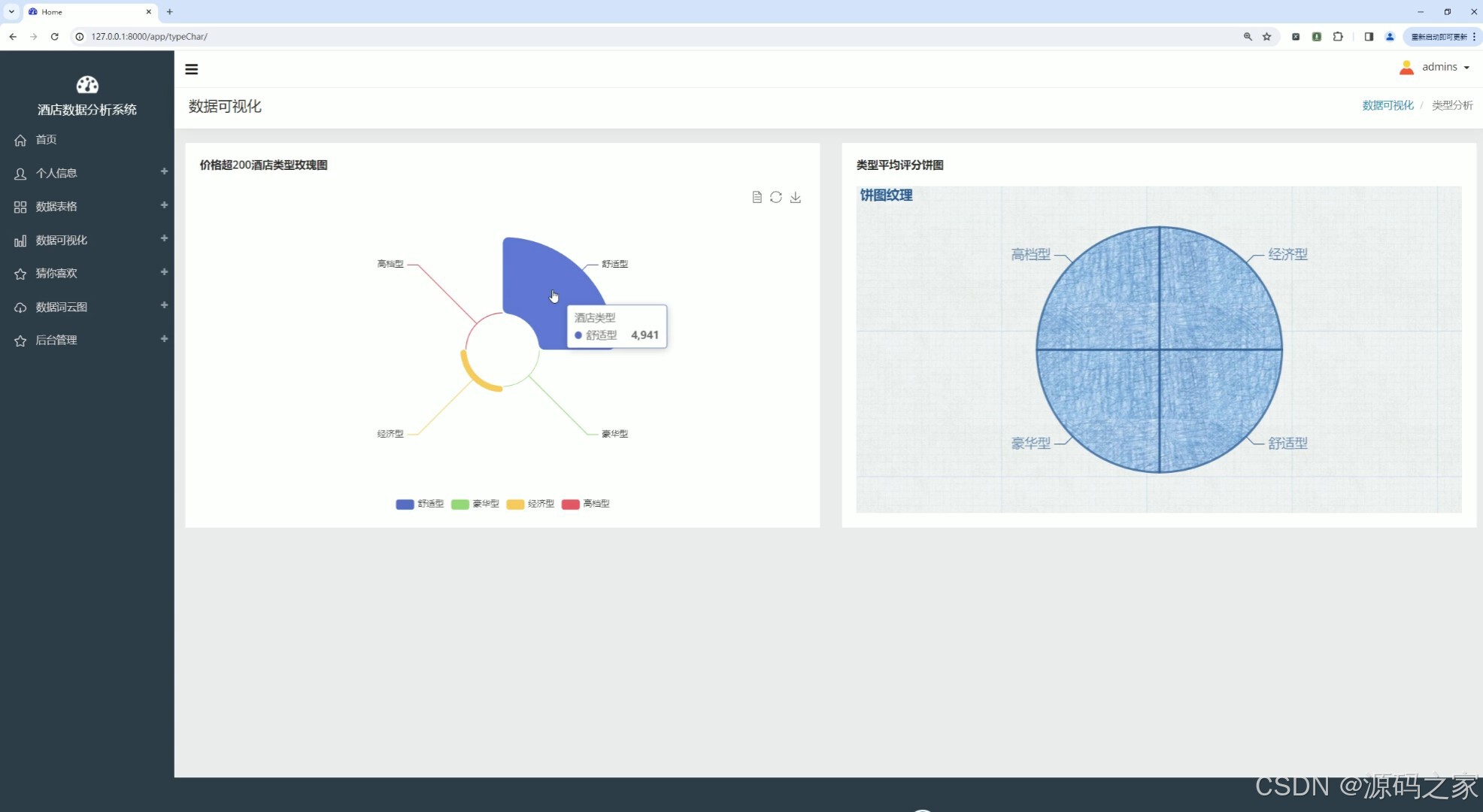
(6)价格超200酒店类型分析、酒店类型平均评分分析
该页面为酒店数据分析系统的类型分析可视化界面,左侧通过玫瑰图展示价格超200酒店的类型占比,右侧采用饼图呈现各类型酒店的平均评分情况,可从价格区间和评分维度直观对比不同类型酒店的分布特征与服务水平。
(7)酒店名称词云图分析
该页面为酒店数据分析系统的数据词云图界面,展示酒店名字词云,通过词语字体大小呈现对应酒店名称的出现频次与热度,直观反映数据集中的高频酒店名称分布特征,快速凸显热门酒店信息。

(8)注册登录界面
该页面为大数据酒店数据分析系统的登录界面,提供用户名与密码输入框,支持记住我功能,设有登录按钮与账号注册入口,可完成用户身份验证与账号创建,保障系统访问安全。
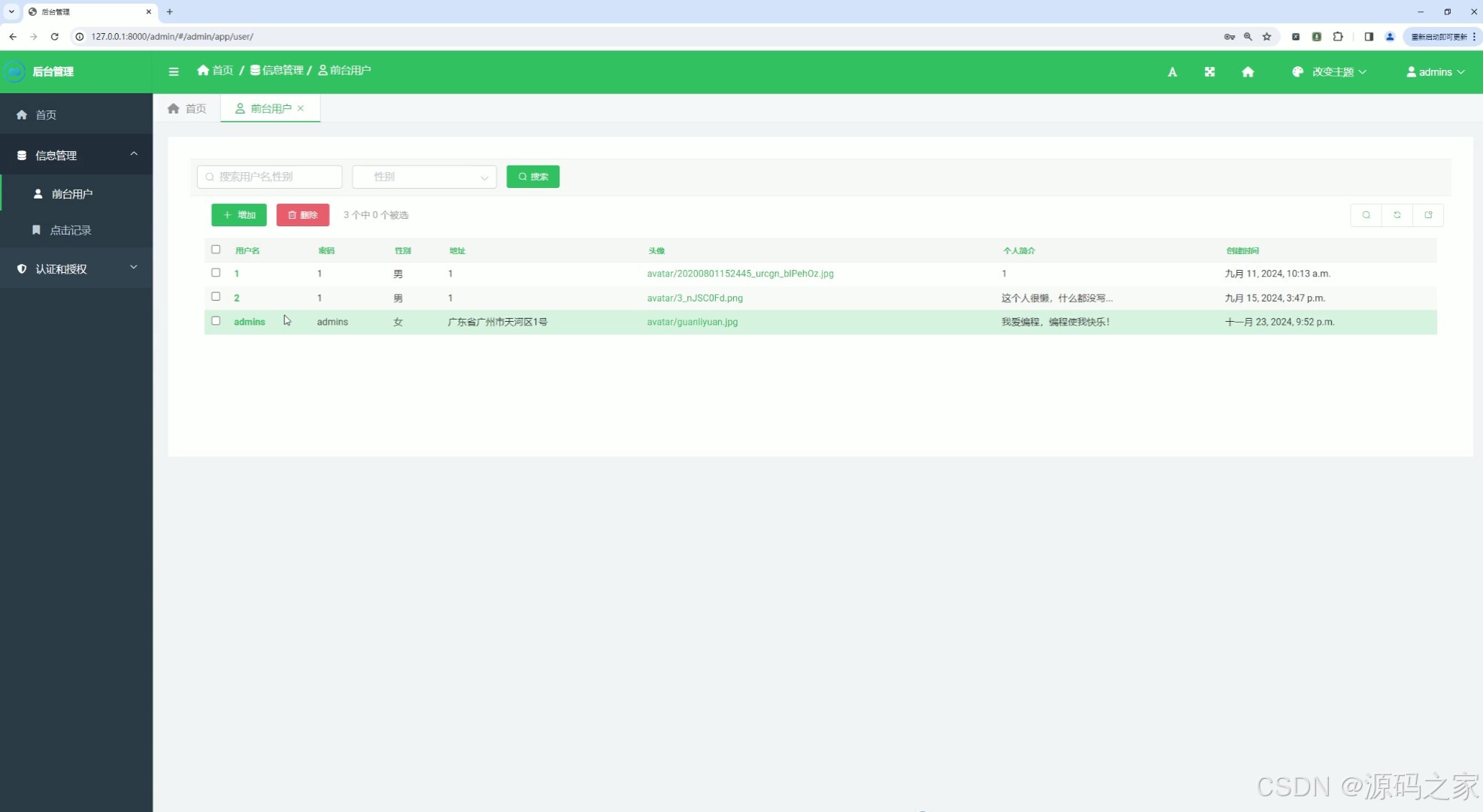
(9)后台数据管理
该页面为后台管理系统的前台用户管理界面,提供用户名和性别筛选搜索功能,以表格形式展示用户账号、性别、地址、头像等信息,支持增加、删除用户操作,可高效管理前台用户数据。
(10)Spark大数据分析
该页面为Python代码编辑与运行界面,基于Spark框架实现酒店数据的分布式分析,可完成城市均价排行、城市酒店数量统计、高价酒店筛选等分析任务,并在控制台输出分析结果,实现大数据场景下的酒店数据处理与统计展示。
3、项目说明
一、技术栈说明
本系统以Python为核心开发语言,后端采用Django框架构建业务逻辑与API接口,前端使用Vue框架实现响应式交互界面。大数据处理层基于Spark框架进行分布式计算,结合Hadoop实现HDFS分布式存储,通过Hive构建数据仓库对采集数据进行结构化管理和查询。数据采集层使用selenium爬虫技术从锦江酒店网站抓取酒店信息。推荐模块采用协同过滤算法,基于用户历史行为生成个性化推荐。可视化层借助Echarts图表库,将分析结果以多种图表形式在前端动态呈现。
二、功能模块详细介绍
· 数据采集模块
该模块基于selenium爬虫技术编写自动化采集脚本,实现对锦江酒店网站酒店数据的抓取。开发者可配置目标URL与采集规则,爬取内容包括酒店名称、地址、封面图片、市区距离、类型、标签、评分、价格、城市等字段。采集到的原始数据经初步整理后存入HDFS分布式文件系统,为后续大数据处理提供基础数据源。
· 数据清洗与预处理模块
原始数据存储于HDFS后,通过Hive构建数据仓库实现结构化管理和初步查询。模块调用Spark框架对数据进行分布式清洗处理,包括去重、异常值过滤、缺失值填补、字段格式标准化等操作。清洗后的高质量数据按照分析需求进行特征提取与维度划分,形成可用于可视化分析与推荐算法训练的标准数据集。
· 用户注册登录模块
系统前端提供统一的用户登录入口,包含用户名与密码输入框、登录按钮及注册链接。新用户可通过注册功能创建个人账号,后端对用户密码进行加密存储,并实现身份验证与会话管理。该模块保障系统访问安全,确保可视化分析与个性化推荐功能仅对授权用户开放。
· 可视化大屏展示模块
作为系统的核心展示界面,该模块将多维度分析结果集成于单一可视化大屏。页面包含城市均价柱状图、基础数据统计卡片、酒店数量柱状图、距离与价格对比图、评分对比面积图、评分分类统计表及类型分类饼图。用户可在一屏之内直观对比酒店在价格、评分、数量、距离等多个维度的分布特征与关联规律,快速把握市场整体状况。
· 酒店信息查询模块
该模块以数据表格形式呈现酒店详细信息,页面提供关键词搜索功能,支持按酒店名称、地址、城市等字段进行模糊查询。表格列展示酒店名称、地址、封面、市区距离、类型、标签、评分、价格、城市等字段,支持分页浏览与查看详情操作,方便用户快捷检索目标酒店并获取完整信息。
· 数据分析模块
