在人工智能从"感知智能"迈向"认知智能"的今天,大语言模型(LLM)正加速超越对话助手的局限,演变为可编程、可集成的智能数据代理(AI Agent)。它们不仅能理解人类用自然语言表达的复杂意图,更能主动执行信息检索、结构化提取、层级组织乃至逻辑校验等类人任务。这一能力为垂直领域知识库的构建提供了全新可能:无需依赖网页结构、不需人工标注、也无须采购昂贵的商业数据库,仅通过语义指令即可驱动模型生成高质量结构化数据。
传统数据采集方式长期面临多重瓶颈:网络爬虫易受反爬策略、页面改版或法律合规限制;人工整理成本高、效率低、难以规模化;而第三方数据接口则常存在字段不全、更新滞后或授权壁垒等问题。相比之下,基于大模型的自动化方案以低代码、高灵活性和强语义理解为核心优势,正在成为新一代轻量级数据工程的实用替代路径。尤其在中小团队或快速原型场景中,这种"用语言定义数据"的范式显著降低了结构化知识获取的门槛。
然而,要让大模型真正"可靠地干活",关键不在于模型本身有多强大,而在于我们如何精准地下达任务指令 。一段模糊的提问可能换来辞藻华丽却空洞无用的回答,甚至掺杂幻觉与虚构;而一个结构清晰、约束明确、边界严谨的提示词(Prompt),则能引导模型像一位训练有素的数据专员,输出格式统一、去重排序、字段规范的结构化结果。这背后,是提示词工程(Prompt Engineering) 与 数据契约(Data Contract) 思维的深度融合------我们不再"问问题",而是"派任务"。
本文通过三个典型场景完整验证这一 AI Agent 工作流:首先,构建覆盖传统与新兴势力的中文汽车品牌数据库 (包含小米、蔚来等新入局者);进而挑战更复杂的地理信息任务,分步生成全国省-市-县三级行政区划 结构化数据,进一步地,将范式延伸至医疗健康领域,通过分科室精细化提示,自动生成涵盖内科、外科、精神科等 20 余个临床方向的常见疾病标准名称清单,确保命名规范、覆盖广泛。整个过程仅需调用 Qwen3-8B 等开源模型的云端 API,配合百行 Python 脚本,即可实现从"一句话需求"到"可用数据资产"的端到端转化。更重要的是,这套方法论具备高度可迁移性------无论是整理高校名单、提取药品目录,还是生成行业术语词典,只需调整提示词中的领域定义与输出规范,同一框架即可复用。用语言驱动数据,让 AI 成为你最高效的初级数据工程师------这正是 AI Agent 时代赋予每个开发者的新型生产力工具。