模块基于清洗后的标准数据集,通过Spark进行多维度统计分析。分析内容包括酒店省市分布热力地图,以气泡标记形式呈现不同区域酒店数量聚集特征;价格区间分布柱状图,展示各价格段酒店数量;酒店类型环形图,分析不同类型酒店均价占比;评分分布折线图,呈现评分区间与酒店数量的关系;市区距离横向柱状图,对比top10酒店的地理区位;价格超200酒店类型玫瑰图与各类型平均评分饼图,从价格和评分维度对比不同类型酒店特征;酒店名称词云图,直观反映高频酒店名称分布。多角度分析结果为用户和运营者提供全面的数据洞察。
· 个性化推荐模块
该模块基于协同过滤推荐算法,分析用户历史评分与行为数据,挖掘用户偏好特征,生成个性化酒店推荐列表。模块通过Spark对用户行为数据进行分布式处理与模型训练,结合酒店特征维度进行相似度计算,为用户推送符合其兴趣偏好的酒店选项,提升用户体验与选择效率。
· 后台管理模块
该模块面向系统管理员,提供前台用户信息的集中管理功能。页面支持按用户名和性别进行筛选搜索,以表格形式展示用户账号、性别、地址、头像等信息,并提供增加用户、删除用户等操作接口。管理员可高效维护用户数据,保障系统用户信息的准确性与规范性。
三、项目总结
本系统经过技术选型、架构设计、模块开发与集成测试四个阶段,成功构建了一个基于Spark大数据框架的酒店数据分析与推荐平台。系统以北京地区酒店为核心分析对象,通过selenium爬虫采集锦江酒店网站数据,依托Hadoop HDFS实现分布式存储,利用Hive构建数据仓库进行结构化整理,借助Spark完成分布式清洗、特征提取与多维度统计分析,采用协同过滤算法实现个性化推荐,并通过Django与Vue搭建前后端分离架构,最终以Echarts可视化大屏和多种图表形式直观呈现分析结果。系统涵盖数据采集、清洗预处理、用户管理、可视化展示、酒店查询、数据分析、智能推荐、后台维护八大功能模块,为用户提供清晰的酒店选择依据,为运营者输出精准的市场分析报告,验证了大数据技术在酒店行业中的应用价值。
4、核心代码
python
# coding:utf8
# 导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import count, avg, col, sum, when
from pyspark.sql.functions import desc, asc
from pyspark.sql.functions import max, lit
def saved(result, table):
# MySQL JDBC URL 和连接属性
jdbc_url = "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"
# 将 DataFrame 写入 MySQL 数据库
result.write.mode("overwrite") \
.format("jdbc") \
.option("url", jdbc_url) \
.option("dbtable", f"{table}") \
.option("user", "root") \
.option("password", "root") \
.option("encoding", "utf-8") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.save()
# 将 DataFrame 写入 Hive 表,使用 parquet 格式
result.write.mode("overwrite").format("parquet").saveAsTable(f"{table}")
# 执行Hive查询并显示结果
spark.sql(f"select * from {table}").show()
if __name__ == '__main__':
# 构建SparkSession,并添加JDBC驱动路径
spark = SparkSession.builder.appName("sparkSQL").master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport(). \
getOrCreate()
sc = spark.sparkContext
# 读取数据表
hoteldata = spark.read.table('hoteldata')
# 需求1:城市均价排行
average_prices = hoteldata.groupby("city") \
.agg(avg(col("price")).alias("avg_price")) \
.orderBy(col("avg_price").desc())
# 取前十的城市均价
result1 = average_prices.limit(10)
saved(result1, 'avepriceTop')
# 需求2:统计各大城市酒店
city_counts = hoteldata.groupby("city") \
.agg(count('*').alias("city_count")) \
.orderBy(desc("city_count"))
result2 = city_counts.limit(10)
saved(result2, 'cityTop')
# 需求3:获取价格前十的数据,保留 'title', 'price', 'star' 列
top_ten_prices = hoteldata.orderBy(col("price").desc()).limit(10)
# 查找 star 字段的最大值
max_star = hoteldata.agg(max(col("star"))).collect()[0][0]
# 将最大值转换为字符串,并截取保留一位小数
max_star_str = "{:.1f}".format(max_star) # 保留一位小数作为字符串
max_star_truncated = float(max_star_str) # 转回浮点数
# 将最大 star 值添加为一个新列到 top_ten_prices DataFrame
top_ten_with_max_star = top_ten_prices.withColumn("max_star", lit(max_star_truncated))
# 保存结果
saved(top_ten_with_max_star, 'priceTop')
# 需求4:酒店前十的价格与市区距离对比
result4 = top_ten_prices.select("overCenter", "title", "price").limit(10)
saved(result4, 'centerPriceTop')
# 需求4:酒店前十的价格与评分对比
result5 = top_ten_prices.select("star", "title", "price").limit(10)
saved(result5, 'starPriceTop')
# 需求6:评分分类
hoteldata_starclass = hoteldata.withColumn(
"star_category",
when(col("star").between(0, 4.6), "0到4.6一般")
.when(col("star").between(4.6, 4.8), "4.6到4.8良好")
.when(col("star").between(4.8, 4.9), "4.8到4.9优秀")