硅基流动:硅基流动 SiliconFlow - 致力于成为全球领先的 AI 能力提供商
首先,我们先可以在这个平台注册登录,申请一个个人API,然后调用免费的大模型进行构建品牌数据库;
在价格这部分,我们可以各类大模型的输入输出价格,我们选择免费的模型进行测试;
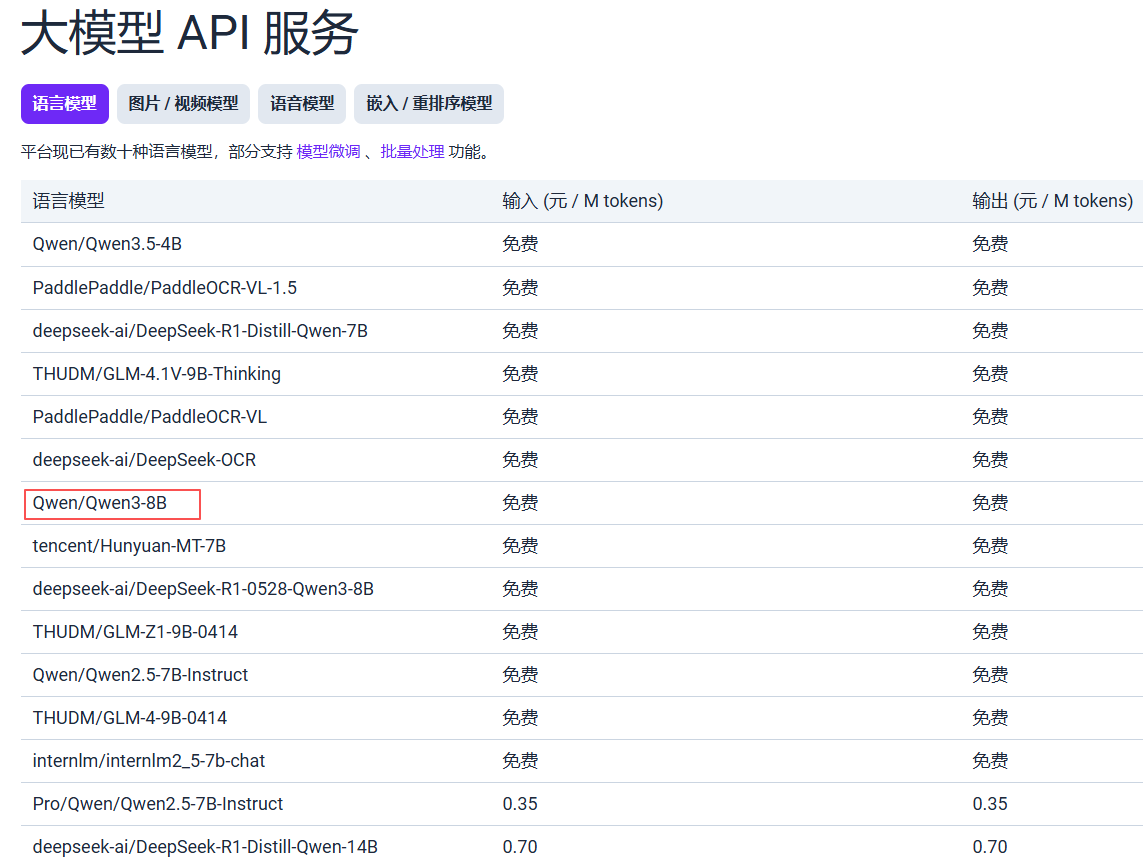
在本文的实践中,我们以构建中文汽车品牌数据库为具体任务场景,选用 Qwen/Qwen3-8B 作为核心推理模型, Qwen3-8B 在保持较小参数量的同时,展现出卓越的中文理解与生成能力,尤其在事实性问答、结构化数据提取和指令遵循方面表现稳定,我们通过形成python脚本来进行实现中文汽车品牌数据库的构建;
完整代码#运行环境 Python 3.11
python
from openai import OpenAI
import json
import re
import csv
# === 配置 ===
API_KEY = "你的API"
MODEL_NAME = "Qwen/Qwen3-8B"
client = OpenAI(
api_key=API_KEY,
base_url="https://api.siliconflow.cn/v1"
)
# === 提示词:要求中文品牌名 ===
prompt = """
你是一个权威的汽车行业知识库。请列出全球范围内所有主流和常见的汽车品牌的**标准中文名称**。
要求:
1. 仅输出 JSON 格式,不要任何解释、注释或额外文本。
2. JSON 必须包含一个键 "brands",其值是一个字符串数组。
3. 使用中国大陆通用的官方或广泛接受的中文译名(例如:"丰田"、"大众"、"比亚迪"、"特斯拉")。
4. 包含中国品牌(如 比亚迪、蔚来、小鹏、吉利)、欧美日韩等主要国家品牌。
5. 不要包含车型(如"凯美瑞")、子品牌(如"AMG")、经销商名称或虚构品牌。
6. 去重,并按中文拼音首字母顺序排序(A-Z)。
7. 如果某个品牌在中国没有通用中文名,可跳过。
示例格式:
{
"brands": ["阿尔法·罗密欧", "奥迪", "宝马", "奔驰", "比亚迪", "大众", "丰田", ...]
}
"""
try:
print("正在调用 Qwen3-8B 获取中文汽车品牌列表...")
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=2000
)
content = response.choices[0].message.content.strip()
# 清理可能的 Markdown 代码块
content = re.sub(r"^```(?:json)?\s*", "", content)
content = re.sub(r"\s*```$", "", content)
# 解析 JSON
result = json.loads(content)
brands = result.get("brands", [])
if not brands:
raise ValueError("返回的品牌列表为空")
print(f"成功获取 {len(brands)} 个中文汽车品牌")
# === 写入 CSV 文件(带 BOM,兼容 Excel 中文)===
output_file = "car_brands_zh.csv"
with open(output_file, "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f)
writer.writerow(["brand_name"]) # 表头
for brand in brands:
writer.writerow([brand])
print(f"已成功保存至 {output_file}")
print("\n前10个品牌预览:")
for i, brand in enumerate(brands[:10], 1):
print(f"{i:2}. {brand}")
except json.JSONDecodeError:
print("模型返回内容不是合法 JSON:")
print(response.choices[0].message.content)
except Exception as e:
print(f"发生错误: {e}")
数据会以csv表格的形式,保存在运行脚本的目录下,存储名称为car_brands_zh.csv,字段为(brand_name)品牌名;

如果汽车品牌量有所缺失,或者不完整,我们可以通过优化提示词的形式来进行调整,比如,这里部分新兴品牌没有加入进来,我们增加要求:即使品牌较新,只要已公开发布量产车型并开始交付,就必须包含;
简单的来说,无需修改代码或重新训练模型,通过调整自然语言指令(即提示词),即可动态引导 AI Agent 输出更符合业务需求的结构化数据;
python
prompt = """
你是一个权威的汽车行业知识库。请列出全球范围内所有主流和常见的汽车品牌的**标准中文名称**,**特别注意包含近年新成立但已量产交付的中国智能电动汽车品牌,例如:小米、蔚来、小鹏、理想、极氪、问界、智己、阿维塔等**。
要求:
1. 仅输出 JSON 格式,不要任何解释、注释或额外文本。
2. JSON 必须包含一个键 "brands",其值是一个字符串数组。
3. 使用中国大陆通用的官方中文名(如 "比亚迪"、"特斯拉"、"小米")。
4. 包含传统车企(如大众、丰田)和新兴智能电动车企。
5. 不要包含车型(如"SU7")、子品牌或经销商。
6. 去重,并按中文拼音首字母排序。
7. 即使品牌较新,只要已公开发布量产车型并开始交付,就必须包含。
示例格式:
{
"brands": ["阿尔法·罗密欧", "奥迪", "宝马", "奔驰", "比亚迪", "大众", "丰田", "小米", "蔚来", ...]
}
"""在成功利用提示词工程与 Qwen3-8B API 自动化构建汽车品牌数据库后,我们进一步将这一范式迁移到更复杂的地理信息领域------通过分步调用大模型,自动生成结构完整、层级清晰的全国省、市、县三级行政区划 CSV 数据集;
完整代码#运行环境 Python 3.11
python
from openai import OpenAI
import json
import re
import csv
import time
import os
# === 配置 ===
API_KEY = "你的API"
MODEL_NAME = "Qwen/Qwen3-8B"
client = OpenAI(
api_key=API_KEY,
base_url="https://api.siliconflow.cn/v1"
)
def clean_json_text(text):
"""清理可能的 Markdown 和截断"""
text = text.strip()
text = re.sub(r"^```(?:json)?\s*", "", text)
text = re.sub(r"\s*```$", "", text)
return text
def safe_parse_json(text, province_name):
"""安全解析 JSON,失败时返回空列表"""
try:
cleaned = clean_json_text(text)
# 如果结尾不完整(如只有 "阿"),尝试补全(简单策略)
if not cleaned.endswith("}"):
# 启发式:如果太短,直接放弃
if len(cleaned) < 20:
print(f"{province_name} → 响应过短,跳过")
return {"cities": []}
return json.loads(cleaned)
except json.JSONDecodeError as e:
print(f"{province_name} → JSON 解析失败: {str(e)[:100]}")
return {"cities": []}
def get_cities_and_districts(province_name, max_retries=3):
prompt = f"""
你是一个权威的中国行政区划数据库。请列出"{province_name}"下辖的所有地级行政单位(包括地级市、自治州、地区、盟)及其下辖的县级单位(包括市辖区、县级市、县、自治县、旗等)。
要求:
1. 仅输出 JSON 格式,不要任何解释。
2. 结构:{{"cities": [{{"name": "广州市", "districts": ["越秀区", "天河区", ...]}}, ...]}}
3. 使用最新官方名称(截至2024年),不要包含街道或乡镇。
4. 如果该省是直辖市(如北京市),则地级单位名称仍为"{province_name}",其下直接是区。
"""
for attempt in range(1, max_retries + 1):
try:
print(f"尝试第 {attempt}/{max_retries} 次...")