.when(col("star").between(4.9, float('inf')), "4.9以上/卓越")
.otherwise("未分类")
)
result6 = hoteldata_starclass.groupby("star_category").agg(count('*').alias("count"))
saved(result6, 'starcategory')
# 需求7:类型分析
result7 = hoteldata.groupby("type").agg(count('*').alias("count"))
saved(result7, 'typecategory')
# 需求8:价格区间分类
hoteldata_priceclass = hoteldata.withColumn(
"price_category",
when(col("price").between(0, 100), "0到100")
.when(col("price").between(100, 200), "100到200")
.when(col("price").between(200, 300), "200到300")
.when(col("price").between(300, 400), "300到400")
.when(col("price").between(400, 500), "400到500")
.when(col("price").between(500, float('inf')), "500以上")
.otherwise("未分类")
)
# 统计每个价格区间的酒店数量
result8 = hoteldata_priceclass.groupby("price_category").agg(count('*').alias("count"))
saved(result8, 'pricecategory')
# 需求9:各类型价格
result9 = hoteldata.groupby("type").agg(avg(col("price")).alias("avg_price"))
saved(result9, 'typeprice')
# 需求10:评分前十的酒店的标题和市区距离
top_start_values = hoteldata.orderBy(desc("star")).limit(10)
result10 = top_start_values.select("title", "overCenter")
saved(result10, 'starCenter')
# 需求11:按类型分组,计算每种类型中价格超过200的酒店数量
result11 = hoteldata.groupby("type").agg(
sum(when(col("price") > 200, 1).otherwise(0)).alias("price_over")
)
saved(result11, 'typeTwo')
# 需求12:计算每种类型的酒店的平均评分
type_avg_start = hoteldata.groupby("type").agg(avg("star").alias("avg_start"))
# 将结果按类型排序
result12 = type_avg_start.orderBy("type")
saved(result12, 'typeStar')
# 需求13:计算每个城市的酒店数量
result13 = hoteldata.groupby("city").count()
saved(result13, 'addresssum')5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看 👇🏻获取联系方式👇🏻