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=2500, # 略微提高
timeout=60 # 关键:延长超时
)
content = response.choices[0].message.content
data = safe_parse_json(content, province_name)
cities = data.get("cities", [])
if cities:
return cities
else:
print(f"{province_name} → 返回空数据")
except Exception as e:
print(f"第 {attempt} 次失败: {e}")
if attempt < max_retries:
time.sleep(2 ** attempt) # 指数退避
return []
def get_provinces():
prompt = """
你是一个权威的中国行政区划数据库。请列出中国大陆(不含港澳台)所有的省级行政区名称,包括:
- 23个省(如:河北省、山西省)
- 5个自治区(如:内蒙古自治区、广西壮族自治区)
- 4个直辖市(如:北京市、上海市)
要求:
1. 仅输出 JSON 格式,不要任何解释。
2. 结构:{"provinces": ["北京市", "天津市", "河北省", ...]}
3. 使用官方全称。
"""
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=1000
)
content = clean_json_text(response.choices[0].message.content)
data = json.loads(content)
return data["provinces"]
def main():
output_file = "china_admin_divisions_full.csv"
# 加载已有数据
completed_provinces = set()
all_rows = []
if os.path.exists(output_file):
with open(output_file, "r", encoding="utf-8-sig") as f:
reader = csv.reader(f)
header = next(reader, None)
if header:
for row in reader:
if len(row) >= 3:
all_rows.append(row)
completed_provinces.add(row[0])
print(f"已存在 {len(all_rows)} 条记录,跳过 {len(completed_provinces)} 个省份")
try:
provinces = get_provinces()
print(f"共获取 {len(provinces)} 个省级单位")
for i, province in enumerate(provinces, 1):
if province in completed_provinces:
print(f"[{i}/{len(provinces)}] {province} → 已完成")
continue
print(f"[{i}/{len(provinces)}] 正在获取 {province} 的市-县数据...")
cities = get_cities_and_districts(province)
if not cities:
print(f" {province} → 最终未能获取有效数据")
continue
# 构造行
new_rows = []
for city in cities:
city_name = city["name"]
districts = city.get("districts", [])
for district in districts:
new_rows.append([province, city_name, district])
# 保存
all_rows.extend(new_rows)
with open(output_file, "w", encoding="utf-8-sig", newline="", errors="replace") as f:
writer = csv.writer(f)
writer.writerow(["province", "city", "district"])
writer.writerows(all_rows)
print(f" {province} → 成功获取 {len(new_rows)} 条记录")
time.sleep(0.8) # 更宽松的间隔
print(f"\n全部完成!共 {len(all_rows)} 条记录,已保存至 {output_file}")
except KeyboardInterrupt:
print("\n用户中断,进度已保存。")
except Exception as e:
print(f"主流程异常: {e}")
if __name__ == "__main__":
main()数据会以csv表格的形式,保存在运行脚本的目录下,存储名称china_admin_divisions_full.csv,字段为(province、city、district)省、市、县;
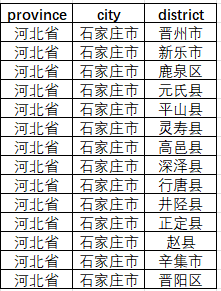
在成功构建汽车品牌与行政区划数据集的基础上,我们将这一 AI Agent 范式进一步拓展至医疗健康领域------通过分科室精细化提示,自动生成覆盖临床各科、数量更全、命名规范的常见疾病清单;
完整代码#运行环境 Python 3.11
python
from openai import OpenAI
import json
import re
import csv
import time
import os
# === 配置 ===
API_KEY = "你的API"
MODEL_NAME = "Qwen/Qwen3-8B"
client = OpenAI(
api_key=API_KEY,
base_url="https://api.siliconflow.cn/v1"
)
def clean_json_text(text):
text = text.strip()
text = re.sub(r"^```(?:json)?\s*", "", text)
text = re.sub(r"\s*```$", "", text)
return text
def get_medical_categories():
"""获取全面的临床科室列表(含细分)"""
prompt = """
你是一个权威的医学知识库。请列出中国医院中用于疾病分类的常见临床科室名称,包括主要大科及其常见细分科室。
要求:
1. 仅输出 JSON 格式。
2. 结构:{"categories": ["内科", "外科", "妇产科", "儿科", "皮肤科", "眼科", "耳鼻喉科", "口腔科", "精神科", "传染科", "肿瘤科", "骨科", "神经内科", "心血管内科", "消化内科", "呼吸内科", "内分泌科", "泌尿外科", "整形外科", "康复医学科"]}
3. 优先包含高频、标准科室,总数控制在 20--25 个以内。
"""
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=600,
timeout=25
)
content = clean_json_text(response.choices[0].message.content)
data = json.loads(content)
return data["categories"]
def get_diseases_for_category(category, max_retries=3):
"""为每个科室生成尽可能多的常见疾病(15--25种)"""
prompt = f"""
你是一个权威的医学知识库。请列出"{category}"中最常见的 20--25 种疾病或疾病大类的标准中文名称。
要求:
1. 仅输出 JSON 格式:{{"diseases": ["疾病1", "疾病2", ...]}}
2. 使用《疾病分类与代码国家临床版》中的规范病名;
3. 包括高发、典型、具有代表性的疾病;
4. 可包含疾病大类(如"原发性高血压"、"2型糖尿病"、"乳腺癌"),但不要写症状(如"胸痛")、体征或检查异常;
5. 尽量覆盖该科室的主要诊疗范围,数量不少于 15 种。
"""
for attempt in range(1, max_retries + 1):
try:
print(f"尝试第 {attempt}/{max_retries} 次...")
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
max_tokens=1000, # 给足空间
timeout=35 # 略微延长
)
content = clean_json_text(response.choices[0].message.content)
data = json.loads(content)
diseases = [d.strip() for d in data.get("diseases", []) if d.strip()]
# 去重并过滤无效项
unique_diseases = []
seen = set()
for d in diseases:
if d and d not in seen and len(d) >= 2:
unique_diseases.append(d)
seen.add(d)
return unique_diseases[:25] # 最多取25个
except Exception as e:
print(f"失败: {e}")
if attempt < max_retries:
time.sleep(2 ** attempt)
return []
def main():
output_file = "common_diseases_comprehensive.csv"
# 断点续跑:加载已有数据
completed_categories = set()
all_rows = []
if os.path.exists(output_file):
with open(output_file, "r", encoding="utf-8-sig") as f:
reader = csv.reader(f)
header = next(reader, None)
if header:
for row in reader:
if len(row) >= 2:
all_rows.append(row)
completed_categories.add(row[0])
print(f"已存在 {len(all_rows)} 条记录,跳过 {len(completed_categories)} 个科室")
try:
categories = get_medical_categories()
print(f"共 {len(categories)} 个科室待处理: {', '.join(categories)}")
for i, cat in enumerate(categories, 1):
if cat in completed_categories:
print(f"[{i}/{len(categories)}] {cat} → 已完成")
continue
print(f"[{i}/{len(categories)}] 正在获取 {cat} 的疾病列表(目标 15--25 种)...")
diseases = get_diseases_for_category(cat)
if not diseases:
print(f"{cat} → 未能获取有效疾病")
continue
new_rows = [[cat, d] for d in diseases]
all_rows.extend(new_rows)
# 实时保存
with open(output_file, "w", encoding="utf-8-sig", newline="", errors="replace") as f:
writer = csv.writer(f)
writer.writerow(["category", "disease"])
writer.writerows(all_rows)
print(f"{cat} → 成功获取 {len(diseases)} 种疾病")
time.sleep(1.0) # 稍长间隔,更稳定
total_diseases = len(all_rows)
total_categories = len(set(row[0] for row in all_rows))
print(f"\n完成!共覆盖 {total_categories} 个科室,{total_diseases} 种疾病")
print(f"数据已保存至 {output_file}")
except KeyboardInterrupt:
print("\n用户中断,进度已保存。")
except Exception as e:
print(f"主流程出错: {e}")
if __name__ == "__main__":
main()数据会以csv表格的形式,保存在运行脚本的目录下,存储名称common_diseases_comprehensive.csv,字段为(category、disease)类别、疾病;
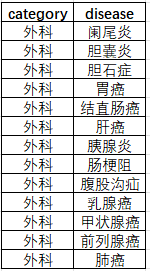
**这里有一个tips:**API_KEY这里需要替换成自己申请的API,另外单一内容输出数量太大的话可以进行分类输出,比如不同省市、不同疾病科等等;
上述汽车品牌数据库,疾病名称数据集与全国省-市-县三级行政区划数据集的构建,本质上是一次轻量级但完整的 AI Agent 数据生产实践 。这三个案例并非以替代官方权威数据源为目标,也不追求生产环境中的绝对精度,而是旨在验证一种新型、可落地的工作流:通过精心设计的结构化提示词 、标准化的大模型 API 调用 以及自动化的后处理逻辑,将大语言模型转化为一个可编程、可复现的数据采集与结构化工具。整个过程无需部署爬虫、不依赖人工标注团队,仅凭自然语言指令即可在短时间内生成垂直领域的结构化数据资产。
正因这一范式的简洁性与通用性,其应用场景远不止于当前示例。无论是提取国家药品目录、整理全国高校及专业列表、汇总上市公司基本信息,还是构建法律术语库、电商品类体系或科研关键词词典,只需在提示词中明确定义目标实体、字段结构与输出格式,同一套技术框架便可快速迁移复用。这种"用语言驱动数据"的能力,标志着数据工程正在从代码密集型向意图驱动型演进------开发者不再需要为每个新数据源重写解析规则,而只需清晰地"告诉 AI 要什么",剩下的交给智能代理完成。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。